 電子發(fā)燒友App
電子發(fā)燒友App


全世界都在搶算力,中國大公司更急迫。
2022 年下半年,生成式 AI 爆火的同時(shí),硅谷著名風(fēng)險(xiǎn)資本 a16z 走訪了數(shù)十家 AI 創(chuàng)業(yè)公司和大科技公司。他們發(fā)現(xiàn),創(chuàng)業(yè)公司轉(zhuǎn)手就把 80%-90% 的早期融資款送給了云計(jì)算平臺(tái),以訓(xùn)練自己的模型。他們估算,即便這些公司的產(chǎn)品成熟了,每年也得把 10%-20% 的營收送給云計(jì)算公司。相當(dāng)于一筆 “AI 稅”。
這帶來了在云上提供模型能力和訓(xùn)練服務(wù),把算力租給其它客戶和創(chuàng)業(yè)公司的大市場(chǎng)。僅在國內(nèi),現(xiàn)在就至少有數(shù)十家創(chuàng)業(yè)公司和中小公司在自制復(fù)雜大語言模型,他們都得從云計(jì)算平臺(tái)租 GPU。據(jù) a16z 測(cè)算,一個(gè)公司一年的 AI 運(yùn)算開支只有超過 5000 萬美元,才有足夠的規(guī)模效應(yīng)支撐自己批量采購 GPU。
據(jù)《晚點(diǎn) LatePost》了解,今年春節(jié)后,擁有云計(jì)算業(yè)務(wù)的中國各互聯(lián)網(wǎng)大公司都向英偉達(dá)下了大單。字節(jié)今年向英偉達(dá)訂購了超過 10 億美元的 GPU,另一家大公司的訂單也至少超過 10 億元人民幣。
僅字節(jié)一家公司今年的訂單可能已接近英偉達(dá)去年在中國銷售的商用 GPU 總和。去年 9 月,美國政府發(fā)布對(duì) A100、H100(英偉達(dá)最新兩代數(shù)據(jù)中心商用 GPU) 的出口限制時(shí),英偉達(dá)曾回應(yīng)稱這可能影響去年四季度它在中國市場(chǎng)的 4 億美元(約合 28 億元人民幣)潛在銷售。以此推算,2022 年全年英偉達(dá)數(shù)據(jù)中心 GPU 在中國的銷售額約為 100 億元人民幣。
相比海外巨頭,中國大科技公司采購 GPU 更為急迫。過去兩年的降本增效中,一些云計(jì)算平臺(tái)減少了 GPU 采購,儲(chǔ)備不足。此外,誰也不敢保證,今天能買的高性能 GPU,明天會(huì)不會(huì)就受到新的限制。
01. 從砍單到加購,同時(shí)內(nèi)部騰挪
今年初之前,中國大型科技公司對(duì) GPU 的需求還不溫不火。
GPU 在中國大型互聯(lián)網(wǎng)科技公司中主要有兩個(gè)用途:一是對(duì)內(nèi)支持業(yè)務(wù)和做一些前沿 AI 研究,二是把 GPU 放到云計(jì)算平臺(tái)上對(duì)外售賣。
一名字節(jié)人士告訴《晚點(diǎn) LatePost》,2020 年 6 月 OpenAI 發(fā)布 GPT-3 后,字節(jié)就曾訓(xùn)練了一個(gè)數(shù)十億參數(shù)的生成式語言大模型,當(dāng)時(shí)主要使用的 GPU 是 A100 前代產(chǎn)品 V100。由于參數(shù)規(guī)模有限,這個(gè)模型生成能力一般,字節(jié)當(dāng)時(shí)看不到它的商業(yè)化可能性,“ROI(投資回報(bào)率) 算不過來”,這次嘗試不了了之。
