 電子發燒友App
電子發燒友App


? ? 導讀:在剛剛舉辦的硅谷芯片技術研討會Hot Chips 34會議上,備受關注的特斯拉Dojo超算指令集結構細節史上首次被公開。 ? 為了滿足對人工智能和機器學習模型越來越大的需求, 特斯拉創建了自己的人工智能技術,來教特斯拉的汽車自動駕駛。 ? 最近,特斯拉在Hot Chips 34會議上,披露了大量關于Dojo(道場)超級計算架構的細節。 ?
本質上,Dojo是一個巨大的可組合的超級計算機,它由一個完全定制的架構構建,涵蓋了計算、網絡、輸入/輸出(I/O)芯片到指令集架構(ISA)、電源傳輸、包裝和冷卻。所有這些都是為了大規模地運行定制的、特定的機器學習訓練算法。 ? Ganesh Venkataramanan是Tesla自動駕駛硬件高級總監,負責Dojo項目,以及AMD的CPU設計團隊。Hot Chips 34會議上,他和眾位芯片、系統和軟件工程師首次公開了該機器的許多架構特性。
? 數據中心「三明治」 ? 「 一般來說,我們制造芯片的過程,是把它們放在包裝上,把包裝放在印刷電路板上,然后進入系統。系統進入機架。」Venkataramanan說。 ? 但是這個過程中存在一個問題:每次數據從芯片移動到封裝上并離開封裝時,都會產生延遲和帶寬損失。 ? 為了繞過這些限制,Venkataramanan和他的團隊決定從頭開始。 ?

? 由此,Dojo的訓練瓦片誕生了。 ? 這是一個獨立的計算集群,占地半立方英尺,在15千瓦的液冷封裝中能夠達到556TFLOPS的FP32性能。 ? 每個瓦片都配備了11GB的SRAM,并在整個堆棧中使用定制的傳輸協議,通過9TB/s結構連接。 ? Venkataramanan說:「這塊訓練板代表了從計算機到存儲器、到電源傳輸、到通信的無與倫比的集成度,不需要任何額外的開關。」 ? 訓練瓦片的核心是特斯拉的D1,這是一個500億個晶體管芯片,基于臺積電的7納米工藝。特斯拉表示,每個D1能夠在400W的TDP下實現22TFLOPS的FP32性能。 ?

? 特斯拉然后用25個D1,把它們分到已知的好模具上,然后用臺積電的晶圓上系統技術把它們包裝起來,以極低的延遲和極高的帶寬實現大量的計算集成。 ? 然而,晶片上的系統設計和垂直堆疊架構,給電力輸送帶來了挑戰。 ?
據Venkataramanan說,目前大多數加速器將電源直接放在硅片旁邊。他解釋說,這種方法雖然行之有效,但這就意味著加速器的很大一部分區域必須專門用于這些組件,這對Dojo來說是不切實際的。于是,特斯拉選擇直接通過芯片底部直接提供電源。 ? 此外,特斯拉還開發了Dojo接口處理器(DIP),它是主機CPU和訓練處理器之間的橋梁。 ? 每個DIP都有32GB的HBM,最多可以將五個這樣的卡以900GB/s的速度連接到一個訓練瓦片上,以達到4.5TB/s的總量,每個瓦片共有160GB的HBM。 ?

? 特斯拉的V1配置成對的這些瓦片——或150個D1模具——在陣列中支持四個主機CPU,每個主機CPU配備五個DIP卡,以實現聲稱的BF16或CFP8性能的exaflop。 ?

? 軟件 ? 這樣一個專門的計算架構,就需要一個專門的軟件棧。然而,Venkataramanan和他的團隊認識到,可編程性將決定Dojo的成敗。 ?
「當我們設計這些系統時,軟件同行的易編程性是最重要的。研究人員不會等待你的軟件人員為適應我們想要運行的新算法而寫一個手寫的內核。」 ?
為了做到這一點,特斯拉放棄了使用內核的想法,圍繞編譯器設計了Dojo的架構。 ? 「我們的做法是使用PiTorch。我們創建了一個中間層,它幫助我們并行化,以擴展其下面的硬件。所有東西下面都是編譯過的代碼。」為了創建可適應任何未來工作負載的軟件堆棧,這是唯一的方法。 ? 盡管強調了軟件的靈活性,Venkataramanan指出,目前在他們的實驗室中運行的平臺,暫時僅限于特斯拉使用。 ? Dojo架構一覽 ? 看完了以上這些,讓我們深入了解一下Dojo的架構。
? 特斯拉擁有用于機器學習的百億億次人工智能級系統。特斯拉有足夠的資金規模來雇傭員工,并專門為其應用構建芯片和系統,就像特斯拉的車載系統一樣。 ?

