 電子發燒友App
電子發燒友App


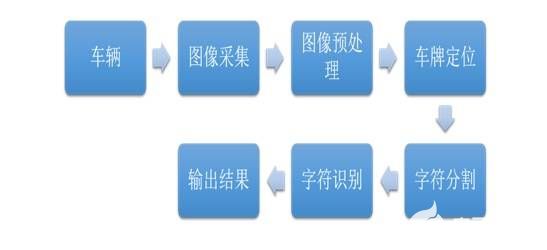
圖象處理技術在車牌識別中的應用
利用數字圖象處理技術研究開發汽車牌照自動識別系統。從汽車圖象中確定車牌位置,提取車牌字符的微結構特征,通過與所建的專用字典庫中的字符標準模板匹配比較,獲得車牌號碼。試驗結果表明該方案是有效的。???? 關鍵詞: 數字圖象處理 字符識別 車牌識別 分類匹配
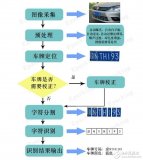
??? ? 車牌自動識別系統能將輸入的汽車圖象通過處理識別,輸出為幾個字節大小的車牌字符串,無論在存儲空間的占用上還是與管理數據庫相連方面都有無可比擬的優越性。在大型停車場,交通部門的違章監測(電子警察)、高速公路及橋梁的收費站管理等方面,有著廣泛的應用前景。
??? 1 車牌定位及預處理
?????? 將汽車圖象文件以Raw格式文件輸入計算機后,計算機將車牌部分從整幅圖象中抽取出來,實現車牌定位。設定門限值為127,設定檢測閾值為16。然后對圖象自上而下逐行掃描,若某一行的0→1和1→0變化次數大于該閾值則假設其為待測車牌最低點,繼續逐行掃描直至0→1和1→0變化次數小于8的情況出現。將該值假設為待測車牌最高點。若最高點與最低點之差大于15則認為目標已檢測到,否則繼續進行掃描。如果未檢測到符合上述條件的目標,則自動調整門限值重復以上的操作。直到找到目標為止。
??? ?? 利用二值圖象在豎直方向上的投影作為特征,從左至右尋找目標的中心點坐標。考察以前所得的目標高度作為邊長的方形窗口內的豎直方向投影之和(即所包含的象素值為1的象素點的個數),若該值小于經驗閾值(經多次試驗該閾值取為150)則視為無文字信息的背景部分,若該值首次大于閾值則視為待識車牌的左邊界部分;之后,若當投影和首次由大變小時跳出循環,則取該窗口的中點橫坐標為目標中心點。以目標中心點為基準向右,以高度為所得目標高度、寬度為30的窗口再次統計象素值為1的象素點個數,若該值首次小于經驗閾值16則視為已到目標右邊界,并取該點坐標為目標最右點的坐標。對目標最左點坐標的確定同理可得。
??? ?? 由于車牌的高寬比固定,將之作為一種目標評定標準,考慮變形因素,若高寬比不處于區間(0.2~0.6)?之內則視為無效目標,修正門限值后開始循環,最終達到邊界。
??? ?? 目標圖象預處理包括圖象平滑、字符與背景的分離、范圍調整和傾斜修正等。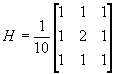
??? ?? 根據實際情況,圖象的平滑采用八鄰域平均法。所用的掩模為:
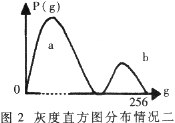
??? ?? 實現字符與背景分離所采用的門限化算法是:在有256個元素的一維整型數數組元素A[i]?中存放目標圖象中所有灰度值為i的象素點個數。比較得到在目標圖象中具有最大概率的灰度值a 。研究發現有以下兩種不同的情況,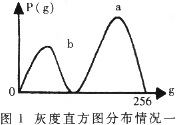 分別如圖1和圖2所示。
分別如圖1和圖2所示。
????? 對情況一,圖象信息主要位于灰度區間(0~a)之間,此時再找出灰度區間(0~b),使該區間內象素點個數占目標圖象總象素點個數的30%。取b為門限值,使灰度值大于該門限值的象素點取值為0,其他情況的象素點取值為1。對情況二同理處理。從左至右用與目標圖象等高且寬度為30的檢測窗口掃描目標圖象。考察其象素密度,當值為1的象素點個數小于50%時停止掃描。取此時檢測窗口的左坐標為目標的左邊界。目標的右邊界同理可得。根據所得車牌圖象的范圍信息,在有必要的情況下,用旋轉變換進行傾斜修正。
???  2 自動單字符列切分
2 自動單字符列切分
??? ?? 列切分是把定位后提取出的牌照圖象,切分成單個的字符圖象。字符塊在垂直方向上的投影必然在正確的分割位置上(即字符或字符內的間隙處)取得了局部最小值,且這個位置應該滿足書寫規則和字符尺寸限制。對字符圖象進行垂直方向的投影。在水平方向上從左至右檢測各坐標的投影數值。檢測到第一個投影值不為0的坐標可視為首字符的左邊界,從該坐標向右檢測到的第一個投影值為0的坐標可視為首字符的右邊界,其余字符的邊界坐標同理可得。
