 電子發燒友App
電子發燒友App


?

?
?
機器深度學習是近年來在人工智能領域的重大突破之一,它在語音識別、自然語言處理、計算機視覺等領域都取得了不少成功。而對于當前大熱的無人駕駛,深度學習可以帶來哪些突破性應用?
由于車輛行駛環境復雜,當前感知技術在檢測與識別精度方面無法滿足無人駕駛發展需要,深度學習被證明在復雜環境感知方面有巨大優勢。
近日,針對這一話題,北京航空航天大學交通學院副教授余貴珍,在2016年中國汽車工程學會暨展覽會期間與廣大汽車專業人士分享了他對于深度學習在無人駕駛環境感知中應用的體會和心得。余貴珍的研究方向主要是智能交通和無人駕駛的感知和控制。
視覺感知是無人駕駛的核心技術
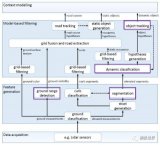
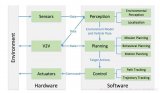
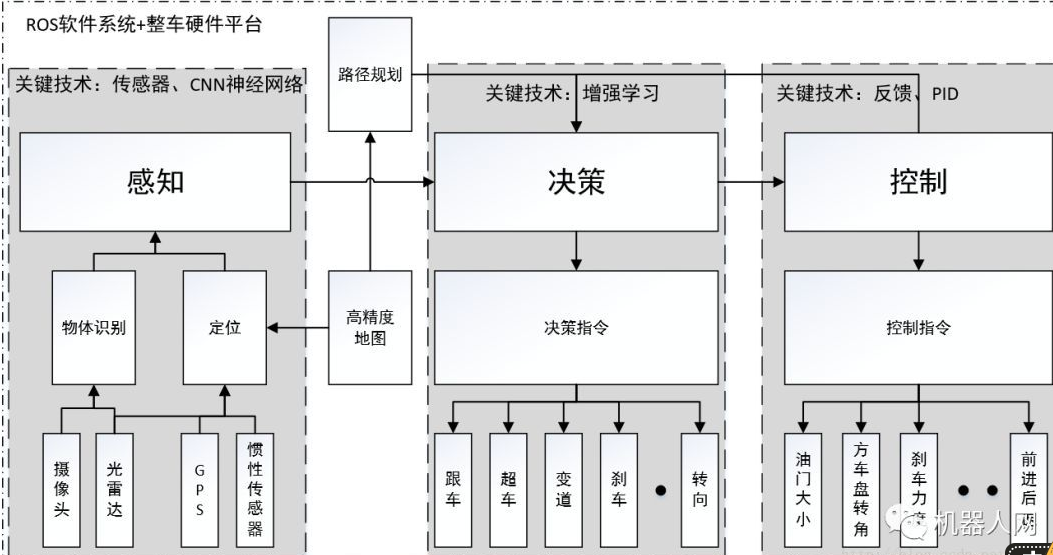
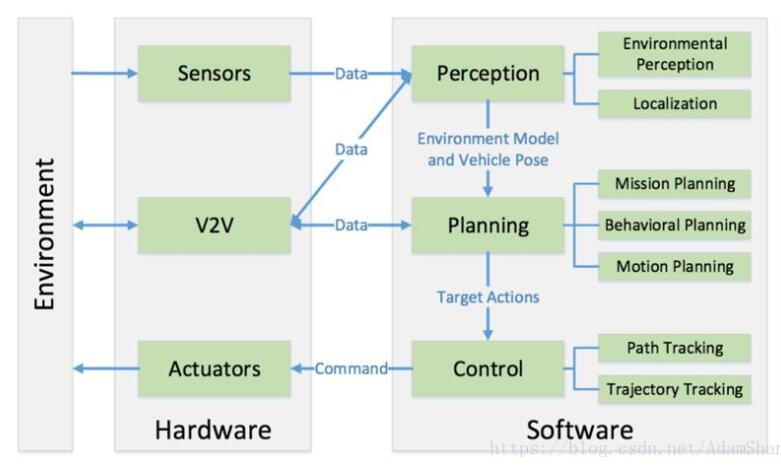
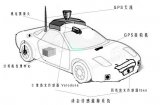
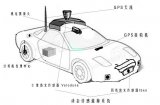
無人駕駛一般包括四個等級或者五個等級,不管哪個等級都會包含環境感知、規劃決策和執行控制等三個方面。其中環境感知方式主要有視覺感知、毫米波雷達感知和激光雷達感知,其中的視覺感知是無人駕駛感知的最主要的方式。
最近炒得比較熱的特斯拉事件,一個是發生在美國,另外一個發生在中國,我想從技術的角度來談談。
在美國事件中,特斯拉車上的毫米波雷達因為安裝的位置較低,無法檢測卡車高的車廂,攝像頭應該能檢測到卡車了,我們知道特斯拉車輛是從遠到近的過程中,所以從這個角度一般能夠檢測到卡車的。但是最后融合起來的時候可能出現了問題,沒有檢測到卡車。
