 電子發燒友App
電子發燒友App


機器學習是使用算法解析數據,從中學習,然后做出決策或預測的過程。機器不是準備程序代碼來完成任務,而是使用大量數據和算法“訓練”以自行執行任務。
機器學習正在使用神經網絡 (NN) 算法發生革命性變化,神經網絡算法是我們大腦中發現的生物神經元的數字模型。這些模型包含像大腦神經元一樣連接的層。許多應用程序都受益于機器學習,包括圖像分類/識別、大數據模式檢測、ADAS、欺詐檢測、食品質量保證和財務預測。
作為機器學習的算法,神經網絡包括由多個層組成的廣泛的拓撲結構和大小;第一層(“輸入層”)、中間層(“隱藏層”)和最后一層(“輸出層”)。隱藏層對輸入執行各種專用任務并將其傳遞到下一層,直到在輸出層生成預測。
一些神經網絡相對簡單,只有兩層或三層神經元,而所謂的深度神經網絡 (DNN) 可能包含多達 1000 層。為特定任務確定正確的 NN 拓撲和大小需要與類似網絡進行實驗和比較。
設計高性能機器學習應用程序需要網絡優化,這通常使用修剪和量化技術完成,以及計算加速,使用 ASIC 或 FPGA 執行。
在本文中,我們將討論 DNN 的工作原理、為什么 FPGA 在 DNN 推理中越來越受歡迎,并考慮使用 FPGA 開始設計和實現基于深度學習的應用程序所需的工具。
開發 DNN 應用程序的設計流程
設計 DNN 應用程序是一個三步過程。這些步驟是選擇正確的網絡,訓練網絡,然后將新數據應用于訓練模型進行預測(推理)。
如前所述,DNN 模型中有多個層,每一層都有特定的任務。在深度學習中,每一層都旨在提取不同層次的特征。例如,在邊緣檢測神經網絡中,第一個中間層檢測邊緣和曲線等特征。然后將第一個中間層的輸出饋送到第二層,第二層負責檢測更高級別的特征,例如半圓或正方形。第三個中間層組裝其他層的輸出以創建熟悉的對象,最后一層檢測對象。
在另一個示例中,如果我們開始識別停車標志,則經過訓練的系統將包括用于檢測八邊形形狀、顏色以及其中的字母“S”、“T”、“O”和“P”的層秩序和孤立。輸出層將負責確定它是否是停車標志。
DNN 學習模型
有四種主要的學習模型:
監督:在這個模型中,所有的訓練數據都被標記了。NN 將輸入數據分類為從訓練數據集中學習的不同標簽。
無監督:在無監督學習中,深度學習模型被交給一個數據集,而沒有明確說明如何處理它。訓練數據集是沒有特定期望結果或正確答案的示例集合。然后,NN 會嘗試通過提取有用的特征并分析其結構來自動找到數據中的結構。
半監督:這包括帶有標記和未標記數據的訓練數據集。這種方法在難以從數據中提取相關特征時特別有用,并且標記示例對于專家來說是一項耗時的任務。
強化:這是獎勵網絡以獲得結果并提高性能的行為。這是一個迭代過程:反饋的輪次越多,網絡就越好。這種技術對于訓練機器人特別有用,機器人會在諸如駕駛自動駕駛汽車或管理倉庫庫存等任務中做出一系列決策。
訓練與推理
在訓練中,未經訓練的神經網絡模型從現有數據中學習新的能力。一旦訓練好的模型準備好,它就會被輸入新數據并測量系統的性能。正確檢測圖像的比率稱為推理。
在圖 1 給出的示例中(識別貓),在輸入訓練數據集后,DNN 開始調整權重以尋找貓;其中權重是每個神經元之間連接強度的度量。
如果結果錯誤,錯誤將被傳播回網絡層以修改權重。這個過程一次又一次地發生,直到它得到正確的權重,這導致每次都得到正確的答案。
如何實現高性能 DNN 應用
