 電子發(fā)燒友App
電子發(fā)燒友App


自DARPA舉辦2004/2005年鄉(xiāng)村無人車大賽和2007年城市自動駕駛挑戰(zhàn)賽以來,自動駕駛一直是人工智能應(yīng)用最活躍的領(lǐng)域之一。本文概述了自動駕駛領(lǐng)域相關(guān)技術(shù)和未解決難題。我們參與調(diào)研的自動駕駛領(lǐng)域主要包括:感知、建圖和定位、預(yù)測、規(guī)劃和控制、仿真、V2X、安全等。與眾不同的是,我們闡述了如何在數(shù)據(jù)閉環(huán)框架下解決上述問題,其中,"數(shù)據(jù)閉環(huán)"是解決自動駕駛"長尾問題"的有效框架。
1 簡介
10多年來,自動駕駛一直是一個熱門話題。2004年和2005年,DARPA舉辦了鄉(xiāng)村無人車大賽。2007年,DARPA還舉辦了城市環(huán)境中的自動駕駛大賽。之后,斯坦福大學(xué)的S.Thrun教授(2005年冠軍和2007年亞軍)加入谷歌,建立了Google X和自動駕駛團(tuán)隊。
最近有三篇關(guān)于自動駕駛的調(diào)查報告[3,9,14]。自動駕駛作為機器學(xué)習(xí)和計算機視覺等人工智能領(lǐng)域最具挑戰(zhàn)性的應(yīng)用之一,已經(jīng)被證明是一個"長尾"問題,即少量類別占據(jù)了絕大多少樣本,而大量的類別僅有少量的樣本。在本文中,我們研究了如何在數(shù)據(jù)閉環(huán)中研發(fā)自動駕駛技術(shù)。我們的綜述工作涵蓋了自動駕駛技術(shù)主要領(lǐng)域,包括:感知、建圖和定位、預(yù)測、規(guī)劃和控制、仿真、V2X和安全等。
最后,我們將討論新興大模型對自動駕駛行業(yè)的影響。
2 簡要介紹
目前存在的一些關(guān)于自動駕駛技術(shù)的綜述文章,包含整個系統(tǒng)/平臺到單個模塊/功能[1-2,4-8,10-13,15-33]。在本節(jié)中,我們簡要介紹圖1所示的基本自動駕駛功能和模塊,硬件和軟件體系結(jié)構(gòu),包括:感知、預(yù)測、定位和建圖、規(guī)劃、控制、安全、仿真以及V2X等。
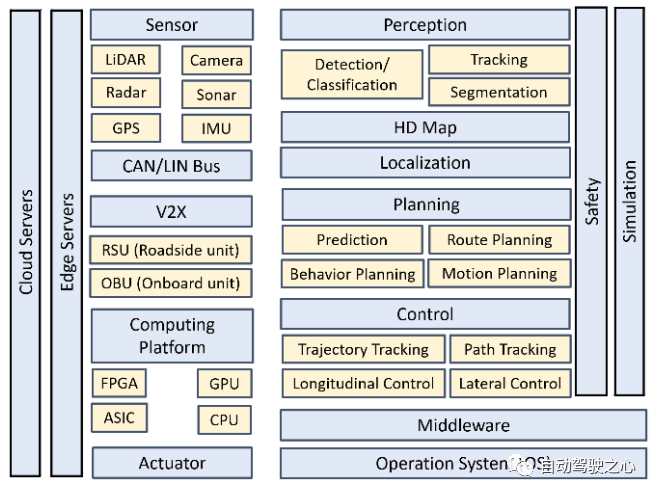
圖 1 自動駕駛平臺的硬件和軟件
2.1 自動化水平
美國運輸部和國家公路交通安全管理局(NHTSA)采用了國際標(biāo)準(zhǔn)化組織汽車工程師學(xué)會(SAE)制定的自動化水平標(biāo)準(zhǔn),該標(biāo)準(zhǔn)將自動駕駛車輛自動化分為6個等級,即從0級(人工駕駛員完全控制)到5級(車輛完全自主駕駛)。
在1級中,駕駛員和自動化系統(tǒng)共同控制車輛。在2級中,自動化系統(tǒng)完全控制車輛,但駕駛員必須時刻準(zhǔn)備好立即干預(yù)。在3級中,駕駛員可以免于駕駛?cè)蝿?wù),車輛將要求立即響應(yīng),因此駕駛員仍須隨時準(zhǔn)備干預(yù)。在4級中,與3級相同,但不需要駕駛員保持注意力來確保安全,駕駛員可以安全地睡覺或離開駕駛員座位。
2.2 硬件
自動駕駛車輛測試平臺應(yīng)該能夠?qū)崿F(xiàn)實時通信,例如使用控制器區(qū)域網(wǎng)絡(luò)(CAN)總線和以太網(wǎng),可以準(zhǔn)確地實現(xiàn)車輛的方向、油門和制動器的實時控制。進(jìn)行車輛傳感器合理配置,以滿足環(huán)境感知的可靠性要求,并最大限度降低生產(chǎn)成本。
自動駕駛車輛的感知可以分為三大類:本體感知、定位和環(huán)境感知。本體感知:通過車輛的傳感器測量當(dāng)前車輛狀態(tài),即橫擺速率、速度、偏航角等。本體感知的傳感器包括行程計、慣性測量單元(IMU)、陀螺儀和CAN總線。定位:使用外部傳感器(如全球定位系統(tǒng)(GPS))或IMU讀數(shù)的里程計來確定車輛的全局和局部位置。環(huán)境感知:使用外部感測器來感知車道標(biāo)線、道路坡度、交通信號牌、天氣條件和障礙物等。
本體感知傳感器和環(huán)境感知傳感器分為主動傳感器和被動傳感器。主動傳感器以電磁波的形式發(fā)出能量,并測量返回時間以確定距離等參數(shù),例如聲納、雷達(dá)和光探測與測距(LiDAR)傳感器。被動傳感器不發(fā)出信號,而是感知環(huán)境中已經(jīng)存在的電磁波(例如基于光的和紅外相機)。
另一個重要方面是計算平臺,它支持傳感器數(shù)據(jù)處理以識別周圍環(huán)境,并通過密集優(yōu)化算法、計算機視覺算法和機器學(xué)習(xí)算法來實時控制車輛。目前存在不同的計算平臺,如CPU、GPU、ASIC和FPGA等。為了支持基于AI的自動駕駛,也需要云服務(wù)器來提供大數(shù)據(jù)服務(wù),例如進(jìn)行大規(guī)模機器學(xué)習(xí)和大容量數(shù)據(jù)存儲(例如高清地圖)。為了實現(xiàn)車路協(xié)同,還需要處理車端信息的路側(cè)通信設(shè)備和計算設(shè)備。圖2顯示了一輛自動駕駛汽車中的傳感器配置示例(來自公開數(shù)據(jù)集NuScene)。它安裝了LiDAR、相機、雷達(dá)、GPS和IMU等。
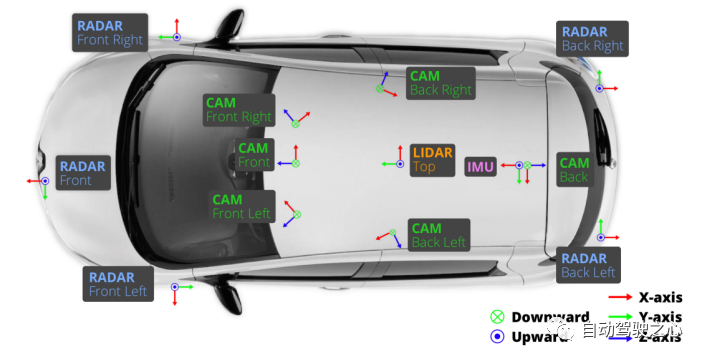
圖 2 自動駕駛傳感器硬件示例
如果需要收集多模態(tài)傳感器數(shù)據(jù),還需要進(jìn)行傳感器校準(zhǔn),其中涉及確定每個傳感器數(shù)據(jù)之間的坐標(biāo)系統(tǒng)關(guān)系,例如相機校準(zhǔn)、相機-LiDAR校準(zhǔn)、LiDAR-IMU校準(zhǔn)以及相機-雷達(dá)校準(zhǔn)。此外,傳感器之間需要使用統(tǒng)一的時鐘(例如GNSS),然后使用某個信號觸發(fā)傳感器的操作。例如,LiDAR的傳輸信號可以觸發(fā)相機的曝光時間,實現(xiàn)時間同步。
2.3 軟件
自動駕駛系統(tǒng)的軟件平臺分為4個層次,從底層到頂層分別為:實時操作系統(tǒng)(RTOS)、中間件、功能軟件和應(yīng)用軟件。軟件體系結(jié)構(gòu)分為:模塊化結(jié)構(gòu)和端到端結(jié)構(gòu)。
模塊化系統(tǒng)由多個構(gòu)件組成,連接感知輸入到執(zhí)行器輸出。模塊化自動駕駛系統(tǒng)(ADS)的關(guān)鍵功能通常分為:感知、定位和繪圖、預(yù)測、規(guī)劃和決策以及車輛控制等。
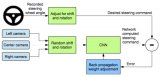
端到端系統(tǒng)直接從傳感器輸入生成控制信號。控制信號主要來自轉(zhuǎn)向輪和油門(加速器),用于加速/減速(甚至停止)和左/右轉(zhuǎn)彎。端到端駕駛主要包括三種方式:直接監(jiān)督深度學(xué)習(xí)、神經(jīng)進(jìn)化和深度強化學(xué)習(xí)。
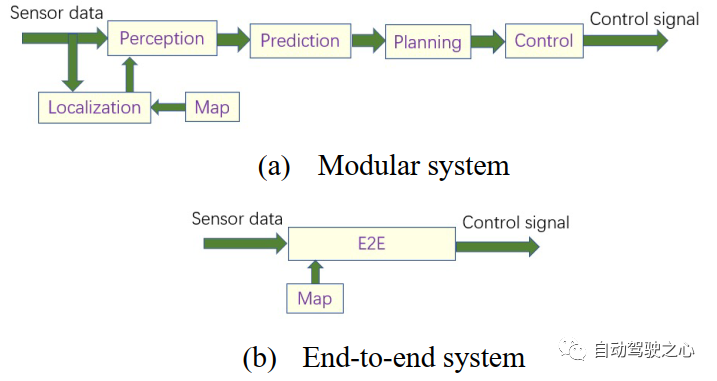
圖 3 顯示了端到端和模塊化系統(tǒng)的體系結(jié)構(gòu)
"感知"系統(tǒng)通過傳感器收集信息并從環(huán)境中提取有效信息。它能對駕駛環(huán)境進(jìn)行上下文理解,如檢測、跟蹤和分割障礙物、道路標(biāo)志/標(biāo)線和空曠的可駕駛區(qū)域。根據(jù)所采用的傳感器,環(huán)境感知任務(wù)主要通過使用LiDAR、相機、雷達(dá)或多傳感器融合來完成。在最高層次上,感知方法可以分為三類:中介感知、行為反射感知和直接感知。中介感知需要繪制車輛、行人、樹木、車道標(biāo)記等周圍環(huán)境的詳細(xì)地圖。行為反射感知將傳感器數(shù)據(jù)(圖像、點云、GPS位置)直接映射到駕駛機動操作。直接感知將行為反射感知與中介感知方法的度量獲取相結(jié)合。
"建圖"是指建立包含道路、車道、標(biāo)志/標(biāo)線和交通規(guī)則等信息的地圖。一般來說,有兩種主要類型的地圖:平面地圖,指依賴地理信息系統(tǒng)(GIS)上的圖層或平面繪制的地圖;點云地圖,指基于GIS中的數(shù)據(jù)點集的地圖。高清(HD)地圖包含自動駕駛所需的有用的靜態(tài)元素,如車道、建筑、交通燈和車道標(biāo)記等。HD地圖與車輛定位功能緊密相連,并與車輛傳感器(如LiDAR、雷達(dá)和相機)保持交互,從而構(gòu)建自動駕駛系統(tǒng)的感知模塊。
