 電子發燒友App
電子發燒友App


本篇文章主要介紹如何利用CUDA實現一個2D卷積算子,實現過程較為簡單,最終的實現效果可以在較小的尺寸下取得比cudnn快較大的性能。實測在以下參數配置下可以達到平均1.2倍cudnn的性能。
前言
CUDA介紹(from chatGPT)

現在深度學習大行其道,作為深度學習的基礎軟件設施,學習cuda也是很有意義的。本篇文章主要介紹如何利用CUDA實現一個2D卷積算子,實現過程較為簡單,最終的實現效果可以在較小的尺寸下取得比cudnn快較大的性能。實測在以下參數配置下可以達到平均1.2倍cudnn的性能(娛樂結果,還與cudnn配置有關,更小更快)。
TIPS: 跳過cudnn初始化的時間,99輪平均時間
????const?int?inC?=?6; ????const?int?inH?=?768; ????const?int?inW?=?512; ????const?int?kernelH?=?6; ????const?int?kernelW?=?6; ????const?int?outC?=?6; ????const?int?outH?=?inH?-?kernelH?+?1; ????const?int?outW?=?inW?-?kernelW?+?1
1 卷積操作通俗介紹
1.1 數據布局(data layout)
卷積操作主要針對圖像進行運算,我們常見的RGB即為三通道的二維圖像,那么就可以通過一個一維數組存儲所有的數據,再按照不同的布局去索引對應的數據,現在主要使用nchw和nhwc兩種數據布局,其中
n - batch size 也可以理解為"圖像"數量
c - channel num 即我們說的通道數量
h - height 圖像高度,每個通道的高度寬度是一致的
w - width 圖像寬度
那么顯然nchw就是逐個通道的讀取圖像,nhwc即對所有通道的同樣位置讀取數據后,再切換到下一個為止
一個是優先通道讀取,一個是優先位置讀取
還有一種CHWN布局,感覺比較奇怪,并未過多了解
詳細的可以參考英偉達官方文檔Developer Guide : NVIDIA Deep Learning cuDNN Documentation (https://docs.nvidia.com/deeplearning/cudnn/developer-guide/index.html)
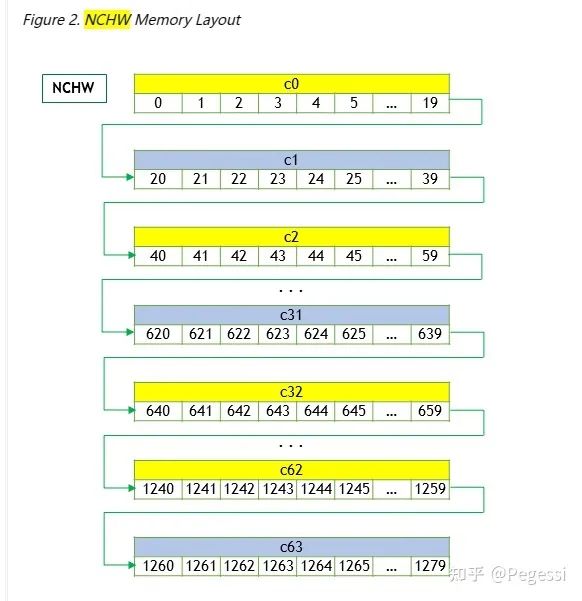
nchw layout
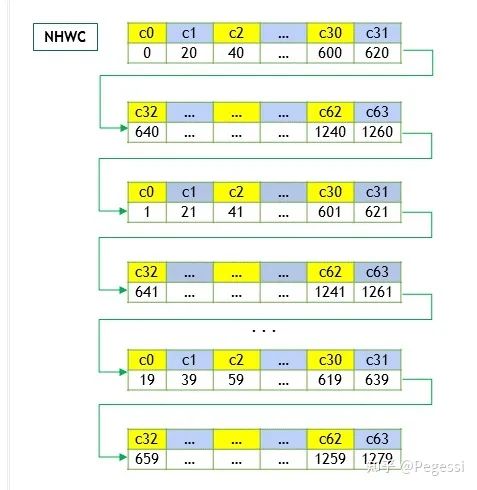
nhwc layout
本文是按照nchw數據格式來進行算子的實現的。
1.2 直接卷積
相信大家都或多或少聽過卷積,可以通過gpt的回答來直觀地認識卷積操作

