 電子發(fā)燒友App
電子發(fā)燒友App


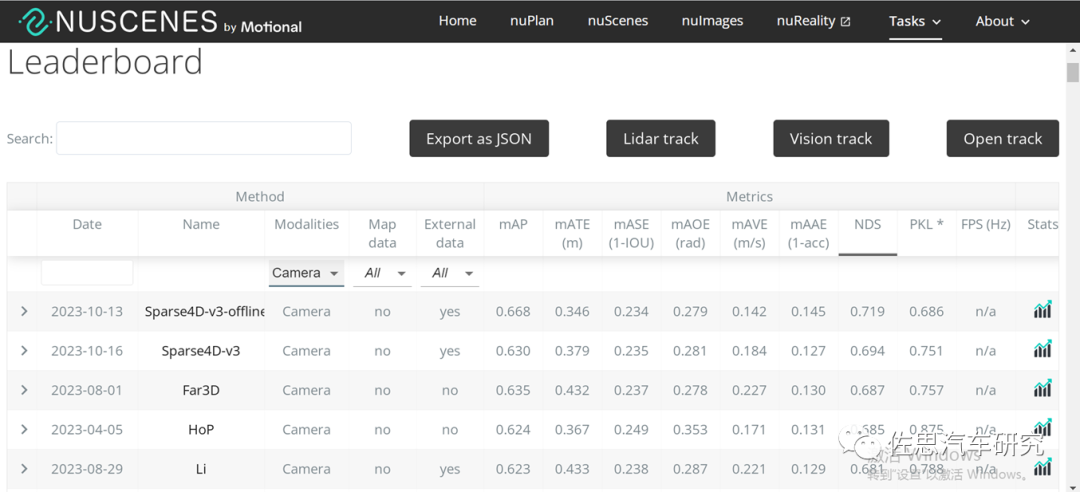
目前學(xué)術(shù)圈還是用“打榜”來對自動駕駛算法評分,所謂“打榜”是指在某一數(shù)據(jù)集上利用其訓(xùn)練數(shù)據(jù)集測試算法的優(yōu)劣勢,目前自動駕駛?cè)?nèi)最常用的打榜數(shù)據(jù)集是安波福Aptiv旗下的nuScenes。nuScenes數(shù)據(jù)集的任務(wù)包括六大類,分別是3D目標(biāo)檢測(Detection)、目標(biāo)追蹤(Tracking)、目標(biāo)軌跡預(yù)測(Prediction)、激光雷達目標(biāo)分割(Lidar Segmentation)、全景(Panoptic)、決策(Planning)。
其中,3D目標(biāo)檢測是自動駕駛最基礎(chǔ)的任務(wù),全球有近300個團隊或企業(yè)參加了比試,也是全球自動駕駛數(shù)據(jù)集參賽者最多的,足見其權(quán)威性。華為的TransFusion出自2021年10月,當(dāng)時也曾在nuScenes數(shù)據(jù)集上打榜,并奪得第一名的位置,不過最近華為沒有打榜。
3D目標(biāo)檢測(Detection)又可分為融合算法和單一傳感器算法,其中純視覺算法第一名就是地平線Sparse4D,NDS得分高達0.719;純激光雷達算法第一名是浪潮信息和中科院的Real-Aug++,NDS得分是0.744;而激光雷達和視覺融合的第一名是零跑汽車的EA-LSS,NDS得分0.776。不難看出傳感器融合性能提升非常有限。很多人會說,特斯拉才是純視覺第一名,不過根據(jù)特斯拉AI Day的資料,特斯拉目標(biāo)感知算法骨干是META開發(fā)的Regnet,脖頸是谷歌的BiFPN,感測頭是Transformer,但特斯拉描述的比較模糊,Transformer似乎只是2D到BEV變換。特斯拉的純視覺基礎(chǔ)似乎是來自Facebook的論文《End-to-End Object Detection with Transformers》(發(fā)表于2020年5月),稀疏化之后就是DETR3D,2021年10月打榜(實際DETR3D在2020年初就有了),DETR3D曾經(jīng)打榜,NDS得分0.479,在當(dāng)年確實是第一,不過第一的位置只保持了近大半年。 ?
