 電子發(fā)燒友App
電子發(fā)燒友App


2020 年,最轟動(dòng)的 AI 新聞莫過于 OpenAI 發(fā)布的 GPT-3 了。它的1750億參數(shù)量及其在眾多NLP任務(wù)上超過人類的出眾表現(xiàn)讓人們開始堅(jiān)信:大模型才是未來。但與之帶來的問題是,訓(xùn)練超大模型所需的算力、存儲(chǔ)已不再是單機(jī)就能搞定。
據(jù) NVIDIA 估算,如果要訓(xùn)練GPT-3 ,即使單個(gè)機(jī)器的顯存/內(nèi)存能裝得下,用 8 張 V100 的顯卡,訓(xùn)練時(shí)長預(yù)計(jì)要 36 年;即使用 512 張 V100 ,訓(xùn)練也需要將近 7 個(gè)月;如果擁有 1024 張 80GB A100, 那么完整訓(xùn)練 GPT-3 的時(shí)長可以縮減到 1 個(gè)月。
除去硬件資源這個(gè)經(jīng)濟(jì)問題,在技術(shù)層面,意味著訓(xùn)練大模型一定是一個(gè)分布式問題。因?yàn)樗懔π枨筮€是一個(gè)相對(duì)容易解決的問題,畢竟擁有大集群的組織并不只 OpenAI 一家,而如何解決上千塊 GPU 的分布式訓(xùn)練問題才是關(guān)鍵。
根據(jù)目前業(yè)界已有的分布式訓(xùn)練方案,即便你是一位非常優(yōu)秀的數(shù)據(jù)科學(xué)家,知曉并能解決 Transformer 相關(guān)的所有算法問題,但如果你不知道如何解決分布式訓(xùn)練時(shí)上百臺(tái)服務(wù)器之間的通信、拓?fù)洹⒛P筒⑿小⒘魉⑿械葐栴},你甚至都無法啟動(dòng)這次訓(xùn)練。一定程度上,這解釋了GPT-3發(fā)布時(shí)隔一年,卻只有 NVIDIA 、微軟等大企業(yè)可以復(fù)現(xiàn) GPT-3 。
目前,開源的 GPT 模型庫主要是 NVIDIA開發(fā)的 Megatron-LM 和經(jīng)過微軟深度定制開發(fā)的 DeepSpeed,其中,DeepSpeed 的模型并行等內(nèi)核取自 Megatron,它們都是專門為支持 PyTorch 分布式訓(xùn)練 GPT 而設(shè)計(jì)。
不過在實(shí)際訓(xùn)練中,PyTorch 、 Megatron、DeepSpeed 都走了一條非常長的彎路。不僅是彎路,你會(huì)發(fā)現(xiàn) Megatron 的代碼只能被 NVIDIA 的分布式訓(xùn)練專家所復(fù)用,它對(duì)于 PyTorch 的算法工程師而言門檻極高,以至于任何想要用 PyTorch 復(fù)現(xiàn)一個(gè)分布式大模型的算法工程師,都得先等 NVIDIA 開發(fā)完才能再使用 Megatron 提供的模型。
作為新一代深度學(xué)習(xí)開源框架,致力于“大模型分布式”高效開發(fā)的 OneFlow 框架用一套通用設(shè)計(jì)非常簡單清晰地解決了GPT模型的分布式訓(xùn)練難題,同時(shí)還在已有的測試規(guī)模上性能超過 NVIDIA 的 Megatron,這為大規(guī)模分布式訓(xùn)練框架提出了更優(yōu)的設(shè)計(jì)理念和路徑。
一、PyTorch 分布式訓(xùn)練GPT的痛點(diǎn)是什么?
