 電子發燒友App
電子發燒友App


趙 洋 1,2,王藝鋼 1,靳永強 1,華 丹 1
(1. 沈陽化工大學 計算機科學與技術學院,遼寧 沈陽 110142;
(2. 遼寧省化工過程工業智能化技術重點實驗室,遼寧 沈陽 110142)
摘 要 :由于以往視頻煙火檢測模型復雜,存在檢測精度與速度不能兼顧的問題,提出一種改進 SSD 的輕量化視頻煙火檢測算法(GSSD)。該算法首先將 SSD 算法中的骨干網絡替換為 GhostNet 網絡模型,減少算法參數量,提高檢測速度,之后通過 Concat 操作進行多尺度特征融合,提升算法對小目標的檢測精度。該算法分別在PASCAL VOC 2012 數據集和煙火數據集上進行了實驗。實驗結果表明,在相同工況條件下,GSSD 算法相比 SSD算法的 mAP 提高了 4.8%,檢測速度提升了 1.9 倍,參數量減少了 84.64%。
關鍵詞 :煙火檢測 ;輕量化 ;SSD ;GhostNet ;Concat ;特征融合
中圖分類號 :TP751 文獻標識碼 :A? ? ?
文章編號 :2095-1302(2022)08-0031-05
0 引 言
為解決目前火災頻發,消防設施和消防人員不足的問題,減少人民生命和財產安全損失,需要對火災做出更加快速而準確的檢測[1]。目前傳統的煙火檢測通常借助傳感器檢測煙霧氣體特征和火焰紅外信息,這種檢測方法檢測精度低,響應速度慢,在智能化、抗干擾和成本等方面有待加強[2]。基于視頻的煙火檢測可以很好地彌補上述不足。視頻煙火檢測借助攝像頭傳輸的視頻畫面,檢測煙火位置并提供豐富的現場狀況,便于采取相應的措施,及時解決火情[3]。
近年來,不少學者從不同的角度研究了視頻煙火的檢測問題。文獻[4] 根據人眼視覺注意機制,提出基于顯著性檢測和高斯混合模型的視頻煙霧分割方法,提高了檢測精度和速度。該算法過于依賴手工提取特征,算法魯棒性較差,難以應用于復雜的煙火檢測場景。文獻[5] 針對視頻火災檢測算法泛化能力弱等問題,提出了一種基于ViBe和機器學習的算法,該算法依靠ViBe算法以及隨機森林和支持向量機組成的兩級分類器,對前景信息進行選擇性提取,再結合Hu矩陣訓練出決策分類器,提升檢測穩定性。由于隨機森林和支持向量機等算法對特征提取的能力較弱,該算法存在分類效果較差,誤報率較高的問題。文獻[6]利用YCrCb顏色空間對捕獲的圖像進行分割,使用基于分群體融合的改進FOA算法搜索SVM最優參數和懲罰因子,提升了對火災圖像的分類效果。該算法以參數量較大的元啟發式算法(MetaHeuristic Algorigthm)為基礎,在檢測速度上不能滿足對視頻實時檢測的需求。上述方法主要依靠人工提取特征,算法的泛化能力不強,檢測精度和速度都難以滿足實時穩定檢測的需求。
隨著深度學習的發展,使用卷積神經網絡(CNN)取代人工提取特征成為趨勢,眾多學者展開了將CNN應用到煙火檢測中的研究。文獻[7]通過CNN對火災圖像進行自動特征提取和分類,大幅提升了對煙火圖像分類的精度和速度,但該算法沒有深入應用到檢測任務中。文獻[8]提出了一種改進YOLOv3的火災檢測方法,通過改進特征提取網絡和多尺度檢測網絡,提高了檢測效果,但該算法模型尺寸較大,計算成本較高。文獻[9]將SSD算法與輕量化模型MobileNet結合,對實時火災圖像進行檢測,提升了算法的檢測速度,降低了模型復雜度,但在檢測精度上存在一定不足。上述深度學習方法在一定程度上提升了算法的檢測性能,但是并沒有完全平衡高檢測精度、實時檢測和小模型尺寸對算法的要求。
