 電子發燒友App
電子發燒友App


本文來自于第八屆中國機器人峰會上張東曉院士題為《科學機器學習中的知識嵌入與知識發現》的報告,通過錄音整理而成。
▍1、數據驅動模型 1.1 人工智能的發展
? “人工智能”自1956年被提出后,其發展過程可以分為三個階段(圖1)。第一代人工智能主要是知識驅動,需要定義明確且完備的規則。這雖然符合人類理解的邏輯,但是無法應對規則之外的復雜狀況(如日常對話)。第二代人工智能主要是數據驅動,需要大數據、大模型、大算力。例如AlphaGo、Chat GPT,它們依賴大量高質量的訓練數據進行自行學習,對于數據的要求高,且容易被攻擊或誤導且決策過程不清晰。對于第三代人工智能的發展,筆者認為應該是知識與數據的雙驅動模型,某種意義上是第一代和第二代的結合。 ?
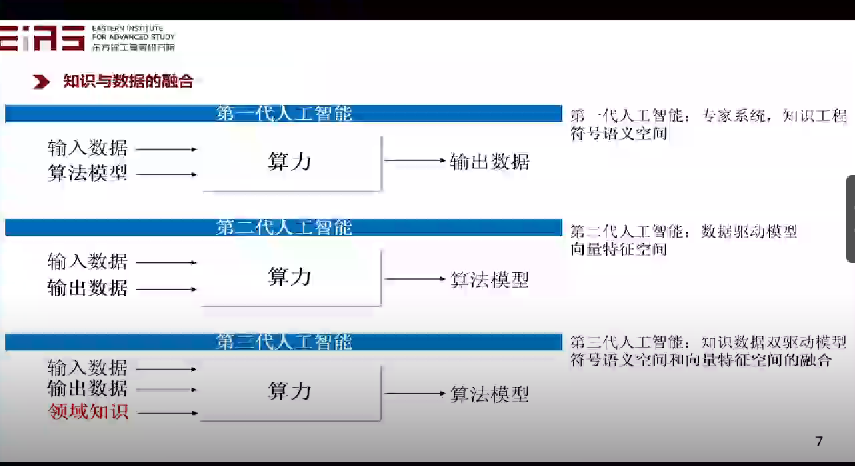
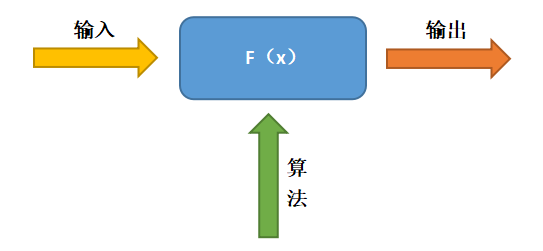
? 圖1 人工智能的發展 ? 1.2 模型驅動方法 ? 模型驅動方法(圖2)的本質是在給定“輸入”的條件下,通過施加一定“條件(或算法)”,得到最終的“輸出”。這些算法可以是確定性的,也可以是隨機的,而問題的關鍵是如何獲得模型(方程或公式),即輸入和輸出之間的映射關系或者模式,進而構造求解方程的復雜算法,同時還需要觀測值、反問題建模、數據同化等模型參數。 ?
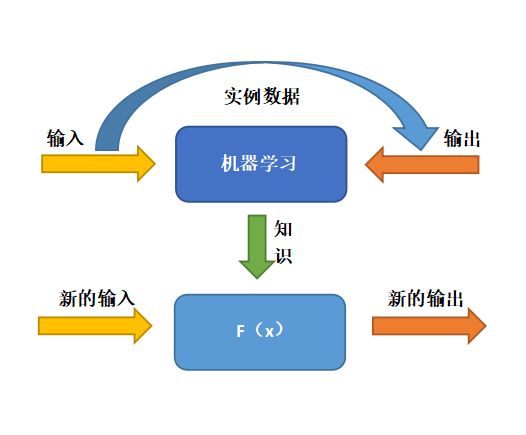
? 圖2 模型驅動方法 ? 1.3 數據驅動方法 ? 數據驅動意味著在數據和模型的天平上側重于數據,例如大數據分析、數據科學、機器學習等。數據驅動方法(圖3)的本質是在沒有對應模式的情況下,通過數據進行映射的學習,建立輸入和輸出之間的映射關系,現在的人工智能大多都是依靠數據驅動。 ?
