 電子發燒友App
電子發燒友App


半個月以來,ChatGPT 這把火越燒越旺。國內很多大廠相繼聲稱要做中文版 ChatGPT,還公布了上線時間表,不少科技圈已功成名就的大佬也按捺不住,攜巨資下場,要創建 “中國版 OpenAI“。
不過,看看過去半個月在群眾眼里稍顯窘迫的 Meta 的 Galactica,以及 Google 緊急發布的 Bard,就知道在短期內打造一個比肩甚至超越 ChatGPT 效果的模型沒那么簡單。
讓很多人不免感到詫異的是,ChatGPT 的核心算法 Transformer 最初是由 Google 提出的,并且在大模型技術上的積累可以說不弱于 OpenAI,當然他們也不缺算力和數據,但為什么依然會被 ChatGPT 打的措手不及?
Meta 首席 AI 科學家 Yann LeCun 最近抨擊 ChatGPT 的名言實際上解釋了背后的門道。他說,ChatGPT “只是巧妙的組合而已”,這句話恰恰道出了一種無形的技術壁壘。
簡單來說,即使其他團隊的算法、數據、算力都準備的與 OpenAI 相差無幾,但就是沒想到以一種精巧的方式把這些元素組裝起來,沒有 OpenAI,全行業不知道還需要去趟多少坑。
即使 OpenAI 給出了算法上的一條路徑,后來者想復現 ChatGPT,算力、工程、數據,每一個要素都需要非常深的積累。七龍珠之中,算力是自由流通的商品,花錢可以買到,工程上有 OneFlow 這樣的開源項目和團隊,因此,對互聯網大廠之外的團隊來說,剩下最大的挑戰在于高質量訓練數據集。
至今,OpenAI 并沒有公開訓練 ChatGPT 的相關數據集來源和具體細節,一定程度上也暫時卡了追趕者的脖子,更何況,業界公認中文互聯網數據質量堪憂。
好在,互聯網上總有熱心的牛人分析技術的細枝末節,從雜亂的資料中串聯起蛛絲馬跡,從而歸納出非常有價值的信息。
此前,發布的《ChatGPT 背后的經濟賬》,其作者從經濟學視角推導了訓練大型語言模型的成本。本文作者則整理分析了 2018 年到 2022 年初從 GPT-1 到 Gopher 的相關大型語言模型的所有數據集相關信息,希望幫助有志于開發 “類 ChatGPT” 模型的團隊少走一步彎路。
作者|Alan D. Thompson
翻譯|楊婷、徐佳渝、賈川
一些研究人員的報告稱,通用人工智能(AGI)可能是從我們當前的語言模型技術進行演進 [1],預訓練 Transformer 語言模型為 AGI 的發展鋪平了道路。雖然模型訓練數據集日漸增大,但缺乏基本指標文檔,包括數據集大小、數據集 token 數量和具體的內容細節。
盡管業內提出了數據集組成和整理文檔的標準 [2],但幾乎所有重點研究實驗室在揭示模型訓練數據集細節這方面都做得不夠。這里整合的研究涵蓋了 2018 年到 2022 年初從 GPT-1 到 Gopher 的精選語言模型的所有數據集(包括主要數據集:Wikipedia 和 Common Crawl)的綜合視圖。
1、概述
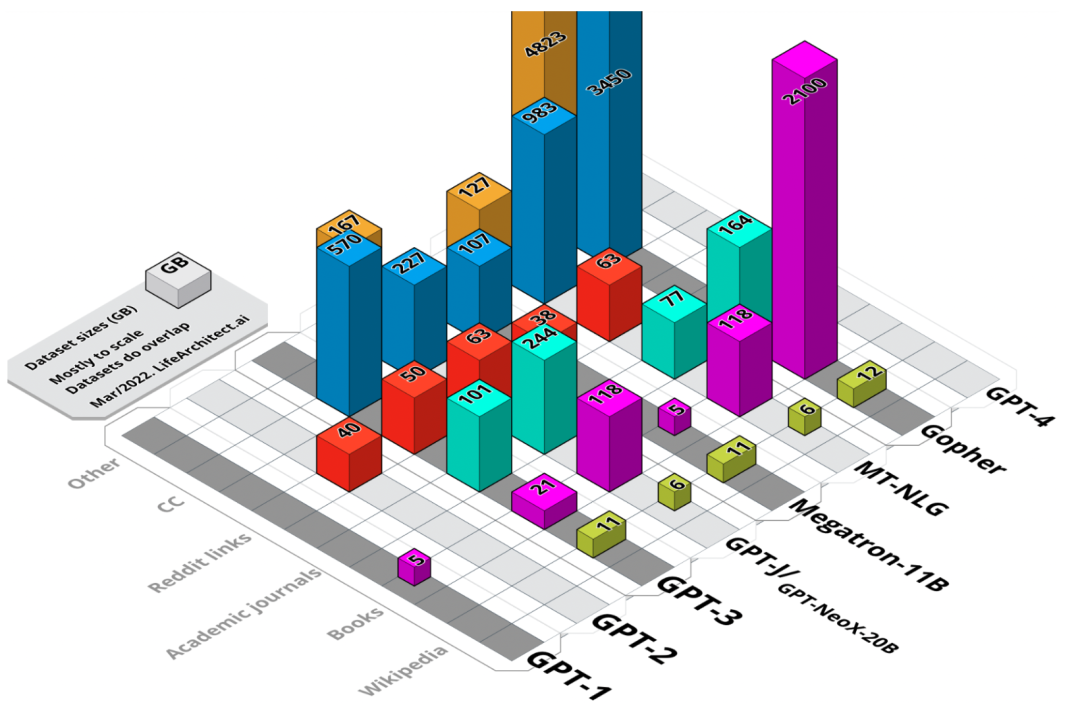
圖 1. 主要數據集大小的可視化匯總。未加權大小,以 GB 為單位。?
