 電子發燒友App
電子發燒友App


Birds-Eyes-View(BEV):鳥瞰圖,這個詞本身沒什么特別意義,但在自動駕駛(Autonomous Driving,簡稱AD)領域逐漸普及后變成了這個行業內的一種術語。
Simultaneous Localization and Mapping(SLAM):并發定位與地圖測繪,相對于BEV的另外一種感知技術。
Perception:感知,SLAM和BEV在AD領域里都是協助控制系統了解車輛周圍狀況的感知技術:知道自己在哪,有哪些障礙物,障礙物在自己的什么方位,距離多遠,哪些障礙物是靜態的那些是移動的,等等相關信息,便于隨后做出駕駛決策。
SLAM VS BEV:SLAM主要通過各種傳感器掃描周圍空間的物體結構,以3維數據來描述這些信息。BEV同樣通過傳感器掃描獲知周邊狀況,主要以2維數據來描述這些信息。從應用范圍來講,目前SLAM更為廣闊,在AD火起來之前主要應用在VR/AR等領域,BEV主要集中在AD行業里。從技術實現來看,SLAM偏向于傳統數學工具,包括各種幾何/概率論/圖論/群論相關的軟件包,而BEV基本上清一色的基于深度神經網絡DNN。兩者最好不要對立著看,很多情況下可以互補。
以下將側重于BEV的基礎介紹。
SLAM和BEV最基礎和核心的傳感器就是相機(Camera),所以兩者在計算過程中有大量的算力都被消耗在了圖像中信息提取/識別和變換計算。SLAM傾向于識別圖像中的特征(Feature)點,屬于特征信息里的低級信息,通過計算這些特征點在不同圖像幀上的位置來獲取場景結構以及相機自身的位姿(Position and Pose)。而BEV傾向于識別車輛/道路/行人/障礙物等等高級特征信息,這些是卷積網CNN和Transformer擅長的。
相機有兩個最基礎的數據:內參(Instrinsics)和外參(Extrinsics),內參主要描述的是相機的CCD/CMOS感光片尺寸/分辨率以及光學鏡頭的系數,外參主要描述的是相機在世界坐標系下的擺放位置和朝向角度。
其中內參的常見矩陣是:

其中fx和fy分別表示光學鏡頭的橫向/縱向焦距長度(Focus),正常情況下焦距是不分橫縱向的,但因為CCD/CMOS感光片上的像素單元不夠正,如果這個像素是絕對的正方形,那么fx = fy,實際上很難做到,有微小的差異,導致光線經過鏡頭投射到感光片上后,橫縱坐標在單位距離上出現不等距的問題,所以相機模塊的廠家會測量這個差異并給出fx和fy來,當然開發者也可以利用標定(calibration)過程來測量這兩個值。
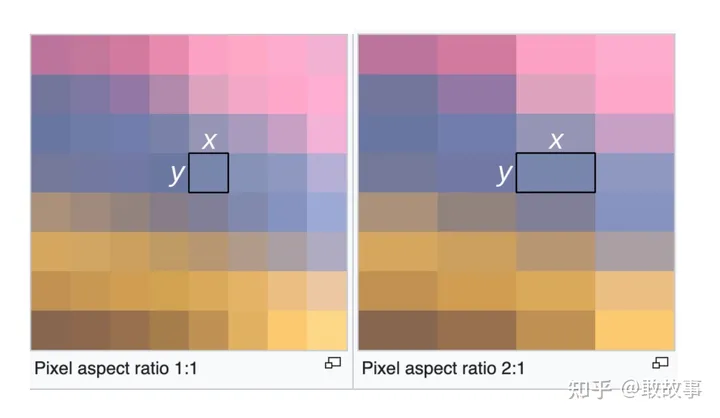
圖1
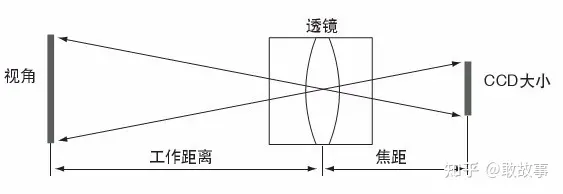
圖2
另外,在傳統的光學領域里,fx和fy的默認單位是毫米:mm,但在這個領域默認單位是像素:Pixel,導致很多有攝影經驗的人看到fx和fy的值都挺納悶,特別大,動不動就是大幾千,這數值都遠超業余天文望遠鏡了。為什么這里用像素?我們試著通過內參計算一下相機的FOV(Field of View,視場大小,通常以角度為單位)就明白了:
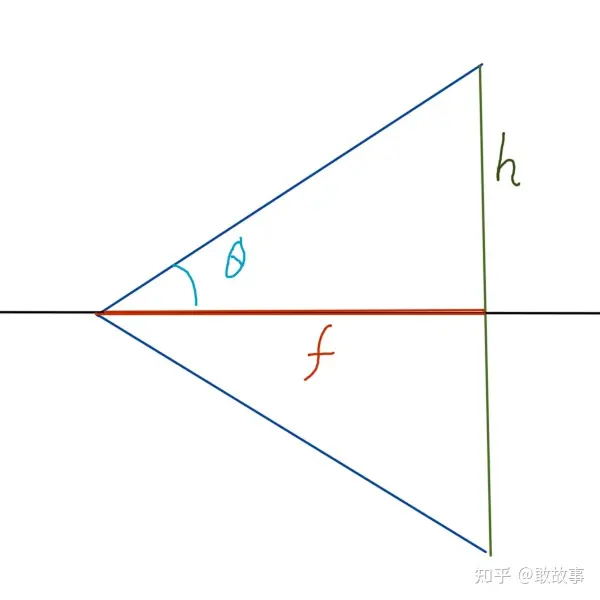
圖3
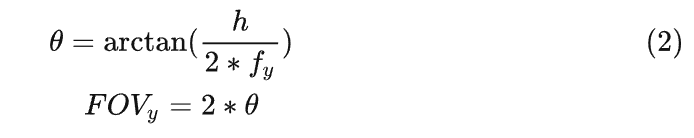
這里fy是縱向焦距,h是照片高度。因為h的單位是像素,所以fy也必須是像素,這樣才好便于計算機處理,所以fx和fy的單位就統一成了像素。其實都不用到計算機這步,CCD/CMOS感光片一般是要集成另外一塊芯片ISP(Image Signal Processor)的,這塊芯片內部就要把感光數據轉成數字化的圖片,這里就可以用像素單位了。
