 電子發燒友App
電子發燒友App


激光雷達與攝像頭性能對比
在無人駕駛環境感知設備中,激光雷達和攝像頭分別有各自的優缺點。
攝像頭的優點是成本低廉,用攝像頭做算法開發的人員也比較多,技術相對比較成熟。攝像頭的劣勢,第一,獲取準確三維信息非常難(單目攝像頭幾乎不可能,也有人提出雙目或三目攝像頭去做);另一個缺點是受環境光限制比較大。
激光雷達的優點在于,其探測距離較遠,而且能夠準確獲取物體的三維信息;另外它的穩定性相當高,魯棒性好。但目前激光雷達成本較高,而且產品的最終形態也還未確定。

就兩種傳感器應用特點來講,攝像頭和激光雷達攝像頭都可用于進行車道線檢測。除此之外,激光雷達還可用于路牙檢測。對于車牌識別以及道路兩邊,比如限速牌和紅綠燈的識別,主要還是用攝像頭來完成。如果對障礙物的識別,攝像頭可以很容易通過深度學習把障礙物進行細致分類。但對激光雷達而言,它對障礙物只能分一些大類,但對物體運動狀態的判斷主要靠激光雷達完成。
多線激光雷達----多少線合適?
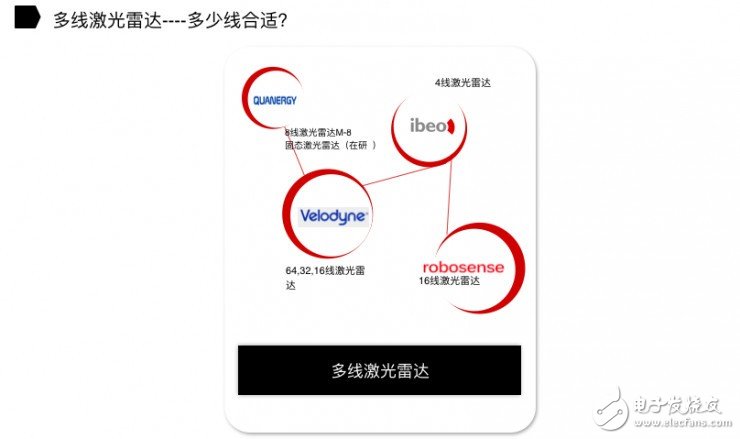
目前,國外和國內做激光雷達的廠商并不多。比如 Velodyne 推出 16 線、32 線和 64 線激光雷達產品。Quanergy 早期推出的 8 線激光雷達產品 M-8(固態激光雷達在研)。Ibeo 主要推出的是 4 線激光雷達產品,主要用于輔助駕駛。速騰聚創(RoboSense)推出的是 16 線激光雷達產品。
到底多少線的激光雷達產品才能符合無人駕駛廠商,包括傳統汽車廠商、互聯網造車公司的需求?
多線激光雷達,顧名思義,就是通過多個激光發射器在垂直方向上的分布,通過電機的旋轉形成多條線束的掃描。多少線的激光雷達合適,主要是說多少線的激光雷達掃出來的物體能夠適合算法的需求。理論上講,當然是線束越多、越密,對環境描述就更加充分,這樣還可以降低算法的要求。
業界普遍認為,像谷歌或百度使用的 64 線激光雷達產品,并不是激光雷達最終的產品形態。激光雷達的產品的方向肯定是小型化,而且還要不斷減少兩個相鄰間發射器的垂直分辨率以達到更高線束。
激光雷達產品參數包括四方面:測量距離、測量精度、角度分辨率以及激光單點發射的速度。我主要講分辨率的問題:一個是垂直分辨率,另一個是水平分辨率。
現在多線激光雷達水平可視角度是 360 度可視,垂直可視角度就是垂直方向上可視范圍。分辨率與攝像頭的像素是非常相似的,激光雷達最終形成的三維激光點云,類似于一幅圖像有許多像素點。激光點云越密,感知的信息越全面。
水平方向上做到高分辨率其實不難,因為水平方向上是由電機帶動的,所以水平分辨率可以做得很高。目前國內外激光雷達廠商的產品,水平分辨率為 0.1 度。
垂直分辨率是與發射器幾何大小相關,也與其排布有關系,就是相鄰兩個發射器間隔做得越小,垂直分辨率也就會越小。可以看出來,線束的增加主要還是為了對同一物體描述得更加充分。如果是不通過減少垂直分辨率的方式來增加線束,其實意義不大。
如何去提高垂直分辨率?目前業界就是通過改變激光發射器和接收器的排布方式來實現:排得越密,垂直分辨率就可以做得很小。另一方面就是通過多個 16 線激光雷達耦合的方式,在不增加單個激光雷達垂直分辨率的情況下同樣達到整體減小垂直分辨率的效果。
但是,這兩種方法都有一定的缺陷。
第一種方法,如果在不增加垂直可視范圍情況下增加線束,是有一定天花板的。因為激光發射器的幾何大小很難進一步再縮小,比如說做到垂直 1 度的分辨率,如果想做到 0.1 度,幾乎不可能。
第二種方法,多傳感器耦合,即多個激光雷達耦合,因為它不是單一產品,那么對往后的校準將會有很高的要求。