2018 年以來,大語言模型的開發和生產使用呈現出爆炸式增長。一些重點研究實驗室報告稱,公眾對大語言模型的使用率達到了驚人高度。2021 年 3 月,OpenAI 宣布 [3] 其 GPT-3 語言模型被 “超過 300 個應用程序使用,平均每天能夠生成 45 億個詞”,也就是說僅單個模型每分鐘就能生成 310 萬詞的新內容。
值得注意的是,這些語言模型甚至還沒有被完全理解,斯坦福大學的研究人員 [4] 最近坦言,“目前我們對這些模型還缺乏認知,還不太了解這些模型的運轉模式、不知道模型何時會失效,更不知道這些模型的突現性(emergent properties)能產生什么效果”。
隨著新型 AI 技術的快速發展,模型訓練數據集的相關文檔質量有所下降。模型內部到底有什么秘密?它們又是如何組建的?本文綜合整理并分析了現代大型語言模型的訓練數據集。
因為這方面的原始文獻并不對外公開,所以本文搜集整合了二、三級研究資料,在必要的時候本文會采用假設的方式來推算最終結果。
在本文中,我們會將原始論文中已經明確的特定細節(例如 token 數量或數據集大小)歸類為 “公開的(disclosed)” 數據,并作加粗處理。
多數情況下,適當地參考二、三級文獻,并采用假設的方式來確定最終結果是很有必要的。在這些情況下,token 數量和數據集大小等細節是 “確定的(determined)”,并以斜體標記。
模型數據集可分為六類,分別是:維基百科、書籍、期刊、Reddit 鏈接、Common Crawl 和其他數據集。
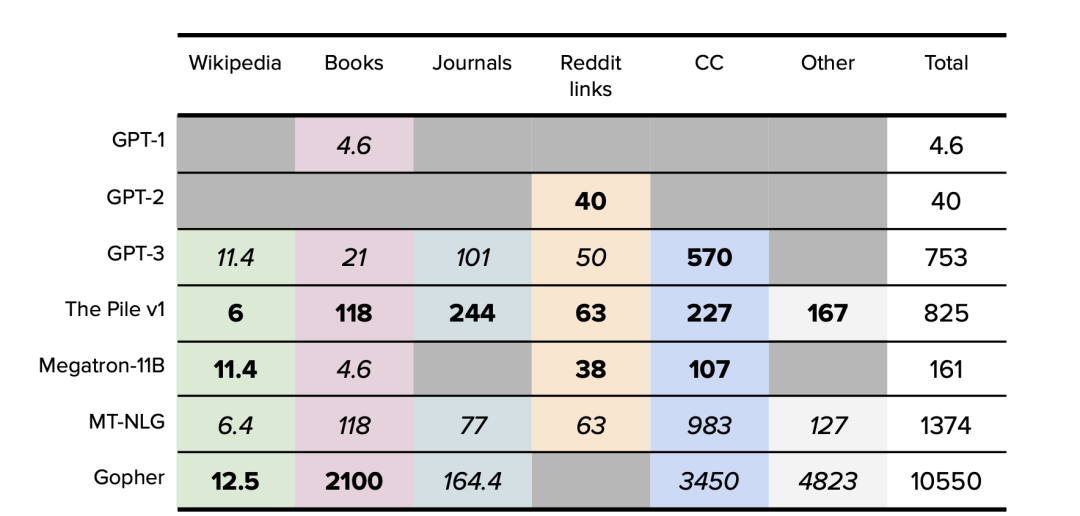
表 1. 主要數據集大小匯總。以 GB 為單位。公開的數據以粗體表示。確定的數據以斜體表示。僅原始訓練數據集大小。
1.1. 維基百科
維基百科是一個免費的多語言協作在線百科全書,由超過 300,000 名志愿者組成的社區編寫和維護。截至 2022 年 4 月,英文版維基百科中有超過 640 萬篇文章,包含超 40 億個詞 [5]。維基百科中的文本很有價值,因為它被嚴格引用,以說明性文字形式寫成,并且跨越多種語言和領域。一般來說,重點研究實驗室會首先選取它的純英文過濾版作為數據集。
1.2.?書籍
故事型書籍由小說和非小說兩大類組成,主要用于訓練模型的故事講述能力和反應能力,數據集包括 Project Gutenberg 和 Smashwords (Toronto BookCorpus/BookCorpus) 等。
1.3.?雜志期刊
預印本和已發表期刊中的論文為數據集提供了堅實而嚴謹的基礎,因為學術寫作通常來說更有條理、理性和細致。這類數據集包括 ArXiv 和美國國家衛生研究院等。
1.4.?Reddit 鏈接
WebText 是一個大型數據集,它的數據是從社交媒體平臺 Reddit 所有出站鏈接網絡中爬取的,每個鏈接至少有三個贊,代表了流行內容的風向標,對輸出優質鏈接和后續文本數據具有指導作用。
1.5.?Common Crawl
Common Crawl 是 2008 年至今的一個網站抓取的大型數據集,數據包含原始網頁、元數據和文本提取,它的文本來自不同語言、不同領域。重點研究實驗室一般會首先選取它的純英文過濾版(C4)作為數據集。
1.6. 其他數據集
不同于上述類別,這類數據集由 GitHub 等代碼數據集、StackExchange 等對話論壇和視頻字幕數據集組成。
2、常用數據集
2019 年以來,大多數基于 Transformer 的大型語言模型 (LLM) 都依賴于英文維基百科和 Common Crawl 的大型數據集。在本節中,我們參考了 Jesse Dodge 和 AllenAI(AI2)[8] 團隊的綜合分析,按類別對英文維基百科作了高級概述,并在 Common Crawl 數據集 [7] 的基礎上,用谷歌 C4 [6] (Colossal Clean Crawled Corpus) 在 Common Crawl 中提供了頂級域(domains)。
2.1. 維基百科(英文版)分析
下面按類別 [9] 列出了維基百科的詳細信息,涵蓋了 2015 年抽樣的 1001 篇隨機文章,研究人員注意到隨時間推移文章傳播的穩定性。假設一個 11.4GB、經過清理和過濾的維基百科英文版有 30 億 token,我們就可以確定類別大小和 token。
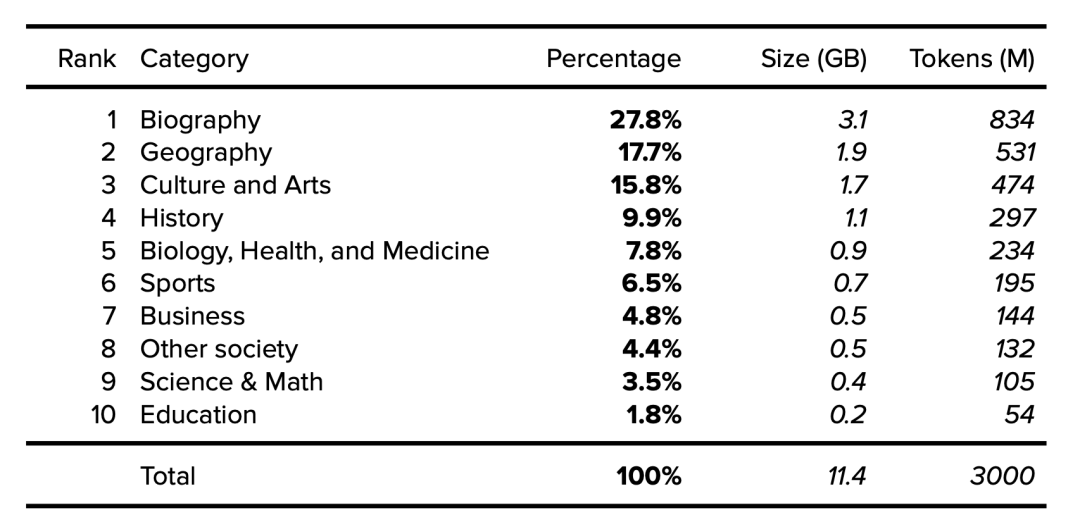
表 2. 英文維基百科數據集類別。公開的數據以粗體表示。確定的數據以斜體表示。
2.2 Common Crawl 分析
基于 AllenAI (AI2) 的 C4 論文,我們可以確定,過濾后的英文 C4 數據集的每個域的 token 數和總體百分比,該數據集為 305GB,其中 token 數為 1560 億。
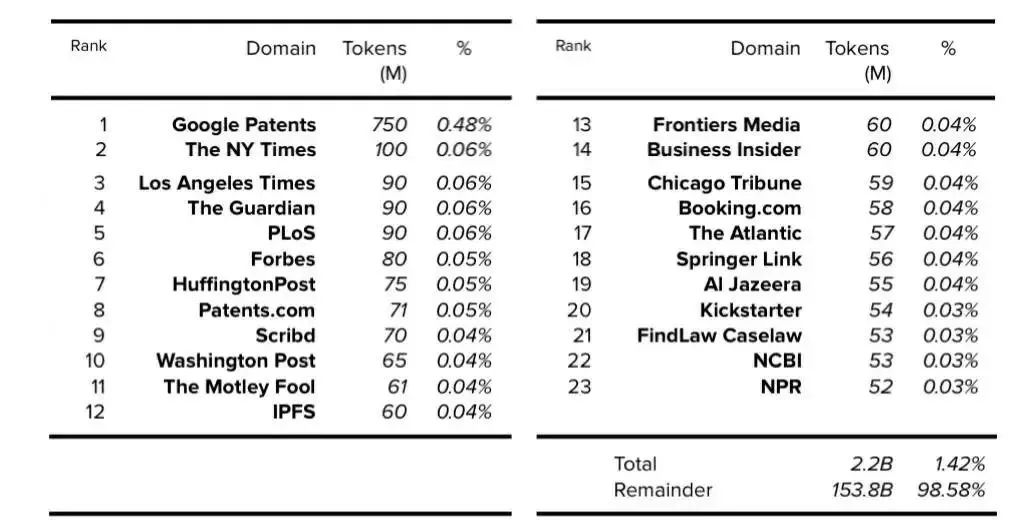
表 3. C4:前 23 個域(不包括維基百科)。公開的數據以粗體表示,確定的數據以斜體表示。