阿里也曾在 2018-2019 年積極采購 GPU。一位阿里云人士稱,當(dāng)時(shí)阿里的采購量至少達(dá)到上萬塊規(guī)模,購買的型號(hào)主要是 V100 和英偉達(dá)更早前發(fā)布的 T4。不過這批 GPU 中只有約十分之一給到了達(dá)摩院用作 AI 技術(shù)研發(fā)。2021 年發(fā)布萬億參數(shù)大模型 M6 后,達(dá)摩院曾披露訓(xùn)練 M6 使用了 480 塊 V100。
阿里當(dāng)時(shí)購買的 GPU,更多給到了阿里云用于對(duì)外租賃。但包括阿里云在內(nèi),一批中國云計(jì)算公司都高估了中國市場(chǎng)的 AI 需求。一位科技投資人稱,大模型熱潮之前,國內(nèi)主要云廠商上的 GPU 算力不是緊缺,而是愁賣,云廠商甚至得降價(jià)賣資源。去年阿里云先后降價(jià) 6 次,GPU 租用價(jià)下降超兩成。
在降本增效,追求 “有質(zhì)量的增長(zhǎng)” 與利潤的背景下,據(jù)了解,阿里在 2020 年之后收縮了 GPU 采購規(guī)模,騰訊也在去年底砍單一批英偉達(dá) GPU。
然而沒過多久后的 2022 年初,ChatGPT 改變了所有人的看法,共識(shí)很快達(dá)成:大模型是不容錯(cuò)過的大機(jī)會(huì)。
各公司創(chuàng)始人親自關(guān)注大模型進(jìn)展:字節(jié)跳動(dòng)創(chuàng)始人張一鳴開始看人工智能論文;阿里巴巴董事局主席張勇接手阿里云,在阿里云峰會(huì)發(fā)布阿里大模型進(jìn)展時(shí)稱,“所有行業(yè)、應(yīng)用、軟件、服務(wù),都值得基于大模型能力重做一遍”。
一名字節(jié)人士稱,過去在字節(jié)內(nèi)部申請(qǐng)采購 GPU 時(shí),要說明投入產(chǎn)出比、業(yè)務(wù)優(yōu)先級(jí)和重要性。而現(xiàn)在大模型業(yè)務(wù)是公司戰(zhàn)略級(jí)別新業(yè)務(wù),暫時(shí)算不清 ROI 也必須投入。
研發(fā)自己的通用大模型只是第一步,各公司的更大目標(biāo)是推出提供大模型能力的云服務(wù),這是真正可以匹配投入的大市場(chǎng)。
微軟的云服務(wù) Azure 在中國云計(jì)算市場(chǎng)本沒有太強(qiáng)存在感,入華十年來主要服務(wù)跨國公司的中國業(yè)務(wù)。但現(xiàn)在客戶得排隊(duì)等待,因?yàn)樗?OpenAI 商業(yè)化的唯一云代理商。