此前,NVIDIA 放出了一篇重量級(jí)的論文:Efficient Large-Scale Language Model Training on GPU Clusters ,用 3072 張 80 GB A100 訓(xùn)練 GPT,最大規(guī)模的模型參數(shù)量達(dá)到了 1T,這是 GPT-3 原版規(guī)模的 5 倍。

NVIDIA 訓(xùn)練 GPT-3 最大到 1T 參數(shù)規(guī)模
論文里,NVIDIA 介紹了分布式訓(xùn)練超大規(guī)模模型的三種必須的并行技術(shù):
· 數(shù)據(jù)并行(Data Parallelism)
· 模型并行(Tensor Model Parallelism)
· 流水并行(Pipeline Model Parallelism)
其中,數(shù)據(jù)并行是最常見的并行方式。而模型并行是對(duì)某一層(如 Linear/Dense Layer 里的 Variable )的模型 Tensor 切分,從而將大的模型 Tensor 分成多個(gè)相對(duì)較小的 Tensor 進(jìn)行并行計(jì)算;流水并行,是將整個(gè)網(wǎng)絡(luò)分段(stage),不同段在不同的設(shè)備上,前后階段流水分批工作,通過一種“接力”的方式并行。
對(duì)于 1T 規(guī)模的模型,NVIDIA 一共使用了 384 臺(tái) DGX-A100 機(jī)器(每臺(tái)裝有 8 張 80GB A100 GPU),機(jī)器內(nèi)部各 GPU 間使用超高速 NVLink 和 NVSwitch 互聯(lián),每臺(tái)機(jī)器裝有 8 個(gè) 200Gbps 的 InfiniBand (IB) 網(wǎng)卡,可以說是硬件集群頂配中的頂配。
那么,這些機(jī)器是如何協(xié)同工作的?GPT 網(wǎng)絡(luò)是由很多層 Transformer Layer 組成,每一層內(nèi)部是一個(gè)由多層 MLP 和 attention 機(jī)制組成的子圖,對(duì)于參數(shù)規(guī)模 1T 的 GPT 而言就有 128 層的 Transformer Layer,這個(gè)超大超深的網(wǎng)絡(luò)被分割成了 64 個(gè) stage (階段),每個(gè) stage 跑在 6 臺(tái) DGX-A100 上,其中 6 臺(tái)機(jī)器之間進(jìn)行數(shù)據(jù)并行,每臺(tái)機(jī)器內(nèi)部的 8 張卡之間做模型并行,整個(gè)集群的 3072 張 A100 按照機(jī)器拓?fù)浔粍澐殖闪?[6 x 8 x 64] 的矩陣,同時(shí)使用數(shù)據(jù)并行 & 模型并行 & 流水并行進(jìn)行訓(xùn)練。

3072 張 A100 集群拓?fù)?/p>
GPipe、梯度累加、重計(jì)算(Checkpointing)和 1F1B(One Forward pass followed by One Backward pass)是分布式訓(xùn)練 GPT 的流水并行的核心技術(shù)。無論是 NVIDIA 的Megatron(PyTorch),還是 OneFlow、PaddlePaddle、MindSpore ,都是通過不同的設(shè)計(jì)實(shí)現(xiàn)了上述相同的功能。
基于 PyTorch 開發(fā)的 Megatron,本質(zhì)上是一個(gè)專用于 GPT 的模型庫,所有的代碼都是 Python 腳本,NVIDIA 為 GPT 專門定制了分布式訓(xùn)練所需的算子、流水并行調(diào)度器、模型并行所需的通信原語等功能,在 GPU 上的性能表現(xiàn)上,Megatron已經(jīng)非常優(yōu)異。可以說,NVIDIA 在使用 PyTorch 做分布式訓(xùn)練上已經(jīng)做到極致了。
