 電子發燒友App
電子發燒友App


(文章來源:EEworld)
隨著人工智能、機器學習等應用場景快速發展演進,對芯片的算力、安全性等性能也提出了更高的訴求。據市場調研公司Semico?Research數據顯示,2018年FPGA市值約為10億美元,在未來4年內,人工智能應用中FPGA的市場規模將增長3倍,達到52億美元。要知道,這個增長是非常驚人的,畢竟過去多年,FPGA市場的年均增長率也才8%-9%。目前人工智能、機器學習等應用場景的FPGA市場約為25%,預計兩年后將達到72%。如此龐大的市場空間,則需要性能更高、更加靈活的AI 算法解決方案。
關于塊浮點數(BFP)已經出現一段時間了,但是現在才開始被看作是執行機器學習操作的一種非常有用的技術。值得指出的是,這與bfloat不是一回事。BFP結合了定點運算的效率,并提供了全浮點運算的動態范圍。在研究BFP中使用的方法時,我想起了幾個用于簡化數學問題的“技巧”。首先想到的是所謂的日本乘法,它使用簡單的圖形方法來確定產品。另一個,當然,是曾經流行但現在幾乎被遺忘的計算尺。
在即將到來的網絡研討會上,Achronix的戰略和規劃高級總監Mike Fitton解釋了關于在人工智能/ML工作負載的FPGA中使用BFP的相關問題,BFP依賴于標準化的不動點隨機數,因此計算中使用的“塊”數字都具有相同的指數值。在乘法的情況下,只需要對尾數進行定點乘法,對指數進行簡單的加法。令人驚訝的是,與傳統的浮點運算相比,BFP提供了更快的速度和更低的功耗。當然,整數運算更精確,使用的功耗也更低,但是它們缺乏BFP的動態范圍。根據Mike BFP的說法,他為人工智能/ML工作負載提供了一個最佳位置,而網絡研討會將為他的結論提供支持數據。
AI/ML訓練和推理的需求與dsp中信號處理通常需要的需求大不相同。它適用于內存訪問,也適用于數學單元實現。Mike詳細討論了這一點,并展示他們構建到Speedster7t中的新機器學習處理器(MLP)單元如何對BFP提供本機支持,還支持廣泛的完全可配置的整數和浮點精度。實際上,它們的MLP非常適合傳統的工作負載,并且在AI/ML方面也很出色,沒有任何區域損失。每個MAC塊最多有32個倍增器。
Achronix MLP具有緊密耦合的內存,方便了AI/ML工作負載。每個MLP有一個本地72K位塊RAM和一個2K位寄存器文件。MLP的數學塊可以配置為級聯內存和操作數,而無需使用FPGA路由資源。
Achronix公司推出了創新性的、全新的FPGA系列產品——Speedster 7t系列。Achronix稱,Speedster 7t系列是基于一種高度優化的全新架構,以其所具有的如同ASIC一樣的性能、可簡化設計的FPGA靈活性和增強功能,從而遠遠超越傳統的FPGA解決方案。
Speedster7t也非常有趣,因為芯片上的高數據速率網絡(NoC)可以用來移動數據之間的MLP和/或其他塊或芯片上的數據接口。NoC可以在不消耗寶貴的FPGA資源的情況下移動數據,并且避免了FPGA結構內部的瓶頸。NoC有多個管道,256位寬,2GHz運行,數據速率為512G。它們可以直接將數據從外圍設備(如400G以太網)移動到GDDR6內存中,而不需要使用任何FPGA資源。
Achronix將提出一個令人信服的理由,說明為什么在他們的架構中本地實現BFP(包括許多開創性的特性)對于AI/ML和其他更傳統的FPGA應用程序(如數據聚合、IO橋接、壓縮、加密、網絡加速等)來說是非常有吸引力的選擇。
對于AI加速來說,相較于我們常見的CPU、GPU等通用型芯片以及可編程的FPGA來說,ASIC芯片的計算能力和計算效率都直接根據特定的算法的需要進行定制的,它可以實現體積小、功耗低、高可靠性、保密性強、計算性能高、計算效率高等優勢。所以,在其所針對的特定的應用領域,ASIC芯片的能效表現要遠超CPU、GPU等通用型芯片以及可編程的FPGA。
但是,目前AI算法仍然處在一個不斷的快速更新迭代的階段,數值精度的可選擇性也越來越多。同時隨著AI的應用場景快速發展演進,新的解決方案都要去應對在高性能、靈活和上市時間等方面的不同需求。而AISC是針對特定的算法加速所設計的,這也使得其在靈活性上遠不如可通過編程快速適應新的軟件算法的FPGA。但是,FPGA在體積、能效、成本上卻又不如AISC。那么是否能夠有這樣一款產品,能夠很好的將FPGA和ASIC的優點結合在一起呢?Achronix的Speedster 7t系列或許就是這樣一款產品。
Speedster7t FPGA系列產品是專為高帶寬應用進行設計,具有一個革命性的全新二維片上網絡(2D NoC),以及一個高密度全新機器學習處理器(MLP)模塊陣列。Achronix CEO Robert Blake認為Speedster7t是Achronix歷史上最令人激動的發布,代表了建立在四個架構代系的硬件和軟件開發基礎上的創新和積淀,以及與我們領先客戶之間的密切合作。
Speedster7t是靈活的FPGA技術與ASIC核心效率的融合,從而提供了一個全新的‘FPGA+’芯片品類,它們可以將高性能技術的極限大大提升。
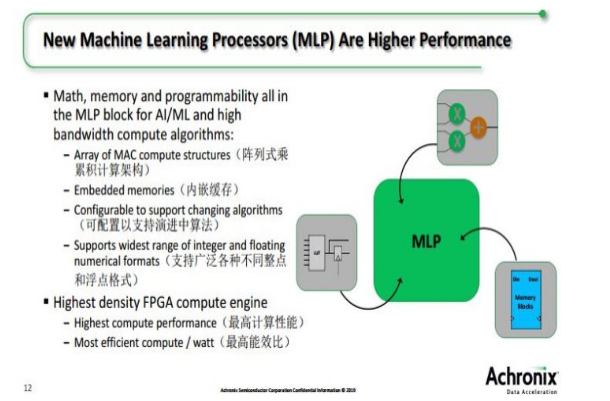
AI、ML需要矢量矩陣乘法,而傳統的帶DSP模塊的FPGA性能有限,需要消耗額外邏輯和Memory資源,而新的MLP是高度可配置的、計算密集型的單元模塊,可支持4到24位的整點格式和高效的浮點模式,包括對TensorFlow的16位格式的支持,以及可使每個MLP的計算引擎加倍的增壓塊浮點格式的直接支持。它可提供業界最高的、基于FPGA的計算密度。
值得一提的是,Speedster7t器件是唯一支持GDDR6存儲器的FPGA,該類存儲器是具有最高帶寬的外部存儲器件。每個GDDR6存儲控制器都能夠支持512 Gbps的帶寬,Speedster7t器件中有多達8個GDDR6控制器,可以支持4 Tbps的GDDR6累加帶寬,并且以很小的成本就可提供與基于HBM的FPGA等效存儲帶寬。

