 電子發燒友App
電子發燒友App


1
概述
語音識別技術,是將語音信號轉換為文本內容的技術。目前比較流行的語音識別技術主要有兩種。一種是基于Kaldi的傳統語音識別技術,另一種是目前流行的基于深度學習模型的端到端語音識別技術。Kaldi是一種大而全的語音識別處理框架,集成了數據預處理、特征提取、聲學模型建模、語言模型建模、解碼等,識別效果上能夠滿足大多數的語音識別場景。但是Kaldi是自成一體的框架,沒有現在流行的pytorch、tensorflow框架的支持,需要開發者自行開發能應用到生產環境中的服務。基于深度學習模型的端到端語音識別框架是指將語音信號直接輸入到深度學習模型中,通過端到端的方式進行語音識別,無需使用傳統的聲學模型和語言模型,常見的基于深度學習的端到端語音識別框架有很多,比如EspNet,WeNet等,這類語音識別框架有更通用的模型訓練和部署框架支持,有著更好的識別性能和識別效果。
58自研語音識別引擎,最初是基于Kaldi框架進行開發,在自研初期上線了架構1.0版本,后續以降低機器資源、提升資源利用率、優化性能為目標進行了升級重構,上線了架構2.0版本。本文將介紹基于Kaldi的語音識別引擎的架構設計,介紹從架構1.0到2.0版本的優化歷程。首先介紹業務背景,然后介紹Kaldi語音解碼的優化,以及后端服務的各種優化,最后是優化取得的效果。
我們也在持續探索基于深度學習模型的端到端語音識別,嘗試了ESPNet,WeNet等流行的端到端框架。在2021年12月引入了端到端WeNet語音識別(由出門問問和西北工業大學于2021年1月開源),經過持續的優化,WeNet解碼服務在效果和性能上都超過了Kadli解碼,在2022年8月份,我們在線上全量替換了Kaldi語音解碼服務(WeNet端到端語音識別技術在58同城的大規模落地)。
2
背景
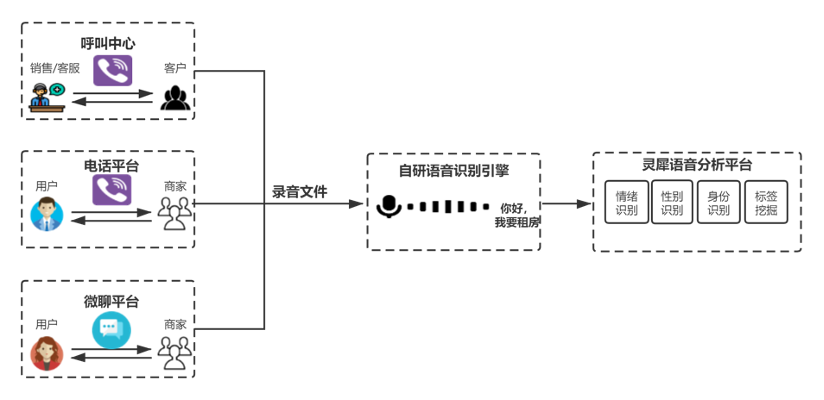
58同城是國內領先的生活分類信息網站平臺,涉及業務有招聘、房產、車、本地生活服務(黃頁)等。語音是平臺上商家、用戶、銷售、客服之間溝通的主要媒介。
58平臺上的B端商家和C端用戶會使用電話、微聊進行語音溝通,同時58呼叫中心支撐著數千名銷售、客服人員工作,年通話時長數百萬小時。這些場景下產生了海量的語音數據,這些語音數據經過語音識別轉為文字之后,對于語音質檢、信息治理和用戶畫像等任務有巨大的價值。此外,AI Lab團隊研發了可以提高人效的語音外呼機器人,典型應用為銷售機器人“黃頁銷售智能外呼助手”和面試機器人“神奇面試間”。
