 電子發燒友App
電子發燒友App


本文為大家介紹用XGBoost解釋機器學習。
這是一個故事,關于錯誤地解釋機器學習模型的危險以及正確解釋所帶來的價值。如果你發現梯度提升或隨機森林之類的集成樹模型具有很穩定的準確率,但還是需要對其進行解釋,那我希望你能從這篇文章有所收獲。
假定我們的任務是預測某人的銀行財務狀況。模型越準確,銀行就越賺錢,但由于該預測要用于貸款申請,所以我們必須要提供預測背后的原因解釋。在嘗試了幾種類型的模型之后,我們發現XGBoost實現的梯度提升樹能提供最佳的準確率。不幸的是,很難解釋為何XGBoost做出某個決策,所以我們只有兩種選擇:要么退回到線性模型,要么搞清楚如何解釋XGBoost模型。沒有數據科學家愿意在準確率上讓步,于是我們決定挑戰自己,去解釋復雜的XGBoost模型(本例中,是6棵深達1247層的樹)。
經典的全局特征重要性度量
首先一個顯而易見的選擇是使用XGBoost中Python接口提供的plot_importance()方法。它給出一個簡單明了的柱狀圖,表示數據集中每個特征的重要性(復現結果的代碼在Jupyter notebook中)。
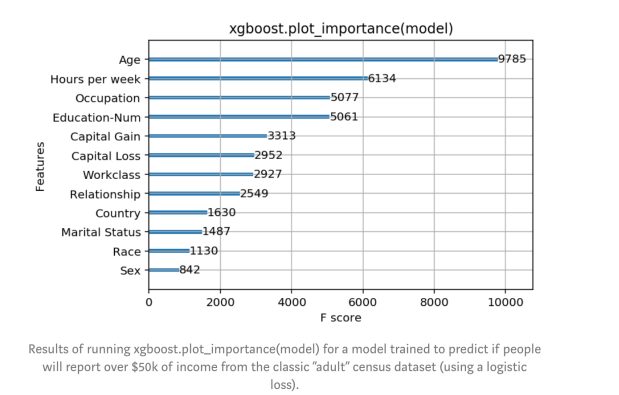
圖:該模型在經典的成人普查數據集上被訓練用于預測人們是否會報告超過5萬美元的收入(使用logistic loss),上圖是執行xgboost.plot_importance(model)的結果
仔細看一下XGBoost返回的特征重要性,我們發現年齡在所有特征中占統治地位,成為收入最重要的預測指標。我們可以止步于此,向領導報告年齡這個直觀且讓人滿意的指標是最重要的特征,緊隨其后的是每周工作時長和受教育程度這些特征。但是,作為一名好的數據科學家,我們查詢了一下文檔,發現在XGBoost中衡量特征重要性有3個選項:
1. Weight。某個特征被用于在所有樹中拆分數據的次數
2. Cover。同上,首先得到某個特征被用于在所有樹中拆分數據的次數,然后要利用經過這些拆分點的訓練數據數量賦予權重
3. Gain。使用某個特征進行拆分時,獲得的平均訓練損失減少量
這些是在任何基于樹的建模包中都能找到的重要性度量。Weight是默認選項,因此我們也試試另外兩種方法,看看有何不同:
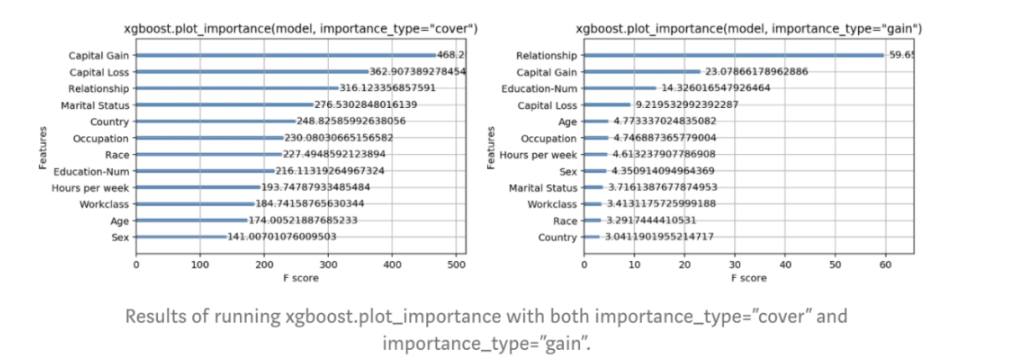
圖:運行xgboost.plot_importance,并使用參數 importance_type=’cover’和’gain’的結果
結果令人詫異,對于XGBoost提供的3個選項,特征重要性的排序都大不相同。對于cover方法,資本收益似乎是收入最重要的預測指標,而對于gain方法,關系狀態特征獨占鰲頭。不知道哪種方法最好的情況下,依靠這些度量來報告特征重要性,這很讓人不爽。
什么因素決定了特征重要性度量的好壞?
