 電子發(fā)燒友App
電子發(fā)燒友App


常規(guī)的SLAM算法首先假設環(huán)境中所有物體均處于靜止的狀態(tài)。而一些能夠在動態(tài)環(huán)境中運行的SLAM系統(tǒng),只是將環(huán)境中的動態(tài)物體視為異常值并將他們從環(huán)境中剔除,再使用常規(guī)的SLAM算法進行處理。這嚴重影響SLAM在自動駕駛中的應用。
MonoDOS通過兩種方式對常規(guī)SLAM進行擴展。其一,具有對象感知功能,不僅可以檢測跟蹤關鍵點,還可以檢測跟蹤具有語義含義的對象。其次,它可以處理帶有動態(tài)對象的場景并跟蹤對象運動。
但小伙伴要注意一點,并非所有OSLAM都是動態(tài)的,也不是所有動態(tài)SLAM系統(tǒng)都需要對象感知。SLAM ++?(CVPR 2013)完成了OSLAM的開創(chuàng)性工作,?但仍然需要一定的靜態(tài)場景。一些動態(tài)SLAM系統(tǒng)通過假設剛體以及速度恒定,來約束和改善姿態(tài)估計結果,但其中并沒有明確的對象概念。
動態(tài)對象SLAM的元素
DOS系統(tǒng)引入了對象的概念,這個概念具有以下幾個內(nèi)容。首先,需要從單個圖像幀中提取對象,就相當于常規(guī)SLAM系統(tǒng)中的關鍵點(例如ORB-SLAM中的ORB特征點)提取階段。該階段將給出2D或3D對象檢測結果。現(xiàn)階段單目3D對象檢測取得了很大進展。其次,它的數(shù)據(jù)關聯(lián)性更加復雜。靜態(tài)SLAM只關心圖像中的關鍵點,因此靜態(tài)SLAM的數(shù)據(jù)關聯(lián)只是關鍵幀特征向量的匹配。對于動態(tài)SLAM我們必須對幀中的關鍵點和對象之間執(zhí)行數(shù)據(jù)關聯(lián)。第三,作為傳統(tǒng)SLAM中Bundle Adjustment的拓展,我們必須為這個處理過程添加跟蹤對象(tracklet)和動態(tài)關鍵點,其次還可以利用運動模型中的速度約束。
我們制作了以下圖表來表示DOS的三個過程。綠色方框代表數(shù)據(jù)關聯(lián)過程,藍色方框代表BA過程,紅色方塊是BA調整的因子圖。
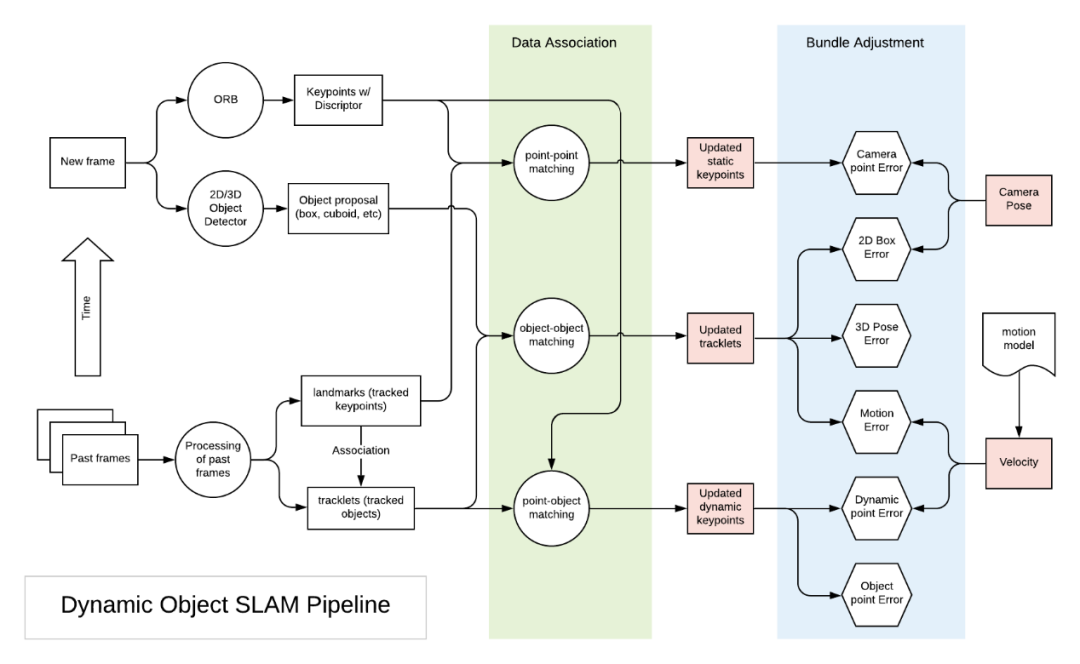
典型動態(tài)對象SLAM的處理過程
為什么需要對象檢測?