"定位"確定車輛相對于駕駛環(huán)境的位置。全球?qū)Ш叫l(wèi)星系統(tǒng)(GNSS)如GPS、GLONASS、北斗和伽利略等,他們使用不少于四顆衛(wèi)星并以相對較低的成本估計車輛的全球位置。全球?qū)Ш叫l(wèi)星系統(tǒng)可以使用差分模式來提高GNSS的精度。GNSS通常與IMU集成來設(shè)計性價比高的車輛定位系統(tǒng)。IMU用于估計車輛相與其初始位置的相對位置,這種方法稱為里程計。由于HD地圖已經(jīng)用于自動駕駛,基于HD地圖的定位也被考慮在內(nèi)。最近,出現(xiàn)了許多自主的里程計方法和同時定位與建圖方法(SLAM)。SLAM技術(shù)通常應(yīng)用一個里程計算法來獲得當(dāng)前姿態(tài)信息,然后將其送到一個全局地圖優(yōu)化算法中。基于圖像的計算機視覺算法包括:特征提取和匹配、相機運動估計、三維重建(三角測量)和優(yōu)化(約束調(diào)整)等,由于這些算法的缺點,目前視覺SLAM仍然是一個具有挑戰(zhàn)性的方向。
"預(yù)測"是指根據(jù)障礙物的運動學(xué)、行為和長短期歷史估計其軌跡。要完全解決軌跡預(yù)測問題,社會智能化非常重要。因為智能化的社會環(huán)境中,各種可能性被約束,無限的搜索空間也被約束。為了建立社會互動模型,我們需要了解智能體及其周圍環(huán)境的動態(tài),以預(yù)測其未來的行為,防止發(fā)生任何碰撞。
"規(guī)劃"是生成一條避障的參考路徑或軌跡,使車輛在避開障礙物的同時到達(dá)目的地。規(guī)劃可以分為不同的等級:路線(任務(wù))規(guī)劃、行為規(guī)劃和運動規(guī)劃。路徑規(guī)劃是指在有向圖中尋找點到點的最短路徑,傳統(tǒng)方法分為目標(biāo)導(dǎo)向技術(shù)、基于分離器的技術(shù)、分層技術(shù)和有界跳技術(shù)四類。行為規(guī)劃決定了局部駕駛?cè)蝿?wù),該任務(wù)使車輛向目的地前進(jìn)并遵守交通規(guī)則,傳統(tǒng)上由有限狀態(tài)機(FSM)定義。最近正在研究模仿學(xué)習(xí)和強化學(xué)習(xí),以生成車輛所需的行為。運動規(guī)劃在環(huán)境中選擇一條連續(xù)路徑,以完成局部驅(qū)動任務(wù),例如RRT(快速探索隨機樹)和Lattice規(guī)劃。
"控制"是通過選擇適當(dāng)?shù)膱?zhí)行器輸入來執(zhí)行規(guī)劃的動作。通常控制可分為橫向控制和縱向控制。大部分情況下,可以將控制解耦為兩階段,即軌跡/路徑生成階段和跟蹤階段,例如純跟蹤法。然而,它也可以同時生成軌跡/路徑并進(jìn)行跟蹤。
"V2X(車聯(lián)網(wǎng))"是一種能夠使車輛能夠與周圍的車流和環(huán)境進(jìn)行通信的車輛技術(shù)系統(tǒng),包括:車輛間通信(V2V)和車輛基礎(chǔ)設(shè)施通信(V2I)。從行人的移動設(shè)備到交通燈上的固定傳感器,車輛可以通過V2X訪問大量數(shù)據(jù)。通過積累來自其他車輛的詳細(xì)信息,將克服單車智能的感知范圍、盲區(qū)和規(guī)劃不足等缺點。V2X有助于提高安全性和交通效率,但車輛之間和車路之間的協(xié)同仍然具有挑戰(zhàn)性。
值得一提的是,ISO(國際標(biāo)準(zhǔn)化組織)26262標(biāo)準(zhǔn)適用于自動駕駛車輛,它定義了一套全面的要求,以確保車輛軟件開發(fā)的"安全"。該標(biāo)準(zhǔn)建議使用危險分析和風(fēng)險評估(HARA)方法來識別危險事件,并確定了減輕危險的安全目標(biāo)。車輛安全完整性級別(ASIL)是ISO 26262中定義的車輛系統(tǒng)風(fēng)險分類方案。AI系統(tǒng)帶來了更多安全問題,這些問題由一個新建立的標(biāo)準(zhǔn)ISO/PAS 21448 SOTIF(預(yù)期功能的安全性)來解決。
除了模塊化或端到端系統(tǒng),ADS開發(fā)中還有一個重要的"仿真"平臺。由于在道路上駕駛實驗車輛的成本很高,而且在現(xiàn)有的人類駕駛的道路網(wǎng)絡(luò)上進(jìn)行實驗,會受到限制,因此仿真環(huán)境可以實現(xiàn)在實際道路測試之前開發(fā)某些算法/模塊。仿真系統(tǒng)由以下核心部分組成:傳感器模型(相機、雷達(dá)、LiDAR和聲納)、車輛動力學(xué)和運動學(xué)、行人、駕車者和騎車者的形狀和運動學(xué)模型、路網(wǎng)和交通網(wǎng)絡(luò)、三維虛擬環(huán)境(城市和鄉(xiāng)村場景)以及駕駛行為模型(年齡、文化、種族等)。仿真平臺存在的關(guān)鍵問題是"sim2real"和"real2sim",前者是指如何模擬真實場景,后者是指如何以數(shù)字孿生的方式進(jìn)行情景再現(xiàn)。
3 感知
感知周圍環(huán)境并提取信息是自動駕駛的關(guān)鍵任務(wù)。使用不同傳感模式的各種任務(wù)都屬于感知范疇[5-6,25,29,32,36]。基于計算機視覺技術(shù),相機成為使用最廣泛的傳感器,3D視覺則成為一個強大的替代方案/補充。
最近,BEV(鳥瞰視角)感知[25,29]成為自動駕駛中最活躍的感知方向之一,特別是在基于視覺的系統(tǒng)中。主要原因有以下兩點:首先,BEV對駕駛場景的表示可以直接由下游模塊應(yīng)用,如軌跡預(yù)測和運動規(guī)劃等。其次,BEV提供了一種可解釋的方式來融合來自不同視角、模式、時間序列和智能體的信息。例如,其他常用傳感器,如LiDAR和Radar在3D空間中獲取的數(shù)據(jù),可以輕松轉(zhuǎn)換到BEV,并直接與相機直接進(jìn)行傳感器融合。
在調(diào)研報告[25]中,BEV工作可以分為以下幾個類別,如圖4所示。
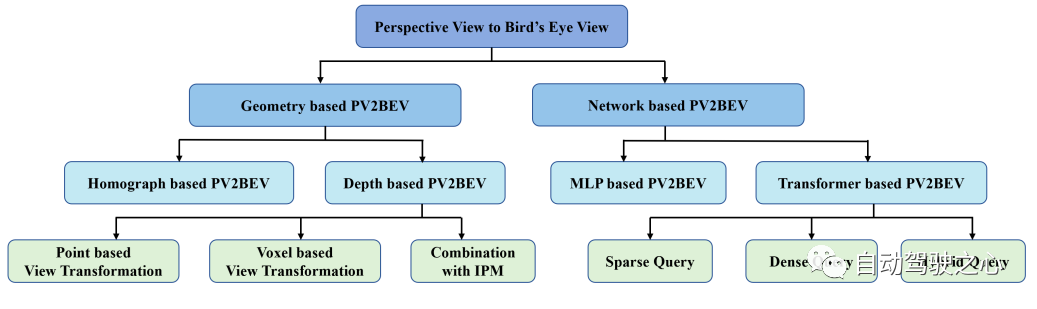
圖 4 BEV工作的類別
首先,根據(jù)視圖變換方式可以分為基于幾何的變換和基于網(wǎng)絡(luò)的變換。基于幾何的變換充分利用相機的物理原理進(jìn)行視圖轉(zhuǎn)換,該方法可進(jìn)一步分為經(jīng)典的基于同圖的方法(即逆投影映射)和基于深度的方法,通過顯式或隱式深度估計可以將二維特征提升至三維特征。
根據(jù)深度信息的利用方式,我們可以將基于深度的方法分為兩類:基于點的方法和基于體素的方法;基于點的方法直接利用深度估計將像素轉(zhuǎn)換為點云,散布在連續(xù)的三維空間中;而基于體素的方法通常直接利用深度引導(dǎo)將二維特征(而不是點)散布在相應(yīng)的三維位置上。
基于網(wǎng)絡(luò)的方法可以采用自下而上的策略,即神經(jīng)網(wǎng)絡(luò)像視圖投影儀一樣發(fā)揮作用;另一種方法可以采用自上而下的策略,即直接構(gòu)建BEV查詢,并通過交叉注意力機制(基于Transformer)在前視圖像上搜索相應(yīng)的特征,提出稀疏、密集或混合查詢以匹配不同的下游任務(wù)。
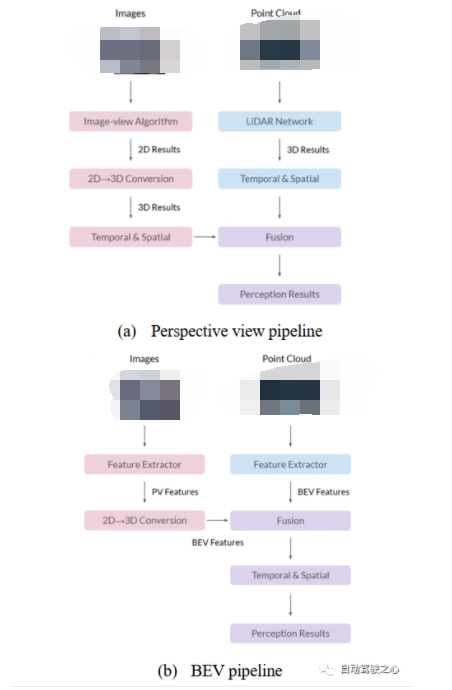
圖 5 BEV方案
迄今為止,BEV網(wǎng)絡(luò)已被用于物體檢測、語義分割、在線映射、傳感器融合和軌跡預(yù)測等。如研究論文[29]圖5所示,BEV融合算法有兩種典型的過程設(shè)計。兩者主要區(qū)別在于2D到3D的轉(zhuǎn)換和融合模塊。在透視圖方案(a)中,首先將不同算法的結(jié)果轉(zhuǎn)換到三維空間,然后使用先驗規(guī)則或人工方法進(jìn)行融合。BEV方案(b)首先將透視圖特征轉(zhuǎn)換為BEV,然后融合特征以獲得最終預(yù)測結(jié)果,從而保留大部分原始信息并避免人工設(shè)計。
