 電子發燒友App
電子發燒友App


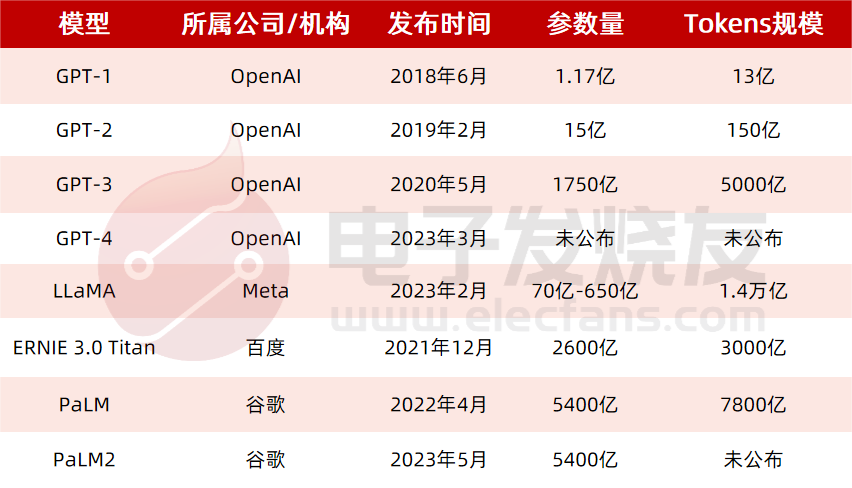
ChatGPT發布之后,引發了全球范圍的關注和討論,國內各大廠商相繼宣布GPT模型開發計劃。以GPT模型為代表的AI大模型訓練,需要消耗大量算力資源,主要需求場景來自:預訓練+日常運營+Finetune。以預訓練為例,據測算,進行一次ChatGPT的模型預訓練需要消耗約27.5PFlop/s-day算力。基于此,隨著國產大模型開發陸續進入預訓練階段,算力需求持續釋放或將帶動算力基礎設施產業迎來增長新周期。產業鏈相關公司包括:
?算力芯片廠商:景嘉微、寒武紀、海光信息、龍芯中科、中國長城等;
?服務器廠商:浪潮信息、中科曙光等;
?IDC服務商:寶信軟件等。
ChatGPT:大模型訓練帶來高算力需求
訓練ChatGPT需要使用大量算力資源。據微軟官網,微軟Azure為OpenAI開發的超級計算機是一個單一系統,具有超過28.5萬個CPU核心、1萬個GPU和400 GB/s的GPU服務器網絡傳輸帶寬。據英偉達,使用單個Tesla架構的V100 GPU對1746億參數的GPT-3模型進行一次訓練,需要用288年時間。此外,算力資源的大量消耗,必然伴隨著算力成本的上升,據Lambda,使用訓練一次1746億參數的GPT-3模型所需花費的算力成本超過460萬美元。我們認為,未來擁有更豐富算力資源的模型開發者,或將能夠訓練出更優秀的AI模型,算力霸權時代或將開啟。
具體來看,AI大模型對于算力資源的需求主要體現在以下三類場景:
1、模型預訓練帶來的算力需求
模型預訓練過程是消耗算力的最主要場景。
預計,訓練一次ChatGPT模型需要的算力約27.5PFlop/s-day。據OpenAI團隊發表于2020年的論文《Language Models are Few-Shot Learners》,訓練一次13億參數的GPT-3 XL模型需要的全部算力約為27.5PFlop/s-day,訓練一次1746億參數的GPT-3模型需要的算力約為3640 PFlop/s-day。考慮到ChatGPT訓練所用的模型是基于13億參數的GPT-3.5模型微調而來,參數量與GPT-3 XL模型接近,因此我們預計訓練所需算力約27.5PFlop/s-day,即以1萬億次每秒的速度進行計算,需要耗時27.5天。
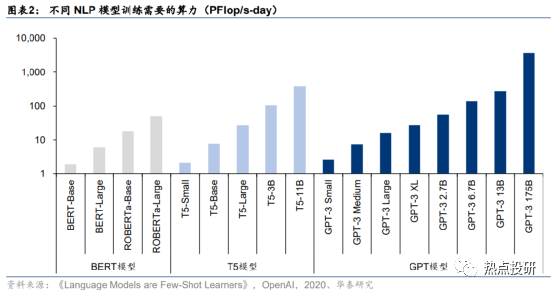
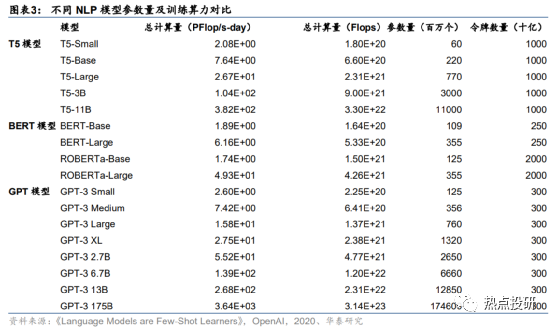 此外,預訓練過程還存在幾個可能的算力需求點:
此外,預訓練過程還存在幾個可能的算力需求點:
1)模型開發過程很難一次取得成功,整個開發階段可能需要進行多次預訓練過程;
2)隨著國內外廠商相繼入局研發類似模型,參與者數量增加同樣帶來訓練算力需求;
3)從基礎大模型向特定場景遷移的過程,如基于ChatGPT構建醫療AI大模型,需要使用特定領域數據進行模型二次訓練。
