 電子發(fā)燒友App
電子發(fā)燒友App


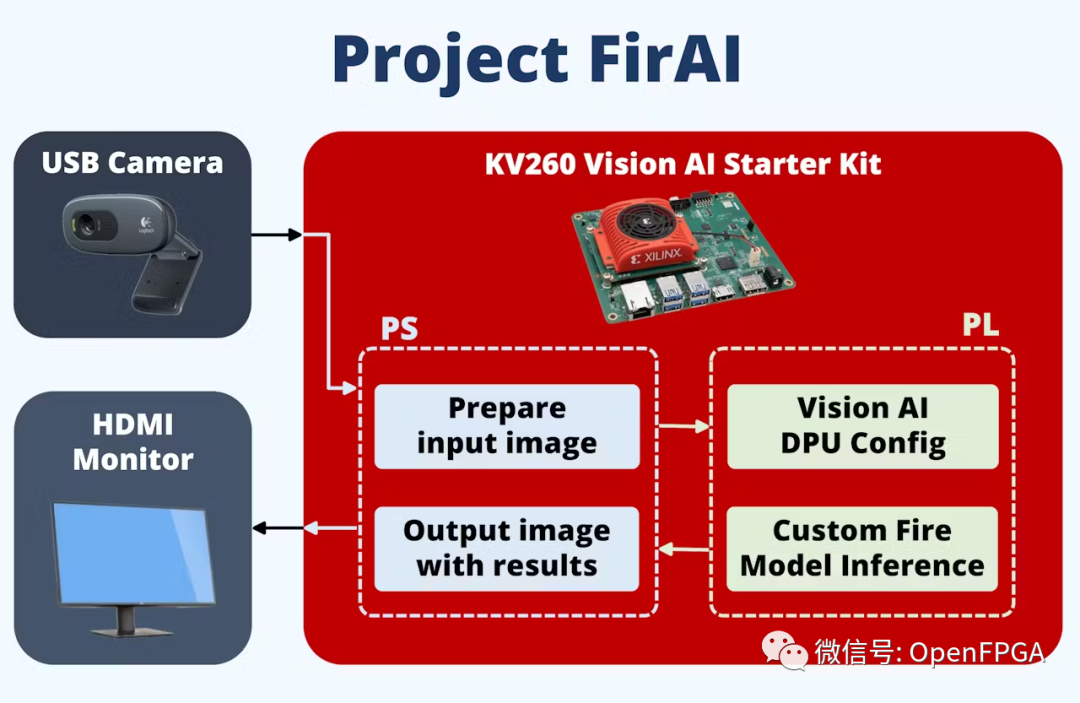
部署在 FPGA 上加速的 AI 火災(zāi)偵查。助力消防人員快速應(yīng)對火災(zāi)事故~
緒論
問題:近年來,不斷增加的城市人口、更復(fù)雜的人口密集建筑以及與大流行病相關(guān)的問題增加了火災(zāi)偵查的難度。因此,為了增強消防人員對火災(zāi)事件的快速反應(yīng),安裝視頻分析系統(tǒng),可以及早發(fā)現(xiàn)火災(zāi)爆發(fā)。
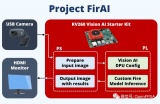
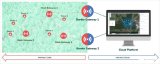
目標(biāo):解決方案包括建立一個分布式計算機視覺系統(tǒng),增加建筑物火災(zāi)的早期檢測。該系統(tǒng)的分布式和模塊化特性可以輕松部署,而無需增加更多基礎(chǔ)設(shè)施。在不增加人力規(guī)模的情況下,可以明顯增強消防能力。系統(tǒng)通過使用 Xilinx FPGA實現(xiàn)邊緣 AI 加速圖像處理功能來實現(xiàn)。
開發(fā)流程介紹
使用的硬件是 Xilinx Kria KV260,用于加速計算機視覺處理和以太網(wǎng)連接的相機套件。嵌入式軟件使用 Vitis AI。在 PC 上,使用現(xiàn)有的火災(zāi)探測數(shù)據(jù)集對自定義 Yolo-V4 模型進(jìn)行訓(xùn)練。之后,對Xilinx YoloV4 模型進(jìn)行量化、裁剪和編譯 DPU ,最后部署在FPGA上。
系統(tǒng)框圖
PC:設(shè)置 SD 卡鏡像
首先我們需要為 FPGA Vision AI Starter Kit 準(zhǔn)備 SD 卡(至少 32GB)。
這次將使用 Ubuntu 20.04.3 LTS 作為系統(tǒng)。可以從下面網(wǎng)站下載鏡像。
?
https://ubuntu.com/download/xilinx
?

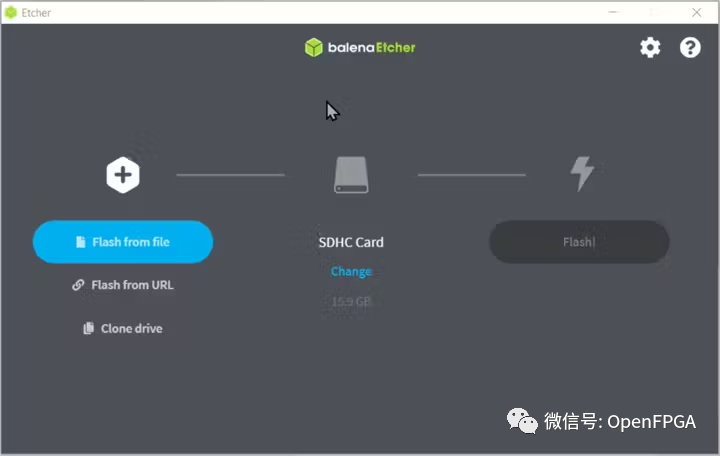
在 PC 上,下載 Balena Etcher 將其寫入 SD 卡。
?
https://www.balena.io/etcher/
?