內參除了這個矩陣外還有一套畸變(Distortion)系數K,這個東西不詳細說了,正常的鏡頭成像后都是居中位置的變形小,四周變形大,一般通過標定(Calibration)獲得這個參數后,對照片做反畸變處理,恢復出一個相對“正常”的照片。SLAM算法里很強調這個反畸變的重要性,因為特征點在照片上的絕對位置直接關系到了定位和建圖的準確性,而大部分的BEV代碼里看不到這個反畸變處理,一方面是BEV注重物體級別的高級特征,像素級別的輕微偏移影響不大,另一方面是很多BEV項目都是為了寫論文,采用了類似nuScenes/Argoverse這類訓練數據,這些數據的畸變比較小而已,一旦你在自己的項目里用了奇怪的鏡頭還是老老實實得做反畸變預處理。
圖4
外參就簡單多了,一個偏移(Transform)系數加一個旋轉(Rotation)系數。
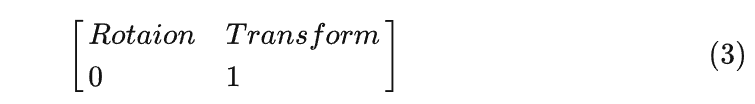
3維空間里表述旋轉的計算方式常見的有2種:矩陣(Matrix)和四元數(Quaternion),為了防止矩陣方式存在萬向節死鎖(Gimbal Lock)問題,通常采用四元數來計算旋轉。但在AD領域里很少這么干,因為相機是固定在車子上,只有垂直于地面的軸(一般是Z軸)才會發生360度的旋轉,根本無法引發萬向節問題,總不至于用戶堅持在翻車的階段仍舊保持自動駕駛這個詭異的需求。所以BEV的代碼里通常就是矩陣形式,SLAM因為還會用在AR和其它領域,相機不是相對固定的,所以會采用四元數。另外,AD領域里不考慮透視現象,所以外參都是仿射矩陣(Affine Matrix),這點和CG領域的3維渲染是不同的。
另外,一般文章里介紹內參時還會考慮旋轉偏差,這是由于CCD/CMOS感光片在工廠里被機器給裝歪了,但AD領域一般不會考慮它,誤差太小,而相機安裝在車輛上時本身外參就有很大的相對旋轉,不如一并算了,最后交由DNN學習過濾掉,而AR領域里的SLAM更是要主動計算外參,這點毛毛雨就不考慮了。
內外參了解之后,下一個基礎的重點就是坐標系。AD的坐標系有好幾個,不事先理清楚就直接看代碼有點暈。
世界坐標系(World Coordination),這個是真實世界空間里,車輛的位置和方位角,通常粗略的位置是由GNSS(Global Navigation Satellite System)衛星定位系統獲取,GNSS包括了美國GPS/中國BDS/歐洲Galileo/毛子GLONASS/日本QZSS/印度IRNSS,各有千秋,定位精度一言難盡,一般標稱的精度都是指:車輛在空曠地區,上面有好幾顆定位衛星罩著你,車輛靜止,定位設備天線粗壯,無其它信號源干擾的情況下的測試結果。如果你處在城市內,四周高樓林立,各種無線電干擾源,衛星相對你時隱時現,車速還不慢,這種情況下給你偏個幾十米都是對的起你了。為此有兩種常見解決方案:差分基站糾偏和地圖通行大數據糾偏。這能給你造成一種錯覺:衛星定位還是蠻準的。不管怎么弄,最后得到的坐標位置是經緯度,但跟常規GIS(Geographic Information System)相比,AD的經緯度不是球面坐標系,而是展開成2維地圖的坐標系,所以最終在系統內的坐標系也是有區別的,比如google會把WGS84的經緯度換算成它自家地圖的矩形切片編碼,Uber提出過一種六邊形切片的H3坐標編碼,百度則是在火星坐標的基礎上疊加了一個BD09的矩形切片坐標,等等諸如此類。這些都是絕對坐標位置,而通過類似SLAM技術掃描的高精度地圖還會在這個基礎上引入一些相對坐標。不管怎么樣,最后在代碼里看到的只剩下XY了。但這些系統都不能獲取車輛朝向(地理正北為0度,地理正東為90度,依此類推,這仍舊是在2維地圖上表示方式),所以AD里的車輛角度都是指“軌跡朝向”,用當前位置坐標減去上一時刻的坐標獲得一個指向性的矢量。當然在高精度地圖的加持下,是可以通過SLAM技術算出車輛的瞬時方位角。在缺失GNSS定位的時候,比如過隧道,需要用車輛的IMU(Inertial Measurement Unit)這類芯片做慣性導航補充,它們提供的數值是一個相對的坐標偏移,但隨著時間的推移累積誤差大,所以長時間沒有GNSS信號的時候,IMU表示也沒辦法。