繼BEV之后,三維占位網(wǎng)絡(luò)逐漸成為自動駕駛感知領(lǐng)域的前沿技術(shù)[32]。BEV可以簡化駕駛場景的縱向幾何,而三維體素能夠以較低的分辨率表示完整的幾何,包括道路地面和障礙物體積,這需要較高的計算成本。基于相機的方法正在三維占位網(wǎng)絡(luò)中興起。圖像具有天然的像素密度,但是需要深度信息才能反向投射到三維占位中。注:對于LiDAR數(shù)據(jù),占位網(wǎng)絡(luò)實際上實現(xiàn)了語義場景補全(SSC)任務(wù)。
在圖6中,我們解釋了BEV和占用網(wǎng)絡(luò)的三種模型體系結(jié)構(gòu),僅針對相機輸入,僅針對LiDAR輸入以及兩者結(jié)合輸入。
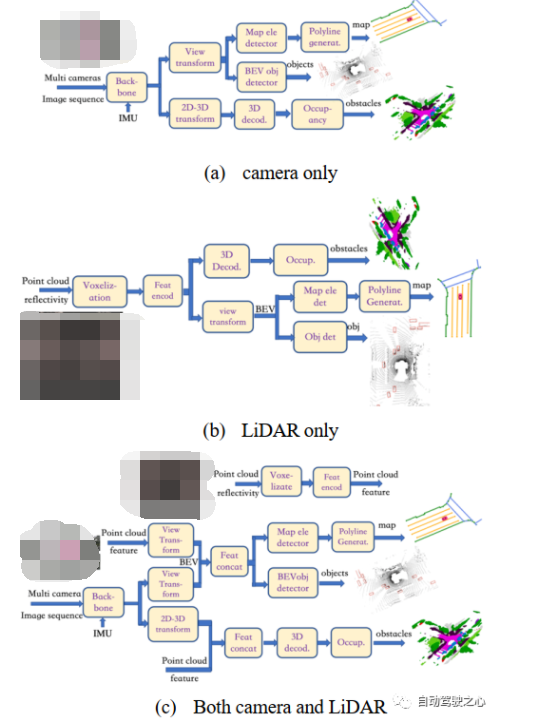
圖 6 BEV和占位網(wǎng)絡(luò)實例
僅多相機輸入如圖6(a)所示,多相機圖像首先通過"Backbone"模塊編碼,如EfficientNetor/RegNet加上FPN/Bi-FPN,然后分為兩路;一方面,圖像特征進(jìn)入"view transform"模塊,通過深度分布或Transformer架構(gòu)構(gòu)建BEV特征,然后分別進(jìn)入兩個不同的頭部:一個頭通過"map ele detector"模塊輸出地圖元素的矢量化表示(其結(jié)構(gòu)類似于基于Transformer的DETR模型,也有一個可變形的關(guān)注模塊,并輸出關(guān)鍵點的位置和它們所屬元素的ID)和"polyline generat"模塊(它也是一個基于Transformer結(jié)構(gòu)的模型,輸入這些嵌入的關(guān)鍵點、多段線分布模型可以生成多段線的頂點并獲得地圖元素的幾何表示),另一個頭通過"BEV obj Detector"模塊獲得obj BEV邊界框,它可以使用Transformer架構(gòu)或類似的PointPillar架構(gòu)來實現(xiàn);另一方面,在"2D-3D transform"模塊中,基于深度分布將二維特征編碼投影到三維坐標(biāo),其中保留高度信息,得到的相機體素特征進(jìn)入"3D decod."模塊得到多尺度體素特征,然后進(jìn)入"occupancy"模塊進(jìn)行類預(yù)測,生成體素語義分割。
僅LiDAR輸入如圖6(b)所示,部分模塊與圖6(a)相同。首先,在"Voxelization"模塊中,將點云劃分為間距均勻的體素網(wǎng)格,生成三維點與體素的多對一映射;然后進(jìn)入"FeatEncod"模塊,將體素網(wǎng)格轉(zhuǎn)換為點云特征圖(使用PointNet或PointPillar);一方面,在"view transform"模塊中,將特征圖投影到BEV上,在BEV空間中結(jié)合特征聚合器和特征編碼器,然后進(jìn)行BEV解碼,分為兩個頭:一個頭部的工作原理如圖6(a)所示。另一方面,三維點云特征圖可以直接進(jìn)入"3D Decod"模塊,通過三維解卷積獲得多尺度體素特征,然后在"Occup"模塊中進(jìn)行上采樣和類預(yù)測,生成體素語義分割。
相機和LiDAR同時輸入如圖6(c)所示,大多數(shù)模塊與圖6(a)和6(b)相同,除了"Feat concat"模塊將連接來自LiDAR路徑和相機路徑的特征。
注:對于基于相機的占位網(wǎng)絡(luò),值得一提的是計算機圖形學(xué)和計算機視覺領(lǐng)域的一種新范例--神經(jīng)輻射場(NeRF)[47]。NeRF不是直接還原整個三維場景的幾何圖形,而是生成一種被稱為"輻射場"的體積表示,它能夠為相關(guān)三維空間中的每一點創(chuàng)建顏色和密度。
4 軌跡預(yù)測
為實現(xiàn)安全高效的導(dǎo)航,自動駕駛汽車應(yīng)考慮周圍其他智能體的未來軌跡。軌跡預(yù)測最近受到了廣泛關(guān)注,這是一項極具挑戰(zhàn)性的任務(wù),它根據(jù)場景中所有運動的智能體的當(dāng)前和過去狀態(tài)預(yù)測其未來狀態(tài)。
預(yù)測任務(wù)可分為兩部分。第一部分是作為分類任務(wù)的"意圖",它通常可被視為一個監(jiān)督學(xué)習(xí)問題,我們需要標(biāo)注智能體可能的意圖。第二部分是需要預(yù)測智能體在未來N個幀中的一組可能位置的"軌跡",這個"軌跡"被稱為"路徑點"(way-points)。這建立了它們與其他智能體以及道路的交互。
文獻(xiàn)[10,12,34]進(jìn)行了一些預(yù)測相關(guān)的研究。傳統(tǒng)上,我們將行為預(yù)測模型分為基于物理的模型、基于機動的模型和基于交互意識的模型。基于物理的模型由動態(tài)方程構(gòu)成,為不同類別的智能體建立人工設(shè)計運動模型。基于機動的模型是基于智能體的預(yù)期運動類型的實際模型。交互感知模型通常是基于ML的系統(tǒng),能夠?qū)鼍爸械拿恳粋€智能體進(jìn)行配對推理,并為所有動態(tài)智能體生成交互感知預(yù)測。
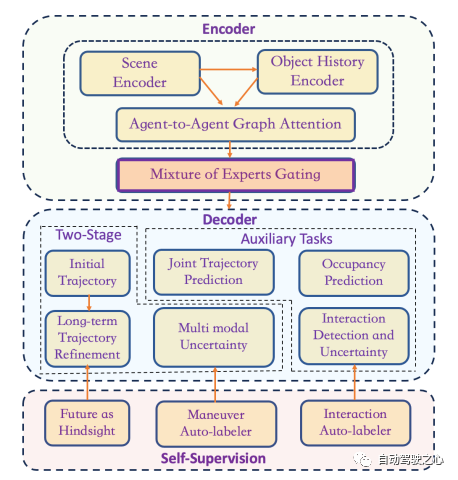
圖 7 L4創(chuàng)業(yè)公司Cruise.AI的預(yù)測模型
圖7給出了L4自動駕駛創(chuàng)業(yè)公司Cruise.AI[36]設(shè)計的預(yù)測模型圖。顯然,它展示了一個編碼器-解碼器結(jié)構(gòu)。在編碼器中,有一個"場景編碼器"來處理環(huán)境上下文(地圖),類似于谷歌Waymo的ChauffeurNet(光柵化圖像作為輸入)或VectorNet(矢量化輸入)架構(gòu)一樣;有一個"對象歷史編碼器"來處理智能體歷史數(shù)據(jù)(位置);還有一個基于注意力圖網(wǎng)絡(luò)來捕捉智能體之間的聯(lián)合交互。為了處理動態(tài)場景的變化,他們將專家混合(MoE)編碼到門控網(wǎng)絡(luò)中。例如,在停車場有不同的行為,如倒車駛出、駛出和K形轉(zhuǎn)彎、平行停車第二次嘗試、倒車和駛出、倒車平行停車和垂直駛出等。
在圖7所示的解碼器中,有一個兩階段的結(jié)構(gòu),即由一個簡單的回歸器生成初始軌跡,然后由具有"多模態(tài)不確定性"估計的長期預(yù)測器進(jìn)行完善。為了增強軌跡預(yù)測器,還有一些輔助任務(wù)需要訓(xùn)練,如"聯(lián)合軌跡不確定性"估計和"交互檢測和不確定性"估計,以及"占位預(yù)測"。
該軌跡預(yù)測器的一個大創(chuàng)新是它的"自監(jiān)督"機制。基于"后見之明"的觀察,他們提供"機動自動標(biāo)注器"和"交互自動標(biāo)注器"為預(yù)測器模型生成大量訓(xùn)練數(shù)據(jù)。
5 建圖
地圖,特別是HD地圖,是自動駕駛的先驗知識。建圖技術(shù)可以分類為在線建圖和離線建圖[24]。在離線建圖中,我們在中心位置收集所有數(shù)據(jù),這些數(shù)據(jù)采集來自安裝有GNSS、IMU、LiDAR和相機的車輛。另一方面,在線建圖使用輕量級模塊在自動駕駛車輛上進(jìn)行。
所有有前途的建圖技術(shù)目前都使用LiDAR作為主要傳感器,特別是用于HD地圖。另一方面,也有一些方法只使用視覺傳感器構(gòu)建地圖,如Mobileye的REM,或稱為roadbook,它基于視覺SLAM和深度學(xué)習(xí)[35]。
創(chuàng)建HD地圖通常涉及采集高質(zhì)量的點云、對準(zhǔn)同一場景的多個點云、標(biāo)記地圖元素以及頻繁更新地圖。這個過程需要大量人力和時間,限制了其可擴展性。BEV感知[25,29]具有在線學(xué)習(xí)地圖的潛力,它根據(jù)局部傳感器觀察動態(tài)地構(gòu)建高清地圖,這可能是一種可以為自動駕駛汽車提供語義和先驗幾何信息的更具可擴展性的方式,。
在這里,我們介紹在線建圖的最新工作,稱為MachMap[45],它將高清地圖構(gòu)建公式化為BEV空間中的點檢測范式,以端到端的方式。基于地圖緊湊方案,它遵循基于查詢的范式,集成了CNN基礎(chǔ)架構(gòu)(如InternImage),基于時間的實例解碼器和點掩膜耦合頭。
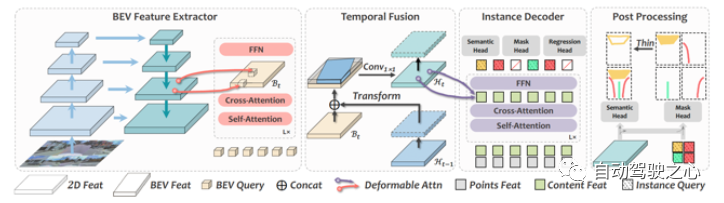