針對上述模型復雜度較高,檢測速度與檢測精度難以兼顧的問題,本文提出了一種基于改進SSD[10] 的視頻煙火檢測算法(GSSD)。首先,使用GhostNet[11] 輕量化網絡模型替換SSD算法中的VGG16[12]網絡模型。相較于VGG16網絡模型,GhostNet網絡模型大幅度減少了模型的參數量,并在PASCAL VOC 2012數據集上具有較高的準確率。使用GhostNet 網絡模型可以提高算法的檢測速度,減少模型的參數量。其次,在SSD算法的特征映射網絡中使用多尺度特征融合技術。通過下采樣和Concat拼接操作,對多尺度的特征圖進行融合,以提升模型對小目標物體的檢測能力。通過以上改進得到了GSSD算法,該算法有效改善了原始SSD算法檢測精度不高、檢測速度慢和模型參數量大的問題。在PASCAL VOC 2012數據集和自制的煙火數據集上對GSSD算法進行實驗。結果表明,該算法具有更高的檢測精度和速度,以及更小的模型復雜度。 ? 1 SSD 算法 SSD算法主要由骨干網絡、特征映射網絡和檢測網絡組成,其算法流程如圖1所示。
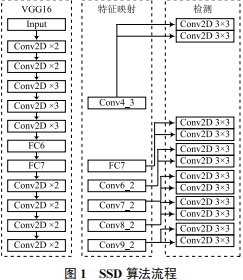
SSD算法使用改進的VGG16 網絡模型作為骨干網絡[13]。考慮到全連接層會干擾模型對特征位置信息的提取,將VGG16網絡中的兩個全連接層FC6和FC7替換為3×3卷積1×1卷積。為進一步提取特征,在FC7層后添加4組卷積層:Conv6、Conv7、Conv8和 Conv9,每組卷積層首先使用1×1卷積核進行下采樣,然后使用3×3卷積核進行特征提取。
特征映射網絡選取若干尺寸不一的特征圖,為檢測提供更多的特征信息。SSD 算法選用6個卷積得到的特征圖為:Conv4_3、FC7、Conv6_2、Conv7_2、Conv8_2、Conv9_2。
在檢測網絡中,使用2個大小為3×3的卷積核對特征提取網絡的6張特征圖進行卷積運算,其中一個卷積核輸出類別置信度,另一個為回歸提供對象位置信息。所有運算結果被合并后,轉移給損失計算函數,然后迭代訓練直到模型收斂。
由于SSD算法采用改進的VGG16網絡模型作為骨干網絡,其僅僅依靠多層卷積進行特征提取,網絡結構較為單一,網絡模型中含有較多冗余計算。針對SSD算法的不足,本文通過相對應的改進提出了對視頻煙火檢測效果更優的GSSD算法。
2 GSSD
2.1 骨干網絡改進
GhostNet是一種通過少量計算表征更多特征的輕量化卷積神經網絡。相較于MobileNet 系列[14-16]和ShuffleNet系列[17-18]等輕量級網絡模型,GhostNet具有更高的準確率 [19]。各輕量化模型在PASCAL VOC 2012數據集上的比較結果見表1所列。由表1可知,GhostNet雖然具有較大的模型參數量,但準確率得到了大幅度提升,可以認為GhostNet相比其他輕量化模型具有一定優勢。

GhostNet的核心思想是使用一系列線性運算代替部分卷積,減少推理計算量。這種結合卷積運算和線性運算的模塊叫做GhostNet module,其結構如圖2所示。
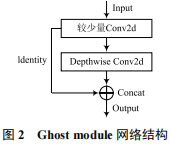
GhostNet module將傳統的卷積分為三步。首先使用較少的卷積核生成第一部分特征圖;其次對該部分特征圖采用深度卷積(Depthwise Convolution)運算得到第二部分特征圖;最后將兩組特征圖通過Concat方式拼接,得到GhostNetmodule的運算結果。
為對比GhostNet module和VGG16中普通卷積的運算成本,分別計算所需的浮點計算量和運算時的參數量。當輸入特征圖的尺寸為H×W×Cin,輸出特征圖的尺寸為H×W×Cout,普通卷積核大小為k×k,通道卷積核大小為k*×k*,Ghost module中標準卷積數為Cout/n時, 使 用VGG16普通卷積的浮點計算量為 :