再就是什么是所謂端到端。傳統(tǒng)的自動駕駛系統(tǒng)通常會采用級聯(lián)式的架構(gòu),在模塊與模塊之間通常傳遞的是結(jié)構(gòu)化信息,同時在系統(tǒng)內(nèi)存在著海量人工設(shè)計的復(fù)雜規(guī)則。這使得整體的自動駕駛系統(tǒng)復(fù)雜性高、難以聯(lián)合優(yōu)化以及迭代周期比較長。而端到端的設(shè)計思路則帶來了全新的可能性。在端到端架構(gòu)中,首先各個主要的模塊都是基于神經(jīng)網(wǎng)絡(luò)的形式設(shè)計;其次模塊間也不再只是傳遞結(jié)構(gòu)化信息,而是同時傳遞稀疏實例特征表示,這使得從感知到規(guī)控的整體系統(tǒng)可以進行聯(lián)合優(yōu)化;最終的決策規(guī)劃模塊也能從更加靠前的階段獲得更豐富的信息。BEV就是端到端的典型代表。
還有一種徹底的端到端,就是英偉達在2016年的論文《End to End Learning forSelf-Driving Cars》,不產(chǎn)生中間結(jié)果,可以直接通過圖像輸入,直接輸出控制信號的徹底端到端技術(shù)路線。貌似很高大上,不過神經(jīng)網(wǎng)絡(luò)或者說AI本身就是黑盒,加上這個徹底黑盒的流程,完全不具備任何可解釋性,成敗完全取決于運氣,無法迭代,因此2020年以后再也無人提及。從自動駕駛產(chǎn)品安全性的角度來看,把每個模塊都網(wǎng)絡(luò)化并串聯(lián)在一起的技術(shù)路線,會更加可靠可行,感知的結(jié)果必須有顯式的。
與科研機構(gòu)不同,地平線是要考慮產(chǎn)品落地商業(yè)化的,從名字就可看出,地平線是要“稀疏”,從圖像空間到BEV空間的轉(zhuǎn)換,是稠密特征到稠密特征的重新排列組合,計算量比較大,與圖像尺寸以及BEV特征圖尺寸成正相關(guān)。在大家常用的nuScenes 數(shù)據(jù)中,感知范圍通常是長寬 [-50m, +50m] 的方形區(qū)域,然而在實際場景中,我們通常需要達到單向100m,甚至200m的感知距離。若要保持BEV Grid 的分辨率不變,則需要大大增加BEV 特征圖的尺寸,從而使得端上計算負擔(dān)和帶寬負擔(dān)都過重;若保持BEV特征圖的尺寸不變,則需要使用更粗的BEV Grid,感知精度就會下降。