圖 8 MachMap框架
MachMap的框架如圖8所示。它通過圖像骨干和周圍圖像的頸部從每個視圖生成2D特征。然后,可變形注意力用于聚合不同視圖之間的3D特征,并沿z軸對其進(jìn)行平均。在時間融合模塊中,新的BEV特征與BEV特征的隱藏狀態(tài)進(jìn)行融合。
利用實例級可變形注意力機制執(zhí)行實例解碼器可以完善內(nèi)容和點特征并獲得最終結(jié)果。
6 定位
自動駕駛車輛的精準(zhǔn)定位可對下游任務(wù)(如行為規(guī)劃)產(chǎn)生巨大的影響。雖然使用傳統(tǒng)的動態(tài)傳感器(如IMU和GPS)可以獲得可接受的結(jié)果,但基于視覺的傳感器(LiDAR或相機)顯然更適合這項任務(wù),因為使用這類傳感器獲得的定位結(jié)果同時依賴于車輛本身及其周圍的環(huán)境。雖然這兩種傳感器都具有良好的定位性能,但它們也存在一些局限性[27]。
多年來,研究者一直在研究自動駕駛汽車定位,這大多數(shù)情況下是與建圖一起進(jìn)行的,這帶來了兩種不同的路線:第一種是SLAM,即定位和建圖同時循環(huán)運行;第二種是將定位和建圖分開,直接離線構(gòu)建地圖。
最近,深度學(xué)習(xí)為SLAM帶來了新的數(shù)據(jù)驅(qū)動的方法,尤其是更具挑戰(zhàn)性的視覺SLAM,這在論文[28]中有所提及。這里我們討論一個基于Transformer定位方法的例子[48],其中獲取姿勢是通過所提出的POse Estimator Transformer(POET)模塊使用注意機制與從跨模型特征中檢索到的相關(guān)信息交互來更新的。定位架構(gòu)如圖9所示。
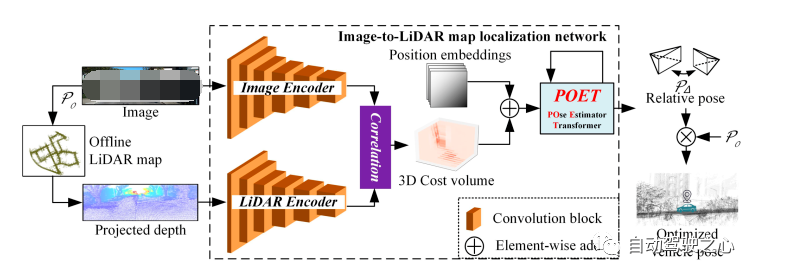
圖 9 使用Transformers進(jìn)行地圖定位
如圖9所示,該網(wǎng)絡(luò)以RGB圖像和LiDAR地圖上給定初始姿態(tài)的相鄰點云的重投影深度圖像作為輸入。然后,它們分別通過對應(yīng)的編碼器進(jìn)行處理以獲得高維特征。之后,進(jìn)行圖像特征和LiDAR特征融合,獲得融合特征。之后,把位置信息添加到融合特征后,將融合特征輸入到所提出的POET模塊中。
POET將融合特征作為輸入并初始化姿勢信息。經(jīng)過與融合特征相關(guān)信息的迭代更新,姿勢信息可以被優(yōu)化為圖像與初始姿態(tài)之間高精度的相對姿態(tài)。
這里應(yīng)用了DETR解碼器來更新姿勢信息。解碼器由交替堆疊的自注意層和交叉注意層組成。自注意力在姿勢信息內(nèi)計算,而交叉注意力在姿勢信息和處理過的代價量之間計算。
7 規(guī)劃
大多數(shù)規(guī)劃方法,尤其是行為規(guī)劃,是基于規(guī)則的[1,2,7-8],這為數(shù)據(jù)驅(qū)動系統(tǒng)的探索和升級帶來了巨大的負(fù)擔(dān)。基于規(guī)則的規(guī)劃框架負(fù)責(zé)為車輛的低級控制器要跟蹤的軌跡點序列。基于規(guī)則的規(guī)劃框架的優(yōu)點是具有可解釋性,當(dāng)出現(xiàn)故障或意外的系統(tǒng)行為時,可以識別有缺陷的模塊。其局限性在于需要許多手動啟發(fā)式功能。
基于學(xué)習(xí)的規(guī)劃方法已成為自動駕駛研究中的一種趨勢[15,18,33]。駕駛模型可以通過仿真學(xué)習(xí)獲取知識,并通過強化學(xué)習(xí)探索駕駛策略。與基于規(guī)則的方法相比,基于學(xué)習(xí)的方法可以更有效地處理車輛與環(huán)境的交互。盡管其概念吸引人,但當(dāng)模型行為不當(dāng)時,很難甚至不可能找出原因。
仿真學(xué)習(xí)(IL)是指基于專家軌跡的智能體學(xué)習(xí)策略。每個專家軌跡都包含一系列狀態(tài)和動作,并且所有"狀態(tài)-動作"對都被提取來構(gòu)建數(shù)據(jù)集。IL的具體目標(biāo)是評估狀態(tài)與動作之間最適合的映射,以便智能體盡可能接近專家軌跡。
為了緩解標(biāo)注數(shù)據(jù)的負(fù)擔(dān),一些科學(xué)家已經(jīng)將強化學(xué)習(xí)(RL)算法應(yīng)用于行為規(guī)劃或決策制定。智能體可以通過與環(huán)境交互獲得一些獎勵。RL的目標(biāo)是通過試誤來優(yōu)化累積數(shù)值獎勵。通過與環(huán)境持續(xù)交互,智能體逐步獲得關(guān)于達(dá)到目標(biāo)端點的最佳策略的知識。在RL中從零開始訓(xùn)練策略通常很耗時且具有挑戰(zhàn)性。將RL與其他方法(如IL和課程學(xué)習(xí))相結(jié)合可能是一個可行的解決方案。
近年來,深度學(xué)習(xí)(DL)技術(shù)通過深度神經(jīng)網(wǎng)絡(luò)(DNN)的奇妙特性:函數(shù)逼近和表征學(xué)習(xí),為行為規(guī)劃問題提供了強大的解決方案。DL技術(shù)使RL/IL能夠擴展到以前難以解決的問題(如高維狀態(tài)空間)。
這里介紹一個兩階段占位預(yù)測引導(dǎo)的神經(jīng)規(guī)劃器(OPGP)[46],它將未來占位和運動規(guī)劃的聯(lián)合預(yù)測與預(yù)測引導(dǎo)相結(jié)合,如圖10所示。
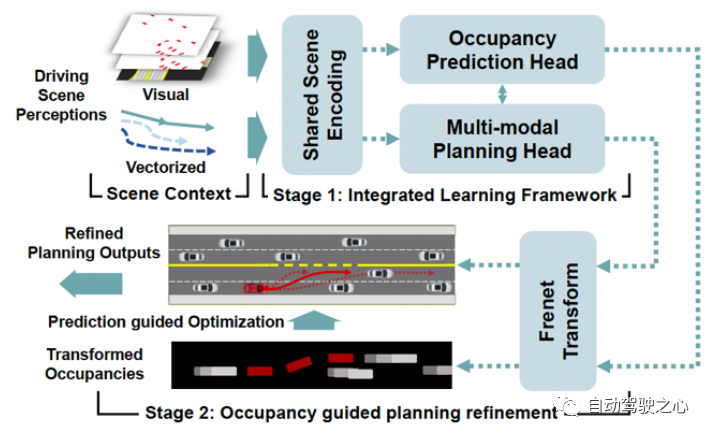
圖 10 兩階段式OPGP
在OPGP的第一階段,在基于Transformer骨干上建立了一個集成網(wǎng)絡(luò)。視覺特征是歷史占用柵格和柵格化BEV路線圖的組合,代表特定場景下交通參與者的空間-時間狀態(tài)。矢量化上下文最初關(guān)注以自動駕駛車輛為中心的參與者的動態(tài)上下文。考慮到視覺特征和矢量化上下文的交互,同時輸出所有類型交通參與者的占位預(yù)測。同時,編碼后的場景特征和占位情況在規(guī)劃頭中共享并實現(xiàn)有條件地查詢,規(guī)劃頭進(jìn)行多模態(tài)運動規(guī)劃。
OPGP第二階段的重點是以一種優(yōu)化可行的方式為細(xì)化建模來自占用率預(yù)測的明確指導(dǎo)。更具體地說,他們在Frenet空間(這是一個由切線和曲率決定的移動右旋坐標(biāo)系)中構(gòu)建了一個優(yōu)化過程,用于使用變換后的占用率預(yù)測進(jìn)行規(guī)劃細(xì)化。
8 控制
與自動駕駛中的其他模塊(如感知和規(guī)劃)相比,車輛控制相對成熟,經(jīng)典控制理論發(fā)揮著主要作用[20,21]。然而,深度學(xué)習(xí)方法不僅能在各種非線性控制問題上獲得優(yōu)異的性能,還能將先前學(xué)習(xí)到的規(guī)則外推到新的場景中,因此在自動駕駛控制領(lǐng)域的應(yīng)用前景十分廣闊。因此,深度學(xué)習(xí)在自動駕駛控制中的應(yīng)用正變得越來越流行[13]。
傳感器的配置多種多樣;有些人僅通過視覺來控制車輛,有些人則利用測距傳感器(LiDAR或雷達(dá)),還有些人利用多傳感器。在控制目標(biāo)方面也存在差異,有些人將系統(tǒng)設(shè)計為一個高級控制器提供目標(biāo),然后通過低級控制器實現(xiàn)目標(biāo),這種方式通常使用經(jīng)典控制技術(shù)。另一些則旨在端到端學(xué)習(xí)的自動駕駛,將觀測結(jié)果直接映射到低級車輛控制界面命令。
車輛控制可以分為橫向控制和縱向控制。橫向控制系統(tǒng)旨在控制車輛在車道上的位置,并實現(xiàn)其他橫向動作,如變道和回避碰撞動作。在深度學(xué)習(xí)領(lǐng)域,這通常是通過使用車載相機的圖像/LiDAR的點云捕捉環(huán)境信息作為神經(jīng)網(wǎng)絡(luò)的輸入來實現(xiàn)的。
在本節(jié)中,我們將介紹一種帶有語義視覺地圖和相機的端到端(E2E)駕駛模型[16]。仿真人類駕駛是通過對抗學(xué)習(xí)來實現(xiàn)的,其中一個生成器模仿人類駕駛員,一個識別器使其像人類駕駛員。
