 電子發(fā)燒友App
電子發(fā)燒友App


2022年11月30日,ChatGPT模型問世后,立刻在全球范圍內(nèi)掀起了軒然大波。無論AI從業(yè)者還是非從業(yè)者,都在熱議ChatGPT極具沖擊力的交互體驗(yàn)和驚人的生成內(nèi)容。這使得廣大群眾重新認(rèn)識(shí)到人工智能的潛力和價(jià)值。對(duì)于AI從業(yè)者來說,ChatGPT模型成為一種思路的擴(kuò)充,大模型不再是刷榜的玩具,所有人都認(rèn)識(shí)到高質(zhì)量數(shù)據(jù)的重要性,并堅(jiān)信“有多少人工,就會(huì)有多少智能”。
ChatGPT模型效果過于優(yōu)秀,在許多任務(wù)上,即使是零樣本或少樣本數(shù)據(jù)也可以達(dá)到SOTA效果,使得很多人轉(zhuǎn)向大模型的研究。
不僅Google提出了對(duì)標(biāo)ChatGPT的Bard模型,國(guó)內(nèi)涌現(xiàn)出了許多中文大模型,如百度的“文心一言”、阿里的“通義千問”、商湯的“日日新”、知乎的“知海圖AI”、清華智譜的“ChatGLM”、復(fù)旦的“MOSS”、Meta的“Llama1&Llama2”等等。
Alpaca模型問世之后,證明了70億參數(shù)量的模型雖然達(dá)不到ChatGPT的效果,但已經(jīng)極大程度上降低了大模型的算力成本,使得普通用戶和一般企業(yè)也可以使用大模型。