本文采用的是ALTERA公司的EP1C6Q240C8型號的FPGA,整個體統采用模塊化設計的思想,將各個模塊用VHDL語言描述出來再進行連接。
2020-08-04 09:39:44 1670
1670 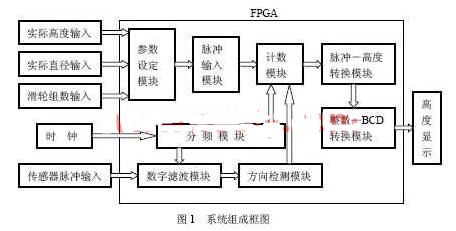
該系統采用C8051系列單片機中的 C8051F121作為控制器,CvcloneⅢ系列EP3C40F484C8型FPGA為數字信號算法處理單元。
2015-02-03 15:58:265087 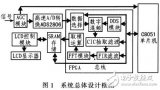
EP2S60F484I4N特價 EP2S60F484I4N貨期EP2S60F484I4N 價格EP2S60F484I4N國宇航芯特價訂貨EP2S60F484C4N國宇航芯特價訂貨
2020-01-06 09:07:44
采集數據中的量化噪聲,在進行數據壓縮前采用濾波的預處理技術。介紹LZW算法和滑動濾波算法的基本理論,詳細闡述用單片FPGA實現兩種算法的方法。最終測試結果表明,該設計方案能夠有效濾除數據中的高頻噪聲
2010-04-24 09:05:21
的數目之外,就是采用可編程邏輯器件,主要是FPGA芯片來實現。本課程以DSP設計在FPGA芯片上的開發為主線,遵照由淺入深的基本步驟和思路進行詳細講解,每一個知識點都給出了基于ISE(HDL語言
2009-07-21 09:22:42
H.264。采用TI公司1GHz主頻的DSP芯片需要4顆芯片,而采用Altera的StraTIxII EP2S130芯片只需要一顆就可以完成相同的任務。FPGA的實現流程和ASIC芯片的前端設計相似
2020-10-26 14:35:32
最近,需要使用fpga實現iec-61850-9-2報文編碼,設計中涉及到的 字段非常多,以至于邏輯特別復雜,占用資源太多,設計的頻率上不去。有沒有哪位同道做過fpga報文編碼類的設計,請不吝賜教。
2013-11-12 23:20:19
fpga實現濾波器fpga實現濾波器在利用FPGA實現數字信號處理方面,分布式算法發揮著關鍵作用,與傳統的乘加結構相比,具有并行處理的高效性特點。本文研究了一種16階FIR濾波器的FPGA設計方法
2012-08-12 11:50:16
。本文研究了一種16階FIR濾波器的FPGA設計方法,采用Verilog HDI語言描述設計文件,在Xilinx ISE 7.1i及ModelSim SE 6.1b平臺上進行了實驗仿真及時序分析,并探討了實際工程中硬件資源利用率及運算速度等問題。
2012-08-11 18:27:41
,采用核心板和底層板結合的硬件結構。系統原理框圖如圖1所示,FPGA 芯片采用Atera 公司的Cyclone Ⅱ 系列EP2C5Q208C8N,它采用90 nm 工藝,具有4 608個邏輯單元。此外
2019-06-24 07:16:30
在單片上集成實現。由于現代電子技術的飛速發展,可編程邏輯芯片FPGA的集成度越來越高,受到很多廠家和研究機構的關注,利用它的可編程性和可擴展,可將絕大部分的功能集成到FPGA芯片中。如文獻采用FPGA
2019-05-16 07:00:09
就已經出現,隨著FPGA芯片價格的不斷降低,其在工業領域的應用正在飛速發展,采用FPGA來實現SVPWM調制算法也將層出不窮2. 系統任務分析及實現SVPWM調制算法相對比較復雜,在完成系統控制任務
2022-01-20 09:34:26
CAS。我們的設計(圖1)采用Altera公司Cyclone III系列型號為EP3C16F484C6N的FPGA作為控制器,以Micron公司生產的型號為MT47H16M16BG-5E(16M
2019-05-31 05:00:05
CAN過濾器的配置(f103 hal1.8 系列)can的過濾器的配置是對can接收到的報文進行過濾的配置,在STM32芯片中,可以對can的報文進行過濾,從而省略cpu的處理過程。can的過濾模式
2021-08-19 06:11:28
我現在使用CC3200 transceiver mode,我想將報文過濾下,請問transceiver mode下支持sl_WlanRxFilterAdd 過濾條件添加嗎?如果能,我想要根據field:FRAME_SUBTYPE_FIELD來過濾,能給一個例子嗎
2016-04-27 10:12:25
FPGA實現的 FFT 處理器的硬件結構。接收單元采用乒乓RAM 結構, 擴大了數據吞吐量。中間數據緩存單元采用雙口RAM , 減少了訪問RAM 的時鐘消耗。計算單元采用基 2 算法, 流水線結構, 可在