阿里在 4 月的云峰會(huì)上,再次強(qiáng)調(diào) MaaS(模型即服務(wù))是未來云計(jì)算趨勢(shì),在開放自研的通用基礎(chǔ)模型 “通義千問” 測(cè)試之外,還發(fā)布了一系列幫助客戶在云上訓(xùn)練、使用大模型的工具。不久后騰訊和字節(jié)火山引擎也先后發(fā)布自己的新版訓(xùn)練集群服務(wù)。騰訊稱用新一代集群訓(xùn)練萬億參數(shù)的混元大模型,時(shí)間可被壓縮到 4 天;字節(jié)稱它們的新集群支持萬卡級(jí)大模型訓(xùn)練,國內(nèi)數(shù)十家做大模型的企業(yè),多數(shù)已在使用火山引擎。
所有這些平臺(tái)使用的要么是英偉達(dá) A100、H100 GPU,要么是去年禁令后英偉達(dá)專門推出的減配版 A800、H800,這兩款處理器帶寬分別是原版的約 3/4 和約一半,避開了高性能 GPU 的限制標(biāo)準(zhǔn)。
圍繞 H800 和 A800,中國科技大公司開始了新一輪下單競(jìng)爭(zhēng)。
一名云廠商人士稱,字節(jié)、阿里等大公司主要是和英偉達(dá)原廠直接談采購,代理商和二手市場(chǎng)難以滿足他們的龐大需求。
英偉達(dá)會(huì)按目錄價(jià),根據(jù)采購規(guī)模談一個(gè)折扣。據(jù)英偉達(dá)官網(wǎng),A100 售價(jià)為 1 萬美元 / 枚(約 7.1 萬元人民幣),H100 售價(jià)為 3.6 萬美元 / 枚(約 25.7 萬元人民幣);據(jù)了解,A800 和 H800 售價(jià)略低于原版。
中國公司能否搶到卡,更多是看商業(yè)關(guān)系,比如以往是不是英偉達(dá)的大客戶。“你是和中國英偉達(dá)談,還是去美國找老黃(黃仁勛,英偉達(dá)創(chuàng)始人、CEO)直接談,都有差別。” 一位云廠商人士說。
部分公司也會(huì)和英偉達(dá)進(jìn)行 “業(yè)務(wù)合作”,在購買搶手的數(shù)據(jù)中心 GPU 時(shí),也購買其它產(chǎn)品,以爭(zhēng)取優(yōu)先供應(yīng)。這就像愛馬仕的配貨,如果你想買到熱門的包,往往也得搭配幾萬元的衣服、鞋履。
綜合我們獲得的行業(yè)信息,字節(jié)今年的新下單動(dòng)作相對(duì)激進(jìn),超過 10 億美元級(jí)別。
一位接近英偉達(dá)的人士稱,字節(jié)到貨和沒到貨的 A100 與 H800 總計(jì)有 10 萬塊。其中 H800 今年 3 月才開始投產(chǎn),這部分芯片應(yīng)來自今年的加購。據(jù)了解,以現(xiàn)在的排產(chǎn)進(jìn)度,部分 H800 要到今年底才能交貨。
字節(jié)跳動(dòng) 2017 年開始建設(shè)自己的數(shù)據(jù)中心。曾經(jīng)的數(shù)據(jù)中心更依賴適應(yīng)所有計(jì)算的 CPU,直到 2020 年,字節(jié)采購英特爾 CPU 的金額還高于英偉達(dá) GPU。字節(jié)采購量的變化,也反映了如今大型科技公司的計(jì)算需求中,智能計(jì)算對(duì)通用計(jì)算的趕超。
據(jù)了解,某互聯(lián)網(wǎng)大廠今年至少已給英偉達(dá)下了萬卡級(jí)別訂單,按目錄價(jià)估算價(jià)值超 10 億元人民幣。