之前一直強(qiáng)調(diào)的數(shù)據(jù)問題,可以通過GPT-3.5或GPT-4接口來獲取數(shù)據(jù),并且數(shù)據(jù)質(zhì)量也相當(dāng)高。如果只需要基本的效果模型,數(shù)據(jù)是否再次精標(biāo)已經(jīng)不是那么重要了(當(dāng)然,要獲得更好的效果,則需要更精準(zhǔn)的數(shù)據(jù))。
1Tansformer架構(gòu)模型
預(yù)訓(xùn)練語言模型的本質(zhì)是通過從海量數(shù)據(jù)中學(xué)到語言的通用表達(dá),使得在下游子任務(wù)中可以獲得更優(yōu)異的結(jié)果。隨著模型參數(shù)不斷增加,很多預(yù)訓(xùn)練語言模型又被稱為大型語言模型(Large Language Model,LLM)。不同人對(duì)于“大”的定義不同,很難說多少參數(shù)量的模型是大型語言模型,通常并不強(qiáng)行區(qū)分預(yù)訓(xùn)練語言模型和大型語言模型之間的差別。
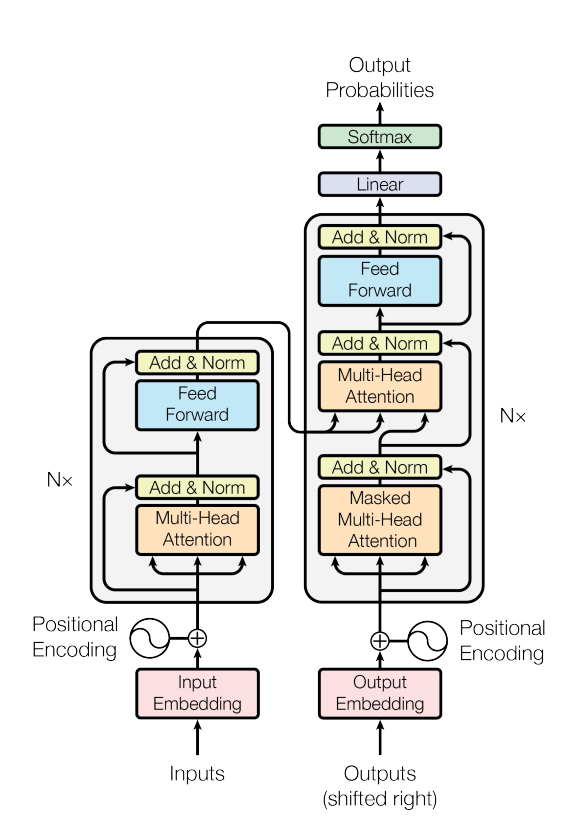
圖注:來自《Attention Is All You Need》
預(yù)訓(xùn)練語言模型根據(jù)底層模型網(wǎng)絡(luò)結(jié)構(gòu),一般分為僅Encoder架構(gòu)模型、僅Decoder架構(gòu)模型和Encoder-Decoder架構(gòu)模型。其中,僅Encoder架構(gòu)模型包括但不限于BERT、RoBerta、Ernie、SpanBert、AlBert等;僅Decoder架構(gòu)模型包括但不限于GPT、CPM、PaLM、OPT、Bloom、Llama等;Encoder-Decoder架構(gòu)模型包括但不限于Mass、Bart、T5等。
