 電子發燒友App
電子發燒友App


這是新的系列教程,在本教程中,我們將介紹使用 FPGA 實現深度學習的技術,深度學習是近年來人工智能領域的熱門話題。
在本教程中,旨在加深對深度學習和 FPGA 的理解。
用 C/C++ 編寫深度學習推理代碼
高級綜合 (HLS) 將 C/C++ 代碼轉換為硬件描述語言
FPGA 運行驗證
在上一篇文章中,我們在 MNIST 數據集上創建并訓練了一個網絡模型。從本文開始,為了在 FPGA 上運行推理處理,我們將首先用 C++ 編寫推理處理代碼。
在這篇 C++ 實現的第一篇文章中,我們開始針對卷積層的 C++ 實現。具體內容是(1)卷積層的實現,(2)運算校驗(C驗證,C/RTL協同驗證)(就是HLS的流程)。
卷積層實現
在上一篇文章中,我解釋了卷積層是對圖像的過濾過程,但是并沒有解釋輸入輸出通道如何處理,過濾時圖像的邊緣處理等。由于本文旨在實現層面的理解,因此我將詳細介紹這些要點。
處理 I/O 通道
在圖像處理中,對RGB輸入圖像進行噪聲去除等濾波處理,并頻繁地進行RGB圖像的處理。在這種情況下,卷積過程往往是針對每個通道(R/G/B)獨立完成的,輸入的G/B通道值不影響輸出的R通道結果。
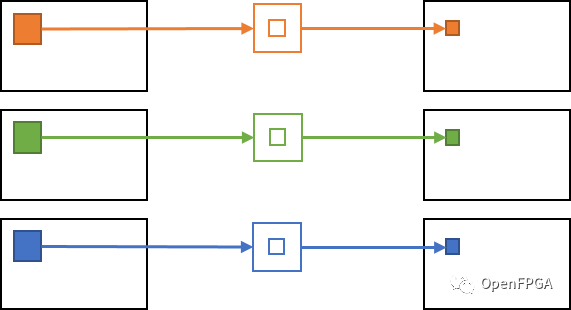
每通道獨立卷積
另一方面,在卷積層中執行的卷積過程中,所有輸入通道的值影響每個輸出通道。因此,對于輸出圖像的每個像素(輸出通道,Y坐標,X坐標),所有輸入通道和周圍的像素區域都會參與計算,導致計算量非常大。
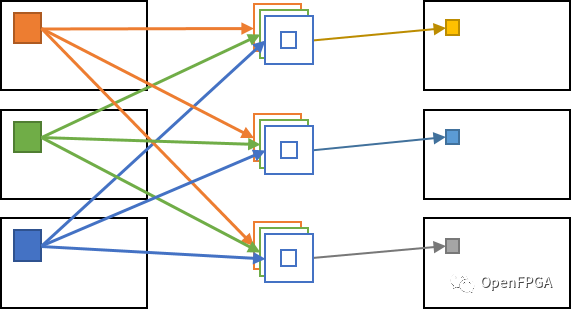
使用所有通道的卷積
另外,如上所述每個通道獨立卷積的卷積層稱為Depthwise Convolution。
這通常用于減少計算量的網絡模型,例如MobileNet(https://arxiv.org/abs/1704.04861)。
圖像邊緣處理
在對圖像進行卷積處理時,圖像邊緣的處理往往是一個問題。
由于卷積過程在計算某個像素時使用了周圍像素,因此對于沒有周圍像素的像素,例如圖像邊緣的像素,就無法獲取周圍像素。
卷積神經網絡主要通過以下兩種方式處理邊緣像素。
無填充:輸出圖像減少了輸入圖像的卷積區域。
補零:將輸入圖像預先用卷積區域擴展,用零填充該區域,對原始輸入圖像進行卷積處理。
沒有填充的卷積的圖形表示如下所示:在這種情況下,輸出圖像將是比輸入圖像小一個濾波器尺寸的區域(橙色部分)。如果內核大小為 3(中心像素 +/-1),則輸出圖像大小在寬度和高度上都將為 -2,因為圖像之外的 1 個像素是無法進行卷積的區域。
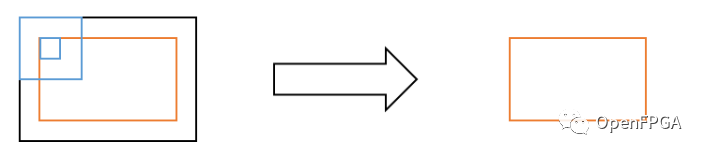
無填充卷積:輸出圖像縮小
接下來,零填充的圖形表示如下所示。在這個例子中,預先在輸入圖像的外部添加了一個值為0的區域(灰色區域),進行卷積,這樣就不會出現圖像縮小現象。如果內核大小為 3,則帶填充的輸入圖像大小在寬度和高度上均為 +2,因為 +1 像素將添加到屏幕外部且值為零。
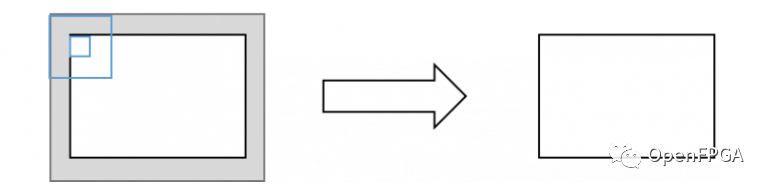
零填充卷積:輸出圖像大小保持不變
在我們的模型中,我們在所有卷積層中使用零填充。
C代碼
如果根據目前為止的解釋用 C 語言實現卷積過程,它將類似于下面的代碼。
?void?conv2d(const?float*?x,?const?float*?weight,?const?float*?bias,?int32_t?width,?int32_t?height,
?????????????int32_t?in_channels,?int32_t?out_channels,?int32_t?ksize,?float*?y)?{
???for?(int32_t?och?=?0;?och?=?height?||?pw?=?width)?{
?????????????????continue;
???????????????}
???????????????int64_t?pix_idx?=?(ich?*?height?+?ph)?*?width?+?pw;
???????????????int64_t?weight_idx?=?((och?*?in_channels?+?ich)?*?ksize?+?kh)?*?ksize?+?kw;