? 特斯拉不僅在構建自己的AI芯片,還在構建超級計算機。 ?

分布式系統分析 ? Dojo的每個節點都有自己的CPU、內存和通信接口。 ?
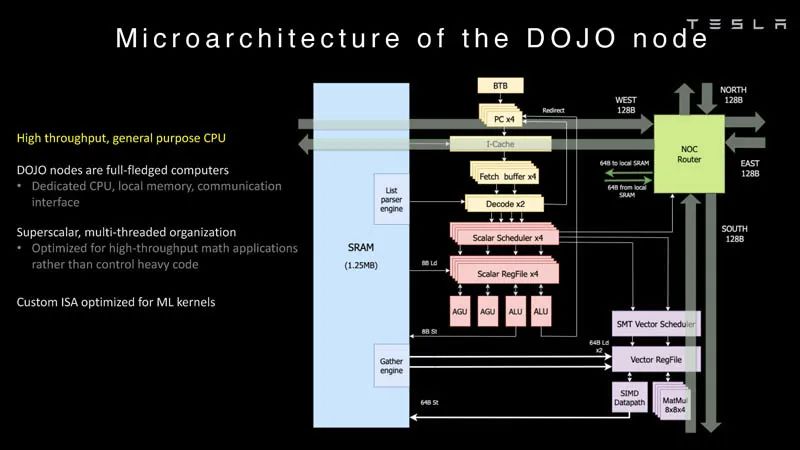
Dojo節點 ? 這是Dojo處理器的處理管線。 ?
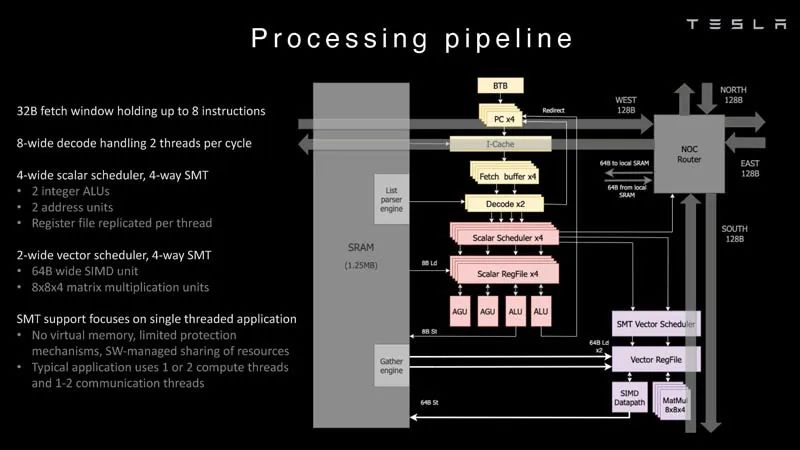
處理管道 ? 每個節點有1.25MB的SRAM。在AI訓練和推理芯片中,一種常見的技術是將內存與計算共置,以最大限度地減少數據傳輸,因為從功率和性能的角度來看,數據傳輸非常昂貴。 ?
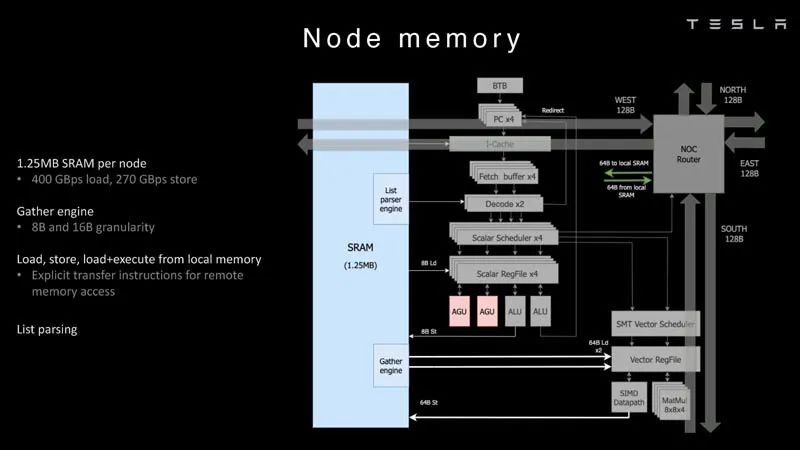
節點內存 然后每個節點都連接到一個2D網格。 ?
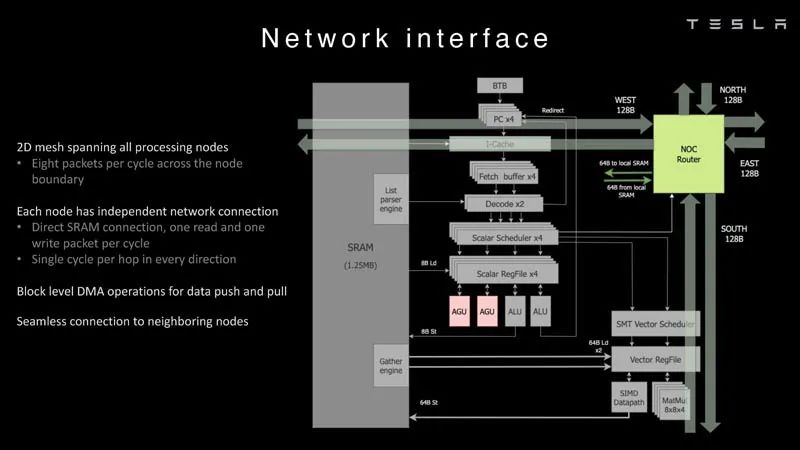
網絡接口 ? 這是數據路徑概述。 ?
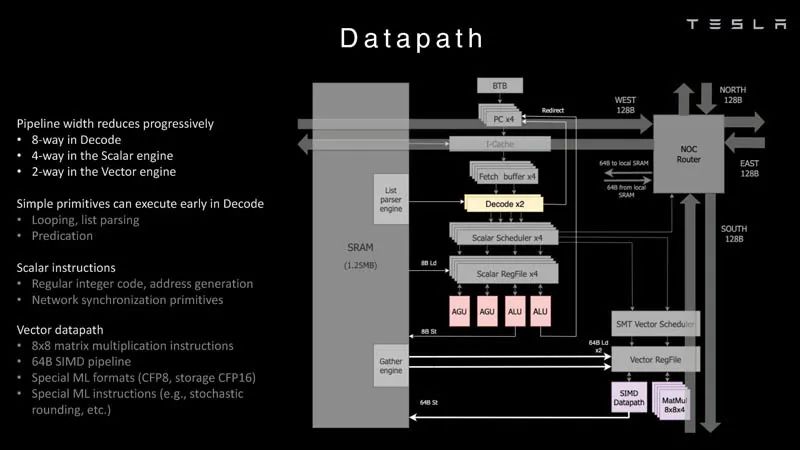
數據路徑 ? 下面是一個例子,說明芯片可以做的列表解析。 ?