3、GPT-1 數據集
2018 年,OpenAI 發布了 1.17 億參數的 GPT-1。在論文中,OpenAI 并沒有公布模型訓練數據集的來源和內容 [10],另外,論文誤將‘BookCorpus’拼寫成了‘BooksCorpus’。BookCorpus 以作家未出版的免費書籍為基礎,這些書籍來自于 Smashwords,這是一個自稱為 “世界上最大的獨立電子書分銷商” 的電子書網站。這個數據集也被稱為 Toronto BookCorpus。經過幾次重構之后,BookCorpus 數據集的最終大小確定為 4.6GB [11]。
2021 年,經過全面的回顧性分析,BookCorpus 數據集對按流派分組的書籍數量和各類書籍百分比進行了更正 [12]。數據集中有關書籍類型的更多詳細信息如下:
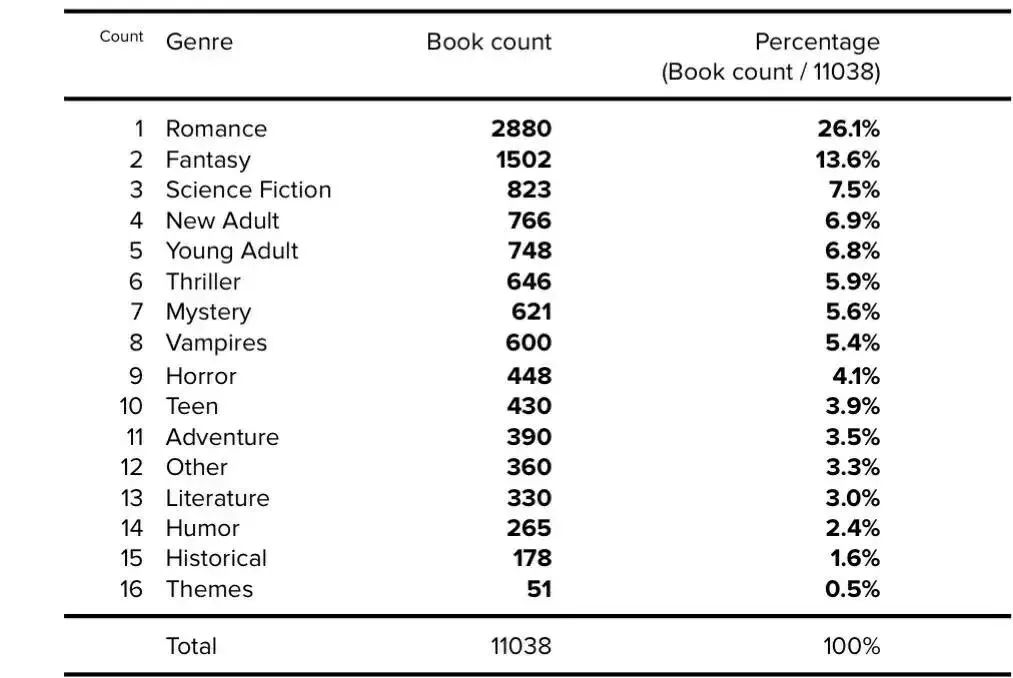
表 4. BookCorpus 書籍類型。公開的數據以粗體表示,確定的數據以斜體表示。
在隨后的數據集重構中,BookCorpus 數據集進一步過濾掉了書籍中的 “吸血鬼” 類別、降低了言情類書籍的百分比、增加了 “歷史” 類書籍,增加了收集的書籍數量。
3.1. GPT-1 數據集總結
GPT-1 最終的數據集總結分析如下:

表 5.GPT-1 數據集總結。以 GB 為單位。公開的數據以粗體表示,確定的數據以斜體表示。
?4、GPT-2 數據集
2019 年,OpenAI 發布了擁有 15 億參數的語言模型 GPT-2。GPT-2 論文闡明了所用訓練數據集的大小 [13],不過并未說明其內容。而 GPT-2 模型卡(model card)(在 GPT-2 GitHub 倉庫中)說明了模型內容 [14]。
我們可以從 GPT-3 論文中得到 token 數量,該論文使用了 WebText 擴展版本來表示 190 億 token。據推測,2020 年推出的 WebText 擴展版本擁有 12 個月的額外數據(additional data),因此它可能比 2019 年推出的 GPT-2 版本大 25% 左右 [15]。GPT-2 最終的 token 數量確定為 150 億左右。
如 GPT-2 論文所述,假設模型卡顯示鏈接數時,每個鏈接都可以被 4500 萬鏈接總數所除,那 WebText 的內容在數據集中所占的百分比的詳細信息就可以確定。
然后可以使用確定的 150 億 token 數量來查找每個域的 token 數量。請注意,在可用的前 1,000 個域中,此處僅顯示前 50 個域。
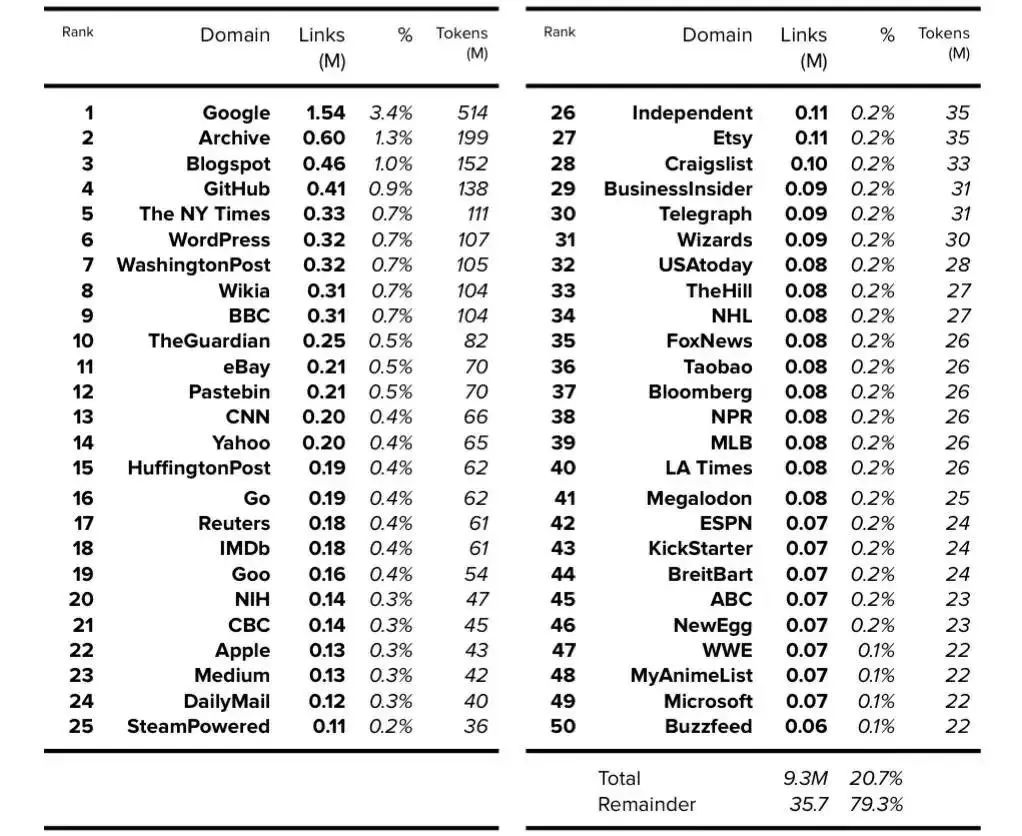
表 6. WebText: 前 50 個域。?公開的數據以粗體表示,確定的數據以斜體表示。
4.1. GPT-2 數據集總結
GPT-2 模型最終的數據集總結分析如下:

表 7. GPT-2 數據集總結。?公開的數據以粗體表示,確定的數據以斜體表示。
5、GPT-3 數據集
GPT-3 模型由 OpenAI 于 2020 年發布。論文闡明了所用訓練數據集的 token 數量 [16],但訓練數據集的內容和大小尚不清楚(Common Crawl 的數據集大小除外 [17])

表 8. GPT-3 數據集。?公開的數據以粗體表示,確定的數據以斜體表示。
5.1. GPT-3:關于 Books1 和 Books2 數據集的分析
特別值得關注的是,在 OpenAI 的 GPT-3 論文中,并未公開 Books1 數據集(120 億 token)和 Books2 數據集(550 億 token)的大小和來源。關于這兩個數據集的來源人們提出了幾個假設,包括來自 LibGen18 和 Sci-Hub 的類似數據集,不過這兩個數據集常以 TB 為計,大到無法匹配。
5.2. GPT-3:Books1
GPT-3 使用的 Books1 數據集不可能與 GPT-1 使用的 BookCorpus 數據集相同,原因在于 Books1 的數據集更大,達 120 億 token。在一篇引用的論文 [19] 中就提及 GPT-1 使用的 BookCorpus 數據集擁有 9.848 億個詞,但這可能只相當于 13 億 token(984.8 字 x 1.3 字的 token 乘數)。
通過標準化項目古騰堡語料庫(SPGC),Books1 有可能與古騰堡項目保持一致性。SPGC 是一種開放式科學方法,被用于古騰堡項目完整的 PG 數據的精選(curated)版本。SPGC 包含 120 億個 token [20],大約為 21GB [21]。
5.3. GPT-3:Books2
Books2(550 億 token)可能與 Bibliotik 保持一致,并由 EleutherA 收集該來源的數據,組成數據集,使其成為 The Pile v1 的一部分。Bibliotik 版本為 100.96GB [22],其確定的 token 數僅為 250 億,低于 Books2 公開的 550 億。然而,使用 SPGC 的‘每字節 token 數’比率(大約為 1:1.75),Bibliotik 的 token 數和大小將更接近于 Books2。