因此,在車端有限的算力條件下,BEV 方案通常難以實現(xiàn)遠距離感知和高分辨率特征的平衡。此外,BEV 空間可以看作是壓縮了高度信息的3D空間,這使得BEV范式的方法難以直接完成2D相關(guān)的任務(wù),如標(biāo)志牌和紅綠燈檢測等,感知系統(tǒng)中仍然要保留圖像域的感知模型;這也正是馬斯克展示特斯拉的v12版時,紅綠燈檢測出現(xiàn)明顯的錯誤,Occupancy Network忽略了部分2D相關(guān)任務(wù)。
特斯拉的OccupancyNetwork在找尋自由空間方面優(yōu)勢明顯,策略是避障而非減速剎車,但也有缺點,大量的無意義的靜態(tài)目標(biāo)如路兩邊的建筑物浪費了不少運算資源,按照特斯拉2022 AI Day上的資料,特斯拉的幀率大概是12fps,通常智能駕駛是30fps以上,顯然是運算資源不足導(dǎo)致的。
地平線追求一個高性能、高效率的長時序純稀疏BEV感知算法,既能提高效率也不降低性能。基礎(chǔ)還是首個稀疏的BEV感知模型,即DETR3D。《DETR3D:3D Object Detection from Multi-view Images via 3D-to-2D Queries》,作者來自五湖四海,包括麻省理工學(xué)院(MIT)、清華大學(xué)、卡梅隆大學(xué)、理想汽車(不過作者留的郵箱是斯坦福大學(xué),應(yīng)該還是學(xué)生)豐田北美研究院和斯坦福大學(xué)。
DETR3D是第一個端到端的目標(biāo)檢測模型,不需要眾多手工設(shè)計組件,如anchor、固定規(guī)則的標(biāo)簽分配策略、NMS后處理等),也是首先將tranformer引入目標(biāo)檢測的。DETR3D模型包含3個關(guān)鍵組件。第一,遵循 2D 視覺中的常見做法,使用共享的 ResNet主干從相機圖像中提取特征,視需要使用特征金字塔FPN加強這些特征。第二,一個以幾何感知方式將計算的2D特征和3D包絡(luò)框預(yù)測集合進行連接的檢測頭,檢測頭的每一層都從一組稀疏的目標(biāo)查詢開始,這些查詢是從數(shù)據(jù)中學(xué)習(xí)的。每個目標(biāo)查詢編碼一個3D位置,該位置投影到相機平面并通過雙線性插值用于收集圖像特征。DERT類似,然后我們使用多頭注意力通過合并目標(biāo)交互來優(yōu)化目標(biāo)查詢。這一層會重復(fù)多次,在特征采樣和目標(biāo)查詢優(yōu)化之間交替。最后,我們使用set-to-set損失來訓(xùn)練網(wǎng)絡(luò)。
