 電子發(fā)燒友App
電子發(fā)燒友App


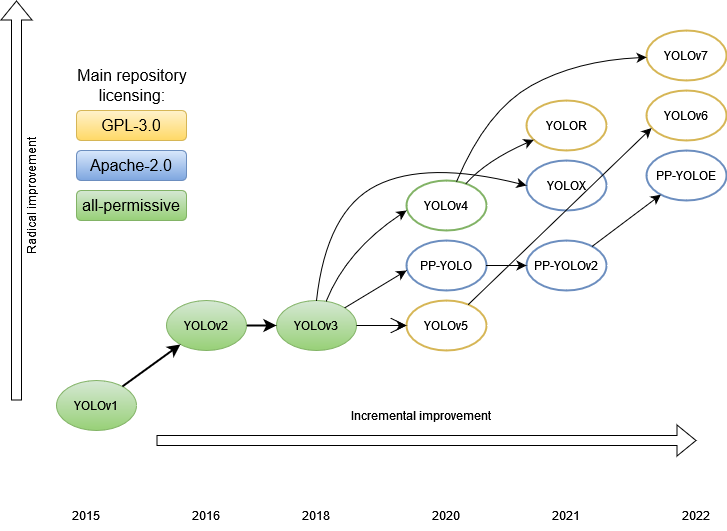
經(jīng)典再回顧,本文介紹v1到v3。
如果你需要速度快的目標(biāo)檢測器,那么 YOLO 系列的神經(jīng)網(wǎng)絡(luò)模型實際上是當(dāng)今的標(biāo)準(zhǔn)。
解決檢測問題還有很多其他優(yōu)秀的模型,但我們不會在這篇綜述中涉及它們。
目前,已經(jīng)寫了相當(dāng)多的文章來分析 YOLO 各個版本的功能。本文的目的是對整個家族進行比較分析。我們想看看架構(gòu)的演變,這樣我們就可以更好地了解檢測器是如何發(fā)展,哪些發(fā)展提高了性能,也許還可以想象事情的發(fā)展方向。
在YOLO出現(xiàn)之前,檢測圖像中目標(biāo)的主要方法是使用各種大小的滑動窗口按順序穿過原始圖像的各個部分,以便分類器給出圖像的哪個部分包含哪個目標(biāo)。這種方法是合乎邏輯的,但非常慢。
一段時間之后,出現(xiàn)了一個特殊的部分,它暴露了感興趣的區(qū)域 —— 一些假設(shè),圖像上可能有有趣的東西。但是這些感興趣區(qū)域還是太多,有數(shù)千個。最快的算法,F(xiàn)aster R-CNN,平均在0.2秒內(nèi)處理一張圖片,每秒5幀。總的來說,在出現(xiàn)一種全新的方法之前,速度不容樂觀。
有什么新奇之處?
在以前的方法中,原始圖像的每個像素可以被神經(jīng)網(wǎng)絡(luò)處理數(shù)百甚至數(shù)千次。每次這些像素都通過相同的神經(jīng)網(wǎng)絡(luò)傳遞,經(jīng)過相同的計算。是否可以做一些事情以免重復(fù)相同的計算?
