 電子發(fā)燒友App
電子發(fā)燒友App


摘要
現(xiàn)代汽車使用先進的電子系統(tǒng)來幫助駕駛員完成駕駛過程,即所謂的高級駕駛員輔助系統(tǒng) (ADAS)。ADAS系統(tǒng)用于自動化、定制和改進車輛內(nèi)的系統(tǒng),以實現(xiàn)更高的安全性和更好的駕駛體驗。由于ADAS系統(tǒng)本身會對駕駛過程、車輛和駕駛員產(chǎn)生重大影響,因此必須在許多行業(yè)標準范圍內(nèi)對其進行徹底測試和開發(fā)。他們工作的關鍵因素是各個系統(tǒng)組件之間的通信。這種標準化的通信是測試所必需的,通常通過開發(fā)汽車開放系統(tǒng)架構(gòu) (AUTOSAR) 通信測試來執(zhí)行。由于ADAS測試可能是一個相當復雜和耗時的過程,因此自動測試是在一個適當?shù)臏y試環(huán)境中進行的。本文介紹了現(xiàn)有的ADAS環(huán)境測試系統(tǒng),它為AUTOSAR架構(gòu)的中間層(Middleware)中的通信仿真生成了一個測試環(huán)境。測試環(huán)境生成器(TEG)是一個用于處理ARXML測試文件的Python程序,在此基礎上,它以C編程語言的獨立組件的形式生成測試環(huán)境模型。該程序包括輸入數(shù)據(jù)解析、解析數(shù)據(jù)存儲和構(gòu)建測試環(huán)境的組件生成。根據(jù)檢測到的現(xiàn)有TEG的缺點,提出了一些修改意見,以加快其執(zhí)行時間,并以數(shù)據(jù)庫的形式引入更強大和穩(wěn)定的數(shù)據(jù)存儲方法。
I.簡介
ADAS系統(tǒng)是協(xié)助司機駕駛車輛的電子系統(tǒng)。ADAS系統(tǒng)可以直接影響汽車的一些部件,目的是為了從完成更安全和更舒適的駕駛的角度開發(fā)各種有用的功能:從自動點火燈和交通標志識別到與智能手機的整合。ADAS通信系統(tǒng)運行的一個關鍵因素是其組件之間的通信。利用該傳感器,汽車的計算機系統(tǒng)接收有關汽車周邊環(huán)境的信息,即感知環(huán)境。這些傳感器是激光雷達、雷達、照相機和超聲波傳感器等。傳感器提供的信息由適當?shù)?a target="_blank">算法處理,并獲得所需的輸出:自動剎車、根據(jù)檢測到的限速標志對車輛進行減速、司機監(jiān)控、交通線檢測和警告司機越線,等等。由于ADAS系統(tǒng)本身會對交通、車輛和駕駛者本身產(chǎn)生重大影響,它們必須經(jīng)過詳細的測試并適應嚴格的標準。在 ADAS 中實施的軟件系統(tǒng)必須結(jié)構(gòu)穩(wěn)健且能夠適應變化,具有標準化的代碼慣例,最重要的是,其測量和結(jié)果必須保持一致。
需要對標準化的通信進行測試,最好是在系統(tǒng)內(nèi)開發(fā)測試代碼,以測試AUTOSAR的通信模型。AUTOSAR是一個由汽車公司組成的國際伙伴關系,其目的是在汽車開發(fā)環(huán)境中的軟件和硬件架構(gòu)創(chuàng)建中引入標準化。該測試環(huán)境允許在汽車計算機系統(tǒng)上工作的工程師能夠?qū)崿F(xiàn)流程和程序的自動化,否則由于物流和時間的限制,這些流程和程序是不可能人工完成的。它還允許他們對系統(tǒng)進行壓力測試,而不必使用實際的組件并冒著失敗的風險。一個高質(zhì)量的測試環(huán)境是至關重要的,因為不正確的汽車部件模擬或不正確的數(shù)據(jù)處理會導致代碼在實際執(zhí)行中出現(xiàn)災難性的故障。因此,模擬測試環(huán)境是一個細致和耗時的過程,但對于開發(fā)ADAS系統(tǒng)是必不可少的。
