 電子發(fā)燒友App
電子發(fā)燒友App


李蓉 1,周美麗 2
(1.延安大學(xué)西安創(chuàng)新學(xué)院,陜西 西安 710100;2.延安大學(xué),陜西 延安 716000)
摘要:在語言翻譯方面,人工翻譯的速度比較慢,越來越不能適應(yīng)當(dāng)前社會發(fā)展的快速需求。因此,需要有新技術(shù)代替人工翻譯,以開發(fā) AI 為基礎(chǔ),實現(xiàn)快速、準(zhǔn)確、高效的機器翻譯。針對傳統(tǒng)機器自動翻譯系統(tǒng)在翻譯過程中準(zhǔn)確率較低的問題,為了提高機器自動翻譯的速度和準(zhǔn)確性,該文提出基于人工智能處理器設(shè)計的機器自動翻譯系統(tǒng)設(shè)計。通過客戶端結(jié)構(gòu)設(shè)計和人工智能處理器設(shè)計,完成系統(tǒng)的硬件設(shè)計;依托句子相似度的計算和消除句子歧義,完成系統(tǒng)的軟件設(shè)計,從而實現(xiàn)機器自動翻譯系統(tǒng)的設(shè)計。測試結(jié)果表明,基于人工智能技術(shù)的機器自動翻譯系統(tǒng),相比于基于文本庫的機器自動翻譯系統(tǒng),在句子翻譯速度和準(zhǔn)確率方面都有所提高。
中圖分類號:TN915?34;TP391? ?文獻標(biāo)識碼:A
文章編號:1004?373X(2022)02?0183?04
0 引 言
如今即使手工翻譯可以完整地將原文表達(dá)出來,但是隨著文獻資源的增多,人工翻譯的速度變得越來越慢。機器自動翻譯是加快文本翻譯的重要手段,機器自動翻譯分為基于文本庫和基于翻譯規(guī)則,基于文本庫的機器自動翻譯需要大量的文本資源來構(gòu)建文本信息資源庫,而且文本資源在組成資源庫時經(jīng)常出現(xiàn)文本數(shù)據(jù)密集和稀疏的問題,在翻譯少見詞匯時缺乏精準(zhǔn)度[1];基于翻譯規(guī)則的機器自動翻譯可以將文本內(nèi)容清楚地描述出來,但是規(guī)則庫的構(gòu)建存在一定難度,翻譯時很難達(dá)到較好的翻譯成果[2]。基于上述兩種翻譯系統(tǒng)存在的問題,本文將人工智能技術(shù)應(yīng)用到機器自動翻譯系統(tǒng)設(shè)計中。機器自動翻譯的主要目的就是消除歧義語句,針對一個詞語,在不用的語境下會被翻譯成不同的意思,因此在人工智能技術(shù)的基礎(chǔ)上,讓機器在不同的語境條件下,自動找到該詞語的真正對應(yīng)的意思是機器翻譯亟需解決的關(guān)鍵問題。機器自動翻譯系統(tǒng)的文本翻譯質(zhì)量雖然還沒有達(dá)到人工翻譯的程度,但是如今已經(jīng)在社會上的各個鄰域都得到了廣泛的應(yīng)用[3]。機器自動翻譯系統(tǒng)作為人工翻譯的補充和修正,在一定條件下可以提高翻譯人員的工作效率,并提高了翻譯的準(zhǔn)確度,早已經(jīng)成為翻譯人員的得力助手。現(xiàn)如今,各個民族和國家之間的文化交流比較頻繁,語言上的不通已經(jīng)成為阻礙民族與民族之間、國家與國家之間溝通的障礙[4],為了促進文化知識的溝通和交流,在人工智能技術(shù)的基礎(chǔ)上,設(shè)計機器自動翻譯系統(tǒng)對國家和民族的發(fā)展有著積極作用。
1 大學(xué)人力資源管理系統(tǒng)硬件設(shè)計
1.1 客戶端結(jié)構(gòu)設(shè)計
