 電子發燒友App
電子發燒友App


今年4月底,中國工程院院士徐匡迪等多位院士的發聲,直擊我國在算法這一核心技術上的缺失,引發業界共鳴,被稱為“徐匡迪之問”。
由此,“依靠開源代碼和算法是否足夠支撐人工智能產業發展?”、“為什么要有自己的底層框架和核心算法?”等一系列問題,成為行業熱議的話題。
事實上,除了核心算法之外,對底層框架的忽視,也成為影響我國人工智能發展的重要因素,甚至比“缺芯少魂”、“卡脖子”問題更危險!
然而,想要理清其中的緣由,就需要從讀懂機器學習開始。
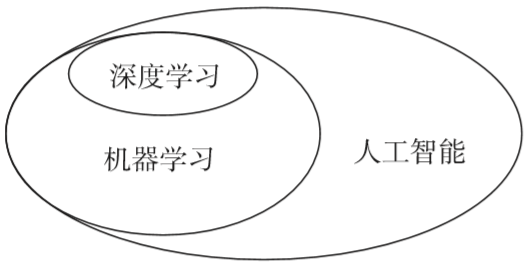
什么是機器學習?
眾所周知,AI的根本目的就是讓計算機模擬人類的行為和思維,以實現解放人力,提升效率,降低成本。其中,機器學習(Machine Learning)則是AI的智慧源泉。
從學術上來說,機器學習涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多領域交叉的課題和技術。
從廣義上來說,機器學習就是賦予計算機學習能力,并實現模仿人類的一種方法。
從技術應用上來說,機器學習是利用大量數據,訓練出專用的算法模型,然后通過該模型實現類似人的預測、推理,從而獲取決策的方法。
從層級上來說,機器學習位于AI的技術層,與其他技術的相融合,構成了計算機視覺、智能語音、模式識別、數據挖掘、統計學習等AI核心技術,并在應用層得以體現。
從AI發展來看,幾乎所有核心技術和應用場景的背后,都離不開機器學習所賦予的學習能力,也就是智能。
總之,機器學習既是人工智能的核心,也是計算機獲得學習能力和智力的方法或途徑。
而機器學習的核心則是算法。
深度學習算法與底層框架
作為AI大三元素(數據、算力、算法),目前主流的算法主要面向機器學習領域。因此,機器學習也可以理解為用于訓練和推理的算法合集。
目前,機器學習算法可以分為傳統算法和深度學習(Deep Learning)算法兩大類。
深度學習是機器學習中一個新興的研究方向,也是一個復雜的機器學習算法。深度學習的概念源于人工神經網絡的研究,建立模擬人腦進行分析學習的神經網絡,以模仿人腦的機制來解釋數據,強調模型結構的深度和明確特征學習的重要性。
因此,深度學習使計算機實現模仿視聽和思考等人類的活動,解決了大量復雜的模式識別難題,從而推動計算機視覺、智能語音等復雜AI基礎技術的落地。
可以說,深度學習算法決定了未來AI的發展趨勢,乃是兵家必爭之地。
現在,全球AI領域,深度學習已經超越傳統機器學習,成為主流算法。但是,機器學習仍未被取代,兩者呈現互補的態勢。隨著深度學習與神經網絡算法的結合,不僅降低了算法訓練的門檻,更衍生出大量熱門算法以及相應的底層構架。
與依賴于芯片的算力不同,算法由于開源代碼、自動化工具等助力,門檻相對降低不少,因而成為初創公司不錯的切入點。現在,大多AI企業基本都是圍繞算法及相應的應用場景做文章,在國內尤為普遍。
然而,這些基于開源代碼和自動化工具的算法往往過于通用和初級,僅僅依托國內海量數據儲備和豐富的應用場景的優勢,實現最基本的功能而已。真正核心和關鍵算法仍然掌握在國外大廠手中,核心競爭力明顯不足。
而且,不僅是核心算法,深度學習的底層框架也同樣來自于國外廠商。
底層框架,一般被稱作為開源框架或算法訓練平臺。通俗來說,就是AI工具包,其作用就是用以訓練算法模型的平臺。
如果將算法比作“子彈”的話,底層框架就是“軍工廠”,重要性不言而喻。
僅僅是算法的缺失,可以通過企業、開發者及整個行業的共同努力來彌補,但連工具都被“卡脖子”的話,顯然將大大制約我國深度學習,乃至整個AI產業的發展。
外來的和尚好念經
目前,主流的深度學習底層框架雖然大多已經開源,但基本都來自于美國科技巨頭及大學相關實驗室,例如TensorFlow(谷歌)、PyTorch(Facebook)、MXNet(亞馬遜)、CNTK(微軟)、Deeplearning4j(美國AI初創公司Skymind)、Theano(蒙特利爾理工學院)、Caffe(加州大學伯克利/賈揚清開發)、Keras(谷歌工程師Fran?oisChollet開發)等等。
