 電子發燒友App
電子發燒友App


隨著“大數據”概念而興起的分布式機器學習,在人工智能的新時代里解決了大量最具挑戰性的問題。
近幾年,機器學習在很多領域取得了空前的成功,也因此徹底改變了人工智能的發展方向。大數據時代的到來一方面促進了機器學習的長足發展,另一方面也給機器學習帶來了前所未有的新挑戰。
在這些發展與挑戰中,分布式機器學習應運而生并成功解決了大量具有挑戰性的關鍵問題,今天晚上班主任就來和同學們聊一聊分布式機器學習起源、流程、算法以及目前流行的分布式機器學習平臺。
01
起源:大數據和大模型帶來的挑戰
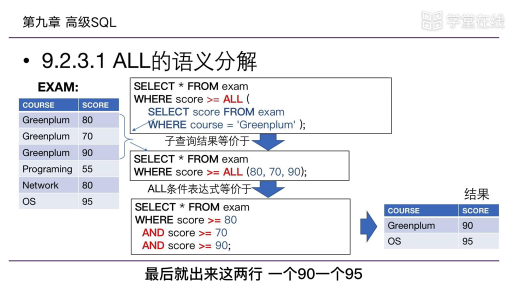
在開始聊起源之前,我們先來看張圖:
這張圖是展示了ImageNet近幾年的錯誤率,2011年的時候錯誤率還將近有25%,這樣的錯誤率很難運用到實際應用中。到2015年,ImageNet錯誤率已經降低到3%左右,比人類的錯誤率(5%)還要低, 短短的4-5年時間,機器在ImageNet上的識別率便超過了人類。
導致這一結果的原因有2個:一是數據,另一個是模型。
大規模訓練數據的出現為訓練大模型提供了物質基礎,大規模機器學習模型具有超強的表達能力,可以解決很多復雜和高難度的問題。
在解決這些問題的同時,大規模機器學習模型也有著非常明顯的弊端:包含參數眾多,訓練耗時;模型巨大,傳統的計算機和工作站難以處理;容易過擬合,在訓練數據集上表現良好,在未知測試數據上表現不盡人意。
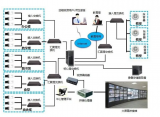
比較典型的例子是電商網站上的用戶行為數據,比如在淘寶上很多用戶每天都能看到系統推薦的產品,這些產品是根據用戶日常瀏覽和點擊習慣進行推薦的,淘寶的服務器將用戶點擊的產品行為記錄下來,作為分布式機器學習系統的輸入。輸出是一個數學模型,可以預測一個用戶喜歡看到哪些商品,從而在下一次展示推薦商品的時候,多展示那些用戶喜歡的商品。
類似的,還有互聯網廣告系統,根據幾億用戶的廣告點擊行為,為其推薦更容易被點擊的廣告。
淘寶推薦系統大致如圖所示
由上述案例可以知,現在我們很難用一臺計算機去處理工業規模的機器學習模型了,所以說分布式訓練已經成為了一個先決條件。
流程:了解-探索-設計
分布式機器學習說白了,其實就是把任務發放給許多機器,然后讓它們協同去幫忙訓練數據和模型。

如圖所示,我們會把任務下發給許多的worker,然后這些worker協同的去訓練模型。
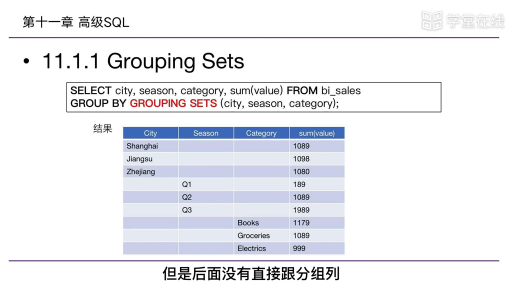
通過對分布式機器學習起源的講解,我們可以將分布式機器學習的使用場景粗分為三類:計算量太大、訓練數據太多、訓練模型太大太過復雜。
這三種場景都有相對應的解決辦法,對于計算量太大可采用共享內存的多機并行運算;對于訓練數據太多,可以將數據進行劃分,分配到多個工作節點上進行訓練;而對于訓練模型太大,也可以將模型進行劃分,分配到不同的工作節點上進行訓練。

不管是以上場景中的哪一種,還是幾種場景混合在一起的情況,分布式機器學習都可以分為三步流程:
第一步是了解機器學習的模型以及優化方法;第二步是要去探索分布式機器學習的范式;第三步是設計系統,無論系統的設計者還是系統的使用者,都要知道系統為什么要這樣設計,這樣設計對我們選擇什么樣的機器學習有怎樣的幫助。
算法:數據并行、模型并行、梯度下降
數據并行
數據并行是指由于訓練樣本非常多模型非常大,我們需要把訓練數據劃分到不同的機器上,比如說我們用100臺機器同時存儲這些數據,如果這些模型有10萬個數據樣,用100臺機器來存儲,每臺機器存儲1000條數據即可。
對于每一臺worker來說,訓練算法、分布式和在單機上沒有什么區別,只是需要在節點之間同步模型參數。
其中參數平均是最簡單的一種數據并行化。若采用參數平均法,訓練的過程如下所示:
1、基于模型的配置隨機初始化網絡模型參數
2、將當前這組參數分發到各個工作節點
3、在每個工作節點,用數據集的一部分數據進行訓練
4、將各個工作節點的參數的均值作為全局參數值
5、若還有訓練數據沒有參與訓練,則繼續從第二步開始