或者,可以使用下面命令行(警告:請確保系統(tǒng)下/dev/sdb必須是 SD 卡)進(jìn)行操作:
?
?
xzcat?~/Downloads/iot-kria-classic-desktop-2004-x03-20211110-98.img.xz?|?sudo?dd?of=/dev/sdb?bs=32M
?
?
完成后, SD 卡就準(zhǔn)備好了,將其插入 開發(fā)板上。
設(shè)置 Xilinx Ubuntu
將 USB 鍵盤、USB 鼠標(biāo)、USB 攝像頭、HDMI/DisplayPort 和以太網(wǎng)連接到開發(fā)板。

連接電源,將看到 Ubuntu 登錄屏幕。
?
?
默認(rèn)用戶名:ubuntu密碼:ubuntu
?
?
啟動時,系統(tǒng)ui可能會非常慢,可以運行下面這些命令來禁用一些組件以加快速度。
?
?
gsettings?set?org.gnome.desktop.interface?enable-animations?false gsettings?set?org.gnome.shell.extensions.dash-to-dock?animate-show-apps?false
?
?
接下來,調(diào)用下面命令將系統(tǒng)更新到最新版本
?
?
sudo?apt?upgrade
?
?
早期版本的 Vitis-AI 不支持 Python,詳見:
?
https://support.xilinx.com/s/question/0D52E00006o96PISAY/how-to-install-vart-for-vitis-ai-python-scripts?language=en_US
?
安裝用于系統(tǒng)管理的 xlnx-config snap 并對其進(jìn)行配置(https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/2037317633/Getting+Started+with+Certified+Ubuntu+20.04+LTS+for+Xilinx+Devices):
?
?
sudo?snap?install?xlnx-config?--classic xlnx-config.sysinit
?
?
接下來檢查設(shè)備配置是否工作正常。
?
?
sudo?xlnx-config?--xmutil?boardid?-b?som
?
?
安裝帶有示例的 Smart Vision 應(yīng)用程序和 Vitis AI 庫。(智能視覺應(yīng)用程序包含我們將重復(fù)使用的 DPU 的比特流,庫樣本稍后也將用于測試我們訓(xùn)練的模型)
?
?
sudo?xlnx-config?--snap?--install?xlnx-nlp-smartvision sudo?snap?install?xlnx-vai-lib-samples
?
?
檢查已安裝的示例和應(yīng)用程序
?
?
xlnx-vai-lib-samples.info sudo?xlnx-config?--xmutil?listapps
?
?
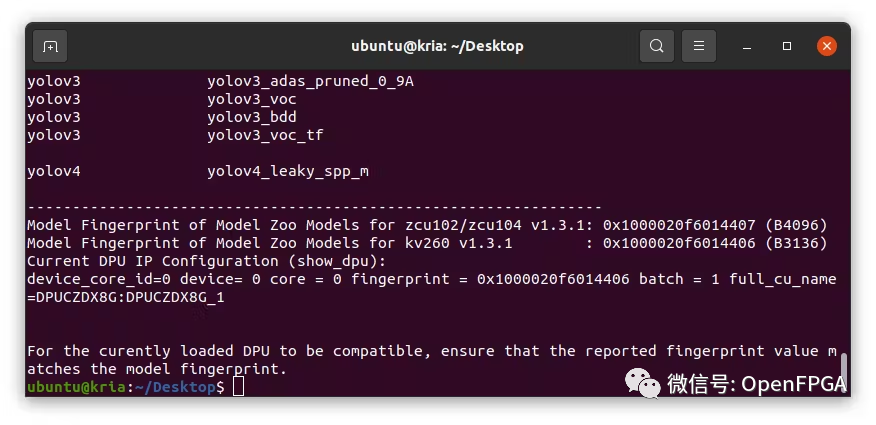
運行上述命令后,就會注意到 DPU 需要 Model Zoo 樣本。
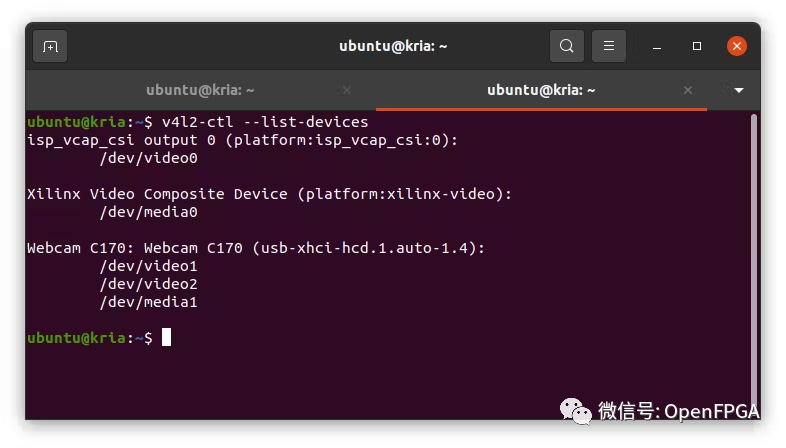
接下倆運行其中一個示例。在運行示例之前,需要將 USB 攝像頭連接到開發(fā)板并確保系統(tǒng)驅(qū)動能檢測到視頻設(shè)備。這次使用的是 Logitech C170,它被掛載到/dev/video1
?
?
v4l2-ctl?--list-devices
?
?
加載并啟動智能視覺應(yīng)用程序。
?
?
sudo?xlnx-config?--xmutil?loadapp?nlp-smartvision xlnx-nlp-smartvision.nlp-smartvision?-u
?
?
在運行任何加速器應(yīng)用程序之前,我們需要先加載 DPU。我們可以簡單地調(diào)用 smartvision 應(yīng)用程序,它會為我們加載比特流。或者,可以打包自己的應(yīng)用程序(https://www.hackster.io/AlbertaBeef/creating-a-custom-kria-app-091625)。
注意:加速器比特流位于/lib/firmware/xilinx/nlp-smartvision/.