考慮到這三個基本過程,我們可以提出一個問題:為什么在SLAM中引入動態(tài)對象?首先,假定對象是具有固定形狀和大小的剛體。其次假定這些對象在物理上具有簡單且符合要求的運動模型,該模型最好可以隨時間推移進行一定的調整。因此,可以通過少量參數(shù)來描述對象大小和姿態(tài)變化。另一方面,對象的引入可以為BA調整階段提供更多的約束條件。這將提高SLAM系統(tǒng)的魯棒性。
接下來我們將介紹近些年來較為優(yōu)秀的論文,我們將介紹篇論文中上述的的三個基本過程。
CubeSLAM:單目3D對象SLAM(TRO 2019)
這篇文章可以說是DOS中最全面的了。cubeSLAM的主要貢獻之一就是巧妙地將長方體的大小和位置集成到因子圖優(yōu)化中,并使用運動模型來限制長方體的可能運動,優(yōu)化了物體的速度。在這種情況下,3D對象檢測和SLAM可以相互促進。對象為BA和深度初始化提供了幾何約束。除此之外它還增加了泛化功能,使orb slam可以在低紋理環(huán)境中工作。mono3D結果通過BA優(yōu)化,并通過運動模型進行約束。
對象提取
這篇文章將2D對象檢測和初級圖像特征點用于3D長方體的檢測和評分。看似簡單的方法對椅子和汽車的檢測都具有非常好的效果。但是基于深度學習的方法可以得到更加精確的結果。
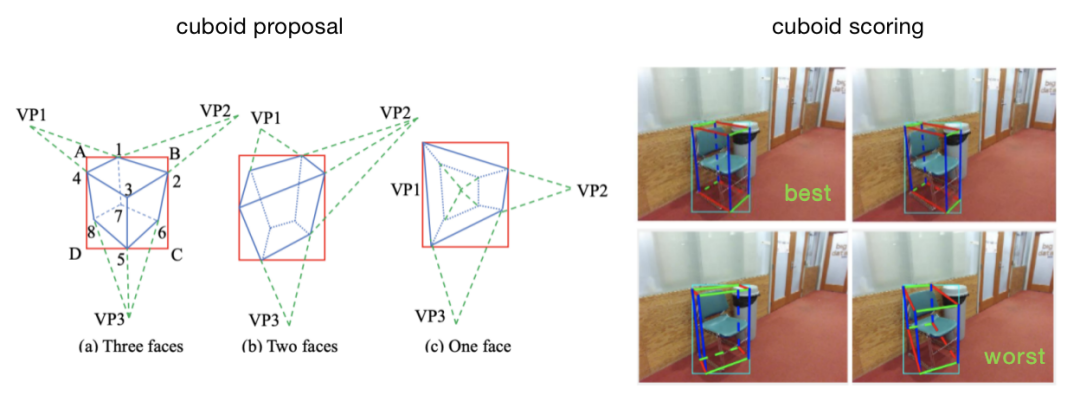
長方體對象的生成和評分
數(shù)據(jù)關聯(lián)
如概述中所述,這篇文章在多個級別上執(zhí)行數(shù)據(jù)關聯(lián),包括點-點、點-對象和對象-對象。
點-點匹配:與標準ORB-SLAM方式相同,基于orb進行特征點匹配。對于不滿足對極約束的匹配點對,我們將其歸類于動態(tài)對象。對于動態(tài)關鍵點采用稀疏光流法(KLT光流)直接對它們進行跟蹤。完成跟蹤之后,使用三角測量確定動態(tài)關鍵點的3D位置。