客戶端結(jié)構(gòu)設(shè)計可以讓用戶通過上傳圖片來獲取翻譯內(nèi)容,省去了用戶打字的時間,提高了翻譯的速度和準(zhǔn)確率。用戶可以選擇通過手機拍照軟件,來捕獲需要翻譯的文字內(nèi)容,以圖片的形式將翻譯內(nèi)容上傳到云端服務(wù)器[5];還可以直接從本機圖庫中選擇提前拍攝好的文字圖片,再將圖片上傳到云端服務(wù)器,并在翻譯系統(tǒng)的設(shè)置選項中,完成攝像頭的對焦和閃光設(shè)置,在用戶需求的情況下,還要設(shè)置需要識別的語言。然后將選擇好的圖片利用HTTP協(xié)議上傳到系統(tǒng)云端服務(wù)器,并由部署在云端服務(wù)器上的OCR軟件,將圖片識別成可以進行編輯的文本內(nèi)容[6]。通過調(diào)用Google翻譯來執(zhí)行翻譯工作,最終將識別出來的源語言文本內(nèi)容翻譯出目標(biāo)語言文本內(nèi)容,并將目標(biāo)語言文本內(nèi)容返回給客戶端。用戶可以對客戶端接收的源語言文本內(nèi)容以及目標(biāo)語言文本內(nèi)容進行相應(yīng)的編輯操作,或者對文本內(nèi)容中感興趣的部分在互聯(lián)網(wǎng)上搜索[7]。客戶端工作流程示意圖如圖1所示。
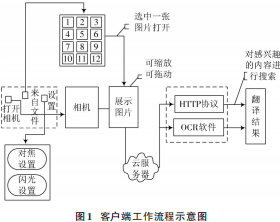
結(jié)合客戶端的需求分析和工作流程,可以將客戶端的功能分為圖片保存、拍照、圖片編輯、在線搜索、設(shè)置語言類型、翻譯文本保存等。客戶端的功能結(jié)構(gòu)見圖2。
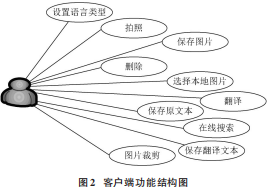
以縮短用戶獲取目標(biāo)翻譯本文的時間、提高翻譯準(zhǔn)確性為目的,對采集到的文本內(nèi)容進行簡單處理,并向服務(wù)器發(fā)送翻譯請求,將采集到的圖片信息傳輸給服務(wù)器,完成客戶端的結(jié)構(gòu)設(shè)計。
1.2 人工智能處理器設(shè)計
在服務(wù)端的所有組件中,人工智能處理屬于計算密集型的處理器,也是整個系統(tǒng)應(yīng)用性能的瓶頸。因此,需要多臺人工智能處理器并行處理用戶的服務(wù)請求,人工智能處理器的數(shù)量是根據(jù)用戶請求的數(shù)量確定的,處理器數(shù)量越多,翻譯的速度就越快。人工智能技術(shù)作用于包含待識別文本信息的數(shù)字圖像,預(yù)處理數(shù)字圖像后,利用文本信息的定位、分割和提取算法,將待識別的文本信息提取出來[8],通過模式識別算法完成提取文本信息形態(tài)特征的分析,最后得到目標(biāo)文本信息的標(biāo)準(zhǔn)編碼,將結(jié)果輸出[9]。人工智能處理流程如圖 3所示。
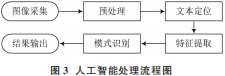
人工智能處理器的功能實現(xiàn)是基于Tesseract?OCR2.3,它是一個在實驗室內(nèi)開發(fā)的人工智能引擎,谷歌對Tesseract?OCR2.3進行了優(yōu)化,使得它已經(jīng)成為人工智能領(lǐng)域中精度最高的開源引擎,可以支持中文,使用命令行方式調(diào)用[10]。人工智能處理器的結(jié)構(gòu)如圖4所示。
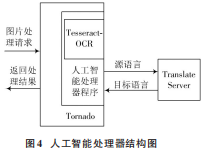
基于用戶需求分析,設(shè)計客戶端的工作流程,結(jié)合客戶端的需求分析,完成客戶端的結(jié)構(gòu)設(shè)計;利用人工智能技術(shù)確定人工智能處理流程,通過人工智能處理的實現(xiàn),完成人工智能處理器的結(jié)構(gòu)設(shè)計,從而實現(xiàn)系統(tǒng)的硬件設(shè)計。
2 大學(xué)人力資源管理系統(tǒng)軟件設(shè)計
2.1 計算句子相似度
句子相似度算法先根據(jù)詞性特性對相似的句子進行粗選,然后進一步精細(xì)選擇,再計算句子的相似度。該方法雖然考慮句子中每一個詞的詞頻特征,也對詞語賦予了不同的權(quán)值,但是缺乏詞語黏著性,造成長句子或者詞頻低的句子相似度的計算偏差大[11],反而降低了系統(tǒng)的翻譯速度。計算句子相似度時先利用倒排索引文件獲取句子的編號,利用編號得到將要計算的句子內(nèi)容[12]。相似度計算流程如圖5所示。
