 電子發燒友App
電子發燒友App


去年年底,OpenAI 向公眾推出了 ChatGPT,一經發布,這項技術立即將 AI 驅動的聊天機器人推向了主流話語的中心,眾多研究者并就其如何改變商業、教育等展開了一輪又一輪辯論。
隨后,科技巨頭們紛紛跟進投入科研團隊,他們所謂的「生成式 AI」技術(可以制作對話文本、圖形等的技術)也已準備就緒。
眾所周知,ChatGPT 是在 GPT-3.5 系列模型的基礎上微調而來的,我們看到很多研究也在緊隨其后緊追慢趕,但是,與 ChatGPT 相比,他們的新研究效果到底有多好?近日,亞馬遜發布的一篇論文《Multimodal Chain-of-Thought Reasoning in Language Models》中,他們提出了包含視覺特征的 Multimodal-CoT,該架構在參數量小于 10 億的情況下,在 ScienceQA 基準測試中,比 GPT-3.5 高出 16 個百分點 (75.17%→91.68%),甚至超過了許多人類。
這里簡單介紹一下 ScienceQA 基準測試,它是首個標注詳細解釋的多模態科學問答數據集 ,由 UCLA 和艾倫人工智能研究院(AI2)提出,主要用于測試模型的多模態推理能力,有著非常豐富的領域多樣性,涵蓋了自然科學、語言科學和社會科學領域,對模型的邏輯推理能力提出了很高的要求。

論文地址:https://arxiv.org/abs/2302.00923
項目地址:https://github.com/amazon-science/mm-cot
下面我們來看看亞馬遜的語言模型是如何超越 GPT-3.5 的。
包含視覺特征的 Multimodal-CoT
大型語言模型 (LLM) 在復雜推理任務上表現出色,離不開思維鏈 (CoT) 提示的助攻。然而,現有的 CoT 研究只關注語言模態。為了在多模態中觸發 CoT 推理,一種可能的解決方案是通過融合視覺和語言特征來微調小型語言模型以執行 CoT 推理。
然而,根據已有觀察,小模型往往比大模型更能頻繁地胡編亂造,模型的這種行為通常被稱為「幻覺(hallucination)」。此前谷歌的一項研究也表明( 論文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ),基于 CoT 的提示只有在模型具有至少 1000 億參數時才有用!
也就是說,CoT 提示不會對小型模型的性能產生積極影響,并且只有在與 ~100B 參數的模型一起使用時才會產生性能提升。
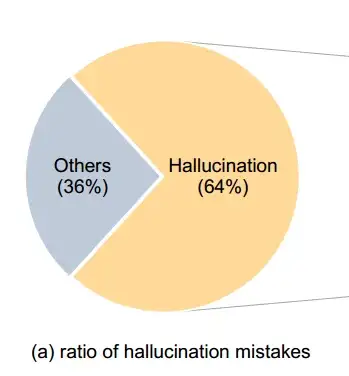
然而,本文研究在小于 10 億參數的情況下就產生了性能提升,是如何做到的呢?簡單來講,本文提出了包含視覺特征的 Multimodal-CoT,通過這一范式(Multimodal-CoT)來尋找多模態中的 CoT 推理。
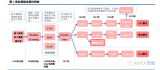
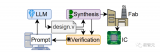
Multimodal-CoT 將視覺特征結合在一個單獨的訓練框架中,以減少語言模型有產生幻覺推理模式傾向的影響。總體而言,該框架將推理過程分為兩部分:基本原理生成(尋找原因)和答案推理(找出答案)。?
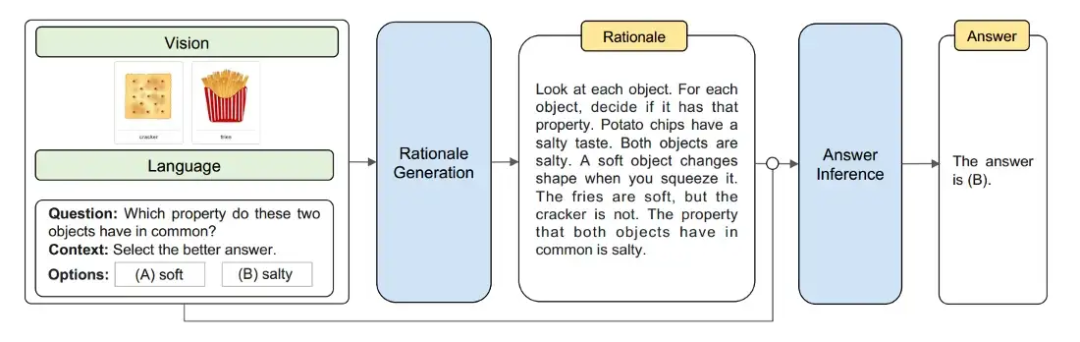
Multimodal CoT 兩階段過程:使用文本(問題 + 上下文)和視覺特征來產生邏輯依據。
數據集
本文主要關注 ScienceQA 數據集,該數據集將圖像和文本作為上下文的一部分,此外,該數據集還包含對答案的解釋,以便可以對模型進行微調以生成 CoT 基本原理。此外,本文利用 DETR 模型生成視覺特征。
較小的 LM 在生成 CoT / 基本原理時容易產生幻覺,作者推測,如果有一個修改過的架構,模型可以利用 LM 生成的文本特征和圖像模型生成的視覺特征,那么 更有能力提出理由和回答問題。
架構
總的來說,我們需要一個可以生成文本特征和視覺特征并利用它們生成文本響應的模型。
又已知文本和視覺特征之間存在的某種交互,本質上是某種共同注意力機制,這有助于封裝兩種模態中存在的信息,這就讓借鑒思路成為了可能。為了完成所有這些,作者選擇了 T5 模型,它具有編碼器 - 解碼器架構,并且如上所述,DETR 模型用于生成視覺特征。
T5 模型的編碼器負責生成文本特征,但 T5 模型的解碼器并沒有利用編碼器產生的文本特征,而是使用作者提出的共同注意式交互層(co-attention-styled interaction layer)的輸出。
拆解來看,假設 H_language 是 T5 編碼器的輸出。X_vision 是 DETR 的輸出。第一步是確保視覺特征和文本特征具有相同的隱藏大小,以便我們可以使用注意力層。
注意:所有代碼片段均來自論文的 GitHub:https://github.com/amazon-science/mm-cot/blob/main/model.py