列表解析 ? 這里有更多關于指令集的內容,屬于特斯拉原創,而不是典型的Intel、Arm、NVIDIA或AMD CPU/GPU的指令集。 ?
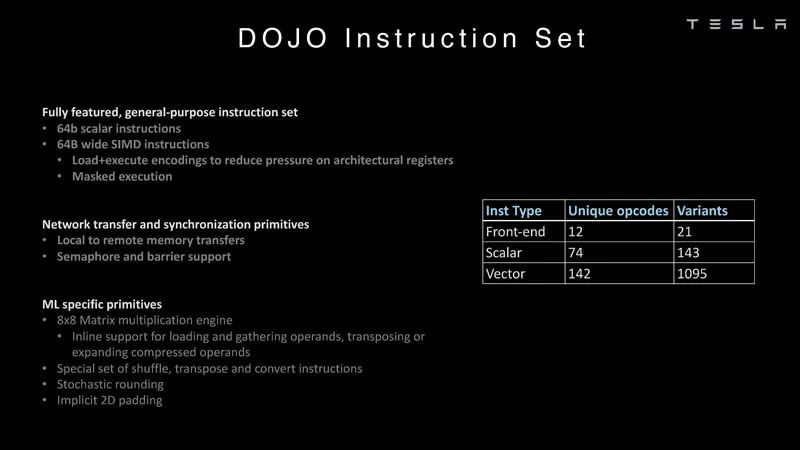
指令集 ? 在人工智能中,算術格式很重要,尤其是芯片支持哪些格式。利用DOJO,特斯拉就可以研究常用格式,例如FP32、FP16和BFP16。這些是常見的行業格式。 ?