事實證明,這是可能的。但為此,我們不得不稍微重新表述問題。如果說以前它是一個分類任務(wù),那么現(xiàn)在它變成了一個回歸任務(wù)。
YOLO aka YOLOv1
讓我們考慮第一個 YOLO 模型,也稱為 YOLOv1。
作者
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
主要論文
“You Only Look Once: Unified, Real-Time Object Detection”, publication date 2015/06
性能比較
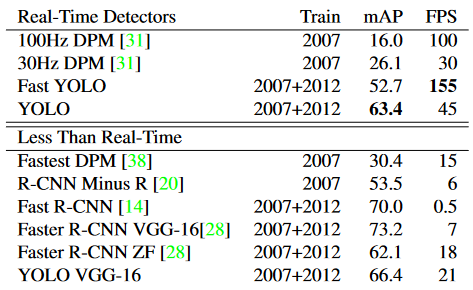
Pascal VOC 2007上的實時系統(tǒng)。YOLO是有記錄以來最快的Pascal VOC檢測檢測器,其準(zhǔn)確性仍然是任何其他實時檢測器的兩倍。
結(jié)構(gòu)
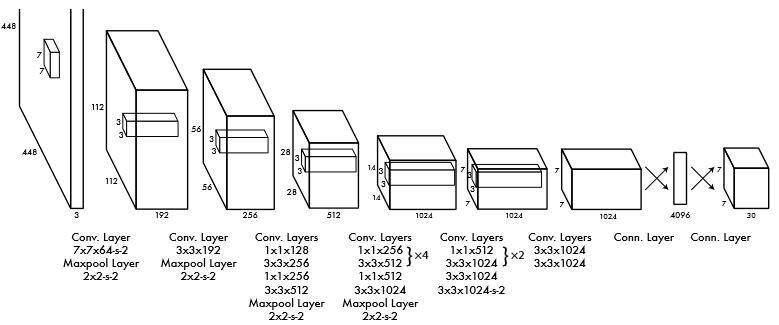
在結(jié)構(gòu)上,YOLO 模型由以下部分組成:
input ― 輸入圖像被饋送到的輸入層
backbone — 輸入圖像以特征形式編碼的部分。
neck — 這是模型的其他部分,用于處理按特征編碼的圖像
head — 生成模型預(yù)測的一個或多個輸出層。
該網(wǎng)絡(luò)的第一個版本基于GoogLeNet的架構(gòu)。卷積層接MaxPool層級聯(lián),最后以兩個全連接層的級聯(lián)作為結(jié)束。
此外,作者訓(xùn)練了Fast YOLO架構(gòu)的更快版本,包含更少的卷積層(9而不是24)。兩個模型的輸入分辨率均為 448x448,但網(wǎng)絡(luò)主要部分的預(yù)訓(xùn)練通過分辨率為 224x224 的分類器訓(xùn)練。
在此結(jié)構(gòu)中,原始圖片被劃分為 S x S 單元格(在原始 7 x 7 中),每個單元格預(yù)測 B 個邊界框,這些 bbox 中存在目標(biāo)的置信度,以及 C 類的概率。每條邊的單元格數(shù)是奇數(shù),因此圖像的中心有一個單元格。這比偶數(shù)具有優(yōu)勢,因為照片的中心通常有一個主要目標(biāo),在這種情況下,主要的預(yù)測是在中心單元格中進行的。在區(qū)域數(shù)量為偶數(shù)的情況下,中心可能位于四個中央?yún)^(qū)域中的某個位置,這降低了網(wǎng)絡(luò)的置信水平。
置信度值表示模型對給定 bbox 包含某個目標(biāo)的置信度,以及 bbox 預(yù)測其位置的準(zhǔn)確度。事實上,這是IoU存在物體概率的乘積。如果單元格中沒有目標(biāo),則置信度為零。