最基本的直接卷積操作是十分簡單的,你可以想象一個滑動的矩陣窗口在原矩陣上移動,對應位置進行點積,得到結果后求和放到目標矩陣上,可以用以下圖像直觀地理解這一過程,向老師稱為對對碰:)
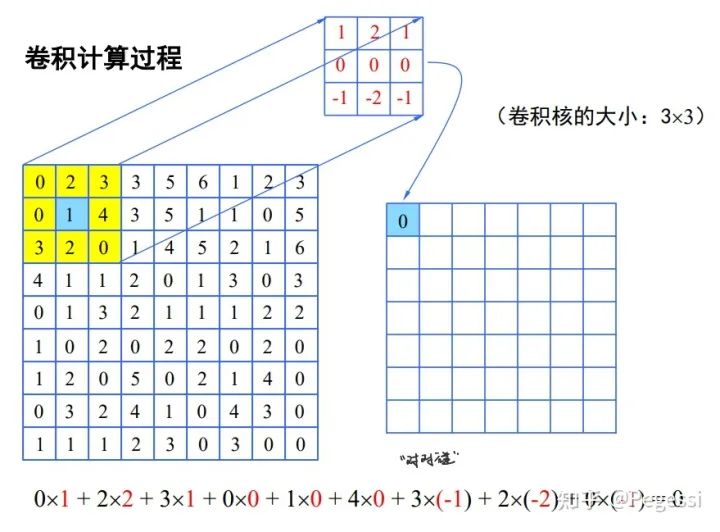
圖源:國科大模式識別課程
你會注意到上述過程中怎么沒有什么channel的參與,只有一個矩陣
多輸入通道的情況下,就是對每個通道的相同位置分別與卷積核進行對對碰,結果累加作為輸出矩陣值;
多輸入多輸出通道,即對每個輸出通道都進行上述操作
對于通道的理解建議參考[@雙手插袋]的文章CNN卷積核與通道講解 (https://zhuanlan.zhihu.com/p/251068800)
那么我們需要知道的是直接卷積操作其實就是原矩陣與卷積核間的對對碰,產生所謂的特征圖feature map,十分的簡單,這也方便我們對其進行并行任務劃分
注意到上述文章中并沒有提到padding和stride,本篇文章并沒有針對padding和stride的實現
padding
padding是作為對圖像的填充,可以發現上面的特征圖尺寸縮小了一圈,是因為直接卷積勢必會造成這一結果
通過padding可以加強圖像邊緣特征,避免邊緣特征被忽略
stride
stride可以簡單的理解為跨步,即上面的小窗口在矩陣上滑動的步長,默認為1
即上述圖像中下一次卷積的中心應該是4為中心的3*3子矩陣
如果你設置為2,那么下一次是3為中心的3*3子矩陣了
1.3 其他卷積計算方法
除去直接卷積,也有一些其他方法進行卷積,感興趣的讀者可以自行了解,僅舉以下幾例參考
Img2col
即把圖像展開為一個行向量組,卷積核/濾波器(kernel/filter)展開為一列或多列向量,轉化為矩陣乘去計算卷積結果
FFT method
利用傅里葉變換的頻域變換去做卷積,這樣做的優勢是計算量會小很多
Winograd Algorithm
也是一種將圖像變換到另外一個空間再去做運算再做變換得到結果,會減少很多乘法運算
2 整體實現思路
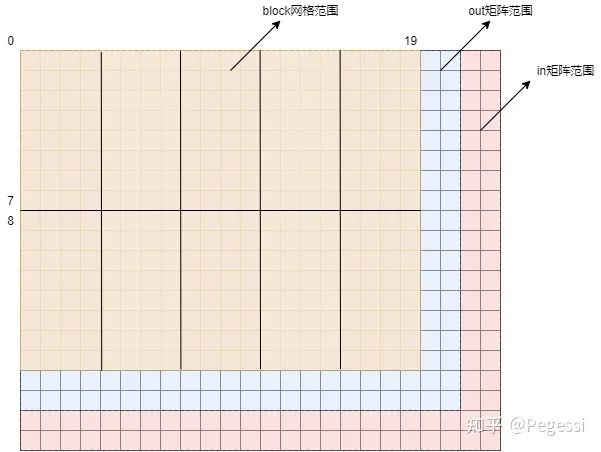
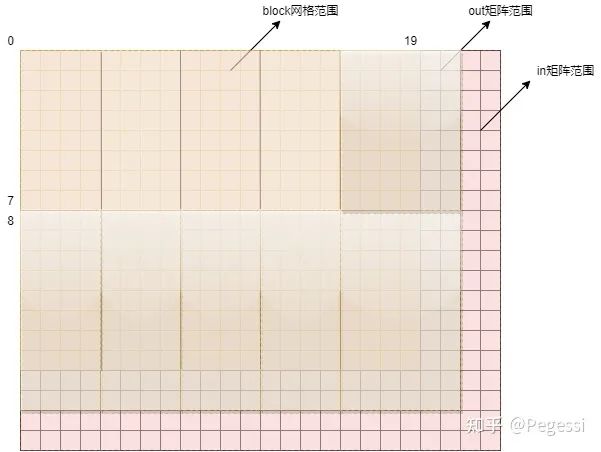
2.1 block與thread劃分
首先我們需要考慮如何對代表圖像的多通道矩陣來進行block與thread的劃分,這一部分是有說法的
不同的切分方式會讓block在SM上的流轉效率有很大的差別
本文僅提供一個十分草率的切分,我們都清楚目前在英偉達的GPU上,任務的調度最小單元是warp
一個warp以32個線程為一組,故通過8*4的block來進行矩陣的切分,每個block里共32個位置
這樣可以保證每個block上到SM時不用去與其他的block拼接線程,產生額外開銷
注意我這里用的是位置,并不是元素,32個線程,每個線程去負責一個位置的計算
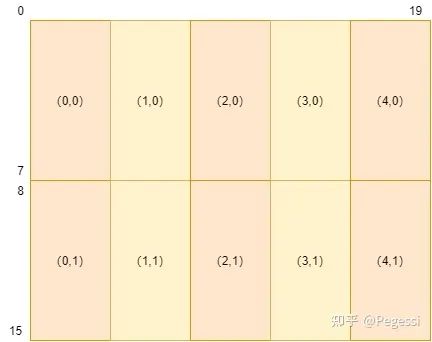