 2、日常運營帶來的算力需求
2、日常運營帶來的算力需求
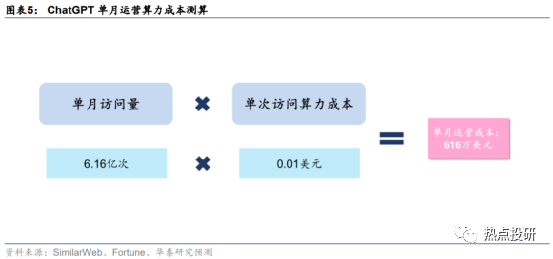
ChatGPT單月運營需要算力約4874.4PFlop/s-day,對應成本約616萬美元。
在完成模型預訓練之后,ChatGPT對于底層算力的需求并未結束,日常運營過程中,用戶交互帶來的數據處理需求同樣也是一筆不小的算力開支。據SimilarWeb數據,2023年1月ChatGPT官網總訪問量為6.16億次。據Fortune雜志,每次用戶與ChatGPT互動,產生的算力云服務成本約0.01美元。基于此,我們測算得2023年1月OpenAI為ChatGPT支付的運營算力成本約616萬美元。據上文,我們已知訓練一次1746億參數的GPT-3模型需要3640 PFlop/s-day的算力及460萬美元的成本,假設單位算力成本固定,測算得ChatGPT單月運營所需算力約4874.4PFlop/s-day。
3、Finetune帶來的算力需求
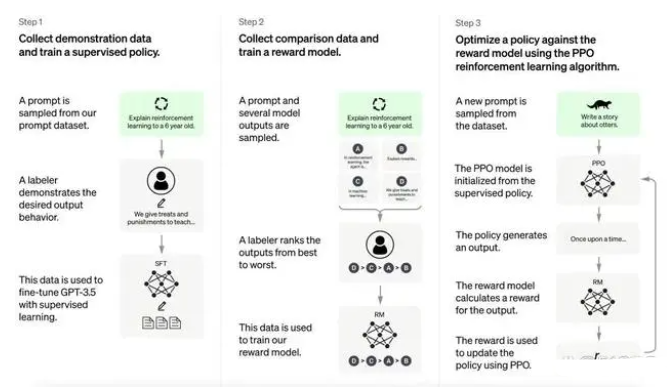
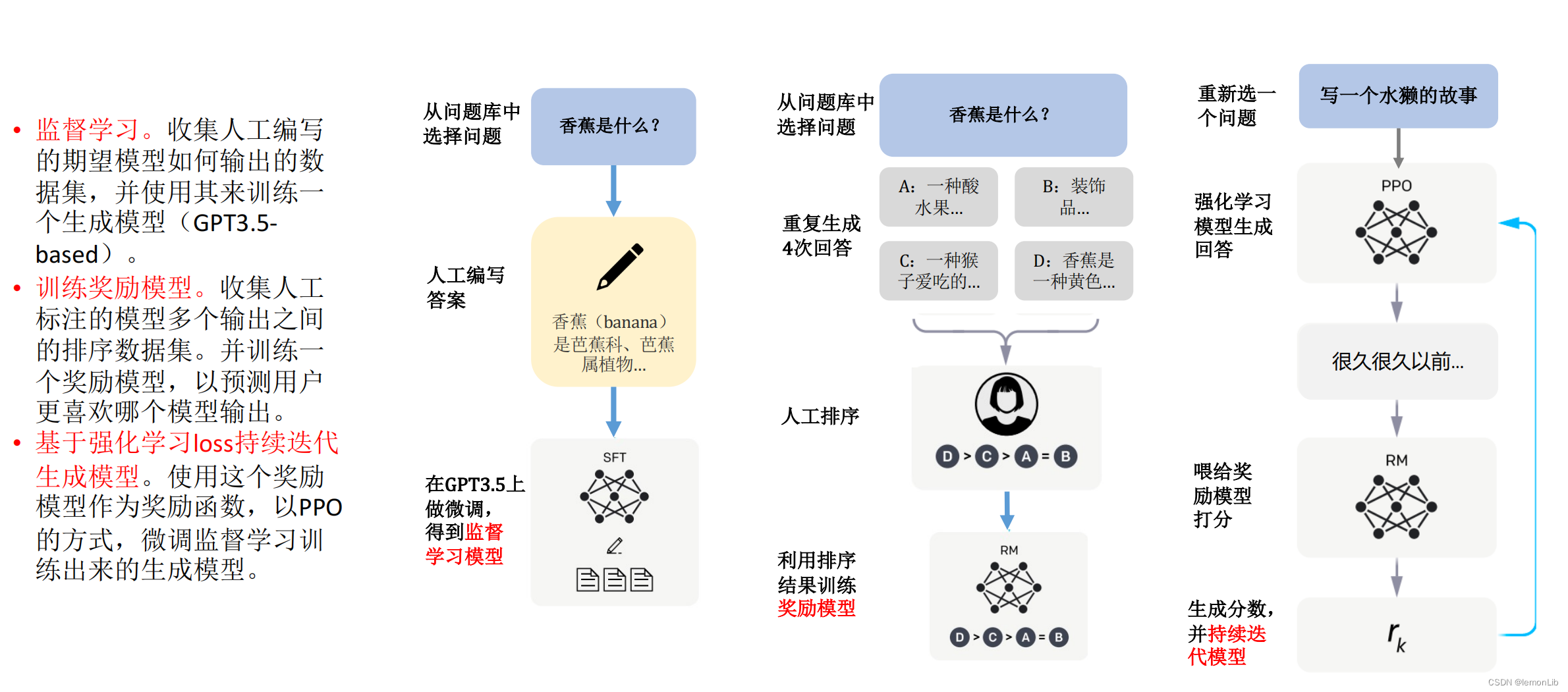
模型調優帶來迭代算力需求。從模型迭代的角度來看,ChatGPT模型并不是靜態的,而是需要不斷進行Finetune模型調優,以確保模型處于最佳應用狀態。這一過程中,一方面是需要開發者對模型參數進行調整,確保輸出內容不是有害和失真的;另一方面,需要基于用戶反饋和PPO策略,對模型進行大規模或小規模的迭代訓練。因此,模型調優同樣會為OpenAI帶來算力成本,具體算力需求和成本金額取決于模型的迭代速度。
需求場景:預訓練+日常運營+Finetune
具體來看,AI大模型對于算力資源的需求主要體現在以下三類場景:
1)模型預訓練:ChatGPT采用預訓練語言模型,核心思想是在利用標注數據之前,先利用無標注的數據訓練模型。據我們測算,訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day;
2)日常運營:用戶交互帶來的數據處理需求同樣也是一筆不小的算力開支,我們測算得ChatGPT單月運營需要算力約4874.4PFlop/s-day,對應成本約616萬美元;
3)Finetune:ChatGPT模型需要不斷進行Finetune模型調優,對模型進行大規模或小規模的迭代訓練,預計每月模型調優帶來的算力需求約82.5~137.5 PFlop/s-day。
算力芯片+服務器+數據中心,核心環節率先受益
隨著國內廠商相繼布局ChatGPT類似模型,算力需求或將持續釋放,供給端核心環節或將率先受益:
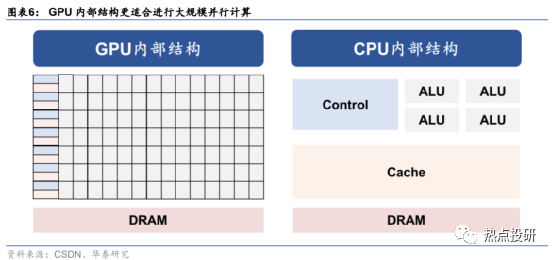
1)算力芯片:GPU采用了數量眾多的計算單元和超長的流水線,架構更適合進行大吞吐量的AI并行計算;