每個 bbox 由 5 個數(shù)字組成:x、y、w、h 和置信度。(x, y)為單元格內(nèi) bbox 中心的坐標(biāo),w 和 h為 bbox相對于整個圖片尺寸的歸一化的寬度和高度,即歸一化從 0 到 1 的值。置信度是預(yù)測的 bbox 和GT框之間的 IoU。每個單元格還預(yù)測目標(biāo)類的 C 個條件概率。每個單元格僅預(yù)測一組類別,而不考慮 bbox的數(shù)量。
因此,在一次前向中,預(yù)測了 S×S×B個包圍框。他們中的大多數(shù)框的置信度都很低,但是,通過設(shè)置一定的閾值,我們可以去除其中的很大一部分。但最重要的是,(與競爭對手相比)檢測率提高了幾個數(shù)量級。這是非常合乎邏輯的,因為所有類別的所有 bbox 現(xiàn)在只需一次預(yù)測。對于不同的實現(xiàn),原始文章給出了從 45 到 155 的FPS。盡管與以前的算法相比,mAP的準(zhǔn)確性仍然有所下降,但在某些問題中,實時檢測更為重要。
得到檢測框
由于與物體中心相鄰的單元格也可以產(chǎn)生bbox,從而導(dǎo)致框過多,因此有必要選擇其中最好的。為此,使用NMS技術(shù),其工作原理如下。此類的所有 bbox,置信度低于給定閾值的那些將被丟棄。對于其余部分,執(zhí)行IoU的成對比較過程。如果兩個框的 IoU > 0.5,則丟棄置信度較低的框。否則,兩個框都會保留在列表中。因此,類似的框被抑制了。
損失函數(shù)是組合的,具有以下形式:
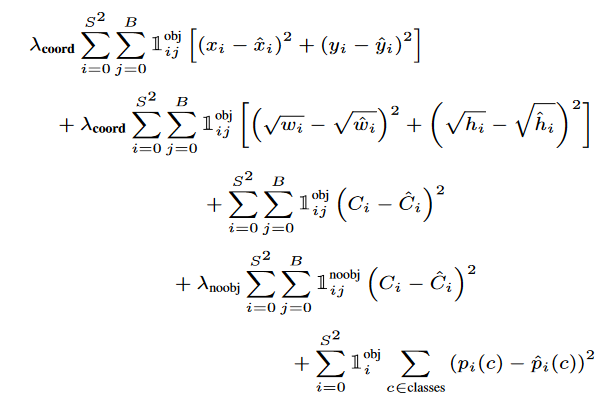
第一項是目標(biāo)中心坐標(biāo)的損失,第二項是框尺寸的損失,第三項是目標(biāo)的類損失,如果目標(biāo)不存在,則第四項是類的損失,第五項是在框中找到某個目標(biāo)的概率。
需要 lambda 系數(shù)來防止置信度變?yōu)榱悖驗榇蠖鄶?shù)單元格中沒有目標(biāo)。1(obj,i)?表示的中心是否出現(xiàn)在單元格 i 中,1(obj,i,j)?表示單元格 i 中的第 j 個 bbox 負(fù)責(zé)此預(yù)測。
優(yōu)勢
高速
比當(dāng)時的競爭對手更好的泛化能力,在另一個領(lǐng)域進行測試(訓(xùn)練是在ImageNet上進行的)顯示出更好的性能。
圖像背景部分的誤報更少。
局限性
每個單元格 2 個 bbox 和一個類目標(biāo)的限制。這意味著一堆小物體的識別度較低。
原始圖像的幾個連續(xù)下采樣導(dǎo)致精度不高。
損失的設(shè)計方式是,它對大框和小框的錯誤具有同樣懲罰。作者試圖通過取尺寸大小的根來補償這種影響,但這并沒有完全消除這種影響。
