由于本文以大語言模型 RLHF 的 PPO 算法為主,所以希望你在閱讀前先弄明白大語言模型 RLHF 的前兩步,即 SFT Model 和 Reward Model 的訓練過程。另外因為本文不是純講強化學習的文章,所以我在敘述的時候不會假設你已經非常了解強化學習了。
2023-12-11 18:30:49 1151
1151 
等,在實際應用場景中效果不好。為了解決這個問題,將知識注入到PLMs中已經成為一個非常活躍的研究領域。本次分享將介紹三篇知識增強的預訓練語言模型論文,分別通過基于知識向量、知識檢索以及知識監督的知識注入方法來增強語言預訓練模型。
2022-04-02 17:21:438765 將模型稱為 “視覺語言” 模型是什么意思?一個結合了視覺和語言模態的模型?但這到底是什么意思呢?
2023-03-03 09:49:37665 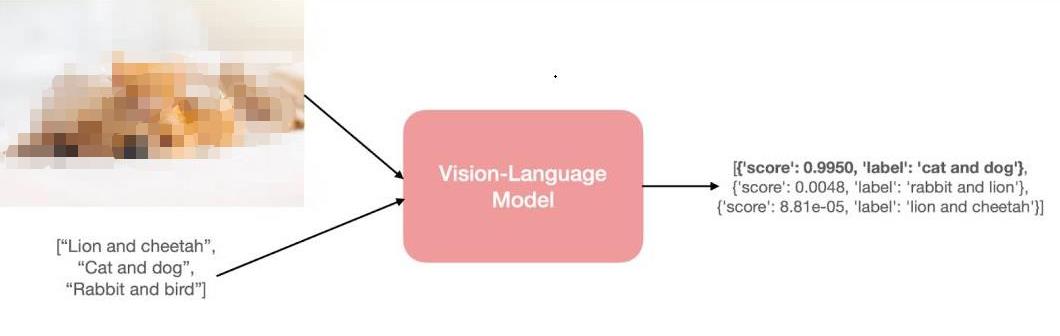
大型語言模型的出現極大地推動了自然語言處理領域的進步,但同時也存在一些局限性,比如模型可能會產生看似合理但實際上是錯誤或虛假的內容,這一現象被稱為幻覺(hallucination)。幻覺的存在使得
2023-08-15 09:33:451090 
Saber不僅支持MAST語言和VHDL‐AMS語言建立模型,也支持C語言建立器件模型,這對熟悉C語言編程的用戶帶來了很大的方便和實用。采用C語言建立的模型可以像用硬件語言建立的模型一樣保存和使用。
2023-12-05 11:30:42454 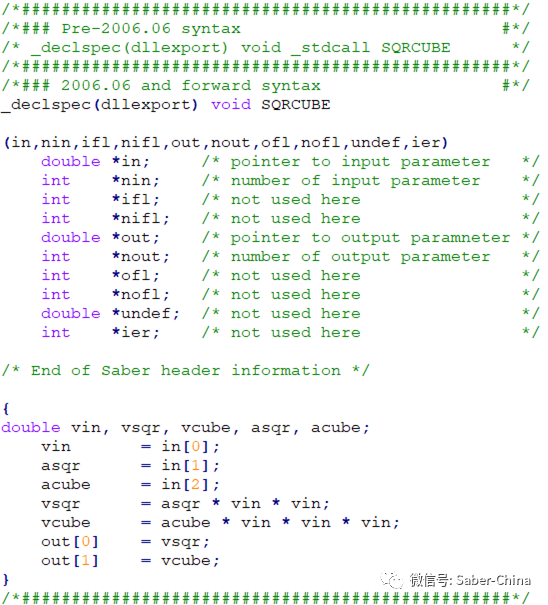
ChatGPT已經成為家喻戶曉的名字,而大語言模型在ChatGPT刺激下也得到了快速發展,這使得我們可以基于這些技術來改進我們的業務。
2023-12-06 17:02:27719 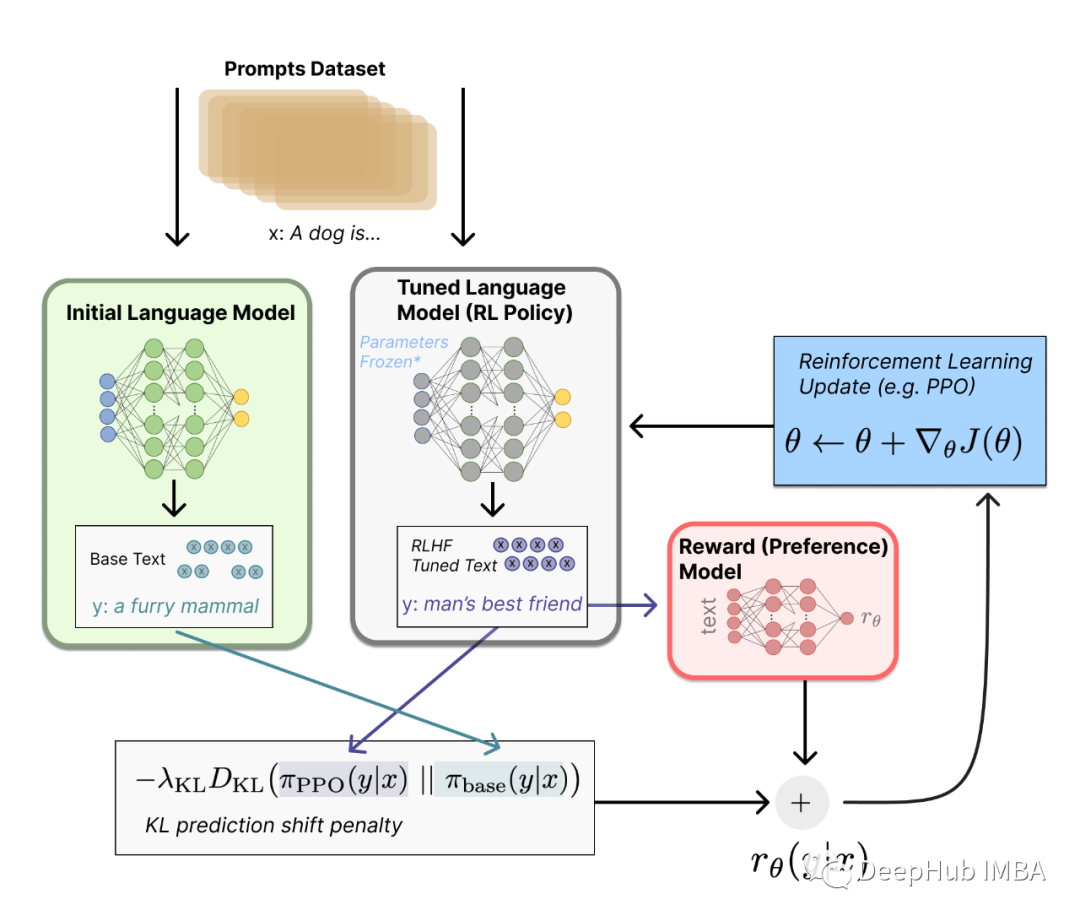
? 電子發燒友網報道(文/李彎彎)近年來,隨著大語言模型的不斷出圈,Transformer這一概念也走進了大眾視野。Transformer是一種非常流行的深度學習模型,最早于2017年由谷歌
2023-12-25 08:36:001282 
電子發燒友網報道(文/李彎彎)大語言模型(LLM)是基于海量文本數據訓練的深度學習模型。它不僅能夠生成自然語言文本,還能夠深入理解文本含義,處理各種自然語言任務,如文本摘要、問答、翻譯
2024-01-02 09:28:331267 400mhz語言視頻傳輸方案怎么實現
2023-10-17 07:22:27
DeepLearning筆記 語言模型和 N-gram
2019-07-23 17:13:48