訓(xùn)練數(shù)據(jù)(名稱為"Drive360數(shù)據(jù)集")由前置相機和渲染的TomTom路線規(guī)劃模塊采集。然后采用HERE地圖數(shù)據(jù)對數(shù)據(jù)集進(jìn)行離線增強,以提供同步的語義地圖信息。
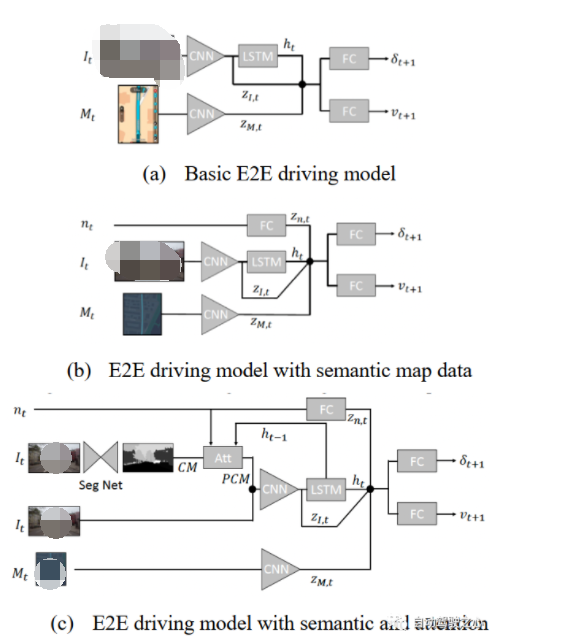
圖 11 E2E駕駛模式框架
對于基本的E2E駕駛模型,記錄歷史圖像和地圖渲染序列,并預(yù)測動作。網(wǎng)絡(luò)結(jié)構(gòu)如圖11(a)所示:圖像通過視覺編碼器輸入,輸出的潛變量進(jìn)一步輸入LSTM,從而產(chǎn)生隱藏狀態(tài)h;地圖渲染也在視覺編碼器中處理,產(chǎn)生另一個潛變量量;然后將這三個變量連接起來預(yù)測動作。 ? 帶有額外語義地圖信息的簡單方法稱為后融合方法,其示意圖如圖11(b)所示:一個向量嵌入所有語義地圖信息,經(jīng)過全連接網(wǎng)絡(luò)處理,輸出潛在變量量與、和h連接。 ? 最近,一種新方法被提出:根據(jù)語義圖信息提高分割網(wǎng)絡(luò)的輸出類別概率,其完整架構(gòu)如圖11(c)所示。該方法使用語義分割網(wǎng)絡(luò)獲得所有19個類別的置信度掩碼,然后使用軟注意力網(wǎng)絡(luò)使該掩碼生成19個類別的注意力向量。 ? 在訓(xùn)練駕駛模型時,決策問題可以被視為匹配動作序列(稱為drivelets)的監(jiān)督回歸問題。因此可以使用生成對抗網(wǎng)絡(luò)(GAN)來制定模仿學(xué)習(xí)問題,其中生成器是駕駛模型,判別器識別drivelet是否類似于人類規(guī)劃的路徑。 ?
9 V2X
得益于通信基礎(chǔ)設(shè)施的完善和通信技術(shù)的發(fā)展(如車聯(lián)網(wǎng)(V2X)通信等),車輛可以通過可靠的方式傳遞信息,從而實現(xiàn)車輛之間的協(xié)作[4,11]。協(xié)同駕駛利用車對車(V2V)和車對基礎(chǔ)設(shè)施(V2I)通信技術(shù),旨在實現(xiàn)協(xié)同功能:(i)協(xié)同感知和(ii)協(xié)同操縱。 ? 有一些通用的協(xié)同駕駛場景:智能停車、變道和并線以及交叉路口協(xié)同管理。車輛隊列(Vehicle Platooning),也稱為車隊駕駛,是指兩輛或兩輛以上的車輛連續(xù)在同一車道上以較小的的車間距(通常小于1秒)同速并排行駛,這是實現(xiàn)合作自動駕駛的一個主要用例[26]。 ? 采用集中式或分散式的策略進(jìn)行有價值的研究工作主要集中在協(xié)調(diào)交叉路口的CAV和高速公路入口匝道上的并線上。在集中式的策略中,系統(tǒng)中至少有一項任務(wù)是由單個中央控制器控制所有車輛的。在分散控制中,每輛車根據(jù)從道路上其他車輛或協(xié)調(diào)器接收到的信息選擇自己的控制策略。 ? 分散式的策略可分為三種類型:協(xié)商、協(xié)議和緊急。最有代表性的協(xié)商類型是:協(xié)同合作問題和博弈競爭問題。協(xié)調(diào)過程的協(xié)議將產(chǎn)生一系列可接受的措施,甚至動態(tài)地重新確定目標(biāo)。緊急問題使得每輛車根據(jù)自己的目標(biāo)和感知,以一種有利于自己的方式規(guī)劃,例如博弈論或自組織。 ? 與單車感知不同,協(xié)同感知可以利用多個智能體之間的交互來豐富自動駕駛系統(tǒng)的感知,因此受到了廣泛關(guān)注[31]。隨著深度學(xué)習(xí)方法被廣泛應(yīng)用于自動駕駛感知系統(tǒng),協(xié)同感知系統(tǒng)的能力和可靠性也在穩(wěn)步增加。 ? 根據(jù)信息傳遞和協(xié)同階段,協(xié)同感知方案可大致分為早期協(xié)同、中期協(xié)同和后期協(xié)同。早期協(xié)同采用網(wǎng)絡(luò)輸入端的原始數(shù)據(jù)融合,也稱為數(shù)據(jù)級融合或低級融合。考慮到早期協(xié)同的高帶寬,一些工作提出了中間協(xié)同方法,以平衡性能和帶寬之間的權(quán)衡。后期協(xié)同或?qū)ο蠹墔f(xié)同采用網(wǎng)絡(luò)預(yù)測融合。協(xié)同感知的挑戰(zhàn)性問題包括:標(biāo)定、車輛定位、時空同步等。 ?
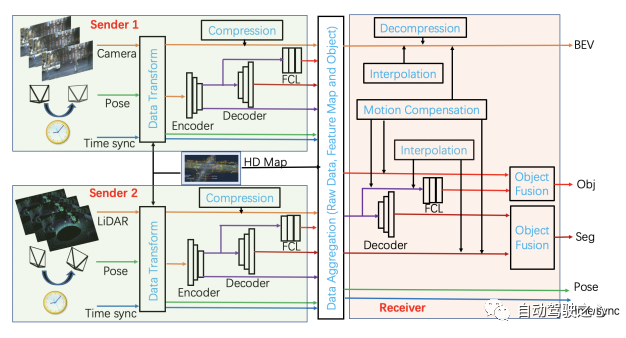
圖 12 V2X協(xié)同感知示意圖 ? 這里我們提出了一個多層的V2X感知平臺,如圖12所示。時間同步信息處理不同智能體的數(shù)據(jù)之間的時間差異。為了靈活性,數(shù)據(jù)容器優(yōu)先保留一個時間窗口,例如1秒(LiDAR/雷達(dá)為10幀,相機為30幀)。空間構(gòu)建需要姿態(tài)信息,姿態(tài)信息從車輛定位和標(biāo)定中獲取,大多基于在線地圖或與離線建立的HD地圖信息進(jìn)行匹配。 ? 我們假設(shè)傳感器是相機和LiDAR。神經(jīng)網(wǎng)絡(luò)模型可以處理原始數(shù)據(jù),包括:輸出中間表征(IR)、場景分割和目標(biāo)檢測。為統(tǒng)一協(xié)同空間,原始數(shù)據(jù)映射到BEV(鳥瞰視圖),處理結(jié)果也位于相同的空間中。 ? 為了保持有限的尺度空間,保留多個IR層,如3層,這允許不同數(shù)據(jù)分辨率的靈活融合。V2X協(xié)同感知需要接收端做更多工作,整合來自其他車輛和路側(cè)的信息,分別融合IR、分割和檢測。融合模塊可以使用CNN、Transformer或圖神經(jīng)網(wǎng)絡(luò)(GNN)。 注意:FCL代表全連接層原始數(shù)據(jù)需要"壓縮"模塊和"解壓縮"模塊;"插值"模塊和"運動補償"模塊對基于時間同步的信號和基于在線建圖/定位/HD地圖(離線構(gòu)建)的相對姿態(tài)的接收器都是有用的。 ?
10 仿真
在封閉道路或公共道路上進(jìn)行實車測試既不安全,成本又高,而且并不總是可重復(fù)的。模擬測試有助于填補這項空白,然而,模擬測試的問題在于:它的好壞取決于用來測試的模擬器和模擬場景對于真實環(huán)境的代表性程度[17]。 ? 理想的仿真效果應(yīng)該盡可能接近現(xiàn)實。然而,這意味著模擬器必須模擬三維場景環(huán)境方面高度精細(xì),并在汽車物理等底層車輛計算方面非常精確。因此,需要在三維場景的精細(xì)度度和車輛動力學(xué)的簡化之間進(jìn)行權(quán)衡。 ? 一般來說,從虛擬場景中學(xué)到的駕駛知識需要遷移到現(xiàn)實世界中,因此如何將在模擬場景中學(xué)到的駕駛知識適應(yīng)到現(xiàn)實中成為一個關(guān)鍵問題。虛擬世界和現(xiàn)實世界之間的差距通常被稱為"現(xiàn)實差距"。為了處理這種差距,人們提出了各種方法,分為兩類:從仿真到現(xiàn)實的知識轉(zhuǎn)移(sim2real)和在數(shù)字孿生中學(xué)習(xí)(real2sim)[44]。 ? 在sim2real中逐漸發(fā)展出6種方法,包括課程學(xué)習(xí)、材料學(xué)習(xí)、知識提煉、魯棒性強化學(xué)習(xí)、領(lǐng)域隨機化和遷移學(xué)習(xí)。基于數(shù)字孿生的方法旨在利用傳感器和物理模型的數(shù)據(jù),在仿真環(huán)境中構(gòu)建真實世界物理實體的映射,達(dá)到反映相應(yīng)物理實體全生命周期過程的作用,如AR(增強現(xiàn)實)和MR(混合現(xiàn)實)。 ? 盡管仿真的自動駕駛測試系統(tǒng)相對便宜而且安全,但為了評估而制作的安全關(guān)鍵場景對于管理風(fēng)險和降低成本更為重要[22]。實際上,安全關(guān)鍵場景在現(xiàn)實世界中并不多見,因此在仿真中生成這些場景數(shù)據(jù)的各種方法被投入研究,生成方式分為三種類型:數(shù)據(jù)驅(qū)動生成,即僅利用收集到的數(shù)據(jù)集信息生成場景;對抗生成,即利用部署在仿真中的自動駕駛車輛的反饋信息生成場景;基于知識的生成,即主要利用外部知識信息作為生成場景的約束或指導(dǎo)。 ?