但是,用 PyTorch 做分布式訓(xùn)練,真的好用嗎?
具體來說,從PyTorch 在分布式并行上的設(shè)計(jì)以及開放給用戶的接口來看,PyTorch 分布式的有以下困境:
· PyTorch 只有物理視角(Physical View),沒有邏輯視角(Logical View)。PyTorch 的用戶想要做分布式并行,任何時(shí)候都需要自己推導(dǎo)深度學(xué)習(xí)模型中哪處需要跟其他的物理設(shè)備進(jìn)行通信和數(shù)據(jù)同步操作,既要推導(dǎo)通信所在的位置,又要推導(dǎo)通信的操作類型,還要推導(dǎo)跟其他哪些設(shè)備通信。這個(gè)在簡單的數(shù)據(jù)并行下可以使用 DDP 或 Horovod 來實(shí)現(xiàn),但是在復(fù)雜的模型并行、混合并行下,做并行的門檻非常高。
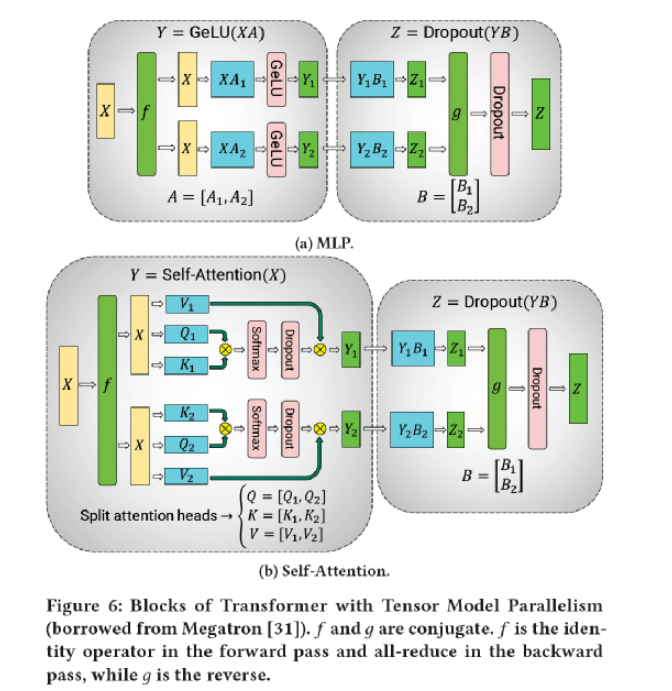
NVIDIA 模型并行通信推導(dǎo)
· PyTorch 沒有將模型網(wǎng)絡(luò)的算法邏輯和分布式并行訓(xùn)練的通信邏輯解耦出來,導(dǎo)致用戶需要在算子的 kernel 實(shí)現(xiàn)中,搭網(wǎng)絡(luò)的腳本里到處插入通信原語。這些手寫通信原語的操作不僅繁瑣、易錯(cuò)、而且沒法復(fù)用,是根據(jù)特定模型、特定腳本位置、特定算子特判得到的。
· PyTorch 在非對(duì)稱的并行方式里(如流水并行,PyTorch 需要人工排線和精細(xì)控制流水),各個(gè)設(shè)備的調(diào)度邏輯需要用戶自己手寫。用戶需要自己精細(xì)的控制每個(gè)設(shè)備上的啟動(dòng)以及執(zhí)行邏輯,且執(zhí)行邏輯把前后向執(zhí)行和send/recv通信操作糅合在一起,即使在最規(guī)整的 Transformer Layer 的流水并行下也很復(fù)雜,想要擴(kuò)展到其他模型上的工作量也很大。
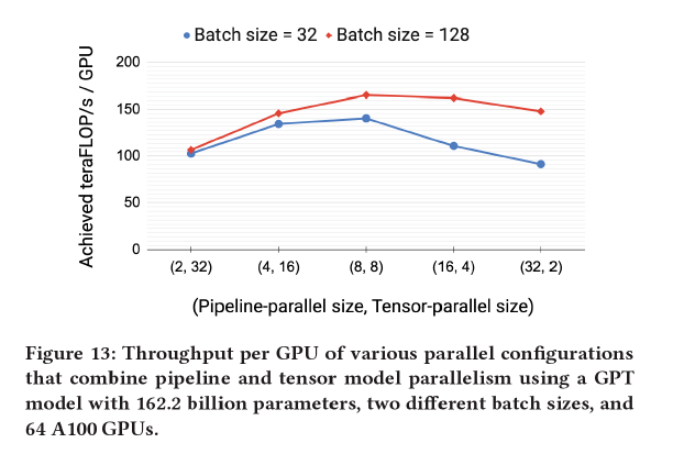
模型并行度和流水并行度對(duì)性能的影響
· PyTorch 沒有機(jī)制保證分布式并行訓(xùn)練中的正確性和數(shù)學(xué)一致性。即使用戶寫錯(cuò)了通信操作,插錯(cuò)了位置, 跟錯(cuò)誤的設(shè)備進(jìn)行通信,PyTorch也檢查不出來。
上述困境使得普通算法工程師使用 PyTorch 開發(fā)復(fù)雜分布式訓(xùn)練的腳本極為困難。其實(shí),NVIDIA、 微軟、 PyTorch 都被繞進(jìn)了一個(gè)大坑:在沒有一致性視角( Consistent View )的情況下做復(fù)雜的分布式并行非常困難,往往只能做一些具體網(wǎng)絡(luò)、具體場景、具體算子的特判和分析,通過簡單的通信原語來實(shí)現(xiàn)分布式。
那么,OneFlow如何解決這些困境?
二、OneFlow 用一致性視角輕松填平分布式訓(xùn)練難的鴻溝
對(duì)于分布式集群環(huán)境(多機(jī)多卡訓(xùn)練場景),OneFlow 會(huì)把整個(gè)分布式集群抽象成一個(gè)超級(jí)設(shè)備,用戶只需要在這個(gè)超級(jí)設(shè)備上搭建深度學(xué)習(xí)模型即可。這個(gè)虛擬出來的超級(jí)設(shè)備稱之為邏輯視角,而實(shí)際上的分布式集群的多機(jī)多卡就是物理視角,OneFlow維護(hù)邏輯視角和物理視角之間的數(shù)學(xué)上的正確性就稱之為一致性視角。