如何比較兩種特征歸因(feature attribution)方法并不明顯。我們可以在諸如數據清洗,偏差檢測等任務上測量每種方法的最終用戶性能。但這些任務僅僅是特征歸因方法質量的間接度量。這里,定義兩個我們認為任何好的特征歸因方法都應遵循的屬性:
1. 一致性(Consistency)。當我們更改模型以使其更多依賴于某個特征時,該特征的重要性不應該降低。
2. 準確性(Accuracy)。所有特征重要性的和應該等于模型的總體重要性。例如,如果重要性由R^2值來衡量,則每個特征的歸因值加起來應該等于整個模型的R^2。
如果一致性不滿足,那我們就無法比較任意兩個模型的特征重要性,因為此時分配到更高的歸因并不意味著模型對此特征有更多依賴。
如果準確性不滿足,那我們就不知道每個特征的歸因是如何合并起來以代表整個模型的輸出。我們不能簡單的對歸因進行歸一化,因為這可能會破壞該方法的一致性。
當前的歸因方法是否一致且準確?
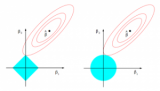
回到之前銀行數據科學家的工作。我們意識到一致性和準確性很重要。實際上,如果一個方法不具備一致性,我們就無法保證擁有最高歸因的特征是最重要的特征。因此,我們決定使用兩個與銀行任務無關的樹模型來檢查各個方法的一致性:
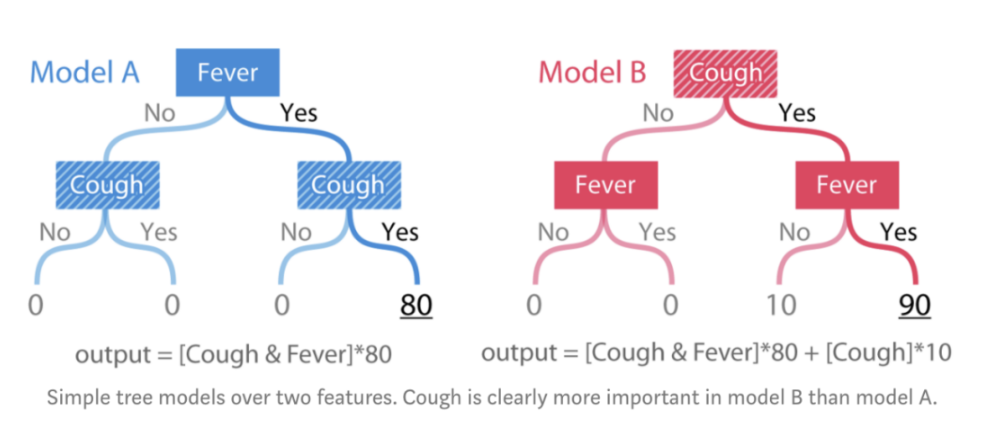
圖:在兩個特征上的簡單樹模型。咳嗽顯然在模型B中比模型A中更重要。
模型的輸出是根據某人的癥狀而給出的風險評分。模型A僅僅是一個用于發燒和咳嗽兩個特征的簡單“and”函數。模型B也一樣,只不過只要有咳嗽癥狀,就加10分。為了檢查一致性,我們需要定義“重要性”。此處,我們用兩種方式定義重要性:
1) 作為當我們移除一組特征時,模型預期準確率的變化。
2) 作為當我們移除一組特征時,模型預期輸出的變化。
第一個定義度量了特征對模型的全局影響。而第二個定義度量了特征對單次預測的個性化影響。在上面簡單的樹模型中,當發燒和咳嗽同時發生時對于兩種定義,咳嗽特征在模型B中明顯都更重要。