使用 DNN 進行分類需要大數據集,從而提高準確性。然而,一個缺點是它為模型產生了許多參數,這增加了計算成本并且需要高內存帶寬。
優化 DNN 應用程序有兩種主要方法。首先是通過修剪冗余連接和量化權重并融合神經網絡來縮小網絡規模的網絡優化。
修剪: 這是 DNN 壓縮的一種形式。它減少了與其他神經元的突觸連接數,從而減少了數據總量。通常,接近零的權重會被移除。對于分類 [2] 等任務,這有助于消除冗余連接,但精度會略有下降。
量化: 這樣做是為了使神經網絡達到合理的大小,同時實現高性能的準確性。這對于內存大小和計算數量必然受到限制的邊緣應用程序尤其重要。在此類應用中,為了獲得更好的性能,模型參數保存在本地內存中,以避免使用 PCIe 或其他互連接口進行耗時的傳輸。在該方法中,執行通過低位寬數的神經網絡(INT8)來逼近使用浮點數的神經網絡(FTP32)的過程。這極大地降低了使用神經網絡的內存需求和計算成本。通過量化模型,我們稍微損失了精度和準確度。但是,對于大多數應用程序來說,不需要 32 位浮點。
優化 DNN 的第二種方法是通過計算加速,使用 ASIC 或 FPGA。其中,后一種選擇對機器學習應用程序有很多好處。這些包括:
電源效率: FPGA 提供了一種靈活且可定制的架構,它只允許使用我們需要的計算資源。在 ADAS 等許多應用中,為 DNN 配備低功耗系統至關重要。
可重構性: 與 ASIC 相比,FPGA 被認為是原始可編程硬件。此功能使它們易于使用,并顯著縮短了上市時間。為了趕上每天發展的機器學習算法,擁有對系統重新編程的能力是非常有益的,而不是等待 SoC 和 ASIC 的長時間制造。
低延遲: 與最快的片外存儲器相比,FPGA 內部的 Block RAM 提供的數據傳輸速度至少快 50 倍。這是機器學習應用程序的游戲規則改變者,低延遲是必不可少的。
性能可移植性: 您無需任何代碼修改或回歸測試即可獲得下一代 FPGA 設備的所有優勢。
靈活性: FPGA 是原始硬件,可以針對任何架構進行配置。沒有固定的架構或數據路徑可以束縛您。這種靈活性使 FPGA 能夠進行大規模并行處理,因為數據路徑可以隨時重新配置。靈活性還帶來了任意對任意 I/O 連接能力。這使 FPGA 無需主機 CPU 即可連接到任何設備、網絡或存儲設備。
功能安全:: FPGA 用戶可以在硬件中實現任何安全功能。根據應用程序,可以高效地進行編碼。FPGA 廣泛用于航空電子設備、自動化和安全領域,這證明了這些設備的功能安全性,機器學習算法可以從中受益。
成本效率: FPGA 是可重新配置的,應用程序的上市時間非常短。ASIC 非常昂貴,如果沒有出現錯誤,制造時間需要 6 到 12 個月。這是機器學習應用程序的一個優勢,因為成本非常重要,而且 NN 算法每天都在發展。
現代 FPGA 通常在其架構中提供一組豐富的 DSP 和 BRAM 資源,可用于 NN 處理。但是,與 DNN 的深度和層大小相比,這些資源已不足以進行完整和直接的映射;當然不會像前幾代神經網絡加速器中經常使用的那樣。即使使用像 Zynq MPSoC 這樣的設備(即使是最大的設備也僅限于 2k DSP 片和總 BRAM 大小小于 10 MB),將所有神經元和權重直接映射到 FPGA 上也是不可能的。
那么,我們如何利用 FPGA 的功率效率、可重編程性、低延遲等特性進行深度學習呢?