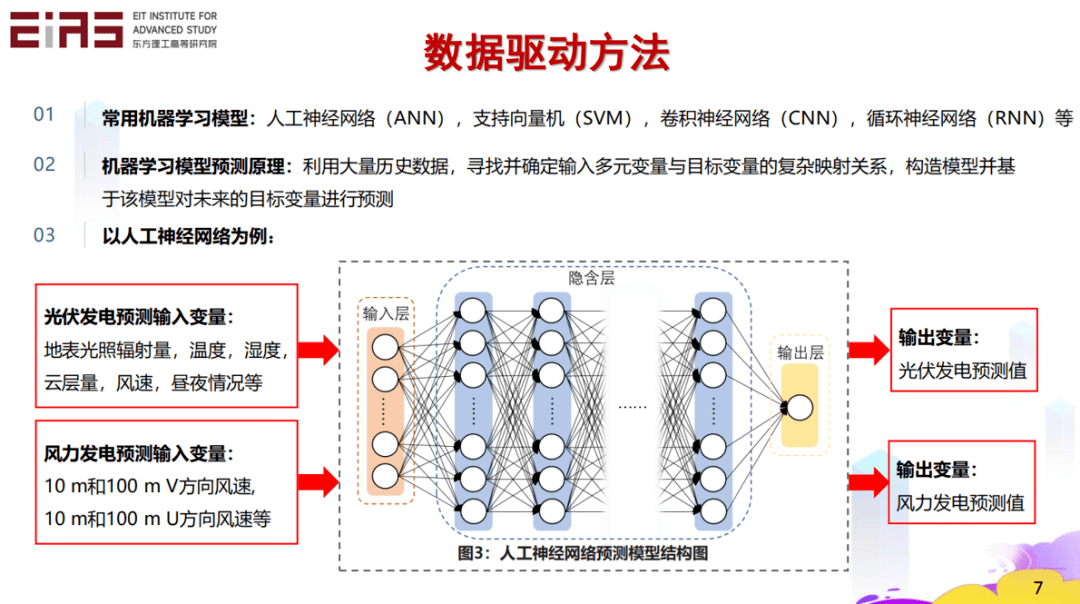
? 圖3 數據驅動方法 ? 目前,常用的機器學習模型包括人工神經網絡(ANN)、支持向量機(SVM)、卷積神經網絡(CNN)、循環神經網絡(RNN)等,通過利用大量歷史數據,尋找并確認多元輸入變量與目標變量之間復雜的映射關系,構造模型并基于該模型對未來的目標變量進行預測。 ? 以人工神經網絡為例,依靠人工神經網絡預測模型能夠對未來光伏發電值進行預測(圖4)。結合歷史發電量和歷史天氣狀況(地表光照輻射量、溫度、濕度等),通過大數據、人工智能的機器學習辦法建立一種映射關系,基于此映射關系和天氣預報數據,預測未來光伏發電值。 ?
? 圖4 基于人工神經網絡預測未來光伏發電值 ? 此外,筆者基于兩個獨立的光伏發電站獲取的數據進行試驗,將17個與光伏發電相關的天氣變量(地表光照輻射量、溫度、濕度、云層量、大氣壓強等)作為輸入的變量,采用最大最小歸一化(min-max normalization)方法,將數據限制在01之間,根據730天的訓練數據集與91天的測試數據集的天氣數據和對應光伏發電量數據進行交叉驗證設置,最終得到預測模型并實現光伏發電預測,預測的準確率高達97%。(圖5) ?