進行初始化時回調。context接口示例:*附件:HarmonyOSOpenHarmony應用開發-stage模型ArkTS語言AbilityStage.docx
2023-04-07 15:16:35
,然后將得到的特征向量輸入到SVM中進行分類。
LabVIEW是一種視覺編程語言,與傳統的文本編程語言不同,更適合于進行復雜數據分析和預測模型的開發。
LabVIEW使用數據流模型,可以并行處理多個過程
2023-12-13 19:04:23
2022年11月,ChatGPT的問世展示了大模型的強大潛能,對人工智能領域有重大意義,并對自然語言處理研究產生了深遠影響,引發了大模型研究的熱潮。
距ChatGPT問世不到一年,截至2023年10
2024-03-11 15:16:39
深遠影響,尤其在優化業務流程和重塑組織結構方面。然而,在研究和實踐過程中,我們遇到了一個主要挑戰:市場上缺乏大語言模型在實際應用方面的資料。現有的資料多聚焦于理論研究,而具體的實踐方法多被保密,難以獲得
2024-03-18 15:49:46
自然語言處理——54 語言模型(自適應)
2020-04-09 08:20:30
如圖前兩張為一張圖片的R通道進行增強的小程序,可以實現讀片的增強,我想問各路大神,如果單純地從數組方面進行圖像增強,如對數增強,那該怎么操作呢,就在第三章圖里面,就對一個數組進行處理,后面再由數組轉變為圖片。
2017-09-26 17:13:37
如何提升EMC性能?求增強電源模塊系統穩定性的幾個方案
2021-03-16 06:48:24
測試藍牙增強數據率產品的創新解決方案
2019-09-11 14:07:11
自然語言處理——53 語言模型(數據平滑)
2020-04-16 11:11:25
該文提出了一種新的基于身份的環簽名方案,并在標準模型下證明其能抵抗簽名偽造攻擊,且具有無條件匿名性。與現有標準模型下基于身份的環簽名方案相比,新方案具有更短的
2009-11-13 11:49:03 7
7 重新增強高可用性縮減 IT 基礎設施模型
2016-01-06 17:33:540 voico 重新增強高可用性縮減 IT 基礎設施模型
2016-06-02 15:41:580 唇語識別中的話題相關語言模型研究_王淵
2017-03-19 11:28:160 語言競爭傳播演化現象是典型的不能假設、無法進行真實性實驗的社會科學問題,而建立在社會仿真模型基礎上的計算實驗是可行的方案。利用基于Agent的社會圈子網絡理論并引入語言的內部詞匯結構給出一種新的動態
2017-11-23 15:41:046 自然語言處理常用模型使用方法一、N元模型二、馬爾可夫模型以及隱馬爾可夫模型及目前常用的自然語言處理開源項目/開發包有哪些?