2)服務器:ChatGPT模型訓練涉及大量向量及張量運算,AI服務器具備運算效率優勢,大模型訓練有望帶動AI服務器采購需求放量;
3)數據中心:IDC算力服務是承接AI計算需求的直接形式,隨著百度、京東等互聯網廠商相繼布局ChatGPT類似產品,核心城市IDC算力缺口或將加大。
算力芯片:AI算力基石,需求有望大規模擴張
GPU架構更適合進行大規模AI并行計算,需求有望大規模擴張。從ChatGPT模型計算方式來看,主要特征是采用了并行計算。對比上一代深度學習模型RNN來看,Transformer架構下,AI模型可以為輸入序列中的任何字符提供上下文,因此可以一次處理所有輸入,而不是一次只處理一個詞,從而使得更大規模的參數計算成為可能。而從GPU的計算方式來看,由于GPU采用了數量眾多的計算單元和超長的流水線,因此其架構設計較CPU而言,更適合進行大吞吐量的AI并行計算。基于此,我們認為,隨著大模型訓練需求逐步增長,下游廠商對于GPU先進算力及芯片數量的需求均有望提升。
 單一英偉達V100芯片進行一次ChatGPT模型訓練,大約需要220天。我們以AI訓練的常用的GPU產品—NVIDIA V100為例。V100在設計之初,就定位于服務數據中心超大規模服務器。據英偉達官網,V100 擁有 640 個 Tensor 內核,對比基于單路英特爾金牌6240的CPU服務器可以實現24倍的性能提升。考慮到不同版本的V100芯片在深度學習場景下計算性能存在差異,因此我們折中選擇NVLink版本V100(深度學習算力125 TFlops)來計算大模型訓練需求。據前文,我們已知訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day,計算得若由單個V100 GPU進行計算,需220天;若將計算需求平均分攤至1萬片GPU,一次訓練所用時長則縮短至約32分鐘。
單一英偉達V100芯片進行一次ChatGPT模型訓練,大約需要220天。我們以AI訓練的常用的GPU產品—NVIDIA V100為例。V100在設計之初,就定位于服務數據中心超大規模服務器。據英偉達官網,V100 擁有 640 個 Tensor 內核,對比基于單路英特爾金牌6240的CPU服務器可以實現24倍的性能提升。考慮到不同版本的V100芯片在深度學習場景下計算性能存在差異,因此我們折中選擇NVLink版本V100(深度學習算力125 TFlops)來計算大模型訓練需求。據前文,我們已知訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day,計算得若由單個V100 GPU進行計算,需220天;若將計算需求平均分攤至1萬片GPU,一次訓練所用時長則縮短至約32分鐘。
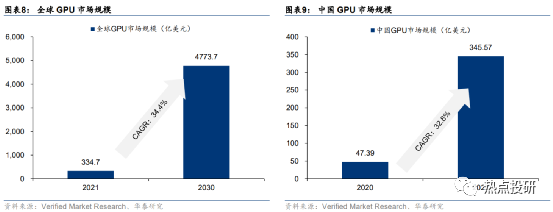