算術格式 ? 特斯拉也在研究可配置的FP8或CFP8。它有4/3和5/2的范圍選項。這類似于 NVIDIA H100 Hopper配置的FP8。我們還看到Untether.AI Boqueria 1458 RISC-V核心AI加速器專注于不同的FP8類型。 ?
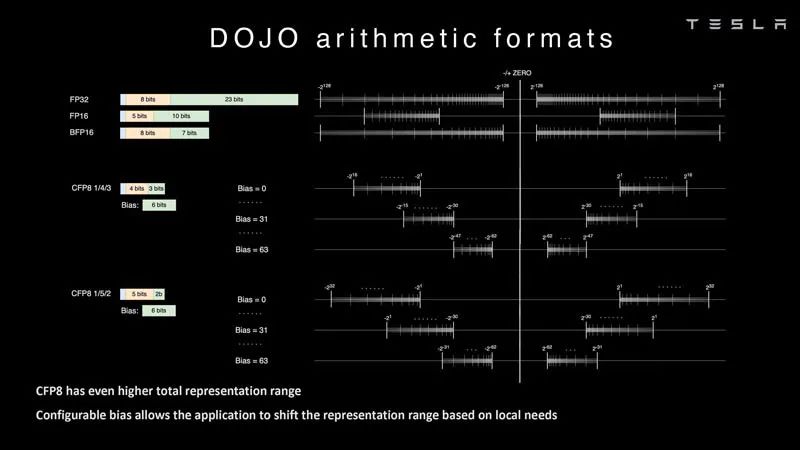
算術格式 2 ? Dojo還具有不同的CFP16格式,以實現更高的精度,并支持FP32、BFP16、CFP8和CFP16。 ?

算術格式 3 ? 然后將這些核心集成到制造的模具中。特斯拉的D1芯片由臺積電以7nm工藝制造。每個芯片有354個Dojo處理節點和440MB的SRAM。 ?
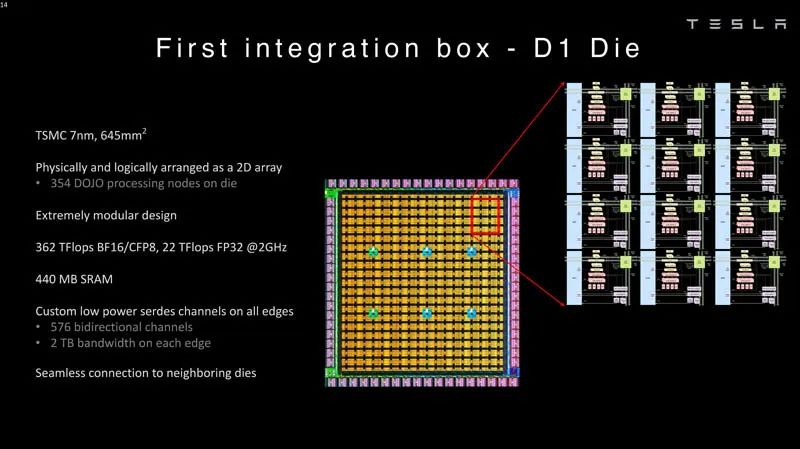
First Integration Box D1 模具 ? 這些D1芯片被封裝在一個道場訓練瓦片上。D1芯片經過測試,然后被組裝成一個5×5的瓦片。這些瓦片每個邊緣有4.5TB/s的帶寬。它們還具有每個模塊15kW的功率傳輸包絡,或者可以說,每個D1芯片去掉40個I/O裸片所使用的功率后,大約還有600W。 ? 通過對比可以看出,如果一家公司不想設計這種東西,為什么像Lightmatter Passage會更有吸引力。 ?

二次集成箱Dojo訓練瓦片 ? Dojo的接口處理器位于2D網格的邊緣。每個訓練塊有11GB的SRAM和160GB的共享DRAM。 ?

Dojo系統拓撲 ? 以下是連接處理節點的2D網格的帶寬數據。 ?

Dojo系統通信邏輯二維網格 ? 每個DIP和主機系統提供32GB/s的鏈接。 ?

Dojo系統通信 PCIe鏈接DIP和主機 ? 特斯拉還具有用于更長路線的Z平面鏈接。在接下來的演講中,特斯拉談到了系統級的創新。 ?