5.4. GPT-3 數據集總結
附錄 A 概述了使用 Wikipedia + CommonCrawl + WebText 數據集的頂級資源列表。GPT-3 模型的最終數據集總結分析如下:

表 9.GPT-3 數據集總結。公開的數據以粗體表示,確定的數據以斜體表示。
?6、The Pile v1(GPT-J 和 GPT-NeoX-20B)數據集
The Pile v1 數據集由 EleutherAI 于 2021 年發布,該數據集已被用于訓練包括 GPT-J、GPT-NeoX-20B 在內的多種模型,并作為包括 MT-NLG 在內的其他模型的部分數據集。The Pile v1 論文闡明了所用訓練數據集的來源和大小。隨著 token 數量的增加,The Pile v1 論文應被用作未來數據集文檔的黃金標準。
有關 token 數量的更多詳情,可以使用本文提供的信息來確定,參見表 1(大小以 GB 為單位)和表 7(token / 每字節)[23]。
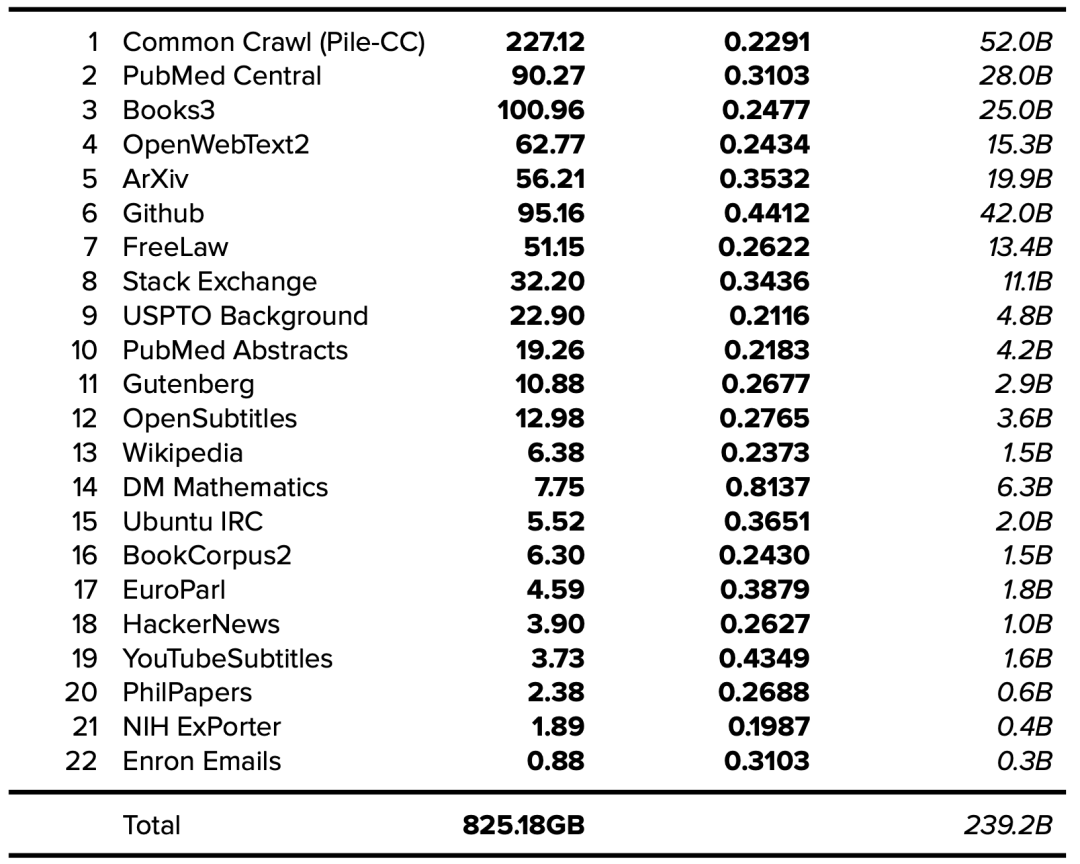
表 10. The Pile v1 數據集。公開的數據以粗體表示,確定的數據以斜體表示。
6.1. The Pile v1 分組數據集(Grouped Datasets)
為了確定如‘Books’、‘Journals’和‘CC’這類數據集的大小,筆者對數據集進行了分組,如下表所示。
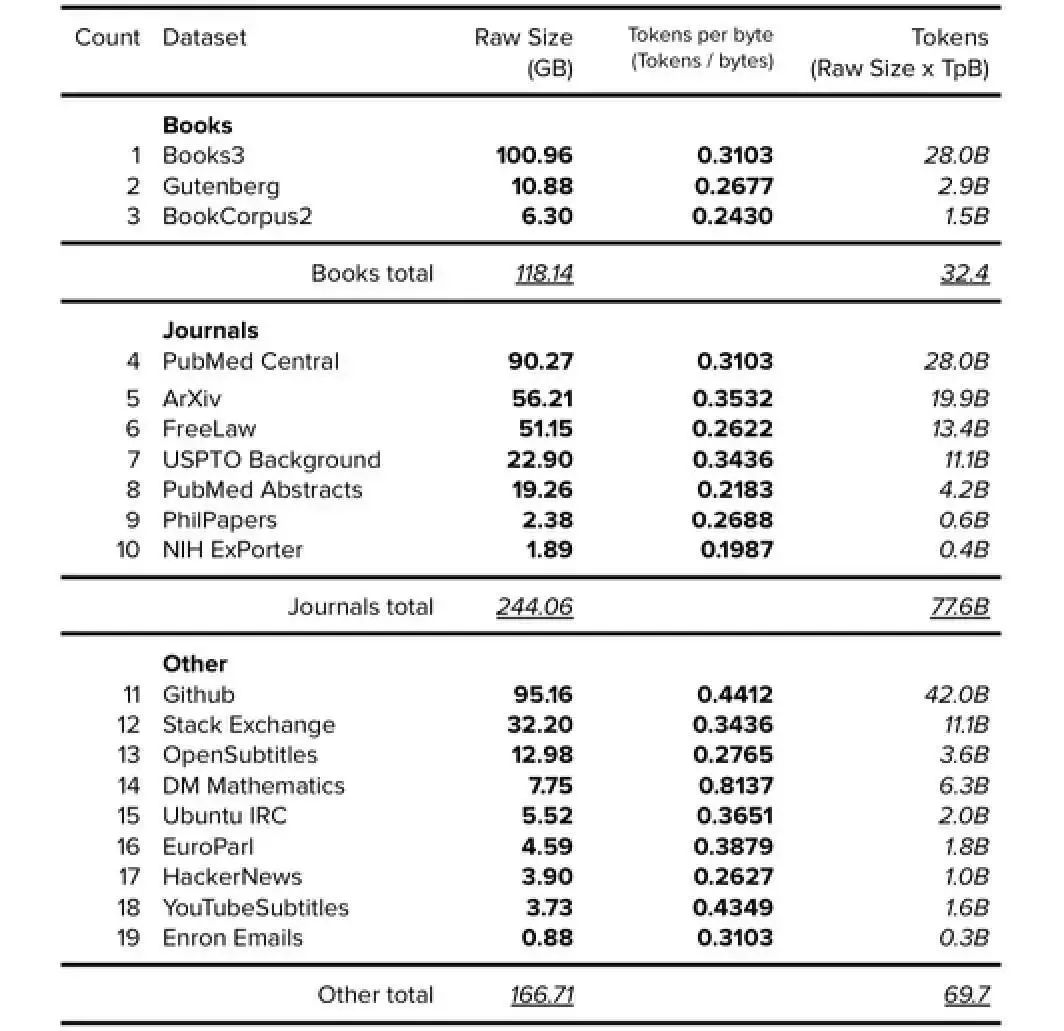
表 11. The Pile v1 分組數據集(不包括 Wikipedia、CC 和 WebText)。公開的數據以粗體表示,確定的以斜體表示。
6.2. The Pile v1 數據集總結
The Pile v1 數據集與 GPT-J 和 GPT-NeoX-20B 模型的最終數據集總結分析如下:

表 12. Pile v1 數據集總結。?公開的數據以粗體表示,確定的數據以斜體表示。
7、Megatron-11B 和 RoBERTa 數據集
2019 年,Meta AI (當時稱之為 Facebook AI) 和華盛頓大學聯合發布了擁有 1.25 億參數的 RoBERTa 模型。次年,Meta AI 發布了擁有 110 億參數的 Megatron-11B 模型。Megatron-11B 使用的訓練數據集與 RoBERTa 相同。RoBERTa [24] 論文闡明了所用訓練數據集的內容,不過必須參考引用的論文 (BERT [25] 和 toryes [26]) 來確定最終的數據集大小。
BookCorpus?:?確定的數據集為 4.6GB,如上面的 GPT-1 部分所示。
維基百科:公開的數據集為 “16GB(BookCorpus 加上英文維基百科)”。在減去 BookCorpus 數據集(4.6GB,如上面的 GPT-1 部分所述)后,維基百科數據集確定為 11.4GB。
CC-News?:(經過濾后)公開的數據集為 76GB。
OpenWebText?:?公開的數據集為 38GB。
Stories?:?公開的數據集為 31GB。請注意,此數據集是 “基于常識推理任務問題” 的 Common Crawl 內容,不屬于本文的‘Books’類別。相反,將 Stories 與 CC-News 數據集(76GB)相結合,Common Crawl 的總數據集則為 107GB。
7.1. Megatron-11B 和 RoBERTa 的數據集總結
Megatron-11B 和 RoBERTa 最終的數據集總結分析如下:

表 13. Megatron-11B 和 RoBERTa 的數據集總結。?公示的數據以粗體表示,確定的數據以斜體表示。
8、MT-NLG 數據集
2021 年,英偉達和微軟發布了擁有 5300 億參數的語言模型 MT-NLG。MT-NLG 是微軟 Turing NLG(擁有 170 億參數)和英偉達 Megatron-LM(擁有 83 億參數)的 “繼任者”。MT-NLG 論文闡明了所用訓練數據集的來源和 token 數量,不過沒有明確指出數據集的大小。
如前所述,有關數據集大小的更多詳情,可以使用 The Pile v1 論文中提供的信息來確定。雖然使用的組件相同,但注意的是,MT-NLG 和 The Pile v1 中報告的組件大小卻各不相同,這是由于來自 Eleuther AI (The Pile v1 數據集) 和 Microsoft/NVIDIA (MT-NLG 模型) 的研究人員采用了不同的數據過濾和去重方法。
8.1. MT-NLG 中的 Common Crawl 數據集
Pile-CC:公開的數據集為 498 億 token,確定的數據為 227.12GB 左右,參見上述 Pile v1 部分。