BEV訓練數據集的世界坐標系(nuScenes World Coordination,其它訓練集就不特別說明了),這個跟GNSS的絕對坐標系就不同了:
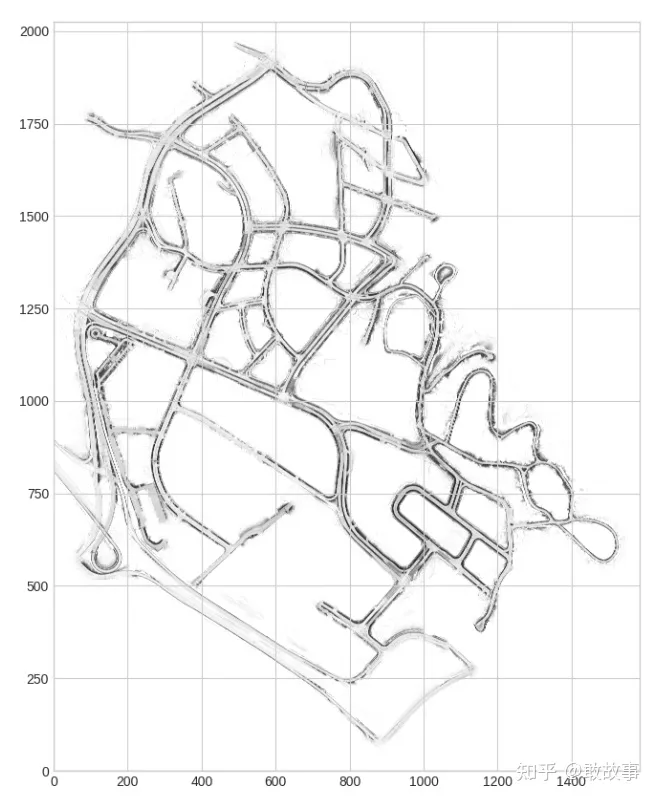
圖5
這是一個nuScenes地圖,它的世界坐標系是圖片坐標系,原點在圖片左下角,單位是米,因此在使用訓練數據集時,是不用考慮經緯度的。數據集中會根據時間序列給出車輛的瞬時位置,也就是在這個圖片上的XY。
Ego坐標系(Ego Coordination),在BEV里,這個Ego是特指車輛本身,它是用來描述攝像機/激光雷達(Lidar,light detection and ranging)/毫米波雷達(一般代碼里就簡稱為Radar)/IMU在車身上的安裝位置(單位默認都是米)和朝向角度,坐標原點一般是車身中間,朝向如圖:
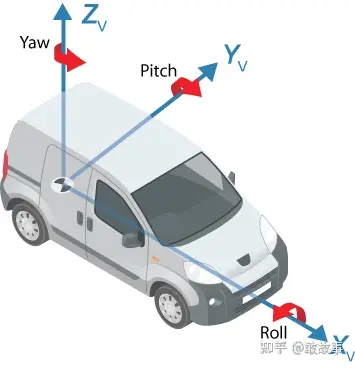
圖6
所以車頭正放的相機默認都是Yaw(Z軸)為0度,外參(Extrinsics Matrix)主要就是描述這個坐標系的。
相機坐標系(Camera Coordination),切記,這個不是照片坐標系,坐標原點在CCD/CMOS感光片的中央,單位是像素,內參(Intrinsics Matrix)主要就是描述這個坐標系的。
照片坐標系(Image Coordination),坐標原點在圖片的左上角,單位是像素,橫縱坐標軸一般不寫成XY,而是uv。
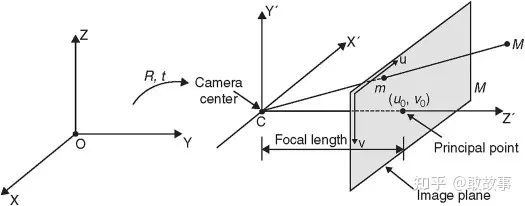
圖7
左中右三套坐標系分別為:Ego Coordination, Camera Coordination, Image Coordination。
所以,當在BEV中做LSS(Lift,Splat,Shoot)時,需要把照片中的像素位置轉換到世界坐標系時,要經歷:
Image_to_Camera, Camera_to_Ego, Ego_to_World,用矩陣表示:
Position_in_World = Inv_World_to_Ego * Inv_Ego_to_Camera * Inv_Camera_to_Image * (Position_in_Image)
其中Inv_表示矩陣的逆。實際代碼里,Camera_to_Image通常就是Intrinsics參數矩陣,Ego_to_Camera就是Extrinsics參數矩陣。
這里要注意的一點是:fx,fy,它們實際上是這樣計算得到的:

Fx和Fy分別是橫向/縱向的鏡頭焦距,但單位是米,Dx和Dy分別是一個像素有幾米寬幾米高,得出fx和fy的單位就是像素。當使用(Ego_to_Camera * Camera_to_Image)矩陣乘上Ego空間的坐標,會以像素為單位投影到照片空間,當使用(Inv_Ego_to_Camera * Inv_Camera_to_Image)矩陣乘上照片空間的坐標,會以米為單位投影到Ego空間,不會有單位上的問題。
大部分的BEV是多攝像頭的,意味著要一次性把多組攝像頭拍攝的照片像素換算到Ego或者世界坐標系:
在統一的坐標系下,多角度的照片才能正確得“環繞”出周邊的景象。另外還有一些單目(Monocular)攝像頭的BEV方案,它們有的不考慮Ego坐標系,因為只有一個朝向正前方(Yaw,Pitch,Roll全部為0)的攝像頭,而且原點就是這個攝像頭本身,所以直接從相機坐標系跳到世界坐標系。
Frustum,這個東西在3維渲染領域通常叫做“視錐體”,用來表示相機的可視范圍:
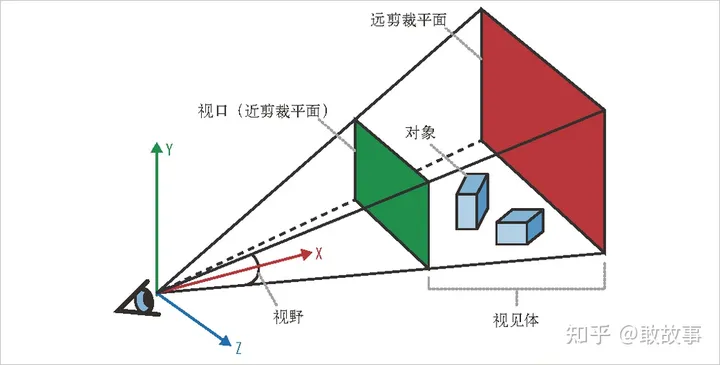