本文對測試ADAS系統(tǒng)的軟件解決方案進行了升級,重點是通信。所提出的解決方案使用創(chuàng)建的發(fā)生器和測試環(huán)境來測試汽車中或 ECU 的 CPU 內(nèi)部的控制單元之間的通信。所提出的解決方案是基于加速現(xiàn)有的測試環(huán)境生成過程的方法,主要是在多個計算機進程中同時分配程序工作,但也可以使用在多個程序運行中消除冗余的解決方案。因此,增強的程序允許在現(xiàn)代多核處理器上對程序的整體運行進行多重加速,并能夠跳過部分程序以節(jié)省時間。
本文由五部分組成。第 2 節(jié)介紹了現(xiàn)有的測試環(huán)境生成器 (TEG) 及其實現(xiàn)方法。第 3 節(jié)中給出了對現(xiàn)有 TEG 的改進建議的詳細信息。第 4 節(jié)介紹了使用改進后的 TEG 獲得的結(jié)果,并附有討論。最后給出了結(jié)論和對未來工作的建議。
II.測試環(huán)境生成器
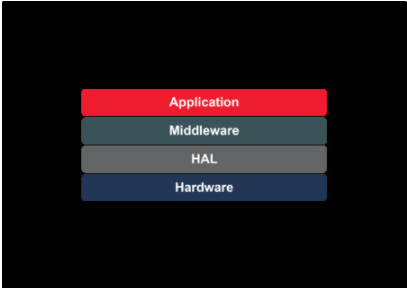
用于汽車測試的測試環(huán)境生成器是基于AUTOSAR環(huán)境,有助于測試汽車系統(tǒng)和部件之間的通信。AUTOSAR采用三層架構(gòu):
基礎軟件:一套標準化的軟件模塊,包含操作頂層、應用層所需的服務。
RTE:用于交換信息的中間層,即基礎層和應用層之間的通信。
應用層:與 RTE 通信的應用軟件組件。
TEG位于AUTOSAR通信的中間層。輸入端的 TEG 收集特定 ECU 的信號數(shù)據(jù),并以此為基礎在輸出端生成通信環(huán)境模型。本節(jié)更詳細地描述了 TEG 的工作。更確切地說,本節(jié)分析了一個具體的現(xiàn)有解決方案,并在隨后的章節(jié)中提出了修改意見。
A. 基于AUTOSAR的通信
ARXML(AUTOSAR XML)是一種特殊類型的XML文件,專門用于汽車開發(fā)環(huán)境,用于存儲有關所使用的通信輸入和輸出的數(shù)據(jù)、發(fā)送的數(shù)據(jù)包和處理這些數(shù)據(jù)的軟件組件。ARXML模式是XML數(shù)據(jù)語言的特殊定義,用于交換AUTOSAR通信模型,其中包含信號類型、組件和輸入輸出端口信息。它是一個W3C矩陣,定義了AUTOSAR模型交換的語言。該矩陣源于AUTOSAR的主要描述性模型,并定義了AUTOSAR的數(shù)據(jù)交換格式。
ARXML 文檔表示單個 ECU 的配置,該ECU解釋了它使用的原始數(shù)據(jù)類型。它代表了每個ECU在兩個或多個ECU之間通信時使用的特定端口、軟件組件和信號。因此,ARXML定義了特定ECU通信所需的所有數(shù)據(jù)類型,從基本類型(int, float, string)到更復雜的類型(list, objects)。使用基本類型,ARXML以信號和發(fā)送這些信號的相關端口的形式建立了一個通信的數(shù)據(jù)模型。它還包含了進一步處理數(shù)據(jù)所需的軟件組件清單。
ECU ARXML 文件是深度 XML 文件,其大小可能因 ECU 和應用程序而異,從幾千字節(jié)到幾百兆字節(jié)不等。這些文件中的數(shù)據(jù)從原始數(shù)據(jù)類型開始描述,然后ARXML 中的所有其他數(shù)據(jù)定義都引用到這些原始數(shù)據(jù)類型。