由于我們計劃是使用YOLOv4框架,所以讓我們測試一個模型的例子。有“ yolov4_leaky_spp_m”預(yù)訓(xùn)練模型。
?
?
sudo?xlnx-config?--xmutil?loadapp?nlp-smartvision #?the?number?1?is?because?my?webcam?is?on?video1 xlnx-vai-lib-samples.test-video?yolov4?yolov4_leaky_spp_m?1
?
?
上面的命令將在第一次運行時下載模型。模型將被安裝到 ~/snap/xlnx-vai-lib-samples/current/models 目錄中。
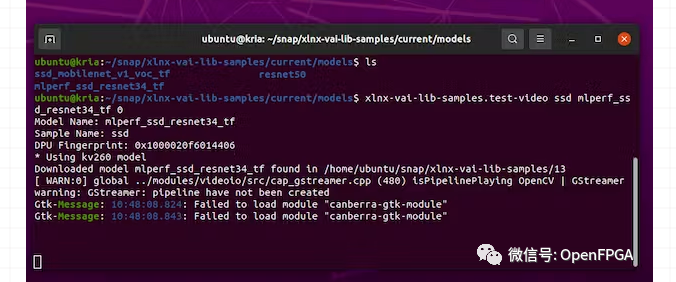
上面測試良好,接下來就可以訓(xùn)練我們自己的模型。
PC:運行 YOLOv4 模型訓(xùn)練
要訓(xùn)練模型,請遵循Xilinx 提供的07-yolov4-tutorial文檔。它是為 Vitis v1.3 編寫的,但步驟與當(dāng)前的 Vitis v2.0 完全相同。
?
https://xilinx.github.io/Vitis-Tutorials/2020-2/docs/Machine_Learning/Design_Tutorials/07-yolov4-tutorial/README.html
?
我們的應(yīng)用程序用于檢測火災(zāi)事件,因此請在下面鏈接中下載火災(zāi)圖像開源數(shù)據(jù)集:
?
https://github.com/gengyanlei/fire-smoke-detect-yolov4/blob/master/readmes/README_EN.md
?
fire-smoke (2059's images, include labels)-GoogleDrive
?
https://drive.google.com/file/d/1ydVpGphAJzVPCkUTcJxJhsnp_baGrZa7/view?usp=sharing
?
請參考.cfg此處的火災(zāi)數(shù)據(jù)集文件。
?
https://raw.githubusercontent.com/gengyanlei/fire-smoke-detect-yolov4/master/yolov4/cfg/yolov4-fire.cfg
?
我們必須修改此.cfg配置文件以與 Xilinx Zynq Ultrascale+ DPU 兼容:
Xilinx 建議文件輸入大小為 512x512(或 416x416 以加快推理速度)

DPU 不支持 MISH 激活層,因此將它們?nèi)刻鎿Q為 Leaky 激活層

DPU 僅支持最大 SPP maxpool 內(nèi)核大小為 8。默認(rèn)設(shè)置為 5、9、13。但決定將其更改為 5、6、8。
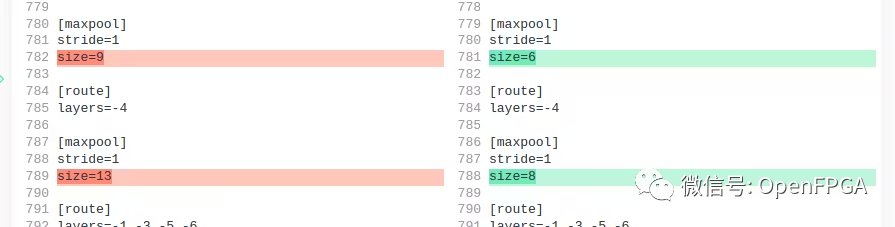
在 Google Colab 上對其進(jìn)行了訓(xùn)練。遵循了 YOLOv4 的標(biāo)準(zhǔn)訓(xùn)練過程,沒有做太多修改。
在 github 頁面中找到帶有分步說明的 Jupyter notebook。
?
https://github.com/zst123/xilinx_kria_firai
?