圖9
紅面和綠面以及線框包圍起來的空間就是視錐體,綠面通常叫做近平面(Near Plane),紅面叫做遠平面(Far Plane),線框構成的角度叫做FOV,如果CCD/CMOS成像的高寬相同,那么近平面和遠平面就都是正方形,一個FOV就足以表示,反之,就要區分為FOVx和FOVy了,超出這個視錐體范圍的物體都不考慮進計算。圖7中由6個三角面構成了組合的可視范圍,實際上應該是6個俯視的視錐體構成,能看出視錐體之間是有交疊區域的,這些區域有利于DNN在訓練/推理中對6組數據做相互矯正,提高模型準確性,在不增加相機數量的前提下,如果想擴大這個交疊區域,就必須選擇FOV更大的相機,但FOV越大的相機一般鏡頭畸變就會越嚴重(反畸變再怎么做也只能一定程度上的矯正圖片),物體在圖片上的成像面積也越小,干擾DNN對圖片上特征的識別和提取。
BEV是個龐大的算法族,傾向于不同方向的算法選擇,粗略得看,有Tesla主導的以視覺感知流派,核心算法建立在多路攝像頭上,另外一大類是激光雷達+毫米波雷達+多路攝像頭的融合(Fusion)派,國內很多AD公司都是融合派的,Google的Waymo也是。
嚴格得講,Tesla正在從BEV(Hydranet)過渡到一種新的技術:Occupancy Network,從2維提升到3維:
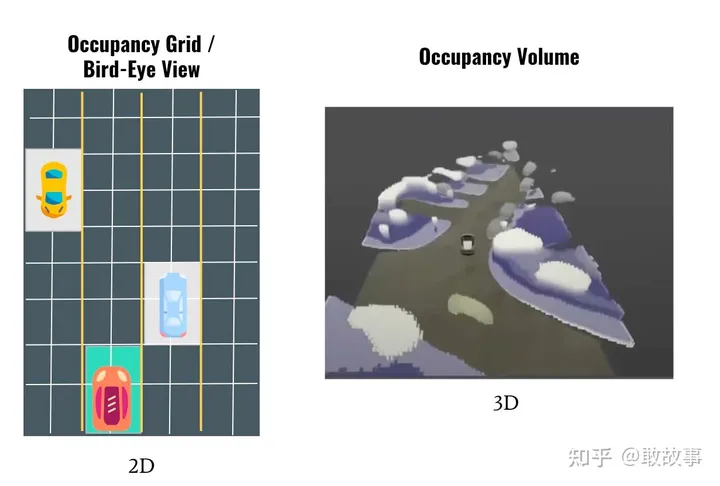
圖10
無論是2維的還是3維的,都在試圖描述周遭空間的Occupany(占用)情況,只是一個用2維棋盤格來表述這種占用情況,一個是用3維的積木方式表述占用。DNN在度量這種占用時采用的是概率,比如我們直觀看到某個格子上是一輛車,而DNN給出的原始結果是:這個格子上,是車的可能性有80%,是路面的可能性為5%,是行人的可能性為3%。。。。。所以,在BEV代碼里,一般將各種可能出現的物體分了類,通常是兩大類:
不常變化的:車輛可通信區域(Driveable),路面(Road),車道(Lane),建筑(Building),植被(Foliage/Vegetation),停車區域(Parking),信號燈(Traffic Light)以及一些未分類靜態物體(Static),它們之間的關系是可以相互包容的,比如Driveable可以包含Road/Lane等等。
可變的,也就是會發生移動的物體:行人(Pedestrian),小汽車(Car),卡車(Truck),錐形交通標/安全桶(Traffic Cone)等等
這樣分類的目的是便于AD做后續的駕駛規劃(Planning,有的翻譯成決策)和控制(Control)。而BEV在感知(Perception)階段就是按照這些物體在格子上出現的概率打分,最后通過Softmax函數將概率歸一取出最大的那個可能性作為占用這個格子的物體類型。
但這有個小問題:BEV的DNN模型(Model)在訓練階段,是要指明照片中各個物體是啥?也就是要在標注數據(Labeled Data)上給各種物體打上類型標簽的:
右邊的我們權當做是標注數據吧,左邊是對應的相片,按照這個物體分類訓練出來的DNN模型,真得跑上路面,如果遭遇了訓練集里未出現的物體類型怎么辦?如果模型效果不好,比如某個姿勢奇葩的人體未被識別成行人和其它已知類型,又當如何?Occupancy Network為此改變的感知策略,不再強調分類了(不是不分類,只是重點變了),核心關注路面上是否有障礙物(Obstacle),先保證別撞上去就行了,別管它是什么類型。3維的積木方式表述這種障礙物更為貼切,有的地方借用了3維渲染(Rendering/Shading)領域的常見概念把這種3維表述叫做體素(Voxel),想象一下我的世界(MineCraft)就很簡單了。