DETR3D架構(gòu)
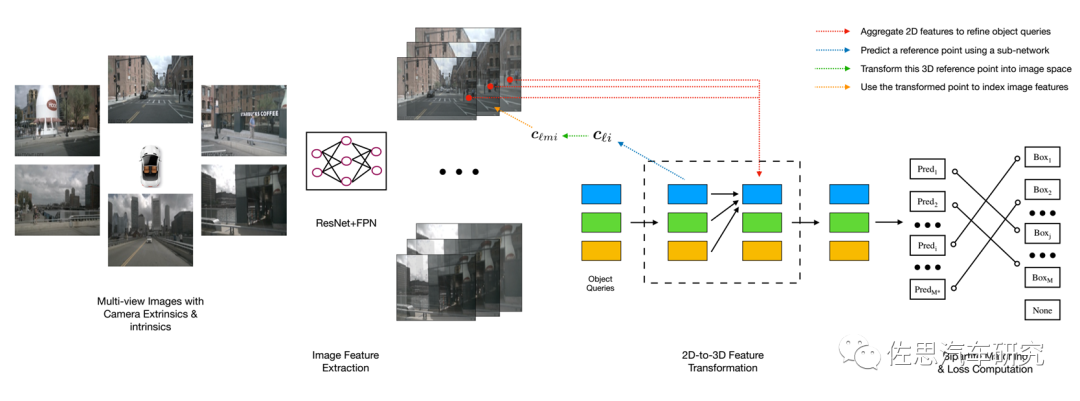
圖片來源:網(wǎng)絡(luò)
與Transformer那種全局(global)&密集(dense)的注意力機制相比,DETR3D提出了新思路:每個參考點僅關(guān)注鄰域的一組采樣點,這些采樣點的位置并非固定,而是可學(xué)習(xí)的(與可變形卷積一樣),從而實現(xiàn)了一種局部(local)&稀疏(sparse)的高效注意力機制。Transformer在計算注意力權(quán)重時,伴隨著高計算量與空間復(fù)雜度。特別是在編碼器部分,與特征像素點的數(shù)量成平方級關(guān)系,因此難以處理高分辨率的特征(這點也是DETR檢測小目標(biāo)效果差的原因),說白了就是計算量太大,高分辨率攝像頭沒法用。DETR的第一波改進就是Deformable DETR。它提出可變形注意力模塊,相比于Transformer那種方式,在這里,每個特征像素不必與所有特征像素交互計算,只需要與部分基于采樣獲得的其它像素交互即可,這就大大加速了模型收斂,同時也降低了計算復(fù)雜度與所需的空間資源。另外,該模塊能夠很方便地應(yīng)用到多尺度特征上,連FPN都不需要。
地平線做了二次改進,就是Sparse 4D。
Sparse4D概覽
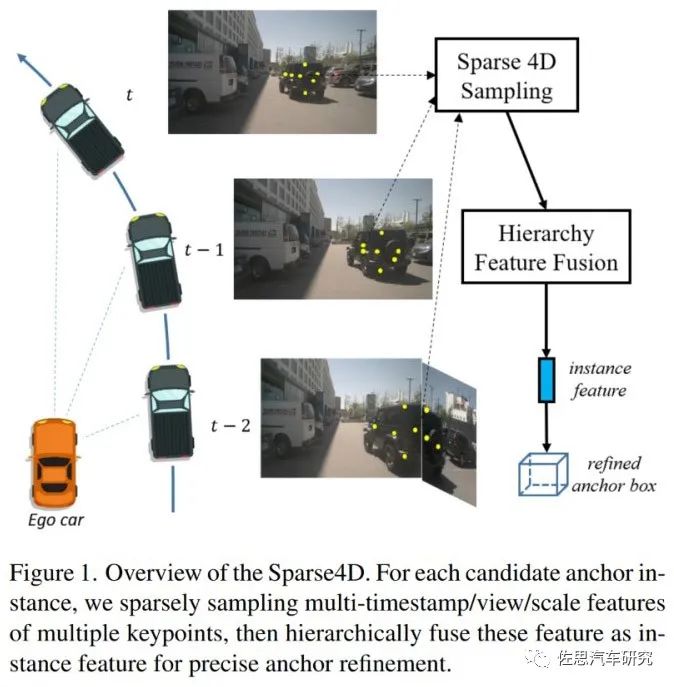
圖片來源:地平線
Sparse4D提出instance特征,即實例特征,應(yīng)該是車的實例,然后重新定義anchor盒尺寸。
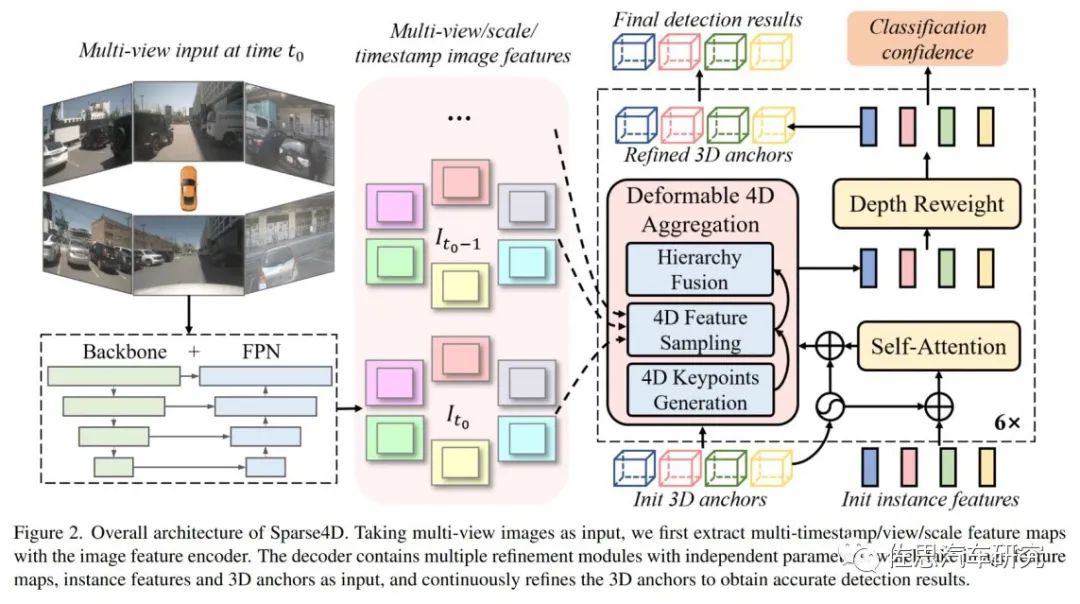
圖片來源:地平線
Sparse4D也采用了Encoder-Decoder 結(jié)構(gòu),其中Encoder包括imagebackbone和neck,用于對多視角圖像進行特征提取,得到多視角多尺度特征圖。同時,cache 多張歷史幀的圖像特征用于在decoder 中提取時序特征;Decoder為多層級聯(lián)形式,輸入時序多尺度圖像特征圖和初始化instance,輸出精細化后的instance,每層decoder包含self-attention、deformable aggregation和refine module三個主要部分。