下圖是損失的進(jìn)展圖。運行了大約 1000 次迭代我覺得這個原型的準(zhǔn)確性已經(jīng)足夠好了,但如果可以的話,建議進(jìn)行幾千次迭代訓(xùn)練。
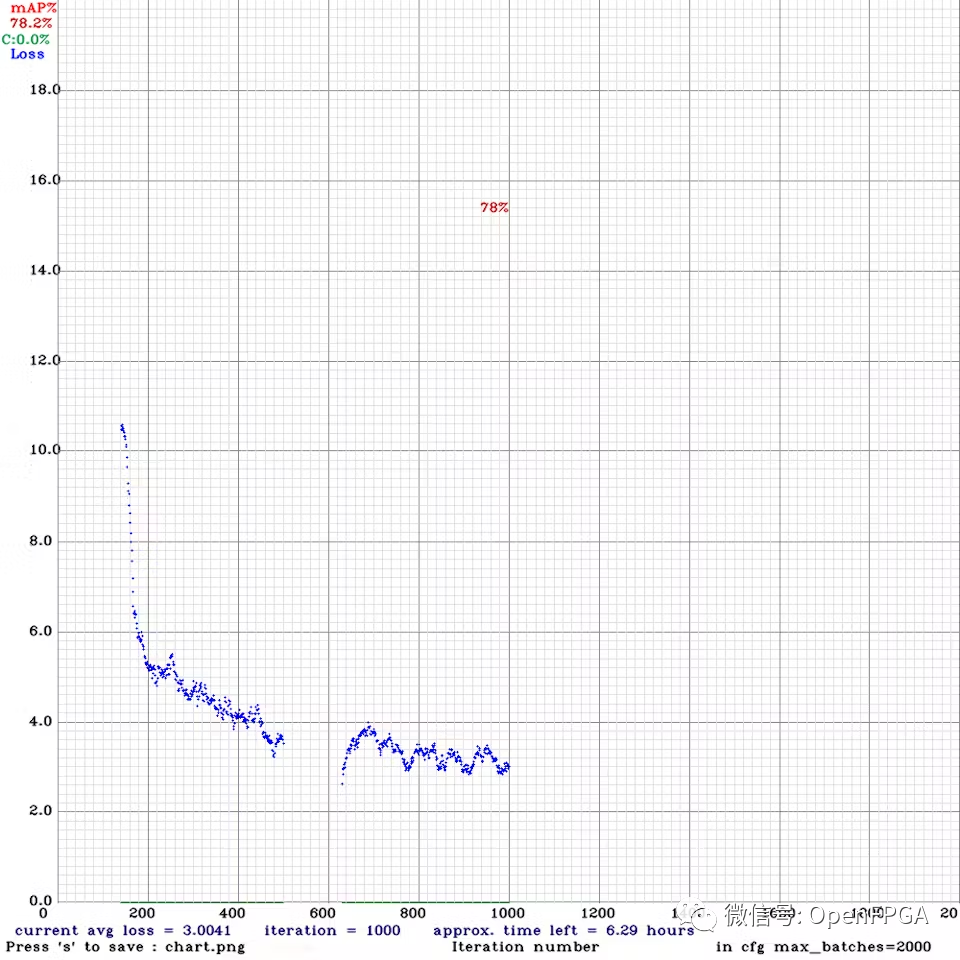
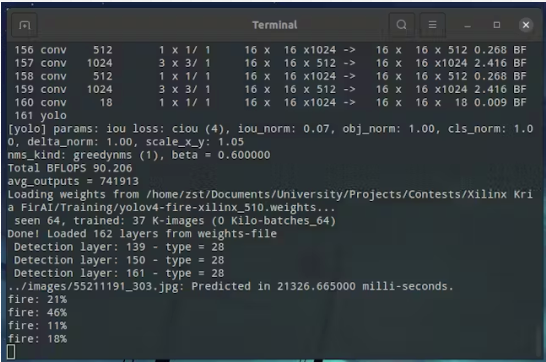
下載最佳權(quán)重文件 ( yolov4-fire-xilinx_1000.weights)。在本地運行了 yolov4 推理,一張圖像大約需要 20 秒!稍后我們將看到使用 FPGA 可以將其加速到接近實時的速度。
?
?
./darknet?detector?test?../cfg/fire.data?../yolov4-fire.cfg? ../yolov4-fire_1000.weights?image.jpg?-thresh?0.1
?
?
現(xiàn)在有了經(jīng)過訓(xùn)練的模型,接下來就是將其轉(zhuǎn)換和部署在 FPGA 上。
PC:轉(zhuǎn)換TF模型
下一步是將darknet model轉(zhuǎn)換為frozen tensorflow流圖。keras-YOLOv3-model-set 存儲庫為此提供了一些有用的腳本。我們將運行 Vitis AI 存儲庫中的一些腳本。
首先安裝docker,使用這個命令:
?
?
sudo?apt?install?docker.io sudo?service?docker?start sudo?chmod?666?/var/run/docker.sock?#?Update?your?group?membership
?
?
拉取 docker 鏡像。使用以下命令下載最新的 Vitis AI Docker。請注意,此容器是 CPU 版本。(確保運行Docker的磁盤分區(qū)至少有100GB的磁盤空間)
?
?
$?docker?pull?xilinx/vitis-ai-cpu:latest
?
?
clone Vitis-AI 文件夾
?
?
git?clone?--recurse-submodules?https://github.com/Xilinx/Vitis-AI cd?Vitis-AI

?
?
啟動 Docker
?
?
bash?-x?./docker_run.sh?xilinx/vitis-ai-cpu:latest
?
?
進(jìn)入 docker shell 后,clone教程文件。
?
?
>?git?clone?https://github.com/Xilinx/Vitis-AI-Tutorials.git >?cd?./Vitis-AI-Tutorials/ >?git?reset?--hard?e53cd4e6565cb56fdce2f88ed38942a569849fbd?#?Tutorial?v1.3
?
?
現(xiàn)在我們可以從這些目錄訪問 YOLOv4 教程:
從主機目錄:~/Documents/Vitis-AI/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial
從 docker 中:/workspace/Vitis-AI-Tutorials/07-yolov4-tutorial
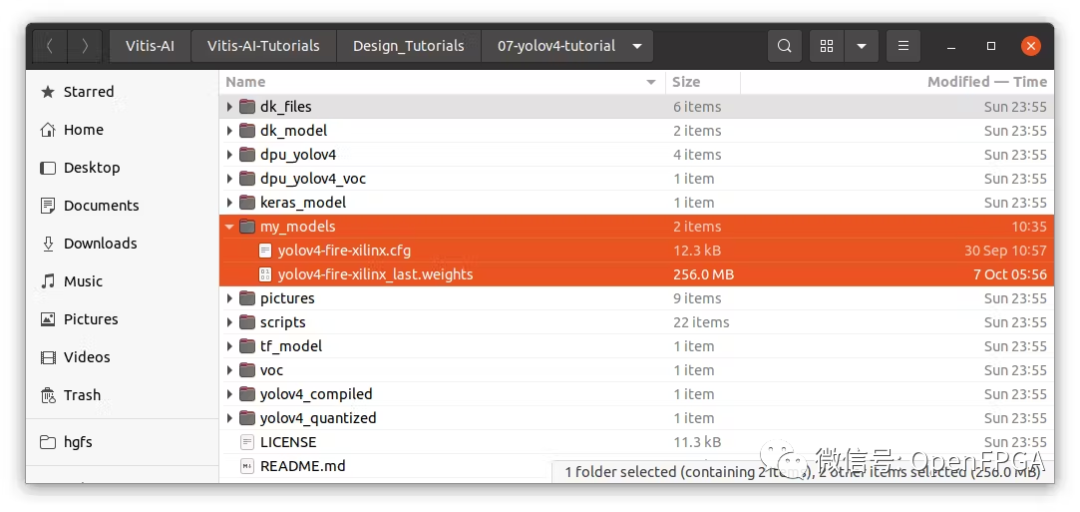
進(jìn)入教程文件夾,創(chuàng)建一個名為“ my_models ”的新文件夾并復(fù)制這些文件:
?