激光雷達和攝像頭分別完成什么工作?
無人駕駛過程中,環境感知信息主要有這幾部分:一是行駛路徑上的感知,對于結構化道路可能要感知的是行車線,就是我們所說的車道線以及道路的邊緣、道路隔離物以及惡劣路況的識別;對非結構道路而言,其實會更加復雜。
周邊物體感知,就是可能影響車輛通行性、安全性的靜態物體和動態物體的識別,包括車輛,行人以及交通標志的識別,包括紅綠燈識別和限速牌識別。
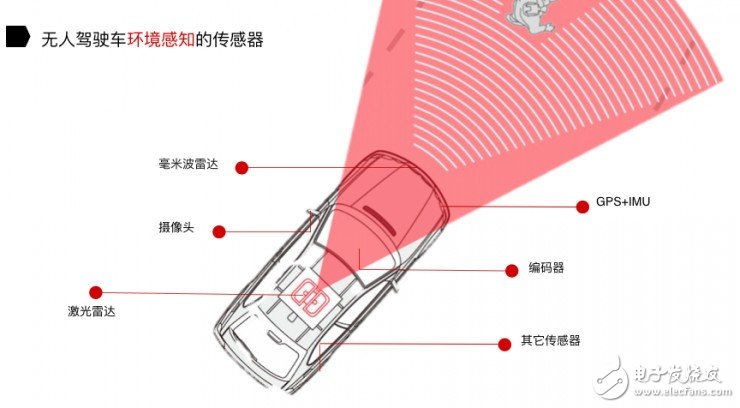
對于環境感知所需要的傳感器,我們把它分成三類:
感知周圍物體的傳感器,包括激光雷達、攝像頭和毫米波雷達這三類;
實現無人駕駛汽車定位的傳感器,就是 GPS 、IMU 和 Encoder;
其他傳感器,指的是感知天氣情況及溫、濕度的傳感器。
今天主要講的是感知周圍物體的傳感器,即:激光雷達、毫米波雷達和攝像頭。其實他們都有各自的優缺點。

在無人駕駛環境感知中,攝像頭完成的工作包括:
車道線檢測;
障礙物檢測,相當于把障礙物識別以及對障礙物進行分類;
交通標志的識別,比如識別紅綠燈和限速牌。

對車道線的檢測主要分成三個步驟:
第一步,對獲取到的圖片預處理,拿到原始圖像后,先通過處理變成一張灰度圖,然后做圖像增強;
第二步,對車道線進行特征提取,首先把經過圖像增強后的圖片進行二值化( 將圖像上的像素點的灰度值設置為 0 或 255,也就是將整個圖像呈現出明顯的黑白效果),然后做邊緣提取;
第三步,直線擬合。
車道線檢測難點在于,對于某些車道線模糊或車道線被泥土覆蓋的情況、對于黑暗環境或雨雪天氣或者在光線不是特別好的情況下,它對攝像頭識別和提取都會造成一定的難度。
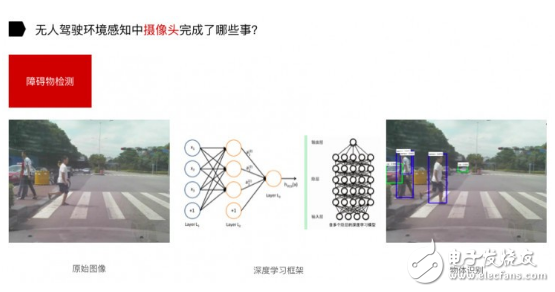
另一個是障礙物檢測。上圖是我們在十字路口做的實驗,獲取到原始圖像后,通過深度學習框架對物體進行識別。在這當中,做訓練集其實是主要的難點。