學(xué)習(xí)2D檢測領(lǐng)域DETR改進的經(jīng)驗,重新引入了Anchor的使用,并將待感知的目標(biāo)定義為instance,每個instance主要由兩個部分構(gòu)成:目標(biāo)的高維特征,在decoder 中不斷由來自于圖像特征的采樣特征所更新;目標(biāo)結(jié)構(gòu)化的狀態(tài)信息,比如3D檢測中的目標(biāo)3D框(x, y, z, w, l, h, yaw, vx, vy);通過kmeans 算法來對anchor 的中心點分布進行初始化;同時,在網(wǎng)絡(luò)中會基于一個MLP網(wǎng)絡(luò)來對anchor的結(jié)構(gòu)化狀態(tài)進行高維空間映射得到 Anchor Embed 并與instance feature 相融合。
Anchor源自RPN,在深度學(xué)習(xí)時代,大名鼎鼎的RCNN和Fast RCNN依舊依賴滑窗來產(chǎn)生候選框,也就是Selective Search算法,該算法優(yōu)化了候選框的生成策略,但仍會產(chǎn)生大量的候選框,導(dǎo)致即使是Fast RCNN算法,在GPU上的速度也只有三、四幀每秒。直到Faster RCNN的出現(xiàn),提出了RPN網(wǎng)絡(luò),使用RPN直接預(yù)測出候選框的位置。RPN網(wǎng)絡(luò)一個最重要的概念就是anchor,啟發(fā)了后面的SSD和YOLOv2等算法,雖然SSD算法稱之為default box,也有算法叫做prior box,其實都是同一個概念,他們都是anchor的別稱。anchor就是在圖像上預(yù)設(shè)好的不同大小,不同長寬比的參照框。(其實非常類似于上面的滑窗法所設(shè)置的窗口大小)。
anchor有點定制的意味,首先你要知道你檢測的最重要的目標(biāo)類型是什么,是車還是小貓,再根據(jù)這個確定anchor,大大提高計算效率,也提高準確度,而缺點就是可能出現(xiàn)漏檢。對智能駕駛來說,最重要的目標(biāo)是車和行人,這個anchor很好確定,也可以讓網(wǎng)絡(luò)自己確定。