騰訊則率先宣布已用上 H800,騰訊云在今年 3 月發(fā)布的新版高性能計(jì)算服務(wù)中已使用了 H800,并稱這是國內(nèi)首發(fā)。目前這一服務(wù)已對(duì)企業(yè)客戶開放測(cè)試申請(qǐng),這快于大部分中國公司的進(jìn)度。
據(jù)了解,阿里云也在今年 5 月對(duì)內(nèi)提出把 “智算戰(zhàn)役” 作為今年的頭號(hào)戰(zhàn)役,并設(shè)立三大目標(biāo):機(jī)器規(guī)模、客戶規(guī)模和營收規(guī)模;其中機(jī)器規(guī)模的重要指標(biāo)就是 GPU 數(shù)量。
新的 GPU 到貨前,各公司也在通過內(nèi)部騰挪,優(yōu)先支持大模型研發(fā)。
能一次釋放較多資源的做法是砍掉一些沒那么重要,或短期看不到明確前景的方向。“大公司有好多半死不活的業(yè)務(wù)占著資源。” 一位互聯(lián)網(wǎng)大公司 AI 從業(yè)者說。
今年 5 月,阿里達(dá)摩院裁撤自動(dòng)駕駛實(shí)驗(yàn)室:300 多名員工中,約 1/3 劃歸菜鳥技術(shù)團(tuán)隊(duì),其余被裁,達(dá)摩院不再保留自動(dòng)駕駛業(yè)務(wù)。研發(fā)自動(dòng)駕駛也需要用高性能 GPU 做訓(xùn)練。這一調(diào)整可能與大模型無直接關(guān)系,但確實(shí)讓阿里獲得了一批 “自由 GPU”。
字節(jié)和美團(tuán),則直接從給公司帶來廣告收入的商業(yè)化技術(shù)團(tuán)隊(duì)那里勻 GPU。
據(jù)《晚點(diǎn) LatePost》了解,今年春節(jié)后不久,字節(jié)把一批原計(jì)劃新增給字節(jié)商業(yè)化技術(shù)團(tuán)隊(duì)的 A100 勻給了 TikTok 產(chǎn)品技術(shù)負(fù)責(zé)人朱文佳。朱文佳正在領(lǐng)導(dǎo)字節(jié)大模型研發(fā)。而商業(yè)化技術(shù)團(tuán)隊(duì)是支持抖音廣告推薦算法的核心業(yè)務(wù)部門。
美團(tuán)在今年一季度左右開始開發(fā)大模型。據(jù)了解,美團(tuán)不久前從多個(gè)部門調(diào)走了一批 80G 顯存頂配版 A100,優(yōu)先供給大模型,讓這些部門改用配置更低的 GPU。
財(cái)力遠(yuǎn)不如大平臺(tái)充裕的 B 站對(duì)大模型也有規(guī)劃。據(jù)了解,B 站此前已儲(chǔ)備了數(shù)百塊 GPU。今年,B 站一方面持續(xù)加購 GPU,一方面也在協(xié)調(diào)各部門勻卡給大模型。“有的部門給 10 張,有的部門給 20 張。” 一位接近 B 站的人士稱。
字節(jié)、美團(tuán)、B 站等互聯(lián)網(wǎng)公司,原本支持搜索、推薦的技術(shù)部門一般會(huì)有一些 GPU 資源冗余,在不傷害原有業(yè)務(wù)的前提下,他們現(xiàn)在都在 “把算力水份擠出來”。