YOLOv2 / YOLO9000
作者
Joseph Redmon, Ali Farhadi
主要論文
“YOLO9000: Better, Faster, Stronger”, publication date 2016/12
性能比較
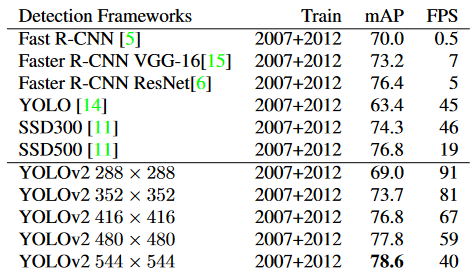
Pascal VOC 2007的檢測框架。YOLOv2 比以前的檢測方法更快、更準(zhǔn)確。它還可以以不同的分辨率運行,以便在速度和準(zhǔn)確性之間輕松權(quán)衡。每個 YOLOv2 條目實際上是具有相同權(quán)重的相同訓(xùn)練模型,只是以不同的大小進行評估。所有計時信息均在 Geforce GTX Titan X 上測試。
結(jié)構(gòu)特點
作者對模型的第一個版本進行了一些改進。
刪除了 dropout,并在所有卷積層中添加了BN。
預(yù)訓(xùn)練為分辨率為 448x448 的分類器(YOLOv1 分辨率為 224x224),然后將最終網(wǎng)絡(luò)縮小到 416x416 輸入,以產(chǎn)生奇數(shù)個 13x13 單元。
刪除了全連接層。相反,他們開始使用全卷積和錨框來預(yù)測bbox(如Faster RCNN)。這樣可以減少空間信息的丟失(就像在 v1 中的全連接層中一樣)。
刪除了一個最大池化以增加特征的細(xì)節(jié)(分辨率)。在 v1 中,每張圖片只有 98 個 bbox,使用 V2 中的錨點,結(jié)果有超過 1000 個 bbox,而 mAP 略有下降,但召回率顯著增加,這使得提高整體準(zhǔn)確性成為可能。
維度先驗。bbox的大小和位置不是像FasterRCNN那樣隨機手動選擇的,而是通過k-means聚類自動選擇的。盡管在小bbox上使用具有歐氏距離的標(biāo)準(zhǔn)k均值,但檢測誤差更高,因此對于k均值,選擇了另一個距離度量,1 - IoU(box,質(zhì)心)。選擇5個作為分組數(shù)目的折衷方案。測試表明,對于以這種方式選擇的 5 個質(zhì)心,平均 IoU 與 9 個錨點大致相同。
直接位置預(yù)測。最初,對于錨,與確定中心(x,y)坐標(biāo)相關(guān)的網(wǎng)絡(luò)訓(xùn)練存在不穩(wěn)定性:由于網(wǎng)絡(luò)權(quán)重是隨機初始化的,并且坐標(biāo)預(yù)測是線性的,大小是沒有限制的。因此,我們沒有預(yù)測相對于錨中心的偏移量,其中系數(shù)的正確范圍是 [-1,1],而是決定預(yù)測 bbox 相對于單元格中心的偏移,范圍 [0,1],并使用 sigmoid 來限制它。網(wǎng)絡(luò)為每個單元格預(yù)測 5 個 bbox,每個 bbox 5 個數(shù)字:tx、ty、tw、th、to。bbox 的預(yù)測參數(shù)計算如下:
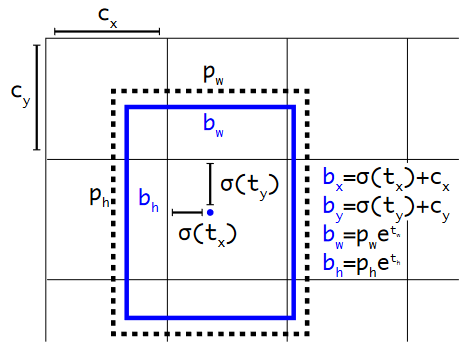
具有維度先驗和位置預(yù)測的邊界框。我們將框的寬度和高度預(yù)測為聚類質(zhì)心的偏移量。我們使用 sigmoid 函數(shù)預(yù)測框相對于中心坐標(biāo)的偏移。
細(xì)粒度特征。特征映射現(xiàn)在為 13x13。
多尺度訓(xùn)練。由于網(wǎng)絡(luò)是全卷積的,因此只需更改輸入圖像的分辨率即可動態(tài)更改其分辨率。為了提高網(wǎng)絡(luò)的魯棒性,其輸入分辨率每 10 批次更改一次。由于網(wǎng)絡(luò)縮小了 32 倍,因此輸入分辨率是從集合 {320, 352, ..., 608} 中選擇的。網(wǎng)絡(luò)的大小從 320x320 調(diào)整為 608x608。
加速。VGG-16作為v1的骨干,太重了,所以在第二個版本中使用了darknet-19:
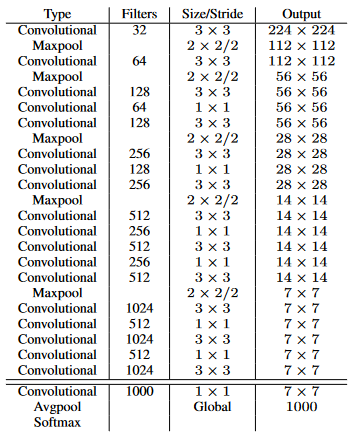
訓(xùn)練分類器后,從網(wǎng)絡(luò)中刪除最后一個卷積層,添加三個具有 1024 個濾波器的 3x3 卷積層和一個具有檢測所需輸出數(shù)量的最終 1x1的卷積層。在 VOC 的情況下,它是 5 個 bbox,每個 bbox 有 5 個坐標(biāo),每個 bbox 有 20 個類,總共有 125 個濾波器。
分層分類。在 v1 中,這些類屬于同一類目標(biāo)并且是互斥的,而在 v2 中引入了 WordNet 樹結(jié)構(gòu),這是一個有向圖。每個類別中的類都是互斥的,并且有自己的softmax。因此,例如,如果圖片顯示已知品種網(wǎng)絡(luò)的狗,則網(wǎng)絡(luò)將返回狗和特定品種的類。如果是網(wǎng)絡(luò)未知品種的狗,那么它只會返回狗的類別。因此,訓(xùn)練了 YOLO9000,它是具有 3 個先驗的 v2,而不是 5 個和 9418 個目標(biāo)類。
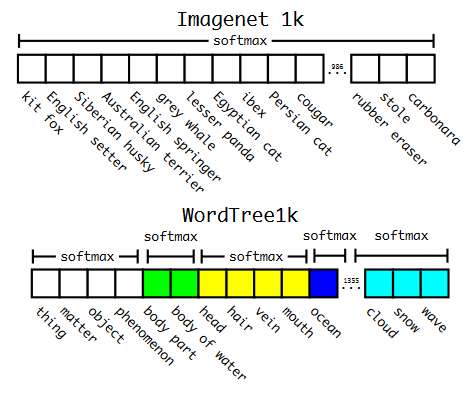
ImageNet vs WordTree上的預(yù)測。大多數(shù) ImageNet 模型使用一個大的 softmax 來預(yù)測概率分布。使用WordTree,我們對共同下義詞執(zhí)行多個softmax操作。
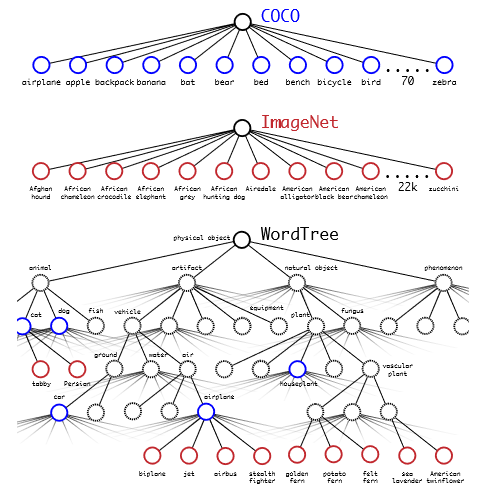