其中, TensorFlow和PyTorch應用最為廣泛,全球AI企業都將其視為重要的工具包。據TensorFlow網站顯示,京東、中國移動、美團、搜狗等中國企業都在使用該框架,用于深度學習的應用和開發。
任何企業和開發者都可以將數據饋入其中,并開始訓練自己的算法模型,無需重頭開始自行開發底層框架和開發平臺,所謂 “站在巨人的肩膀”。
谷歌、Facebook、亞馬遜、微軟也在不遺余力地投入,對這些底層框架進行維護、升級和推廣,以確保其受到全球開發者的歡迎。根本目的就是建立統一的標準和規范,進而形成完整的生態。最簡單的例子就是谷歌的安卓操作系統,雖為開源,但也形成了技術壁壘,讓其他廠商難以逾越。
同時,大量企業和開發者也在為這些開源構架默默地做著貢獻,從而推動其不斷壯大。從另一個層面來說,盡管底層框架均為開源、免費,但獲得全球開發者助力的同時,也省去了建立國際性開發團隊的巨額成本。
其實,國內巨頭已經意識到了這個問題。BAT、華為、商湯、曠視、360以及浪潮等廠商都已經推出了各自的機器學習底層框架。
尤其是百度飛槳(Paddle Paddle)自2016年開源起,一直在不斷升級和推廣,以吸引更多的企業和開發者的關注。2017年,騰訊Angel、360 Xlearning先后宣布開源。2018年年底,阿里x-deeplearning也正式開源。今年8月,華為推出了MindSpore深度學習框架,并將在2020年第一季度開源。此外,包括商湯、曠視、浪潮等廠商雖然已經擁有自己的底層構架,但遺憾的是并沒有開源。
最近,小米宣布語音識別開源工具Kaldi 之父DanielPovey將出任語音首席科學家,很可能會加大相關底層構架的研發。
盡管中國廠商已經擁有了自研底層框架的實力,但在先入為主的國外開源構架面前,不僅用戶量不足,而且缺乏貢獻者,更有過于封閉的問題,因此底層構架的國產化可謂路漫漫。
如何突圍?
隨著國內自研AI芯片成為全新的風潮,讓人看到了突破芯片“卡脖子”,實現“彎道超車”的可能。
即便如此,現在中國AI基礎研究和基礎設施仍然相當薄弱,包括硬件在內的大量核心技術掌控在美國手中,更隨時面臨“技術封鎖”和“斷供”的風險。
同樣的情況也發生在深度學習領域,核心算法和底層構架的缺失,一旦風險爆發,將對中國AI發展帶來致命影響。
從國外廠商在AI領域的布局來看,無論是云計算、芯片,還是算法和底層框架,均以構建自己的生態為根本目的,從而建立起牢不可破的“護城河”。
好在,阿里、百度、華為等國內巨頭已經從各個角度開展布局,阿里平頭哥“含光800”、華為麒麟系列芯片、鴻蒙操作系統以及百度飛槳等都是典型的代表。其中,今年7月,百度宣布飛槳與華為麒麟展開合作,芯片與底層構架的聯手,無疑將共同推動中國深度學習和AI產業的落地和發展。相信這也是建立中國力量生態圈最好范例。
此外,建立和推動開源文化,也是擺在中國企業面前的老生常談的問題。唯有擁抱開放、共享,才能真正推動中國核心技術,尤其是AI技術的快速進步和發展,從而突破“卡脖子”封鎖。
目前,國內深度學習廠商主要分為云計算平臺、AI初創企業、傳統計算廠商以及大數據企業多個陣營。其中,云計算平臺主要是BAT、華為、京東等互聯網巨頭為首;AI初創企業主要有第四范式、商湯、曠視、寒武紀等;浪潮、中科曙光等則發揮自身計算優勢,占有一席之地;星環科技、美林數據、九章云極等大數據企業擁有數據挖掘的優勢,也成為生態中不可獲取的力量。
由此可知,除了AI本身之外,深度學習、機器學習與云、計算、數據等關鍵技術密不可分,這也恰恰證實了國內海量數據儲備和互聯網基礎設施建設對AI行業起到的推動作用。然而,正如上文所述,唯有掌控核心算法和底層框架,擁有基礎設施和核心技術的自研能力,才能真正主導深度學習及機器學習行業。
總之,就連機器學習、深度學習這樣的AI工具包都一直掌控在美國手中,無疑比芯片、操作系統等核心技術的“卡脖子”問題更危險!














 工商網監
工商網監
評論