 全球/中國GPU市場規模有望保持快速增長。據VMR數據,2021年全球GPU行業市場規模為334.7億美元,預計2030年將達到4773.7億美元,預計22-30年CAGR將達34.4%。2020年中國GPU市場規模47.39億美元,預計2027年市場規模將達345.57億美元,預計21-27年CAGR為32.8%。
全球/中國GPU市場規模有望保持快速增長。據VMR數據,2021年全球GPU行業市場規模為334.7億美元,預計2030年將達到4773.7億美元,預計22-30年CAGR將達34.4%。2020年中國GPU市場規模47.39億美元,預計2027年市場規模將達345.57億美元,預計21-27年CAGR為32.8%。
服務器:AI服務器有望持續放量
ChatGPT主要進行矩陣向量計算,AI服務器處理效率更高。從ChatGPT模型結構來看,基于Transformer架構,ChatGPT模型采用注意力機制進行文本單詞權重賦值,并向前饋神經網絡輸出數值結果,這一過程需要進行大量向量及張量運算。而AI服務器中往往集成多個AI GPU,AI GPU通常支持多重矩陣運算,例如卷積、池化和激活函數,以加速深度學習算法的運算。因此在人工智能場景下,AI服務器往往較GPU服務器計算效率更高,具備一定應用優勢。
 單臺服務器進行一次ChatGPT模型訓練所需時間約為5.5天。我們以浪潮信息目前算力最強的服務器產品之一—浪潮NF5688M6為例。NF5688M6是浪潮為超大規模數據中心研發的NVLink AI 服務器,支持2顆Intel最新的Ice Lake CPU和8顆NVIDIA最新的NVSwitch全互聯A800GPU,單機可提供5PFlops的AI計算性能。據前文,我們已知訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day,計算得若由單臺NF5688M6服務器進行計算,需5.5天。
單臺服務器進行一次ChatGPT模型訓練所需時間約為5.5天。我們以浪潮信息目前算力最強的服務器產品之一—浪潮NF5688M6為例。NF5688M6是浪潮為超大規模數據中心研發的NVLink AI 服務器,支持2顆Intel最新的Ice Lake CPU和8顆NVIDIA最新的NVSwitch全互聯A800GPU,單機可提供5PFlops的AI計算性能。據前文,我們已知訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day,計算得若由單臺NF5688M6服務器進行計算,需5.5天。
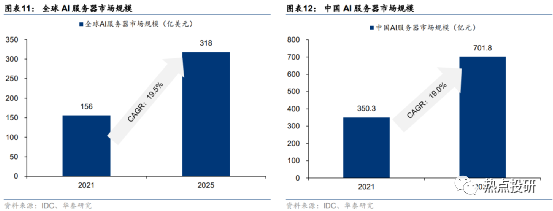
大模型訓練需求有望帶動AI服務器放量。隨著大數據及云計算的增長帶來數據量的增加,對于AI智能服務器的需求明顯提高。據IDC數據,2021年全球AI服務器市場規模為156億美元,預計到2025年全球AI服務器市場將達到318億美元,預計22-25年CAGR將達19.5%。