?
訓(xùn)練好的模型權(quán)重:yolov4-fire-xilinx_last.weights 訓(xùn)練配置文件:yolov4-fire-xilinx.cfg
?
?
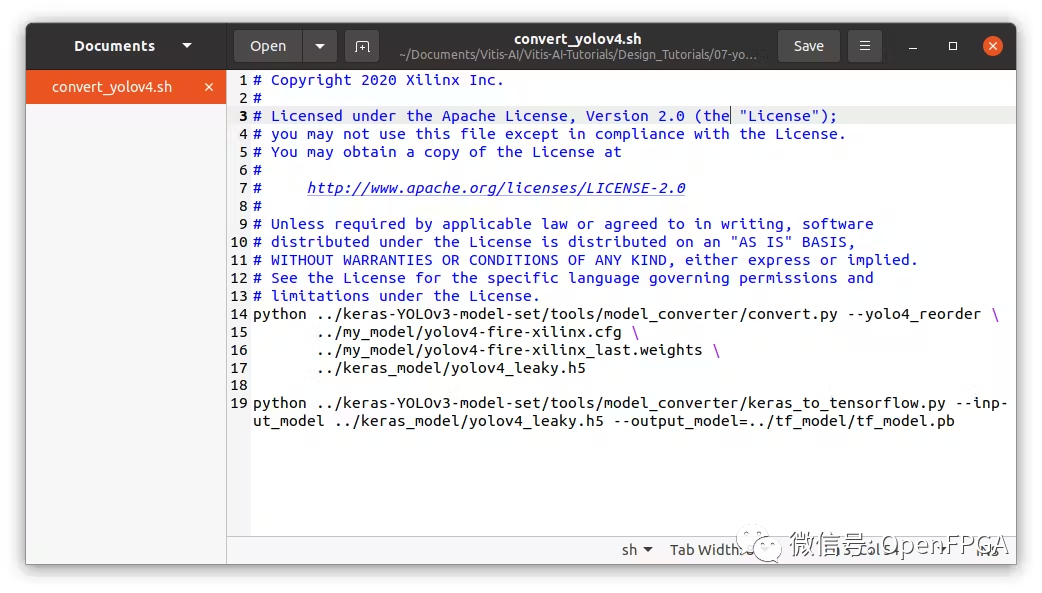
在 scripts 文件夾下,找到convert_yolov4腳本。編輯文件指向我們自己的模型(cfg 和權(quán)重文件):
?
?
../my_models/yolov4-fire-xilinx.cfg? ../my_models/yolov4-fire-xilinx_last.weights?
?
?
現(xiàn)在回到終端并輸入 docker。激活tensorflow環(huán)境。我們將開始轉(zhuǎn)換yolo模型的過程
?
?
>?conda?activate?vitis-ai-tensorflow >?cd?/workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/scripts/ >?bash?convert_yolov4.sh
?
?
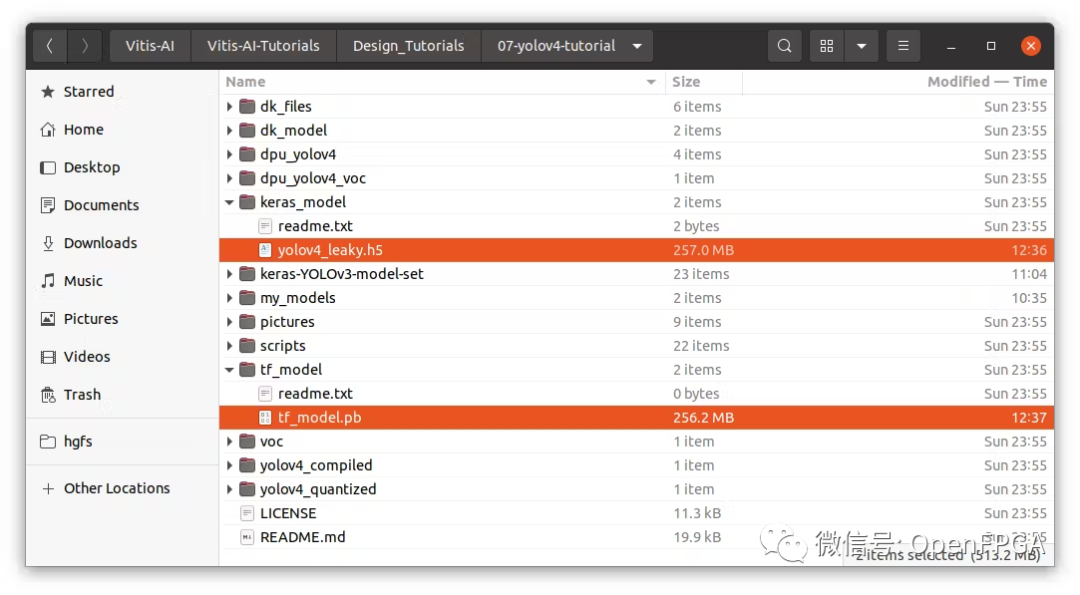
轉(zhuǎn)換后,現(xiàn)在可以在“keras_model”文件夾中看到 Keras 模型(.h5)。以及“tf_model”文件夾下的frozen model(.pb)。
PC:量化模型