以上是視覺流派的簡述,混合派在干嘛?它們除了相機外,還側重于激光雷達的數據,毫米波雷達由于數據品相太差逐漸退出,留守的去充當停車雷達了,也不能說它一無是處,Tesla雖然強調視覺處理,但也保留了一路朝向正前方的毫米波雷達,而且AD這個領域技術變化非常快,冷不丁哪天有新算法冒出又能把毫米波雷達的價值發揚光大一把。
激光雷達的好處是什么:可以直接測出物體的遠近,精度比視覺推測出的場景深度要高很多,一般會轉化為深度(Depth)數據或者點云(Point Cloud),這兩者配套的算法有很長的歷史了,所以AD可以直接借用,減少開發量。另外,激光雷達可以在夜間或糟糕的天氣環境下工作,相機就抓瞎了。
但這幾天出現了一種新的感知技術HADAR(Heat-Assisted Detection and Ranging),可以和相機/激光雷達/毫米波雷達并列的傳感器級別感知技術。它的特點是利用特殊的算法把常規熱成像在夜間拍攝的圖片轉化為周圍環境/物體的紋理和深度,這個東西和相機配合能解決夜間視覺感知的問題。
以前的BEV為什么不提熱成像/紅外相機,因為傳統算法有些明顯的缺陷:只能提供場景的熱量分布,形成一張灰度(Gray)圖,缺乏紋理(Texture),原始數據缺乏深度信息,推算出的深度精度差,如果僅僅通過從灰度圖上提取的輪廓(Contour)和亮度過渡(Gradient),很難精確還原場景/物體的體積信息,并且目前的2維物體識別是很依賴紋理和色彩的。這個HADAR的出現,恰好可以解決這個問題:在較暗的環境下提取場景的深度以及紋理:
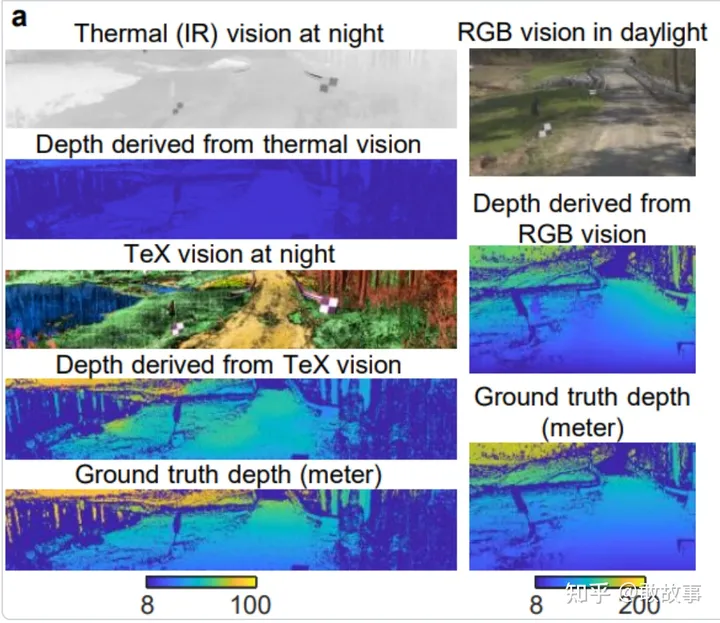
圖13
左列,自上而下:
基礎的熱成像,簡稱T
用常規熱成像算法從T提取的深度
用HADAR算法從T提取的紋理圖
用HADAR算法從T提取的深度
真實場景的深度
右列,自上而下:
這個場景在白天用可見光相機拍攝的照片
通過照片推理的深度
真實場景的深度
HADAR的這個深度信息老牛逼了,對比一下激光雷達的效果就知道了:
激光雷達的掃描范圍是有限的,一般半徑100米,從上圖可以看出,沒有紋理信息,遠處的場景也沒有深度了,掃描線導致其數據是個稀疏(Sparse)結構,想要覆蓋半徑更大更稠密(Dense)就必須買更昂貴的型號,最好是停下來多掃一段時間。激光雷達模塊廠家在展示產品時,當然得給出更好看的圖了,只有AD研發人員才知道這里面有多苦。
以上都是基礎的概念,作為BEV算法的入門,必須先提到LSS(Lift,Splat,Shoot):
https://link.zhihu.com/?target=https%3A//github.com/nv-tlabs/lift-splat-shoot
老黃家的,很多文章都把它列為BEV的開山(Groundbreaking)之作。它構建了一個簡單有效的處理過程:
把相機的照片從2維數據投影成3維數據,然后像打蒼蠅一樣把它拍扁,再從上帝視角來看這個被拍扁的場景,特別符合人看地圖的直覺模式。一般看到這里會有疑惑的:都已經建立了3維的場景數據,3維不香么?干嘛還要拍扁?不是不想要3維,是沒辦法,它不是一個完善的3維數據:

圖15
看過這玩意吧,它就是LSS的本質,從正面看,能形成一張2維照片,這個照片被LSS拉伸到3維空間后就是上圖,你從BEV的視角也就是正上方向下看會是啥?什么都看不出來,所以后續要拍扁(Splat),具體過程是這樣:
先提取圖像特征和深度(Feature and Depth,LSS里是同時提取的,后面會具體解釋),深度圖類似
只能說類似,并不準確,后面也會具體說明的,這個深度信息可以構建一個偽3D模型(Point Cloud點云模式),類似圖15:

圖18
看著還行,但把這個3D模型轉到BEV俯視角下,估計親娘都認不出來了:

圖19
拍扁后結合特征Feature再做一次語義識別,形成:
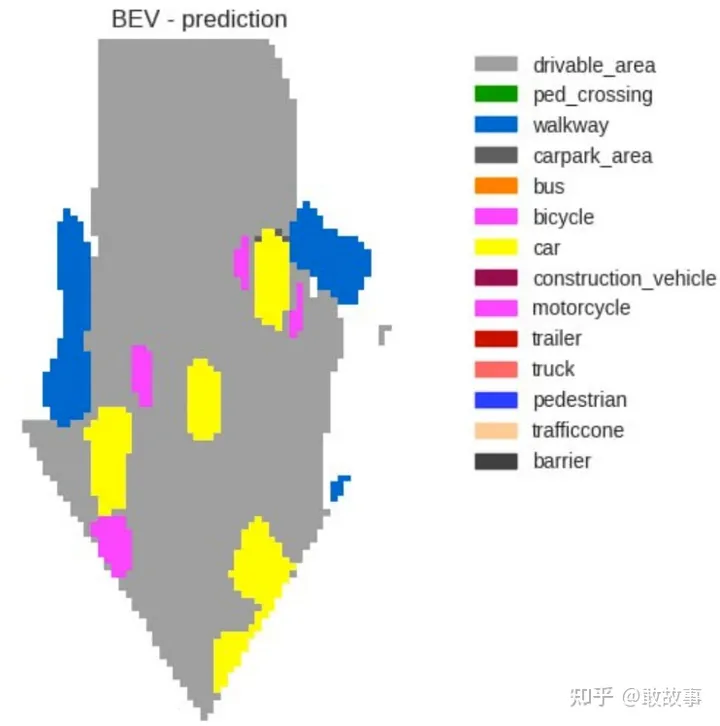
圖20
這個就是喜聞樂見的BEV圖了。以上是對LSS的直觀認知,算法層面是如何實現的?