2017-11-21 15:55:13
的要求和FPGA芯片設計的靈活性結合起來,采用Alter公司的CycloneⅡ系列FPGA芯片EP2C35F672C8,用VHDL語言編程,最后分別使用Quartus Ⅱ和Matlab軟件開發工具驗證實現
2010-05-28 13:38:38
求助!STC12C5A60S2無法實現開平方算法(sqrt函數),以及atan2和asin怎么辦?我已經包含了相關的頭文件了,但是編譯通不過。
2020-05-20 09:07:38
下面內容為轉載:一、在STM32互聯型產品中,CAN1和CAN2分享28個過濾器組,其它STM32F103xx系列產品中有14個過濾器組,用以對接收到的幀進行過濾。1、過濾器組 每組過濾器包括了2個
2021-08-23 07:29:40
TC39x的can報文過濾規則怎么設置
2024-02-19 06:12:48
處理器的數目之外,就是采用可編程邏輯器件,主要是FPGA芯片來實現。本課程以DSP設計在FPGA芯片上的開發為主線,遵照由淺入深的基本步驟和思路進行詳細講解,每一個知識點都給出了基于ISE(HDL語言
2009-07-21 09:20:11
處理器的數目之外,就是采用可編程邏輯器件,主要是FPGA芯片來實現。本課程以DSP設計在FPGA芯片上的開發為主線,遵照由淺入深的基本步驟和思路進行詳細講解,每一個知識點都給出了基于ISE(HDL語言
2009-07-24 13:07:08
的不足,同時也方便在現場可編程門陣列(FPGA)中增加一些其他相關的應用功能,因此在FPGA中實現CVSD語音編譯碼調制功能的前景將是非常廣闊的。這里將詳細介紹什么是CVSD?其算法分析如何在FPGA中實現?
2019-08-07 07:04:27
基于FPGA的FFT算法研究
2012-08-24 01:09:50
碼力分享基于FPGA的可變祖沖之(ZUC)算法的設計與實現1:概述基于FPGA的可變祖沖之(ZUC)算法的設計與實現軟件:ISE語言:Verilog HDL,C語言 2:功能通過加入可配置模塊(如S
2015-10-14 21:56:52
基于FPGA的模糊PID控制算法的研究及實現
2013-03-18 14:25:05
進行了校驗,通過了功能仿真。同時,借助于QuatusII綜合布線工具,使用Altera公司的StratixII EP2S60 FPGA芯片進行了綜合、布線,模塊的運行頻率達到107MHz,RLDRAM
2008-10-07 11:00:19
必須具備A/D轉換功能。采用專門的A/D轉換芯片,固然可實現輸出電壓的檢測,但電路變得復雜且成本偏高。經綜合考慮,本系統采用STC12C5A60S2單片機作為系統的主控制器。 STC12C5A60S2
2018-10-18 16:55:48
具備A/D轉換功能。采用專門的A/D轉換芯片,固然可實現輸出電壓的檢測,但電路變得復雜且成本偏高。經綜合考慮,本系統采用STC12C5A60S2單片機作為系統的主控制器。 STC12C5A60S2
2018-09-30 16:26:35
本設計方案采用了一種改進的快速中值濾波算法,成功地在Altera公司的高性能Stratix II EP2S60上實現整個數字紅外圖像濾波,在保證實時性的同時,使得硬件體積大為縮減,大大降低了成本
2021-04-23 06:00:55
使用TMS320C6455芯片,FPGA采用ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于獲取雙通道數據采集,實現1路的Base CameraLink
2012-07-06 16:17:50
ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于獲取雙通道數據采集,實現1路的Base CameraLink輸入,一路Base CameraLink
2012-06-13 11:39:49
ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于獲取雙通道數據采集,實現1路的Base CameraLink輸入,一路Base CameraLink
2012-06-13 12:01:23
本設計中采用了ALTERA公司的 EP1C3T144芯片進行設計,實際測試表明系統的各項設計要求均得到滿足并且系統工作良好,該設計采用了SOPC技術和FPGA,幾乎將整個系統下載于同一芯片中,實現了
2021-04-30 06:56:14
如何采用FPGA芯片完成基于LMS算法的自適應譜線增強系統的設計?