CC-2020-50:?公開的數據集為 687 億 token,假設 token 的每字節率(per byte rate)為 0.25 TpB=274.8GB。
CC-2021-04:公開的數據集為 826 億 token,假設 token 的每字節率為 0.25 TpB=330.4GB
RealNews(來自 RoBERTa/Megatron-11B):顯示為 219 億 token。根據 RealNews 論文 [27],數據集確定為 120GB。
CC-Stories (來自 RoBERTa/Megatron-11B):公開的數據集為 53 億 token,如上述 RoBERTa 部分所示,數據集確定為 31GB。
根據以上來源,可確認 Common Crawl 的總數據量為 983.32GB,共計 2283 億 token。
8.2. MT-NLG 分組數據集(Grouped Datasets)
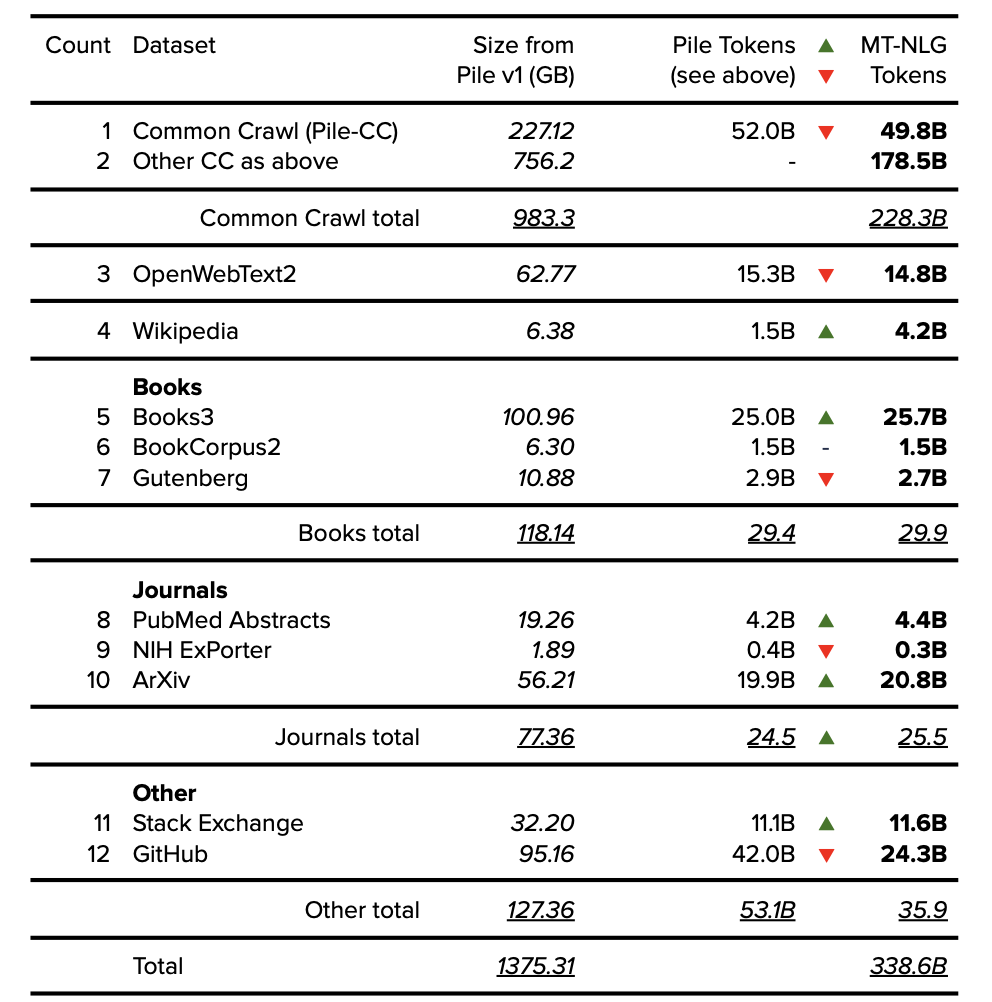
表 14. MT-NLG 分組數據集。公開的數據以粗體表示,確定的數據以斜體表示。
8.3. MT-NLG 數據集總結
MT-NLG 模型最終的數據集總結分析如下:

表 15. MT-NLG 數據集總結。?公示的數據以粗體表示,確定的數據以斜體表示。
9、MT-NLG 數據集?Gopher?數據集
Gopher 模型由 DeepMind 于 2021 年發布,有 2800 億參數。該論文清楚地說明了所使用訓練數據集所包含的高級 token 數量和大小 [28],但沒有說明詳細內容。
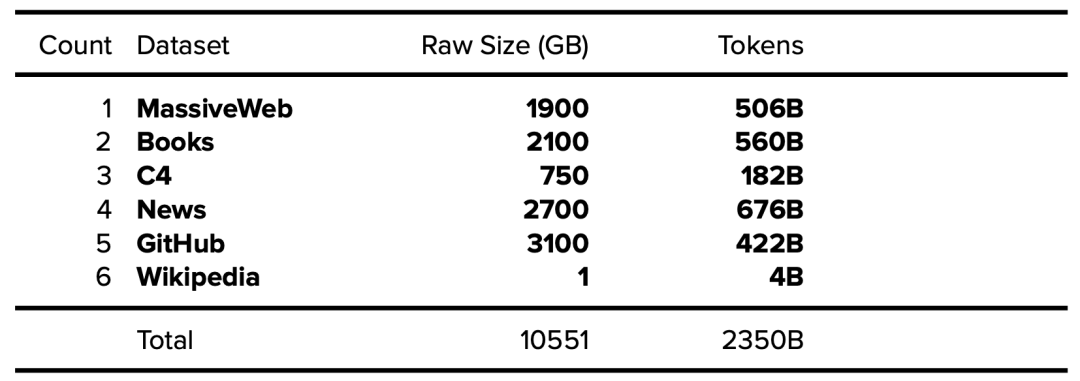
表 16. 公開的 Gopher 數據集 (MassiveText)。公開的數據以粗體表述,確定的數據以斜體表示。
有趣的是,據 Gopher 論文披露:其 Books 數據集中包含一些超過 500 年歷史(1500-2008)的書籍。
9.1. MassiveWeb 數據集分析
DeepMind 于 2014 年被谷歌收購,并在創建 MassiveText 時獲得了海量數據。雖然 Gopher 論文中沒有進一步詳細描述 MassiveWeb,但第 44 頁附錄中的表 A3b 注明了 MassiveWeb 中出現的前 20 個域 [29]。根據披露的每個域所占的百分比,我們可以使用 MassiveWeb 的總 token 數(5060 億 token)和總原始大小(1900GB)來確定每個域的 token 數量和大小。
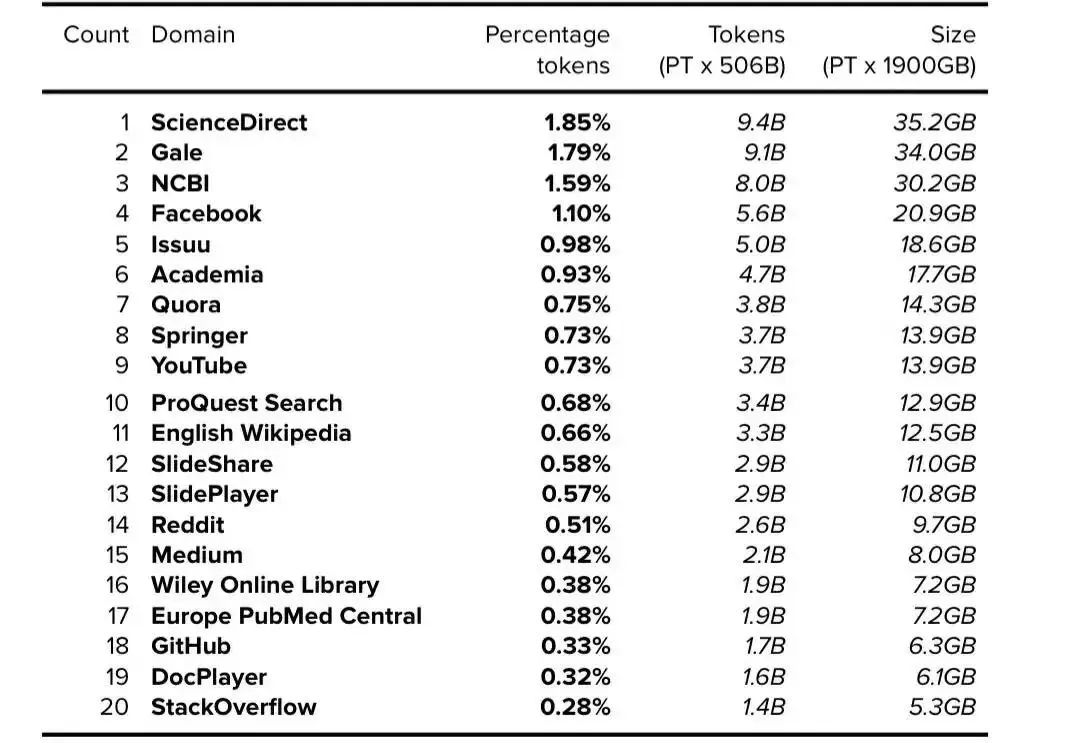
表 17. MassiveWeb:前 20 個域。公開的數據以粗體表示,確定的數據以斜體表示。
9.2. Gopher:關于維基百科數據集的分析
維基百科數據集的總規模很難確定。在 Gopher 論文中,研究人員指出維基百科沒有進行數據去重 [30]。然而,論文中列出的不同大小數據集(12.5GB MassiveWeb Wikipedia 與 1GB MassiveText Wikipedia)可能是由于失誤而造成的,誤將 “10GB” 寫成了 “1GB”。無論如何,本文僅使用 MassiveWeb 數據集版本 (12.5GB)。
9.3. Gopher: 不包括 WebText
Gopher 數據集的組成部分不包括 Reddit 外鏈的 WebText 數據集。為了清楚起見,盡管 Reddit 是 MassiveWeb 中的頂級域,但該數據集僅抓取 Reddit 域內的 Reddit 鏈接。根據定義,WebText [31] 由 “所有 Reddit 的外鏈” 組成(即指向 Reddit 域外的鏈接)。
9.4. Gopher 分組數據集
MassiveWeb 被認為是 MassiveText 的子組件,并被集成到 Gopher 的數據集匯總中,其分組基于以下列出的可用信息:
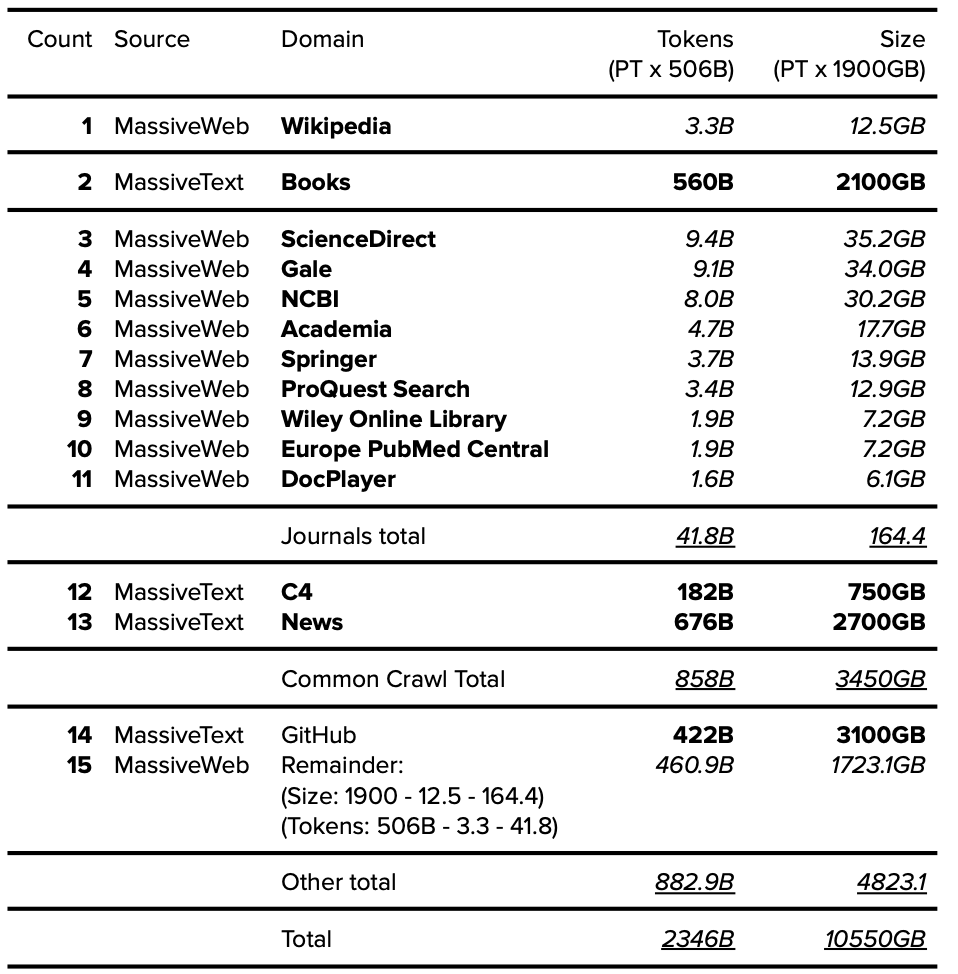
表 18. Gopher 分組數據集。公開的數據以粗體表示,確定的數據以斜體表示。
9.5. Gopher 數據集總結
Gopher 是本文中最大的數據集,大小為 10.5TB。Gopher 模型的最終數據集總結分析為:

表 19. Gopher 數據集總結。公開的數據以粗體表示,確定的數據以斜體表示。
10、結論
對于訓練當代 Transformer 大型語言模型的數據集而言,這可能是最全面的整合分析內容(截止 2022 年初)。在主要數據源不透明的情況下,本次研究主要從二級和三級來源收集數據,并經常需要假定來確定最終估計值。隨著研究人員要處理千萬億個 token(1,000 萬億)和數千 TB 的數據(1,000TB),確保詳細披露數據集組成的文檔變得越來越重要。
特別值得關注的是,基于大型語言模型的強大 AI 系統產生的冗長而匿名的輸出正在迅速發展,其中許多數據集的細節內容幾乎沒有文檔說明。