先給單個相機可拍攝的范圍構建一個立方體模樣的鐵絲籠子(高8寬22深41),祭出大殺器Blender:

圖21
這里是示意圖,不要糾結于格子的數量和尺寸。這個3D網格代表的是一路相機的視錐體(Frustum),前面貼過視錐體的形狀(圖9),這里變形成立方體,在相機空間里看這個照片和這個立體網格的關系就是:

圖22
右邊是個正對著網格立方體的相機示意圖,相片提取深度后(深度圖的實際像素尺寸是高8寬22):

圖23
把這個深度圖按照每個像素的深度沿著紅線方向展開(Lift)后:

圖24
可以看到,部分深度像素已經超出了視錐體的范圍,因為LSS一開始就假設了這么個有限范圍的籠子,超出部分直接過濾掉。這里必須提醒一下:LSS并不是直接算出每個像素的深度,而是推理出每個像素可能處于籠子里每個格子的概率,圖24是已經通過Softmax提取出每個像素最有可能位于哪個格子,然后把它裝進對應格子的示意結果,便于理解,更準確的描述如下:
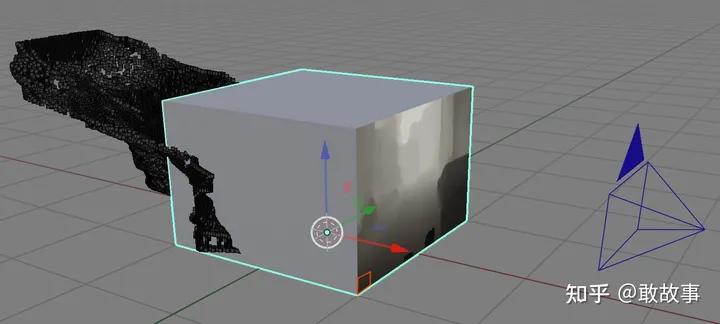
圖25
在圖25中選取深度圖的某個像素(紅色格子,事實上LSS的深度圖分辨率是很小的,默認只有8*22像素,所以這里可以用一個格子當做一個像素),它隸屬于籠子下方邊沿的一條深度格子(這條格子其實就代表相機沿著深度看向遠方的一條視線):

圖26
圖25中的那個紅色的深度像素,沿著圖26這條視線格子的概率分布就是:
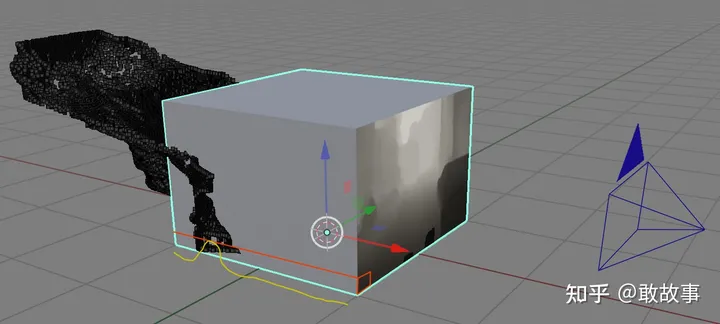
圖27
黃線的起伏表示2D深度圖像素在Lift后沿著視線3D深度的概率分布(Depth Distribution,我這是示意性得畫法,不是嚴格按照實際數據做的)。等價于LSS論文里的這張圖:
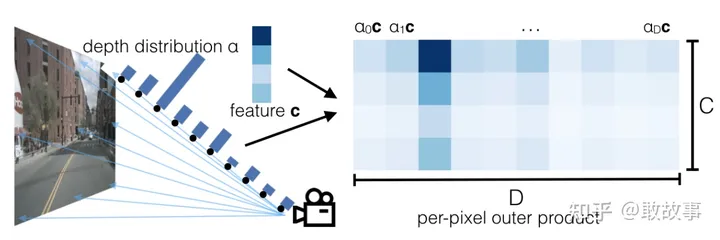
圖28
LSS中構建立方籠子的代碼位于:
?
