 電子發(fā)燒友App
電子發(fā)燒友App


針對FFT算法基于FPGA實現(xiàn)可配置的IP核。采用基于流水線結(jié)構(gòu)和快速并行算法實現(xiàn)了蝶形運算和4k點FFT的輸入點數(shù)、數(shù)據(jù)位寬、分解基自由配置。使用Verilog語言編寫,利用ModelSim仿真,由ISE綜合并下載,在Xilinx公司的Virtex-5 xc5vfx70t器件上以200 MHz的時鐘實現(xiàn)驗證,運算結(jié)果與其他設(shè)計的運算效率對比有一定優(yōu)勢。
在現(xiàn)代聲納、雷達(dá)、通信、圖像處理等領(lǐng)域中,數(shù)字信號處理系統(tǒng)經(jīng)常要進(jìn)行高速、高精度的FFF運算。現(xiàn)場可編程邏輯陣列(FPGA)是一種可定制集成電路,具有面向數(shù)字信號處理算法的物理結(jié)構(gòu)。用FPGA實現(xiàn)FFT處理器具有硬件系統(tǒng)簡單、功耗低的優(yōu)點,同時具有開發(fā)時間較短、成本較低的優(yōu)勢。基于FPGA實現(xiàn)的數(shù)字信號處理系統(tǒng)具有較高的實時性和嵌入性,并能方便地實現(xiàn)系統(tǒng)集成與功能擴(kuò)展。基于FPGA的硬件實現(xiàn)FFT通常有兩種方法:(1)并行方法,其采用多個蝶形處理器并行運算,能對較高的數(shù)據(jù)采樣率進(jìn)行運算,但其硬件規(guī)模較大,當(dāng)在FPGA上要實現(xiàn)較大點數(shù)的FFT時較為困難。(2)串行方法,采用一個蝶形處理器完成運算,使用的邏輯資源較少,但運算速度較慢。本文在串行方法的基礎(chǔ)上實現(xiàn)了一種在FPGA上實現(xiàn)的可配置FFT IP核,具有輸入點數(shù)可配置(實現(xiàn)0~4 096點自由配置)、數(shù)據(jù)位寬可配置、分解基可配置的特性。
1 原理分析
自從基2快速算法出現(xiàn)以來,人們?nèi)栽诓粩鄬で蟾斓乃惴ā;? FFT算法比最初的基2 FFT算法更快,但從理論上講,用較大的基數(shù)還可進(jìn)一步減少運算次數(shù),但要以程序(或硬件)變得更復(fù)雜為代價。提高FFF處理速度的4個主要技術(shù)途徑是采用流水線結(jié)構(gòu)、并行運算、增加蝶形處理單元數(shù)目和高基數(shù)結(jié)構(gòu)。
1.1 基2算法基本原理
點數(shù)N是2的整數(shù)次冪,將x(n)先按n的奇偶分成兩組

1.2 基4算法基本原理
與基2算法類似,對于N點有限長序列x(n)的DFT按照時域分解展開有
2 可配置FFT IP核硬件結(jié)構(gòu)
現(xiàn)有的FFT IP核在硬件實現(xiàn)時不具備并行度可配置能力,只提供全循環(huán)、全流水、循環(huán)展開與流水結(jié)合等形式下的某種特定實現(xiàn),可重用性較差,難以適應(yīng)不同的計算吞吐量和對計算資源和計算時間的需求。可配置FFT IP核技術(shù)實現(xiàn)FFT算法流水、循環(huán)等并行化參數(shù)的可配置問題,兼顧FFT轉(zhuǎn)換點數(shù)、輸入輸出數(shù)據(jù)位寬、蝶形運算基數(shù)、輸入輸出FIFO深度的可配置,滿足不同應(yīng)用條件下IP復(fù)用的需求,適應(yīng)各種環(huán)境和數(shù)據(jù)吞吐量的FFT運算。可配置FFTIP核功能組成如圖1所示。