點-對象匹配:對于靜態(tài)關鍵點,如果它們屬于同一邊界框,則它與該對象相關聯(lián)。這里會使用多種方法來確保匹配的正確性。例如,該點在連續(xù)2幀中必須處于同一個box內(nèi),并且距長方體中心小于1米。并且框之間重疊區(qū)域中的特征點將被忽略。
對象-對象匹配:對象匹配通過關鍵點匹配間接完成。如果連續(xù)幀中的兩個對象共享最多的特征點(且超過10個),則將它們作為同一對象進行跟蹤。如果基于特征的匹配或KLT跟蹤失敗,則使用邊界框級別的可視對象跟蹤完成動態(tài)對象跟蹤。
對象感知以及BA
靜態(tài)關鍵點與攝像機位姿一起進行優(yōu)化,與ORB-SLAM一樣會存在攝像機點錯誤或重投影錯誤等問題。從每個幀中獲得對象最佳的3D位姿后,我們可以將其視為9DoF的3D“測量”,并確定BA問題。對于靜態(tài)對象,會存在以下幾種誤差。
3D相機對象誤差:跟蹤的地標對象具有6DoF姿態(tài)+ 3DoF長方體尺寸,可以將其與9DoF 3D測量結果進行比較,并形成第一個誤差項。
2D相機對象誤差:從3D測量中,我們可以將長方體的8個角投影到相機圖像中。這8個點的最小邊界框應與每幀的2d檢測邊框一致。
我們要注意到,這種2D-3D一致的假設并不總是正確。但在大多數(shù)情況下,對于自動駕駛中車載攝像頭的典型情況(水平或略微向下看)來說,這種假設可以成立。
對象點誤差:對于與框架中相關的點,它應基于長方體的中心和大小位于長方體內(nèi)。
對于動態(tài)對象,curbSLAM假定動態(tài)對象是遵循一定運動模型的剛體。這引入了兩個附加的誤差。
運動誤差:根據(jù)運動模型假設一段時間內(nèi)速度恒定,利用幀計算幀處的狀態(tài)。然后,與幀處觀察結果進行比較。請注意,這涉及為每個動態(tài)對象更新速度。
動態(tài)點誤差:如果點在動態(tài)對象上,則動態(tài)點與該對象的相對位置不會隨著時間發(fā)生改變。