不過這種拆東補(bǔ)西的做法能獲得的 GPU 數(shù)量有限,訓(xùn)練大模型所需的大頭 GPU 還是得靠各公司過去的積累和等待新 GPU 到貨。
02. 全世界都在搶算力
對(duì)英偉達(dá)數(shù)據(jù)中心 GPU 的競(jìng)賽也發(fā)生在全球范圍。不過海外巨頭大量購買 GPU 更早,采購量更大,近年的投資相對(duì)連續(xù)。
2022 年,Meta 和甲骨文就已有對(duì) A100 的大投入。Meta 在去年 1 月與英偉達(dá)合作建成 RSC 超級(jí)計(jì)算集群,它包含 1.6 萬塊 A100。同年 11 月,甲骨文宣布購買數(shù)萬塊 A100 和 H100 搭建新計(jì)算中心。現(xiàn)在該計(jì)算中心已部署了超 3.27 萬塊 A100,并陸續(xù)上線新的 H100。
微軟自從 2019 年第一次投資 OpenAI 以來,已為 OpenAI 提供數(shù)萬塊 GPU。今年 3 月,微軟又宣布已幫助 OpenAI 建設(shè)了一個(gè)新計(jì)算中心,其中包括數(shù)萬塊 A100。Google 在今年 5 月推出了一個(gè)擁有 2.6 萬塊 H100 的計(jì)算集群 Compute Engine A3,服務(wù)想自己訓(xùn)練大模型的公司。
中國大公司現(xiàn)在的動(dòng)作和心態(tài)都比海外巨頭更急迫。以百度為例,它今年向英偉達(dá)新下的 GPU 訂單高達(dá)上萬塊。數(shù)量級(jí)與 Google 等公司相當(dāng),雖然百度的體量小得多,其去年?duì)I收為 1236 億元人民幣,只有 Google 的 6%。
據(jù)了解,字節(jié)、騰訊、阿里、百度這四家中國投入 AI 和云計(jì)算最多的科技公司,過去 A100 的積累都達(dá)到上萬塊。其中字節(jié)的 A100 絕對(duì)數(shù)最多。不算今年的新增訂單,字節(jié) A100 和前代產(chǎn)品 V100 總數(shù)接近 10 萬塊。
成長(zhǎng)期公司中,商湯今年也宣稱,其 “AI 大裝置” 計(jì)算集群中已總共部署了 2.7 萬塊 GPU,其中有 1 萬塊 A100。連看似和 AI 不搭邊的量化投資公司幻方之前也購買了 1 萬塊 A100。
僅看總數(shù),這些 GPU 供各公司訓(xùn)練大模型似乎綽綽有余——據(jù)英偉達(dá)官網(wǎng)案例,OpenAI 訓(xùn)練 1750 億參數(shù)的 GPT-3 時(shí)用了 1 萬塊 V100 ,訓(xùn)練時(shí)長(zhǎng)未公開;英偉達(dá)測(cè)算,如果用 A100 來訓(xùn)練 GPT-3 ,需要 1024 塊 A100 訓(xùn)練 1 個(gè)月,A100 相比 V100 有 4.3 倍性能提升。但中國大公司過去采購的大量 GPU 要支撐現(xiàn)有業(yè)務(wù),或放在云計(jì)算平臺(tái)上售賣,并不能自由地用于大模型開發(fā)和對(duì)外支持客戶的大模型需求。