B. 測試環(huán)境發(fā)生器的工作原理
為了使用從ECU收集的信息來測試ECU模型,有必要將信號和通信分解成有意義的單元和軟件組件(SWC)之間的關系,在此基礎上可以生成一個測試環(huán)境。這就是 TEG 的任務。來自ARXML的分類數(shù)據(jù)首先被收集在一個復雜的數(shù)據(jù)結(jié)構(gòu)中,該結(jié)構(gòu)是在程序環(huán)境中創(chuàng)建的。所創(chuàng)建的結(jié)構(gòu)比.arxml文件的訪問速度更快,它形成了一個內(nèi)部數(shù)據(jù)源,需要識別特定的代碼,這些代碼需要注入到共同構(gòu)成模型的軟件組件(SWC)的特定和預先確定的代碼片段中。在TEG的輸入文件中,有一個包含模板的.c文件,這些模板被輸送到由特定ECU配置預定義的SWCs中 。根據(jù)從ARXML文件中收集的數(shù)據(jù),確定必要的模板(具體到每個SWC),然后將變量和值添加到SWC的模板中。
C. 現(xiàn)有解決方案的架構(gòu)
現(xiàn)有的測試環(huán)境生成器有一個解析的文件結(jié)構(gòu),程序代碼與生成的數(shù)據(jù)、數(shù)據(jù)庫和輸入分開。每次TEG運行時,它都會檢查相應的.ini文件中配置的文件結(jié)構(gòu)的布局。生成器代碼本身被分成幾個相關的函數(shù),構(gòu)成了前面提到的實體,并以Python編程語言實現(xiàn)。ython 2.7 版與其標準庫一起使用,并帶有一個用于解析 XML 和結(jié)構(gòu)相似的文件類型的附加模塊 - LXML。解析后的數(shù)據(jù)存儲是通過Python的標準Pickle模塊完成的,隨同生成的XML用于對解析后的數(shù)據(jù)的修訂。程序生成器的組件使用存儲的數(shù)據(jù)將代碼片段放置在的用 C 編程語言編寫的主 .c 文件中的模板中指定位置 (較小的C類文件,代表構(gòu)成模型的組件)。然后,同樣的代碼被TEG再次傳遞過去,特定的變量或數(shù)值被放入片段中。因此,TEG被分為三個主要部分:
1) 解析器
解析器的目的是提取特定ECU的配置數(shù)據(jù),在此基礎上生成模型。解析器接收.arxml文件形式的數(shù)據(jù),瀏覽其結(jié)構(gòu),并將解析后的數(shù)據(jù)以復雜的數(shù)據(jù)結(jié)構(gòu)形式存儲,并在整個TEG中進一步使用。現(xiàn)有的TEG的核心組件是一個高度復雜的Python對象,它由結(jié)構(gòu)化的預定義類的模板初始化,這些模板都相互引用并形成底層對象,即所謂TOM。TOM反映了ARXML的層次結(jié)構(gòu),它從層次結(jié)構(gòu)中最高的對象開始,稱為根--TOM根。TOM根,連同ARXML文件的位置,被作為參數(shù)傳遞給解析函數(shù),該函數(shù)迭代地通過ARXML中的所有數(shù)據(jù),并通過邏輯分支將它們存儲在TOM子對象中。TOM的架構(gòu)與ARXML的架構(gòu)密切相關,它限制了解析器在XML格式中的順序傳遞,使其速度變慢,因為ARXML架構(gòu)需要由Python架構(gòu)紀實地表示出來,而且隨著ARXML文件越來越大,這一任務會成倍增加。
當所有來自ARXML的相關數(shù)據(jù)被傳輸?shù)絋OM Root時,解析器的操作就被認為是完成了,然后TOM Root被存儲在RAM中供將來參考。