基于分布式訓(xùn)練難的鴻溝,OneFlow通過一致性視角下的 Placement(流水并行) + SBP (數(shù)據(jù)和模型的混合并行),非常簡單的實(shí)現(xiàn)了通用的復(fù)雜并行支持。當(dāng)然,這離不開 OneFlow 的兩大獨(dú)特設(shè)計(jì):
1. 運(yùn)行時(shí) Actor 機(jī)制
2. 編譯期一致性視角,通過 Placement + SBP + Boxing 解決分布式易用性的問題。

一致性視角(Consistent View)抽象
理想情況下,抽象出來的超級(jí)設(shè)備(邏輯視角)的算力是所有物理視角下的設(shè)備算力之和(如果算力完全用滿,就是線性加速比);邏輯視角下的顯存資源也是所有物理設(shè)備的顯存資源之和。
總體而言,基于一致性視角的 OneFlow 分布式有以下易用性體現(xiàn):
· OneFlow 的一致性視角將分布式訓(xùn)練下的多機(jī)通信和算法邏輯解耦,使得用戶可以不用關(guān)心分布式訓(xùn)練的細(xì)節(jié),降低了分布式訓(xùn)練的使用門檻。
· 相比其他框架和高級(jí)定制用戶在所有分布式并行上的努力,OneFlow 通過 Placement + SBP 機(jī)制解決了分布式訓(xùn)練中任意并行場景的需求。用戶只需要配置 op 的 Placement 就可以完成流水并行,只需要配置 Tensor 的 SBP 就可以實(shí)現(xiàn)數(shù)據(jù)并行、模型并行和混合并行。并且,任何并行方式都是 Placement + SBP 的一種特例, OneFlow 從系統(tǒng)層面不需要做任何的特判,SBP 才是各種分布式并行的本質(zhì)。
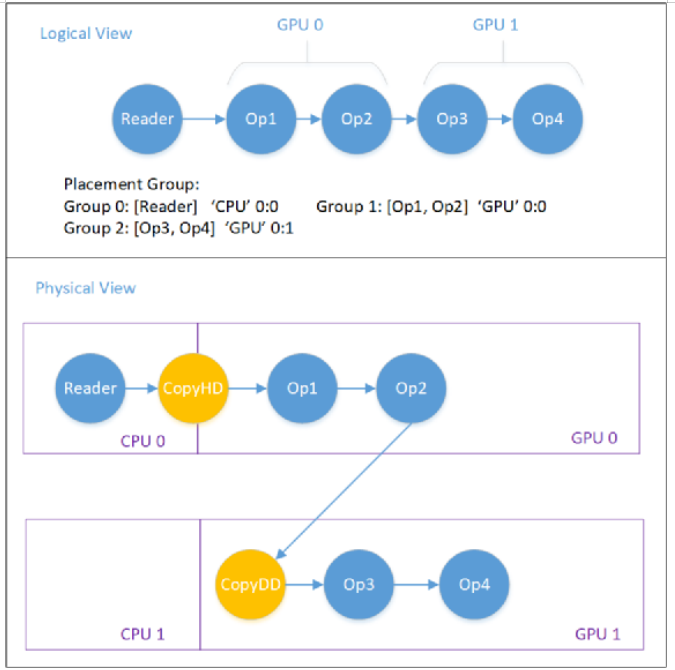
上圖展示了一個(gè) Placement 例子,用于 GPU0 和 GPU1 之間的流水并行。圖中負(fù)責(zé)在 CPU 和 GPU、GPU 與 GPU 之間進(jìn)行數(shù)據(jù)搬運(yùn)的Op(CopyH2D、CopyD2D)是 OneFlow 系統(tǒng)自動(dòng)添加的。
· OneFlow 的通信邏輯可以復(fù)用,不需要為任何特定網(wǎng)絡(luò)和特定算子實(shí)現(xiàn)相應(yīng)的通信邏輯。通信邏輯由 OneFlow 的 Boxing 機(jī)制完成,與具體的算子和模型無關(guān)。
· OneFlow 的 SBP 還保證了數(shù)學(xué)上的一致性。 相同的邏輯上的模型腳本,使用任意的并行方式(數(shù)據(jù)并行、模型并行、流水并行)、使用任意的集群拓?fù)洌琌neFlow 都從數(shù)學(xué)上保證了模型分布式訓(xùn)練的正確性。
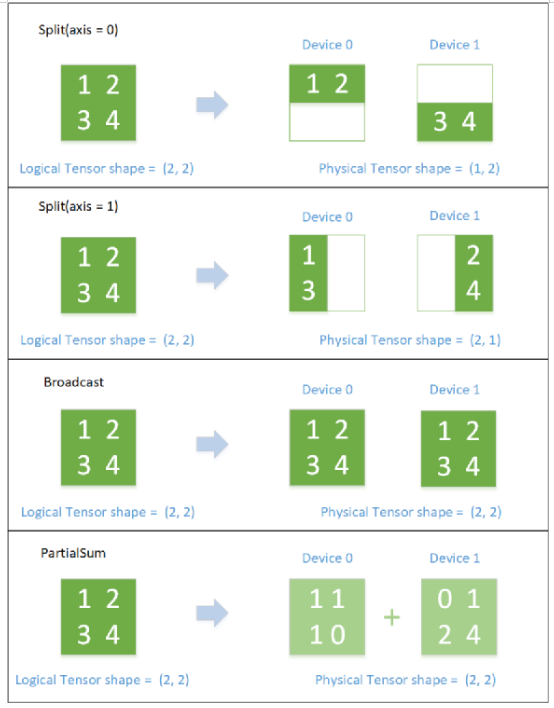
SBP 邏輯與物理 Tensor 的對(duì)應(yīng)關(guān)系(SBP 描述了 邏輯上的 Tensor 和 物理上的 Tensor 的映射關(guān)系。SBP 全稱叫做 SbpParallel,是三種基礎(chǔ)映射的首字母組合:Split、Broadcast、Partial,其中 Partial 是一個(gè) reduce 操作,包括 PartialSum、PartialMin、PartialMax等)
采用這樣一套簡潔設(shè)計(jì)可解決分布式并行的各種難題,OneFlow 使得每一位算法工程師都有能力訓(xùn)練 GPT模型。它讓你不需要成為一位分布式訓(xùn)練的專家也有能力做復(fù)雜的分布式訓(xùn)練, 只要有硬件資源,任何一位算法工程師都可以訓(xùn)練 GPT, 都可以開發(fā)一個(gè)新的大規(guī)模分布式訓(xùn)練的模型。
三、為什么分布式深度學(xué)習(xí)框架要像 OneFlow 這樣設(shè)計(jì)?