這也解釋了中國 AI 從業(yè)者對(duì)算力資源估算的巨大差別。清華智能產(chǎn)業(yè)研究院院長(zhǎng)張亞勤 4 月底參加清華論壇時(shí)說,“如果把中國的算力加一塊,相當(dāng)于 50 萬塊 A100,訓(xùn)練五個(gè)模型沒問題。”AI 公司曠視科技 CEO 印奇接受《財(cái)新》采訪時(shí)則說:中國目前可用作大模型訓(xùn)練的 A100 總共只有約 4 萬塊。
主要反映對(duì)芯片、服務(wù)器和數(shù)據(jù)中心等固定資產(chǎn)投資的資本開支,可以直觀說明中外大公司計(jì)算資源的數(shù)量級(jí)差距。
最早開始測(cè)試類 ChatGPT 產(chǎn)品的百度,2020 年以來的年資本開支在 8 億到 20 億美元之間,阿里在 60-80 億美元之間,騰訊在 70-110 億美元之間。同期,亞馬遜、Meta、Google、微軟這四家自建數(shù)據(jù)中心的美國科技公司的年資本開支最少均超過 150 億美元。
疫情三年中,海外公司資本開支繼續(xù)上漲。亞馬遜去年的資本開支已來到 580 億美元,Meta、Google 均為 314 億美元,微軟接近 240 億美元。中國公司的投資在 2021 年之后則在收縮。騰訊、百度去年的資本開支均同比下滑超 25%。
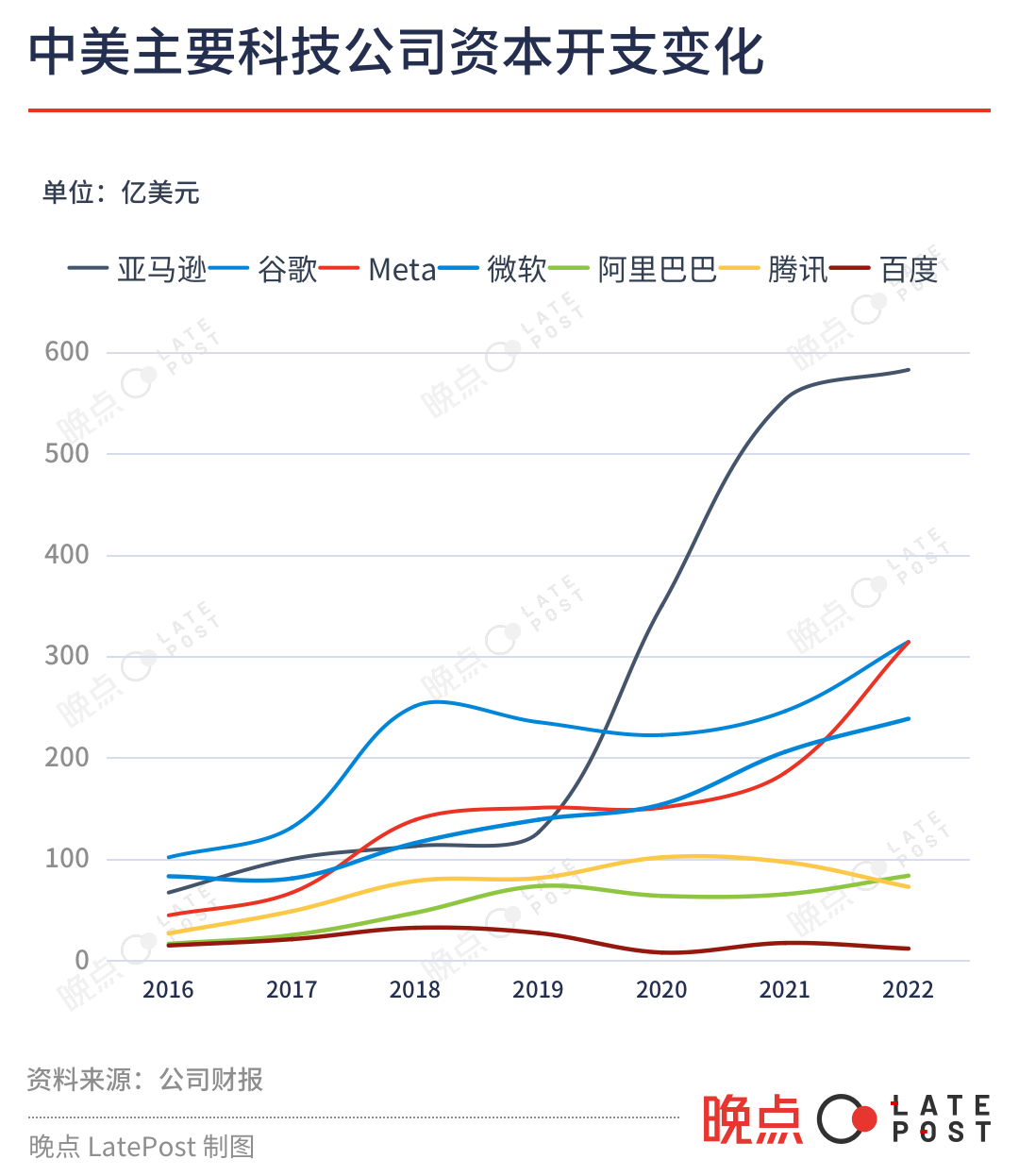
訓(xùn)練大模型的 GPU 已不算充足,各家中國公司如果真的要長(zhǎng)期投入大模型,并賺到給其它模型需求 “賣鏟子” 的錢,未來還需要持續(xù)增加 GPU 資源。
走得更快 OpenAI 已遇到了這一挑戰(zhàn)。5 月中旬,OpenAI CEO SamAltman 在與一群開發(fā)者的小范圍交流中說,由于 GPU 不夠,OpenAI 現(xiàn)在的 API 服務(wù)不夠穩(wěn)定,速度也不夠快,在有更多 GPU 前,GPT-4 的多模態(tài)能力還無法拓展給每個(gè)用戶,他們近期也不準(zhǔn)備發(fā)布新的消費(fèi)級(jí)產(chǎn)品。技術(shù)咨詢機(jī)構(gòu) TrendForce 今年 6 月發(fā)布報(bào)告稱,OpenAI 需要約 3 萬塊 A100 來持續(xù)優(yōu)化和商業(yè)化 ChatGPT。
與 OpenAI 合作頗深的微軟也面臨類似情境:今年 5 月,有用戶吐槽 New Bing 回答速度變慢,微軟回應(yīng),這是因?yàn)?GPU 補(bǔ)充速度跟不上用戶增長(zhǎng)速度。嵌入了大模型能力的微軟 Office 365 Copilot 目前也沒有大規(guī)模開放,最新數(shù)字是有 600 多家企業(yè)在試用——Office 365 的全球總用戶數(shù)接近 3 億。
中國大公司如果不是僅把訓(xùn)練并發(fā)布一個(gè)大模型作為目標(biāo),而是真想用大模型創(chuàng)造服務(wù)更多用戶的產(chǎn)品,并進(jìn)一步支持其它客戶在云上訓(xùn)練更多大模型,就需要提前儲(chǔ)備更多 GPU。
03. 為什么只能是那四款卡?