以16*20的矩陣為例,對其進行劃分的結果如下圖所示,(x,y)是笛卡爾坐標系,與行主序不同
2.2 數據轉移
關于位置和規模(size)
那么為什么說一個block有32個位置,而不是32個元素呢,首先注意到卷積操作雖然遍歷到了原矩陣的所有元素
但是你按中心點的位序去數的話(以卷積核3*3為例),結果應該是這個樣子
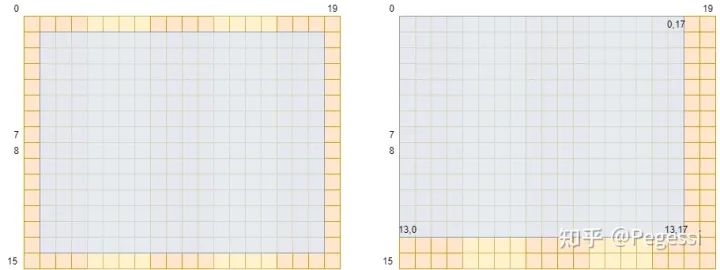
注意這里僅示意卷積中心點范圍,請與后文作區分
按3*3矩陣的中心來看,中心正好是去掉外面一圈的位置,按照左上角元素來看,恰好應該是(左上角,右下角)
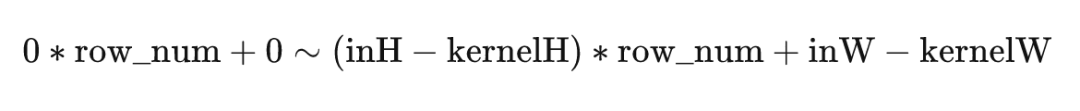
這樣一個區間,參數解釋如下
row_num 原矩陣中一行元素的數目
inH inW 原矩陣的H W
kernelH kernelW 卷積核的H W
outH outW 輸出矩陣的H W
當然你也可以用中心點而不是左上角的元素作為窗口的標識來設計算法
恰巧你上面算出來的這個范圍也正是你得到的feature map的下標范圍
我們也可以得到輸出矩陣的規模為
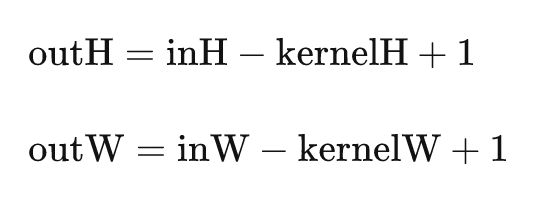
請注意大小和位置下標的區別,一個從1開始數一個從0開始數
一個block的數據轉移
確定了整體的尺寸,那么我們來看一個block需要的數據尺寸是多少呢
顯然你可以發現,對于輸出矩陣進行block劃分是更合理的,這樣可以保證一個block
32個位置恰好對應輸出矩陣的32個位置,而不用過多的去考慮輸出矩陣的排布
那么對于上述提到的劃分,可以通過下圖來直觀感受block劃分在原矩陣的效果
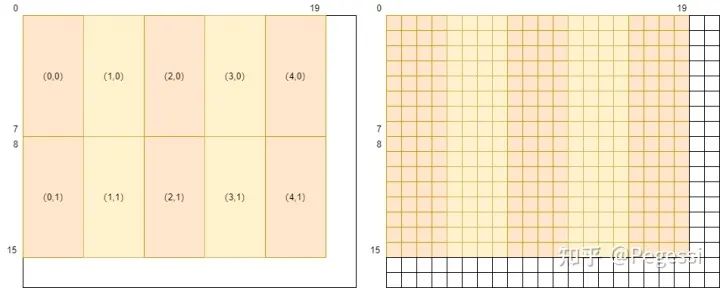
22*18的in產生20*16的out
那么一個block用到的元素范圍應該是哪些呢,我們要做的是卷積操作,每個中心點應該有對應卷積核大小的矩陣參與運算,那么以(0,0)和(4,1)的block為例,給出他們的涉及原矩陣范圍如下圖所示
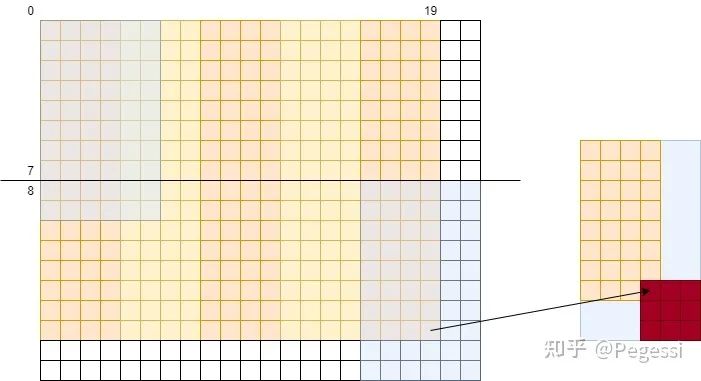
藍色為一個block需要用到的原矩陣元素
那么我們可以確定一個block,8×4的情況下需要讀取10×6的原矩陣的元素,也是+kernelH-1來確定的
那么對應輸出矩陣就是一個蘿卜一個坑了,不需要額外考慮
這樣就確定了一個block需要從GMEM到SMEM的元素范圍
至于怎么轉移,我們在代碼實現中講述,當然你可以單獨指定某幾個進程去完成所有的轉移任務
2.3 計算邏輯
不考慮channel
不考慮channel的情況下,即單輸入通道單輸出通道單卷積核這樣最簡單的情況
我們只需要做三件事
① 將block對應的數據轉移到SMEM中
② 利用線程的tid去計算對應輸出矩陣位置的結果