?
class?LiftSplatShoot(nn.Module): ????def?__init__(self,?grid_conf,?data_aug_conf,?outC): ????????self.frustum?=?self.create_frustum() ????def?create_frustum(self): ????????#?D?x?H?x?W?x?3 ????????frustum?=?torch.stack((xs,?ys,?ds),?-1) ????????return?nn.Parameter(frustum,?requires_grad=False) ????def?get_geometry(self,?rots,?trans,?intrins,?post_rots,?post_trans): ????????"""Determine?the?(x,y,z)?locations?(in?the?ego?frame) ????????of?the?points?in?the?point?cloud. ????????Returns?B?x?N?x?D?x?H/downsample?x?W/downsample?x?3 ????????""" ????????B,?N,?_?=?trans.shape ????????#?undo?post-transformation ????????#?B?x?N?x?D?x?H?x?W?x?3 ????????points?=?self.frustum?-?post_trans.view(B,?N,?1,?1,?1,?3) ????????points?=?torch.inverse(post_rots).view(B,?N,?1,?1,?1,?3,?3).matmul(points.unsqueeze(-1)) ????????#?cam_to_ego ????????points?=?torch.cat((points[:,?:,?:,?:,?:,?:2]?*?points[:,?:,?:,?:,?:,?2:3], ????????????????????????????points[:,?:,?:,?:,?:,?2:3] ????????????????????????????),?5) ????????combine?=?rots.matmul(torch.inverse(intrins)) ????????points?=?combine.view(B,?N,?1,?1,?1,?3,?3).matmul(points).squeeze(-1) ????????points?+=?trans.view(B,?N,?1,?1,?1,?3) ????????return?points
?
?
為了便于分析,我裁減了代碼。單個相機的frustum尺寸為:D x H x W x 3(深度D:41,高度H:8,寬度W:22),也就是創建了一個D x H x W的容器,容器的每個格子里存儲了這個格子的坐標值(X,Y,Z)。
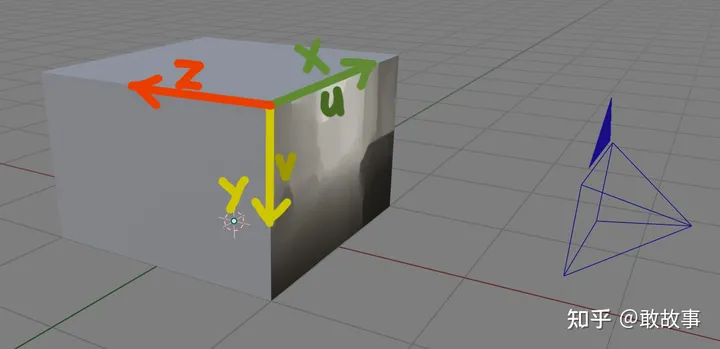
圖29
實際上是在照片坐標系(uv)上拓展了一個深度Z構成的新坐標系。由于LSS默認是5路攝像頭,把5個Frustum送到get_geometry函數里,會輸出5路Frustum構成的一個組合籠子,其張量尺寸變為:B x N x D x H x W x 3,其中B是batch_size,默認是4組訓練數據,N是相機數量5。
get_geometry里一開始要做一個
?
?
?#?undo?post-transformation?
?
?
這玩意是干啥的?這跟訓練集有關,在深度學習里里,有一種增強現有訓練樣本的方法,一般叫做Augmentation(其實AR技術里這個A就是Augmentation,增強的意思),通過把現有的訓練數據做一些隨機的:翻轉/平移/縮放/裁減,給樣本添加一些隨機噪音(Noise)。比如,在不做樣本增強前,相機的角度是不變的,訓練后的模型只認這個角度的照片,而隨機增強后再訓練,模型可以學習出一定角度范圍變化內的適應性,也就是Robustness。
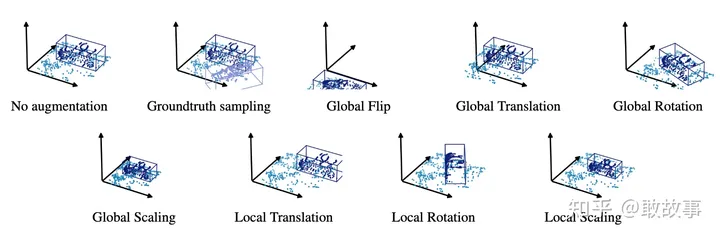
圖30
Augmentation技術也是有相關理論和方法的,這里就貼個圖不贅述了。數據增強的代碼一般都是位于DataLoader內:
?
?
class?NuscData(torch.utils.data.Dataset): ???def?sample_augmentation(self):
?
?
回到剛才的get_geometry,數據增強會給照片增加一些隨機變化,但相機本身是必須固定的,這樣才能讓DNN模型學習這些隨機變化的規律并去適應它們。所以將5路Frustum的安置到車身坐標系時候要先去掉(undo)這些隨機變化。
然后通過:
?
?
#?cam_to_ego ????????points?=?torch.cat((points[:,?:,?:,?:,?:,?:2]?*?points[:,?:,?:,?:,?:,?2:3], ????????????????????????????points[:,?:,?:,?:,?:,?2:3] ????????????????????????????),?5) ????????combine?=?rots.matmul(torch.inverse(intrins)) ????????points?=?combine.view(B,?N,?1,?1,?1,?3,?3).matmul(points).squeeze(-1) ????????points?+=?trans.view(B,?N,?1,?1,?1,?3)
?
?
將各路Frustum從相機坐標系轉入車輛自身坐標系,注意這里的intrins是相機內參,rots和trans是相機外參,這些都是nuScenes訓練集提供的,這里只有intrincs用了逆矩陣,而外參沒有,因為nuScenes是先把每個相機放在車身原點,然后按照各路相機的位姿先做偏移trans再做旋轉rots,這里就不用做逆運算了。如果換個數據集或者自己架設相機采集數據,要搞清楚這些變換矩陣的定義和計算順序。
四視圖大概就是這個樣子:
圖31
LSS中推理深度和相片特征的模塊位于:
?
?
class?CamEncode(nn.Module):
????def?__init__(self,?D,?C,?downsample):
????????super(CamEncode,?self).__init__()
????????self.D?=?D
????????self.C?=?C
????????self.trunk?=?EfficientNet.from_pretrained("efficientnet-b0")
????????self.up1?=?Up(320+112,?512)
????????self.depthnet?=?nn.Conv2d(512,?self.D?+?self.C,?kernel_size=1,?padding=0)
?