上述內(nèi)容從用戶角度分析和比較了 OneFlow 和 PyTorch(Megatron)的分布式易用性,
那么從框架設(shè)計(jì)和開發(fā)者的角度,它又是如何具體實(shí)現(xiàn)分布式并行的?為什么說 OneFlow 會(huì)是分布式訓(xùn)練更為本質(zhì)的設(shè)計(jì)?
1. OneFlow 如何實(shí)現(xiàn)流水并行?
OneFlow 的運(yùn)行時(shí) Actor 機(jī)制有以下幾個(gè)特點(diǎn):
· 天然支持流水線, Actor 通過內(nèi)部的狀態(tài)機(jī)和產(chǎn)出的 Regst 個(gè)數(shù)以及上下游的 Regst 消息機(jī)制解決了流控問題(Control Flow)。
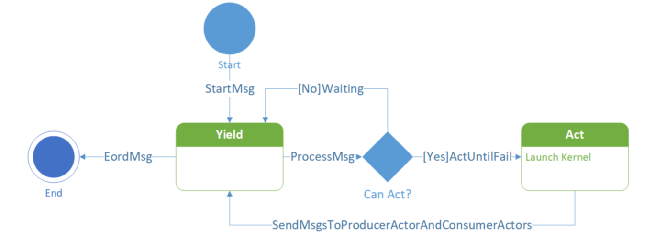
Actor 狀態(tài)機(jī)
· Actor 組成的計(jì)算圖運(yùn)行時(shí)調(diào)度是去中心化的,每個(gè) Actor 當(dāng)前是否可以執(zhí)行都僅與自己的狀態(tài)、空閑 Regst 數(shù)量以及收到的消息有關(guān)。
所以使用 Actor 做流水并行,本身就不需要自己定制復(fù)雜的調(diào)度邏輯。以數(shù)據(jù)加載的 Pipeline 為例, 當(dāng)一個(gè)由 Actor 組成的數(shù)據(jù)預(yù)處理流程如下圖所示:

數(shù)據(jù)預(yù)處理流程
當(dāng)這4個(gè)Actor之間的 RegstNum 均為2時(shí),如果訓(xùn)練時(shí)間比較長(訓(xùn)練是整個(gè)網(wǎng)絡(luò)的瓶頸),就會(huì)得到如下這種流水線的時(shí)間線:
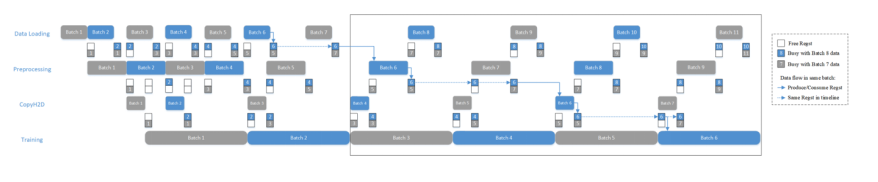
數(shù)據(jù)預(yù)處理 pipeline 時(shí)間線
在執(zhí)行幾個(gè) Batch 之后, 4 個(gè)階段的執(zhí)行節(jié)奏完全被最長的那個(gè)階段所控制,這就是 OneFlow 使用背壓機(jī)制(Back Pressure)解決流控問題。
所以流水并行問題,在 OneFlow 中就是 Regst 數(shù)量的問題。在實(shí)際實(shí)現(xiàn)中, OneFlow 采用了一個(gè)更通用的算法實(shí)現(xiàn)了 Megatron 的流水并行:插入 Buffer Op。在邏輯計(jì)算圖上, 會(huì)給后向消費(fèi)前向的邊插入一個(gè) Buffer Op, Buffer 的 Regst 數(shù)量 和 Stage 相關(guān)。由于后向?qū)η跋虻南M(fèi)經(jīng)過 Checkpointing 優(yōu)化后,每個(gè) Placement Group 下只會(huì)有非常少的幾條消費(fèi)邊。

OneFlow 通過插入 Buffer Op 實(shí)現(xiàn)流水并行
與 Megatron 復(fù)雜的手寫調(diào)度器和手寫通信原語相比, OneFlow 系統(tǒng)層面只需要插入 Buffer 就可以實(shí)現(xiàn)流水并行。