需要新的 NN 算法和架構修改才能在 FPGA 等內存資源有限的平臺上進行 DNN 推理。
現代 DNN 將應用程序分成更小的塊,由 FPGA 處理。由于 FPGA 中的片上存儲器不足以存儲網絡所需的所有權重,我們只需要存儲當前階段的權重和參數,它們是從外部存儲器(可能是 DDR 存儲器)加載的。
然而,在 FPGA 和內存之間來回傳輸數據將使延遲增加多達 50 倍。首先想到的是減少內存數據。除了上面討論的網絡優化(剪枝和量化)之外,還有:
權重編碼:在FPGA中,編碼格式可以隨意選擇。可能會有一些準確性損失,但是與數據傳輸引起的延遲及其處理的復雜性相比,這可以忽略不計。權重編碼創建了二元神經網絡 (BNN),其中權重減少到只有一位。這種方法減少了傳輸和存儲的數據量,以及計算復雜度。然而,這種方法只會導致具有固定輸入寬度的硬件乘法器的小幅減少。
批處理:在這種方法中,我們使用流水線方法將芯片上已有的權重用于多個輸入。它還減少了從片外存儲器傳輸到 FPGA [5] 的數據量。
在 FPGA 上設計和實現 DNN 應用
讓我們深入研究在 FPGA 上實現 DNN。在此過程中,我們將利用最合適的商用解決方案來快速跟蹤應用程序的開發。
例如,Aldec 有一個名為TySOM-3A-ZU19EG的嵌入式開發板。除了廣泛的外設,它還搭載 Xilinx Zynq UltraScale+ MPSoC 系列中最大的 FPGA,該器件具有超過一百萬個邏輯單元,并包括一個運行頻率高達 1.5GHz 的四核 Arm Cortex-A53 處理器。
重要的是,就我們的目的而言,這款龐大的 MPSoC 還支持賽靈思為機器學習開發人員創建的深度學習處理單元 (DPU)。
DPU 是專用于卷積神經網絡 (CNN) 處理的可編程引擎。它旨在加速計算機視覺應用中使用的 DNN 算法的計算工作量,例如圖像/視頻分類和對象跟蹤/檢測。
DPU 有一個特定的指令集,使其能夠有效地與許多 CNN 一起工作。與常規處理器一樣,DPU 獲取、解碼和執行存儲在 DDR 內存中的指令。該單元支持多種 CNN,如 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet、FPN 等 [3]。
DPU IP 可以作為一個塊集成到所選 Zynq?-7000 SoC 和 Zynq UltraScale?+ MPSoC 器件的可編程邏輯 (PL) 中,并直接連接到處理系統 (PS)。
為了創建 DPU 的說明,Xilinx 提供了深度神經網絡開發套件 (DNNDK) 工具包。賽靈思聲明:
DNNDK 被設計為一個集成框架,旨在簡化和加速深度學習處理器單元 (DPU) 上的深度學習應用程序開發和部署。DNNDK是一個優化推理引擎,它使DPU的計算能力變得容易獲得。它為開發深度學習應用程序提供了最佳的簡單性和生產力,涵蓋了神經網絡模型壓縮、編程、編譯和運行時啟用 [4] 的各個階段。
DNNDK 框架包括以下單元:
DECENT: 執行剪枝和量化以滿足低延遲和高吞吐量
DNNC: 將神經網絡算法映射到 DPU 指令