使用 WordTree 層次結(jié)構(gòu)合并數(shù)據(jù)集。使用WordNet概念圖,我們構(gòu)建了一個視覺概念的分層樹。然后,我們可以通過將數(shù)據(jù)集中的類映射到樹中的合成集來將數(shù)據(jù)集合并在一起。這是 WordTree 的簡化視圖,用于說明目的。
優(yōu)勢
現(xiàn)在它不僅是速度方面的 SOTA,而且在 mAP 方面也是。
現(xiàn)在可以更好地檢測小物體。
YOLOv3
作者
Joseph Redmon, Ali Farhadi
主要論文
“YOLOv3: An Incremental Improvement”, publication date 2018/04
性能比較
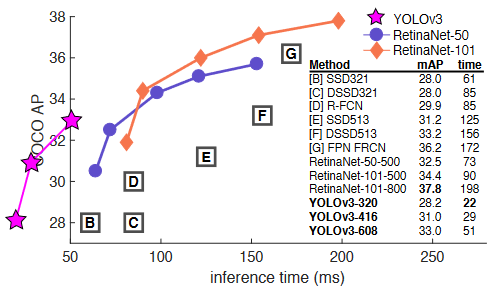
YOLOv3 的運行速度明顯快于具有相當(dāng)性能的其他檢測方法。從M40或Titan X開始,它們基本上是相同的GPU。
結(jié)構(gòu)
這是模型的增量更新,即沒有根本上更改,只有一組改進技巧。
每個 bbox 的置信度得分,即給定 bbox 中存在目標(biāo)的概率,現(xiàn)在也使用 sigmoid 計算。
作者從多類分類切換到多標(biāo)簽,所以我們擺脫了softmax,轉(zhuǎn)而支持二進制交叉熵。
在三個尺度上對 bbox 進行預(yù)測,輸出張量大小:N * N * (3 * (4 + 1 + num_classes))
作者使用k均值重新計算先驗框,并在三個尺度上得到了9個bbox。
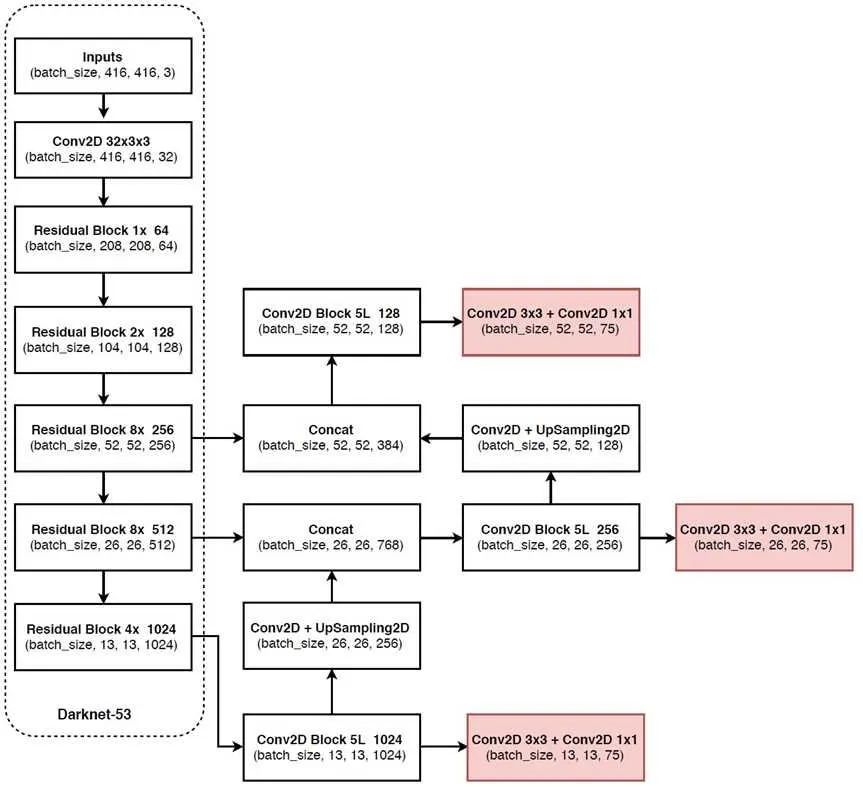
新的、更深、更準(zhǔn)確的骨干/特征提取器Darknet-53。
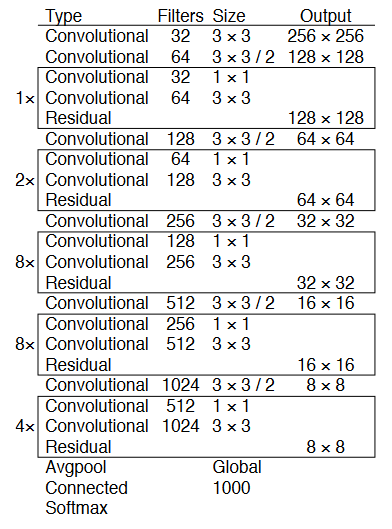
在準(zhǔn)確性方面,它與 ResNet-152 相當(dāng),但由于更有效地使用 GPU,它所需的操作減少了近 1.5 倍,產(chǎn)生的 FPS 提高了 2 倍。
總體結(jié)構(gòu)
不起作用的方法
BBOX 通過線性激活函數(shù)而不是logistic激活函數(shù)來協(xié)調(diào)位移預(yù)測。
focal loss — mAP 下降了 2 點。
用于確定GT的雙 IoU — 在 Faster R-CNN 中,IOU 有兩個閾值,通過該閾值確定正樣本或負(fù)樣本(>0.7 正值,0.3-0.7 忽略,<0.3 負(fù)樣本)
優(yōu)勢
發(fā)布時的檢測精度高于競爭對手
發(fā)布時的檢測率高于競爭對手
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論