 電子發(fā)燒友App
電子發(fā)燒友App


編者按:最近英特爾舉辦了一場引人注目的“架構(gòu)日”活動,公布了未來多年的產(chǎn)品技術(shù)路線圖、技術(shù)戰(zhàn)略規(guī)劃以及一系列新技術(shù)。外媒The Next Platform隨即發(fā)布了一篇深度分析文章,對Tick-Tock模式演進和Foveros 3D芯片封裝技術(shù)進行了深度解析。作者認為,面臨壓力,英特爾能從現(xiàn)有工藝中釋放出超乎想象的更高性能;而Foveros將在不久的將來為英特爾計算引擎的構(gòu)建奠定基礎(chǔ)。
以下為部分摘選:
創(chuàng)新離不開動力。從財務(wù)角度來看,RISC/Unix供應(yīng)商的衰落以及AMD在服務(wù)器市場的缺席使英特爾大為受益,它在數(shù)據(jù)中心的霸權(quán)也從未如此強大,收入和利潤不斷突破記錄。
這也來源于超大規(guī)模運營商和云構(gòu)建商的崛起所帶來的機遇,同時也帶給英特爾一些競爭壓力,這些壓力在之前往往來自于直接競爭對手、OEM和ODM。雖然英特爾在數(shù)據(jù)中心計算服務(wù)器方面仍幸運地保持增長且接近壟斷,并擴展到網(wǎng)絡(luò)和存儲設(shè)備且都取得了一些成績,但缺乏競爭確實損害了英特爾的工程優(yōu)勢。
對于英特爾來說輕松賺錢是好事。服務(wù)器市場的增長速度比弱小競爭對手吞食市場份額的速度要快得多,AMD Epyc和Marvell ThunderX2的攻擊以及IBM Power9的一系列動作并沒有真正打擊到英特爾的核心服務(wù)器業(yè)務(wù)。延遲了兩年的10納米工藝雖然擾亂了英特爾的路線圖,但也沒造成什么確切影響。然而在2019年,隨著AMD和Marvell使用臺積電的先進工藝推出下一代產(chǎn)品,戰(zhàn)火將會蔓延,并很可能會波及英特爾。
挫敗這些攻擊,是英特爾公司處理器核心和視覺計算高級副總裁、英特爾邊緣計算解決方案總經(jīng)理兼首席架構(gòu)師Raja Koduri,以及高級副總裁兼硅工程事業(yè)部總經(jīng)理Jim Keller的工作。Koduri和Keller是分別負責讓AMD Radeon GPU和Epyc CPU產(chǎn)品線重生的人物。這兩位和其他英特爾高管在最近舉行的架構(gòu)日活動中,在英特爾聯(lián)合創(chuàng)始人Robert Noyce舊居發(fā)布了攻防計劃。在這里,英特爾從高處俯瞰硅谷,試圖在數(shù)據(jù)中心拿下更大一塊地盤。
羅馬不是一天建成的,也不是一天毀滅的
大家都熟悉英特爾十多年來采用的Tick-Tock模式。英特爾將芯片改進的過程分為兩個部分以降低風險,其中Tick階段是晶體管制造工藝的縮小,Tock階段是基于前階段工藝的架構(gòu)改進。使用Tick-Tock模式,英特爾可以維持穩(wěn)定的性能提升,該模式也運作得非常好,直到Tick階段需要花費更長的時間且Tock階段變得越來越難。
英特爾從14納米開始打破Tick-Tock模式,延長為Tick-Tick-Tick-Tick模式,試圖從一個芯片工藝節(jié)點獲得更高的性能。這種改變很有必要,10納米工藝的推遲導(dǎo)致了14納米Tick階段的拉伸以及10納米Tick階段的延期,接著影響到依賴于10納米工藝的一大堆Tock階段。
從中得到的經(jīng)驗可能就是Tock階段不能過分依賴于前面的Tick階段,需要學(xué)習(xí)混搭不同工藝的芯片將它們?nèi)M一個2D封裝,或者堆疊成3D封裝。實際上只需要在最有用的芯片上使用最先進的Tick工藝,而把其它的小芯片組件放在封裝上,比如把消耗大量電能的內(nèi)存控制器和I/O控制器放在芯片之外,這樣成熟的晶體管蝕刻工藝尺寸會更大,但制造成本也更低。
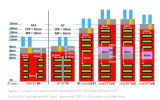