銀行例子中的Weight,cover和gain方法都是全局特征歸因方法。當在銀行部署模型時,我們還需要針對每個客戶的個性化說明。為了檢查一致性,我們在簡單的樹模型上運行6種不同的特征歸因方法:
1. Tree SHAP。我們提出的一種新的個性化度量方法。
2. Saabas。一種個性化的啟發式特征歸因方法。
3. Mean( |Tree SHAP| )。基于個性化Tree SHAP平均幅度的一種全局歸因方法。
4. Gain,上述XGBoost使用的相同方法,等同于scikit-learn樹模型中使用的Gini重要性度量。
5. 拆分次數(Split Count)。代表XGBoost中緊密相關的’weight’和’cover’方法,但使用’weight’方法來計算。
6. 排列(Permutation)。當在測試集中隨機排列某個特征時,導致模型準確率的下降。
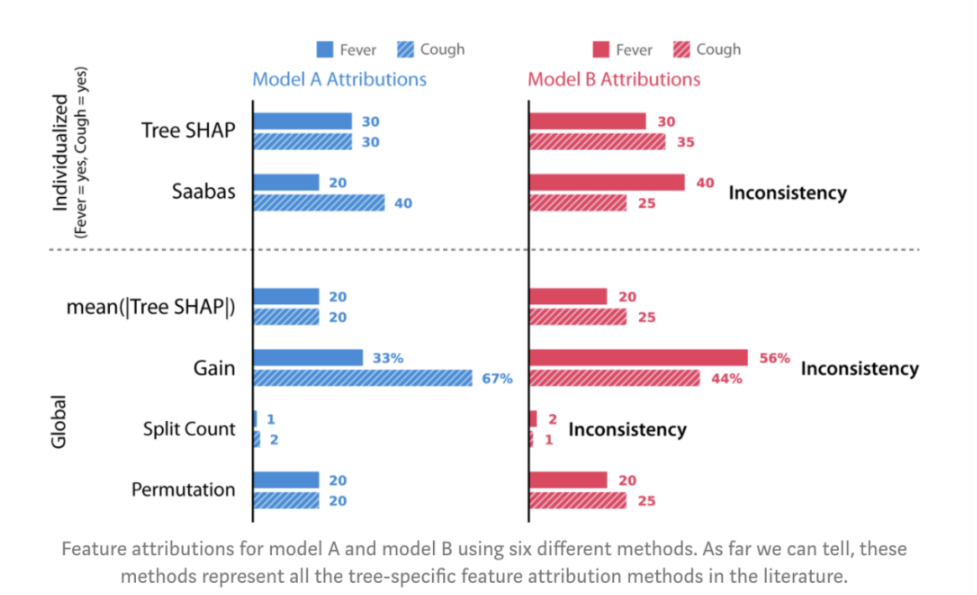
圖:使用6種不同方法對模型A和B做特征歸因。截止發文時間,這些方法代表了文獻中所有關于樹模型的特征歸因方法。
從圖上可知,除了permutation方法外,其余方法都是不一致的。因為它們在模型B中比在模型A中給咳嗽分配的重要性更少。不一致的方法無法被信任,它無法正確地給最有影響力的特征分配更多的重要性。細心的讀者會發現,之前我們在同一模型上使用經典的歸因方法產生矛盾時,這種不一致已經顯現。對于準確性屬性呢?事實證明,Tree SHAP,Sabaas和 Gain 都如先前定義的那樣準確,而permutation和split count卻不然。
令人驚訝的是,諸如gain(Gini重要性)之類廣泛使用的方法居然會導致如此明顯的不一致。為了更好地理解為何會發生這種情況,我們來仔細看看模型A和B中的gain是如何計算的。簡單起見,我們假設每個葉子節點中落有25%的數據集,并且每個模型的數據集都具有與模型輸出完全匹配的標簽。
如果我們用均方誤差MSE作為損失函數,則在模型A中進行任何拆分之前,MSE是1200。這是來自恒定平均預測20的誤差。在模型A中用發燒特征拆分后,MSE降到了800,因此gain方法將此400的下降歸因于發燒特征。然后用咳嗽特征再次拆分,會得到MSE為0,gain方法會把這次800的下降歸因于咳嗽特征。同理,在模型B中,800歸因于發燒,625歸因于咳嗽。