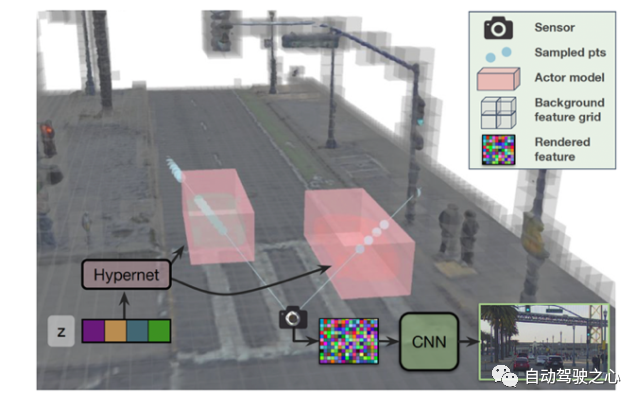
圖 13 UniSim傳感器模擬器概述 ? 這里我們報告一個最新的神經(jīng)傳感器仿真平臺[49]-UniSim,由Waabi、Toronto 和MIT構(gòu)建。UniSim將車輛傳感器捕獲的單個記錄日志轉(zhuǎn)換為逼真的閉環(huán)多傳感器仿真作為可編輯和可控制的數(shù)字孿生。圖13展示了UniSim的概況。 ? 如圖13所示,UniSim是一個神經(jīng)閉環(huán)仿真器,它聯(lián)合學(xué)習(xí)靜態(tài)場景和動態(tài)行為者的形狀和外觀表示,從對環(huán)境的單次通過中捕獲的傳感器數(shù)據(jù)。為了更好地處理外推視角,為動態(tài)對象引入了可學(xué)習(xí)的先驗知識,并利用卷積網(wǎng)絡(luò)完成未見區(qū)域。 ? 此外,UniSim中的3D場景被分為靜態(tài)背景(灰色)和一組動態(tài)行為者(紅色)。神經(jīng)特征場對靜態(tài)背景和動態(tài)行為者模型進(jìn)行單獨訪問,并執(zhí)行體繪制以生成神經(jīng)特征描述符。靜態(tài)場景由稀疏特征網(wǎng)格建模,并使用Hypernet從可學(xué)習(xí)潛在空間生成每個參與者的表示。最后,使用CNN將特征解碼為圖像。 ? 注意:一類稱為擴散模型[50]的新興生成模型,具有正向過程和反向過程的通用過程,以學(xué)習(xí)數(shù)據(jù)分布以及采樣過程以生成新數(shù)據(jù),在計算機視覺中獲得了重大關(guān)注。最近,它在圖像到圖像、文本到圖像、3D形狀生成、人體運動合成、視頻合成等方面變得越來越受歡迎。期待擴散模型為自動駕駛中的仿真器合成可想象的駕駛場景內(nèi)容。 ?
11 安全性
安全性是實際部署自動駕駛系統(tǒng)(ADS)的主要挑戰(zhàn)[19,23]。除了傳感器和網(wǎng)絡(luò)系統(tǒng)的可能受到傳統(tǒng)攻擊之外,基于人工智能或機器學(xué)習(xí)(包括深度學(xué)習(xí))的系統(tǒng),尤其需要考慮神經(jīng)網(wǎng)絡(luò)天生易受來自對抗性示例的對抗性攻擊所帶來的新的安全問題。 ? ISO 26262道路車輛——功能安全是廣泛使用的安全指導(dǎo)標(biāo)準(zhǔn),僅適用于緩解與已知部件故障相關(guān)的已知不合理風(fēng)險(即已知不安全情景)。但不適用于因復(fù)雜的環(huán)境變化以及ADS如何應(yīng)對它們而產(chǎn)生的AV駕駛風(fēng)險,而車輛不存在技術(shù)故障 ? 目前,對抗防御可以分為主動防御和被動防御。主動防御集中于改善目標(biāo)AI模型的魯棒性,而被動防御則針對檢測反向示例,然后再將它們反饋到模型中。主動防御方法主要有五種類型:對抗訓(xùn)練、網(wǎng)絡(luò)蒸餾、網(wǎng)絡(luò)正則化、模型集成和認(rèn)證防御。被動防御主要包括以下兩類:對抗檢測和對抗轉(zhuǎn)換。 ? 可解釋性是由深度神經(jīng)網(wǎng)絡(luò)的黑盒特性引起的一個問題。簡單地說,它應(yīng)該為深度學(xué)習(xí)模型的行為提供人類可以理解的解釋。解釋過程可以分為兩個步驟:提取步驟和展示步驟。提取步驟獲得中間表征,展示步驟以簡單的方式將其呈現(xiàn)給人類。在自動駕駛中,可視化模型主干中的特征圖或管理解碼器輸出的損失,是增強可解釋性的有效方式。 ? 為了提供安全保證,需要針對ADS將面臨的現(xiàn)實世界中的各種場景進(jìn)行大量的驗證和確認(rèn)(V&V)。V&V最大化場景覆蓋率的一個常規(guī)策略是在模擬生成的大量包含ADS的場景樣本。確保合理覆蓋率的方法分為兩類:基于場景抽樣的方法和形式化方法。 ? 場景抽樣方法是人工智能安全控制的主要方法,包括基于測試的抽樣和基于偽造的抽樣,基于測試的抽樣是為了以最小的代價獲得最大的場景覆蓋率,基于偽造的抽樣是為了發(fā)現(xiàn)開發(fā)人員更關(guān)注的不常見案例,如安全關(guān)鍵場景。 ?

圖 14 SOTIF的目標(biāo)[23] ? ISO 21448《預(yù)定功能安全》(SOTIF)提出了一個定性目標(biāo),從高層次描述了如何最小化ADS功能設(shè)計中已知和未知的不安全場景后果[23],如圖14所示。基于采樣的方法在發(fā)現(xiàn)未知的不安全場景時偏差較小,更具探索性,并且從未知到已知的過程中,所有采樣場景都在一致的仿真環(huán)境和相同的保真度水平下進(jìn)行。 ? 在AV安全性中廣泛使用的常規(guī)方法包括模型檢查、可達(dá)性分析和定理證明。模型檢查來自軟件開發(fā),以確保軟件行為遵循設(shè)計規(guī)范。當(dāng)安全規(guī)范以公理和引理描述時,然后進(jìn)行定理證明以使用最壞情況假設(shè)來證明安全性。由于可達(dá)性分析可以對動態(tài)駕駛?cè)蝿?wù)(DDT)的特征給出安全聲明,它估計DDT的特征,例如Mobileye的安全模型RSS(責(zé)任敏感安全)和Nvidia的安全模型SFF(安全力場)。 ?
12 數(shù)據(jù)閉環(huán)
從車輛采集數(shù)據(jù)、篩選有價值的數(shù)據(jù)、標(biāo)注數(shù)據(jù)、訓(xùn)練/優(yōu)化預(yù)期模型、驗證目標(biāo)模型并部署到車輛上等過程,構(gòu)成了自動駕駛研發(fā)的數(shù)據(jù)閉環(huán)[37-41],如圖15所示。 ?
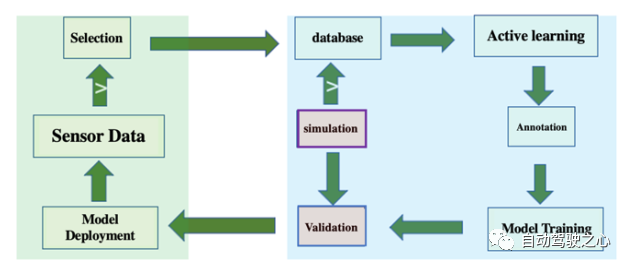
圖 15 自動駕駛研發(fā)的數(shù)據(jù)閉環(huán) ? 作為自動駕駛研發(fā)平臺,數(shù)據(jù)閉環(huán)應(yīng)包括客戶端車端和服務(wù)器云端,實現(xiàn)車端數(shù)據(jù)采集和初步篩選、云端數(shù)據(jù)庫基于主動學(xué)習(xí)的挖掘、自動標(biāo)注、模型訓(xùn)練和仿真測試(仿真數(shù)據(jù)也可加入模型訓(xùn)練)、模型部署回車端。數(shù)據(jù)選擇/篩選和數(shù)據(jù)標(biāo)注/標(biāo)注是決定數(shù)據(jù)閉環(huán)效率的關(guān)鍵模塊。 ?
12.1 數(shù)據(jù)選擇
特斯拉是第一家在量產(chǎn)車上明確提出數(shù)據(jù)選擇策略的公司,被稱為在線"影子模式"。可以看出,數(shù)據(jù)選擇分為兩種方式:一種是在線方式,將數(shù)據(jù)采集的觸發(fā)模式設(shè)置在人類駕駛的車輛上,這樣可以最經(jīng)濟地采集到所需的數(shù)據(jù);這種方式大多用于量產(chǎn)和商務(wù)階段(注:商務(wù)車配備安全操作員通常直接手動觸發(fā)采集)。另一種是離線數(shù)據(jù)庫模式,一般采用數(shù)據(jù)挖掘模式,在云服務(wù)器中對增量數(shù)據(jù)進(jìn)行篩選,這種模式常用于研發(fā)階段,即使是量產(chǎn)階段采集的數(shù)據(jù)也會在服務(wù)器端數(shù)據(jù)中心進(jìn)行二次篩選;此外,在已知場景或目標(biāo)數(shù)據(jù)嚴(yán)重缺乏的情況下,也可以在車輛或服務(wù)器端設(shè)置"內(nèi)容搜索"模式,搜索類似的物體、場景或場景數(shù)據(jù),以提高訓(xùn)練數(shù)據(jù)的多樣性和模型的泛化能力。 ? 在自動駕駛領(lǐng)域,邊緣情況也有等同或類似的概念,如異常數(shù)據(jù)、新奇數(shù)據(jù)、異常值數(shù)據(jù)、分布外數(shù)據(jù)(OOD)等。邊緣情況檢測可分為在線和離線兩種模式。在線模式通常用作安全監(jiān)測和預(yù)警系統(tǒng),而離線模式通常用于在實驗室中開發(fā)新算法,選擇合適的訓(xùn)練和測試數(shù)據(jù)。邊緣情況可以定義在幾個不同的層次:1)像素/體素;2)域;3)對象;4)場景;5)情景。最后一個情景級別的極端情況通常不僅與感知相關(guān),還涉及預(yù)測和決策規(guī)劃。 ?