2017-12-28 15:42:305382 
在這篇文章中,我會介紹一篇最新的預訓練語言模型的論文,出自MASS的同一作者。這篇文章的亮點是:將兩種經典的預訓練語言模型(MaskedLanguage Model, Permuted
2020-11-02 15:09:362334 在自然語言處理任務中使用注意力機制可準確衡量單詞重要度。為此,提出一種注意力增強的自然語言推理模型aESM。將詞注意力層以及自適應方向權重層添加到ESIM模型的雙向LSTM網絡中,從而更有
2021-03-25 11:34:159 感謝清華大學自然語言處理實驗室對預訓練語言模型架構的梳理,我們將沿此脈絡前行,探索預訓練語言模型的前沿技術,紅框中為已介紹的文章,綠框中為本期介紹的模型,歡迎大家留言討論交流。 在之前的一期推送
2021-05-19 15:47:413355 
本文關注于向大規模預訓練語言模型(如RoBERTa、BERT等)中融入知識。
2021-06-23 15:07:313468 
golang的MPG調度模型是保障Go語言效率高的一個重要特性,本文詳細介紹了Go語言調度模型的設計。 前言 Please remember that at the end of the day
2021-07-26 10:12:431726 
NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力
2021-10-11 16:46:052226 
盡管巨型語言模型正在推動語言生成技術的發展,但它們也面臨著偏見和毒性等問題。人工智能社區正在積極研究如何理解和消除語言模型中的這些問題,包括微軟和 NVIDIA 。
2022-04-17 11:25:341946 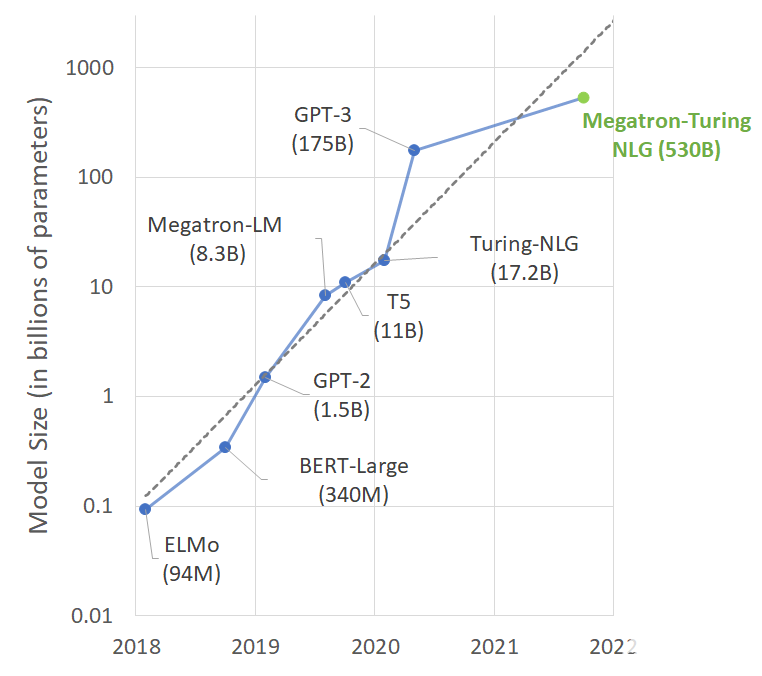
Facebook在Crosslingual language model pretraining(NIPS 2019)一文中提出XLM預訓練多語言模型,整體思路基于BERT,并提出了針對多語言預訓練的3個優化任務。后續很多多語言預訓練工作都建立在XLM的基礎上,我們來詳細看看XLM的整體訓練過程。
2022-05-05 15:23:492521 由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:271173 今天給大家帶來一篇IJCAI2022浙大和阿里聯合出品的采用對比學習的字典描述知識增強的預訓練語言模型-DictBERT,全名為《Dictionary Description Knowledge
2022-08-11 10:37:55866 NVIDIA NeMo 大型語言模型(LLM)服務幫助開發者定制大規模語言模型;NVIDIA BioNeMo 服務幫助研究人員生成和預測分子、蛋白質及 DNA
2022-09-22 10:42:29742 韓國先進的移動運營商構建包含數百億個參數的大型語言模型,并使用 NVIDIA DGX SuperPOD 平臺和 NeMo Megatron 框架訓練該模型。
2022-09-27 09:24:30915 輸入文本的要點; ? (2)模型過度依賴語言模型,生成流暢但不充分的單詞。 ? 在本文研究中,提出了一個忠實增強摘要模型(FES),旨在解決這兩個問題,提高抽象摘要的忠實度。對于第一個問題,本文使用問答(QA)來檢查編碼器是否完全掌握輸入文檔,并
2022-11-01 11:37:57692 另一方面,從語言處理的角度來看,認知神經科學研究人類大腦中語言處理的生物和認知過程。研究人員專門設計了預訓練的模型來捕捉大腦如何表示語言的意義。之前的工作主要是通過明確微調預訓練的模型來預測語言誘導的大腦記錄,從而納入認知信號。