數據中心:核心城市集中算力缺口或將加劇
IDC算力服務是承接AI計算需求的直接形式。ChatGPT的模型計算主要基于微軟的Azure云服務進行,本質上是借助微軟自有的IDC資源,在云端完成計算過程后,再將結果返回給OpenAI。可見,IDC是承接人工智能計算任務的重要算力基礎設施之一,但并不是所有企業都需要自行搭建算力設施。從國內數據中心的業務形態來看,按照機房產權歸屬及建設方式的角度,可分為自建機房、租賃機房、承接大客戶定制化需求以及輕資產衍生模式四種。
若使用某一IDC全部算力,可在11分鐘完成一次ChatGPT模型訓練。我們以亞洲最大的人工智能計算中心之一—商湯智算中心為例。據商湯科技官網,商湯智算中心于2022年1月啟動運營,峰值算力高達3740 Petaflops。據前文,我們已知訓練一次ChatGPT模型(13億參數)需要的算力約27.5PFlop/s-day,計算得若使用商湯智算中心全部算力進行計算,僅需11分鐘即可完成。
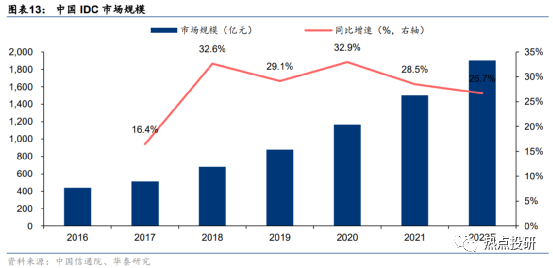
AI訓練需求有望帶動IDC市場規模快速增長。據中國信通院,2021年國內IDC市場規模1500.2億元,同比增長28.5%。據信通院預計,隨著我國各地區、各行業數字化轉型深入推進、AI訓練需求持續增長、智能終端實時計算需求增長,2022年國內市場規模將達1900.7億元,同增26.7%。
 互聯網廠商布局ChatGPT類似產品,或將加大核心城市IDC算力供給缺口。據艾瑞咨詢,2021年國內IDC行業下游客戶占比中,互聯網廠商居首位,占比為60%;其次為金融業,占比為20%;政府機關占比10%,位列第三。而目前國內布局ChatGPT類似模型的企業同樣以互聯網廠商為主,如百度宣布旗下大模型產品“文心一言”將于2022年3月內測、京東于2023年2月10日宣布推出產業版ChatGPT:ChatJD。另一方面,國內互聯網廠商大多聚集在北京、上海、深圳、杭州等國內核心城市,在可靠性、安全性及網絡延遲等性能要求下,或將加大對本地IDC算力需求,國內核心城市IDC算力供給缺口或將加大。
互聯網廠商布局ChatGPT類似產品,或將加大核心城市IDC算力供給缺口。據艾瑞咨詢,2021年國內IDC行業下游客戶占比中,互聯網廠商居首位,占比為60%;其次為金融業,占比為20%;政府機關占比10%,位列第三。而目前國內布局ChatGPT類似模型的企業同樣以互聯網廠商為主,如百度宣布旗下大模型產品“文心一言”將于2022年3月內測、京東于2023年2月10日宣布推出產業版ChatGPT:ChatJD。另一方面,國內互聯網廠商大多聚集在北京、上海、深圳、杭州等國內核心城市,在可靠性、安全性及網絡延遲等性能要求下,或將加大對本地IDC算力需求,國內核心城市IDC算力供給缺口或將加大。
編輯:黃飛
















 工商網監
工商網監
評論