2021-04-29 06:55:16
請問如何采用Altera公司Cyclom系列FPGA來實現ATM層UTOPIA LEVEL2主接口,與物理層UTOPIA從接口連接?
2021-04-08 06:32:34
請問一下有沒有采用EEPROM對大容量FPGA芯片數據實現串行加載的實際方案?
2021-04-08 06:01:39
如何采用STC12C5A60S2實現無線多功能防火報警系統的設計?
2021-10-13 07:07:03
和模式識別的主要特征提取手段,在計算機視覺、圖像分析等應用中起著重要的作用,是圖像分析與處理中研究的熱點問題。數字信號和圖像處理算法的實現有多種途徑,傳統上多采用高級語言編程實現,便于使用的還有
2019-07-31 06:38:07
介紹了利用現場可編程邏輯門陣列FPGA實現直接數字頻率合成(DDS)的原理、電路結構和優化方法。重點介紹了DDS技術在FPGA中的實現方法,給出了采用ALTERA公司的ACEX系列FPGA芯片EP1K30TC進行直接數字頻率合成的VHDL源程序。
2021-04-30 06:29:00
如何去實現一種基于stc15f2k60s2芯片的流水燈編程呢?
2021-10-25 06:48:41
如何在ALTERA公司的Quartus II環境下用VHDL、Verilog HDL實現設計輸入,采用同步時鐘,成功編譯、綜合、適配和仿真,并下載到Stratix系列FPGA芯片EP1S25F780C5中。
2021-04-15 06:19:38
主要內容包括:1. 為什么很多人覺得學習FPGA很困難,以及HDL學習的一些誤區;2. 軟件和硬件在算法實現上的區別;3. 通過具體例子詳細講解了從算法的行為級建模向RTL級建模的轉換思想和底層電路
2015-09-18 15:44:39
,采用AGC算法,可提高音頻信號系統和音頻信號輸出的穩定性,解決了AGC調試后的信號失真問題。本文針對基于實用AGC算法的音頻信號處理方法與FPGA實現,及其相關內容進行了分析研究。1、 實用AGC算法在
2020-10-21 16:42:15
一種在FPGA中實現的基于軟判決的Viterbi譯碼算法,并以一個(2,1,2)、回溯深度為10的軟判決Viterbi譯碼算法為例驗證該算法,在Xilinx的XC3S500E芯片上實現了該譯碼器,最后對其性能做了分析。 關鍵詞: OFDM;Viterbi譯碼;軟判決;FPGA
2009-09-19 09:41:24
各位朋友好,我的導師要求我設計一個新的報文調度算法,能夠實現不同優先級的報文在發送的過程中,實現高優先級報文的低延時和低抖動。要求使用stm32的LWIP協議棧進行報文調度算法的開發,請問要實現
2020-04-07 04:35:59
和Motion JPEG三種算法,有將這3種算法用FPGA實現的大神么?還有就是這3種算法到底適不適合用FPGA實現,麻煩有過研究的大大們分析下啊!謝謝!PS:如果有這3種算法的資料說明麻煩大家分享下,我找到的都是C語言的源碼,看起來好吃力!