2) 數(shù)據(jù)存儲
從.arxml文件解析出來的數(shù)據(jù)被儲存起來,以便在出現(xiàn)錯誤或調(diào)整時進一步檢查輸入數(shù)據(jù)的有效性,并作為備份。收集的數(shù)據(jù)代表了TEG的生成器組件進一步運行所需的所有數(shù)據(jù)。
TEG的現(xiàn)有解決方案依賴于用于序列化存儲的標準Python模塊--Pickle。存儲函數(shù)在解析器函數(shù)之后啟動,并接收TOM Root和所需的.pickle文件的存儲位置作為參數(shù)。有了這個功能,整個TOM Root被序列化為上述文件,即使在執(zhí)行程序后,該文件仍被永久存儲在輸出目錄中。
除了pickle功能外,TOM Root還以復雜的XML格式存儲,作為一個次要的、更容易被人閱讀的來源。這樣做的目的是為了更容易調(diào)整程序,也更容易排除潛在的錯誤。XML存儲功能,很像一個解析器,使用邏輯分支和遞歸,將TOM內(nèi)容解析為鏈接的XML部分。XML文件也是用LXML模塊生成的。
3) 代碼生成器
從.arxml文檔中解析出來的數(shù)據(jù)被注入到模板和軟件組件中實現(xiàn)的C代碼的特定切口中,同時還有變量的相應值。
測試代碼生成函數(shù)接收 TOM Root 和主 .c 文件的位置作為參數(shù),其中包含模板和所需的 SWC 組件,也是 .c 文件的形式。它使用正則表達式(RegEx)方法將TOM數(shù)據(jù)邏輯地過濾成上述模板,即代碼片斷。然后將模板插入到SWC .c文件中預定義的位置。
發(fā)電機操作是迄今為止要求最高的TEG組件,其運行時間取決于輸入文件的大小。生成器還被設計為在組裝模型組件時按順序使用RegEx,因為輸入量增加,這對程序性能(就時間而言)產(chǎn)生了負面影響。
III.測試環(huán)境生成器的改進
本文的基本目的是加速現(xiàn)有的TEG。隨著輸入數(shù)據(jù)的增加,整個程序的執(zhí)行時間會明顯增加,這是一個實際問題。此外,目標是創(chuàng)造一種更穩(wěn)定的數(shù)據(jù)庫存儲形式,而不是將數(shù)據(jù)序列化作為一種存儲方法。具體來說,對升級版的TEG的要求是:
加速現(xiàn)有的TEG,使其在解析和生成輸出文件方面花費更少的時間。
利用更穩(wěn)定和透明的存儲方法。
擬議的解決方案是通過對現(xiàn)有解決方案實施代碼更改來實現(xiàn)的。
這些變化是針對程序的每一部分的,但其結(jié)構(gòu)和執(zhí)行順序保持不變。因此,提議的解決方案使用Python 2.7。TEG在啟動時檢查.ini配置文件,該文件包含一個獨特的哈希字符串,代表其中的文件結(jié)構(gòu)。TEG的主要組件,即解析器,以同樣的方式運行--通過ARXML的可選Python LXML解析器模塊。ARXML被解析成一個初始化的TOM--底層對象。然后Python多處理模塊同時將TOM發(fā)送給生成器,并使用Python SQLite模塊存儲在SQL數(shù)據(jù)庫中。生成器收到TOM后,通過一個新的多進程實例,在多個進程中同時生成SWC。當在一個相同的數(shù)據(jù)集上遞歸運行TEG時,TEG有能力跳過解析過程以節(jié)省時間。
A. 加速