強烈建議研究人員使用突出顯示的 “數據集的數據表(Datasheet for Datasets)” 論文中提供的模板,并在記錄數據集時使用最佳實踐論文(即 Pile v1 論文,包括 token 數量)。數據集大小(GB)、token 數量(B)、來源、分組和其他詳細信息指標均應完整記錄和發布。
隨著語言模型不斷發展并更廣泛地滲透到人們的生活中,確保數據集的詳細信息公開透明、所有人都可訪問且易于理解是有用、緊迫和必要的。
擴展閱讀及腳注
考慮到簡潔和可讀性,本文使用了腳注而非文本 / 括弧式引文。主要參考文獻如下,或者參見?http://lifearchitect.ai/papers/,獲取大語言模型領域的主要基礎論文。以下論文按本文順序顯示。
Datasheets for Datasets?Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J., Wallach, H., Daumé III, H., & Crawford, K. (2018). Datasheets for Datasets.??https://arxiv.org/abs/1803.09010
GPT-1 paper?Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI.??https://cdn.openai.com/research-covers/language-unsupervised/language_understan??ding_paper.pdf
GPT-2 paper?Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI.??https://cdn.openai.com/better-language-models/language_models_are_unsupervised??_multitask_learners.pdf
GPT-3 paper?Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., & Dhariwal, P. et al. (2020). OpenAI. Language Models are Few-Shot Learners.??https://arxiv.org/abs/2005.14165
The Pile v1 paper?Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., & Foster, C. et al. (2021). The Pile: An 800GB Dataset of Diverse Text for Language Modeling.
EleutherAI.??https://arxiv.org/abs/2101.00027
GPT-J announcement?Komatsuzak, A., Wang, B. (2021). GPT-J-6B: 6B JAX-Based Transformer.??https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
GPT-NeoX-20B paper?Black, S., Biderman, S., Hallahan, E. et al. (2022). EleutherAI. GPT-NeoX-20B: An Open-Source Autoregressive Language Model.??http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
RoBERTa paper?Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., & Chen, D. et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. Meta AI.??https://arxiv.org/abs/1907.11692
MT-NLG paper?Smith, S., Patwary, M., Norick, B., LeGresley, P., Rajbhandari, S., & Casper, J. et al. (2021). Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. Microsoft/NVIDIA.??https://arxiv.org/abs/2201.11990
Gopher paper?Rae, J., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., & Song, F. et al. (2021). Scaling Language Models: Methods, Analysis & Insights from Training Gopher. DeepMind.??https://arxiv.org/abs/2112.11446