2017-07-04 11:17:17
本文研究的就是在FPGA設計平臺上設計硬件電路,實現數字圖像的空域濾波算法。
2021-04-30 06:29:41
方面不支持64位操作,于是RC6修正這個錯誤,使用4個32位寄存器而不是2個64位寄存器,以更好地實現加解密。利用FPGA來實現RC6算法,可以提高運算速度。芯片設計為RC6算法處理器,輔助計算機處理器完成加解密操作,可以方便地實現對加解密的分析和研究。因此,此芯片可以作為協處理器來看待。
2019-08-19 07:27:09
本帖最后由 eehome 于 2013-1-5 10:04 編輯
指紋識別算法的研究及基于FPGA的硬件實現
2012-05-23 20:14:46
FPGA芯片- CycloneIII EP3C55F484,內含55865 個L C s ,具有2 60萬B IT內嵌R AM容量, 4個鎖相環( 2 KH Z - 1300MHZ),484個IO引腳。可
2018-03-06 09:30:50
求EP2S60F672詳細資料哪位大俠有啊,給我發一個
2009-08-11 22:14:25
設計題目:基于NXP K60的蜂窩物聯網數據傳輸終端設計1. 設計所采用的控制芯片必須是K60系列;2. 蜂窩物聯網芯片推薦采用中移物聯網公司的NB-IoT系列芯片。3. 數據傳輸關系:RS485
2019-12-19 21:27:55
和論證的基礎上,選取較優化的預處理算法,作為FPGA指紋預處理平臺的算法。并用FPGA實現所選算法。1 處理步驟 本系統采用XILINX公司Spartan 3E系列FPGA作為核心控制芯片,通過富士通
2009-09-19 09:38:11
協同過濾算法的原理及實現基于物品的協同過濾算法詳解協同過濾算法的原理及實現
2020-11-05 06:51:34
一種基于FPGA技術的虛擬邏輯分析儀的研究與實現:邏輯分析儀的現狀" 發展趨勢及研制虛擬邏輯分析儀的必要性, 論述了基于FPGA技術的虛擬邏輯分析儀的設計方案及具體實現方法,介紹
2008-11-27 13:13:04 29
29 小波盲源分離算法的仿真及FPGA實現:提出了一種基于小波變換的盲源分離方法,在理論分析和仿真結果的基礎上,給出了FPGA 的實現方案。針對傳統盲分離算法對源信號統計特征敏
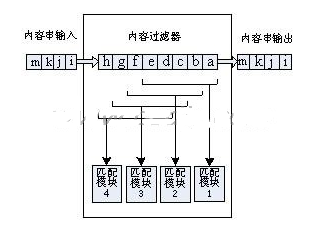
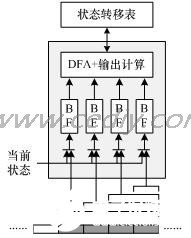
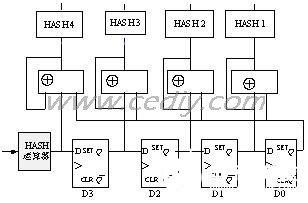
2009-06-21 22:44:0921 IP 過濾是把IP 數據報文分成不同種類的過程,主要取決于IP 報頭中的信息。基于軟件的字符串匹配已經不能跟上高速的網絡傳輸速度,需要尋找
2009-09-09 09:17:5216 針對信息檢索分類技術發展的需求,本文通過對協同過濾推薦算法的綜述,提出傳統過濾算法無法適用于用戶多興趣下的推薦問題進行了剖析,提出了一種基于用戶聚類的協同過濾推薦
2010-03-01 16:09:4711 介紹了AES中,SubBytes算法在FPGA的具體實現.構造SubBytes的S-Box轉換表可以直接查找ROM表來實現.通過分析SubBytes算法得到一種可行性硬件邏輯電路,從而實現SubBytes變換的功能.