由于ARXML文件的結(jié)構(gòu)和底層對象的TOM結(jié)構(gòu),如果不徹底重組整個現(xiàn)有的解決方案,就不可能對解析器的操作進行重大改變以加速它。然而,開發(fā)了一種加速整個TEG運行的方法--更具體地說,就是完全避免運行解析器,以節(jié)省整個程序運行時間的形式。
加速是通過驗證新版本TEG的結(jié)構(gòu)與寫入數(shù)據(jù)庫文件的最后一個結(jié)構(gòu)來實現(xiàn)的,這允許程序跳過冗余解析操作。為此使用了一個標準的 Python hashlib 模塊。
還有一個問題是,生成器內(nèi)部的累積操作會大大降低TEG的執(zhí)行速度,特別是在數(shù)據(jù)量增加的情況下。顯然,加速進程的最直接方法是將現(xiàn)有的算法進程劃分給更多的處理器核心,從而利用現(xiàn)代硬件架構(gòu)。通過使用多個進程,預計TEG的執(zhí)行速度將大大加快,因為生成器是TEG中最耗時的部分。
因此,實現(xiàn)了Python的多進程模塊,它將一個或多個函數(shù)的操作分解成多個進程。該解決方案將每個SWC分離成多個并發(fā)的進程。SWC根據(jù)計算機上可用的核心總數(shù)來分配計算機核心。來自主C文檔的片段或模板使用正則表達式作為組件并行輸入,然后與特定 ECU 相關的值也輸入到預先批準的位置。
B. 儲存
數(shù)據(jù)序列化被關系數(shù)據(jù)庫所取代。關系數(shù)據(jù)庫是基于關系數(shù)據(jù)模型的。在關系數(shù)據(jù)模型中,數(shù)據(jù)被表示為N對分組的表,即關系。因此,關系數(shù)據(jù)模型中的每一個n對實際上是一個表中的一行,有一定數(shù)量的命名列,代表了存儲在表中的對象的屬性名稱。管理關系型數(shù)據(jù)庫的系統(tǒng)被稱為RDBMS(Relational Data BaseManagement System)。本文采用SQLite作為關系數(shù)據(jù)庫。SQLite允許我們使用Python命令來創(chuàng)建、寫入、交互和刪除SQL數(shù)據(jù)庫。存儲在SQLite文件中的數(shù)據(jù)庫很容易被移動,因為它只是一個文件,通常非常小,并且獨立于其他外部庫和程序。此外,SQLite很容易獲得(開放源碼),而且非常流行,這意味著強大的軟件支持。
在運行SQLite數(shù)據(jù)庫的存儲函數(shù)之前,現(xiàn)有TEG解決方案的父數(shù)據(jù)庫功能用代表TOM Root的初始表創(chuàng)建了數(shù)據(jù)庫的基礎。數(shù)據(jù)存儲函數(shù)接收參數(shù)Tom Root、初始表和文件系統(tǒng)中的數(shù)據(jù)庫位置。該函數(shù)依次通過TOM中的每個對象,分別驗證每個單獨的屬性。最初,每個屬性通過一個邏輯過濾器來檢測拋出的錯誤(錯誤的數(shù)據(jù)類型、語法錯誤、空白數(shù)據(jù))。然后,通過邏輯分支,確定它們是否是基本數(shù)據(jù)類型(整數(shù)、浮點數(shù)、字符串、長)、不可變的n元組列表、數(shù)據(jù)集還是嵌套對象。在第一種情況下,當前表中的數(shù)據(jù)庫(與對象共享名稱)會創(chuàng)建一個新的列(如果當前不存在此列)。對于數(shù)據(jù)集、列表和嵌套對象,則啟動一個遞歸函數(shù),在一個單獨的循環(huán)中存儲數(shù)據(jù)。然后,該函數(shù)接收要進入遞歸的對象、它的表以及它將通過外鍵引用的父對象的表,作為參數(shù)。因此,數(shù)據(jù)存儲函數(shù)遞歸地遍歷整個TOM,并將其內(nèi)容存儲在一個復雜的關系數(shù)據(jù)庫中。