在中國發生的事故,由于前車突然變道,故障車輛離特斯拉比較近,都在視覺感知和雷達的盲區,毫米波雷達由于前面角度的問題,無法掃描到近距離的側向車。另外由于故障車的部分出現在攝像頭中,視覺感知也沒有辦法檢測到,發生了特斯拉這種刮蹭事故。
所以從以上事故可以看出,視覺感知仍然需要完善。
而中國的路況較為復雜,雨天、霧霾天以及下雪天。另外,像馬車、吊車以及摩托車,還有摩托車拉豬、卡車拉樹的現象在我們生活中經常遇到,這些場景對視覺是一個難題,提高這種復雜路況下的感知精度是無人駕駛研究的挑戰。?
深度學習能夠滿足復雜路況下視覺感知的高精度需求
深度學習被認為是一種有效的解決方案,深度學習是模擬人的大腦,是近10年來人工智能取得一個較大的突破。深度學習在視覺感知中近幾年應取得了較大的進展,相對于傳統的計算機視覺,深度學習在視覺感知精度方面有比較大的優勢。
特別是2011年以后,有報導指出深度學習如果算法和樣本量足夠的話,其準確率可以達到99.9%以上,傳統的視覺算法檢測精度的極限在93%左右。而人的感知,也就是人能看到的準確率一般為95%,所以從這個方面看,深度學習在視覺感知方面是有優勢的。
所謂深度學習,又名深度神經網絡,相對于以前的神經網絡來說是一種更多層和節點的神經網絡機器學習算法,從這兒可以看出來,其實深度學習是一種機器學習,可以說是一種更智能的機器學習。深度學習主要類型一般包括5種類型,像CNN、RNN、LSTM、RBM和Autoencoder,其中我們主要的是用的CNN,CNN另外一個名字叫卷積神經網絡。卷積神經網絡已經被證明在圖像處理中有很好的效果。
其中,自學特征是深度學習的最大優勢。例如智能駕駛需要識別狗,在以前的算法中如果要識別狗,對狗的特征要用程序來詳細描述,深度學習這個地方如果采集到足夠的樣本,然后放在深度學習中訓練,訓練出來后的系統就可以識別這個狗。傳統的計算機的視覺算法需要手工提取特征,很多時候需要專家的知識,算法的魯棒性設計非常困難,很難保證魯棒性,我們做視覺感知的時候就遇到很多困難。另外如果要保證這個穩定需要大量的調試,非常耗時。
?