3
架構1.0
3.1 架構1.0的背景
我們從2019年12月開始語音識別引擎的自研工作(3人半年打造語音識別引擎——58同城語音識別自研之路),業務方采購的是第三方的語音識別引擎,采購費用昂貴,采購合同即將在半年后到期。最終提前一個月上線切換到自研語音識別引擎。
語音識別系統通用處理流程是:客戶端發送音頻文件或者音頻流,服務端在接收后進行格式、采樣率等轉換,以及聲道分離、說話分離,轉換為多個人聲片段,再由解碼器對人聲片段進行解碼,輸出轉寫結果。一個語音識別系統的重點和關鍵點就是在盡量低資源(CPU/GPU)占用的情況下,能較大吞吐、較低延遲、較可靠的處理海量的音頻輸入,并保持較高的轉寫準確率。
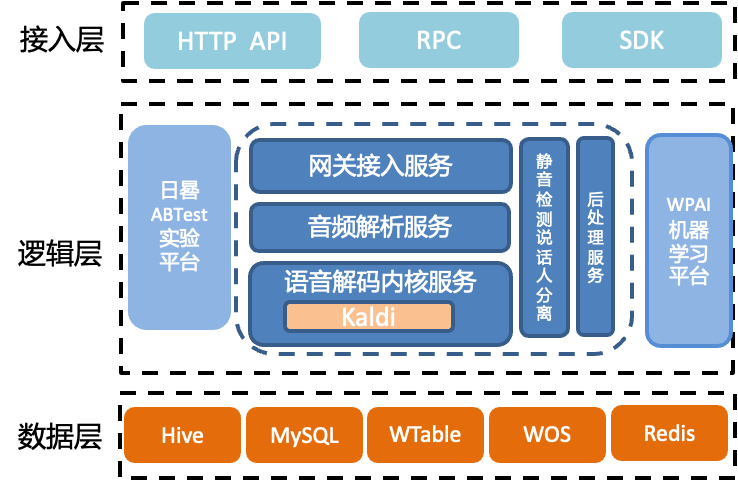
架構1.0系統,基于語音識別系統的通用流程建立,服務主要包括網關接入服務、音頻解析服務、以及基于Kaldi的語音解碼內核服務、靜音檢測和說話人服務、后處理服務等。各服務的主要功能:
網關接入服務,負責業務接入分發、鑒權和檢測等功能。
音頻解析服務,負責將音頻做轉換處理。語音解碼內核服務負責將音頻解碼為文字。
靜音檢測和說話人服務,負責將人聲片段分離出來,用于后續解碼。
后處理服務,負責將轉寫后文字添加標點等處理任務。
語音解碼內核服務,負責將音頻片段轉寫為文本。
3.2 架構1.0的不足
架構1.0系統是在時間緊、任務重的情況下,滿足了快速上線的需要,但也存在以下不足:
占用機器資源太高
機器資源利用率不均衡
系統整體耗時高
可靠性和擴展性不足
重構的目標主要是以下三個:
降低機器資源,節省成本
提高機器資源利用率
降低系統耗時、提升可靠性
4
架構2.0
針對架構1.0的不足,主要在以下兩個大方向上進行優化:
1. 針對語音內核解碼服務中,Kaldi并發解碼支持不足、性能差的問題,進行了服務性能優化
2. 針對后端應用服務中的不足,進行了服務拆分和一系列的性能優化。
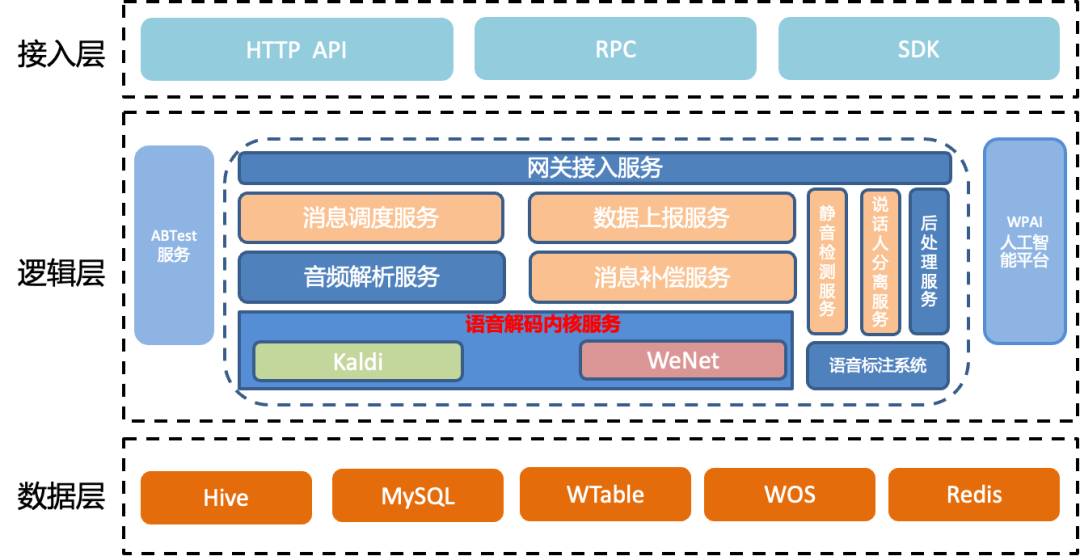
架構2.0對1.0架構中部分服務功能耦合的部分進行了拆分、對網關接入服務、音頻解析、解碼內核服務做了重構升級。
架構2.0的服務包括網關接入服務、消息調度服務、數據上報服務、音頻解析服務、消息補償服務、靜音檢測服務、說話人分離服務、以及語音解碼內核服務等。其中新增了消息調度服務、數據上報服務、消息補償服務。靜音檢測服務、說話人分離服務,是從之前靜音檢測和說話人分離服務拆分而來。對這幾個服務的情況進行如下說明:
網關接入服務,負責業務接入分發、鑒權和檢測等功能。將消息可靠性功能拆分為補償服務,對服務的性能進行了優化
消息調度服務、數據上報服務,負責基于機器負載狀態進行消息分發。
消息補償服務,將消息補償的部分消息可靠性保證的功能,從之前的服務中拆分,負責對不同業務提供不同個性化補償策略。
靜音檢測服務、是從之前靜音檢測和說話人分離服務拆分而來,將之前同步的流程拆分,進行異步處理。
語音解碼內核服務,負責將音頻片段轉寫為文本。將語音解碼內核服務優化為可以進行并發解碼,處理并發請求。
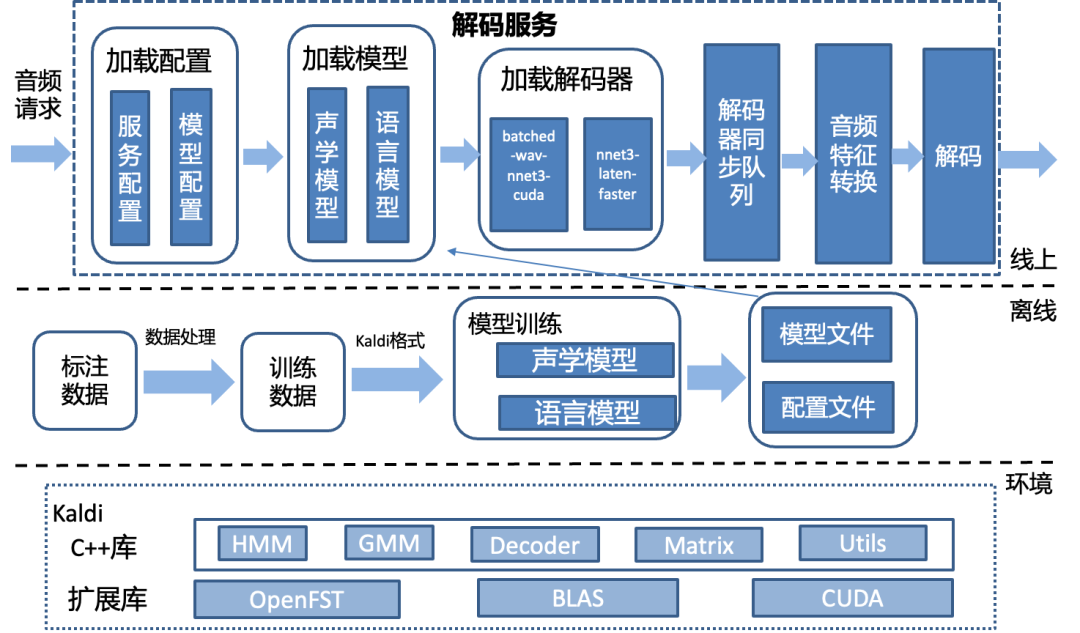
4.1 Kaldi解碼優化實踐
Kaldi主要功能由c++開發完成,共有26萬行代碼。解碼器是Kaldi中的核心組件,用于將聲學特征序列轉換為文本序列。Kaldi提供了一些解碼器的接口,以及shell離線腳本demo。但是未提供生產級的服務。Kaldi原生解碼的主要問題有:
4.1.1 無服務化支持
需要梳理調用關系,增加服務端、協議、客戶端調用支持。我們將模型、解碼器相關的接口抽象出來,封裝為gRPC服務,服務接收音頻數據、解碼為文本轉寫結果。
4.1.2 無并發能力支持
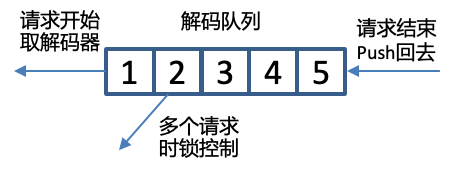
原生的解碼器對并發請求的處理能力差。需要將服務的網絡請求模型和解碼器關聯起來,使服務獲取并發處理能力。我們的方案是服務啟動時初始化足夠的解碼器數目到同步隊列中,當服務請求線程到來時,從隊列中取出解碼器。當請求結束后,再放回隊列中。
那么服務啟動時初始化足夠數目的解碼器,這個數目是多少比較合適?服務初始的解碼器數目,就是可以支持的最大并行解碼的數目,這個數目越大,耗時越高、CPU/GPU的資源利用率越高。設置多少數目的解碼器,取決對實時率、尾包延遲的性能要求、也取決于服務器的硬件性能。比如在一臺CPU是Intel Xeon Silver 4210的物理機上,轉寫一個30s的音頻,要求在2s內返回轉寫結果,系統最多能容忍32個解碼器并行處理,或者正在實時轉寫的數據流,尾包延遲要求在100ms內,系統最多能容忍16個解碼器并行處理。以定義好的性能數值為目標,從小到大的設置解碼器數目進行測試,滿足性能數值目標時,此時的數字就是服務需要初始化的解碼器數目。