2022-11-03 15:07:08707 (需要有Decoder部分,所以「不包括BERT這類純Encoder語言模型」),論文的核心貢獻是提出一套多任務的微調方案(Flan),來極大提升語言模型的泛化性。
2022-11-24 11:21:561040 我們提出了LiteVL,這是一種視頻語言模型,它無需大量的視頻語言預訓練或目標檢測器。LiteVL從預先訓練的圖像語言模型BLIP中繼承了空間視覺信息和文本信息之間已經學習的對齊。然后,我們提出
2022-12-05 10:54:49413 來自:圓圓的算法筆記 今天給大家介紹3篇EMNLP 2022中語言模型訓練方法優化的工作,這3篇工作分別是: 針對檢索優化語言模型 :優化語言模型訓練過程,使能夠生成更合適的句子表示用于檢索
2022-12-22 16:14:56679 InstaDeep、慕尼黑工業大學(TUM)和 NVIDIA 之間的合作推動了面向基因組學的多超級計算規模的基礎模型開發進程。這些模型在大量預測任務(例如啟動子和增強子位點預測)中展示了最先進的性能
2023-01-17 01:05:04444 BigCode 是一個開放的科學合作組織,致力于開發大型語言模型。近日他們開源了一個名為 SantaCoder 的語言模型,該模型擁有 11 億個參數
2023-01-17 14:29:53692 如果給語言模型生成一些 prompting,它還向人們展示了其解決復雜任務的能力。標準 prompting 方法,即為使用少樣本的問答對或零樣本的指令的一系列方法,已經被證明不足以解決需要多個推理步驟的下游任務(Chowdhery 等,2022)。
2023-02-02 16:15:26772 傳統的多模態預訓練方法通常需要"大數據"+"大模型"的組合來同時學習視覺+語言的聯合特征。但是關注如何利用視覺+語言數據提升視覺任務(多模態->單模態)上性能的工作并不多。本文旨在針對上述問題提出一種簡單高效的方法。
2023-02-13 13:44:05727 大型語言模型能識別、總結、翻譯、預測和生成文本及其他內容。 AI 應用在大型語言模型的幫助下,可用于解決總結文章、編寫故事和參與長對話等多種繁重工作。 大型語言模型(LLM)是一種深度學習算法,可以
2023-02-23 19:50:043887 最近圖靈獎得主Yann LeCun參與撰寫了一篇關于「增強語言模型」的綜述,回顧了語言模型與推理技能和使用工具的能力相結合的工作,并得出結論,這個新的研究方向有可能解決傳統語言模型的局限性,如可解釋性、一致性和可擴展性問題。
2023-03-03 11:03:20673 大型語言模型能識別、總結、翻譯、預測和生成文本及其他內容。
2023-03-08 13:57:006989 谷歌正在朝著構建支持1000種不同語言的人工智能語言模型的目標邁進……
2023-03-07 10:22:58466 
能力。從現場展示來看,文心一言某種程度上具有了對人類意圖的理解能力。但李彥宏也多次提及,這類大語言模型還遠未到發展完善的階段,進步空間很大。 百度同時公布了文心一言的邀請測試方案。3 月 16 日起,首批用戶即可通過邀請測試碼,在
2023-03-17 04:40:01604 Bloom是個多語言模型,由于需要兼容多語言,所以詞表有25w之多,在中文領域中,大部分詞表并不會被用到。我們通過刪減冗余的詞表,從多語言模型中提取常用的中英文詞表,最終詞表從25w減少到46145,縮減為原來的18.39%,在保留預訓練知識的同時,有效減少參數量,提高訓練效率。