???????????????sum?+=?x[pix_idx]?*?weight[weight_idx];
?????????????}
???????????}
?????????}
?????????//?add?bias
?????????sum?+=?bias[och];
?????????y[(och?*?height?+?h)?*?width?+?w]?=?sum;
???????}
?????}
???}
?}
此函數的解釋如下所示:
輸入
-- x: 輸入圖像。shape=(in_channels, height, width)
-- weight: 權重因子。shape=(out_channels, in_channels, ksize, ksize)
-- bias: 偏置值。shape=(out_channels)
輸出
-- y: 輸出圖像。shape=(out_channels, height, width)
參數:-- width: 輸入/輸出圖像的寬度
-- height: 輸入/輸出圖像高度
-- in_channels:輸入圖像的通道數
-- out_channels:輸出圖像的通道數
-- ksize: 內核大小
每個輸入/輸出的內存布局shape=(...)如表格所示,但float x[in_channels][height][width];將其視為定義為三維數組。
卷積層的處理是一個6級循環。第一個三級循環確定輸出圖像上的位置,隨后的三級循環對該位置執行卷積操作。
零填充在第 24-26 行完成。由于實際創建零填充輸入圖像是低效的,所以零填充是通過在訪問圖像外部時不參與乘積之和來實現的。
第31行是卷積過程中的積和運算部分,這個積和運算out_channels * height * width * in_channels * ksize * ksize進行了兩次。這個卷積過程的操作數量非常大,在很多情況下,卷積層支配著卷積神經網絡的執行時間。這就是為什么計算單元比 CPU 多的 GPU 和 FPGA 更適合處理神經網絡。
第37行是偏差處理部分。到目前為止,我還沒有觸及什么是偏差處理,但正如我在這里所寫的那樣,它是一個簡單地對輸出值進行偏移的過程。這種偏差處理在輸入通道/內核大小 (Y,X) 循環之外,因此處理步驟的數量非常微不足道。
運算檢查
作為對上一節創建的函數運行的確認,conv2d我們將比較結果是否足夠接近在 PyTorch 的 C++ API (libtorch) 上執行的卷積計算。
每個測試包括以下兩個步驟。
C. 驗證
C/RTL 協同驗證
1、C 驗證類似于正常的軟件開發,gcc只是用通用的編譯器編譯源代碼并檢查結果。
2、C/RTL協同驗證是使用AMD-Xilinx提供的高階綜合工具Vitis HLS進行驗證。對于此驗證,HLS 首先將 C 源代碼轉換為 Verilog HDL 等 RTL。然后在 Vivado 中對生成的 RTL 執行功能仿真。
在這個邏輯仿真中,將一個類似于C驗證的數據序列輸入到創建的電路中,確認輸出結果是否正確。
本節以后的內容將以運行創建的源代碼的形式進行說明。
源代碼將在后面發布。
運行環境
運行環境面向 Linux 機器。不支持 Windows/Mac 操作系統。此外,由于預裝gcc版本,該發行版針對 Ubuntu 18.04。難以自行準備運行環境的朋友,看看就行。
需要以下工具。
Vivado ?2020.2(推薦 2019.2)
cmake >= 3.11
cmake比較麻煩,因為它需要的版本比apt等包管理器可以安裝的版本高,但是可以下載預構建的二進制文件(cmake--Linux-x86_64.tar.gz)。
C. 驗證
測試代碼/tests/ref/conv2d.cc的使用,我不會在本文中詳細介紹,但測試將是一個正常的隨機測試。
可以按照以下步驟構建代碼。請將 -DVIVADO_HLS_ROOT 的值相應地替換為安裝的 Vivado 的路徑。
$?mkdir?/build $?cd? /build $?cmake?..?-DVIVADO_HLS_ROOT=/tools/Xilinx/Vivado/2022.2 $?cmake?--build?.