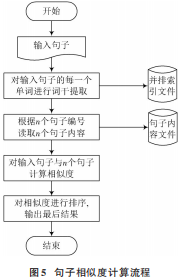
根據(jù)句子相似度計算流程,將已經(jīng)選擇好的n個句子相似度計算結(jié)果上傳到相似句子組合模塊中[13],句子相似度計算公式為:
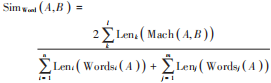
式中:Words(A)表示輸入句子A的單詞集合;Wordsi(A)表示單詞集合中的第i個元素;Len ( )表示字符串長度;Sim Word(A,B)表示詞形相似度。詞形相似度計算可以提高句子翻譯的質(zhì)量。
2.2 消除句子歧義
句子歧義的消除可以提高機器自動翻譯的準(zhǔn)確性,實現(xiàn)機器自動翻譯。一方面是由詞性引起的歧義,同一個單詞可能會具有不同的詞性,也使得翻譯出來的意思不同[14];另一方面是由于同一個單詞在不同的語境中,翻譯出來的意思也是不同的。針對消除由詞性引起的句子歧義,先分清單詞的詞性,本文利用上文計算的相似度對單詞進行詞性標(biāo)注,根據(jù)標(biāo)注后的詞性確定該單詞在句子中的實際含義,消除了歧義,完成整句翻譯[15]。針對語境不同引起的句子歧義,需要利用本體來消除歧義,首先遍歷所要翻譯的句子,將每一個單詞在領(lǐng)域詞典中查找,如果可以在詞典中查找到,就可以認(rèn)為該詞在特殊詞義領(lǐng)域內(nèi),可以賦予其特定的含義,這樣就完成了歧義消除,實現(xiàn)機器自動翻譯。綜上所述,依托客戶端的結(jié)構(gòu)設(shè)計和人工智能處理器設(shè)計,完成了系統(tǒng)的硬件設(shè)計;基于句子相似度的計算和歧義的消除,完成了系統(tǒng)的軟件設(shè)計,從而實現(xiàn)了機器自動翻譯系統(tǒng)的設(shè)計。
3 仿真測試 3.1 測試方法及步驟分析 ? 為了驗證基于人工智能技術(shù)的機器自動翻譯系統(tǒng)的有效性,本文對常見的英文句型進行了測試。系統(tǒng)在測試時從句子資源庫中隨機抽取了50個句子進行翻譯測試。測試的步驟如下:
1)選擇待翻譯句子,如:Foxen is a famous winery.
2)標(biāo)注每一個單詞的詞性并將詞型還原,分清句子中每一個單詞的具體類型以及單詞的原型,如表1所示。

3)消除歧義。在本體詞典中,F(xiàn)oxen 和 winery 都會出現(xiàn),而單詞 Foxen是單詞 winery的一個個體,因此完全可以認(rèn)為兩個單詞都存在于詞語資源庫中。
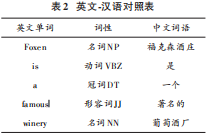
4)得到對應(yīng)的漢語詞匯,如表2所示。
5)句法分析。利用人工智能技術(shù)構(gòu)建語法樹,如圖6所示。
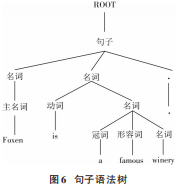
6)選擇句子翻譯模板。通過分析句子語法樹得出,待翻譯句子是由“名詞+動詞+名詞”組成,而在動詞方面選擇的是系動詞,構(gòu)成了“主系表”結(jié)構(gòu),語序與英文一致,因此可以直接翻譯。
7)得出翻譯結(jié)果。
3.2 實驗結(jié)果分析
利用上述的實驗方法和步驟,得到下列實驗結(jié)果,如圖7所示。
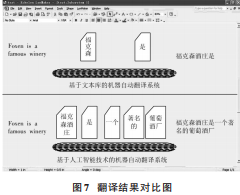
從實驗結(jié)果中可以得出,相同時間內(nèi),基于文本庫的機器自動翻譯系統(tǒng)在翻譯句子時,只能翻譯出兩個英語單詞,且在翻譯準(zhǔn)確率方面,也會出現(xiàn)翻譯不完全的現(xiàn)象;而基于人工智能技術(shù)的機器自動翻譯系統(tǒng)在翻譯句子時,可以將整個句子完整地翻譯出來,不會丟下任何一個簡單或復(fù)雜的單詞,且在翻譯準(zhǔn)確率方面,可以將整個句子準(zhǔn)確地翻譯出來。因此可以得出基于人工智能技術(shù)的機器自動翻譯系統(tǒng),相比于基于文本庫的機器自動翻譯系統(tǒng)具有較快的翻譯速度和較高的準(zhǔn)確度。