在 AI 大模型訓(xùn)練上,現(xiàn)在 A100、H100 及其特供中國的減配版 A800、H800 找不到替代品。據(jù)量化對(duì)沖基金 Khaveen Investments 測(cè)算,英偉達(dá)數(shù)據(jù)中心 GPU 2022 年市占率達(dá) 88%,AMD 和英特爾瓜分剩下的部分。
2020 年的 GTC 大會(huì)上,黃仁勛攜 A100 第一次亮相。
英偉達(dá) GPU 目前的不可替代性,源自大模型的訓(xùn)練機(jī)制,其核心步驟是預(yù)訓(xùn)練(pre-training)和微調(diào)(fine-tuning),前者是打基座,相當(dāng)于接受通識(shí)教育至大學(xué)畢業(yè);后者則是針對(duì)具體場(chǎng)景和任務(wù)做優(yōu)化,以提升工作表現(xiàn)。
預(yù)訓(xùn)練環(huán)節(jié)尤其消耗算力,它對(duì)單個(gè) GPU 的性能和多卡間的數(shù)據(jù)傳輸能力有極高要求。
現(xiàn)在只有 A100、H100 能提供預(yù)訓(xùn)練所需的計(jì)算效率,它們看起來昂貴,反倒是最低廉的選擇。今天 AI 還在商用早期,成本直接影響一個(gè)服務(wù)是否可用。
過去的一些模型,如能識(shí)別貓是貓的 VGG16,參數(shù)量只有 1.3 億,當(dāng)時(shí)一些公司會(huì)用玩游戲的 RTX 系列消費(fèi)級(jí)顯卡來跑 AI 模型。而兩年多前發(fā)布的 GPT-3 的參數(shù)規(guī)模已達(dá)到 1750 億。
大模型的龐大計(jì)算需求下,用更多低性能 GPU 共同組成算力已行不通了。因?yàn)槭褂枚鄠€(gè) GPU 訓(xùn)練時(shí),需要在芯片與芯片間傳輸數(shù)據(jù)、同步參數(shù)信息,這時(shí)部分 GPU 會(huì)閑置,無法一直飽和工作。所以單卡性能越低,使用的卡越多,算力損耗就越大。OpenAI 用 1 萬塊 V100 訓(xùn)練 GPT-3 時(shí)的算力利用率不到 50%。
A100 、H100 則既有單卡高算力,又有提升卡間數(shù)據(jù)傳輸?shù)母邘挕100 的 FP32(指用 4 字節(jié)進(jìn)行編碼存儲(chǔ)的計(jì)算)算力達(dá)到 19.5 TFLOPS(1 TFLOPS 即每秒進(jìn)行一萬億次浮點(diǎn)運(yùn)算),H100 的 FP32 算力更高達(dá) 134 TFLOPS,是競(jìng)品 AMD MI250 的約 4 倍。
A100、H100 還提供高效數(shù)據(jù)傳輸能力,盡可能減少算力閑置。英偉達(dá)的獨(dú)家秘籍是自 2014 年起陸續(xù)推出的 NVLink、NVSwitch 等通信協(xié)議技術(shù)。用在 H100 上的第四代 NVLink 可將同一服務(wù)器內(nèi)的 GPU 雙向通信帶寬提升至 900 GB/s(每秒傳輸 900GB 數(shù)據(jù)),是最新一代 PCle(一種點(diǎn)對(duì)點(diǎn)高速串行傳輸標(biāo)準(zhǔn))的 7 倍多。
去年美國商務(wù)部對(duì) GPU 的出口規(guī)定也正是卡在算力和帶寬這兩條線上:算力上線為 4800 TOPS,帶寬上線為 600 GB/s。
A800 和 H800 算力和原版相當(dāng),但帶寬打折。A800 的帶寬從 A100 的 600GB/s 降為 400GB/s,H800 的具體參數(shù)尚未公開,據(jù)彭博社報(bào)道,它的帶寬只有 H100(900 GB/s) 的約一半,執(zhí)行同樣的 AI 任務(wù)時(shí),H800 會(huì)比 H100 多花 10% -30% 的時(shí)間。一名 AI 工程師推測(cè),H800 的訓(xùn)練效果可能還不如 A100,但更貴。
