 電子發燒友App
電子發燒友App


引言
課題研究背景
智能交通系統是將先進的信息技術、移動通信技術和計算機技術應用在交通網絡,建設一種全方位的、實時準確的綜合運輸和管理系統,實現道路交通和機動車輛的自動化管理。自動化的發展在交通管理領域產生了一系列的應用,比如道路收費、車載導航系統和車聯網等。這些應用對于車輛的識別檢測、安全管理也提出了越來越高的要求。
車牌識別系統研究現狀及難點
車牌識別系統,采用的主要方法是通過圖像處理技術,對采集的包含車牌的圖像進行分析,提取車牌的位置,完成字符分割和識別的功能。隨著計算機技術的發展,對于單個字符的識別已經有非常完善的解決方法,車牌識別系統準確性主要受限于圖像信息的獲取,識別失敗也大多數是由獲取圖像不理想導致。存在的問題包括車牌圖像的傾斜、車牌自身的磨損、光線的干擾都會影響到定位的精度。對于車牌識別系統來說,識別車牌的準確性和快速性往往是互相矛盾的存在,快速實時的捕捉和處理圖像往往會使用來識別的字符產生較大的失真,而不能滿足識別算法的要求,同時為了保證車牌識別的準確性經常會犧牲識別的速度,比如需要車牌在攝像頭前保持更長的一段時間才能完成識別。
1、設計和系統模塊概述
1.1 作品介紹
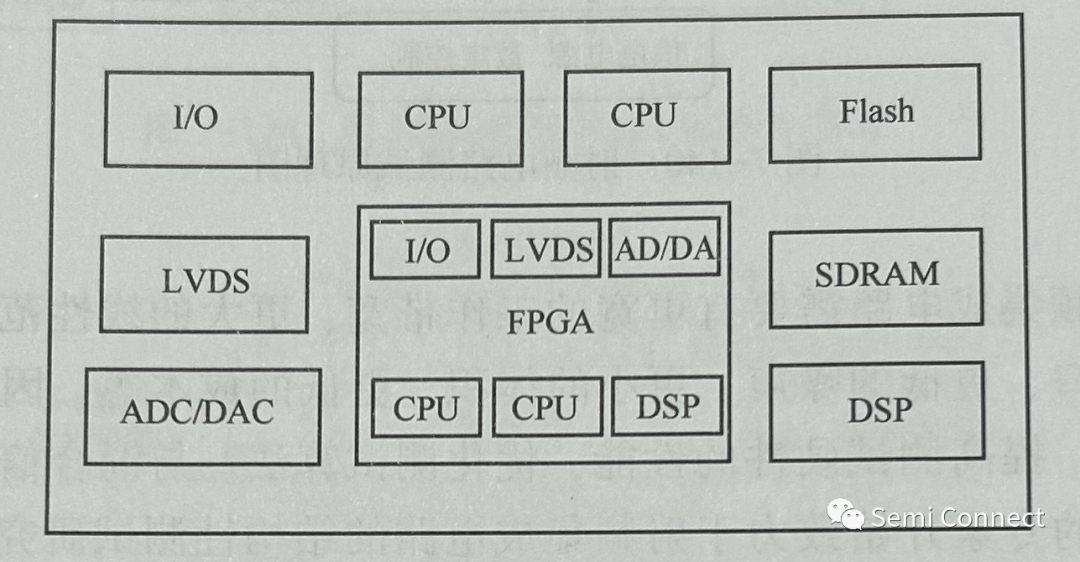
本作品是基于紫光PGT180H的車牌識別系統,包括了紫光開發板、帶FIFO的OV7725攝像頭、像素為320x240的LCD顯示屏以及搭載了攝像頭和LCD的PCB板。
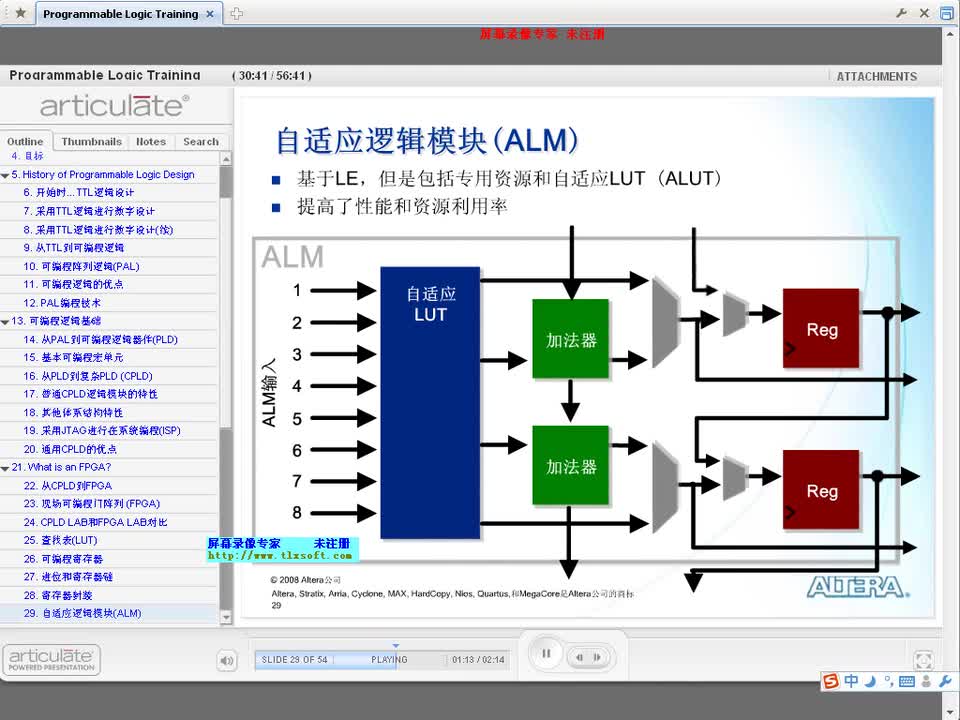
系統采用OV7725攝像頭采集圖片,通過RGB轉HSV的模塊并根據HSV值提取出藍色部分,經過detect模塊檢測有無車牌,然后對圖像進行處理得到車牌的四個頂點,利用線性內插的方法獲得固定大小的圖像,提取出車牌中的7個包含字符的圖像矩陣,然后使用訓練好的神經網絡分別對其進行運算分析,最后識別出結果并顯示到LCD上。
本項目的具體工作如下。
⑴車牌定位檢測。針對攝像頭獲取的圖像受到車牌模糊、光照強度的影響,采用HSV格式的圖像二值化方法,提出了一種通過掃描二值化圖像檢測車牌四個頂點的方法,得到了車牌的位置區域,根據設定判斷依據檢測車牌是否存在于攝像頭前,檢測成功后自動完成識別功能。