?
trunk用于同時推理原始的深度和圖片特征,depthnet用于將trunk輸出的原始數據解釋成LSS所需的信息,depthnet雖是卷積網但卷積核(Kernel)尺寸只有1個像素,功能接近一個全連接網FC(Full Connected),FC日常的工作是:分類或者擬合,對圖片特征而言,它這里類似分類,對深度特征而言,它這里類似擬合一個深度概率分布。EfficientNet是一種優化過的ResNet,就當做一個高級的卷積網(CNN)看吧。對于這個卷積網而言,圖片特征和深度特征在邏輯上沒有區別,兩者都位于trunk上的同一個維度,只是區分了channel而已。
這就引出了另外一個話題:從單張2D圖片上是如何推理/提取深度特征的。這類問題一般叫做:Monocular Depth Estimation,單目深度估計。一般這類系統內部分兩個階段:粗加工(Coarse Prediction)和精加工(Refine Prediction),粗加工對整個畫面做一個場景級別的簡單深度推測,精加工是在這個基礎上識別更細小的物體并推測出更精細的深度。這類似畫家先用簡筆畫出場景輪廓,然后再細致勾勒局部畫面。
除了用卷積網來解決這類深度估計問題,還有用圖卷積網(GCN)和Transformer來做的,還有依賴測距設備(RangeFinder)輔助的DNN模型,這個話題先不展開了,龐雜程度不亞于BEV本身。
那么LSS這里僅僅采用了一個trunk就搞定深度特征是不是太兒戲了,事實上確實如此。LSS估計出的深度準頭和分辨率極差,參看BEVDepth項目里對LSS深度問題的各種測試報告:
https://link.zhihu.com/?target=https%3A//github.com/Megvii-BaseDetection/BEVDepth
BEVDepth的測試里發現:如果把LSS深度估計部分的參數換成一個隨機數,并且不參與學習過程(Back Propagation),其BEV的總體測試效果只有很小幅度的降低。但必須要說明,Lift的機制本身是很強的,這個突破性的方法本身沒問題,只是深度估計這個環節可以再加強。
LSS的訓練過程還有另外一個問題:相片上大約有1半的數據對訓練的貢獻度為0,其實這個問題是大部分BEV算法都存在的:
右邊的標注數據實際上只描述了照片紅線以下的區域,紅線上半部都浪費了,你要問LSS里的模型對上半部都計算了些什么,我也不知道,因為沒有標注數據可以對應上,而大部分的BEV都是這么訓練的,所以這是一個普遍現象。訓練時,BEV都會選擇一個固定面積范圍的周遭標注數據,而照片一般會拍攝到更遠的景物,這兩者在范圍上天生就是不匹配的,另一方面部分訓練集只關注路面標注,缺乏建筑,因為眼下BEV主要解決的是駕駛問題,不關心建筑/植被。
這也是為什么圖17哪里的深度圖和LSS內部真實的深度圖是不一致的,真實深度圖只有接近路面這部分才有有效數據:

圖33
所以整個BEV的DNN模型勢必有部分算力被浪費了。目前沒看到任何論文關于這方面的研究。
接著繼續深入LSS的Lift-Splat計算過程:
?
?
def?get_depth_feat(self,?x): ????????x?=?self.get_eff_depth(x) ????????#?Depth ????????x?=?self.depthnet(x) ????????depth?=?self.get_depth_dist(x[:,?:self.D]) ????????new_x?=?depth.unsqueeze(1)?*?x[:,?self.D:(self.D?+?self.C)].unsqueeze(2) ????????return?depth,?new_x???? ???def?get_voxels(self,?x,?rots,?trans,?intrins,?post_rots,?post_trans): ????????geom?=?self.get_geometry(rots,?trans,?intrins,?post_rots,?post_trans) ????????x?=?self.get_cam_feats(x) ????????x?=?self.voxel_pooling(geom,?x) ????????return?x
?
?
這里的new_x是把深度概率分布直接乘上了圖片紋理特征,為了便于直觀理解,我們假設圖片特征有3個channel:c1,c2,c3,深度只有3格:d1,d2,d3。我們從圖片上取某個像素,那么它們分別代表的意義是:c1:這個像素點有70%的可能性是車子,c2:有20%的可能性是路,c3:有10%的可能性是信號燈, d1:這個像素有80%的可能是在深度1,d2:有15%的可能性是在深度2,d3:有%5的可能性是在深度3上。如果把它們相乘的到:
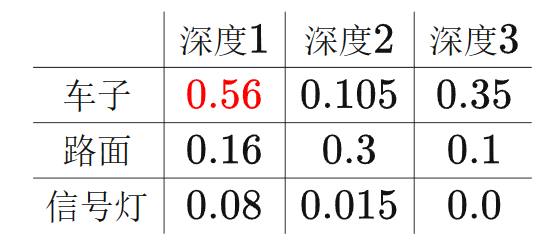
那么這個像素最大的概率是:位于深度1的一輛車子。這也就是LSS里:

公式的意義,注意它這里把圖像特征叫做c(Context), a_d的意義是深度沿視線格子的概率分布,d是深度。new_x就是這個計算結果。前面說過,由于圖像特征和深度都是通過trunk訓練出來的,它們位于同一維度,只是占用channel不同,深度占用了前self.D(41)個channel,Context占用了后面self.C(64)個channel。
由于new_x是分別按照每路相機的Frustum單獨計算的,而5個Frustum有重疊區域,須要做作數據融合,所以在voxel_pooling里計算好格子的索引和對應的空間位置,通過這個對應關系,把new_x的內容一一裝入指定索引的格子。
LSS在voxel_pooling的計算力引入了cumsum這個機制,雖然有很多文章在解釋它,但這里不建議花太多功夫,它只是一個計算上的小技巧,對整個LSS是錦上添花的事,不是必要的。
編輯:黃飛
?













 工商網監
工商網監
評論