③ 將結果寫回輸出矩陣
只考慮inC
這種情況下我們要做的額外的事兒就多一點
加一層循環,讓每個線程計算多個in channel的數據,并累加起來作為結果
需要用到一個寄存器來存儲這個中間結果
考慮inC與outC
其實要做的事情也就比上面多一點,就是開大點空間
讓線程去存儲多個outC的中間結果,分別累加
最后寫回的時候也分別寫回即可
3 詳細實現過程
3.1 整體實現思路
主要從自己的角度出發去還原怎樣一步步構造出這樣一個初級的算法
首先實現一個最簡單的版本,CPU串行版本,并保證CPU串行版本可以獲取正確的結果
此后再在其基礎上進行并行化的改造,而直接卷積運算的過程其實相對是比較簡單的
我們在不考慮padding與stride的情況下,是可以不借助任何參考資料來直接完成第一版代碼的
3.1.1 CPU串行版本的卷積算子
?
?
#define?element_type?float #define?OFFSET(row,?col,?ld)?((row)?*?(ld)?+?(col)) /* ????@brief:?串行卷積實現?CPU代碼?NCHW ????@param?in?inC?inH?inW:?輸入矩陣(數組)?channel?height?width ????@param?out?outC?outH?outW:?輸出矩陣?channel?height?width ????@param?kernel?kernelH?kernelW:?卷積核?height?width */ void?serial_convolution(element_type?*in,?element_type?*out,?element_type?*kernel,?int?batch_size, ????????????????????????int?inC,?int?inH,?int?inW, ????????????????????????int?outC,?int?outH,?int?outW, ????????????????????????int?kernelH,?int?kernelW) { ????float?val; ????int?out_pos,?in_pos,?kernel_pos; ????for?(int?oc?=?0;?oc??
?
這是我最終完成的CPU串行版本代碼,可以發現套了足足有5層循環
在我們傳統觀念中,這可是 O(n5)O(n^5)O(n^5) 的最笨算法了
不過沒有關系,我們關注的并不是他的性能,cuda上也不會去跑這一版代碼
我們需要關注的是怎么樣能得到正確的結果,且如何設計循環的嵌套關系來使用盡量少的訪存次數
使用盡量多的本地中間結果,這樣可以盡可能地減少我們的算法在訪存方面的消耗
要明白GPU上的線程如果去讀GMEM上的數據需要幾百個時鐘周期,讀SMEM需要幾十個時鐘周期
讀取SM上的寄存器需要的時鐘周期會更少!