?
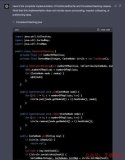
self.image_dense = nn.Linear(self.patch_dim, config.d_model)
W_h 本質上是一個線性層,H_vision 對應最終的視覺特征。W_h 有助于更改視覺特征的大小以匹配文本特征的大小。
下面我們需要添加一個注意力層,以便視覺和文本特征可以相互交互。為此,作者使用單頭注意力層,將 H_language 作為查詢向量,將 H_vision 作為鍵和值向量。
self.mha_layer = torch.nn.MultiheadAttention(embed_dim=config.hidden_size,?
kdim=config.hidden_size, vdim=config.hidden_size,
num_heads=1, batch_first=True)
image_att, _ = self.mha_layer(hidden_states, image_embedding, image_embedding)
現在我們有了包含來自文本和視覺特征的信息的嵌入。隨后,作者利用門控融合來生成最終的一組特征,這些特征將被發送到解碼器。門控融合有兩個步驟:
獲取一個介于 0 和 1 之間的分數向量,以確定每個注意力特征的重要性。
利用 score 融合 text 和 attention 特征。

W_I 和 W_v 本質上是兩個線性層。
?
?
self.gate_dense = nn.Linear(2*config.hidden_size, config.hidden_size) self.sigmoid = nn.Sigmoid() hidden_states = encoder_outputs[0] merge = torch.cat([hidden_states, image_att], dim=-1) gate = self.sigmoid(self.gate_dense(merge)) hidden_states = (1 - gate) * hidden_states + gate * image_att
最后,融合的特征被傳遞給解碼器。
decoder_outputs = self.decoder( input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
inputs_embeds=decoder_inputs_embeds,
past_key_values=past_key_values,
encoder_hidden_states=hidden_states,
這幾乎就是作者所遵循的架構!但是,請記住有兩個階段。第一個階段是產生基本原理 / CoT。第二階段利用第一階段產生的 CoT 來產生答案,如上圖所示。
結果
作者使用 UnifiedQA 模型的權重作為 T5 模型的初始化點,并在 ScienceQA 數據集上對其進行微調。他們觀察到他們的 Multimodal CoT 方法優于所有以前的基準,包括 GPT-3.5。
有趣的地方在于,即使只有 2.23 億個參數的基本模型也優于 GPT-3.5 和其他 Visual QA 模型!這突出了擁有多模態架構的力量。
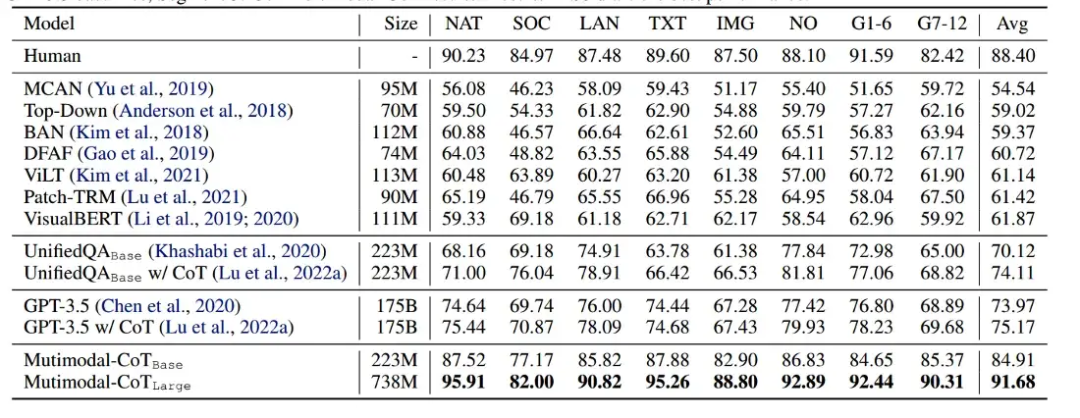
作者還展示了他們的兩階段方法優于單階段方法。

結論
這篇論文帶來的最大收獲是多模態特征在解決具有視覺和文本特征的問題時是多么強大。
作者展示了利用視覺特征,即使是小型語言模型(LM)也可以產生有意義的思維鏈 / 推理,而幻覺要少得多,這揭示了視覺模型在發展基于思維鏈的學習技術中可以發揮的作用。
從實驗中,我們看到以幾百萬個參數為代價添加視覺特征的方式,比將純文本模型擴展到數十億個參數能帶來更大的價值。
參考內容:
https://pub.towardsai.net/paper-review-multimodal-chain-of-thought-reasoning-a550f8de693c
編輯:黃飛
?






























 工商網監
工商網監
評論