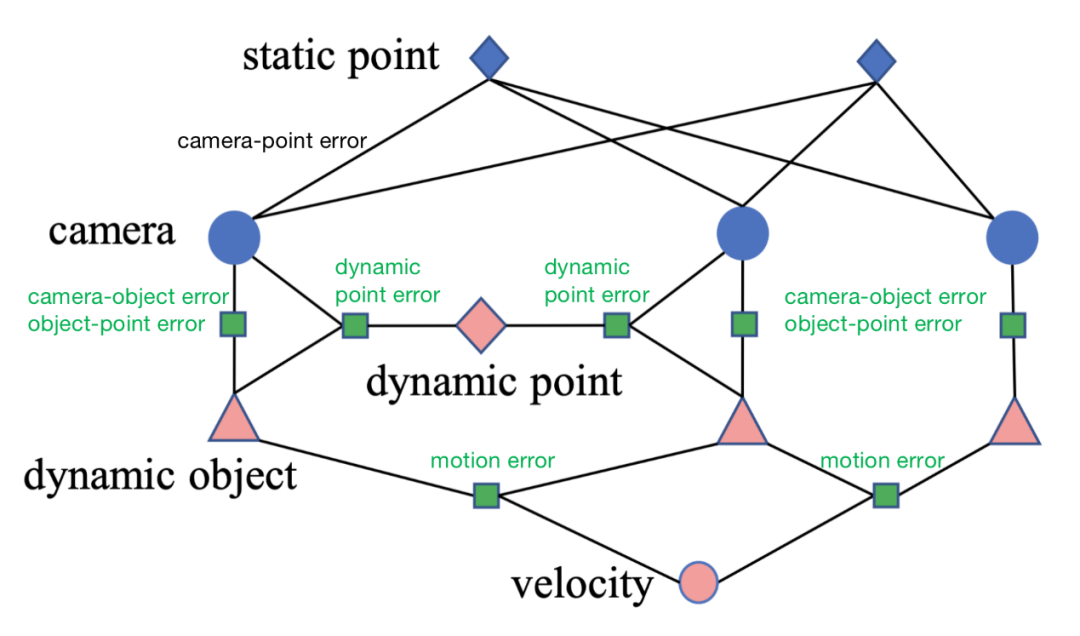
cubeSLAM因子圖(綠色方塊是與動態(tài)對象相關的誤差)
效果
CubeSLAM有一些效果相當不錯的案例,比如對于KITTI動態(tài)場景中的某些形狀大小不變是3D物體進行檢測和跟蹤。然而,SLAM的結果可能并不總是最優(yōu),因為使采用分段恒定運動假設,也可以在一定范圍內(nèi)估計動態(tài)物體的速度曲線。要注意我們在計算里程表(相機姿勢)時會考慮對象約束。
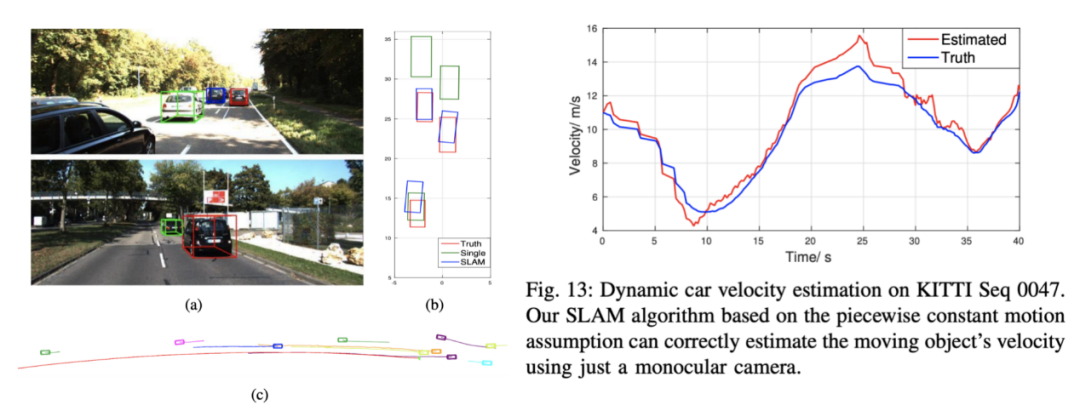
通過SLAM進行3D對象檢測、軌跡跟蹤以及速度估計
S3DOT:用于自動駕駛的基于立體視覺的語義3D對象和自我運動跟蹤(ECCV 2018)
這篇文章的研究雖然是基于立體聲視頻流的,但該框架可以擴展到單目SLAM中。這篇文章的主要貢獻是展示了利用視頻提取和跟蹤3D對象,而這些對象在單個圖像上很難檢測到。
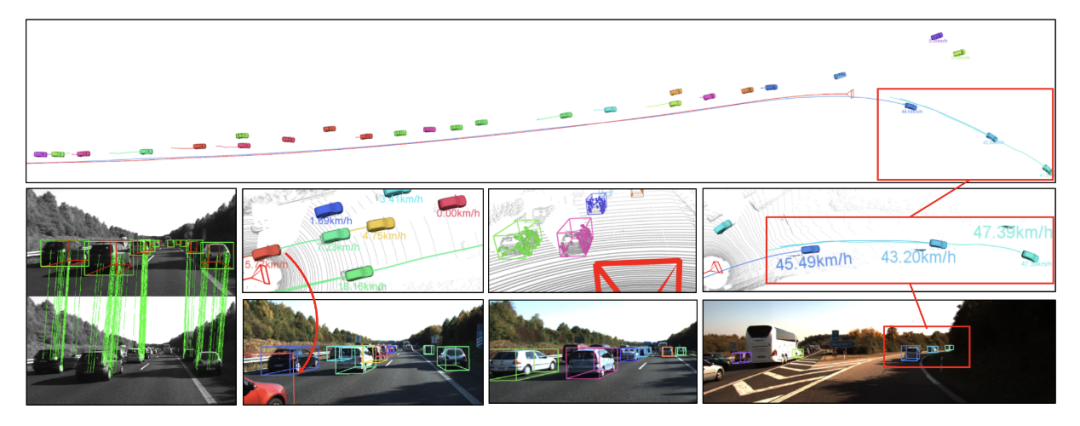
S3DOT預測極端截斷的汽車姿態(tài)、預測一致的軌道并估計被跟蹤汽車的速度
對象提取
這種對象提取方式的靈感來自Deep3DBox。它利用物體檢測得到的2D邊界框和8個視點進行分類。它使用邊界框形狀尺寸來推斷物體距離。這種方法非常通用,可以在單目環(huán)境中使用。
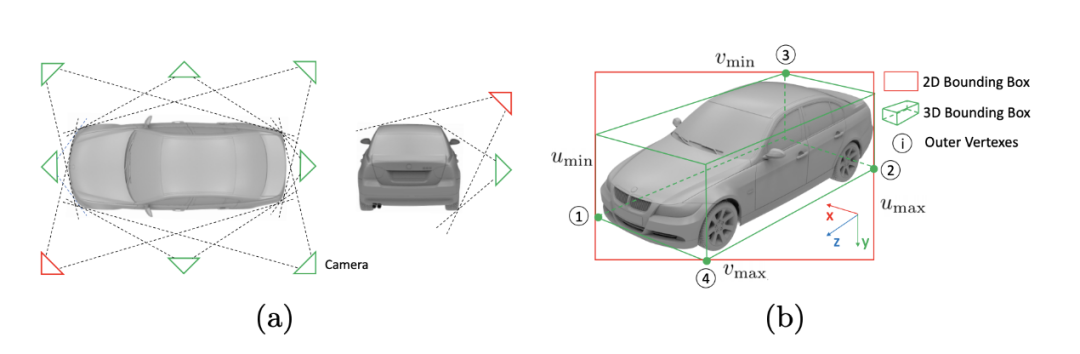
2D框+視點= 3D邊界框
數(shù)據(jù)關聯(lián)
對象-對象匹配:跨幀的2D邊界框通過相似性評分投票進行匹配。在補償相機旋轉后,相似度評分將會考慮邊界框形狀相似度以及中心距離。
點-點匹配:關鍵點與對象輪廓(凸包由2D圖像中的8個投影角對接)內(nèi)的ORB特征點匹配,同時與靜態(tài)背景匹配。
點-對象匹配:沒有明確說明,但是當一個點在該對象的對象輪廓內(nèi)時,應將其與該對象關聯(lián)。這是一種簡單的關聯(lián)策略。