因此我們需要竭力優化的一部分是如何減少訪存,多用本地存儲來代替
另一方面這也是因為計算本身是十分簡單的點積,不太可能去做出更大的優化
3.1.2 循環順序設計
逐層去觀察循環的嵌套順序,發現是
outC-->H-->W--->inC-->kernelH-->kernelW
這樣的計算順序不一定是最優化的,筆者也沒有進行詳細的計算論證,但是這樣的計算順序是出于以下角度考慮
① 多通道卷積結果的維度/通道數/feature map數就是我們的outC,是我們最終要寫回的out矩陣的維度,將其放在最外層循環,作用是:
一次循環內完成這個out channel中的所有計算,再接著進行下一個outC的計算
由于out數據是在一維數組中存儲,且為nchw格式,那么不同outC中的數據跨度其實是很大的,連續的完成一個outC的內容可以更好的利用局部性原理
個人理解逐個outC的計算是很是一種比較直觀和自然(方便想象與理解)的角度
串行過程中我們可以使用盡量少的中間變量去維護中間結果,如果你先遍歷inC后遍歷outC的話,其實你是需要維護outC個中間變量的
這樣的順序也是在后面做并行化改造過程中逐漸發現的一個較為合理的順序,我們可以在后文中更加直觀的感受到這樣設計的優勢
② 出于nchw布局的涉及,H W的順序是基本固定的,當然你也可以先W后H,不過一般是行主序存儲.. 還是先H比較快一些
③ inC為何出現在H W之后?請回顧多通道卷積的過程,一個feature map的值是由多個inC與kernel分別點擊累加形成的,如果你將inC放置在H W之前的話,在下方的代碼中,你是不是就需要設置height×width個中間變量來存儲這里的val值呢?
in_pos?=?ic?*?inH?*?inW?+?OFFSET(i?+?ii,?j?+?jj,?inW); kernel_pos?=?oc?*?kernelH?*?kernelW?+?OFFSET(ii,?jj,?kernelW); val?+=?in[in_pos]?*?kernel[kernel_pos];將inC放置在H W之后,是相當于在一個outC上進行計算,對不同inC同樣的位置分別計算得到了val的準確值,最終寫回,這樣在串行的版本中,我們只需要一個float即可存儲好中間結果來避免空間的浪費!
TIPS:注意上方對于下標的計算,我們以兩個位序舉例說明
in_pos?=?ic?*?inH?*?inW?+?OFFSET(i?+?ii,?j?+?jj,?inW);
nchw的數據布局格式下,這里是默認n為1的,注意本文所有的實現都是建立在n假設為1的情況,其實n為更大值也不是很有意義,這樣的布局下,下一張圖像在計算意義上是沒有任何差別的,無非是你將數據的起始地址跳過一大部分,切到下一張圖像
說回這個式子,其中ic為in channel,inH inW分別是輸入矩陣的高度與寬度,后面宏定義的OFFSET其實就是簡略寫法,你也可以寫成(i+ii)*inW + j + jj
in_pos的含義是在當前循環變量下輸入矩陣的位置
同理,out_pos的計算是一樣的
out_pos?=?oc?*?outH?*?outW?+?OFFSET(i,?j,?outW);
ii和jj是相對于卷積核的相對位置循環變量,輸出位置是用不到他們的
進行并行化改造
其實當你把串行版本設計明白后,你對于并行化改造的想法也差不多有個七七八八了
主要是出于以下三個角度去設計并優化的
① 盡量減少訪存次數(當然不是不訪問),尤其是減少訪問GMEM的次數,善用SMEM與register
(對于GMEM SMEM和register等訪存層次相關知識不熟的讀者可以去了解一下CUDA的存儲層次)
② 此外要劃分明確各個線程要負責的任務區域和他的行為應達到的效果,做好下標計算
③ 計算行為是很快的,我們要盡可能去掩蓋訪存延遲,讓線程去火力全開計算(預取prefetch)
下面的章節都是在并行化改造過程中的一些細節,代碼其實是一版版寫出來的,這里是對最終版本進行說明
(所謂的一版版就是劃分出不同塊,分別測試是否與預期一致,再去完成下面的塊)
3.2 線程任務均分
這部分其實是源于 @有了琦琦的棍子 在GMEM講解中的數據轉移部分,基本算是照抄了
十分感謝前輩,不過還不知道這種方法的確切名字,目前暫時稱為均分,其實思想是很樸素的
我們的block設計的是8*4的大小,對應32個線程,但是涉及到in矩陣的數據可不只是32個元素,那么
我們需要盡可能地平均分配任務給線程,保證每個線程承擔差不多的任務量來達到更好的平均性能
差不多是因為,不太可能都是整除的情況
這部分主要通過圖示講解,自己設計的過程中大多是通過紙筆演算確定下標的
首先確定一些變量,注意CUDA的笛卡爾坐標系和筆者的行號row和列號col的區別
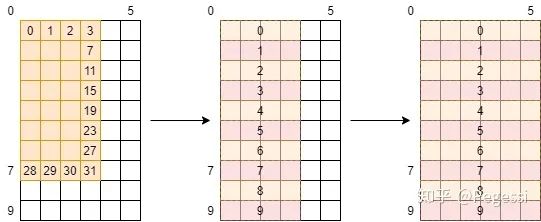
int?block_row?=?blockIdx.y; int?block_col?=?blockIdx.x; int?thread_row?=?threadIdx.y,?thread_col?=?threadIdx.x; int?tid?=?thread_row?*?threadW?+?thread_col;由于要重復使用inC內的數據,我們肯定是要開一個SMEM去存儲這部分數據的,那么就有一個GMEM->SMEM的數據轉移過程,以8×4的block和3×3的kernel為例,我們可以得到如下的景象