2023-04-07 10:36:084319 在本文中,我們將展示如何使用 大語言模型低秩適配 (Low-Rank Adaptation of Large Language Models,LoRA) 技術在單 GPU 上微調 110 億參數的 FLAN-T5 XXL 模型。
2023-04-14 17:37:401503 基礎 LLM 基本信息表,GPT-style 表示 decoder-only 的自回歸語言模型,T5-style 表示 encoder-decoder 的語言模型,GLM-style 表示 GLM 特殊的模型結構,Multi-task 是指 ERNIE 3.0 的模型結構
2023-04-20 11:25:441071 對于任何沒有額外微調和強化學習的預訓練大型語言模型來說,用戶得到的回應質量可能參差不齊,并且可能包括冒犯性的語言和觀點。這有望隨著規模、更好的數據、社區反饋和優化而得到改善。
2023-04-24 10:07:062168 
GPT是基于Transformer架構的大語言模型,近年迭代演進迅速。構建語言模型是自然語言處理中最基本和最重要的任務之一。GPT是基于Transformer架構衍生出的生成式預訓練的單向語言模型,通過對大 量語料數據進行無監督學習
2023-04-28 10:01:59585 
近來NLP領域由于語言模型的發展取得了顛覆性的進展,擴大語言模型的規模帶來了一系列的性能提升,然而單單是擴大模型規模對于一些具有挑戰性的任務來說是不夠的
2023-05-10 11:13:171377 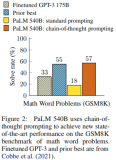
大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推理能力,但其只能處理文本數據。
2023-05-10 16:53:15701 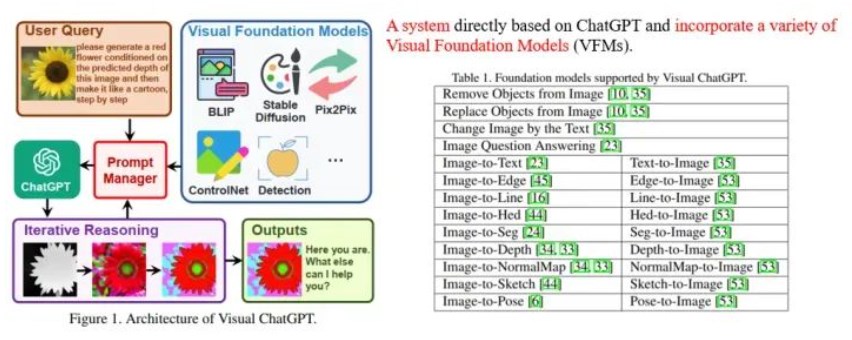
以ChatGPT為代表的大語言模型(Large Language Models, LLM)在機器翻譯(Machine Translation, MT)任務上展現出了驚人的潛力。
2023-05-17 09:56:26903 
電子發燒友網站提供《PyTorch教程9.3.之語言模型.pdf》資料免費下載
2023-06-05 09:59:000 9.3. 語言模型? Colab [火炬]在 Colab 中打開筆記本 Colab [mxnet] Open the notebook in Colab Colab [jax
2023-06-05 15:44:24268 
大型語言模型研究的發展有三條技術路線:Bert 模式、GPT 模式、混合模式。其中國內大多采用混合模式, 多數主流大型語言模型走的是 GPT 技術路線,直到 2022 年底在 GPT-3.5 的基礎上產生了 ChatGPT。
2023-06-09 12:34:533162 
在一些非自然圖像中要比傳統模型表現更好 CoOp 增加一些 prompt 會讓模型能力進一步提升 怎么讓能力更好?可以引入其他知識,即其他的預訓練模型,包括大語言模型、多模態模型 也包括
2023-06-15 16:36:11277 
本文旨在讓沒有計算機科學背景的人對ChatGPT和類似的人工智能系統(GPT-3、GPT-4、Bing Chat、Bard等)的工作原理有一些了解。ChatGPT是一種基于*大語言模型(Large Language Model)* 的對話式AI聊天機器人。