如圖1所示,該IP主要包括RAM、ROM、地址產(chǎn)生模塊、移位模塊、選擇數(shù)據(jù)排序模塊、可配置蝶形運算單元、精度調(diào)整模塊和輸出數(shù)據(jù)排序模塊,Din_R和Din_I是FFT輸入數(shù)據(jù)的實部和虛部,Dout_R和Dout_I是FFT變換結(jié)果的實部和虛部。RAM1和RAM2存儲了FFT迭代過程中的輸入數(shù)據(jù),RAM3和RAM4存儲了FFT迭代過程中的計算結(jié)果,RAM1和RAM2、RAM3和RAM4均為乒乓結(jié)構(gòu)。地址產(chǎn)生模塊主要產(chǎn)生向RAM寫入數(shù)據(jù)和從RAM讀出數(shù)據(jù)的地址。ROM中存儲了FFT需要的旋轉(zhuǎn)因子。
2.1 IP核整體方案
設(shè)計可配置FFT處理,其整體結(jié)構(gòu)如圖2所示,設(shè)計采用基2蝶形和基4蝶形運算兩種配置方式,供用戶選擇。輸入數(shù)據(jù)實部和虛部分開存儲,需4個RAM,為實現(xiàn)對連續(xù)流輸入可連續(xù)流輸出,其模塊構(gòu)成如圖2所示。

如圖2所示,外部輸入數(shù)據(jù)的實數(shù)部分Din_R、虛數(shù)部分Din_I,以及輸入數(shù)據(jù)的地址信號ADR,首先進(jìn)入RAM_ADDR單元,選擇合適的時鐘周期將不同點數(shù)的原始數(shù)據(jù)送入RAM單元,當(dāng)輸入數(shù)據(jù)的實數(shù)和虛數(shù)以及其地址準(zhǔn)備好的時候,RDY輸出1。BIT_SFT單元完成輸入數(shù)據(jù)地址的移位變換,實現(xiàn)奇偶分離。當(dāng)數(shù)據(jù)地址準(zhǔn)備好時,RDY輸出1,當(dāng)RAM_ADDR或BIT_SFT這兩個單元中的一個單元準(zhǔn)備好時,便可觸發(fā)RAM單元,將外部數(shù)據(jù)寫入到RAM的指定地址。RAM中的數(shù)據(jù)符合可配置點數(shù)要求后,進(jìn)入NUM_IN單元,其中輸出的數(shù)據(jù)DOR/DOI就是符合基2蝶形或基4蝶形運算的數(shù)據(jù)順序。這些原始數(shù)據(jù)進(jìn)入蝶形運算單元BUTTERFLY,蝶形單元通過U_SELECT單元選擇蝶形運算的分解基,實現(xiàn)基2蝶形運算、基4蝶形運算的可配置功能。其中R4_FFT是基4蝶形運算單元,B2_FFT是基2蝶形運算單元,蝶形運算過程中所需的旋轉(zhuǎn)因子存儲在ROM_RAT單元中,根據(jù)選擇不同分解基的蝶形運算,BUTIERFLY單元產(chǎn)生相應(yīng)的地址,選擇其計算過程中的旋轉(zhuǎn)因子。當(dāng)?shù)芜\算完成后,結(jié)果數(shù)據(jù)進(jìn)入U_CNORM單元,進(jìn)行順序調(diào)整和精度處理;其中PR信號是用戶指定的精度信號,PR[1:0]可提供3種精度,OVF信號是數(shù)據(jù)溢出信號,若置1表明FFT結(jié)果數(shù)據(jù)超出了表示范圍,則要按照截位處理以保證數(shù)據(jù)準(zhǔn)確。當(dāng)數(shù)據(jù)輸入完成后,結(jié)果數(shù)據(jù)進(jìn)入NUM_OUT單元,由于DIT算法輸出結(jié)果以倒序形式輸出,所有需要NUM_OUT進(jìn)行地址調(diào)整,F(xiàn)FT變換結(jié)束后的結(jié)果實數(shù)部分Dout_R,虛數(shù)部分是Dout_I,地址信號是R_ADDR,以正確的順序和形式輸出。
2.2 可配置蝶形單元模塊
在FFT IP核的蝶形運算單元設(shè)計中,蝶形單元的運算過程:第一個時鐘周期是將下結(jié)點與旋轉(zhuǎn)因子復(fù)乘的實數(shù)乘法進(jìn)行計算;第二個時鐘周期是將復(fù)乘中的實數(shù)進(jìn)行加減運算;在第三個時鐘周期是計算復(fù)乘結(jié)果與上結(jié)點的加減運算,即將蝶形運算單元的結(jié)果輸出。可配置蝶形運算通過在基2和基4兩種分解基之間切換來實現(xiàn),其模塊圖如圖3所示。