除了這種超高的存儲帶寬,Speedster7t器件還包括業界最高性能的接口端口,以支持極高帶寬的數據流。Speedster7t器件擁有多達72個業界最高性能的SerDes,可以達到1到112 Gbps的速度。還有帶有前向糾錯(FEC)的硬件400G以太網MAC,支持4x 100G和8x 50G的配置,以及每個控制器有8個或16個通道的硬件PCI Express Gen5控制器。
Speedster7t高速I/O和存儲器端口的產生的數萬兆比特數據很容易淹沒傳統FPGA面向比特位的可編程互連邏輯陣列的路由容量,而Speedster7t架構包含一個可橫跨和垂直跨越FPGA邏輯陣列的創新性的、高帶寬的二維片上網絡(NOC),它們連接到所有FPGA的高速數據和存儲器接口。
它們就像疊加在FPGA互連這個城市街道系統上的空中高速公路網絡一樣,Speedster7t的NoC支持片上處理引擎之間所需的高帶寬通信。NoC中的每一行或每一列都可作為兩個256位實現,單向的、行業標準的AXI通道,工作頻率為2Ghz,同時可為每個方向提供512 Gbps的數據流量。

通過在Speedster中實現專用二維NoC,極大地簡化了高速數據移動,并確保數據流可以輕松地定向到整個FPGA結構中的任何自定義處理引擎。最重要的是,NOC消除了傳統FPGA使用可編程路由和邏輯查找表資源在整個FPGA中移動數據流中出現的擁塞和性能瓶頸。這種高性能網絡不僅可以提高Speedster7t FPGA的總帶寬容量,還可以在降低功耗的同時提高有效LUT容量。
Speedster7t FPGA系列產品在面臨第三方攻擊的威脅時,可用最先進的比特流安全保護功能應對,它們具有的多層防御能力可保護比特流的保密性和完整性。密鑰是基于防篡改物理不可克隆技術(PUF)進行加密,比特流由256位的AES-GCM加密算法進行加密和驗證。為了防止來自旁側信道的攻擊,比特流被分段,每個數據段使用單獨導出的密鑰,且解密硬件采用差分功率分析(DPA)計數器措施。
此外,2048位RSA公鑰認證協議被用來激活解密和認證硬件。用戶可以確信的是當他們加載其安全比特流時,它是預期的配置,這是因為它已通過RSA公鑰、AES-GCM私鑰和CRC校驗進行了身份驗證。
據悉,Achronix是目前唯一一家既提供獨立FPGA芯片又提供Speedcore嵌入式FPGA(eFPGA)半導體知識產權( IP)的公司。也就是說,芯片設計廠商可以通過購買授權的形式,將Achronix的Speedcore嵌入式FPGA(eFPGA)的IP整合到自己的芯片設計當中,設計出符合自身需求的芯片。
而Achronix在Speedcore eFPGA IP中采用了與Speedster7t FPGA中使用的同一種技術,可支持從Speedster7t FPGA到ASIC的無縫轉換。這也意味著芯片設計廠商通過與Achronix合作,也可以獲得最新的Speedster7t FPGA系列的技術,并可將其轉換為ASIC。Achronix CEORobert Blake表示,該技術有望幫助客戶節省高達50%的功耗并降低90%的成本。
? ? ? (責任編輯:fqj)








 工商網監
工商網監
評論