在ARXML標準中,組件名稱經(jīng)常重復。由于這個原因,在創(chuàng)建表名時,由于SQL的特殊性,不允許兩個表有相同的名字,因此在每個表上都加了一個數(shù)字前綴,以避免由于表名相同而產(chǎn)生的錯誤。在每次創(chuàng)建新表時,通過移動整數(shù)類型變量可以獲得前綴,對于TOMRoot表來說,是從零開始的。哈希字符串也被存儲在數(shù)據(jù)庫中,以避免遞歸運行TEG時的冗余。對數(shù)據(jù)庫的寫入是與生成器的操作同時進行的。
IV.成果與討論
根據(jù)本文框架內(nèi)的變化或改進,包括多處理的邏輯、處理現(xiàn)有功能的邏輯、覆蓋程序中的現(xiàn)有步驟以及過渡到存儲相同數(shù)據(jù)的不同形式,有必要以下列方式檢查改進:
驗證在SQLite數(shù)據(jù)庫中傳輸?shù)臄?shù)據(jù)記錄是否正確,以及
測量改進后的的TEG的性能速度,并與現(xiàn)有的解決方案進行比較。
對現(xiàn)有的和升級后的測試環(huán)境發(fā)生器的所有測試都是在同一數(shù)據(jù)集上進行的,其執(zhí)行形式是兩個5.2和5.6MB的.arxml文件,同時進行處理。
測試是在一臺運行Windows 10、Python 2.7版本的計算機上進行的,硬件規(guī)格見表1。
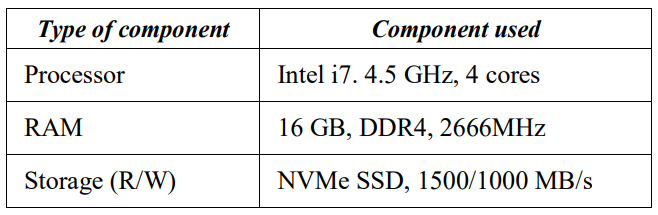
表I. 測試計算機硬件規(guī)格
A. 使用的測試描述
對SQLite數(shù)據(jù)庫中傳輸數(shù)據(jù)的正確性的驗證是通過手動比較從數(shù)據(jù)庫傳輸?shù)缴善鞯膬蓚€測試可用的值,可以對SQLite數(shù)據(jù)庫中傳輸數(shù)據(jù)的正確性進行驗證。生成器代碼輸入臨時函數(shù),打印它在一個單獨的日志文件中所傳遞的所有數(shù)值,用于現(xiàn)有和新的解決方案,然后進行比較以確定有效性。
TEG加速性能的驗證是通過一個單獨的Python模塊完成的,該模塊在Windows命令行中列出了TEG各個部分(解析器、基礎程序、生成器)的執(zhí)行時間和總運行時間。時間以hss.ss的格式表示。使用一個標準的Python時間模塊來處理測量。
B. 有效性測試的結(jié)果
由于SQLite數(shù)據(jù)庫由填滿數(shù)據(jù)的表和列組成,而Pickle數(shù)據(jù)只是TOM代碼的序列化形式,因此不可能直接比較兩種解決方案的內(nèi)容。因此,需要在TEG操作的下一步中進行比較,在不同的TEG版本之間匹配隨機選擇的存儲數(shù)據(jù)。
通過測試,發(fā)現(xiàn)現(xiàn)有的解決方案需要大量的時間(超過6小時),并進一步解釋了為什么本文的任務完全集中在時間性能上。
C. SQL數(shù)據(jù)庫設置排列的效果測量
在制作SQLite數(shù)據(jù)庫時,可以采取一定的安全措施來影響速度,但也可以影響他們所做的數(shù)據(jù)庫的寫入或讀出的質(zhì)量。在SQLite Python模塊中,可以使用獨特的PRAGMA語句來影響這些措施。PRAGMA作為關鍵詞被調(diào)用,緊隨其后的是要改變的數(shù)據(jù)庫設置,然后是新的數(shù)值。以下測量有三種排列方式:
標準SQL數(shù)據(jù)庫設置
同步查詢寫入數(shù)據(jù)庫(SYNCHRONOUS)