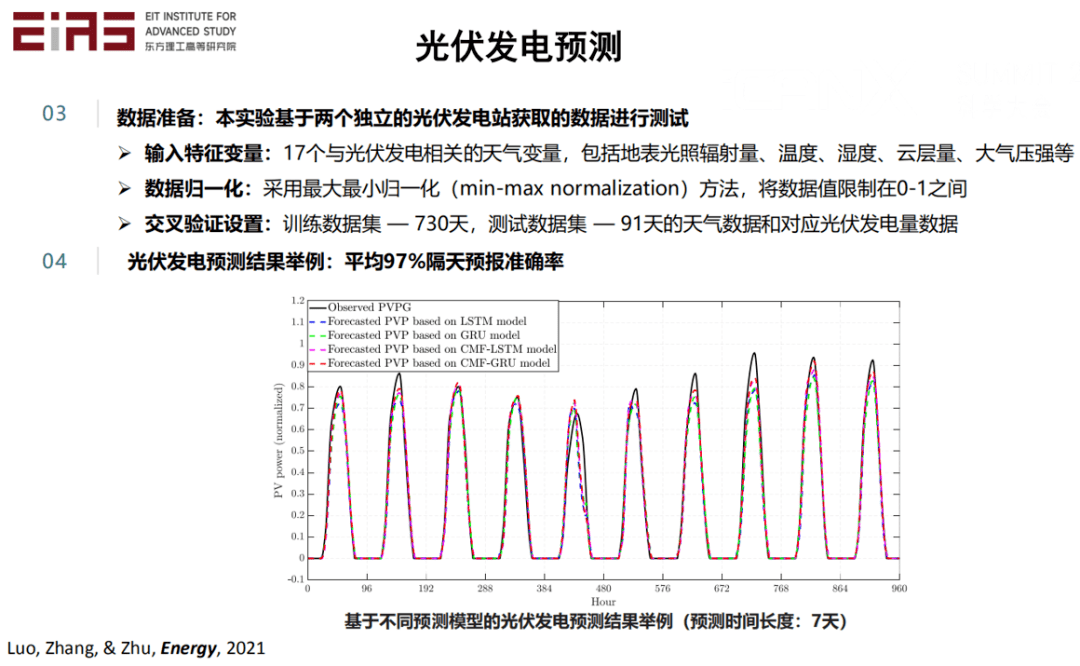
? 圖5 基于不同預測模型的光伏發電預測結果舉例(預測時間長度:7天) ? 1.4 研究背景與意義——數據驅動(連接主義AI)的局限性 ? 1.4.1 現實場景數據極度稀缺 ? 在現實應用場景中建立深度學習網絡,待訓練參數量往往上萬甚至上百萬。以Chat GPT3為例,它有96層的神經網絡,12288個隱層維度,1750億個參數,如此大的模型就需要大算力進行工作。在許多工業場景中,數據不僅有限,而且昂貴,以農業領域為例,對于地下資源勘探與開發重要的側井曲線,打一口井進行測量需要好幾千萬元;做一組吸附解析的實驗要花很長的時間,很難獲得足夠的數據基于數據驅動方法對此類問題建模。 ?
1.4.2均方誤差等指標的局限性
? 數據驅動模型中,均方誤差(Mean Squared Error,MSE)等指標帶來的局限性同樣不容忽視,MSE對誤差的物理過程是沒有區分的,比如一個系統無論是熵增還是熵減,對于MSE來講都是一樣的,但對于一個物理系統來講是不同的。基于數據平均意義上的指標往往會忽略物理過程,例如對于污染擴散的預測,一個區域的污染濃度增加,另一區域的污染濃度減少,平均的污染濃度可以不變,但事實并非如此。 ? ? 1.4.3 易被攻擊與誤導 ? 許多數據驅動的模型是不具備常識、缺少知識的。例如在對抗樣本的問題中,圖片本來是一個熊貓,加上一點輕微的噪音以后,機器可能會認為它是一個長臂猿,但這種識別錯誤不會發生在人的身上(圖6)。 ?

? 圖6 數據驅動模型的局限性 ? 早期的人工智能模型都是知識驅動的,例如DENDRAL系統對于有機化學結構的分析、MYCIN系統對于血液傳染病的診斷、Deep Blue戰勝國際象棋世界冠軍,但它們都是按照規則研制而成,只能解決規則范圍內的問題,難以處理復雜的現實問題。這也是基于數據驅動的人工智能模型被廣泛推廣的原因之一。 ? 如今,數據驅動方法尚且存在許多的不足,僅以能源行業為例,行業面臨著對模型的魯棒性和解釋性要求高、數據采集費時且成本高昂等問題,只有構建知識與數據的雙驅動模型——既有人工智能技術,也有相關領域知識,還有觀測數據,相互的融合才能實現一個智慧能源系統(圖7),提升模型精度和魯棒性,降低對數據的需求。而智慧能源系統作為知識與數據的雙驅動模型,一方面,需要通過理論指導的數據驅動模型(知識嵌入),從而構建具有物理常識的AI模型;另一方面,利用人工智能進行數據驅動的模型挖掘(知識發現),從觀測數據中提煉物理知識。當知識嵌入和知識發現可以形成一個閉環,實現知識和數據的融合,能夠很好地解決仿真模擬,反問題,可解釋性等問題。 ?