⑵字符分割。根據已經提取的圖像定點,采用一種線性內插的方法將原始圖像轉換為固定大小圖像,這一方法也可以適應發生旋轉后的車牌,再將固定大小的圖像順序分割成單個字符用來識別。
⑶字符識別。采用神經網絡算法完成字符識別功能,將已經訓練好的神經網絡矩陣存在存儲器中,在FPGA上建立相應并行與流水線結構的乘累加模塊設計,利用查找表以及線性內插的方法對激活函數sigmoid進行逼近,提高計算精度和算法效率。
1.2 系統工作流程
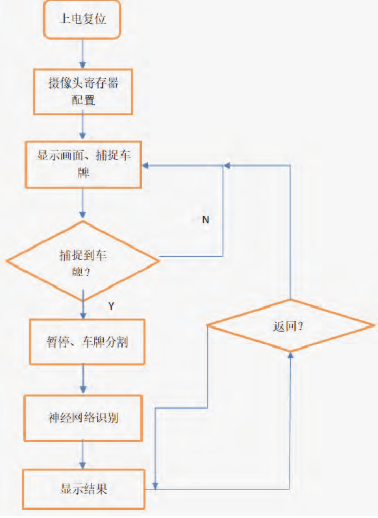
上電后,先進行攝像頭寄存器配置,然后將攝像頭捕捉到的畫面顯示到LCD顯示屏上,同時RGB轉HSV和detect模塊運行;一旦detect模塊提取到車牌,LCD畫面將轉化為暫停的黑白畫面,緊接著運行車牌分割和顯示的模塊image_pro和segment,然后是神經網絡識別車牌,最后將結果顯示至LCD左側并且暫停。若想進行第二次識別,則按下按鍵將會回到攝像頭捕捉畫面的狀態。
2、車牌檢測和圖像處理
2.1 HSV格式
從攝像頭獲得RGB565值的大小會隨著環境光線的變化而變化,直接利用RGB三個值進行二值化是很困難的,我們采取將RGB格式轉換成HSV格式,再設置二值化相應的閾值。HSV分別表示色相、飽和度和亮度。其中主要的二值化指標是色度和飽和度,表示偏向某個顏色和偏向的尺度,通過判斷色相和飽和度,我們將車牌中藍色的部分提取出來供后面使用。
我們使用的閾值如下:飽和度大于30,色相大于200 且小于280,亮度大于30。
2.2 圖像檢測
提取出藍色部分后,利用算法找到車牌的四個頂點,通過四個頂點的相對位置,所表示的矩形的長寬比來檢測車牌是否被放在攝像頭正前方。
為了提取出車牌,我們需要分析車牌的特征。在畫面中,車牌占了一大部分,意味著連續的行和列都會呈現藍色,車牌的四個頂點分別位于左上、左下、右上、右下,所計算出的長寬比在1:3到1:4內。檢測算法如下。
⑴一行一行地遍歷整幅圖。
⑵當一行中檢測到連續的10個藍色點時,flag10賦值為1,視為檢測到車牌的初步狀態,當連續的10個藍色點消失時,flag10賦值為0。