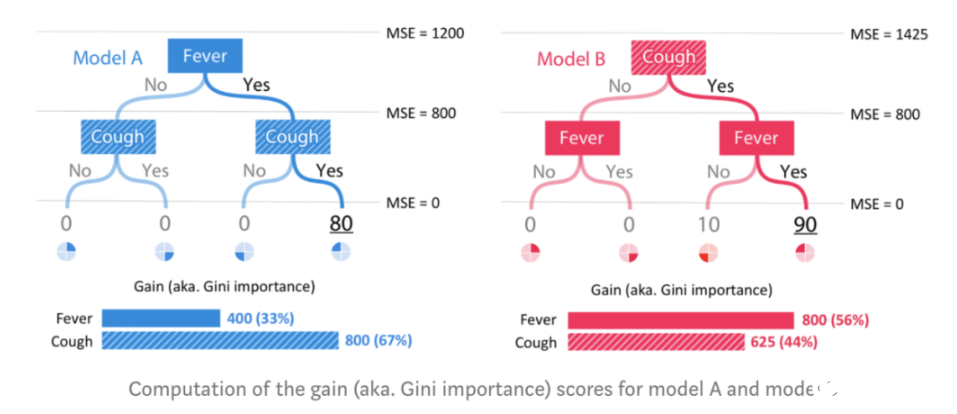
圖:模型A和模型B的gain(又稱基尼重要性)得分計算。
通常,我們期望靠近樹根的特征比葉子節點附近的特征更重要(因為樹就是貪婪地被構造的)。然而gain方法偏向于將更多的重要性歸因于較低的拆分。這種偏見導致了不一致性,即咳嗽應該更重要時(在樹根處拆分),給它歸因的重要性實際卻在下降。個性化的Saabas方法(被treeinterpreter包所使用)在我們從上到下遍歷樹時計算預測的差異,它也同樣受偏見影響,即偏向較低的拆分。隨著樹加深,這種偏見只會加劇。相比之下,Tree SHAP方法在數學上等價于對特征所有可能的排序上的預測差異求均值,而不僅僅是按照它們在樹中的位置順序。
只有Tree SHAP既一致又準確這并不是巧合。假設我們想要一種既一致又準確的方法,事實證明只有一種分配特征重要性的方法。詳細介紹在我們最近的NIPS論文中,簡單來講,從博弈論中關于利潤公平分配的證明引出了機器學習中特征歸因方法的唯一結果。在勞埃德·沙普利(Lloyd Shapley)于1950年代推導出它們之后,這些唯一的值被稱為沙普利值(Shapley values)。我們在這里使用的SHAP值是把與Shapley值相關的幾種個性化模型解釋方法統一而來的。Tree SHAP是一種快速算法,可以精確地在多項式時間內為樹計算SHAP值,而不是在傳統的指數運行時間內(請參閱arXiv)。
充滿信心地解釋我們的模型
扎實的理論依據和快速實用的算法相結合,使SHAP值成為可靠地解釋樹模型(例如XGBoost的梯度提升機)的強大工具。有了這個新方法,讓我們回到解釋銀行XGBoost模型的任務:
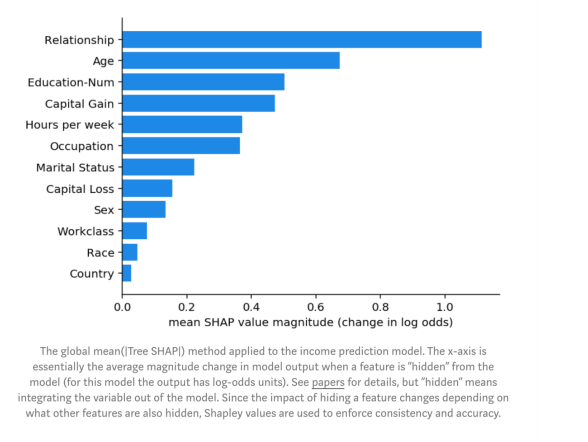
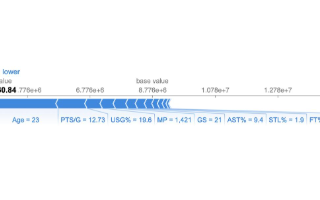