2. OneFlow 如何實(shí)現(xiàn)數(shù)據(jù)+模型的混合并行?
以 Linear Layer 的數(shù)據(jù) + 模型并行為例,來解釋所有的數(shù)據(jù)并行和模型并行的組合,本質(zhì)上都是被 SBP 所描述的 Signature。任何并行方式的設(shè)備間通信操作,該在整個(gè)網(wǎng)絡(luò)的哪里插入、該插入什么通信操作、每個(gè)設(shè)備該和誰通信,完全都是 SBP 自動(dòng)推導(dǎo)得到的,而且還保證數(shù)學(xué)上的一致性。
可以說,OneFlow的設(shè)計(jì)使得算法工程師告別了分布式并行中的通信原語。不僅如此,OneFlow 的框架開發(fā)者絕大多數(shù)時(shí)候也不需要關(guān)心分布式里的通信原語,SBP 這層抽象使得算子/網(wǎng)絡(luò)跟分布式通信解耦。
以 1-D SBP 為例,1-D SBP 下的數(shù)據(jù)并行,對(duì)于一個(gè) Linear Layer 而言,主要是其中的 MatMul(矩陣乘法)計(jì)算。假設(shè)矩陣乘法計(jì)算在邏輯視角上是一個(gè) (m, k) x (k, n) = (m, n) 的計(jì)算,m 表示一共有多少個(gè)樣例, k 和 n 分別是 Linear Layer 中的隱藏層神經(jīng)元數(shù)量以及輸出神經(jīng)元數(shù)量。
數(shù)據(jù)并行的邏輯計(jì)算圖 -》 物理計(jì)算圖 的映射關(guān)系如下圖所示:

數(shù)據(jù)并行下邏輯計(jì)算圖轉(zhuǎn)物理計(jì)算圖
數(shù)據(jù)并行下,每個(gè)設(shè)備上都有全部的模型(Tensor b, Shape = (k, n)),假設(shè)共有兩張卡,則 GPU0 上有前一半的數(shù)據(jù) (Tensor a,Shape = (m/2, k)),GPU1 上有后一半的數(shù)據(jù), 則Tensor a 的 SBP Parallel = Split(0)。同時(shí)可以看到矩陣乘的輸出 Tensor out,也是按照第 0 維切分的。
模型并行對(duì)于 Linear Layer 而言,有兩種,分別是切模型 Tensor 的第0維(行切分,對(duì)應(yīng) Megatron 里的 RowParallelLinear)和 第1維(列切分,對(duì)應(yīng) Megatron 里的 ColumnParallelLinear)。
第一種行切分(RowParallelLinear)模型并行的 邏輯計(jì)算圖 -》 物理計(jì)算圖 的映射關(guān)系如下圖所示:
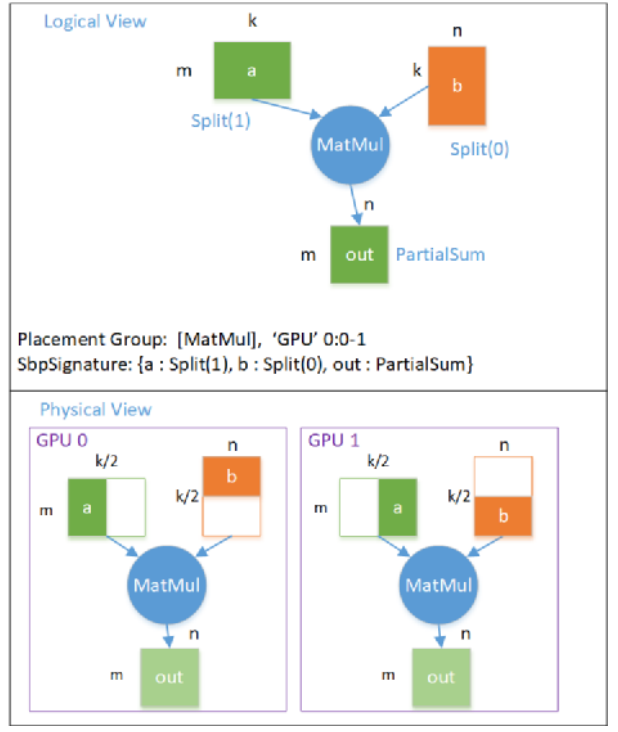
模型并行(行切分) 邏輯圖轉(zhuǎn)物理圖
模型并行下,每個(gè)設(shè)備都只有一部分的模型,在這個(gè)例子中, GPU 0 上有前一半的模型, GPU 1上有后一半的模型,每個(gè)設(shè)備上的模型大小 Tensor b 的 Shape = (k/2, n)。在這種情況下, 每個(gè)設(shè)備輸出的 Tensor out 都是完整的數(shù)據(jù)大小, Shape = (m, n), 但每個(gè)位置上的元素的值,都是邏輯上的輸出 out 對(duì)應(yīng)位置的值的一部分,即 out 的 SBP Parallel = PartialSum 。
第二種列切分(ColumnParallelLinear)模型并行的 邏輯計(jì)算圖 -》 物理計(jì)算圖 的映射關(guān)系如下圖所示:
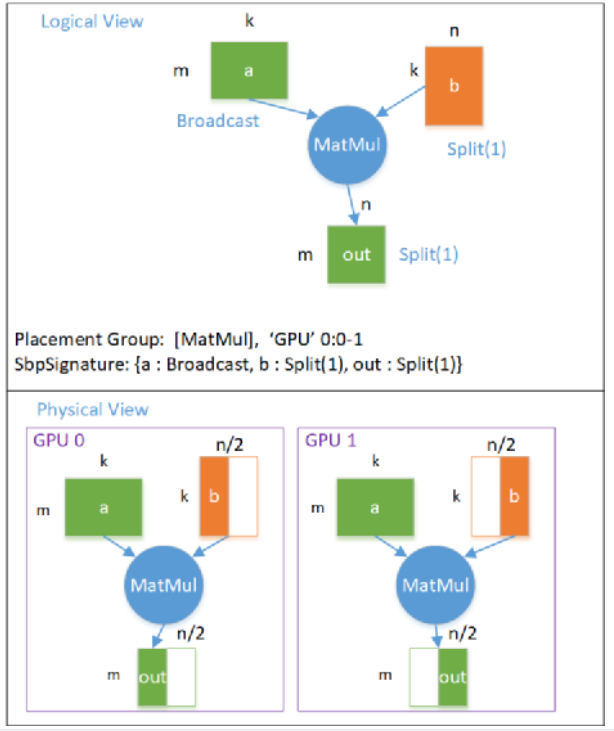
模型并行(列切分)邏輯圖轉(zhuǎn)物理圖
這個(gè)例子中,模型 Tensor b 是按照 Split(1) 切分的,輸出 Tensor out 也是按照 Split(1) 切分的,每個(gè)設(shè)備都需要全部的數(shù)據(jù)。
在 GPT 網(wǎng)絡(luò)中,實(shí)際上的模型并行是組合使用 RowParallelLinear 和 ColumnParallelLinear 實(shí)現(xiàn)的(ColumnParallelLinear 后面接了 RowParallelLinear)。
因?yàn)?Column 的輸出 Tensor SBP 是 Split(1), Row 的輸入數(shù)據(jù) Tensor SBP 也是 Split(1), 所以當(dāng) Column 后接 Row 時(shí),兩者之間是不需要插入任何通信的。但由于 Row 的輸出是 PartialSum, 當(dāng)后面消費(fèi)該 Tensor (在網(wǎng)絡(luò)中是 Add 操作)的 Op 需要全部的數(shù)據(jù)時(shí)(Broadcast), 此處就需要插入 AllReduce 實(shí)現(xiàn)通信了。
這在 OneFlow 中稱之為 Boxing。 當(dāng)兩個(gè)邏輯上的 Op 對(duì)于同一個(gè)邏輯上的 Tensor 看待的 SBP Parallel 不一致時(shí), OneFlow 系統(tǒng)會(huì)自動(dòng)插入通信節(jié)點(diǎn)以完成數(shù)據(jù)的切分/傳輸/拼接等操作,使得下游 Op 總能拿到按照自己期望 SBP 切分的 Tensor。
?

Boxing:通過 AllGather 實(shí)現(xiàn) Split(1) 轉(zhuǎn) Broadcast
在 OneFlow 中, 所有的分布式通信操作都是基于 SBP 的推導(dǎo)結(jié)果,按照需要插入。OneFlow 通過 Boxing 機(jī)制,就實(shí)現(xiàn)了任意的數(shù)據(jù)并行和模型并行。
2-D SBP 其實(shí)就是將兩組 1-D SBP 按照設(shè)備拓?fù)涞木S度拼起來就可以得到。其實(shí) GPT 中用到的 2-D SBP 只是最簡單情形的特例, 分布式下的并行經(jīng)過 2-D SBP 可以拓展出非常多復(fù)雜、靈活多邊的組合出來。而針對(duì)復(fù)雜的組合, 再想用 Megatron 的設(shè)計(jì)就非常難做,但對(duì)于 OneFlow 而言,二者的難度是一樣的,因?yàn)楸举|(zhì)上是用 Boxing 完成一組 2-D SBP 的變換。
四、GPT 分布式訓(xùn)練性能對(duì)比:OneFlow vs Megatron
與 Megatron 相比,OneFlow 除了在用戶接口(分布式易用性) 和框架設(shè)計(jì)上更簡潔、更易用,在 4 機(jī) 32卡 16GB V100 的測試規(guī)模上性能也超過 Megatron。值得一提的是,經(jīng)過 NVIDIA 的深度優(yōu)化, Megatron 在 GPU 上的分布式訓(xùn)練性能已經(jīng)接近極致,DeepSpeed 也無法與之相比。