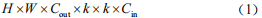
Ghost module的浮點計算量為 :
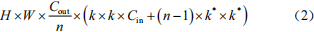
VGG16普通卷積的參數量為 :

Ghost module的參數量為 :
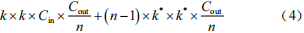
由公式(1)~公式(4)可以看出,相較于標準卷積運算,Ghost module壓縮了大約n 倍的浮點計算量和參數量。
通過對Ghost module的堆疊,可以得到GhostNet的兩種殘差結構(Ghost BottleNeck),如圖3所示。stride=1的Ghost BottleNeck(G1-bneck) 串聯2個Ghost module用于特征提取 ;stride=2的Ghost BottleNeck(G2-bneck)在2個Ghost module之間添加了步長為2的深度卷積,使G2-bneck可以用于下采樣。
2.2 多尺度特征融合
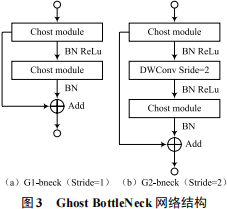
深層卷積層中的小目標經過多次卷積和池化操作后,容易丟失大量的特征信息 ;在淺層卷積層中存在目標特征提取不足,冗余信息過多以至于干擾檢測效果等問題。本文通過將淺層特征與深層特征進行多尺度融合的方式來改善。綜合考慮檢測精度與模型計算量,對算法進行改進,如圖4所示。
多尺度特征融合分為三步。首先對Conv5_1層的特征圖做卷積運算,將通道數擴張到112個;其次將Conv5_6層特征圖上采樣到19×19,并將特征通道數由160個降為112個 ;最后將Conv5_1 層、Conv5_5層和Conv5_6層的特征圖做Concat拼接,拼接后特征圖的通道數為336個。
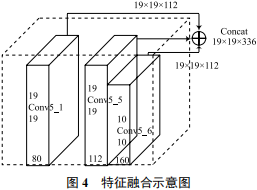
Conv5_1層位于網絡較淺層,特征圖通道數較少,擁有較多的特征信息,在與Conv5_5融合前需要對其做進一步的特征提取。為加強對Conv5_1層特征圖的信息提取,采用步長為1,膨脹率為2,卷積核為3的空洞卷積[20]進行運算。空洞卷積是一種在不做pooling 損失信息的前提下,可以擴大卷積時的感受野,提高特征提取能力的卷積運算,其示意如圖5所示。
空洞卷積的輸入與輸出特征圖的大小關系為 :
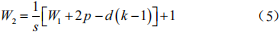
式中:p為填充像素的大小;d為膨脹率;s為步長;k為卷積核大小;W1為輸出特征圖的尺寸;W2為輸入特征圖的尺寸。
Conv5_6層位于網絡較深層,特征圖尺寸較小,在與Conv5_5融合前需要通過上采樣增大特征圖的尺寸。對Conv5_6層特征圖的上采樣操作選用雙線性插值法。相較于轉置卷積,雙線性插值法不需要訓練新參數,運行速度更快且操作簡單,更適用于對檢測速度和模型計算量有較高要求的視頻煙火檢測。
2.3 GSSD 網絡
通過對SSD算法的骨干網絡以及特征融合模塊的改進得到GSSD算法,該算法網絡結構見表2所列。

在模型訓練過程中, 將Conv5_1層、Conv5_5層、Conv5_6層的輸出進行特征融合,作為第一張特征圖,再選取Conv6、Conv7_2、Conv8_2、Conv9_2、Conv10_2特征圖。使用2個大小為3×3的卷積核對檢測網絡中的每個特征圖進行卷積運算,分別得到類別置信度和回歸信息。最后將計算結果合并傳遞給損失計算函數。
3 實驗及結果分析
3.1 數據集