圖:全局Mean( |Tree SHAP| )方法應用到收入預測模型上。x軸是當某個特征從模型中’隱藏’時模型輸出的平均幅度變化(對于此模型,輸出具有log-odds單位)。詳細信息,請參見論文。但是“隱藏”是指將變量集成到模型之外。由于隱藏特征的影響會根據其他隱藏特征而變化,因此使用Shapley值可迫使一致性和準確性。
圖上可看出,關系特征實際上是最重要的,其次是年齡特征。由于SHAP值保證了一致性,因此我們無需擔心之前在使用gain或split count方法時發現的種種矛盾。不過,由于我們現在有為每個人提供的個性化說明,我們還可以做的更多,而不只是制作條形圖。我們可以在數據集中給每個客戶繪制特征重要性。shap Python包使此操作變得容易。我們首先調用shap.TreeExplainer(model).shap_values(X)來解釋每個預測,然后調用shap.summary_plot(shap_values,X)來繪制以下解釋:
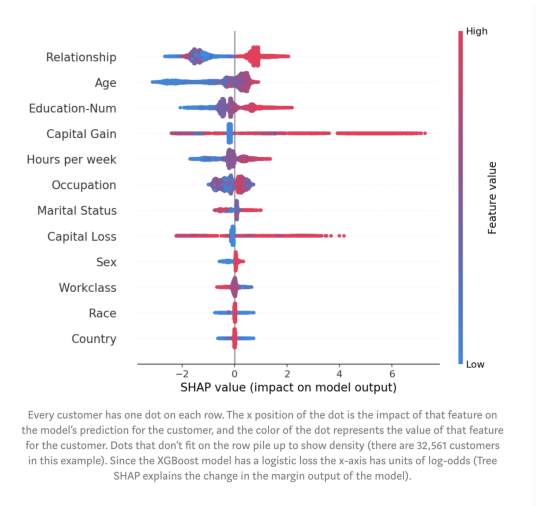
圖:每個客戶在每一行上都有一個點。點的x坐標是該特征對客戶模型預測的影響,而點的顏色表示該特征的值。不在行上的點堆積起來顯示密度(此示例中有32,561個客戶)。由于XGBoost模型具有logistic loss,因此x軸具有log-odds單位(Tree SHAP解釋了模型的邊距輸出變化)。
這些特征按mean(| Tree SHAP |)排序,因此我們再次看到關系這個特征被視為年收入超過5萬美元的最強預測因子。通過繪制特征對每個樣本的影響,我們還可以看到重要的異常值影響。例如,雖然資本收益并不是全局范圍內最重要的特征,但對于部分客戶而言,它卻是最重要的特征。按特征值著色為我們顯示了一些模式,例如,年紀較淺會降低賺取超過 5萬美元的機會,而受高等教育程度越高,賺取超過5萬美元的機會越大。
我們可以停下來將此圖展示給老板,但這里咱們來更深入地研究其中一些特征。我們可以通過繪制年齡SHAP值(log odds的變化)與年齡特征值的關系來實現:
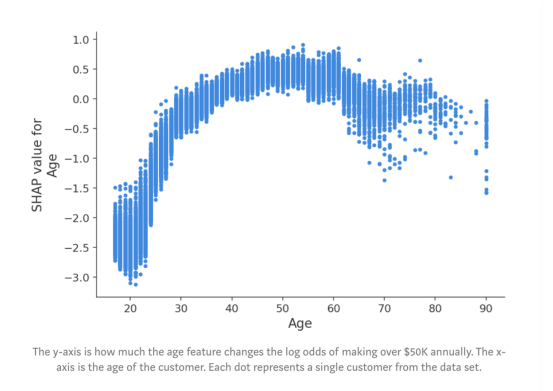