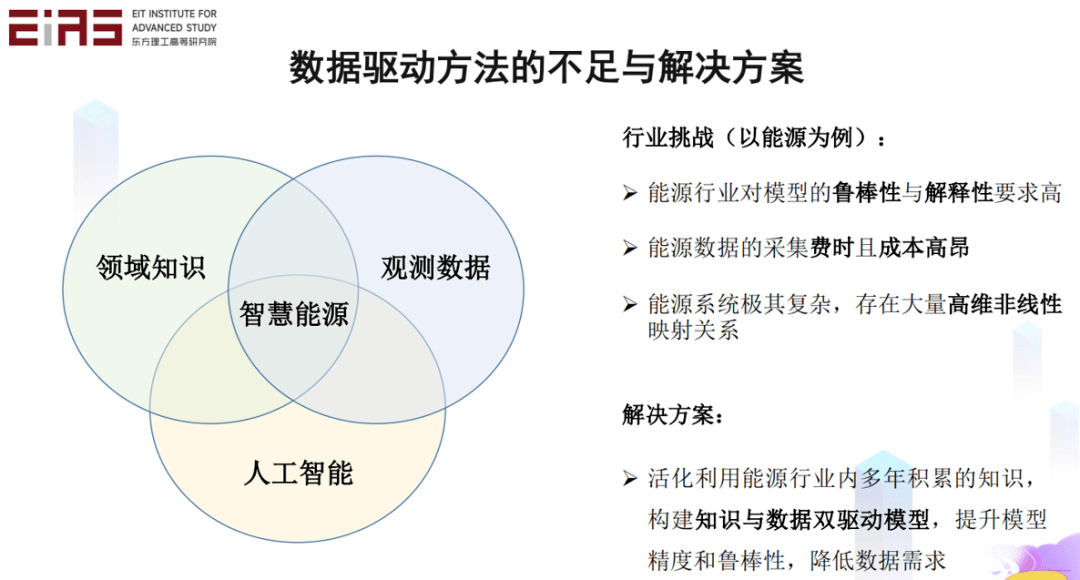
? 圖7 智慧能源系統 ? ▍2、理論指導的數據驅動模型(知識嵌入) ? 理論指導的數據驅動模型是指在建模全流程中進行知識嵌入,構建具有物理常識的AI模型。圖8所示為機器學習建模全流程的知識嵌入方法。一方面借助機器學習的強擬合能力,描述變量間高維復雜映射關系,另一方面利用能源領域內的先驗知識,保證預測結果符合物理機理,構建物理上合理、數學上準確、計算上穩定高效的模型。因此,知識嵌入的核心問題在于四個方面,一是復雜形式控制方程的嵌入方法;二是控制方程以外的通用知識的嵌入方法;三是不規則物理場的知識嵌入方法;四是損失函數中正則項權重的自動調整策略。 ? ? 以智慧能源系統為例,在建模過程的多個環節都可以進行知識嵌入,在數據預處理環節,可以嵌入物理約束和人類的領域知識和先驗經驗;在模型結構設計環節,可以基于領域知識調整模型的網絡結構或者拓撲結構;在模型效果評估環節,可以構建特殊設計的損失函數。 ?