其中橙色部分是我們的block,一個tid(thread id)是一個線程,也是block中的一個位置,也是outC中的一個位置
那么白色部分就是我們在block范圍之外但會用到的數據,這部分數據可以看到像兩條網格
那么我們怎么把這些數據從GMEM轉移到SMEM呢,首先我們考慮(以下部分為自己笨拙的思考過程)
方案① 邊緣線程負責白色區域
橙色為僅負責自己的位置,紫色負責3個位置,紅色負責9個
看起來是不是好像也還行,只要我們通過thread_row和thread_col判斷一下當前進程是否在邊緣
對這些進程進行單獨的編碼就可以了,不過在寫代碼前可以先算一筆賬
這個網格共有10×6=60個元素,我們有32個線程,那么最好的情況下,是每個線程負責
60/32=1.875個元素,也就是花費1.875個單位時間(這里的單位時間是抽象概念,假定為每個線程處理每個元素的時間)
那么可以看一下這種劃分方式下,每個線程平均負責的元素為
后面的項是權重,前面的項如??說明這個線程處理9個線程,那么花費的時間應當是9倍,所以性能應當是九分之一(相當于只處理一個元素的線程),且線程是warp調度的,32個線程里面有這么一個拖后腿分子,想必并行情況下整體花費時間是取決于這個31號線程的
這個方案的效率是理想情況的一半都不到,說明這種方案是不太可行的,寫出來效果也不一定好呢,換!
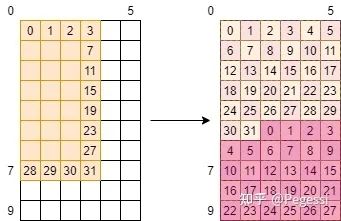
方案② 平均劃分
其實筆者也想過一些其他奇怪的方法,但是感覺平均思想似乎是最佳的,那么何不一步到胃呢?
我們先來定義一些變量,后面再來逐步解釋
//?分塊邊界?boundary是限制正常范圍?edge是需要補的范圍 int?row_boundary?=?outH?/?BLOCK_HEIGHT?-?1, ????col_boundary?=?outW?/?BLOCK_WIDTH?-?1; int?row_edge?=?outH?%?BLOCK_HEIGHT,?col_edge?=?outW?%?BLOCK_WIDTH; ··· int?single_trans_ele_num?=?4;???????????????????????????????//?線程一次轉移的數據數 int?cur_in_block_height?=?BLOCK_HEIGHT?+?KERNEL_HEIGHT?-?1,?//?讀入in的block?height ????cur_in_block_width?=?BLOCK_WIDTH?+?KERNEL_WIDTH?-?1,????//?讀入in的block?width ????in_tile_thread_per_row,?????????????????????????????????//?以tile為單位轉移數據,一行需要的thread數 ????in_tile_row_start,??????????????????????????????????????//?tile的行起始位置 ????in_tile_col,????????????????????????????????????????????//?tile的列 ????in_tile_row_stride;?????????????????????????????????????//?tile行跨度 //?修正邊緣block尺寸 if?(block_row?==?row_boundary) { ????cur_in_block_height?=?BLOCK_HEIGHT?+?row_edge?+?kernelH?-?1; } if?(block_col?==?col_boundary) { ????cur_in_block_width?=?BLOCK_WIDTH?+?col_edge?+?kernelW?-?1; } in_tile_thread_per_row?=?cur_in_block_width?/?single_trans_ele_num; in_tile_row_start?=?tid?/?in_tile_thread_per_row; in_tile_col?=?tid?%?in_tile_thread_per_row?*?single_trans_ele_num; in_tile_row_stride?=?thread_num_per_block?/?in_tile_thread_per_row;3.2.1 “block”設計與修正
不要急著頭大,我們逐個說明,首先看頂頭部分的變量,是關于限制范圍的
因為我們要首先確定一個block內的線程要負責多少元素呢,因此需要界定這樣的范圍
我們前面只提到了block涉及到的in范圍是擴大了一圈的,其實你的in矩陣相對于out矩陣也是多了一圈的
當多的這么一圈不能構成新的block時,那么注定我們的block網格是不能覆蓋到out矩陣的!