在數(shù)據(jù)庫中保存記錄的日志(JOURNAL_MODE)
1) 標準設置
使用激活同步寫入和日志記錄的標準設置進行第一次測量。一個完全優(yōu)化的SQLite數(shù)據(jù)庫的標準設置將TEG的執(zhí)行時間增加至11分鐘到12分鐘,而使用Pickle序列化的現(xiàn)有解決方案,其性能只持續(xù)了幾秒鐘(與程序的生成器部分并行工作)。
2) 同步關閉
在接下來的實驗中,禁用對數(shù)據(jù)庫的同步寫入要求,寫入工作由操作系統(tǒng)負責。這種方法極大地提高了每秒查詢的速度,但可能會發(fā)生數(shù)據(jù)日志錯誤,影響數(shù)據(jù)庫的穩(wěn)定性。誠然,在測試過程中沒有觀察到記錄中的錯誤,或改變這個度量的負面后果,至少在這種規(guī)模的測試數(shù)據(jù)中沒有觀察到。
經(jīng)測量,TEG的平均運行時間為2分8秒。通過將控制權移交給操作系統(tǒng),來加速對數(shù)據(jù)庫的寫入。這一措施將運行時間降低到與Pickle模塊的并行TEG性能的時間差不多。這也是除標準配置外最穩(wěn)定的方法。
3) 內(nèi)存日志模式
最后,修改了將日志記錄寫入數(shù)據(jù)庫的設置。這個設置可以有更多的值。標準值是一個日志條目,與數(shù)據(jù)庫中的記錄平行,位于與文檔相同的目錄中。本測試中使用的值將日志設置從ON改為MEMORY。MEMORY設置將運行和日志記錄轉(zhuǎn)移到計算機的工作存儲器中,當數(shù)據(jù)庫完成后,它將被刪除。
這一措施還顯著增加了每秒的查詢數(shù)量,但更改此設置會影響創(chuàng)建和編寫SQL數(shù)據(jù)庫的安全性,因為在發(fā)生重大計算機故障(電源故障、手動程序中斷等)時,可能會發(fā)生數(shù)據(jù)庫完全丟失。
在采用了架構(gòu)改進和實現(xiàn)了修正的JOURNAL_MODE設置SQL數(shù)據(jù)庫的情況下,可以計算出TEG的平均運行時間為兩分四十八秒。將日志保存在計算機的工作內(nèi)存中的數(shù)據(jù)庫中(而不保存到磁盤),這一方法會導致性能略慢于上一種方法,但它也是標準之外最安全的方法。
D. 加速工作測量
第一個測量是在現(xiàn)有生成器上使用標準多處理Python模塊的TEG的性能。與之前的6個小時相比,本示例的處理時間大約為1分30秒。從比較中可以了解到,由于使用了多處理模塊,生成數(shù)據(jù)的TEG部分在時間方面顯著減少。
TEG的平均持續(xù)時間約為1分31秒,比現(xiàn)有解決方案約少180倍。然后,使用采用的哈希字符串在生成器上執(zhí)行測量,該哈希字符串允許程序跳過主組件——解析器的執(zhí)行。引入哈希字符串后,TEG的運行時間減少了10%。使用多處理模塊和能成功得識別哈希字符串的TEG平均運行時間為1分22秒。
E. 討論
寫入一個新的數(shù)據(jù)庫,即不使用序列化,而是使用SQLite數(shù)據(jù)庫,產(chǎn)生了的結(jié)果與現(xiàn)有解決方案類似(更準確地說,整個程序的最終執(zhí)行是不可察覺的)。因此,不能說數(shù)據(jù)存儲過程本身加快了,但如果配置得當,它的時間性能可以與現(xiàn)有解決方案相當,還能增加數(shù)據(jù)庫的安全性、穩(wěn)定性和透明度。此外,由于數(shù)據(jù)是在生成器運行的同時寫入數(shù)據(jù)庫的,這將花費更長的時間,所以優(yōu)化配置的基庫不會對TEG的整體時間產(chǎn)生很大影響。