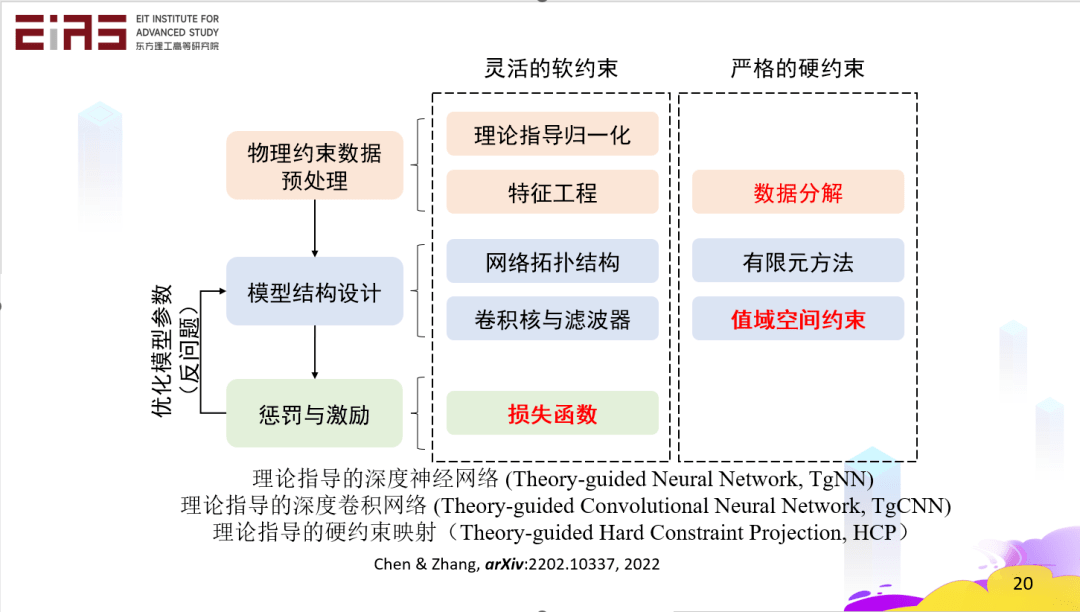
? 圖8 機器學習建模全流程的知識嵌入方法示意圖 ? 2.1 在數據預處理環節嵌入領域知識 ? 在電網負荷預測模型(圖9)的研究中,電力系統基于機器學習模型中的集合神經網絡(ENN)和長短期記憶神經網絡(LSTM),在數據預處理環節引入電力負荷比值分解的方法來嵌入知識,把電力負荷數據分解成一個大的趨勢和局部擾動,大的趨勢反映了預測區域的內在模式,比如能源結構、產業結構、人口密度等,是根據歷史數據和專家經驗來確定的。局部擾動則是系統受到天氣等外驅力影響下所產生的變化,通過數據驅動模型來預測。最終,將大的趨勢和小的擾動結合。 ?
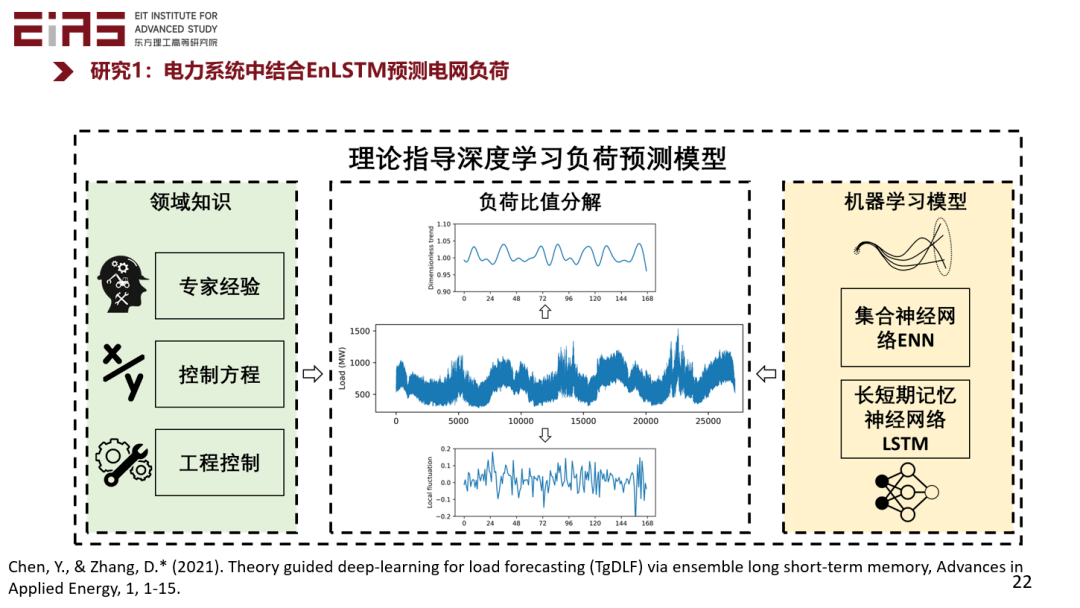
? 圖9 電網負荷預測模型 ? 使用上述方法,基于北京12個區歷史1362天小時級別的真實電力負荷數據進行試驗驗證,預測北京市豐臺區電力負荷(圖10),其中紅色為預測值,黑色為真實值,灰色為置信區間,即使沒有利用預測區域的數據,僅使用周邊區域的數據進行訓練,模型也能夠非常準確地進行電力負荷預測。 ?