以下的所有實(shí)驗(yàn)數(shù)據(jù)均在相同的硬件環(huán)境、相同的第三方依賴(CUDA、 cuDNN等)、使用相同的參數(shù)和網(wǎng)絡(luò)結(jié)構(gòu)下, 對(duì)比了 OneFlow 和 Megatron 在 GPT 模型下的性能表現(xiàn)。所有的性能結(jié)果均公開且可復(fù)現(xiàn)。(GPT 模型腳本在Oneflow-Inc/OneFlow-Benchmark 倉庫, 公開的評(píng)測報(bào)告、復(fù)現(xiàn)方式稍后在Oneflow-Inc/DLPerf 倉庫中可查看。)

數(shù)據(jù)并行性能對(duì)比
注:每組參數(shù)的縮略版含義:
· DP 數(shù)據(jù)并行;MP 模型并行;2D 數(shù)據(jù) & 模型 的 混合并行;PP 流水并行
· dxmxp_B_hxl 其中:
· d = 數(shù)據(jù)并行度(data-parallel-size)
· m = 模型并行度(tensor-model-parallel-size)
· p = 流水并行度(pipeline-model-parallel-size)
· B = 總的BatchSize(global-batch-size)
· h = 隱藏層大小(hidden-size)影響每層 Transformer Layer 的模型大小
· l = Transformer Layer 層數(shù)(num-layers)
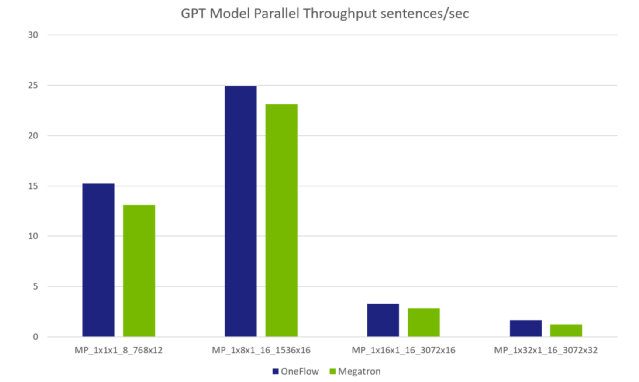
模型并行數(shù)據(jù)對(duì)比
注:由于單卡 GPU 顯存限制,各組參數(shù)里的模型大小是不同的,所以整體不像數(shù)據(jù)并行那樣呈線性增加的關(guān)系。如第 4 組參數(shù)(MP_1x32x1_16_3072x32)的模型大小是第 2 組參數(shù)(MP_1x8x1_16_1536x16)的 8 倍以上。NVIDIA 論文中有模型規(guī)模跟各個(gè)參數(shù)的計(jì)算公式:

其中 l 表示 num-layers ,h 表示 hidden-size, V 表示詞表大小(vocabulary size = 51200), S 表示句子長度(a sequence length = 2048), P 表示參數(shù)規(guī)模。
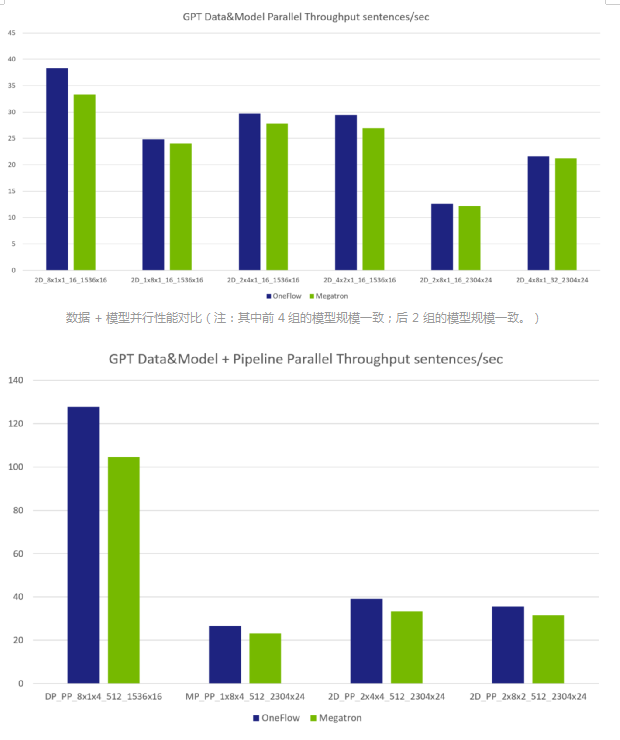
數(shù)據(jù)+模型+流水并行性能對(duì)比(注:第 1 組參數(shù)的模型比后 3 組的都要小,因?yàn)闄C(jī)器內(nèi)的數(shù)據(jù)并行限制了參數(shù)規(guī)模。)
五、小結(jié)
在分布式訓(xùn)練領(lǐng)域擁有獨(dú)特的設(shè)計(jì)和視角,OneFlow 解決了分布式訓(xùn)練中的各種并行難題,因此在大規(guī)模預(yù)訓(xùn)練模型場景下用 OneFlow 做分布式訓(xùn)練更易用也更高效。
同時(shí),OneFlow 團(tuán)隊(duì)正在全力提升框架的單卡使用體驗(yàn)。據(jù)悉,OneFlow 即將在 5 月發(fā)布的大版本 OneFlow v0.4.0 起,將提供兼容 PyTorch 的全新接口以及動(dòng)態(tài)圖等特性。而在 v0.5.0 版本,OneFlow 預(yù)計(jì)全面兼容 PyTorch, 屆時(shí)用戶可將 PyTorch 的模型訓(xùn)練腳本一鍵遷移為 OneFlow 的訓(xùn)練腳本。此外, OneFlow 還會(huì)提供 Consistent 視角的分布式 Eager,用戶可以既享受動(dòng)態(tài)圖的易用性,又可以非常方便的進(jìn)行各種分布式并行訓(xùn)練。














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論