我們還是上圖比較直觀
咱們的block網格只有16×20這么大,out矩陣有18×22這么大,明顯可以看到藍色的兩條
是不足以構成新的block的,那么還有紅色的部分,就是in矩陣的大小了,可以看到有20×24這么大
而我們的block是建立在out矩陣上的,所以我們起碼也要覆蓋到藍色矩陣的所有范圍吧
那么在不修改block尺寸的情況下,最簡單的方法就是人為地去修正這些特定block的大小啦
修正后的block應該是這個樣子的
修正后的block把out全覆蓋了~
怎么修正呢?無非就是利用block位序去判斷并修改尺寸啦,即這兩行代碼
//?修正邊緣block尺寸 if?(block_row?==?row_boundary) { ????cur_in_block_height?=?BLOCK_HEIGHT?+?row_edge?+?kernelH?-?1; } if?(block_col?==?col_boundary) { ????cur_in_block_width?=?BLOCK_WIDTH?+?col_edge?+?kernelW?-?1; }結合圖片,是不是這些變量的概念就清晰了起來
注意我們所有變量都是有一個in的標識,這是標注in矩陣的范圍
out矩陣的劃分自然是有out的標識,且步驟都是一樣的,只不過需要補的范圍不太一樣罷了
3.2.2 線程行為指定
還有一段代碼我們沒有解釋,是這一段(thread_num_per_block本文默認為32,沒有修改)
in_tile_thread_per_row?=?cur_in_block_width?/?single_trans_ele_num; in_tile_row_start?=?tid?/?in_tile_thread_per_row; in_tile_col?=?tid?%?in_tile_thread_per_row?*?single_trans_ele_num; in_tile_row_stride?=?thread_num_per_block?/?in_tile_thread_per_row;這段我覺得是最抽象的部分也恰恰是最為精華的設計,首先要明確,是通過行里面的小片/tile作為線程處理的最小單元來進行設計的
其實變量名已經做了一部分的解釋,可以大概解釋為如下的含義
in_tile_thread_per_row 一行里面會有多少個tile
in_tile_row_start 當前線程負責的tile的起始行號
in_tile_col 當前線程負責的列號
in_tile_row_stride 如果還有元素要處理,那么需要跳過的行數/stride好像不是那么的直觀,我們再上一張圖
左面是我們的block與in矩陣的關系,我們要把他都轉移過來,且利用了fetch_float4的向量指令(也是single_trans_ele_num設置為4的原因)
以7號線程為例,當前的in_block為10×6大小,那么上面四個變量的值分別為1,7,0,32
這個例子比較簡單,可以發現一行其實是有一個半的tile的,那么需要一點點小小的修正來讓每個線程
讀取4+2個元素,這點小小的修正我們可以看代碼
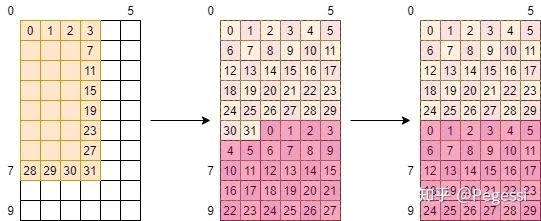
那么再來一個復雜的例子,假設我們在考慮out矩陣的事情,那么一個線程負責一個元素的話
請問這種方式對嘛?
是不是直觀上你感覺應該是這樣的,他可以絲滑的銜接好每個元素,完成我們的分配~
那么給出我們利用這個均分思想讓每個線程負責任務的代碼如下,大家再想一想分配后的圖像
for?(int?i?=?0;?i?淺淺一個for循環,只不過所有條件都是我們仔細設計的,循環內部就是每個線程根據這些位序
去對應的顯存位置上對數據一通操作罷了
那么注意部分,線程在跨過一個stride時,這個單位是不是row?那么意味著0號線程在下次任務會踩到30號的位置!如下圖所示
實際上的線程分配
這樣才是正確的線程操作順序,當然由于我們是通過CUDA并行計算的,實際上上半部分是并行的,下半部分是在0-29號線程完成了上面的任務后才進行計算的(注意他們是32個一組/warp調度上來執行的)
這樣其實有個小隱患,30號和31號以及0,1號會對這兩個位置上重復進行操作,如果他們的行為不一致的話
會導致我們的結果出錯,本例中他們的行為是一致的,故無所謂先后
通過這樣的機制,我們可以指定每個線程負責的元素位置以及個數(tile大小),靈活地應用于不同的任務!