2023-06-16 09:59:041036 
本文旨在更好地理解基于 Transformer 的大型語言模型(LLM)的內部機制,以提高它們的可靠性和可解釋性。 隨著大型語言模型(LLM)在使用和部署方面的不斷增加,打開黑箱并了解它們的內部
2023-06-25 15:08:49991 
?? 大型語言模型(LLM) 是一種深度學習算法,可以通過大規模數據集訓練來學習識別、總結、翻譯、預測和生成文本及其他內容。大語言模型(LLM)代表著 AI 領域的重大進步,并有望通過習得的知識改變
2023-07-05 10:27:351463 7月6日,在世界人工智能大會WAIC上,墨芯人工智能發布了大模型算力方案的最新成果,宣告進入“千億”時代:墨芯AI計算平臺率先支持高達千億參數的大語言模型,并在吞吐、延時等多項指標上表現優異,創下
2023-07-07 14:41:17535 簡單來說,語言模型能夠以某種方式生成文本。它的應用十分廣泛,例如,可以用語言模型進行情感分析、標記有害內容、回答問題、概述文檔等等。但理論上,語言模型的潛力遠超以上常見任務。
2023-07-14 11:45:40454 
LLM(大語言模型)因其強大的語言理解能力贏得了眾多用戶的青睞,但LLM龐大規模的參數導致其部署條件苛刻;
2023-07-20 10:49:29655 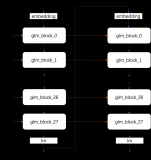
近日,清華大學新聞與傳播學院發布了《大語言模型綜合性能評估報告》,該報告對目前市場上的7個大型語言模型進行了全面的綜合評估。近年,大語言模型以其強大的自然語言處理能力,成為AI領域的一大熱點。它們
2023-08-10 08:32:01607 
? 本篇內容是對于ACL‘23會議上陳丹琦團隊帶來的Tutorial所進行的學習記錄,以此從問題設置、架構、應用、挑戰等角度全面了解檢索增強的語言模型,作為對后續工作的準備與入門,也希望能給大家帶來
2023-08-21 09:58:011234 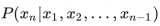
最近,AI大模型測評火熱,尤其在大語言模型領域,“聰明”的上限 被 不斷刷新。 商湯與上海AI實驗室等聯合打造的大語言模型“書生·浦語”(InternLM)也表現出色,分別在 智源FlagEval
2023-08-25 13:00:02315 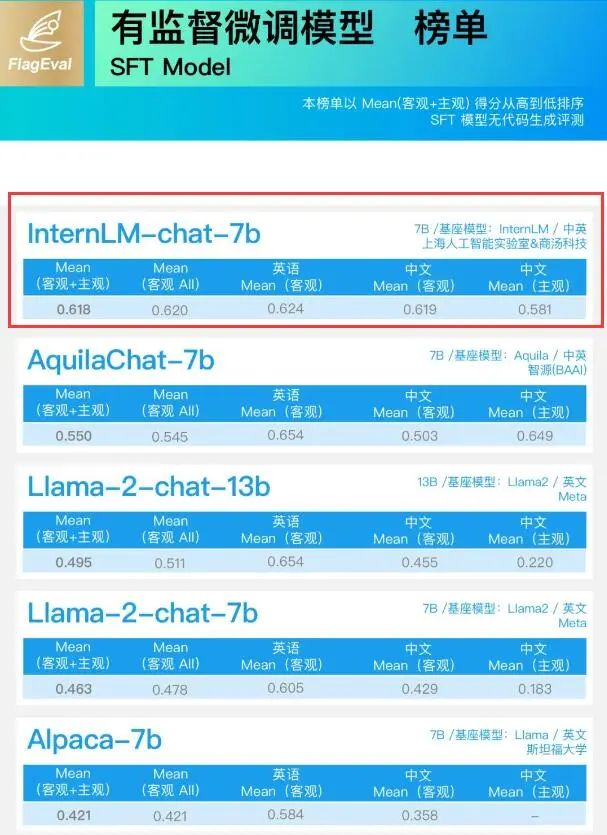
大語言模型的構建通常需要一個大規模的系統來執行該模型,這個模型會持續變大,在其發展到一定程度后,僅靠在CPU上的運行就不再具有成本、功耗或延遲的優勢了。
2023-08-31 15:34:36505 
生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰,以及GPU和網絡行業如何針對訓練的工作負載不斷優化硬件。
2023-09-01 17:14:561046 
作者:Bill Jenkins,Achronix人工智能/機器學習產品營銷總監 探索FPGA加速語言模型如何通過更快的推理、更低的延遲和更好的語言理解來重塑生成式人工智能 簡介:大語言模型 近年來
2023-09-04 16:55:25345 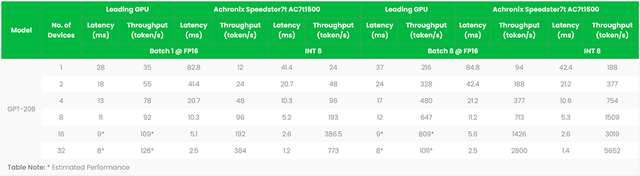
騰訊發布混元大語言模型 騰訊全球數字生態大會上騰訊正式發布了混元大語言模型,參數規模超千億,預訓練語料超2萬億tokens。 作為騰訊自研的通用大語言模型,混元大語言模型具有中文創作能力、任務執行