使用以下命令進行測試:如果沒有任何錯誤,那它就是成功的。
$?ctest?-V?-R?"conv2d_ref"
C/RTL 協同驗證
運行以下命令以使用 HLS 啟動 C/RTL 協同驗證。大約需要 5 分鐘。
$?ctest?-V?-R?"conv2d_hls_cosim"
當執行 C/RTL 協同驗證時,會自動創建一個 HLS 項目文件,因此可以使用它來檢查高級綜合和 RTL 仿真波形的結果。
要檢查這一點,請使用以下命令啟動 HLS:
$?vitis_hls?&
HLS 打開后,單擊“打開項目”,如下所示,導航到/build/tests/hls/conv2d/conv2d_hls_cosim目錄并單擊“確定”。
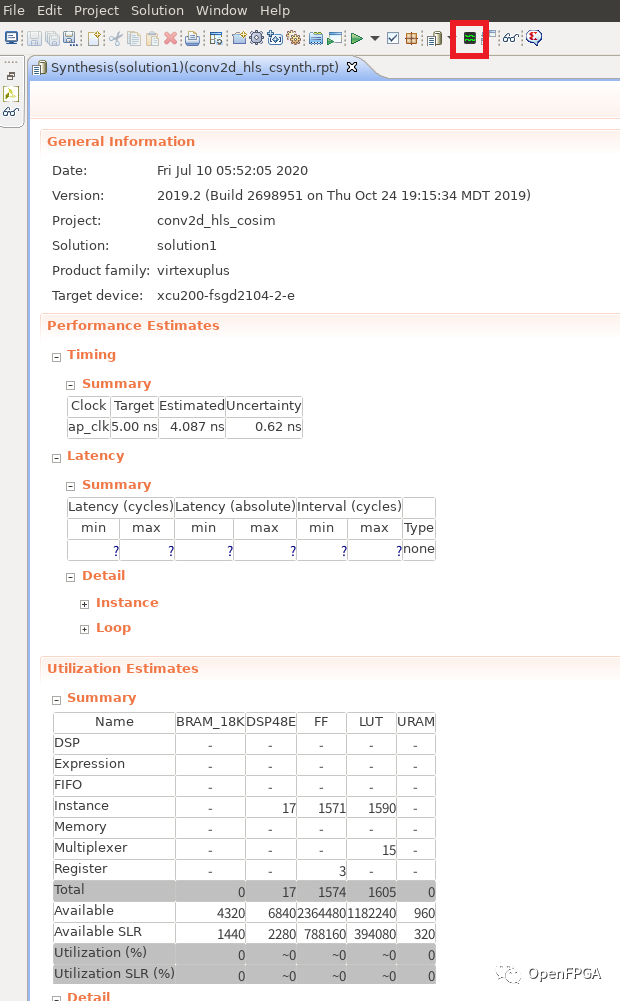
然后,HLS 綜合報告將顯示如下屏幕所示。
從此報告中,可以看到從 Performance Estimates 列創建的電路的估計性能,以及從 Utilization Estimates 看到在目標設備上實施時的估計資源使用情況。
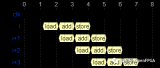
點擊頂部紅框包圍的區域,可以看到仿真的波形。
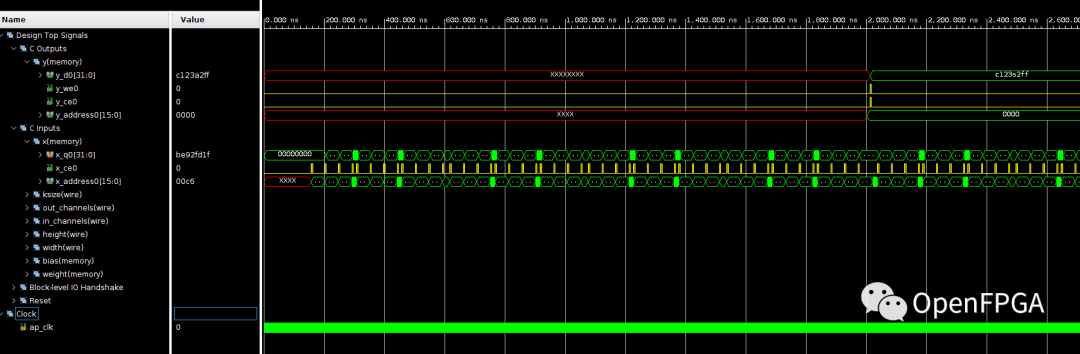
波形如下所示,可以看出可以通過某種方式讀取到該值,大概2000.00ns就能輸出y的第一個值。
通過這種方式,我們能夠創建一個邏輯電路,該邏輯電路使用 ?HLS 執行卷積層計算,而無需特別注意 HW。
然而,由于這個電路根本沒有調整,它的設計只是實現功能,在后續會對此進行優化。
總結
在這篇文章中,用 C++ 實現了一個卷積層并確認了它的運行。我們還在這個 C++ 實現上使用 HLS 進行了高級綜合,并確認它在 C/RTL 協同驗證中沒有任何問題。
原編輯::黃飛















 工商網監
工商網監
評論