即使如此,A800 和 H800 的性能依然超過其他大公司和創(chuàng)業(yè)公司的同類產(chǎn)品。受限于性能和更專用的架構(gòu),各公司推出的 AI 芯片或 GPU 芯片,現(xiàn)在主要用來做 AI 推理,難以勝任大模型預(yù)訓(xùn)練。簡(jiǎn)單來說,AI 訓(xùn)練是做出模型,AI 推理是使用模型,訓(xùn)練對(duì)芯片性能要求更高。
性能差距外,英偉達(dá)的更深護(hù)城河是軟件生態(tài)。
早在 2006 年,英偉達(dá)就推出計(jì)算平臺(tái) CUDA,它是一個(gè)并行計(jì)算軟件引擎,開發(fā)者可使用 CUDA 更高效地進(jìn)行 AI 訓(xùn)練和推理,用好 GPU 算力。CUDA 今天已成為 AI 基礎(chǔ)設(shè)施,主流的 AI 框架、庫、工具都以 CUDA 為基礎(chǔ)進(jìn)行開發(fā)。
英偉達(dá)之外的 GPU 和 AI 芯片如要接入 CUDA,需要自己提供適配軟件,但只有 CUDA 部分性能,更新迭代也更慢。PyTorch 等 AI 框架正試圖打破 CUDA 的軟件生態(tài)壟斷,提供更多軟件能力以支持其它廠商的 GPU,但這對(duì)開發(fā)者吸引力有限。
一位 AI 從業(yè)者稱,他所在的公司曾接觸一家非英偉達(dá) GPU 廠商,對(duì)方的芯片和服務(wù)報(bào)價(jià)比英偉達(dá)更低,也承諾提供更及時(shí)的服務(wù),但他們判斷,使用其它 GPU 的整體訓(xùn)練和開發(fā)成本會(huì)高于英偉達(dá),還得承擔(dān)結(jié)果的不確定性和花更多時(shí)間。
“雖然 A100 價(jià)格貴,但其實(shí)用起來是最便宜的。” 他說。對(duì)有意抓住大模型機(jī)會(huì)的大型科技公司和頭部創(chuàng)業(yè)公司來說,錢往往不是問題,時(shí)間才是更寶貴的資源。
短期內(nèi),唯一影響英偉達(dá)數(shù)據(jù)中心 GPU 銷量的可能只有臺(tái)積電的產(chǎn)能。
H100/800 為 4 nm 制程,A100/800 為 7 nm 制程,這四款芯片均由臺(tái)積電代工生產(chǎn)。據(jù)中國臺(tái)灣媒體報(bào)道,英偉達(dá)今年向臺(tái)積電新增了 1 萬片數(shù)據(jù)中心 GPU 訂單,并下了超急件 ,生產(chǎn)時(shí)間最多可縮短 50%。正常情況下,臺(tái)積電生產(chǎn) A100 需要數(shù)月。目前的生產(chǎn)瓶頸主要在先進(jìn)封裝產(chǎn)能不夠,缺口達(dá)一至兩成,需要 3-6 個(gè)月逐步提升。
自從適用于并行計(jì)算的 GPU 被引入深度學(xué)習(xí),十多年來,AI 發(fā)展的動(dòng)力就是硬件與軟件,GPU 算力與模型和算法的交疊向前:模型發(fā)展拉動(dòng)算力需求;算力增長(zhǎng),又使原本難以企及的更大規(guī)模訓(xùn)練成為可能。
在上一波以圖像識(shí)別為代表的深度學(xué)習(xí)熱潮中,中國 AI 軟件能力比肩全球最前沿水平;算力是目前的難點(diǎn)——設(shè)計(jì)與制造芯片需要更長(zhǎng)的積累,涉及漫長(zhǎng)供應(yīng)鏈和浩繁專利壁壘。
大模型是模型與算法層的又一次大進(jìn)展,沒時(shí)間慢慢來了,想做大模型,或提供大模型云計(jì)算能力的公司必須盡快獲得足夠多的先進(jìn)算力。在這輪熱潮使第一批公司振奮或失望前,圍繞 GPU 的搶奪不會(huì)停止。
編輯:黃飛




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論