4.1.3 CUDA GPU解碼支持不足
需要處理CUDA環境、模型、解碼器的關系,對于非Exclusive模式有OOM異常風險。一個解碼服務進程只能有一個模型對象進行初始化,CUDA環境和模型對象是一一映射關系,單卡綁定一個CUDA環境、一個模型對象。而模型對象和解碼器之間是一對多的關系。
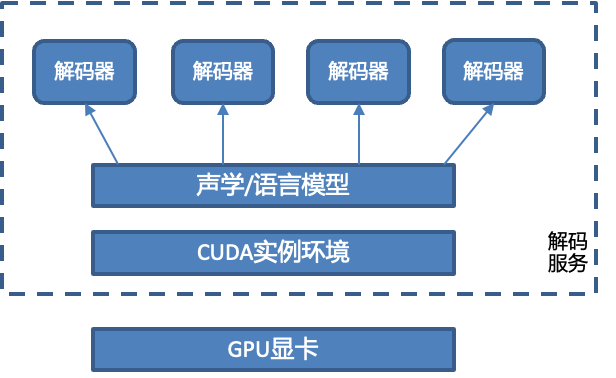
對于GPU解碼需要注意多個并發請求時轉寫結果偶爾會出現亂碼、錯字等情況,這是由于在Kaldi CUDA接口中的轉寫回調函數在一個進程環境下只有一個,這里需要在回調函數處理轉寫結果時加鎖、避免這些問題。
另外的一個問題是在GPU解碼獲取lattice回調結果時,有資源未清理的問題,會直接導致進程異常退出,這是由于在初始化時解碼進程綁定了唯一id和cuda channel的關系,但是在解碼結束時沒有解綁導致的,這個問題我們發現后提交了PR就行了修復。
最終,解碼服務的設計如下,基于Kaldi和CUDA環境,在離線環境中完成聲學模型、語言模型的訓練、添加相關的配置。在解碼服務啟動時,加載服務配置,加載離線訓練的模型,初始化解碼器同步隊列,當有音頻請求到來時,根據協議判斷音頻請求的開始和結束狀態,從隊列中加載解碼器,轉寫出結果后,返回給服務的調用方。
4.2 后端應用服務的優化
除了在語音解碼服務上的優化,在后端服務上我們也進行了一系列的優化,包含并發處理、多級緩存、I/O優化、GC優化、異步處理、分發效率優化等方面,大大的優化了系統的處理性能。具體的優化如下:
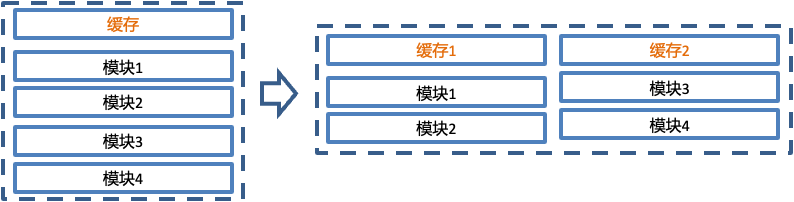
4.2.1 并發處理和兩級緩存優化
在音頻解析服務中,有很多音頻解析、轉換、分離、解碼、組合的處理模塊,處理鏈路長,而消息接收的效率、解析轉換的效率、解碼的效率是不同的。如果整個處理過程是單一的處理鏈條,由于模塊間處理效率上的不匹配,會出現下游模塊等待上游模塊的情況,那么整體的處理效率就會受到影響。為了盡可能降低模塊間的阻塞等待,可以將耦合度低的模塊拆分出來,增加緩存單獨并行處理,此時可以認為兩個緩存下的模塊是并行處理的鏈條,在處理效率上理論上大于等于單一鏈條的處理效率。在單一鏈條模塊有阻塞等待情況時,甚至要遠高于單一鏈條的處理效率。
將服務優化為設立二級緩存來縮短處理鏈條,同時兩個緩存下的模塊獨立并行處理。二級緩存中的第一級在消息接收和解碼轉換之間,第二級在轉換和解碼之間,在兩個不同分級之間,使用多線程批量處理提高吞吐能力。優化后相比優化前,TP999耗時降低了91%。