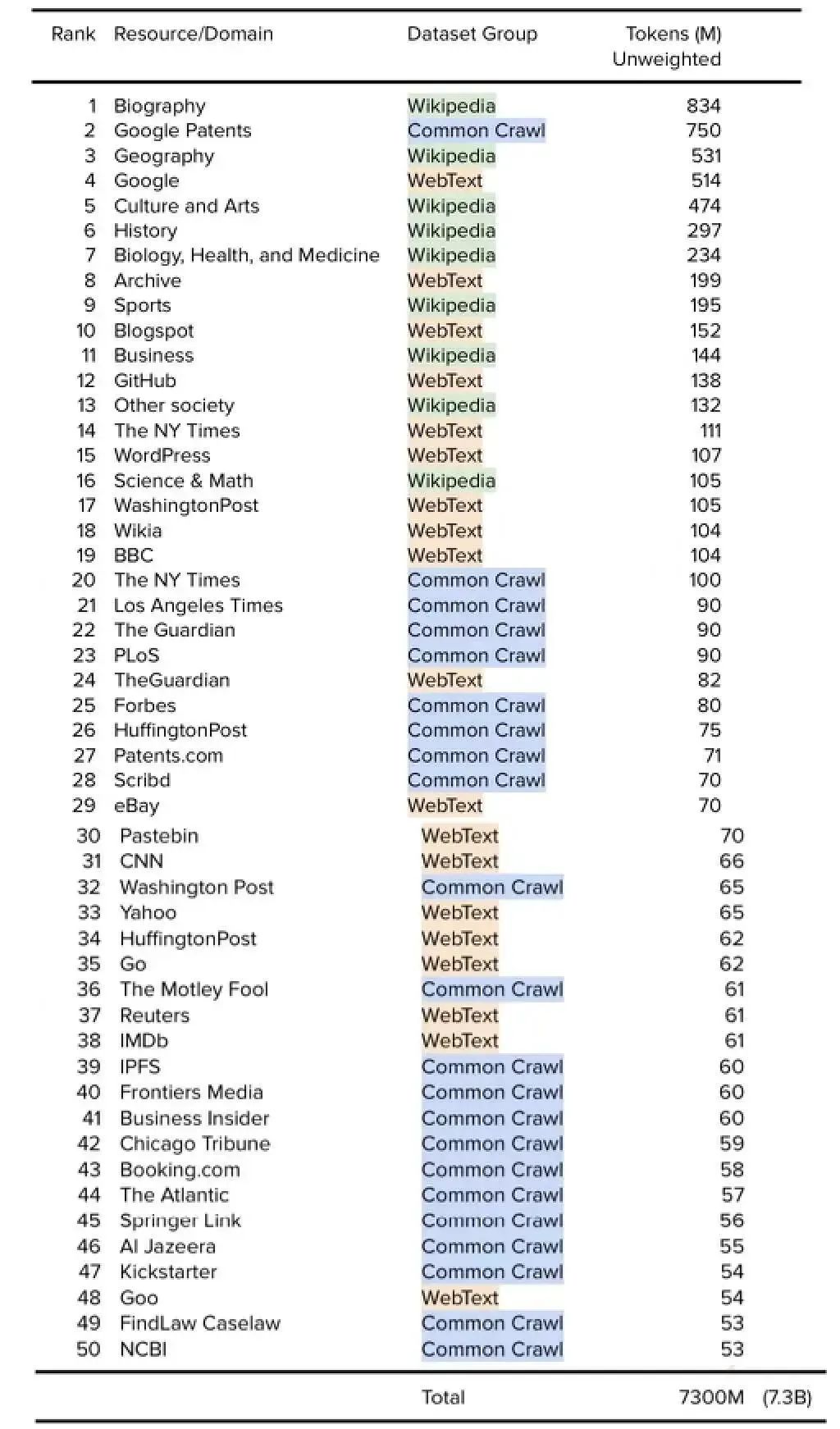
Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3)
附錄 A:前 50 個資源:Wikipedia + CC + WebText(即 GPT-3)
基于本文內容,尤其是每個數據集中每個資源的 token 數量,我們可以對將 Wikipedia + Common Crawl + WebText 數據集的組合,作為其整體訓練數據集的一部分模型進行資源或域的排序。為清楚起見,這包括以下模型:OpenAI GPT-3、EleutherAI GPT-J、EleutherAI GPT-NeoX-20B、Meta AI Megatron-11B 和 RoBERTA,以及 Microsoft/NVIDIA MT-NLG 等。
請注意,展示的排名基于數據集中可用的未加權總 token,每個數據集的主觀權重由研究人員在模型預訓練之前計算得出。其中有一些重復(例如,《紐約時報》既出現在有 1.11 億 token 的 WebText 中,也出現在過濾后有 1 億 token 的 Common Crawl 中)。
腳注
1.?GPT-NeoX-20B paper: pp11, section 6??http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
2.?Datasheet for Datasets paper:??https://arxiv.org/abs/1803.09010
3.?OpenAI blog:??https://openai.com/blog/gpt-3-apps/
4.?On the Opportunities and Risks of Foundation Models:??https://arxiv.org/abs/2108.07258
5.?Size of Wikipedia:??https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia
6.?C4 dataset:??https://www.tensorflow.org/datasets/catalog/c4
7.?Common Crawl website:??https://commoncrawl.org/
8.?C4 paper:??https://arxiv.org/abs/2104.08758??pp2, Figure 1 right
9.?Wikipedia categories:??https://en.wikipedia.org/wiki/User:Smallbones/1000_random_results?: “維基百科涵蓋哪些主題?覆蓋范圍是否隨時間變化?使用 2015 年 12 月抽取的 1001 篇隨機文章對這些問題和類似問題進行了查驗... 隨著時間推移,這些比例相當穩定... 傳記(27.8%),地理(17.7%),文化和藝術(15.8%),歷史(9.9%),生物學、健康和醫學(7.8%),體育(6.5%),商業(4.8%),其他社會(4.4%),科學與數學(3.5%),教育(1.8%)。”
10.?GPT-1 paper: pp4 “We use the BooksCorpus dataset for training the language model.”
11.??https://huggingface.co/datasets/bookcorpus?: “Size of the generated dataset: 4629.00 MB”
12.?BookCorpus Retrospective Datasheet paper: pp9??https://arxiv.org/abs/2105.05241
13. GPT-2 paper: pp3 “我們從社交媒體平臺 Reddit 中抓取了至少有 3 個 karma 的所有出站鏈接。這可以被認為是一個啟發式指標,用于判斷其他用戶是否覺得該鏈接有趣、有教育意義或只是有趣……WebText 包含這 4500 萬個鏈接的文本子集…… 其中不包括 2017 年 12 月之后創建的鏈接。經過去重和一些基于啟發式的清理后,其中包含大約超過 800 萬個文檔,總共 40GB 文本。我們從 WebText 中移除了所有維基百科文檔...”
14.?GPT-2 model card:??https://github.com/openai/gpt-2/blob/master/model_card.md?: “我們已經發布了 WebText 中出現的前 1,000 個域及其頻率的列表。WebText 中排名前 15 位的域是:Google、Archive、Blogspot、GitHub、紐約時報、Wordpress、華盛頓郵報、維基亞、BBC、衛報、eBay、Pastebin、CNN、雅虎和赫芬頓郵報。”