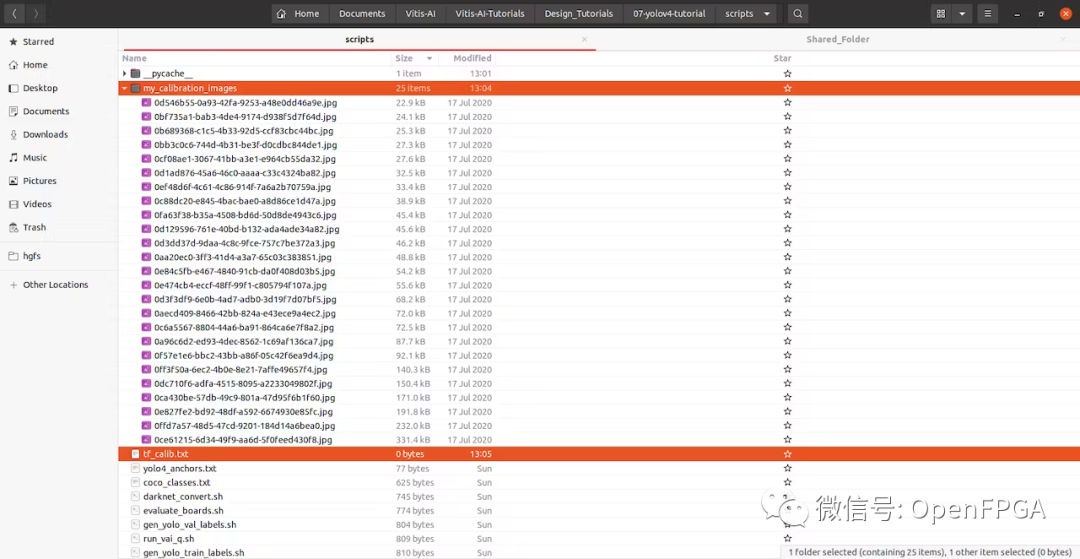
我們需要將部分訓(xùn)練圖像復(fù)制到文件夾“ yolov4_images ”。這些圖像將用于量化期間的校準(zhǔn)。
創(chuàng)建一個名為“ my_calibration_images ”的文件夾,并將訓(xùn)練圖像的一些隨機文件粘貼到那里。然后我們可以列出所有圖像的名稱到 txt 文件中。
?
?
>?ls?./my_calibration_images/?>?tf_calib.txt
?
?
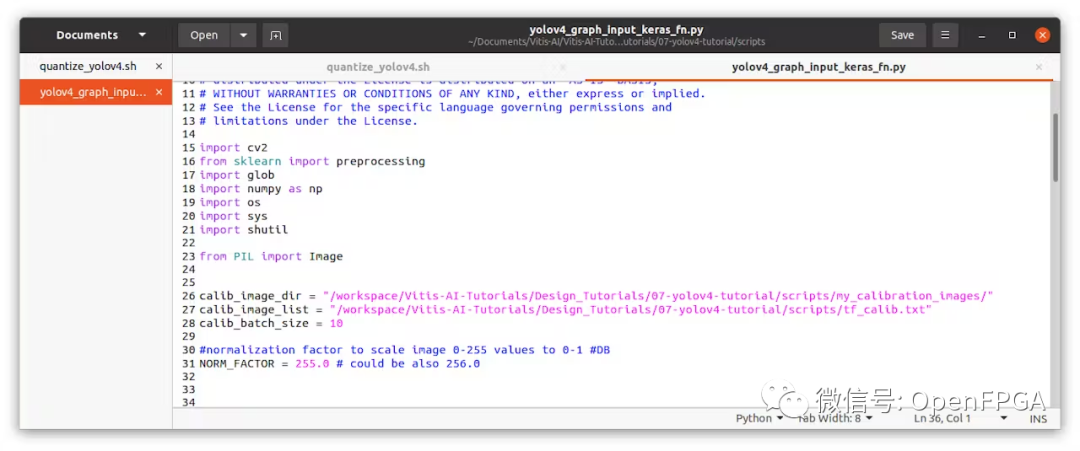
然后編輯yolov4_graph_input_keras_fn.py ,指向這些文件位置。
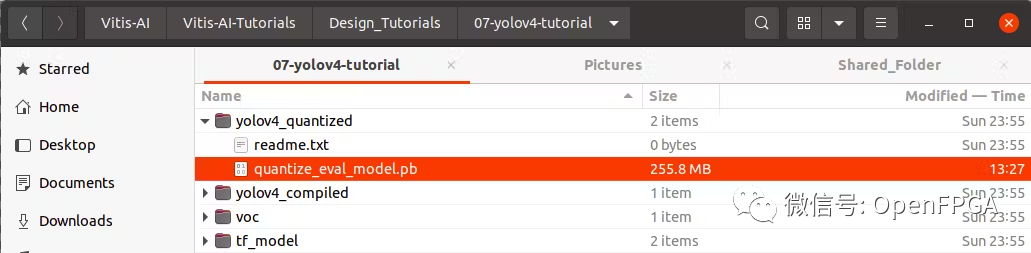
運行./quantize_yolov4.sh。將在yolov4_quantized目錄中生成一個量化圖。

接下來在“yolov4_quantized”文件夾中看到量化的frozen model。
PC:編譯 xmodel 和 prototxt
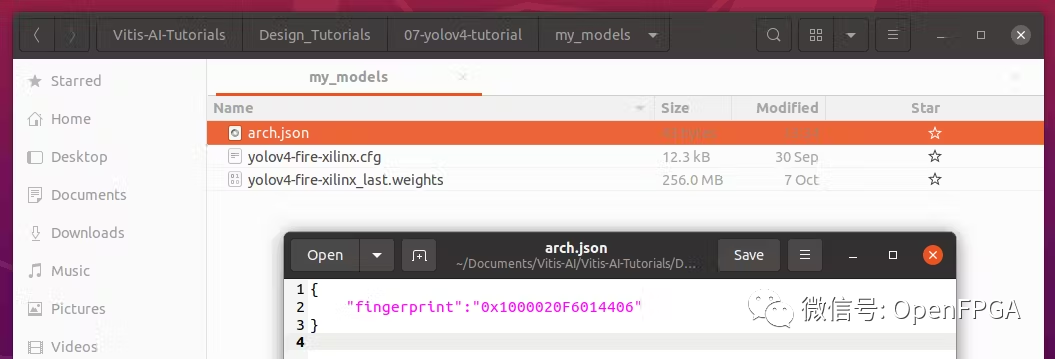
創(chuàng)建用于編譯 xmodel 的arch.json ,并將其保存到同一個“ my_models ”文件夾中。
請注意使用我們之前在 FPGA 上看到的相同 DPU。在這種情況下,以下是 FPGA 配置 (Vitis AI 1.3/1.4/2.0)
?