對象感知以及BA
對象輪廓之外的關鍵點被視為靜態(tài)關鍵點。靜態(tài)關鍵點空間位置和攝像機位姿求解同ORB-SLAM一樣,通過優(yōu)化解決。獲得相機位姿(或運動)后,便可以解決了對象位姿問題。動態(tài)對象BA具有以下四個誤差項。
動態(tài)點(稀疏特征)誤差:剛性對象上的特征點在對象框架中具有固定坐標。
2D相機對象誤差:跟蹤對象的投影應滿足2D測量結果。
對象尺寸一致性誤差:對象形狀在框架之間保持一致。這是cubeSLAM中3D 相機對象誤差的一部分。
運動誤差:預測的位姿應該與圖像幀中的3D位置保持一致。通過運動學模型可以進行運動估計。它涉及車輛的3維位置,速度,轉向角。
動態(tài)點云對準誤差:在將上述誤差最小化之后,我們基于先驗尺寸獲得了物體姿態(tài)的MPA估計。為了糾正先驗中偏差,這里將3D長方體與跟蹤的點云對齊。
效果
S3DOT同樣也有不錯的效果,該結果可以在KITTI的動態(tài)場景中檢測和跟蹤3D對象。但是我們要注意,這里在計算相機姿勢時不會考慮對象約束。
ClusterVO:對移動實例進行聚類并估算自身和周圍環(huán)境的視覺里程計(CVPR 2020)
ClusterVO通過將對象表示為跟蹤的關鍵點(或本文中的地標)的群集,提出了一種更通用的動態(tài)SLAM算法。
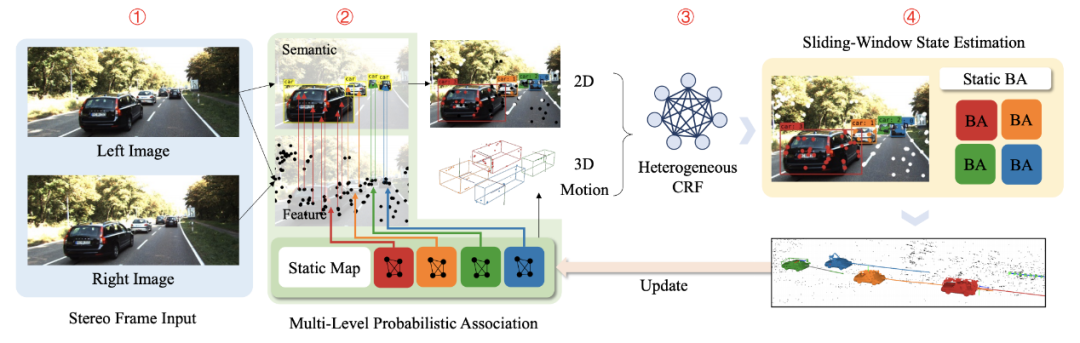
ClusterVO的總體流程
對象提取
ClusterVO使用YOLOv3作為2D對象檢測器,為每個幀中的對象提出語義2D邊界框。它不對描述對象進行假定。因此,相較于上述兩篇文章沒有長方體的產(chǎn)生階段。
數(shù)據(jù)關聯(lián)
ClusterVO數(shù)據(jù)關聯(lián)方法相當復雜,由兩大步驟組成。其一是多級概率關聯(lián),即將觀察到的關鍵點與跟蹤的地標相關聯(lián),并將邊界框與跟蹤的聚類相關聯(lián)。其二是異構CRF,該CRF將跟蹤的地標與跟蹤的聚類相關聯(lián)。