⑶當flag10為1時,記錄連續點中的左頂點和右頂點。
⑷記錄車牌的左上、左下、右上、右下的坐標,即每次的左右頂點分別計算x+y和x-y的最大最小值與所記錄的坐標進行比較。
⑸若存在連續的10行,flag10都被賦值為1,視為找到了一大塊藍色區域。
⑹當遍歷完整幅圖并且找到了藍色區域之后,計算長寬比,達到要求后視為找到了車牌。
⑺MATLAB進行的算法驗證,如圖2所示。
2.3 圖像分割
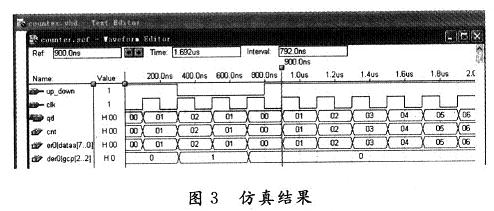
在車牌檢測模塊是我們已經提取出來了4個頂點的坐標,通過其中的3個頂點,可以將車牌部分映射到大小為1687的圖片中,設新圖片中的點坐標為,根據以下公式完成圖片映射。
圖形分割方法如下:按行和列將上圖分割成7個字符,每個字符出去最邊緣一行,再將上圖中紅色框內的點出去,最終得到71410的字符存進RAM中。
映射與圖形分割的效果如圖3。
3、神經網絡與字符識別
3.1 神經網絡算法
3.1.1 神經網絡的設計
前文中,我們已經將車牌上的字符提取了出來,每個字符都是一個1410的由0、1構成的矩陣。已經完成了卷積神經網絡中類似池化的操作,我們不太需要更加復雜的CNN網絡,而可以使用最簡單的神經網絡結構。
于是我們設計了如下的神經網絡。
⑴整個神經網絡由3層感知機組成,輸入層、隱含層和輸出層。
⑵輸入層140個神經元,對應1410中的每個像素點;隱含層80個神經元;輸出層34個神經元,可分別對應10個數字和24個除去I、O的字母(車牌中這兩個字母由于和1、0比較像,故不存在),或34個省級行政區域。
⑶輸入層無激活函數,僅隱含層和輸出層含有激活函數sigmoid。
3.1.2 神經網絡的訓練
神經網絡的訓練采用了梯度下降法,通過誤差反饋調整權值矩陣以減少誤差,使得神經網絡的輸出逐漸收斂至我們想要的輸出。
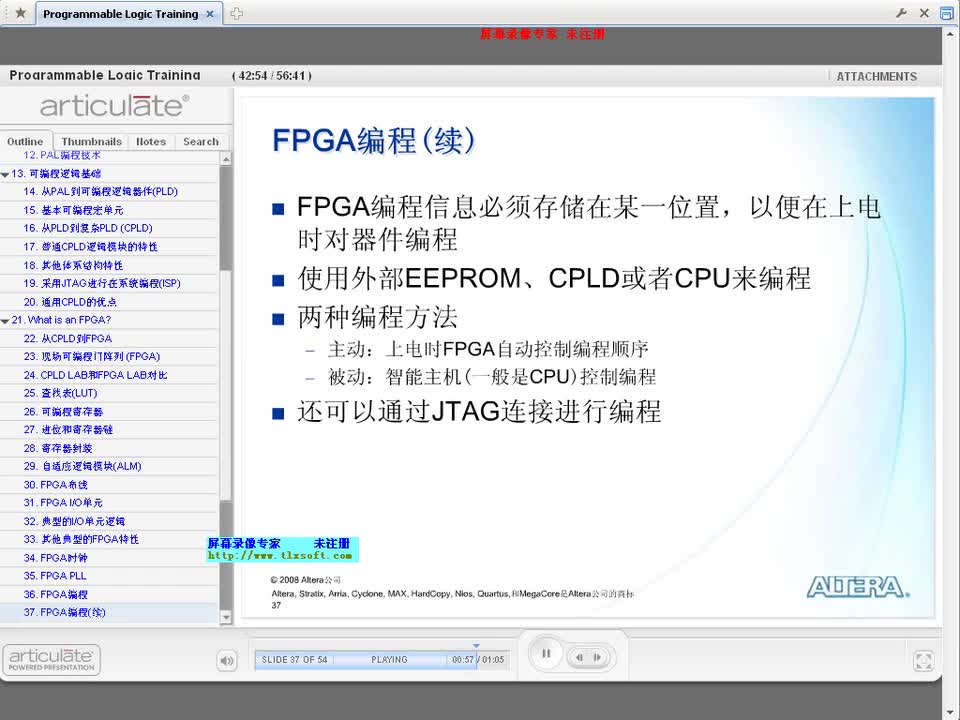
3.2 FPGA實現模塊
神經網絡中包含兩種運算,分別是矩陣乘法和sigmoid函數映射的運算,主要通過以下的模塊實現。
3.2.1 選擇累加模塊