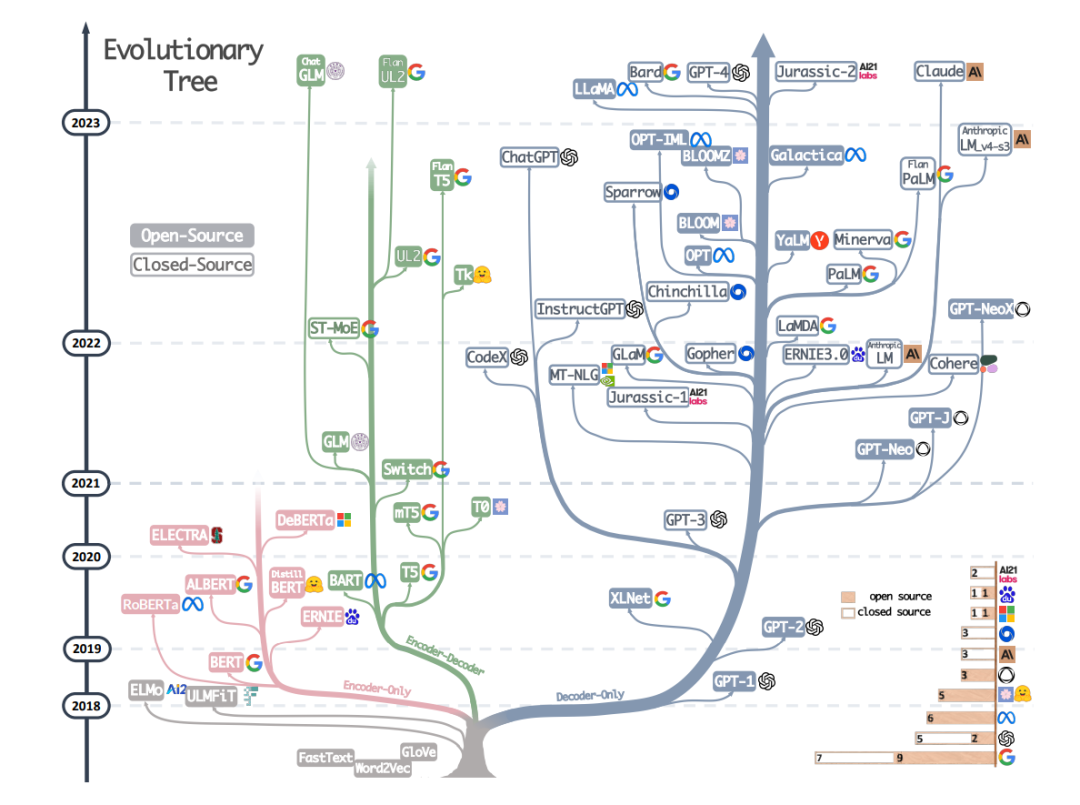
圖注:來自《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》
2ChatGPT原理
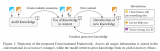
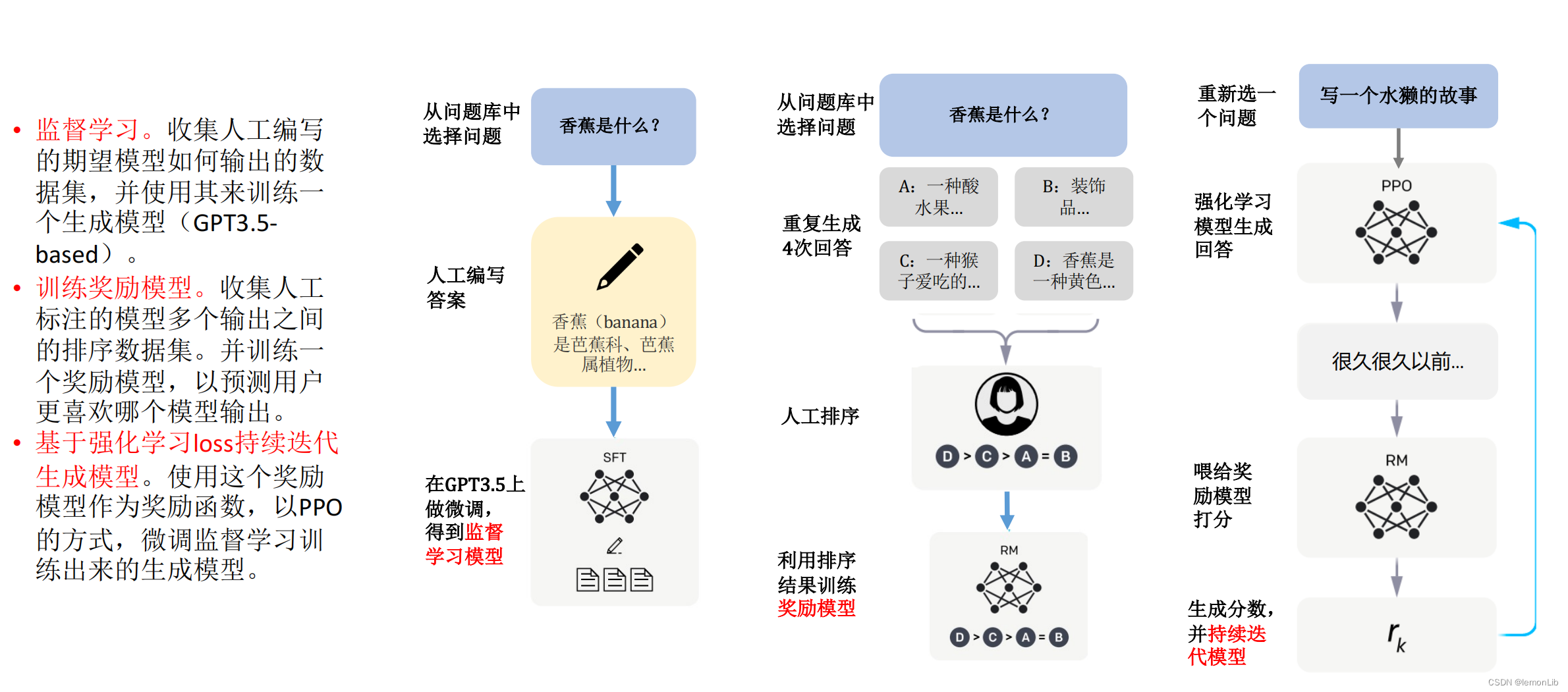
ChatGPT訓(xùn)練的整體流程主要分為3個(gè)階段,預(yù)訓(xùn)練與提示學(xué)習(xí)階段,結(jié)果評(píng)價(jià)與獎(jiǎng)勵(lì)建模階段以及強(qiáng)化學(xué)習(xí)自我進(jìn)化階段;3個(gè)階段分工明確,實(shí)現(xiàn)了模型從模仿期、管教期、自主期的階段轉(zhuǎn)變。
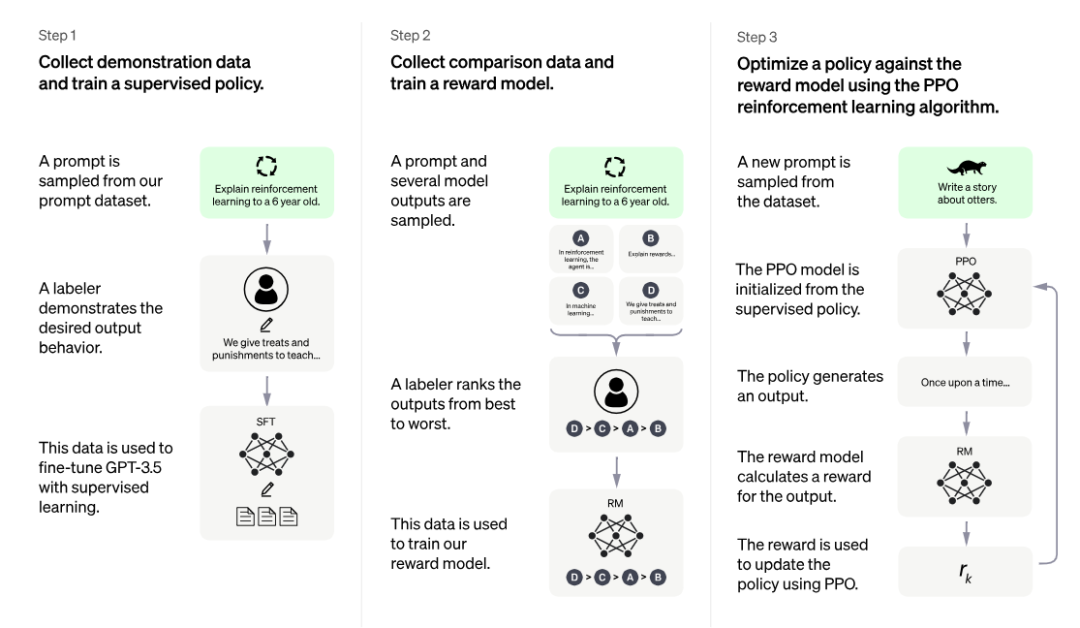
圖注:來自u(píng)rl:https://openai.com/blog/chatgpt
在第一階段的模仿期,模型將重點(diǎn)放在學(xué)習(xí)各項(xiàng)指令型任務(wù)中,這個(gè)階段的模型沒有自我判別意識(shí),更多的是模仿人工行為的過程,通過不斷學(xué)習(xí)人類標(biāo)注結(jié)果讓其行為本身具有一定的智能型。然而僅僅是模仿往往會(huì)讓機(jī)器的學(xué)習(xí)行為變成邯鄲學(xué)步。