?
{
"fingerprint":"0x1000020F6014406"
}
?
?
修改compile_yolov4.sh指向我們自己的文件
?
?
NET_NAME=dpu_yolov4
ARCH=/workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/my_models/arch.json
vai_c_tensorflow?--frozen_pb?../yolov4_quantized/quantize_eval_model.pb?
--arch?${ARCH}?
--output_dir?../yolov4_compiled/?
--net_name?${NET_NAME}?
--options?"{'mode':'normal','save_kernel':'',?'input_shape':'1,512,512,3'}"
?
?
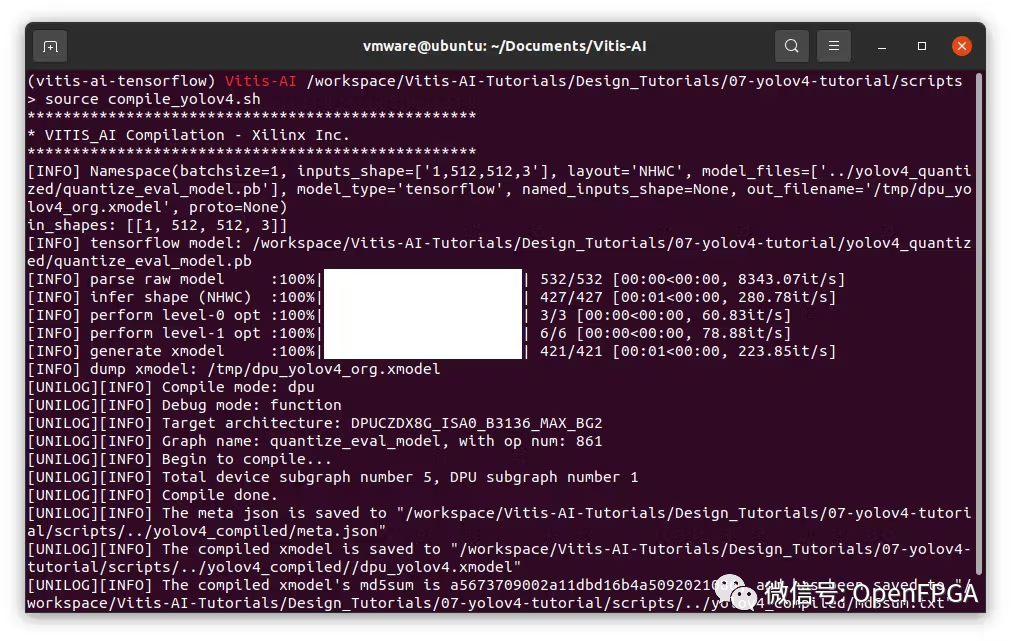
運行編譯
?
?
>?bash?-x??compile_yolov4.sh
?
?
在“yolov4_compiled”文件夾中,將看到 meta.json 和 dpu_yolov4.xmodel。這兩個文件構(gòu)成了可部署模型。將這些文件復(fù)制到 FPGA。
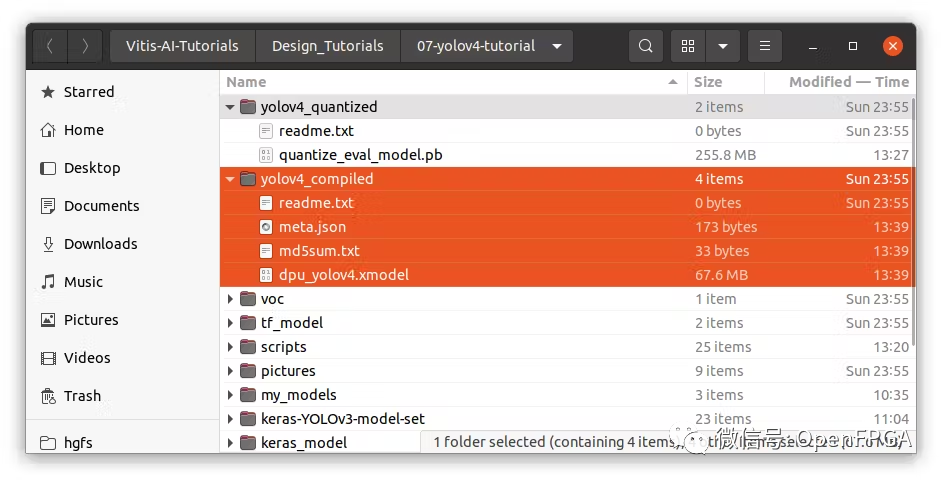
請注意,如果使用官方較舊的指南,能會看到正在使用 *.elf 文件。新指南替換為 *.xmodel 文件
從 Vitis-AI v1.3 開始,該工具不再生成 *.elf 文件,而是 *.xmodel 并且將用于在邊緣設(shè)備上部署模型。
對于某些應(yīng)用程序,需要*.prototxt文件和*.xmodel文件。要創(chuàng)建prototxt,我們可以復(fù)制示例并進(jìn)行修改。
?
https://github.com/Xilinx/Vitis-AI-Tutorials/blob/1.3/Design_Tutorials/07-yolov4-tutorial/dpu_yolov4/dpu_yolov4.prototxt
?