圖 16 在線和離線數(shù)據(jù)選擇 ? 在此,我們提出一個在線和離線數(shù)據(jù)選擇框架,如圖16所示。在圖16(a)所示的在線模式下,我們采用多種篩選路徑,如場景搜索、陰影模式、駕駛操作和單類分類。在內(nèi)容搜索模式下,基于給定的查詢,"場景/情景搜索"模塊從圖像或連續(xù)幀中提取特征(空間或時間信息)進(jìn)行模式匹配,以發(fā)現(xiàn)特定的對象、情境或交通行為,例如夜間街道上出現(xiàn)的摩托車、惡劣天氣下高速公路上的大貨車、環(huán)島中的車輛和行人、高速路上的變道、街道交叉口的掉頭行為等。 ? “陰影模式"模塊根據(jù)車載自動駕駛系統(tǒng)(ADS)的結(jié)果進(jìn)行判斷,如感知模塊中不同攝像頭檢測到的物體匹配錯誤、連續(xù)幀檢測到的抖動或突然消失、隧道出入口強烈的光照變化,以及決策規(guī)劃中要求車輛減速但車輛實際加速或要求車輛加速但車輛實際減速的行為,檢測到前方障礙物但未試圖避讓、變道時接近并幾乎與后側(cè)攝像頭檢測到的車輛相撞等異常情況。 ? ”駕駛操作"模塊將從車輛CAN總線獲得的偏航率、速度等數(shù)據(jù)中檢測異常情況,如奇怪的之字形現(xiàn)象、過度加速或制動、大角度轉(zhuǎn)向或轉(zhuǎn)彎角度,甚至觸發(fā)突然緊急制動(AEB)。 ? "單類分類"模塊一般為感知、預(yù)測和規(guī)劃中的數(shù)據(jù)進(jìn)行訓(xùn)練異常檢測器,這是一種廣義的數(shù)據(jù)驅(qū)動的"影子模式";它依據(jù)感知特征、預(yù)測軌跡和規(guī)劃路徑的正常駕駛數(shù)據(jù);對于車端的輕量化任務(wù),則采用單類SVM模型。 ? 最后,根據(jù)采集路徑對"數(shù)據(jù)采集"模塊中對采集到的數(shù)據(jù)進(jìn)行標(biāo)注。 ? 對于圖16(b)所示的離線模式,我們同樣選擇多條路徑進(jìn)行數(shù)據(jù)篩選。無論是從研發(fā)數(shù)據(jù)采集車還是量產(chǎn)商業(yè)車上采集的新數(shù)據(jù),都將存儲在"臨時存儲"硬盤中,以備二次選擇。同樣,另一個"場景/情景搜索"模塊根據(jù)定義的某種情景的直接檢索數(shù)據(jù)。應(yīng)用的算法/模型規(guī)模更大,計算耗時更長,但不受實時性的限制。此外,還可以使用數(shù)據(jù)挖掘技術(shù)。聚類"模塊將執(zhí)行一些無監(jiān)督的分組方法或密度估計方法來生成場景聚類。因此,某些遠(yuǎn)離聚類中心點的數(shù)據(jù)會產(chǎn)生異常。 ? 為了進(jìn)一步篩選數(shù)據(jù),可以分步驟在數(shù)據(jù)上運行自動駕駛軟件(如LogSim風(fēng)格),并可以在一系列設(shè)計的檢查點上檢測到異常。這里,自動駕駛采用模塊化過程,包括"感知/定位/融合"模塊、"預(yù)測/時間域融合"模塊和"規(guī)劃和決策"模塊。每個模塊的輸出是一個檢查點,通過"單類分類"模塊檢測異常。因為沒有實時限制,所采用這種異常檢測器更復(fù)雜。在服務(wù)器端,可以使用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行單類分類。這是一種離線的“影子模式”。 ?

圖 17 預(yù)測模塊 ? "感知/定位/融合"模塊的架構(gòu)與圖6相似。"預(yù)測/時空融合"模塊作為額外的輸出頭,其結(jié)構(gòu)圖如圖17所示。特征進(jìn)入"時序編碼"模塊,該模塊的結(jié)構(gòu)可以設(shè)計為類似于RNN(GRU或LSTM)模型或基于圖神經(jīng)網(wǎng)絡(luò)(GNN)的交互建模器,融合多幀特征。運動解碼"模塊理解類似于BEVerse模型的時空特征,并輸出預(yù)測軌跡。 ?

圖 18 規(guī)劃和決策模塊 ? 在感知和預(yù)測的基礎(chǔ)上,我們設(shè)計了與ST-P3類似的規(guī)劃決策算法框圖,如圖18所示。基于預(yù)測輸出的BEV時空特征,我們選擇了基于采樣的規(guī)劃方法,在 "Plan Decod"模塊中訓(xùn)練代價函數(shù)來計算采樣器生成的各種軌跡,并在"ArgMin"模塊中找到代價最小的軌跡。代價函數(shù)包括安全性(避開障礙物)、交通規(guī)則和軌跡平滑性(加速度和曲率)等方面。最后,對整個感知-預(yù)測-規(guī)劃過程的全局損失函數(shù)進(jìn)行優(yōu)化。 ? 綜上所述,BEV/Occupancy網(wǎng)絡(luò)為基礎(chǔ)的感知、預(yù)測和規(guī)劃構(gòu)成了一個端到端的自動駕駛解決方案,稱為BP3。 ?
12.2 數(shù)據(jù)標(biāo)注
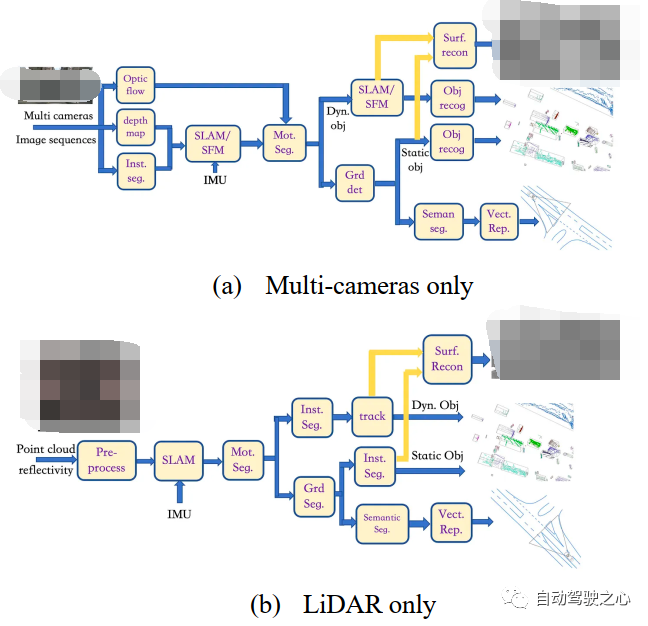
數(shù)據(jù)標(biāo)注的任務(wù)分為研發(fā)階段和量產(chǎn)階段:1)研發(fā)階段主要涉及研發(fā)團(tuán)隊的數(shù)據(jù)采集車,包括LiDAR,使LiDAR能夠為相機的圖像數(shù)據(jù)提供三維點云數(shù)據(jù),從而提供三維地面真實值。例如,BEV(鳥瞰)視覺感知需要從二維圖像中獲取BEV輸出,這涉及到透視投影和三維信息推測;2)在量產(chǎn)階段,數(shù)據(jù)主要由乘用車客戶或商用車運營客戶提供。其中大部分沒有LiDAR數(shù)據(jù),或者只有有限FOV(如前向)的三維點云。因此,對于相機圖像輸入,需要估計或重建三維數(shù)據(jù)以進(jìn)行標(biāo)注。 ? 在圖6中,我們展示了基于深度學(xué)習(xí)的端到端(E2E)數(shù)據(jù)標(biāo)注模型。然而,為了訓(xùn)練這樣一個E2E模型,我們需要大量的標(biāo)注數(shù)據(jù)。為了緩解數(shù)據(jù)需求,我們提出了一個半傳統(tǒng)的標(biāo)注框架,它是經(jīng)典計算機視覺和深度學(xué)習(xí)的混合體,如圖19所示。
?