DNNAS:將 DPU 指令組裝成 ELF 二進制代碼
N 2 Cube:充當 DNNDK 應用程序的加載器,處理資源分配和 DPU 調度。其核心組件包括 DPU 驅動程序、DPU 加載程序、跟蹤器和用于應用程序開發的編程 API。
Profiler:由 DPU 跟蹤器和 DSight 組成。D 跟蹤器在 DPU 上運行 NN 時收集原始分析數據。DSight 使用此數據生成可視化圖表以進行性能分析。
Dexplorer:為 DPU 提供運行模式配置、狀態檢查和代碼簽名檢查。
DDump:轉儲 DPU ELF、混合可執行文件或 DPU 共享庫中的信息。它加速了用戶的調試和分析。
這些符合圖 2 所示的流程。
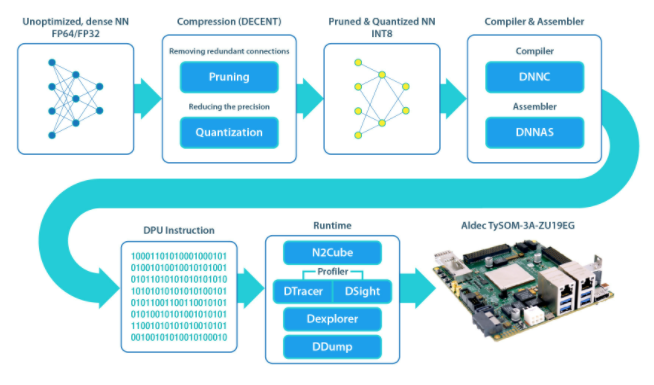
圖 2.上述深度神經網絡開發套件 (DNNK) 框架使基于 FPGA 的機器學習項目的設計過程對開發人員來說更加容易。
使用 DNNDK 可以讓開發人員更輕松地設計基于 FPGA 的機器學習項目;此外,Aldec 的 TySOM-3A-ZU19EG 板等平臺也可提供寶貴的啟動功能。例如,Aldec 準備了一些針對板的示例——包括手勢檢測、行人檢測、分割和交通檢測——這意味著開發人員不是從一張白紙開始的。
讓我們考慮一下今年早些時候在 Arm TechCon 上展示的一個演示。這是使用 TySOM-3A-ZU19EG 和 FMC-ADAS 子卡構建的交通檢測演示,該子卡為 5 倍高速數據 (HSD) 攝像頭、雷達、激光雷達和超聲波傳感器提供接口和外圍設備——大多數人的感官輸入ADAS 應用程序。
圖 3 顯示了演示的架構。FPGA 中實現了兩個 DPU,它們通過 AXI HP 端口連接到處理單元,以執行深度學習推理任務,例如圖像分類、對象檢測和語義分割。DPU 需要指令來實現由 DNNC 和 DNNAS 工具準備的神經網絡。他們還需要訪問輸入視頻和輸出數據的內存位置。
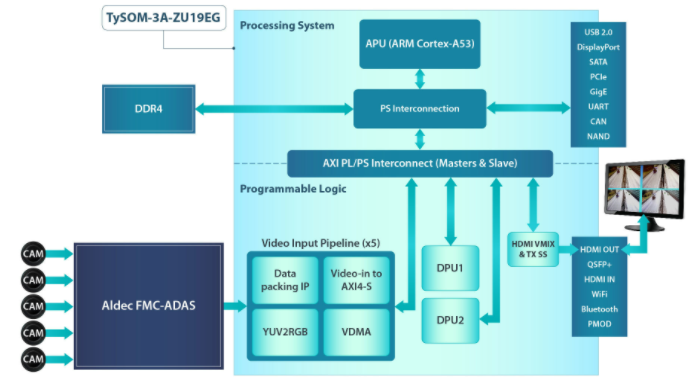
圖 3. 流量檢測演示具有 5 個視頻輸入管道,用于數據打包、AXI4 到 AXI 流數據傳輸、色彩空間轉換 (YUV2RGB) 以及將視頻發送到內存。
應用程序在應用程序處理單元 (APU) 上運行,以通過管理中斷和執行單元之間的數據傳輸來控制系統。DPU 和用戶應用程序之間的連接是通過 DPU API 和 Linux 驅動程序實現的。有一些功能可以將新圖像/視頻讀取到 DPU、運行處理并將輸出發送回用戶應用程序。
開發和訓練模型是使用 FPGA 之外的 Caffe 完成的,而優化和編譯是使用作為 DNNDK 工具包的一部分提供的 DECENT 和 DNNC 單元完成的(圖 2)。在本設計中,SSD 對象檢測 CNN 用于背景、行人和車輛檢測。
在性能方面,使用四個輸入通道實現了 45 fps,展示了使用 TySOM-3A-ZU19EG 和 DNNDK 工具包的高性能深度學習應用程序。
審核編輯:郭婷












 工商網監
工商網監
評論