關(guān)于制程,有一點非常重要。面臨壓力,英特爾能從現(xiàn)有工藝中釋放出超乎想象的更高性能。當前14納米FinFET工藝蝕刻的酷睿臺式機處理器就是一個很好的例子,并且這也適用于凌動或服務(wù)器的至強芯片。下表顯示了過去幾年酷睿芯片最高時鐘速率隨工藝優(yōu)化的演變:
制程更新本質(zhì)上是更平滑的優(yōu)化,即使新的工藝已經(jīng)推出,每個制程節(jié)點仍會持續(xù)更長的時間。這種更平滑的方式可以幫助緩解一些競爭壓力,但隨著英特爾增加10納米設(shè)備而減少14納米設(shè)備,導(dǎo)致了2018年P(guān)C芯片和一些服務(wù)器芯片的短缺,迫使英特爾集中精力在最佳良率上,并把最好的14納米工藝應(yīng)用于最暢銷的PC和服務(wù)器芯片。
英特爾需要讓客戶習(xí)慣這種Tick-Tick-Tick-Tick-Tick模式,它將改變工廠增減設(shè)施來滿足需求的方式。
Koduri希望大家了解的是,英特爾現(xiàn)在已經(jīng)掌控10納米工藝,而且正在前瞻7納米甚至更先進的5納米。這是當前路徑的樣子:
如圖,英特爾每個制程節(jié)點有兩個不同版本,一個針對計算優(yōu)化,一個針對I/O優(yōu)化,因為二者需要不同的晶體管屬性。以偶數(shù)結(jié)尾的制程變數(shù)用于計算,以奇數(shù)結(jié)尾的用于I/O。在最初的10納米制程后面,有兩個優(yōu)化的計算節(jié)點,英特爾可能會對外稱之為10納米+和10納米++。與此同時,后續(xù)的7納米工藝,目前正在開發(fā)中。英特爾也正在對5納米制程進行“尋路”研究。
制程工藝過剩
然而還有一個更大的問題需要解決,那就是數(shù)據(jù)中心的計算類型如同寒武紀大爆發(fā)一樣增長。英特爾一直在構(gòu)建不同計算類型的產(chǎn)品組合,除了至強和凌動服務(wù)器CPU、Arria和Stratix(來自收購的Altera)FPGA,及其Crest神經(jīng)網(wǎng)絡(luò)處理器(來自收購的Nervana)之外,英特爾非常清楚它還需要加入可用作加速器的獨立GPU。英特爾需要可與Nvidia Tesla和AMD Radeon Instinct GPU加速器直接競爭的產(chǎn)品,這也是其首先雇用Koduri的原因之一。
目前尚不清楚英特爾將如何幫助客戶選擇用于任意特定工作負載的計算產(chǎn)品,因為在許多情況下會出現(xiàn)大量的重疊。
但是在我們深入了解這些讓人眼花繚亂的芯片組合之前,且先退一步看看。英特爾一再表示,它追求的不再是價值僅450億美元的客戶端和服務(wù)器處理器市場,再加上一些閃存和部分超微互連,而是追求更廣闊的3000億美元的計算市場,將其產(chǎn)品嵌入數(shù)據(jù)中心、園區(qū)和邊緣各式各樣的裝置中。要負擔所有這些芯片的研究和工廠建設(shè)費用,英特爾將必須大規(guī)模生產(chǎn)。
Koduri提醒大家的第一件事是,并非所有的晶體管都適用于不同的場景,而且在這個摩爾定律放緩的世界,作為一個多元電子器件供應(yīng)商,需要為不同類型的電路使用不同的制程工藝。即使可以使用單個制程技術(shù)大費周章地在芯片上建立單片系統(tǒng),那也許并不算明智的做法。
“我們期望建立一個3000億美元的潛在市場規(guī)模,并進入不同的市場領(lǐng)域,我們注意到需要建造的晶體管設(shè)計十分多樣,”Koduri解釋道。“例如,臺式機CPU就對于性能和功率都有廣泛的需求,新晶體管在這些場景中并不總是更適用。事實上,沒有晶體管可以覆蓋所有這些需求。另外,我們需要集成的晶體管越來越多樣——我們有通信晶體管,I/O晶體管,FPGA晶體管,以及傳統(tǒng)的CPU邏輯晶體管。“
因此,出于經(jīng)濟和技術(shù)因素,以及不同市場需要根據(jù)功率限制、性能特征、特性和成本集成不同原件,單個大芯片需要被拆分成多個小芯片(chiplet)。正如我們已經(jīng)指出,不僅僅是英特爾,業(yè)界的一切都將向插槽內(nèi)多芯片封裝發(fā)展。