?
深度學習一般包括四種類型的神經網絡層,輸入層、卷積層、池化層、輸出層。網絡的結構可以10層甚至上百層,一般層數越多檢測精度會更精準。并且隨著網絡層數和節點數的增加,可以表達更細、更多的識別物的特征,這樣的話可以為檢測精度的提高打下基礎。
?

其中卷積層和池化層是深度學習的核心處理層。卷積層主要是用于負責物體特征的提取;池化層主要是負責采樣。比如簡單理解池化層,(就是一個數獨里面取一個最大值),這就是池化層。卷積層與池化層是深度學習兩個核心的層。
深度學習工作的原理,深度學習一般包括兩個方面,一個是訓練,一個是檢測,訓練一般主要是離線進行,就是把采集到的樣本輸入到訓練的網絡中。訓練網絡進行前向輸出,然后利用標定信息進行反饋,最后訓練出模型,這個模型導入到檢測的網絡中,檢測網絡就可以對輸入的視頻和圖像進行檢測和識別。通常情況下,樣本的數量越多,識別的精度一般也會越高,所以這個樣本的數量是影響深度學習精度重要的一個因素。
深度學習在無人駕駛感知上應用前景廣闊
一般的環境感知方面用到的深度學習會多一些,主要是視覺與毫米波雷達方面。在駕駛策略里面也會用到機器學習,但是我們一般叫做增強學習,用于駕駛策略的研究。在環境感知方面,深度學習可以在視覺感知、激光雷達感知,還有駕駛員狀態監測等方面,甚至在攝像頭和毫米波雷達融合方面都具有優勢。
在環境感知方面,我們在這方面做的重要工作就是前向視覺感知應用。大家知道前向視覺感知是作為無人駕駛很重要的一部分,我們嘗試深度學習在這方面一些應用。主要采用了單目攝像頭的方案,選用的模型是Faster R-CNN,在GPU TITAN 平臺上運行。目標檢測物主要包括車道線、車輛、行人、交通標識和自行車,目前車輛的樣本有3萬左右,行人樣本大概2萬左右,其他的樣本較少,大概1000—2000。從運行效果來看,識別精度、識別類型較以前開發的一些傳統的視覺算法,我們覺得有比較大的改善。
深度學習的優勢之一,容易擴展目標物體類型。
?
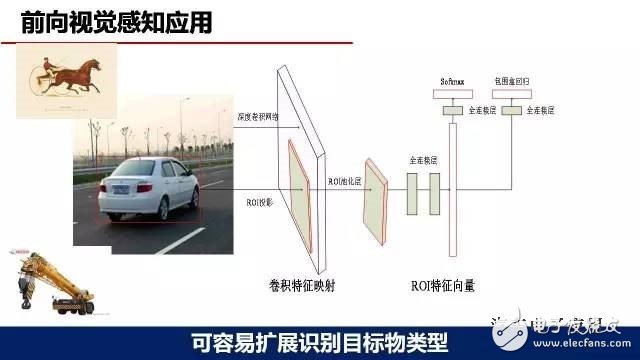
深度學習優勢之二,能夠提高部分遮擋物體的識別精度。
?

例如在圖1中如果采用傳統的視覺算法,人在車輛前面,一般的車輛檢測比較困難。在圖2中,可以看到深度學習的檢測結果,紅色車的前面已經有人和自行車,但是這個車輛仍然能夠被檢測到,采用深度學習能提高部分遮擋物體的識別精度。
深度學習優勢之三,可以解決臨車道車輛部分出現視頻中的識別困難問題。
?

其中圖1是采用傳統的算法,右車道白色的車輛沒有被檢測出來。為什么沒有被檢測出來?我們知道一般的傳統算法主要是對車輛后部的車子進行檢測,對車輛側向的檢測并不好,離你最近的兩個車道臨近車輛其實對你也是一個危險物。如果能把左右車輛出現部分車輛能夠檢測出來,我覺得這個對視覺也是一個比較大的改善。前面講的特斯拉事故,就是說一個車停在路旁,前面的車突然轉道,刮蹭的事故中就是因為這個車輛離它太近,沒有檢測到故障車輛的原因。從圖2中可以看到我們用深度學習檢測的效果,右車道車輛只有部分在圖像中,這個車輛仍然能夠被檢測出來。所以我們感覺利用深度學習可以解決臨道車輛部分出現在視頻中識別困難的問題。
深度學習優勢之四,可以減少光線變化對物體識別精度的影響。
?

圖1是晚上的識別效果,但是實際上我們整個訓練樣本中沒有晚上的車輛和行人。我們最后是把訓練之后的網絡,檢測晚上的視頻,效果不錯。圖2中可以看出,右邊樹蔭底下的幾個人,其實如果用肉眼看很難分別出來有幾個行人,但是使用深度學習,基本上能把行人都檢測出來了。以上就是我們在深度學習中的一些體會,不一定正確,因為我們只是做了一些粗淺的研究。更細的問題,如果大家有什么好的建議,或者發現有一些更新的東西我們可以一起來分享。
小結:
1,深度學習在無人駕駛視覺感知方面,相對于傳統的視覺算法,在精度、環境適應性和擴展性方面有一定的優勢。前面看到的幾個,都是我們做的一些實踐的總結。
2,深度學習大家知道除了在視覺方面,在毫米波雷達、激光雷達甚至駕駛員識別方面,我們覺得也有廣闊的應用前景。特別是駕駛員狀態識別方面,我想提一下,因為最近特斯拉的一些事件都是駕駛員采用的無人駕駛狀態,然后把手撒開方向盤,手沒有在方向盤上。如果我們有一種攝像頭可以檢測到這個駕駛員狀態的話,那么可以給駕駛員提醒,甚至說監督駕駛員是不是把手放在方向盤上,這樣可以減少事故的發生。
3,我們這個PPT僅僅是探討了深度學習在視頻檢測中的一些粗淺的應用,距離工程化應用方面仍然還有很多的技術困難需要克服。



























 工商網監
工商網監
評論