2023-09-07 10:23:54815 自ChatGPT發布以來,生成式AI在全球引起了新的浪潮,它影響著各行各業,為世界帶來智能化的發展。然而,類ChatGPT的大語言模型極度依賴算力巨大的服務器,導致目前大部分應用只能通過集中調用
2023-09-09 08:02:39952 
本文提出了新型的可控光照增強框架,主要采用了條件擴散模型來控制任意區域的任意亮度增強。通過亮度控制模塊(Brightness Control Module)將亮度信息信息融入Diffusion網絡中,并且設計了和任務適配的條件控制信息和損失函數來增強模型的能力。
2023-09-11 17:20:14384 
基礎模型和高性能數據層這兩個基本組件始終是創建高效、可擴展語言模型應用的關鍵,利用Redis搭建大語言模型,能夠實現高效可擴展的語義搜索、檢索增強生成、LLM 緩存機制、LLM記憶和持久
2023-09-18 11:26:49316 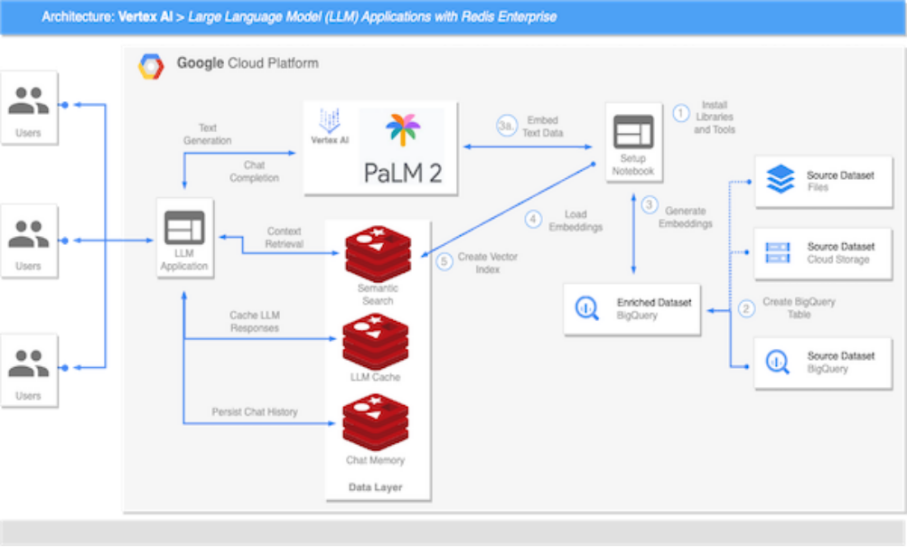
近來,大語言模型 (LLM) 已被證明是提高編程、內容生成、文本分析、網絡搜索及遠程學習等諸多領域生產力的可靠工具。
2023-10-19 09:13:57410 
Transformer 架構的問世標志著現代語言大模型時代的開啟。自 2018 年以來,各類語言大模型層出不窮。
2023-10-24 11:42:05337 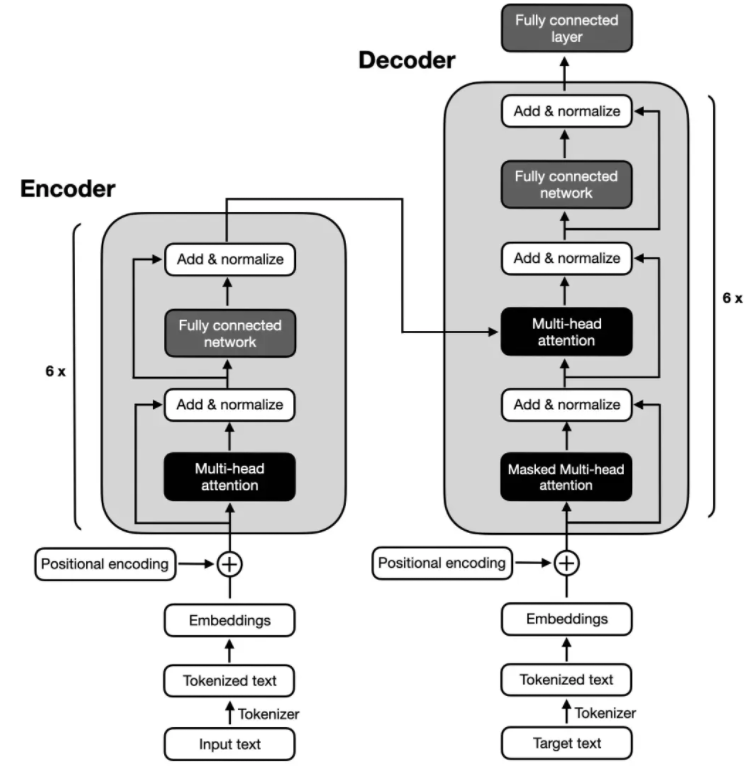
10 月 28 日,汽車行業大語言模型研討會正式結束。 NVIDIA 解決方案架構師陳文愷 在研討會中講解了 汽車行業如何開發企業級大語言模型,以加速行業創新和發展 。同時,NVIDIA 汽車行業
2023-11-03 19:10:03356 人工智能尤其是大型語言模型的應用,重塑了我們與信息交互的方式,也為企業帶來了重大的變革。將基于大模型的檢索增強生成(RAG)集成到業務實踐中,不僅是一種趨勢,更是一種必要。它有助于實現數據驅動型決策
2023-11-06 08:10:02216 
進一步地,提出了Cross-Lingual Self-consistent Prompting (CLSP),利用不同語言專家的知識和不同語言間更加多樣的思考方式,集成了多個推理路徑,顯著地提高了self-consistency的跨語言性能。CLSP 都能夠在CLP的基礎上更進一步地有效提高零樣本跨語言 CoT 性能。
2023-11-08 16:59:42261 
11月8日,2023年世界互聯網大會烏鎮峰會正式開幕,今年是烏鎮峰會舉辦的第十年,本次峰會的主題為“建設包容、普惠、有韌性的數字世界——攜手構建網絡空間命運共同體”。百度知識增強大語言模型關鍵技術
2023-11-09 11:02:49307 /算法/軟件工程師的人力投入和包括硬件在內的物力投入。那么在自己的環境中搭建智能搜索大語言模型增強方案是必不可少的。因此,本篇內容主要為大語言模型方案的快速部署。該方案部署流程并不復雜,只需要您對于亞馬遜云科技
2023-11-10 11:08:27404 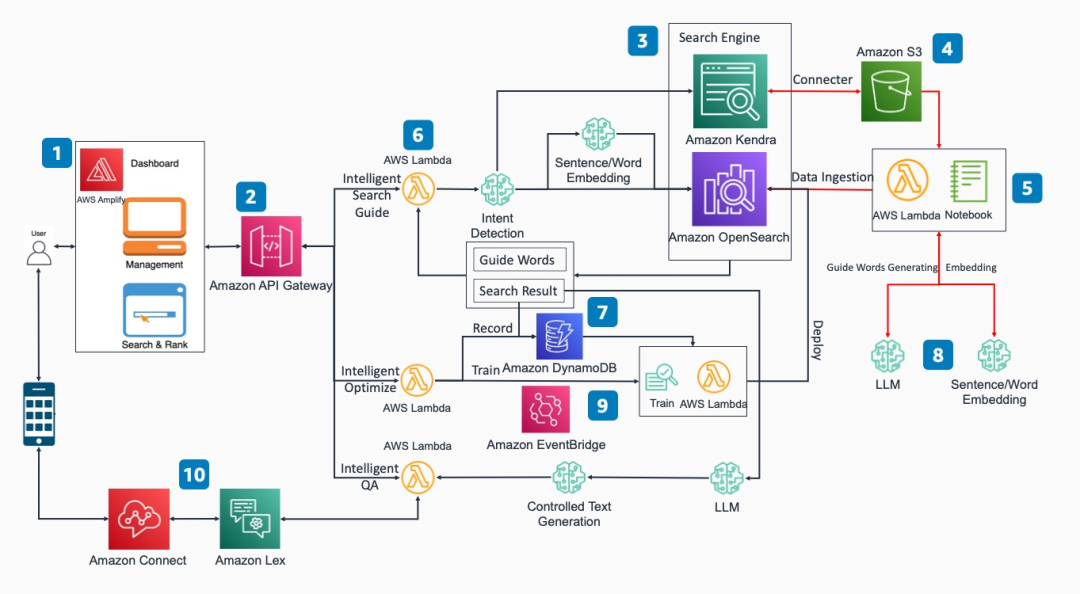
簡介章節講的是比較基礎的,主要介紹了本次要介紹的概念,即檢索(Retrieval)和大語言模型(LLM)
2023-11-15 14:50:36282 
本文基于亞馬遜云科技推出的大語言模型與生成式AI的全家桶:Bedrock對大語言模型進行介紹。大語言模型指的是具有數十億參數(B+)的預訓練語言模型(例如:GPT-3, Bloom, LLaMA)。這種模型可以用于各種自然語言處理任務,如文本生成、機器翻譯和自然語言理解等。