2010-11-09 16:42:4825 提出一種基于DCT域的數字水印算法,并用FPGA硬件實現其中關鍵部分DCT變換。采用VHDL語言有效設計和實現DCT變換,分析與仿真結果表明:與軟件實現相比,用FPGA實現水印算法具有高
2010-12-28 10:22:1420 用FPGA實現FFT算法
引言 DFT(Discrete Fourier Transformation)是數字信號分析與處理如圖形、語音及圖像等領域的重
2008-10-30 13:39:201426 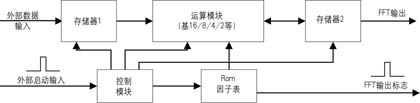
摘要: 針對在FPGA中實現FIR濾波器的關鍵--乘法運算的高效實現進行了研究,給了了將乘法化為查表的DA算法,并采用這一算法設計了FIR濾波器。通過FPGA仿零點驗證
2009-06-20 14:09:36677 
利用FPGA來實現RC6算法的設計與研究
引 言
RC6是作為AES(Advanced Encryption Standard)的候選算法提交給NIST(美國國家標準局)的一種新的分組密碼。它是在RC5的基礎上
2009-12-28 09:20:151022 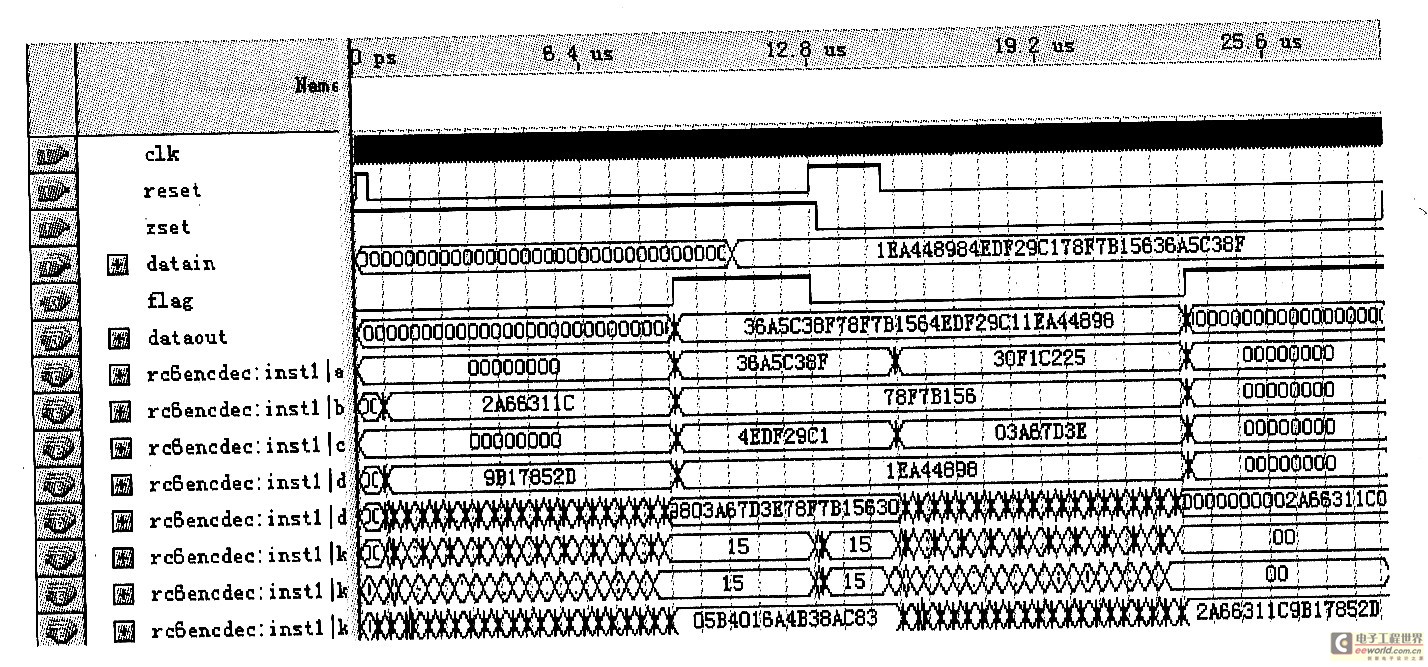
首先分析了8PSK 軟解調算法的復雜度以及MAX算法的基本原理,并在Altera 公司的Stratix II 系列FPGA芯片上實現了此軟解調硬件模塊
2011-04-08 11:22:156901 
本文介紹的電子消像旋系統采用Altera公司的StratixII系列FPGA芯片和ADI公司的ADSP2183為核心,可以滿足系統對功能、實時性及精度的要求。
2011-09-13 11:28:001165 
差分功耗分析是破解AES密碼算法最為有效的一種攻擊技術,為了防范這種攻擊技術本文基于FPGA搭建實驗平臺實現了對AES加密算法的DPA攻擊,在此基礎上通過掩碼技術對AES加密算法進行優
2011-12-05 14:14:3152 以Altera公司的FPGA EP2S60為例,探討了SOPC系統設計的綜合優化方法。
2012-03-12 11:49:281204 
基于FPGA的JPEG解碼算法的研究與實現,很好的資料,快來學習吧
2016-02-18 13:53:550 基于FPGA的模糊PID控制算法的研究及實現-2009。
2016-04-05 10:39:2920 CCD圖像的顏色插值算法研究及其FPGA實現