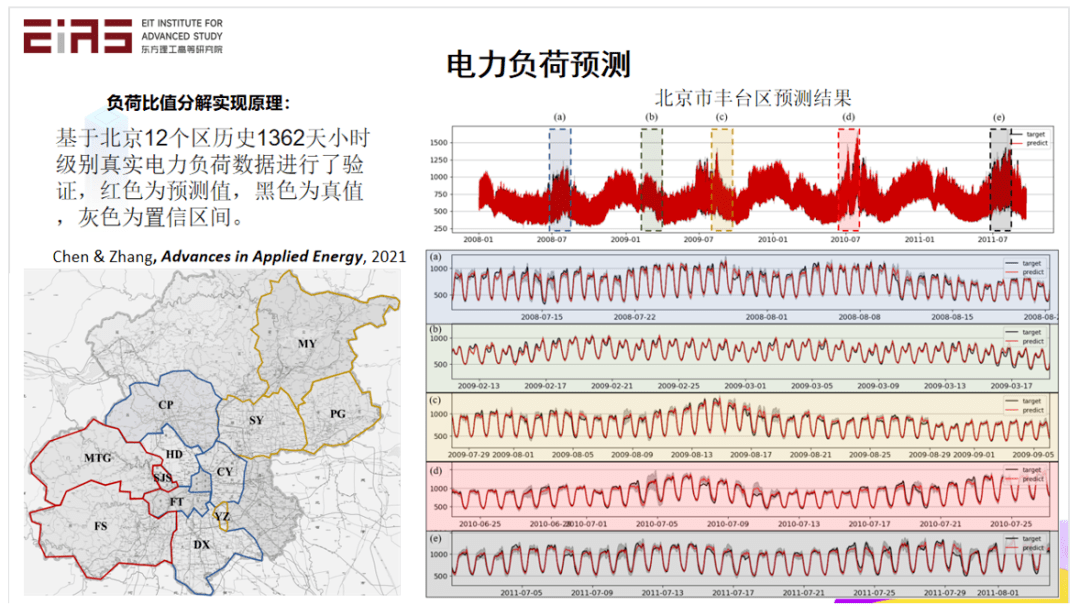
? 圖10 北京市豐臺區電力負荷預測結果 ? 2.2?在模型效果評估階段嵌入領域知識 ? 2.2.1 將概率分布信息作為約束嵌入AI模型 ? 與光伏類似,風力發電也具有強烈的隨機性和波動性,風功率的準確預測有助于提高電網運行的穩定性,能夠有效地幫助電網調度部門做好各類電源的調度計劃。對此,筆者及其團隊成員研發了融合領域知識的風功率預測模型(圖11),根據風電區域的風向、風機轉速、槳距角和實際風功率等數據建立精準風功率預測模型,并嵌入風功率曲線這一物理知識以提高預測準確度。由于實際工況復雜,風功率曲線并非一個一對一的映射,而是需要用描述風速和發電功率之間關系的概率分布函數來表征。從歷史數據得到先驗的風功率曲線,然后通過改造損失函數,將其嵌入到模型的訓練過程中,最終結合天氣預報與氣象觀測站,形成一套軟硬結合的物理與數據雙驅動的風力發電功率預測產品。 ? ?