本文使用的數據集為PASCAL VOC 2012公共數據集和自制的煙火數據集。PASCAL VOC 2012數據集包含20個類別,5717張用以訓練的圖片,5823張用以驗證的圖片。自制的煙火數據集包含 fire 和 smoke 兩個類別,8199張圖片,按照7∶2∶1的比例分配為訓練集、驗證集和測試集。由于自制的煙火數據集圖片數量有限,為了讓模型更好地學習目標特征和提高魯棒性,需要對數據做數據增強。本文對圖像進行 90°、180°、270°旋轉和水平翻轉,如圖6所示。

3.2 評價指標
本文將通過訓練后模型檢測的平均精度(mean AveragePrecision,mAP)、模型參數量(Params)和模型推理速度(FPS)做對比,其中mAP由式(6)~式(9)計算 :
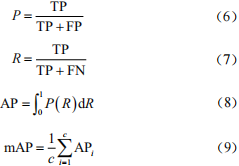
式中:TP為真正例;FP為假正例;FN為負正例;c為種類數。
3.3 對比試驗
為驗證GSSD算法的檢測性能,將GSSD算法與目標檢測效果良好的SSD、YOLOv2[21]、YOLOv3[22]模型分別在PASCAL VOC 2012數據集與煙火數據集上進行實驗對比,4種算法的性能測試結果見表3所列。
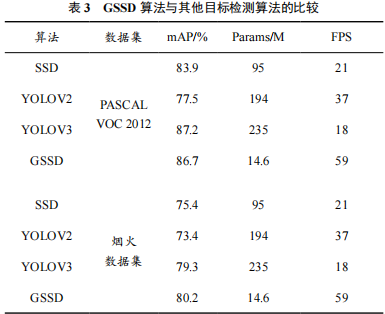
在PASCAL VOC 2012數據集上, 相 比SSD算 法,GSSD算法的檢測效果有較大幅度提升,mAP提高了2.8%,Params減少了84.64%,FPS 提升了1.9倍。GSSD算法在SSD的基礎上進行相應改進和拓展,提高目標檢測的效果,顯著降低了模型參數量,提升了檢測速度。
與YOLO系列算法相比,GSSD比YOLOv2的mAP提高了19.2%,Params減少了92.5%,FPS 提升了59%。YOLOv2算法的網絡結構較為簡單,僅依靠卷積層和池化層對特征進行提取,檢測精度較低。GSSD算法比YOLOv3的mAP降低了0.5%,Params減少了93.8%,FPS 提升了70%。YOLOv3算法使用融入殘差結構的Darknet-53作為骨干網絡,雖然具有比 GSSD 高的檢測精度,但模型參數量較大,檢測速度不能滿足視頻檢測的需求。
在煙火數據集上,GSSD算法的mAP比SSD、YOLOv2和YOLOv3分別提高了4.8%、6.8% 和0.9%。在4種算法中,GSSD對煙火的檢測精度最高,在檢測速度和模型的參數量方面具有較大優勢,實驗證明了GSSD算法在煙火檢測中的可行性。GSSD與SSD算法對煙火數據集可視化檢測對比如圖7所示。

4 結 語
本文針對視頻煙火難以高精度實時檢測和模型參數量較大的問題,提出了GSSD算法。GSSD算法主要對SSD進行了骨干網絡改進和多尺度特征融合改進。通過以上改進,GSSD 算法對視頻煙火檢測的性能得到了提高。
在PASCAL VOC 2012數據集上GSSD算法達到了86.7%的mAP,參數量為14.6 M,FPS為 59。與主流目標檢測算法相比,GSSD算法具有更好的檢測效果,在縮小模型尺寸的同時,檢測精度與速度也有良好的表現。在自行設計的煙火數據集上,GSSD算法比SSD 算法的mAP提高了 4.8%,達到80.2%,參數量減少了84.64%,降為14.6 M,檢測速度提升了1.9 倍,FPS達到了59。下一步將在網絡模型改進的基礎上,針對類火類煙目標的檢測進行研究,以提高算法的魯棒性。
參考文獻
[1] 李國輝,郭歌,趙力增 . 不同起火原因火災時空聚集性研究 [J].消防科學與技術,2019,38(1):141-145.
[2] 張思祥,甘凱,周圍 . 提高火災煙霧傳感器檢測精度的方法 [J].傳感器與微系統,2021,40(1):151-153.