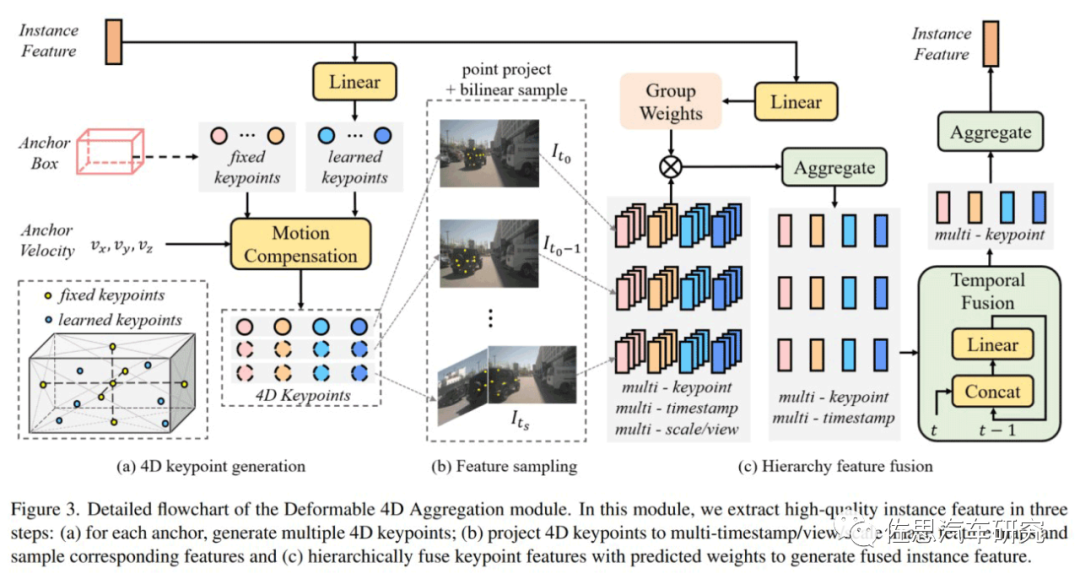
圖片來源:地平線
在Sparse4D的decoder 中,最重要的是Deformable 4D Aggreagation模塊。這個模塊主要負責(zé)instance與時序圖像特征之間的交互,如上圖所示,主要包括三個步驟:
4D關(guān)鍵點生成:首先,基于每個instance的3D anchor信息,生成一系列3D關(guān)鍵點,分為固定關(guān)鍵點和可學(xué)習(xí)關(guān)鍵點。將固定關(guān)鍵點設(shè)置為anchor box的各面中心點及其立體中心點,可學(xué)習(xí)關(guān)鍵點坐標(biāo)通過instancefeature接一層全連接網(wǎng)絡(luò)得到。在Sparse4D 中,采用了7個固定關(guān)鍵點 + 6個可學(xué)習(xí)關(guān)鍵點的配置。然后結(jié)合instance自身的速度信息以及自車的速度信息,對這些3D關(guān)鍵點進行運動補償,獲得其在歷史時刻中的位置。結(jié)合當(dāng)前幀和歷史幀的3D關(guān)鍵點,我們獲得了每個instance的4D關(guān)鍵點。
4D 特征采樣:在獲得每個instance在當(dāng)前幀和歷史幀的3D關(guān)鍵點后,根據(jù)相機的內(nèi)外參將其投影到對應(yīng)的多視角多尺度特征圖上進行雙線性插值采樣。從而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View的特征表示。
然后是層級融合,F(xiàn)use Multi-Scale/View:對于一個關(guān)鍵點在不同特征尺度和視角上的投影,采用了加權(quán)求和的方式,權(quán)重系數(shù)通過將instance feature和anchor embed輸入至全連接網(wǎng)絡(luò)中得到;Fuse Multi-Timestamp:對于時序特征,采用了簡單的recurrent策略(concat + linear)來融合;Fuse Multi-Keypoint:最后,采用求和的方式融合同一個instance不同keypoint的特征。