15. GPT-3 paper: “WebText2:190 億 token。[Alan:WebText2 是從 WebText 稍微擴展而來,所以我們可以減去 20%,得到 150 億 token]”
16.?GPT-2 paper: pp3 “GPT-3: pp9, Table 2.2 “CC: 4100 億 token. WebText2: 190 億 token. Books1: 120 億 token. Books2: 550 億 token. Wiki: 30 億 token”
17.?GPT-3 paper: pp8
18.?BookCorpus repo:??soskek/bookcorpus#27?: “books3.tar.gz 似乎類似于 OpenAI 在他們的論文中引用的神秘 “books2” 數據集。不幸的是,OpenAI 不會提供細節,所以我們對其差異知之甚少。人們懷疑它是 “libgen 的全部”,但這純粹是猜測。盡管如此,books3 仍是 “所有的 bibliotik”......”
19.?BookCorpus paper:??https://arxiv.org/abs/1506.06724?: “# of words: 984,846,357 [Alan: BookCorpus 有 13 億 token。我們想要有 120-550 億 token]”
20.?Gutenberg paper:??https://arxiv.org/abs/1812.08092?: “我們介紹了標準化項目古騰堡語料庫(SPGC),這是一種開放的科學方法,用于處理完整 PG 數據的精選版本,其中包含超過 50,000 本書和 3×109word-token [Alan:相當于大約 120 億 BPE token,見下文]”
21.?Gutenberg repo:??https://zenodo.org/record/2422561??“未壓縮大小:3GB(count)+ 18GB(token)[總計 21GB]”
22. The Pile v1 paper: “Books3(Bibliotik tracker):100.96GB” [Alan:乘以每字節 token 數 0.2477 = 250 億 token]
23.?The Pile v1 paper: pp3, Table 1 for datasets. pp28, Table 7 for Tokens per byte.
24.?RoBERTa paper:??https://arxiv.org/abs/1907.11692??“BOOKCORPUS 加上英文 WIKIPEDIA。這是用來訓練 BERT 的原始數據。(16GB)。”
25.?BERT paper:??https://arxiv.org/abs/1810.04805??“BERT 在 BooksCorpus(8 億字)和維基百科(25 億字)上進行訓練。”
26.?Stories paper:??https://arxiv.org/abs/1806.02847??pp5-6
27.?RealNews paper:??https://arxiv.org/abs/1905.12616v3??“去重后,RealNews 在沒有壓縮的情況下為 120GB。”
28.?Gopher paper:??https://arxiv.org/abs/2112.11446??pp 7: list of sizes and tokens.
29.?Gopher paper:??https://arxiv.org/abs/2112.11446??pp 44, Figure A3b.
30.?Gopher paper: pp41n14 “請注意,我們將文檔去重應用于除 Wikipedia 和 GitHub 之外的所有 MassiveText 子集 “
31.?GPT-2 paper, pp3.
關于作者
Alan D. Thompson 博士是人工智能專家、顧問。在 2021 年 8 月的世界人才大會(World Gifted Conference)上,Alan 與 Leta(由 GPT-3 提供支持的 AI)共同舉辦了一場名為 “The new irrelevance of intelligence” 的研討會。他的應用型人工智能研究和可視化成果受到了國際主要媒體的報道,同時還在 2021 年 12 月牛津大學有關 AI 倫理的辯論中被引用。他曾擔任門薩國際(Mensa International)主席、通用電氣(GE)和華納兄弟(Warner Bros)顧問,也曾是電氣與電子工程師協會(IEEE)和英國工程技術學會(IET)會員。
?
編輯:黃飛
?












 工商網監
工商網監
評論