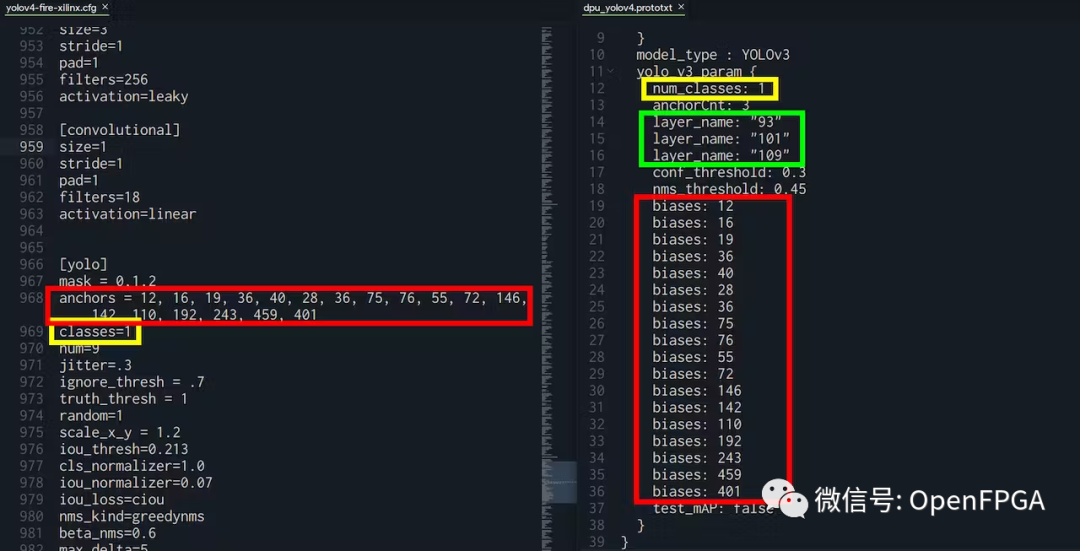
根據(jù)你的YOLO配置需要遵循的事項:
?
?
“biases”:必須與yolo.cfg文件中的“anchors”相同 “num_classes”:必須與 yolo.cfg 文件中的“classes”相同 “l(fā)ayer_name”:必須與 xmodel 文件中的輸出相同
?
?
對于 layer_name,可以轉(zhuǎn)到 Netron ( https://netron.app/ ) 并打開 .xmodel 文件。由于 YOLO 模型有 3 個輸出,還會看到 3 個結(jié)束節(jié)點。
對于這些節(jié)點中的每一個 (fix2float),都可以從名稱中找到編號。
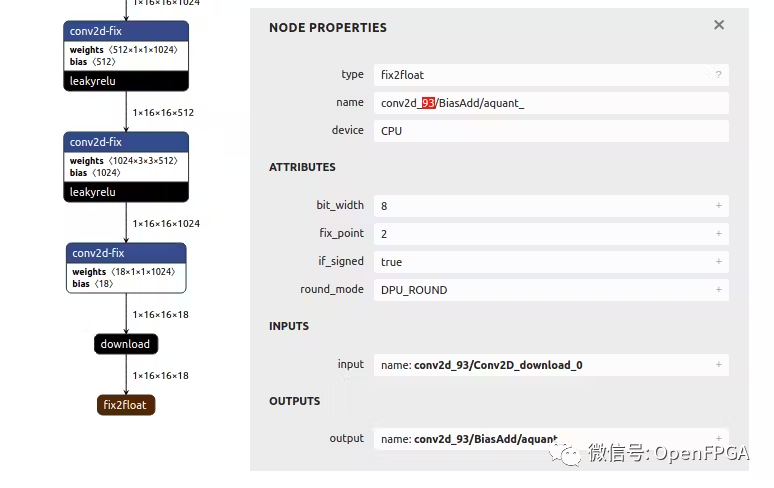
如果在運行模型時可能遇到分段錯誤,很可能是由于.prototxt文件配置錯誤。如果是這樣,請重新運行這一章節(jié)的操作并驗證是否正確。
FPGA:在 FPGA Ubuntu 上測試部署
創(chuàng)建一個名為“dpu_yolov4”的文件夾并復(fù)制所有模型文件。該應(yīng)用程序需要這 3 個文件:
meta.json
dpu_yolov4.xmodel
dpu_yolov4.prototxt
我們可以通過直接從 snap bin 文件夾調(diào)用test_video_yolov4可執(zhí)行文件來測試模型。
?
?
>?sudo?xlnx-config?--xmutil?loadapp?nlp-smartvision?#?Load?the?DPU?bitstream >?cd?~/Documents/ >?/snap/xlnx-vai-lib-samples/current/bin/test_video_yolov4?dpu_yolov4?0
?
?
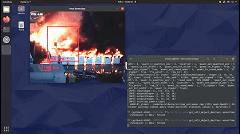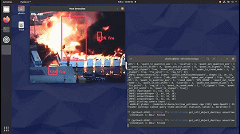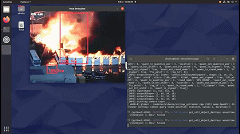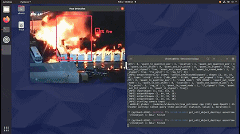
就會看到它檢測到所有的火。在這種情況下,有多個重疊的框。我們在創(chuàng)建 python 應(yīng)用程序時會考慮到這一點。
FPGA:Python 應(yīng)用程序?qū)崿F(xiàn)
在 Github 頁面中,將找到完整應(yīng)用程序?qū)崿F(xiàn)。它考慮了重疊框并執(zhí)行非最大抑制 (NMS) 邊界框算法。它還打印邊界框的置信度。此外,每個坐標(biāo)記錄在幀中。在現(xiàn)實系統(tǒng)中,這些信息將被發(fā)送到服務(wù)器并提醒負(fù)責(zé)人員。
視頻
編輯:黃飛
?














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論