所以,這就是英特爾將要做的事情。尚不清楚具體什么時候、使用什么電路,但顯然未來英特爾可編程解決方案事業(yè)部的“Falcon Mesa” FPGA將采用模塊化插槽設(shè)計,并使用10納米工藝至少來實現(xiàn)其核心邏輯。小芯片的模式不僅是將應(yīng)用不同制程的組件部分組合,而是還能制造出比單個大芯片能適應(yīng)更廣泛的性能和功率范圍的一系列部件。
另一個采用10納米工藝的組件是英特爾112 Gb/s SerDes電路,它的制程可能在未來相當長一段時間內(nèi)不會縮小。它支持脈幅調(diào)制,可在一個信號中承載更多比特。英特爾擁有112 Gb/s SerDes,意味著英特爾可以提供能與業(yè)界相媲美的Omni-Path 200及以太網(wǎng)連接,這對于英特爾和眾多網(wǎng)絡(luò)廠商競爭是很有必要的,其中一些對手同樣銷售英特爾處理器的競品。
所有這些因素最終帶來了Foveros 3D芯片封裝技術(shù),它將在不久的將來為英特爾計算引擎的構(gòu)建奠定基礎(chǔ)。Foveros是一種系統(tǒng)級封裝集成,為嵌入式多芯片互連橋接(EMIB)多芯片封裝技術(shù)增加了第二個維度,EMIB是英特爾一項研究多年的工作,并最終在連接小芯片的Stratix 10 FPGA、以及在單獨封裝的配置AMD GPU和高帶寬內(nèi)存(HBM)的Kaby Lake-G 酷睿芯片上得到應(yīng)用。
使用Foveros系統(tǒng)級封裝多芯片模塊,為計算復(fù)合體(可以包括內(nèi)存及其它組件)提供服務(wù)的I/O電路、SRAM緩存和電源電路可以在基層芯片上構(gòu)建,基層芯片覆蓋于封裝襯底上,襯底可以放置針腳與插槽配合,抑或直接焊接到主板上。有源中介層被放置在該封裝襯底上,其上方的各種小芯片通過硅穿孔(TSV)可以互相連接。小芯片上的微凸塊可以通過TSV向下深入中介層,從而連接到堆疊芯片的最底層,然后在中介層內(nèi)可以到達鄰近,或到達堆疊其上的其它芯片。除了一層底層芯片和另一層頂層芯片,可以有很多分層:
看看這些焊點凸起多么閃亮;當圖形專家做演示時就會發(fā)生這種情況。
使用Foveros工藝的第一個產(chǎn)品在架構(gòu)日上進行了演示,如下圖:
這個設(shè)備定位是超便攜應(yīng)用,封裝尺寸為12毫米×12毫米,遠小于一枚美元硬幣。具有I/O和其它片上系統(tǒng)組件的基層芯片使用1222工藝,該工藝是基礎(chǔ)22納米工藝的代號,非常久遠,在完善后被應(yīng)用于“Ivy Bridge”和“Haswell” 至強上。更大晶體管更適合電源和I/O電路。在其上方是使用10納米工藝實現(xiàn)的計算復(fù)合體(1274,前綴P表示使用Foveros堆疊),在這個例子中,它包含了來自“Sunny Cove” 酷睿的一個核心和來自“Tremont” 凌動的四個核心,以一種ARM已經(jīng)應(yīng)用多年的方式混搭。最頂層是一大塊疊層封裝內(nèi)存。英特爾沒有說明這種芯片復(fù)合體在負載條件下功耗多少,但確實表示它在待機狀態(tài)消耗為2毫瓦,大約是能取得的最低值。
英特爾并未明確表示在未來的酷睿和至強處理器中使用Foveros技術(shù),但顯然未來的“Falcon Mesa” FPGA,和2020年的Xe獨立GPU中將用到它。我們認為未來的至強和凌動,以及各種CPU與GPU、FPGA、及Nervana神經(jīng)網(wǎng)絡(luò)處理器等混搭芯片上都會用到Foveros技術(shù)。
英特爾不再僅靠制程和架構(gòu)來推動其計算業(yè)務(wù),還將充分利用內(nèi)存和互連芯片,將安全性嵌入到所有元素中,并與一個涵蓋這些計算元素的更簡單的集成軟件集合在一起,也就是oneAPI。之后,我們還將深入探討oneAPI以及各種計算引擎的路線圖,以及它們對回歸摩爾定律軌道的預(yù)期影響。








































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論