點-點匹配:屬于多級概率。描述符匹配對于靜態(tài)關鍵點可能效果很好,但對于動態(tài)關鍵點的效果則可能很差。因此,首先以其預測每個群集的位置、速度(僅線性,無旋轉)。如果觀測點在經(jīng)過運動預測后地標的投影范圍內(nèi),那么關鍵點觀察值與地標相關的概率與描述符相似度成正比。
對象-對象匹配:同樣屬于多級概率。如果邊界框m包含來自群集的最多投影點,則它將與該群集q(對象)相關聯(lián)。
點-對象匹配:這是最復雜的部分,并且使用了異構條件隨機場(CRF)。它確定界標是否與聚類相關聯(lián)。它具有多個能量項。一元能量項包括2D能量(如果點在與群集關聯(lián)的邊界框內(nèi),則它與該簇關聯(lián)的可能性很高。如果該點在多個邊界框內(nèi),則可以分配給多個群集)、3D能量(一個點與簇相關的可能性更高,如果該點靠近簇的中心,則由簇的大小進行調制)和運動能量(地標的投影可以通過群集的運動來解釋)。如果成對標簽平滑度能量項與附近的地標相關聯(lián),則會造成不利影響。
對象感知以及BA
在概率數(shù)據(jù)關聯(lián)之后,我們可以為靜態(tài)場景和動態(tài)聚類制定BA。這里使用專門設計的雙軌滑動窗口來管理關鍵幀。
相機點誤差:對于靜態(tài)場景,clusterVO與ORB-SLAM相似,可以同時優(yōu)化相機位姿和靜態(tài)關鍵點的位置。當clusterVO選擇滑動窗口狀態(tài)估計方法時,它還會增加一個附加的邊緣化項。此邊緣化項捕獲了觀測結果,由于滑動窗口的寬度有限,這些結果將被刪除。
運動誤差:運動方程預測得到的位姿應該與從單個幀求解處的3D測量值一致。這里采用的運動模型通過高斯過程采樣得到,且這個運動模型具有加速度。
動態(tài)點誤差:clusterVO也具有動態(tài)點錯誤,類似于cubeSLAM和S3DOT。如果點在動態(tài)對象上,則其在動態(tài)對象中的相對位置將隨時間而固定。