在第二階段的管教期,優(yōu)化內(nèi)容發(fā)生了方向性轉(zhuǎn)變,將重點(diǎn)從教育機(jī)器答案內(nèi)容改變?yōu)榻逃龣C(jī)器答案的好壞。如果第一階段,重點(diǎn)希望機(jī)器利用輸入X,模仿學(xué)習(xí)輸出Y',并力求讓Y'與原先標(biāo)注的Y保持一致。那么,在第二階段,重點(diǎn)則希望多個(gè)模型在針對(duì)X輸出多個(gè)結(jié)果(Y1,Y2,Y3,Y4)時(shí),可以自行判斷多個(gè)結(jié)果的優(yōu)劣情況。
當(dāng)模型具備一定的判斷能力時(shí),認(rèn)為該模型已經(jīng)完成第二階段的學(xué)習(xí),可以進(jìn)入第三階段——自主期。在自主期的模型,需要通過左右互博的方式完成自我進(jìn)化,即一方面自動(dòng)生成多個(gè)輸出結(jié)果,另一方面判斷不同結(jié)果的優(yōu)劣程度,并基于不同輸出的效果模型差異評(píng)估,優(yōu)化改進(jìn)自動(dòng)生成過程的模型參數(shù),進(jìn)而完成模型的自我強(qiáng)化學(xué)習(xí)。
總結(jié)來說,也可以將ChatGPT的3個(gè)階段比喻為人成長(zhǎng)的3個(gè)階段,模仿期的目的是“知天理”,管教期的目的是“辨是非”,自主期的目的是“格萬物”。
3提示學(xué)習(xí)與大模型能力的涌現(xiàn) ?