模型并行
模型并行將模型拆分成幾個分片,由幾個訓練單元分別持有,共同協作完成訓練。
深度學習的計算其實主要是矩陣運算,而在計算時這些矩陣都是保存在內存里的,如果是用GPU卡計算的話就是放在顯存里,可是有的時候矩陣會非常大。面對這種超大矩陣便需要將其拆分,分到不同處理器上去計算。

梯度下降
1847年梯度下降被提出來之后,這些年業內提出了各種各樣的優化算法,優化算法是一個非常漫長的演變過程。

大家可以看到圖中有一條分界線, 在2010之前的算法主要是Deterministic algorithms,這種算法具有很強確定性。換句話說,就是可以在數學上保證此算法進行的每一步都是精確的,能夠指導我們的優化目標。
2010年之后的這些模型被稱做stochastic algorithms,不再要求每一步都是精確的梯度下降,或者每一步要做最精確的優化。stochastic algorithms讓每一步只進行隨機的優化,最終把所有數據優化完以后,還是能夠優化到最低點。
隨著數據越來越大,Deterministic algorithms規則已經越來變得越來越不適用了。對于大量的計算數據,我們不可能每一次都做梯度下降,隨機梯度下降變得越來越有優勢,資源利用率也會更高。
04
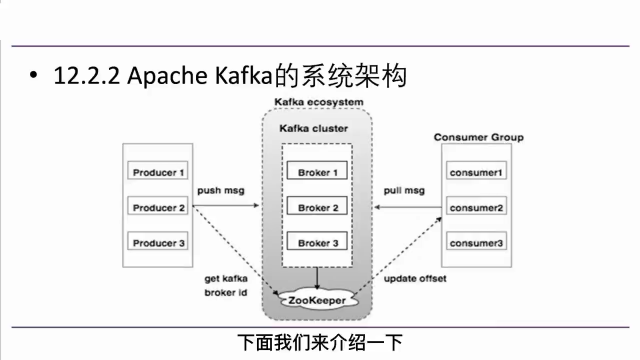
分布式機器學習三大平臺:Spark、PMLS、TensorFlow
在紐約州立大學布法羅分校計算機科學與工程教授、Petuum Inc. 顧問 Murat Demirbas 和他的兩位學生一起發表的那篇對比現有分布式機器學習平臺的論文中,將分布式機器學習平臺歸類為了三大基本設計方法:
1.基本數據流(basic dataflow)
2.參數服務器模型(parameter-server model)
3.先進數據流(advanced dataflow)
并根據這三大基本設計方法,使用了業內著名的三大分布式機器學習平臺,其中基本數據流方法使用了 Apache Spark、參數服務器模型使用了 PMLS(Petuum)、先進數據流模型使用了 TensorFlow 和 MXNet。
并在測試中得出相應的結論,班主任摘取關鍵部分出來,供大家參考(論文原文可訪問:https://www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf,譯文參考網絡翻譯)
Spark
在基本的設置中,Spark 將模型參數存儲在驅動器節點,工作器與驅動器通信從而在每次迭代后更新這些參數。對于大規模部署而言,這些模型參數可能并不適合驅動器,并且會作為一個 RDD 而進行維護更新。
這會帶來大量額外開銷,因為每次迭代都需要創造一個新的 RDD 來保存更新后的模型參數。更新模型涉及到在整個機器/磁盤上重排數據,這就限制了 Spark 的擴展性。
PMLS
PMLS節點會存儲和更新模型參數以及響應來自工作器的請求。工作器會請求來自它們的局部 PS 副本的最新模型參數,并在分配給它們的數據集部分上執行計算。
?
PMLS還采用了 SSP(Stale Synchronous Parallelism)模型,這比 BSP(Bulk Synchronous Parellelism)模型更寬松——其中工作器在每次迭代結束時同步。SSP 為工作器的同步減少了麻煩,確保最快的工作器不能超過最慢的工作器 s 次迭代。
?TensorFlow
?TensorFlow使用節點和邊的有向圖來表示計算。節點表示計算,狀態可變。而邊則表示多維數據數組(張量),在節點之間傳輸。
TensorFlow 需要用戶靜態聲明這種符號計算圖,并對該圖使用復寫和分區(rewrite& partitioning)將其分配到機器上進行分布式執行。(MXNet,尤其是 DyNet 使用了圖的動態聲明,這改善了編程的難度和靈活性。)
?

































 工商網監
工商網監
評論