通信機制 ? 這里是die和tiles的延遲邊界,這就是為什么在Dojo中對它們進行不同處理的原因。需要Z平面鏈路的原因是,長路徑很昂貴。 ?
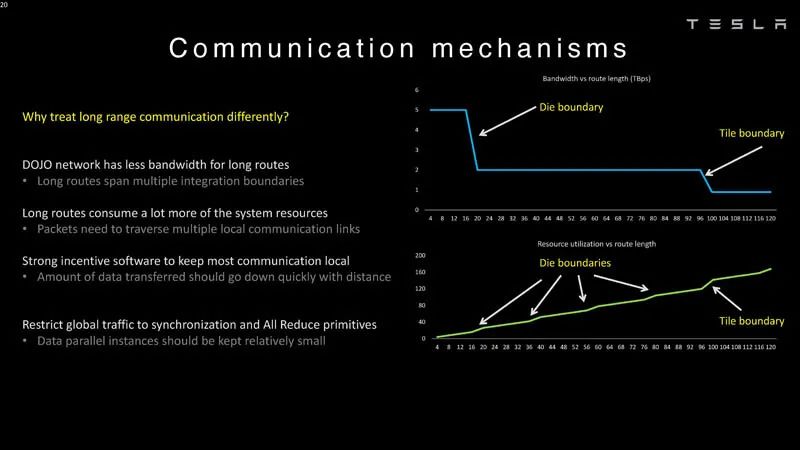
Dojo系統通信機制 ? 任何處理節點都可以跨系統訪問數據。每個節點都可以將數據推送或拉取到SRAM或DRAM。 ?

Dojo系統批量通信 ? Dojo使用平面尋址方案進行通信。 ?