4 結(jié) 語
本文提出基于人工智能技術(shù)的機器自動翻譯系統(tǒng)設(shè)計。依托機器自動翻譯系統(tǒng)的硬件設(shè)計和軟件設(shè)計,實現(xiàn)了本文的研究。結(jié)果表明,基于人工智能技術(shù)的機器自動翻譯系統(tǒng),相比于基于文本庫的機器自動翻譯系統(tǒng)在句子翻譯速度和準(zhǔn)確率方面都有所提高。希望本文的研究可以為基于人工智能技術(shù)的機器自動翻譯系統(tǒng)設(shè)計提供理論依據(jù)。
參 考 文 獻
[1] 羅華珍,潘正芹,易永忠 . 人工智能翻譯的發(fā)展現(xiàn)狀與前景分析[J].電子世界,2017(21):21?23.
[2] 邢蕾 .英漢機器翻譯中譯文自動生成系統(tǒng)設(shè)計[J].現(xiàn)代電子技術(shù),2018,41(24):86?89.
[3] 張睿 .基于短語相似度的統(tǒng)計機器翻譯系統(tǒng)設(shè)計[J].自動化與儀器儀表,2017(8):66?67.
[4] 鄭錦龍,林國銘,孫永 . 穿戴式手語識別翻譯系統(tǒng)[J]. 通訊世界,2017(7):238?239.
[5] 張勝剛,艾山·吾買爾,吐爾根·依布拉音,等 .基于神經(jīng)網(wǎng)絡(luò)的維漢翻譯系統(tǒng)實現(xiàn)[J].現(xiàn)代電子技術(shù),2018,41(24):157?161.
[6] 劉洋 .神經(jīng)機器翻譯前沿進展[J].計算機研究與發(fā)展,2017,54(6):1144?1149.
[7] 艷萍 . 淺談氣象服務(wù)產(chǎn)品漢蒙自動翻譯系統(tǒng)[J]. 文存閱刊,2018(4):191.
[8] 梁亞敏,梁利利 .基于智能手機的英語輔助翻譯學(xué)習(xí)系統(tǒng)構(gòu)建[J].自動化與儀器儀表,2018(8):142?144.
[9] 黃政豪,崔榮一 .基于術(shù)語自動抽取的科技文獻翻譯輔助系統(tǒng)的設(shè)計[J].延邊大學(xué)學(xué)報(自然科學(xué)版),2017,43(3):259?263.
[10] 徐英卓,賈歡 .基于樹結(jié)構(gòu)的本體概念相似度計算方法[J].計算機系統(tǒng)應(yīng)用,2017,26(3):275?279.
[11] 李峰,侯加英,曾榮仁,等 . 融合詞向量的多特征句子相似度計算方法研究[J].計算機科學(xué)與探索,2017,11(4):608?618.
[12] 彭琦,朱新華,陳意山,等 . 基于信息內(nèi)容的詞林詞語相似度計算[J].計算機應(yīng)用研究,2018,35(2):400?404.
[13] 熊明明,李英,郭劍毅,等 .基于 CRFs和歧義模型的越南語分詞[J].數(shù)據(jù)采集與處理,2017,32(3):636?642.
[14] 熊明明,劉艷超,郭劍毅,等 . 基于最大熵模型的越南語交叉歧義消解[J].中文信息學(xué)報,2017,31(4):63?69.
[15] 余倩 . 基于特征提取算法的交互式英漢翻譯系統(tǒng)設(shè)計[J]. 現(xiàn)代電子技術(shù),2018,41(4):161?163.
作者簡介: 李??蓉(1983—),女,陜西西安人,碩士,講師,主要研究方向為計算機應(yīng)用、翻譯系統(tǒng)設(shè)計。 周美麗(1981—),女,陜西橫山人,碩士研究生,副教授,主要從事信號檢測、圖像處理等方面的研究工作。
編輯:黃飛
?








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論