2016-08-29 15:02:0312 基于FPGA的JPEG解碼算法的研究與實現
2016-08-29 16:05:0111 基于FPGA的數字信號處理算法研究與高效實現
2016-08-29 23:20:5639 空間圖像CCSDS壓縮算法研究與FPGA實現,感興趣小伙伴們可以瞧一瞧。
2016-09-18 14:57:4216 算法進行深入研究,面向Xilinx K7 410T FPGA 芯片設計SHA-1算法實現結構,完成SHA-1算法編程,進行測試和后續應用。該算法在FPGA 上實現,可以實現3.2G bit/s的吞吐
2017-10-30 16:25:544 摘要: 介紹了3DES加密算法的原理并詳盡描述了該算法的FPGA設計實現。采用了狀態機和流水線技術,使得在面積和速度上達到最佳優化;添加了輸入和輸出接口的設計以增強該算法應用的靈活性。各模塊均用硬件
2017-11-06 11:10:094 公司的Spartan6系列FPGA芯片,系統可以實現將四路攝像頭采集的視頻信號從任意通道放大到1 920x1 080@60 Hz的分辨率顯示,結果表明輸出視頻圖像的實時性和細節保持良好。
2017-11-16 11:48:094559 
本文采用Altera公司Stratix II系列的EP2S90F1508C3芯片,以Quartus II 8.1為開發環境[4],采用硬件描述語言VHDL進行SM3算法的FPGA實現。SM3算法實現
2017-11-24 15:33:592445 
針對防火墻粗粒度過濾Modbus/TCP導致工控系統存在安全威脅的問題,研究基于Modbus功能碼的細粒度過濾算法。基于Modbus TCP功能碼的特征,對其功能碼字段進行解析,實現基于白名單規則
2018-01-16 15:32:340 傳統的基于幾何區域分割的報文分類算法在空間切分時,通常只采用一種切分方法,并不會根據每個域的特點選取不同的對策.提出了一種采用混合切分法的報文分類算法HIC(hybrid intelligent
2018-02-24 14:06:310 語義主題,從語義層面計算用戶對各資源的偏好概率,將計算出的偏好概率與協同過濾算法計算出的資源相似度相結合,預測用戶偏好值,實現個性化推薦。在Movielens數據集上的實驗結果表明,與傳統基于標簽的推薦算法相比,該算法能消除標簽