ChatGPT模型發(fā)布后,因其流暢的對(duì)話表達(dá)、極強(qiáng)的上下文存儲(chǔ)、豐富的知識(shí)創(chuàng)作及其全面解決問題的能力而風(fēng)靡全球,刷新了大眾對(duì)人工智能的認(rèn)知。提示學(xué)習(xí)(Prompt Learning)、上下文學(xué)習(xí)(In-Context Learning)、思維鏈(Chain of Thought,CoT)等概念也隨之進(jìn)入大眾視野。市面上甚至出現(xiàn)了提示工程師這個(gè)職業(yè),專門為指定任務(wù)編寫提示模板。
提示學(xué)習(xí)被廣大學(xué)者認(rèn)為是自然語言處理在特征工程、深度學(xué)習(xí)、預(yù)訓(xùn)練+微調(diào)之后的第四范式。隨著語言模型的參數(shù)不斷增加,模型也涌現(xiàn)了上下文學(xué)習(xí)、思維鏈等能力,在不訓(xùn)練語言模型參數(shù)的前提下,僅通過幾個(gè)演示示例就可以在很多自然語言處理任務(wù)上取得較好的成績(jī)。
3.1 提示學(xué)習(xí)
提示學(xué)習(xí)是在原始輸入文本上附加額外的提示(Prompt)信息作為新的輸入,將下游的預(yù)測(cè)任務(wù)轉(zhuǎn)化為語言模型任務(wù),并將語言模型的預(yù)測(cè)結(jié)果轉(zhuǎn)化為原本下游任務(wù)的預(yù)測(cè)結(jié)果。
以情感分析任務(wù)為例,原始任務(wù)是根據(jù)給定輸入文本“我愛中國(guó)”,判斷該段文本的情感極性。提示學(xué)習(xí)則是在原始輸入文本“我愛中國(guó)”上增加額外的提示模板,例如:“這句話的情感為{mask}。”得到新的輸入文本“我愛中國(guó)。這句話的情感為{mask}。”然后利用語言模型的掩碼語言模型任務(wù),針對(duì){mask}標(biāo)記進(jìn)行預(yù)測(cè),再將其預(yù)測(cè)出的Token映射到情感極性標(biāo)簽上,最終實(shí)現(xiàn)情感極性預(yù)測(cè)。
3.2 上下文學(xué)習(xí)
上下文學(xué)習(xí)可以看作提示學(xué)習(xí)的一種特殊情況,即演示示例看作提示學(xué)習(xí)中人工編寫提示模板(離散型提示模板)的一部分,并且不進(jìn)行模型參數(shù)的更新。
上下文學(xué)習(xí)的核心思想是通過類比來學(xué)習(xí)。對(duì)于一個(gè)情感分類任務(wù)來說,首先從已存在的情感分析樣本庫(kù)中抽取出部分演示示例,包含一些正向或負(fù)向的情感文本及對(duì)應(yīng)標(biāo)簽;然后將其演示示例與待分析的情感文本進(jìn)行拼接,送入到大型語言模型中;最終通過對(duì)演示示例的學(xué)習(xí)類比得出文本的情感極性。
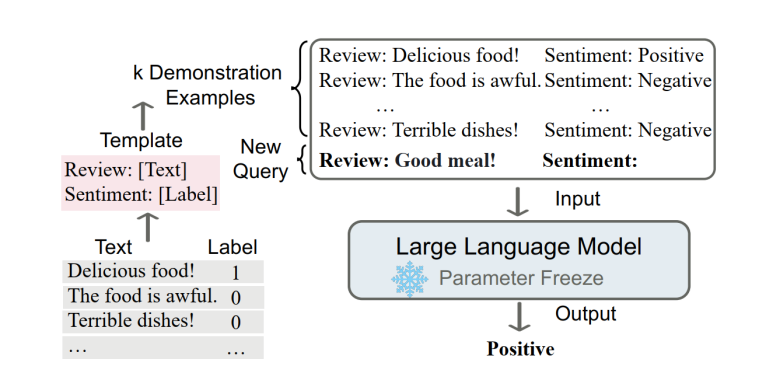
圖注:來自《A Survey on In-context Learning》
這種學(xué)習(xí)方法也更加貼近人類學(xué)習(xí)后進(jìn)行決策過程,通過觀察別人對(duì)某些事件的處理方法,當(dāng)自己遇到相同或類似事件時(shí),可以輕松地并很好地解決。
3.3 思維鏈
大型語言模型橫行的時(shí)代,它徹底改變了自然語言處理的模式。隨著模型參數(shù)的增加,例如:情感分析、主題分類等系統(tǒng)-1任務(wù)(人類可以快速直觀地完成的任務(wù)),即使是在少樣本和零樣本條件下均可以獲得較好的效果。但對(duì)于系統(tǒng)-2任務(wù)(人類需要緩慢而深思熟慮的思考才能完成的任務(wù)),例如:邏輯推理、數(shù)學(xué)推理和常識(shí)推理等任務(wù),即使模型參數(shù)增加到數(shù)千億時(shí),效果也并不理想,也就是簡(jiǎn)單地增加模型參數(shù)量并不能帶來實(shí)質(zhì)性的性能提升。