即便是已經(jīng)稀疏化、輕量化,由于時間T的導(dǎo)入,依然導(dǎo)致計算量偏大,第一代Sparse 4D使用ResNet50做骨干網(wǎng),輸入圖像尺寸704*256,使用英偉達RTX3090顯卡,RTX3090擁有10496個CUDA核心,328個Tensor張量核心,F(xiàn)P32算力是35.58TOPS,F(xiàn)P16張量算力是285TOPS,INT8是570TOPS,論FP32算力比A100還高,價格不到A100的1/5。
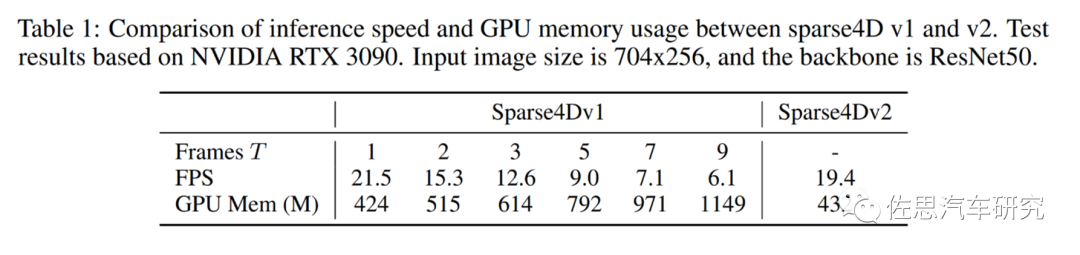
幀率偏低,消耗內(nèi)存也太多,地平線提出第二代Sparse4D。
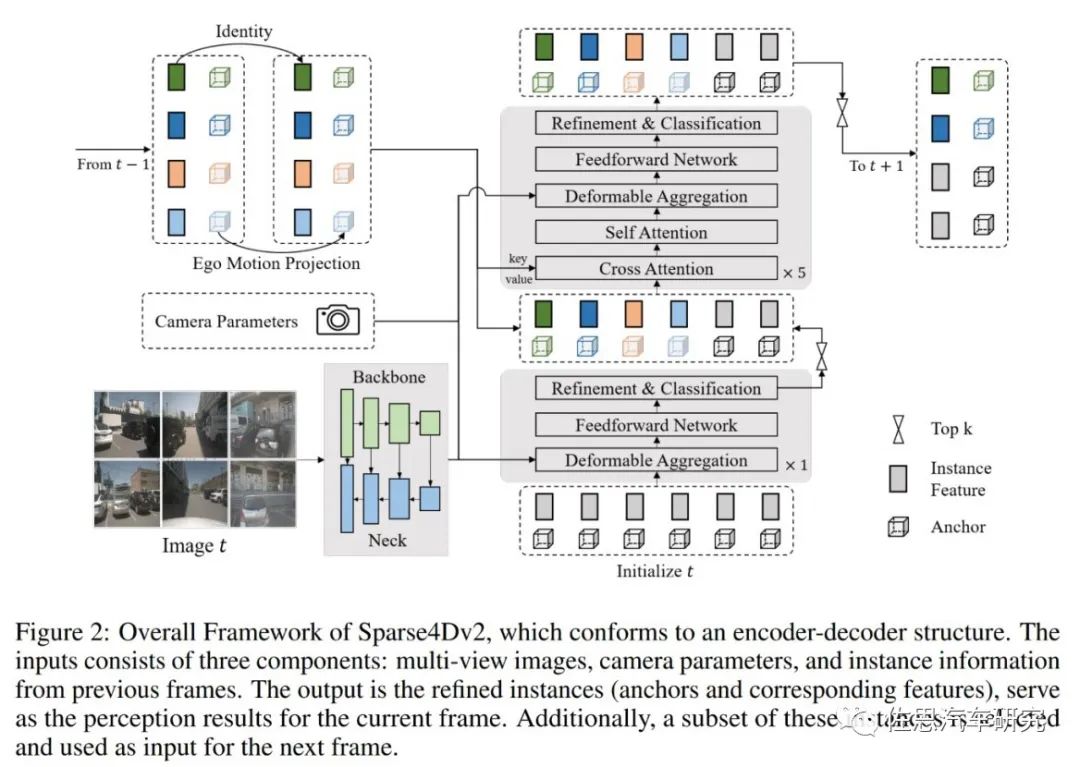
圖片來源:地平線
在Sparse4D-V2中,將decoder分為單幀層和時序?qū)印螏瑢右孕鲁跏蓟膇nstance作為輸入,輸出一部分高置信度的instance至?xí)r序?qū)樱粫r序?qū)拥膇nstance除了來自于單幀層的輸出以外,還來自于歷史幀(上一幀)。將歷史幀的instance投影至當(dāng)前幀,其中,instance feature保持不變,anchor box通過自車運動和目標(biāo)速度投影至當(dāng)前幀,anchor embed通過對投影后的anchor進行編碼得到。這樣避免消耗內(nèi)存的多幀采樣,改為歷史幀重復(fù)利用,用遞歸recurrent的方式取代了多幀采樣。
最新的Sparse4D -V3也已經(jīng)出現(xiàn),對骨干網(wǎng)和訓(xùn)練策略都進行了升級,最終達到了純視覺第一名。
最后要說的是人人都說大模型,實際略大一點的模型無法在車端使用,存儲帶寬和算力最終變?yōu)槌杀鞠拗疲歉删W(wǎng)幾乎沒有例外都還是2015年微軟研究院的何愷明、張祥雨、任少卿、孫劍等人提出的ResNet,何愷明后來去了Facebook (Meta),最近又回MIT教書,基本上何凱明引領(lǐng)了計算機目標(biāo)檢測視覺的發(fā)展潮流,真正的大神。
自動駕駛需要走的路還很長,感知的問題還未完全解決。不過欣慰的是,中國在感知方面是穩(wěn)居第一的,如果中國都無法完成自動駕駛,那么其他國家更不可能。
編輯:黃飛
?












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論