還有一個是道路標識的識別,這一部分的研究比較多,這里不再贅述。

激光雷達能夠完成什么工作?
第一是路沿檢測,也包括車道線檢測;第二是障礙物識別,對靜態物體和動態物體的識別;第三是定位以及地圖的創建。
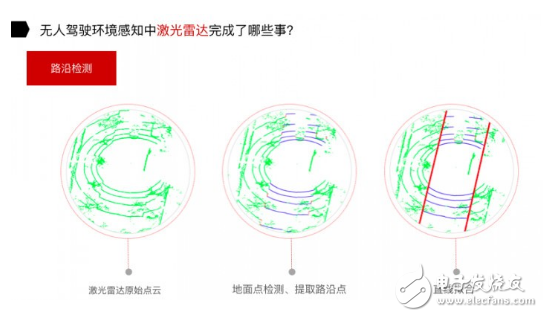
對于路沿檢測,分為三個步驟:拿到原始點云,地面點檢測、提取路沿點,通過路沿點的直線擬合,可以把路沿檢測出來。
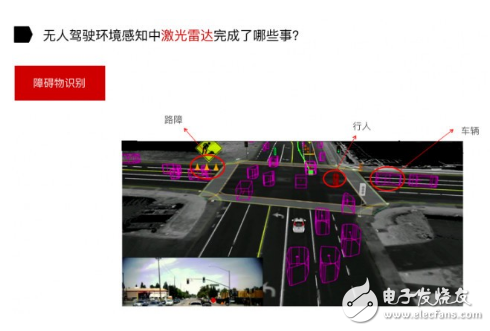
接下來是障礙物識別,識別諸如行人、卡車和私家車等以及將路障信息識別出來。

障礙物的識別有這樣幾步,當激光雷達獲取三維點云數據后,我們對障礙物進行一個聚類,如上圖紫色包圍框,就是識別在道路上的障礙物,它可能是動態也可能是靜態的。
最難的部分就是把道路上面的障礙物聚類后,提取三維物體信息。獲取到新物體之后,會把這個物體放到訓練集里,然后用 SVM 分類器把物體識別出來。

如上圖,左上角、左下角是車還是人?對于機器而言,它是不清楚的。右上角和右下角(上圖)是我們做的訓練集。做訓練集是最難的,相當于要提前把不同物體做人工標識,而且這些標識的物體是在不同距離、不同方向上獲取到的。
我們對每個物體,可能會把它的反射強度、橫向和縱向的寬度以及位置姿態作為它的特征,進行提取,進而做出數據集,用于訓練。最終的車輛、行人、自行車等物體的識別是由SVM分類器來完成。我們用這種方法做出來的檢測精確度還是不錯的。
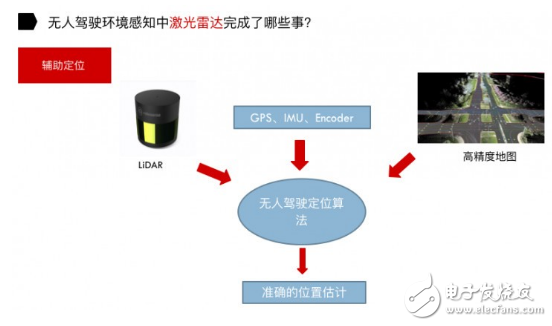
利用激光雷達進行輔助定位。定位理論有兩種:基于已知地圖的定位方法以及基于未知地圖的定位方法。
基于已知地圖定位方法,顧名思義,就是事先獲取無人駕駛車的工作環境地圖(高精度地圖),然后根據高精度地圖結合激光雷達及其它傳感器通過無人駕駛定位算法獲得準確的位置估計。現在大家普遍采用的是基于已知地圖的定位方法。
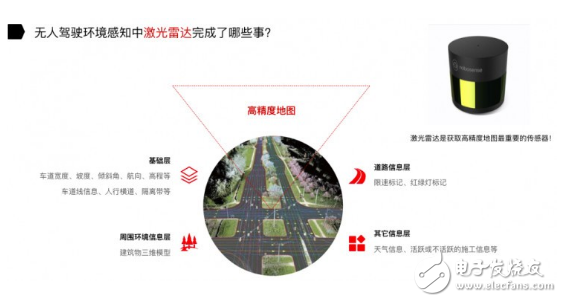
制作高精度地圖也是一件非常困難的事情。舉個例子,探月車在月球上,原來不知道月球的地圖,只能靠機器人在月球上邊走邊定位,然后感知環境,相當于在過程中既完成了定位又完成了制圖,也就是我們在業界所說的 SLAM 技術。
激光雷達是獲取高精度地圖非常重要的傳感器。通過 GPS、IMU 和 Encoder 對汽車做一個初步位置的估計,然后再結合激光雷達和高精度地圖,通過無人駕駛定位算法最終得到汽車的位置信息。














 工商網監
工商網監
評論