[3] 胡燕,王慧琴,張國飛,等 . 基于視頻圖像的遠程火災探測系統[J]. 計算機工程,2013,39(3):279-284.
[4] 賈陽,林高華,王進軍,等 . 基于顯著性檢測和高斯混合模型的早期視頻煙霧分割算法 [J]. 計算機工程,2016,42(2):206-209.
[5] 梅建軍,張為 . 基于 ViBe 與機器學習的早期火災檢測算法 [J]. 光學學報,2018,38(7):60-67.
[6] 苗續芝,陳偉,畢方明,等 . 基于改進 FOA-SVM 的礦井火災圖像識別 [J]. 計算機工程,2019,45(4):267-274.
[7] LI P,ZHAO W. Image fire detection algorithms based onconvolutional neural networks [J]. Case studies in thermalengineering,2020,19:100625.
[8] QIN Y Y,CAO J T,JI X F. Fire Detection method based ondepthwise separable convolution and YOLOv3 [J]. Internationaljournal of automation and computing,2021,18(2):300-310.
[9] Nguyen A Q,Nguyen H T,Tran V C,et al. A Visual Real-timeFire Detection using Single Shot MultiBox Detector for UAV-basedFire Surveillance [C]// 2020 IEEE Eighth International Conference onCommunications and Electronics (ICCE). IEEE,2021: 338-343.
[10] 楊帆,吳韶波 . 基于 SSD 的目標車輛檢測算法研究 [J]. 物聯網技術,2021,11(6):19-22.
[11] Han K,Wang Y,Tian Q,et al. Ghostnet: More features fromcheap operations [C]// Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition. 2020:1580-1589.
[12] SIMONYAN K,ZISSERMAN A. Very deep convolutionalnetworks for large-scale image recognition [Z]. arXiv preprint arXiv:1409.1556,2014.
[13] 張海濤,張夢 . 引入通道注意力機制的 SSD 目標檢測算法 [J].計算機工程,2020,46(8):264-270.
[14] HOWARD A G,ZHU M,CHEN B,et al. Mobilenets:Efficientconvolutional neural networks for mobile vision applications [Z].arXiv preprint arXiv:1704.04861,2017.
[15] 趙洋,許軍 . 基于 MobileNetV2 與樹莓派的人臉識別系統 [J]. 計算機系統應用,2021,30(8):67-72.
[16] H o w a r d A,Sandler M,Chu G,e t a l . S e a r c h i n g f o rmobilenetv3[C]// Proceedings of the IEEE/CVF InternationalConference on Computer Vision. 2019: 1314-1324.
[17] Zhang X,Zhou X,Lin M,et al. Shufflenet: An extremelyefficient convolutional neural network for mobile devices [C]//Proceedings of the IEEE conference on computer vision and patternrecognition. 2018: 6848-6856.
[18] Ma N,Zhang X,Zheng H T,et al. Shufflenet v2: Practicalguidelines forefficient cnn architecture design [C]// Proceedings of theEuropean conference on computer vision (ECCV). 2018: 116-131.
[19] 余洪山,郭豐,郭林峰,等 . 融合改進 SuperPoint 網絡的魯棒單目視覺慣性 SLAM[J]. 儀器儀表學報,2021,42(1):116-126.
[20] YU F,KOLTUN V. Multi-scale context aggregation by dilatedconvolutions [Z]. arXiv preprint arXiv:1511.07122,2015.
[21] Redmon J,Farhadi A. YOLO9000: better,faster,stronger [C]//Proceedings of the IEEE conference on computer vision and patternrecognition. 2017: 7263-7271.
[22] Redmon J,Farhadi A. Yolov3: An incremental improvement [Z].arXiv preprint arXiv:1804.02767,2018.
作者簡介:趙 洋(1974—),男,博士,講師,研究方向為圖像處理與計算機視覺。 王藝鋼(1997—),男,碩士,研究方向為圖像處理。 靳永強(1998—),男,碩士,研究方向為圖像處理。 華 丹(1995—),女,碩士,研究方向為圖像處理。
編輯:黃飛
?











 工商網監
工商網監
評論