2023-12-04 15:51:46356 近年來,隨著科技的飛速發展,大語言模型成為人工智能領域的一顆璀璨明珠。在這個信息爆炸的時代,大語言模型以其強大的自學習能力和廣泛的應用領域引起了廣泛關注。作為亞馬遜云科技的前沿技術之一,本文將深入探討大語言模型的革新之處以及在實際應用中的嶄新可能性。
2023-12-06 13:57:13447 大規模語言模型(Large Language Models,LLM),也稱大規模語言模型或大型語言模型,是一種由包含數百億以上參數的深度神經網絡構建的語言模型,使用自監督學習方法通過大量無標注
2023-12-07 11:40:431141 
在科技飛速發展的當今時代,人工智能技術成為社會進步的關鍵推動力之一。在廣泛關注的人工智能領域中,大語言模型以其引人注目的特性備受矚目。 大語言模型的定義及發展歷史 大語言模型是一類基于深度學習技術
2023-12-21 17:53:59555 盡管基本的CoT提示策略在復雜推理任務中展示出了強大的能力,但它仍然面臨著一些問題,比如推理過程存在錯誤和不穩定等。因此,一系列的研究通過增強的提示方法激發大語言模型的能力,從而完成更通用的任務。
2023-12-27 14:19:04268 
在信息爆炸的時代,我們渴望更智能、更高效的語言處理工具。GPT-3.5等大語言模型的崛起為我們提供了前所未有的機會。這不僅是技術的進步,更是人與機器共舞的一幕。本篇文章將帶你走進這個奇妙的語言王國
2023-12-29 14:18:59276 最近復旦大學自然語言處理組鄭驍慶和黃萱菁團隊提出了基于表征工程(Representation Engineering)的生成式語言大模型人類偏好對齊方法RAHF(如圖1所示),作為基于人類反饋的強化
2024-01-03 14:25:50161 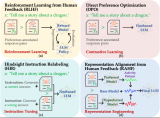
隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放,越來越多的開發者將大語言模型納入到他們的項目中。其中一個關鍵的適應步驟是將領域特定的文檔集成到預訓練模型中,這被稱為微調。
2024-01-04 12:32:39228 
近期的大語言模型(LLM)在自然語言理解和生成上展現出了接近人類的強大能力,遠遠優于先前的BERT等預訓練模型(PLM)。
2024-01-04 14:06:39139 
1月17日,商湯科技與上海AI實驗室聯合香港中文大學和復旦大學正式發布新一代大語言模型書?·浦語2.0(InternLM2)。
2024-01-17 15:03:57332 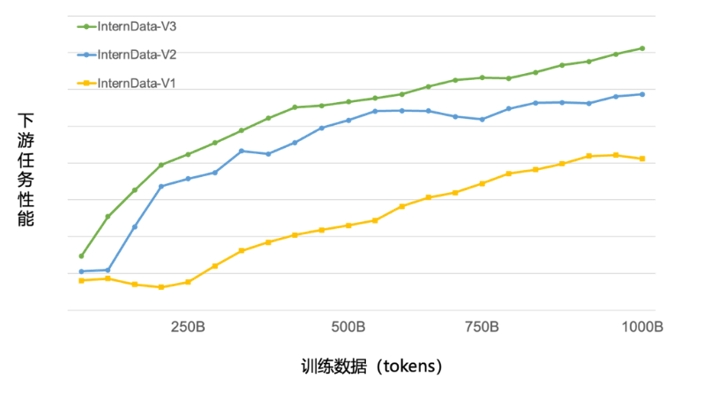
ByteDance Research 基于開源的多模態語言視覺大模型 OpenFlamingo 開發了開源、易用的 RoboFlamingo 機器人操作模型,只用單機就可以訓練。
2024-01-19 11:43:08106 
自然語言處理領域存在著一個非常有趣的現象:在多語言模型中,不同的語言之間似乎存在著一種隱含的對齊關系。
2024-02-20 14:53:0684 
研究者們提出了一個框架來描述LLMs在處理多語言輸入時的內部處理過程,并探討了模型中是否存在特定于語言的神經元。
2024-03-07 14:44:0260 
 電子發燒友App
電子發燒友App












 工商網監
工商網監
評論