Google于2022年提出了思維鏈(Chain of thought,CoT)的概念,來提高大型語言模型執(zhí)行各種推理任務(wù)的能力。思維鏈本質(zhì)上是一種離散式提示模板,主旨是通過提示模板使得大型語言模型可以模仿人類思考的過程,給出逐步的推理依據(jù),來推導(dǎo)出最終的答案,而每一步的推理依據(jù)組成的句子集合就是思維鏈的內(nèi)容。
思維鏈其實(shí)是幫助大型語言模型將一個(gè)多步問題分解為多個(gè)可以被單獨(dú)解答的中間步驟,而不是在一次向前傳遞中解決整個(gè)多跳問題。
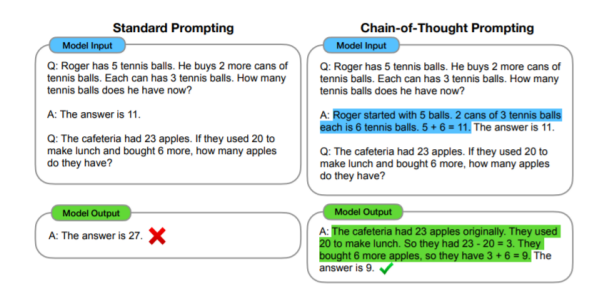
圖注:來自《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
4行業(yè)參考建議
4.1 擁抱變化
與其他領(lǐng)域不同,AIGC領(lǐng)域是當(dāng)前變化最迅速的領(lǐng)域之一。以2023年3月13日至2023年3月19日這一周為例,我們經(jīng)歷了清華發(fā)布ChatGLM 6B開源模型、openAI將GPT4接口發(fā)布、百度文心一言舉辦發(fā)布會(huì)、微軟推出Office同ChatGPT相結(jié)合的全新產(chǎn)品Copilot等一系列重大事件。
這些事件都會(huì)影響行業(yè)研究方向,并引發(fā)更多思考,例如,下一步技術(shù)路線是基于開源模型,還是從頭預(yù)訓(xùn)練新模型,參數(shù)量應(yīng)該設(shè)計(jì)多少?Copilot已經(jīng)做好,辦公插件AIGC的應(yīng)用開發(fā)者如何應(yīng)對(duì)?
即便如此,仍建議從業(yè)者擁抱變化,快速調(diào)整策略,借助前沿資源,以加速實(shí)現(xiàn)自身任務(wù)。
4.2? 定位清晰
一定要明確自身細(xì)分賽道的目標(biāo),例如是做應(yīng)用層還是底座優(yōu)化層,是做C端市場(chǎng)還是B端市場(chǎng),是做行業(yè)垂類應(yīng)用還是通用工具軟件。千萬不要好高騖遠(yuǎn),把握住風(fēng)口,“切準(zhǔn)蛋糕”。
定位清晰并不是指不撞南墻不回,更多的是明白自身目的及意義所在。
4.3? 合規(guī)可控
AIGC最大的問題在于輸出的不可控性,如果無法解決這個(gè)問題,它的發(fā)展將面臨很大的瓶頸,無法在B端和C端市場(chǎng)廣泛使用。在產(chǎn)品設(shè)計(jì)過程中,需要關(guān)注如何融合規(guī)則引擎、強(qiáng)化獎(jiǎng)懲機(jī)制以及適當(dāng)?shù)娜斯そ槿搿臉I(yè)者應(yīng)重點(diǎn)關(guān)注AIGC生成內(nèi)容所涉及的版權(quán)、道德和法律風(fēng)險(xiǎn)。
4.4? 經(jīng)驗(yàn)沉淀
經(jīng)驗(yàn)沉淀的目的是為了建立自身的壁壘。不要將所有的希望寄托于單個(gè)模型上,例如我們?cè)?jīng)將產(chǎn)品設(shè)計(jì)成純文本格式,以便同ChatGPT無縫結(jié)合,但最新的GPT4已經(jīng)支持多模態(tài)輸入。我們不應(yīng)氣餒,而是要快速擁抱變化,并利用之前積累的經(jīng)驗(yàn)(數(shù)據(jù)維度、Prompt維度、交互設(shè)計(jì)維度)快速完成產(chǎn)品升級(jí),以更好地應(yīng)對(duì)全新的場(chǎng)景和交互形態(tài)。
以上建議希望從業(yè)者加以參考。
雖然AIGC的浪潮下存在不少泡沫,但只要我們懷揣著擁抱變化的決心,始終明確我們要到達(dá)的遠(yuǎn)方,認(rèn)真面對(duì)周圍的風(fēng)險(xiǎn)危機(jī),不斷在實(shí)戰(zhàn)中鍛煉自身的能力,相信終有一天,會(huì)到達(dá)我們心中所向往的目的地。
編輯:黃飛
?
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論