??? ?? 通過字符的平均字寬和兩字符左邊界之間的平均距離去除可能存在的誤分。對于字寬小于平均字寬一定比例(如0.2)的字符視為無效字符;前后兩字符距離小于平均距離且此距離與字寬之和不大于平均距離,則合并之為一個字符;對于字寬大于平均字寬一定比例(如2.4)則視為兩字符出現粘連。
??? ?? 經過上述處理可以得到準確的切分結果。將字符變換到64×64的點陣空間上,以方便進行后續特征抽取等階段的處理。
??? 3 輪廓化與細化
??? ?? 輪廓化處理采用四鄰域法,對噪聲平滑后的64×64的文字圖象F(i,j),掃描黑象素點(i,j)?的上、下、左、右四個鄰點,只要有一點不為黑,則點(i,j)?為字符輪廓上的點,置其灰度為1(即黑色),其他情況均令點(i,j)的灰度為0(即白色)。細化處理采用二次掃描細化法,該方法的速度較快,但由于是一種較為簡單的迭代算法,有時會造成一定程度的骨架形變。
 圖3(b)和圖3(c)分別給出輪廓化和細化處理后的結果。
圖3(b)和圖3(c)分別給出輪廓化和細化處理后的結果。
??? ? 4 微結構特征的提取
???? 把字符分割成n×n的網絡,對每個小網絡統計出區域筆劃的方向特征。每個小區域突出字符的局部特征,且對微小的偏移或變形不敏感。把相鄰三點形成的兩條線素定義為微結構。輪廓化后的字符,其中有十二種邊界線素的情況和字符筆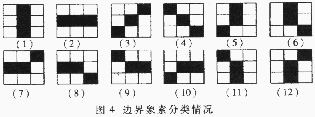 劃相關(如圖4所示)。
劃相關(如圖4所示)。
??? ? 根據字符筆劃的四個基本方向,可以相應定義水平、垂直、±45°四種線素方向。并可以統計出區域筆劃方向密度向量。
???? 把64×64的待識字符劃分為5×5的網格,前4×4的網格大小為13×13,最后一行、一列網格除最后一個為12×12外,最后一行為12×13,最后一列為13×12,統計其筆劃方向特征矢量,這樣就在每個區域上得到一個水平、垂直、+45°、-45°的四維方向特征,組成了整個字符的100維分類特征。
??? ? 所抽取特征的穩定性對識別的正確率至關重要,故在細分類中對字符進行8×8和7×7的二重分割。分別統計這64+49=113個小區域的區域筆劃方向向量(共有四個方向),組成113×4=452維的細分類特征。采用8×8的分割是為了在更小的區域內抽取更精細的結構特征。為了防止分割邊緣的不穩定,進行了7×7的二重分割,使原來最不穩定的8×8網格邊緣的筆劃處于7×7網格的中央最穩定區域,提高了區域邊緣筆劃的穩定性。
??? 5 匹配策略
??? ? 為了提高識別的準確和速度,在匹配中采用多級分類的識別方案。
??? ? 粗分類中,采用單純的區域筆劃方向特征,把字符分成5×5的網格(共25個小區域)分別統計線素的四個方向特性,構成100維(25×4)的特征向量。采用絕對值距離判別準則。設字典庫中的任一特征向量為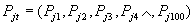 ,待識字符的特征向量為
,待識字符的特征向量為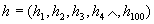 ,字典中的任意一個模板與待識字符之間的距離為dj。
,字典中的任意一個模板與待識字符之間的距離為dj。
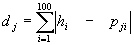
???? 在dj中選取值最小的前10個字符作為初步匹配的結果,進入下一步進行細分類。
???? 在細分類中,對候選字符通過二重分割提取452維的特征矢量作為細分類的特征。用與粗分類類似的判別準則進行第二次匹配。通過試驗確定參數,用不同的權值系數與粗分類準則結合起來決定待識字符與不同標準模板的匹配程度,取前四個作為最終結果并將其輸出到指定的文本文件之中。
??? 6 標準字典庫的建立
??? ? 字庫是在眾多字庫中擇優選取的。其中漢字從宋體字庫中選取,字母及數字從OCR-A字庫中選取。對標準字符分別進行歸一化、輪廓化和特征抽取,標準模板就是從中抽取特征得到的特征向量。
??? 7 試驗結果
??? ? 車牌定位非常理想;字符分割無誤;對漢字首字符的識別有時會出現誤識(可見漢字的識別難度較大,匹配算法和模板庫的建立方面是問題的關鍵所在);對字母及數字的識別較好;在細分類優先級的前兩級達到100%













 工商網監
工商網監
評論