本模塊神經網絡的第一層計算,將輸入的1410的二值化像素點的向量和訓練完成的神經網絡權值矩陣W1相乘,得出結果,結果輸出至sigmoid模塊。因為圖像點陣數據格式已二值化,僅含有數字0、1,所以做乘法時相當于在做選擇,故采用選擇累加的方法計算向量與矩陣的乘積。
3.2.2 sigmoid模塊
Sigmoid函數是一個連續的函數,但是FPGA難以直接地計算該函數,于是我們通過通信中PCM編碼得到的靈感,找到斜率為2的冪次方的折線段的端點坐標存入查找表,對輸入的x即可找到對應區間,然后通過移位即可進行對sigmoid曲線的線性逼近。
3.2.3 乘累加模塊
本模塊中,神經網絡中第一層算出的80個結點為輸入,與訓練完成的神經網絡權值矩陣W2進行矩陣運算。模塊調用乘累加IP核,在模塊內調用神經網絡的權值矩陣rom2,與頂層的ram2讀取的80個結點數據進行乘累加運算,每次運算完成后進行數據的流水輸出至Sigmoid模塊,同時給出相應ram寫入使能的控制。當接收到開始信號有效,模塊開始工作,結束后輸出完成信號。
3.3 神經網絡訓練
神經網絡的訓練應采用準確的數據進行訓練,才可以達到完美的訓練效果。于是我們在FPGA上實現了車牌的字符提取之后,編寫了一個串口通信模塊,將采集好的字符矩陣傳輸至電腦端,并以此作為訓練數據。在MATLAB上將權值矩陣訓練好以后,存儲進FPGA的矩陣。
4、硬件實現結果
4.1 硬件實現
我們使用OV7725攝像頭和LCD作為外設,負責圖像的采集和輸出顯示,自行設計了PCB板,該外設可以通過插拔的簡單方式連接起來,上電后可以直接使用。
4.2 結果驗證
圖4是系統實現的最終效果圖,我們的車牌對經過輕度旋轉的圖像也有很好的處理效果,在做板級驗證的時候,我們也測試了輕度旋轉的圖片識別,可以看出,該系統成功地識別出了車牌。
5 、創新點
本作品利用FPGA可編程邏輯器件和簡單的系統設計,實現了準確性較高的車牌識別系統,創新的采用HSV格式用作圖片二值化方法,獲得了很好的區分效果,能夠適應光線變化的不同場景,圖像的提取和字符分割也取得了理想的效果,保證了車牌識別的正確率,實現了以神經網絡為核心的專用FPGA圖像識別處理器及結構,將神經網絡和圖像處理模塊在FPGA芯片上實現。
責任編輯:gt












 工商網監
工商網監
評論