2018-03-07 13:58:030 中,采用AGC算法,可提高音頻信號系統和音頻信號輸出的穩定性,解決了AGC調試后的信號失真問題。本文針對基于實用AGC算法的音頻信號處理方法與FPGA實現,及其相關內容進行了分析研究。
2018-09-30 16:29:142957 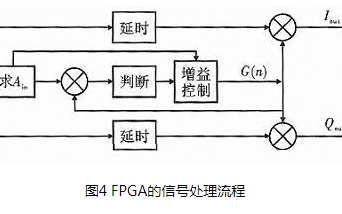
隨著深亞微米工藝的發展, FPGA 的容量和密度不斷增加,以其強大的并行乘加運算(MAC)能力和靈活的動態可重構性,被廣泛應用于通信、圖像等許多領域。但是在復雜算法的實現上,FPGA 不如嵌入式
2020-12-23 12:33:001 為進一步提高編碼效率,在研究菱形算法的基礎上,采用了“十字”形運動估計算法,設計了硬件電路,并用H‘GA(Field-Pmg隱mmable Gate Amy)實現了算法.結合算法的特點,設計了整體
2021-02-03 14:46:0012 提出一種新的高階FIR濾波器的FPGA實現方法。該方法運用多相分解結構對高階FIR濾波器進行降階處理,采用改進的分布式算法來實現降階后的FIR濾波器。設計了一系列階數從8到1 024的FIR濾波器
2021-03-23 15:44:5430 基于顯式反饋的協同過濾算法只存在3個變量,其相似度計算方法依賴用戶評分數據的顯式反饋行為,而未考慮現實推薦場景中存在的隱性因素影響,這決定了協同過濾算法被限制于挖掘用戶及商品的偏好,而缺乏挖掘用戶
2021-04-28 11:30:153 摘要:在對FFT(快速傅立葉變換)算法進行研究的基礎上,描述了用FPGA實現FFT的方法,并對其中的整體結構、蝶形單元及性能等進行了分析。
2022-04-12 19:28:254515 有些transceiver有PNC過濾功能,也可以在硬件上設置此過濾功能。針對NXP TJA1145 Transceiver而言,只能過濾通信速率在1Mbps的報文,因此要注意項目中的網絡管理報文
2022-08-23 12:09:084078 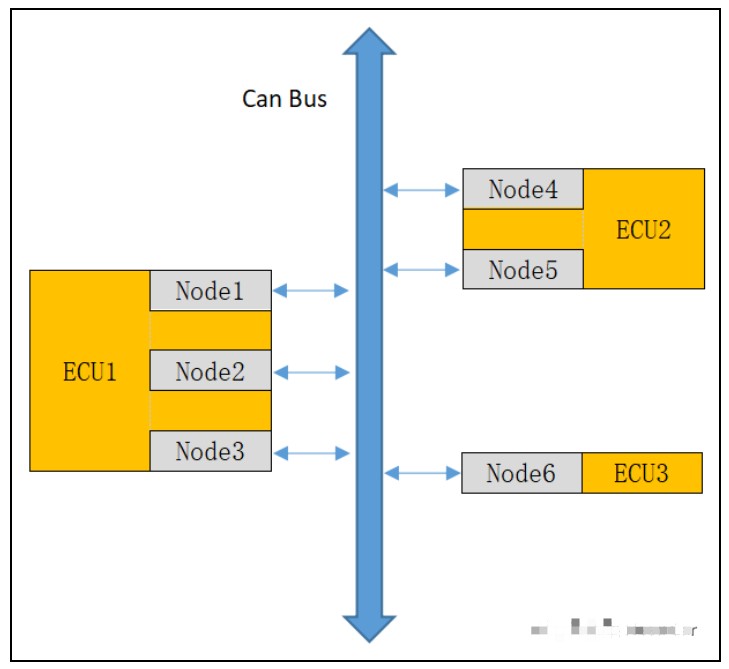
TSMaster軟件平臺支持對不同總線(CAN、LIN、FlexRay)的報文和信號過濾,過濾方法一般有全局接收過濾、數據流過濾、窗口過濾、字符串過濾、可編程過濾,針對不同的總線信號過濾器的使用方法
2023-12-16 08:21:15206 
正在加载...
 電子發燒友App
電子發燒友App










 工商網監
工商網監
評論