如圖3所示,數(shù)據(jù)輸入時能信號EN信號置1,則整個蝶形運算單元的數(shù)據(jù)輸入模塊NUM_IN、旋轉(zhuǎn)因子模塊ROM_RAT、分解基選擇模塊U_SELECT進(jìn)入使能狀態(tài);START信號置1,則分解基選擇單元U_SELECT模塊開始進(jìn)入狀態(tài)機(jī)。根據(jù)用戶設(shè)置,如果選擇基2算法蝶形運算單元,則將輸入數(shù)據(jù)的實部和虛部送入R2_FFT模塊;如果選擇基4算法蝶形運算單元,則將輸入數(shù)據(jù)的實部和虛部送入R4_FFT模塊;如果選擇混合基,則需要在狀態(tài)機(jī)中加入判斷條件,準(zhǔn)確控制分支。當(dāng)?shù)芜\算完成時,F(xiàn)FT運算結(jié)果數(shù)據(jù)的實數(shù)部分Dout_R[nb+2:0],虛數(shù)部分Dout_I[nb+2:0]比輸入數(shù)據(jù)的位數(shù)[nb:0]擴(kuò)展了3位,用于精度調(diào)整模塊進(jìn)行精度控制。
蝶形運算的旋轉(zhuǎn)因子存儲在ROM_RAT中,其中存儲了基4運算和基2運算的旋轉(zhuǎn)因子,實部和虛部分開存儲,通過外部信號EN對其使能,為控制ROM存儲空間的占用,不同分解基的旋轉(zhuǎn)因子可公用,通過地址信號ADR選取控制。
3 仿真、綜合結(jié)果分析與驗證
將設(shè)計的IP核進(jìn)行基于ModelSim的仿真,設(shè)置時鐘頻率為200 MHz,數(shù)據(jù)位寬為36位,在基2和基4兩種分解基下,分析1 024點和4 096點的運算效率,其仿真圖像如下所示。
圖4是1 024,點的基2算法仿真結(jié)果,在這種算法下完成數(shù)據(jù)錄入的時間點為113.1μs,完成結(jié)果輸出的時間點為123.4μs,運算時間為10.3μs。圖5是1 024點的基4算法仿真結(jié)果,在該種算法下完成數(shù)據(jù)錄入的時間點51.3μs,完成結(jié)果輸出的時間點是61.6μs,運算時間為8.3 μs。

圖6是4 096點的基2算法仿真結(jié)果,在這種算法下完成數(shù)據(jù)錄入的時間點533.1μs,完成結(jié)果輸出的時間點是574.1μs,運算時間為40 μs。圖7是4096點的基4算法仿真結(jié)果,在該種算法下完成數(shù)據(jù)錄入的時間點為245.7 μs,完成結(jié)果輸出的時間點是286.9μs,運算時間為41.2μs。

板級驗證選用Xilinx公司的Virtex-5 xc5vfx70t器件進(jìn)行綜合、布局布線和時序分析。將得到的數(shù)據(jù)與其他設(shè)計實現(xiàn)進(jìn)行比較,其消耗的資源,以及在200 MHz時鐘情況下不同點數(shù)的FFT處理器進(jìn)行一次處理需要的時間,與文獻(xiàn)換算后得到的數(shù)值對比如表1所示。

4 結(jié)束語
本文設(shè)計的可配置FFT IP核具有靈活性強(qiáng)、容易擴(kuò)展和設(shè)計可復(fù)用的特點,實現(xiàn)分解基可配置、位寬可配置、輸入輸出點數(shù)可配置。從驗證結(jié)果可以看出,本文數(shù)據(jù)的可配置IP核具有結(jié)構(gòu)簡單及占用硬件資源適當(dāng)?shù)奶攸c,在FPGA中以實現(xiàn)高速數(shù)字信號處理,在處理速度和靈活性方面更有優(yōu)勢。隨著處理點數(shù)的增加,其優(yōu)越性將更加明顯。



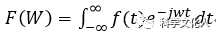

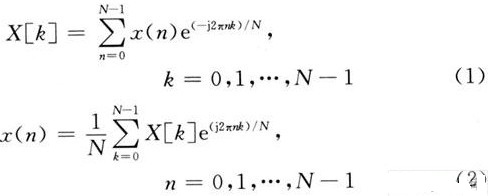
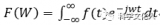






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論