效果
ClusterVO是一種更通用的DOS方法。從KITTI動態(tài)場景的結果來看,用長方體近似得到的的結果質量不如ClusterVO。對于自動駕駛,CubeSLAM和S3DOT似乎更實用。我們還要注意,優(yōu)化里程計(相機位姿)時會考慮對象約束。
MoMoSLAM:用于動態(tài)環(huán)境的多對象單目SLAM(IV 2020)
“多體單目SLAM”的概念似乎來自“ 多體SfM ”,但其本質上與動態(tài)對象SLAM具有相同的含義。
對象提取
MoMoSLAM使用了非常復雜但準確的3D對象提取過程。使用形狀先驗和關鍵點將2D檢測提升為3D形狀。首先檢測車輛可區(qū)分特征上的36個有序關鍵點,并檢測一系列基本形狀的變形系數(shù)。然后,通過最小化重投影誤差將2D檢測提升為3D,以獲得6個DoF姿態(tài)和形狀參數(shù)。這種方法與RoI -10D(CVPR 2019)非常相似。
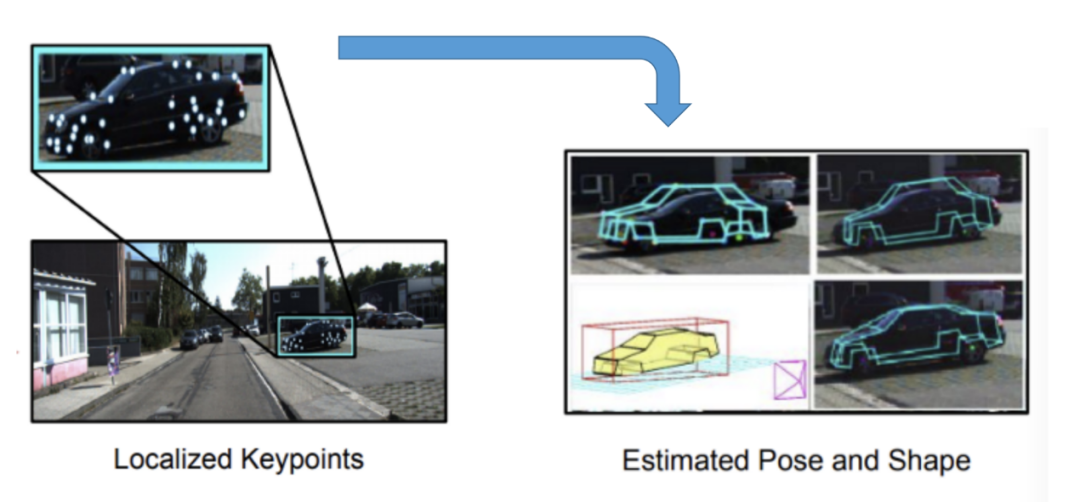
從2D關鍵點到3D形狀
數(shù)據(jù)關聯(lián)
點-點匹配:基于描述符特征的關鍵點匹配,類似于ORB-SLAM。
對象-對象匹配:本文沒有明確提及,但對象與對象之間的匹配是必須的,任何2D對象跟蹤方法都可以使用。
點-對象匹配:未使用,通過檢測每個幀中每個對象的語義關鍵點來間接完成。
對象感知以及BA
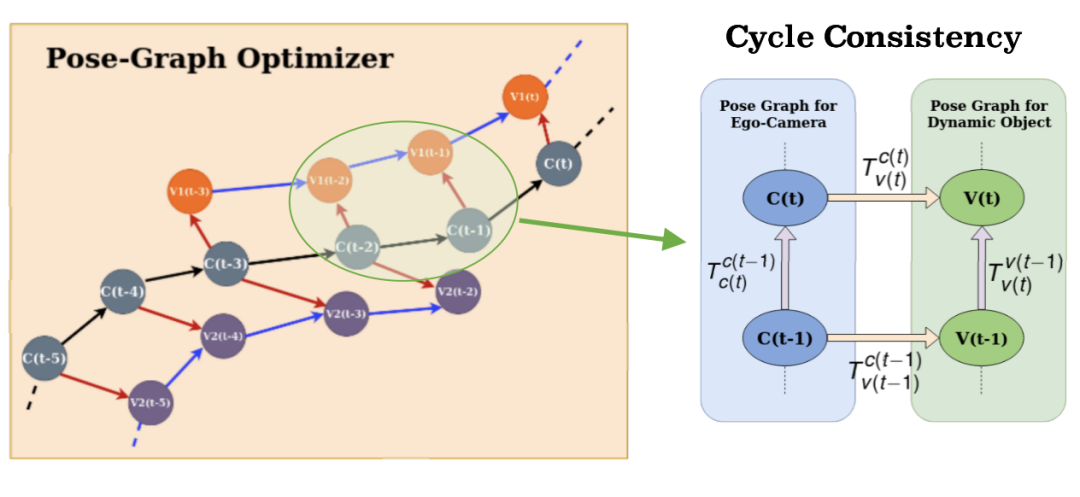
相機-對象姿態(tài)圖和循環(huán)一致性
MoMoSLAM使用了不同的優(yōu)化公式。如上所述,MoMoSLAM沒有指定每個誤差項并使它們最小化,而是對位姿圖中創(chuàng)建的每個循環(huán)強制執(zhí)行一致性處理。但從本質上講,這應等效于平方誤差的最小化。