4.2.2 I/O優化
常說的I/O包含網絡I/O、磁盤I/O、設備I/O等,由于I/O時通常會涉及到數據交換、系統內核態的切換,相應的就會增加系統的開銷。我們本次I/O優化利用緩存、批量處理等手段來降低I/O,提升系統的性能。在服務中,涉及到多次磁盤I/O和網絡I/O:
(1) 服務里包含對大量音頻文件的讀寫操作,會產生多次的磁盤I/O讀。通過使用緩存,以空間換時間的方式,將多次磁盤I/O讀降低為通過一次I/O緩存全部數據,缺點是增加了內存,由于服務是Java服務,會相應的增加GC回收頻率和停頓時長,那就還涉及到GC上的優化。
(2)服務里包含請求和響應相似的單獨請求,涉及到大量的網絡I/O。通過將這些相似請求進行合并,增加批量接口,進行批量請求,降低網絡I/O次數。
整體上,優化后相比優化前,TP999耗時降低了10倍。
4.2.3?GC優化
系統中的上層處理服務是Java服務,Java服務由于垃圾回收的關系,會在回收期間暫停應用程序線程的執行(Stop-The-World),直到垃圾回收操作完成,毫無疑問這會降低系統性能。之前服務使用G1垃圾回收器,也進行了參數調優,比如增加堆內存、調整G1HeapRegionSize、MaxGCPauseMillis等,但是效果不是很理想。這是由于緩存音頻數據導致服務的內存占用大,老年代對象較多,會頻繁的進行Mixed GC和Full GC。服務中G1的回收頻率5s左右,回收停頓的時間平均1.8s、最大停頓時間接近40s,拉低了服務整體處理性能。
ZGC在JDK11中首次發布,是一種低停頓時間、適合大堆內存的垃圾回收器,能在幾毫秒到幾十毫秒內完成垃圾回收。ZGC基于并發標記、并發轉移、以及讀屏障等技術,而且回收時僅需要掃描GC Roots, 使得STW的延遲非常低。通過將JDK版本升級到JDK11,使用ZGC回收器替換G1回收器后,GC回收頻率控制在10~20s左右,回收停頓時間降低到10ms 以內。
4.2.4 分發效率優化
在之前的系統中,是基于不同業務場景的消息分發,對不同的業務場景實現消息隔離、資源隔離,在流量不高的情況下,這種實現方式簡單、靈活。但在各業務流量增大,流量不均衡的情況下,會導致不同業務場景資源利用率不均衡、處理性能不均衡。