圖:y軸是年齡特征改變多少每年賺取5萬美元以上的log odds。x軸是客戶的年齡。每個點代表數據集中的一個客戶。
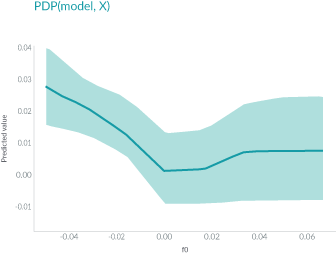
在這里,我們看到了年齡對對收入潛力的明顯影響。請注意,與傳統的部分依賴圖(其顯示當更改特征值時的平均模型輸出)不同,這些SHAP依賴圖顯示了相互影響。即使數據集中的許多人是20歲,但年齡對他們的預測的影響程度卻有所不同,正如圖中20歲時點的垂直分散所示。這意味著其他特征正在影響年齡的重要性。為了了解可能是什么特征在影響,我們用受教育的年限給點涂上顏色,并看到高水平的教育會降低20歲時的年齡影響,而在30歲時會提高影響:
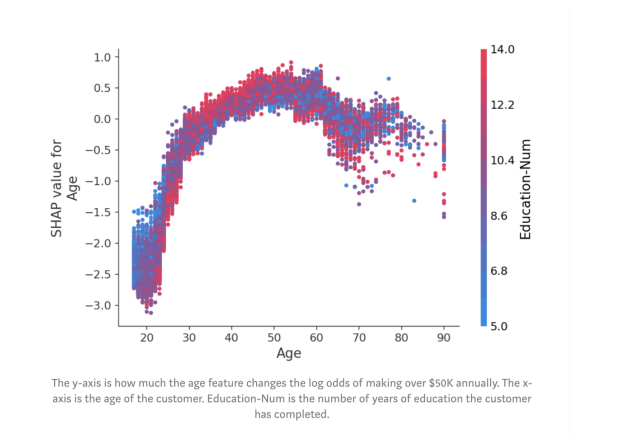
圖:y軸是年齡特征改變多少每年賺取5萬美元以上的log odds。x軸是客戶的年齡。Education-Num是客戶已接受的教育年限。
如果我們對每周的工作小時數做另一個依賴圖,我們會發現,多投入時間工作的好處在每周約50個小時時達到瓶頸,而如果你已婚,則額外工作不太可能代表更高收入:
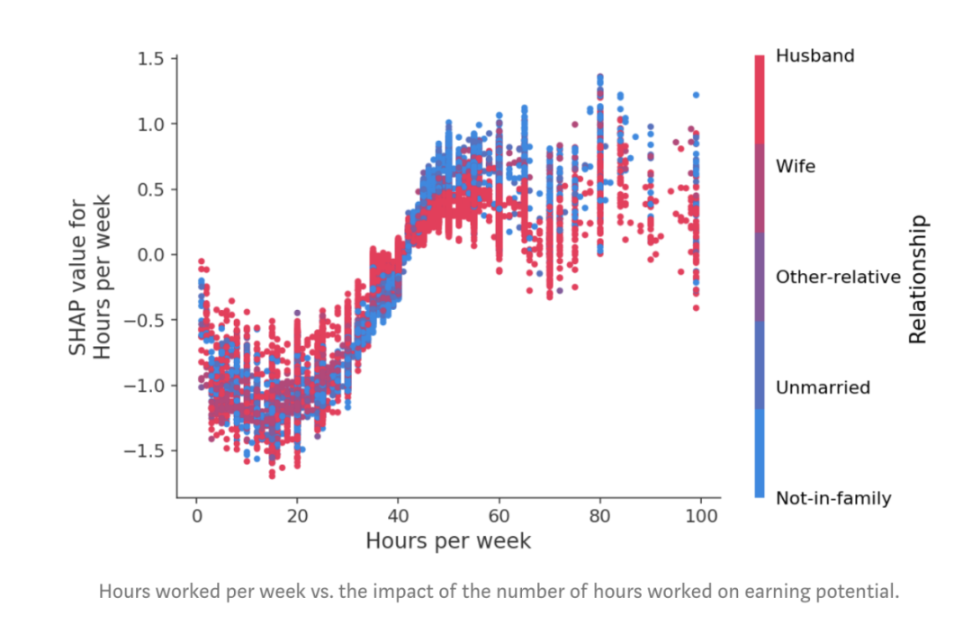
圖:每周工作時間與工作時間數對收入潛力的影響。
解釋你自己的模型
這篇文章整個分析過程旨在模擬你在設計和部署自己的模型時可能要經歷的過程。shap包很容易通過pip進行安裝,我們希望它可以幫助你放心地探索模型。它不僅包含本文涉及的內容,還包括SHAP交互值,模型不可知的SHAP值估算,以及其他可視化。還有很多notebooks來展示在各種有趣的數據集上的各種功能。例如,你可以在一個notebook中根據體檢報告數據來分析你將來最可能的死亡原因,這個notebook解釋了一個XGBoost死亡率模型。對于Python以外的其他語言,Tree SHAP也已直接合并到核心XGBoost和LightGBM軟件包中。
編輯:hfy








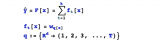












 工商網監
工商網監
評論