相機點誤差:與ORB-SLAM相同。由于單眼圖像的比例尺模糊,因此里程表按比例縮放。使用反透視映射(IPM)對地面區(qū)域進行語義分割并在該區(qū)域中進行特征點匹配,以估計3D深度,以此固定比例因子,并用于里程計中。
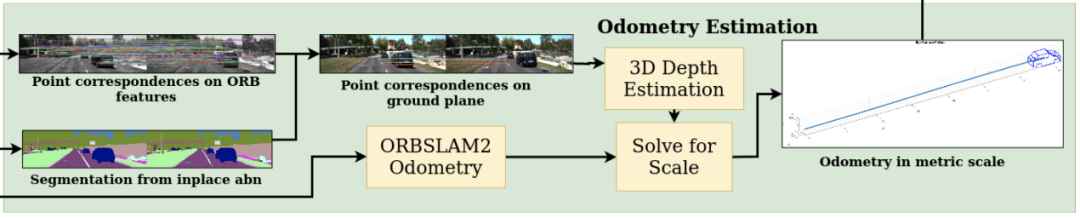
MoMoSLAM的公制里程估算
多對象姿態(tài)圖循環(huán)一致性誤差:姿態(tài)圖中的節(jié)點為估計,姿態(tài)圖中的邊為度量。相機-相機邊緣是通過公制標度里程限制的。攝像機車輛的邊緣通過2D到3D單幀提升來約束。車輛邊緣通過兩種不同的3D深度估算方法(IPM與2D到3D提升)進行約束。但這里沒有顯式運動模型。
我覺得周期一致性存在人為的影響,尤其是車輛邊緣。添加一個錯誤項以優(yōu)化IPM并提升2D到3D之間的距離估計一致性會更加直接。
效果
MoMoSLAM在固定單目度量標準的情況效果較好。這里在計算測距(相機姿勢)時不會考慮對象約束。
總結
DOS將對象檢測和跟蹤功能添加到3D SLAM中,并將對象的位姿和大小添加到后端優(yōu)化中。
CubeSLAM和ClusterVO共同優(yōu)化了相機姿態(tài)和物體姿態(tài)。恒定的對象大小和剛體運動作為附加約束可用于圖優(yōu)化。這將有助于在特征點較少的環(huán)境中計算相機姿態(tài)。相比之下,S3DOT和MoMoSLAM將在ORB-SLAM失敗的情況下失敗,因為它們依賴ORB-SLAM進行相機姿態(tài)計算。
CubeSLAM和S3DOT將對象視為長方體,在自動駕駛中更為實用。盡管ClusterVO非常通用,但是它并沒有運用先驗知識,因此缺乏在3D對象檢測中實現(xiàn)SOTA性能的潛力。
當無法獲取全球位置信息時,CubeSLAM似乎是在自動駕駛中執(zhí)行VIO的很好的選擇。
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論