從基于業務場景的消息分發,修改為基于資源負載數據的消息分發。針對消息不同處理階段,賦予不同的分發狀態:接收狀態、分發狀態、處理狀態、完成狀態。根據這些狀態和機器自身的負載數據,進行分發,盡可能的將消息發送到低利用率的機器上,以達到機器負載水平整體均衡的狀態。優化后的實現方式,實現難度上有所增加,系統上有一個中心化的調度服務,根據收集到的數據分發調度。調度服務不但能實現基于負載的分發,也可以定向分發、或者延遲分發。
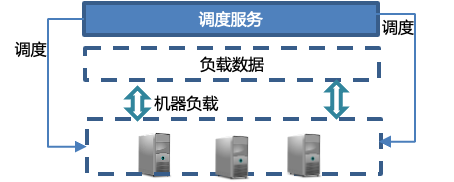
定向分發是對于某些業務場景,有特殊處理情況,可以將流量定向到某臺機器、某個集群上去處理。延遲分發,是對于某些業務場景流量不規律,短時間的流量尖刺會發送大量請求,延遲分發對流量進行平滑、延遲處理,緩解對下游服務的處理負擔。
4.2.5 異步化
如果在服務中存在一些耗時高的模塊,但是和上下鏈的模塊依賴度不高,和服務響應的關聯度也不高,那么可以考慮將高耗時的模塊異步處理,而快速返回低耗時模塊的同步處理結果。
在網關接入服務中,就符合這些異步化處理的條件。存在一些高耗時模塊,比如時長計算、音頻下載分析等模塊,而服務返回結果和這些高耗時模塊也沒有關聯。其他功能模塊和這個高耗時模塊的依賴度也不高。如果服務采用同步處理,一方面服務的響應耗時會很高,另一方面會出現線程阻塞、請求排隊的情況。采取的優化方案是將高耗時模塊后置異步處理,而其它功能模塊則同步處理,快速返回結果。優化上線后,將服務的TP999耗時從數百毫秒降低到了幾十毫秒。
4.3 數據效果
從架構1.0升級到架構2.0后,在資源利用率、系統性能、系統可靠性上都得到了提升。GPU卡的最高利用率從45%提升到75%左右;GPU卡資源占用節省了62%;線上平均耗時降低了88%,TP999耗時降低了98%。
5
總結
本文介紹了基于Kaldi的語音識別引擎的后端架構設計,在前期人力少、排期緊、流量不大的情況下,快速了完成架構1.0的上線,滿足了當時的業務轉寫需求。隨著接入場景越來越多,流量越來越大,針對架構1.0的不足進行了重構和升級,重點針對基于Kaldi的內核解碼服務的不足,進行了并發化改造優化,針對其它后端應用服務進行了拆分和性能優化,提升了GPU的利用率、以更低的資源占用處理更多的音頻數據,系統的整體性能也有了較大幅度的降低,系統可靠性得到了更好的保證。
【作者簡介】
王焱,58同城后端高級架構師,58同城TEG-AI Lab語音架構部負責人,主要負責語音識別、語音合成等語音技術的后端架構設計和開發工作。
編輯:黃飛
?














 工商網監
工商網監
評論