3.3 預取機制
這部分就是很基本的數據預取,計算的效率遠遠大于訪存,計算時讀取數據進來,完成基本的運算
(復雜運算也不是一行代碼可以解決的)
再把結果存到對應位置,我們發現是不是即使是計算你也需要訪存,節省訪存開銷是十分重要的
整體的數據傳輸邏輯是GMEM->SMEM->register->GMEM->MEM
并沒有使用到Constant Memory和Texture Memory,那么結合數據預取的機制下
整體的框架如下方偽代碼所示
初始化我們所需要的所有變量并修正block規模; 分配好shared?memory用于加速訪存; //?預讀取第一個channel的數據 for?(int?i?=?0;?i?=?0?&&?thread_row?到這里其實我們就完成了大部分內容了,整體骨架就是這樣,其余就是一些細節上的下標計算問題了
3.4 一些雜項卻又需要細節
3.4.1 中間結果存儲設計
可以看到我們的偽代碼中循環順序是先oc再ic
可以想象一下,如果你先ic再oc的話,這樣確實是我們只需要遍歷一遍ic,oc多次遍歷
但是我們也要考慮寫回部分,寫回你還需要單獨再去寫,理論上先ic的話會快一些
這里就不給大家放圖了,讀者可以自己想象一下兩種計算順序的區別
需要注意的是
線程能利用的硬件資源是有限的,一個warp共用一個SM上的寄存器,具體到每個線程大概32-255個寄存器(來源于chatGPT,不嚴謹,需要核實,后面gpt又說v100一個線程可以用800個..)
總之我們還是能少用就少用幾個
當register存不下我們這些中間變量,就會放到local memory中
所謂的local memory是位于GMEM上的,如果發生這種情況,每次讀取中間結果
你還得跑到GMEM上去訪存,是非常之浪費時間的
兩種循環其實需要的register數目都是oc×2(2是因為你一個線程要負責好幾個位置的)
出于修正考慮,哥們兒直接開4倍,保證不會越界
3.4.2 下標計算
這部分其實,你串行算的明白,你并行就算的明白,我們舉幾個例子來說明一下
FETCH_FLOAT4(load_reg[0])?= ????????????FETCH_FLOAT4(in[begin_pos?+?OFFSET(in_tile_row_start?+?i,?in_tile_col,?inW)]); s_in[in_tile_row_start?+?i][in_tile_col]?=?load_reg[0]; s_in[in_tile_row_start?+?i][in_tile_col?+?1]?=?load_reg[1]; s_in[in_tile_row_start?+?i][in_tile_col?+?2]?=?load_reg[2]; s_in[in_tile_row_start?+?i][in_tile_col?+?3]?=?load_reg[3];這里是利用向量指令去一次讀取4個32位數據,s_in是開在SMEM上的,in是GMEM上的一位數據
那么可以看這個后面的下標
begin_pos 代表當前block的起始位序
OFFSET 是一個宏定義,代表行×一行元素數目
in[xxx] 下標其實就是當前block位置+block內的位置再看一個寫入中間結果的位置
temp_pos?=?i?/?out_tile_row_stride?+?j?+
???????????????????????????????oc?*?(cur_out_block_height?/?out_tile_row_stride?+?1);這里要考慮到線程是在計算它負責的第幾個元素,那么就要用i / out_tile_row_stride來判斷
如果處理多個元素,那你還得用j來控制一下當前是第幾個元素
還要考慮到不同的oc,一個oc內負責的元素有cur_out_block_height / out_tile_row_stride +1這么多個
我們再看一個
out_pos?=?oc?*?outH?*?outW?+
??????????block_row?*?BLOCK_HEIGHT?*?outW?+?block_col?*?BLOCK_WIDTH?+ ??????????OFFSET(out_tile_row_start?+?i,?out_tile_col?+?j,?outW);首先略過幾個oc的范圍,再計算當前block的起始位置,再計算上block內的相對位置
每個下標都要明白其計算的含義,本例中有很多公共表達式沒有提取出來提前計算,會影響一定性能
3.6 性能測試
雖然是娛樂測試,但是也嚴謹一點,可以發現這個代碼會受channel數目影響很大
代碼還有一點小bug,不過不影響你執行,大家可能會發現(亟待修復)
不同數據規模下性能在cudnn的1/10到10倍上下橫跳,有空給大家測一下放個完整的圖。
編輯:黃飛
?










 工商網監
工商網監
評論