根據(jù)執(zhí)行記錄獲得的測量結(jié)果,即在TEG中的數(shù)據(jù)存儲和它們的平均前置時間,推薦第三種方案,即改變計算機工作內(nèi)存中的日志存儲(保持SYNCHRONOUS測量開啟)。由于增強型TEG的性能極短,相對于其他措施可能帶來的錯誤記錄數(shù)據(jù)的問題,重復性能的時間損失可以忽略不計。
然而,使用多處理和哈希模塊極大地減少了總運行時間,而且沒有不必要的副作用。然而,該模塊的有效性取決于運行該程序的所使用的硬件。從圖1中可以看出提議的pickle(帶多處理)方案(E1)、提議的SQL安全優(yōu)化(帶多處理)方案(E2)和現(xiàn)有方案(E3)的性能差異。
V.結(jié)論及未來的工作
要測試汽車計算機硬件和軟件之間的中間件層,需要使用測試環(huán)境生成器(TEG)。通過使用不同的TEG配置,可以進行多次測試和模擬,從而定性地檢查ADAS系統(tǒng)的性能。TEG在ECU上獲取通信數(shù)據(jù),并在其測試環(huán)境中生成通信模擬,以驗證ADAS系統(tǒng)是否正常工作。
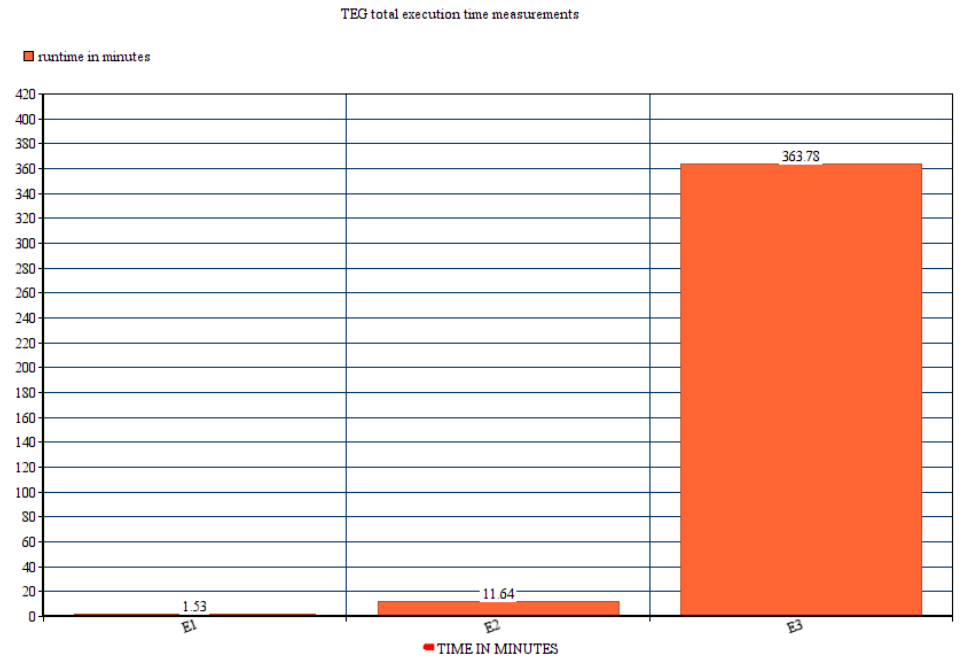
圖1 TEG平均運行時間(分鐘)
TEG有三個主要組件:解析器、數(shù)據(jù)存儲和生成器。本文的目的是提高各個組件的執(zhí)行速度和穩(wěn)定性。這種改進可以是基于算法和架構(gòu)方面的,主要目標是縮短TEG的總執(zhí)行時間,并引入更穩(wěn)定、更安全的數(shù)據(jù)存儲。TEG的核心組件是一個復雜的Python對象(TOM),它被設計用來跟蹤解析它的ARXML文件的結(jié)構(gòu)。TOM作為主要參數(shù)提交給代表TEG三個主要組件的三個主要函數(shù),因此如果沒有更充足的時間來了解現(xiàn)有解決方案,是不可能重新設計它的,而且可能超出一篇論文的范圍。現(xiàn)有解析器的工作與通過ARXML并初始化和寫入TOM的一個循環(huán)有關。需要做兩次數(shù)據(jù)存儲:用一個單獨的XML文件進行數(shù)據(jù)解析以及Pickle序列化。生成器還迭代瀏覽了.c 代碼模板,并將它們按順序放入SWC組件。
如果不需要解析器的話,解析器可以通過一個哈希字符串來加速,該字符串將新的TEG的結(jié)構(gòu)與舊的TEG進行比較,從而繞過解析器。數(shù)據(jù)存儲的加速還沒有實現(xiàn),但可以認為可以與現(xiàn)有的解決方案相媲美。擁有一個更穩(wěn)定、更安全、可讀性更強的基庫所帶來的額外好處是非常重要的,特別是由于基庫與明顯更長的發(fā)電機壽命并排存放,所以不會影響整個TEG的執(zhí)行時間。工作生成器的特點是快速引入了單個SWC組件的并行處理,最初生成的SWC列表被劃分為獨立的計算過程。根據(jù)所有的測量和示例,很明顯,本文開始時設定的目標已經(jīng)成功實現(xiàn),因為執(zhí)行時間已經(jīng)減少了大約180倍。
TEG未來可能的改進包括重新設計進入TEG的ARXML文件,使之成為較小的7arxml文件,每個文件代表一個SWC組件,以及重新設計底層對象的TOM結(jié)構(gòu),使之可以同時在多個進程中工作。為了降低處理時間,可以考慮將整個TEG移植到C語言中。
審核編輯:湯梓紅












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論