系統網絡1 ? 這些芯片可以在軟件中繞過錯誤的處理節點。 ?
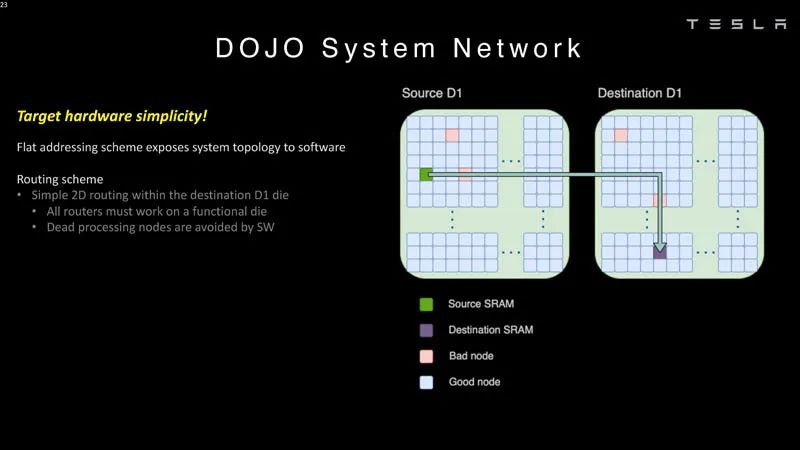
系統網絡2 ? 這意味著軟件必須了解系統拓撲。 ?
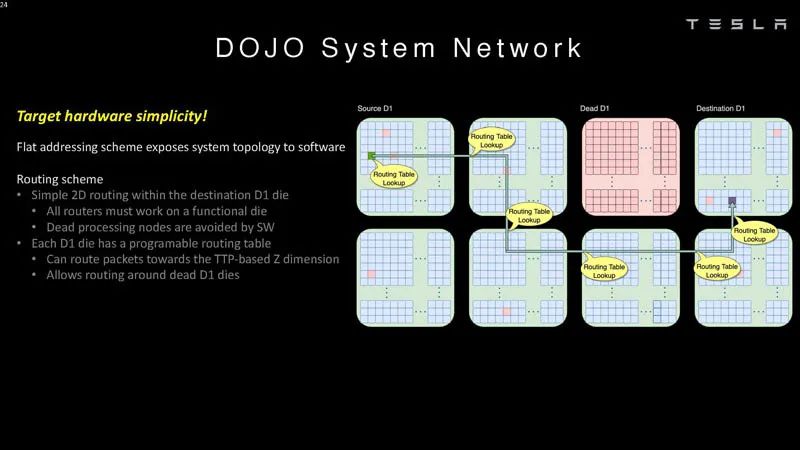
系統網絡3 ? Dojo不保證端到端的流量排序,因此需要在目的地對數據包進行計數。 ?
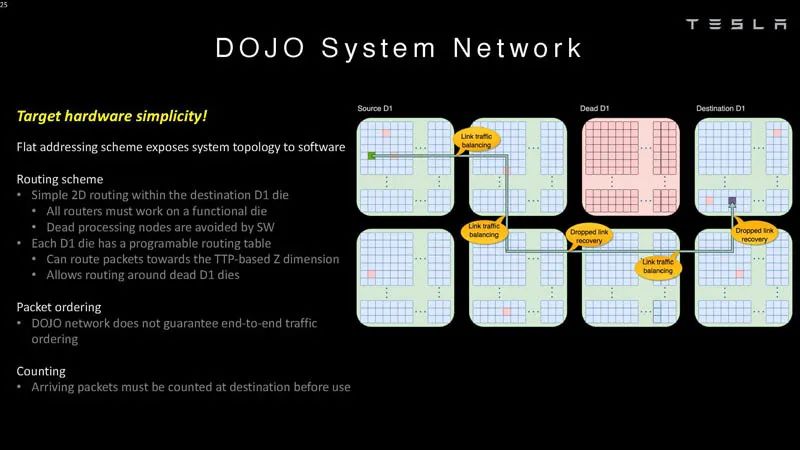
系統網絡4 ? 以下是數據包如何計入系統同步的一部分。 ?
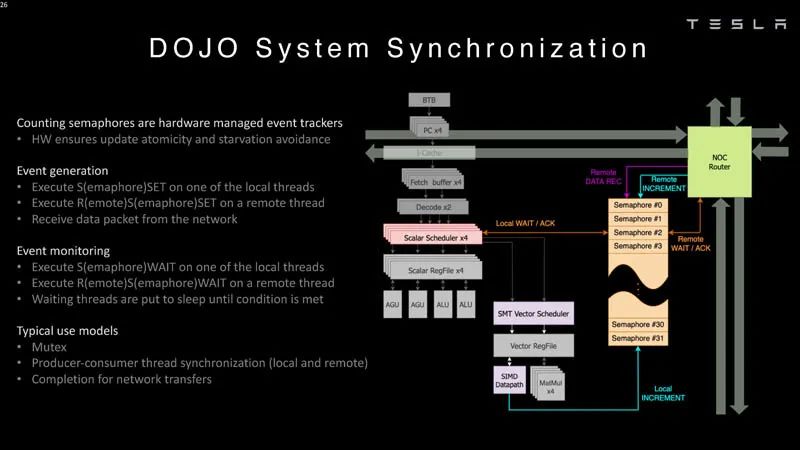
系統同步 ? 編譯器需要定義一個帶有節點的樹。 ?
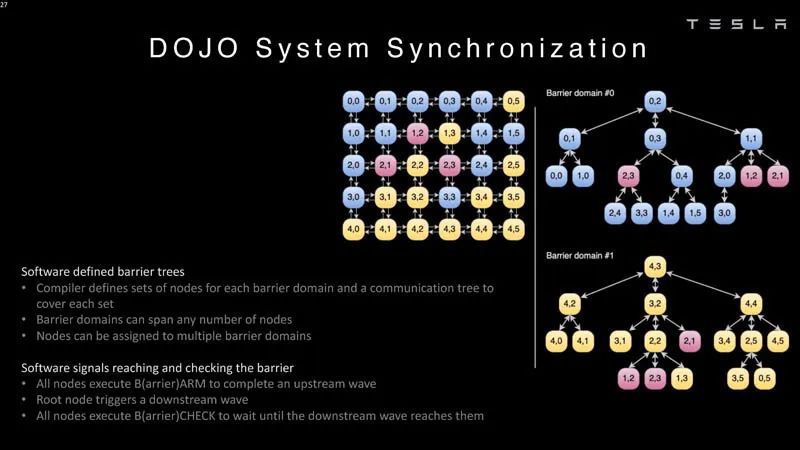
系統同步2 ? 特斯拉表示,一個exa-pod擁有超過100萬個CPU(或計算節點)。這些都是大型系統。 ?

? 總結
特斯拉專門為大規模工作而建造了Dojo。通常,初創公司都希望為每個系統構建一個或幾個芯片的AI芯片。顯然,特斯拉專注于更大的規模。 ? 在許多方面,特斯拉擁有一個巨大的人工智能訓練場是合理的。更令人興奮的是,它不僅使用商業上可用的系統,而且還在構建自己的芯片和系統。標量方面的一些ISA是借用RISC-V的,但矢量方面和很多架構特斯拉都是定制的,所以這需要大量的工作。 ?
編輯:黃飛
?
















 工商網監
工商網監
評論