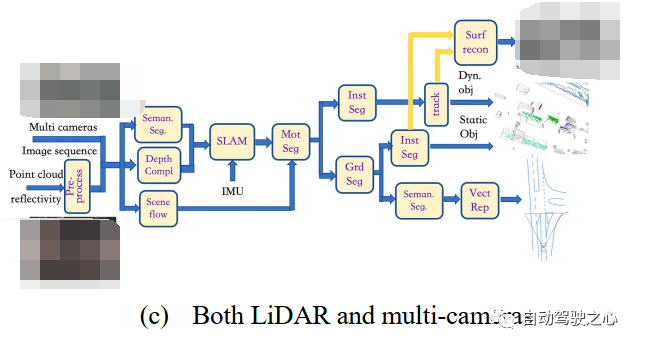
圖 19 半傳統(tǒng)的數(shù)據(jù)標(biāo)注框架 ? 對于僅相機多輸入,如圖19(a)所示,我們首先在多個相機的圖像序列中使用三個模塊,即"inst seg"、"depth map"和"optical flow",以計算實例分割圖、深度圖和光流圖;"inst seg"模塊使用深度學(xué)習(xí)模型定位和分類一些對象像素,如車輛和行人;"depth map"模塊使用深度學(xué)習(xí)模型根據(jù)單目視頻估計兩個連續(xù)幀之間的像素運動,形成虛擬立體視覺來推斷深度圖;"optical flow"模塊使用深度學(xué)習(xí)模型直接推斷兩個連續(xù)幀之間的像素運動;基于深度圖估計,"SLAM/SFM"模塊可以獲得類似RGB-D+IMU傳感器的稠密3D重構(gòu)點云;與此同時,實例分割結(jié)果實際上可以剔除障礙物,如車輛和行人;通過"motseg"模塊,獲得的各種運動障礙物將在下一個"SLAM/SFM"模塊(不輸入IMU)中重建,這類似于RGB-D傳感器的SLAM架構(gòu),可以看作單目SLAM的擴展;然后,它將"instseg"的結(jié)果轉(zhuǎn)移到"obj recog"模塊,并標(biāo)注點云的3D包圍框;對于靜態(tài)背景,"grd det"模塊將區(qū)分靜態(tài)障礙物和道路點云,以便靜止障礙物(如停車車輛和交通錐)將"inst seg"模塊的結(jié)果轉(zhuǎn)移到"obj recog"模塊,對點云的3D邊界框進(jìn)行標(biāo)注;從"SLAM/SFM"模塊獲得的動態(tài)對象點云和從"grd det"模塊獲得的靜態(tài)對象點云進(jìn)入"Surf Recon"模塊進(jìn)行泊松重建;道路表面點云僅提供擬合的3D道路表面;從圖像域"inst seg"模塊可以獲得道路表面區(qū)域;基于自身運動學(xué),可以進(jìn)行圖像拼接;在"seman seg"模塊在拼接的道路表面圖像之后,可以獲得車道標(biāo)線、斑馬線和道路邊界;然后,在"vectrep"模塊中使用多線標(biāo)注;最后,所有標(biāo)注都投影到車輛坐標(biāo)系上,得到一幀的最終標(biāo)注。 ? 圖19(b)所示,對于僅LiDAR輸入,我們經(jīng)過"預(yù)處理"模塊、"SLAM"模塊和"mot seg "模塊。在"inst seg"模塊中,直接對不同于背景的運動物體進(jìn)行基于點云的檢測;使用神經(jīng)網(wǎng)絡(luò)模型(如PointNet和PointPillar)從點云中提取特征圖;對于靜態(tài)背景,經(jīng)過"Grd Seg"模塊后,判斷為非路面的點云進(jìn)入另一個"Inst Seg"模塊進(jìn)行物體檢測,得到靜態(tài)物體的三維邊界框標(biāo)注;對于路面點云,應(yīng)用"Semantic Seg"模塊,基于深度學(xué)習(xí)模型,利用反射強度對與圖像數(shù)據(jù)相似的語義對象進(jìn)行像素級分類,即車道標(biāo)線、斑馬線、道路區(qū)域等;通過檢測道路邊界得到路緣石位置,最后在"Vect Rep"模塊中進(jìn)行多邊形的標(biāo)注;跟蹤到的動態(tài)物體點云和實例分割得到的靜態(tài)物體點云進(jìn)入"surf recon"模塊,進(jìn)行泊松重建;最后,將所有標(biāo)注投影到車輛坐標(biāo)系上得到一幀的最終標(biāo)注。 ? 對于圖19(c)所示具有LiDAR和多相機的輸入,我們將圖19(a)中的"光流"模塊替換為"場景流"模塊,"場景流"模塊使用深度學(xué)習(xí)模型估計三維點云的運動;"深度圖"模塊替換為"深度填充"模塊,"深度填充"模塊使用神經(jīng)網(wǎng)絡(luò)模型完成深度填充,深度填充由點云投影(插值和"填補空洞")到圖像平面得到,然后反向投影回三維空間生成點云;同時,"seg inst"模塊替換為"seman seg"模塊,該模塊使用深度學(xué)習(xí)模型標(biāo)注點云;隨后,稠密的點云和IMU數(shù)據(jù)將進(jìn)入"SLAM"模塊進(jìn)行運動軌跡估計,并選擇標(biāo)記為障礙物(車輛和行人)的點云;同時,估計的場景流也將進(jìn)入"mot seg"模塊,進(jìn)一步區(qū)分運動障礙物和靜態(tài)障礙物;運動物體通過"inst seg"模塊和"track"模塊后,得到運動物體的標(biāo)注;同樣,靜態(tài)障礙物通過"grd seg"模塊后,由"inst seg"模塊標(biāo)注;車道標(biāo)線、斑馬線、道路邊緣等地圖元素通過"seman seg"模塊得到;拼接后的路面圖像和對齊后的點云進(jìn)入"vect rep"模塊進(jìn)行多邊形標(biāo)注;通過跟蹤得到的動態(tài)物體點云和實例分割得到的靜態(tài)物體點云進(jìn)入"surf recon"模塊進(jìn)行泊松重建;最后將所有標(biāo)注投影到車輛坐標(biāo)系上得到一幀的最終標(biāo)注。 ? 注意:這種半傳統(tǒng)標(biāo)注方法也被稱為4D標(biāo)注,是由特斯拉的自動駕駛團(tuán)隊首先探索。因此,所提出的數(shù)據(jù)標(biāo)注框架分兩階段運行:首先是半傳統(tǒng)4D標(biāo)注,然后是基于深度學(xué)習(xí)的端到端標(biāo)注。 ?
12.3 主動學(xué)習(xí)
自動駕駛機器學(xué)習(xí)模型的訓(xùn)練平臺可以根據(jù)邊緣情況、OOD或異常數(shù)據(jù)的檢測方法,采用合理的方法利用這些增量數(shù)據(jù)。其中,主動學(xué)習(xí)是最常用的方法,可以有效利用這些有價值的數(shù)據(jù)。主動學(xué)習(xí)是一個迭代過程,在這個過程中,每次迭代都會學(xué)習(xí)一個模型,并使用一些啟發(fā)式方法從未標(biāo)明點池中選擇一組點進(jìn)行標(biāo)注。不確定性估計是啟發(fā)式方法之一,在自動駕駛領(lǐng)域得到了廣泛應(yīng)用。不確定性有兩種主要類型:感知不確定性和偶然不確定性。感知不確定性通常被稱為模型不確定性,其估計方法主要包括集合法(Ensemble method)和蒙特卡羅剔除法(Monte Carlo dropout method);偶然不確定性被稱為數(shù)據(jù)不確定性,常用的估計方法是基于貝葉斯理論的概率機器學(xué)習(xí)。 ? 注:盡管人們大多采用監(jiān)督學(xué)習(xí)來訓(xùn)練數(shù)據(jù)閉環(huán)中的模型,但為了提高泛化、可擴展性和效率,引入了一些新的機器學(xué)習(xí)技術(shù),如半監(jiān)督學(xué)習(xí)(同時使用有標(biāo)簽和無標(biāo)簽數(shù)據(jù)),甚至自監(jiān)督學(xué)習(xí)(如流行的無標(biāo)簽數(shù)據(jù)對比學(xué)習(xí))。 ?
13 結(jié)論
在這篇關(guān)于自動駕駛的綜述中,我們概述了一些關(guān)鍵的創(chuàng)新和未解決的問題。我們提出了幾種基于深度學(xué)習(xí)的架構(gòu)模型,即BEV/占位感知、V2X中的協(xié)同感知、基于BEV/占用網(wǎng)絡(luò)的感知與預(yù)測和規(guī)劃(BP3)的端到端自動駕駛。本文的一個新觀點是,我們更關(guān)注自動駕駛研發(fā)中的數(shù)據(jù)閉環(huán)。特別是,我們提出了對應(yīng)的數(shù)據(jù)選擇/篩選和數(shù)據(jù)標(biāo)注/標(biāo)記機制來驅(qū)動數(shù)據(jù)閉環(huán)。 ?
13.1 ChatGPT 和 SOTA 大模型
最后,我們簡要討論大模型對自動駕駛領(lǐng)域及其數(shù)據(jù)閉環(huán)范式的影響。 ? 最近,由大型語言模型(LLMs)驅(qū)動的聊天系統(tǒng)(如chatGPT和PaLM)出現(xiàn)并迅速成為自然語言處理(NLP)中實現(xiàn)人工通用智能(AGI)的一個前景廣闊的方向[42]。實際上,諸如大規(guī)模預(yù)訓(xùn)練(學(xué)習(xí)整個世界網(wǎng)絡(luò)上的知識)、指令微調(diào)、提示學(xué)習(xí)、上下文學(xué)習(xí)、思維鏈(COT)和來自人類反饋的強化學(xué)習(xí)(RLHF)等關(guān)鍵創(chuàng)新在提高LLM的適應(yīng)性和性能方面發(fā)揮了重要作用。與此同時,強化偏差、隱私侵犯、有害錯覺(不真實的胡言亂語)和巨大的計算機功耗等問題也引起了人們的關(guān)注。 ? 大模型的概念已經(jīng)從NLP擴展到其他領(lǐng)域,如計算機視覺和機器人學(xué)。同時,多模態(tài)輸入或輸出的實現(xiàn)使應(yīng)用領(lǐng)域更加廣泛。視覺語言模型(VLMs)從網(wǎng)絡(luò)規(guī)模的圖像-文本對中學(xué)習(xí)豐富的視覺語言相關(guān)性,并通過單個VLM(如CLIP和PaLM-E)實現(xiàn)對各種計算機視覺任務(wù)的零樣本預(yù)測。Meta[43]提出的ImageBind是一種學(xué)習(xí)跨六種不同模態(tài)(圖像、文本、音頻、深度、熱和IMU數(shù)據(jù))聯(lián)合嵌入的方法。它實際上利用了大規(guī)模視覺語言模型,并通過與圖像配對將零樣本功能擴展到一種新的模態(tài)。 ? 擴散模型在圖像合成領(lǐng)域取得了巨大成功,并擴展到其他模態(tài),如視頻、音頻、文本、圖形和三維模型等。作為多視圖重建的一個新分支,NeRF提供了3D信息的隱式表示。擴散模型和NeRF的結(jié)合在文本到3D合成方面取得了顯著成效。 ? NavGPT是一個純粹基于LLM的指令遵循導(dǎo)航代理器,它通過在視覺語言導(dǎo)航任務(wù)中進(jìn)行零樣本預(yù)測,揭示了GPT模型在具體場景中的推理能力。NavGPT可以明確對導(dǎo)航進(jìn)行高級規(guī)劃,包括將指令分解為子目標(biāo)、整合與導(dǎo)航任務(wù)相關(guān)的常識知識、從觀察到的場景中識別地標(biāo)、跟蹤導(dǎo)航進(jìn)度以及通過計劃調(diào)整適應(yīng)異常情況。 ?
13.2 大模型在自動駕駛系統(tǒng)中的應(yīng)用
總之,LLM的出現(xiàn)使得AGI從NLP到各個領(lǐng)域,尤其是計算機視覺領(lǐng)域產(chǎn)生了連鎖反應(yīng)。自動駕駛系統(tǒng)(ADS)必將受到這一趨勢的影響。有了足夠多的海量數(shù)據(jù)和視覺語言模型,再加上NeRF和擴散模型,大模型的理念和操作將為自動駕駛帶來革命性的變化。"長尾"問題將在很大程度上得到緩解,數(shù)據(jù)閉環(huán)可能會轉(zhuǎn)變?yōu)榱硪环N閉環(huán)模式,即預(yù)訓(xùn)練+微調(diào)+強化學(xué)習(xí),更不用說輕量級車載模型的仿真平臺搭建和訓(xùn)練數(shù)據(jù)的自動標(biāo)注了。 ? 然而,我們?nèi)匀粚ζ漪敯粜浴⒖山忉屝院蛯崟r延遲表示擔(dān)憂。安全是ADS中最重要的問題,大模型中的有害信息將導(dǎo)致駕駛危險。基于規(guī)則的系統(tǒng)可以很容易地理解一些故障導(dǎo)致的結(jié)果,但深度學(xué)習(xí)模型仍然缺少性能和架構(gòu)之間的聯(lián)系。使用ADS最關(guān)鍵的是實時響應(yīng)。到目前為止,我們還沒有看到任何一個大模型的應(yīng)用可以在100毫秒內(nèi)生成結(jié)果,更不用說車載工作的內(nèi)存要求了。
編輯:黃飛
?








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論