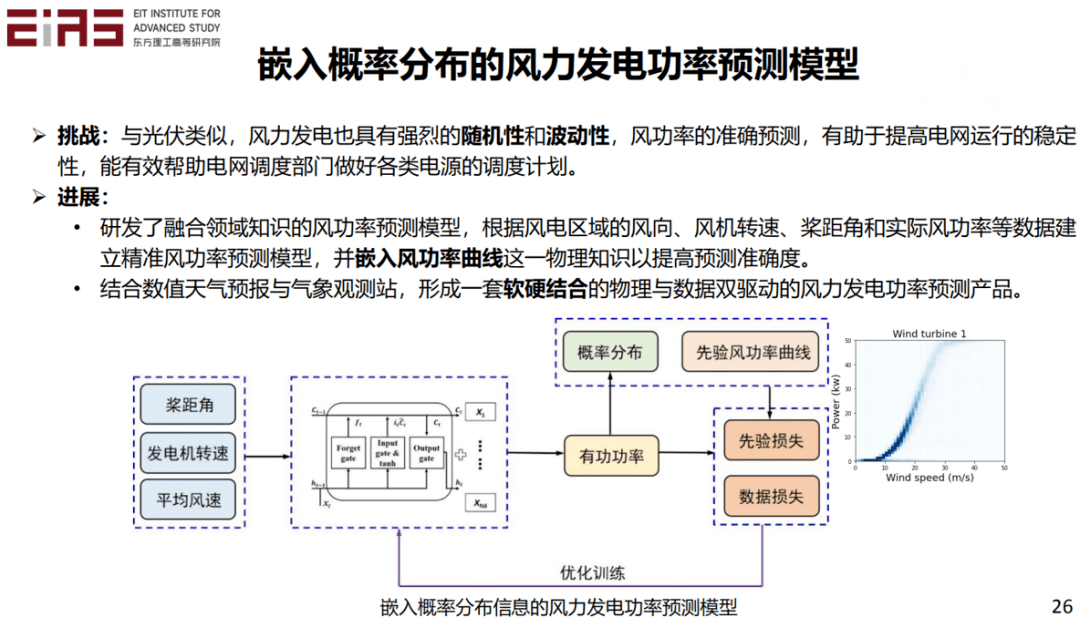
? 圖11 嵌入概率分布信息的風力發電功率預測模型 ? 通過這種方法建立的人工智能模型不僅具有數據驅動的優勢,還能保證輸出結果符合先驗的概率分布。將基于氣象數據和風功率曲線的風功率預測結果與真實值進行對比(圖12),預測準確率高于90%。 ?
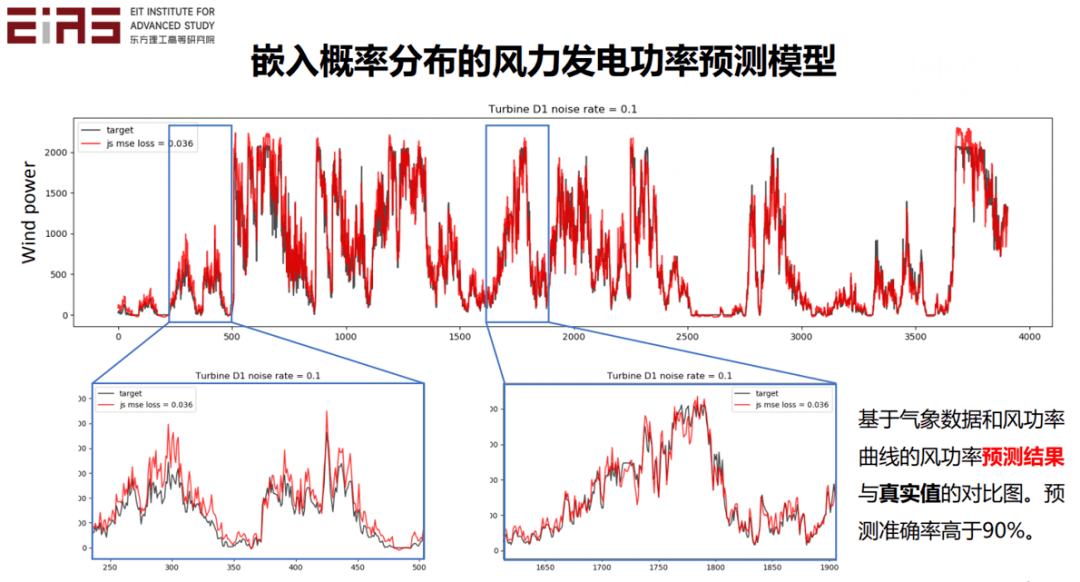
? 圖12 數據對比圖 ? 2.2.2 將控制方程作為約束嵌入AI模型 ? 在模型效果評估階段嵌入領域知識的方法,主要是基于改進損失函數的方法將控制方程作為約束嵌入到人工智能的模型中,這對于大數據量的求解非常有幫助,并且能減小預測的誤差。 ?
基于理論指導神經網路(Theory-guided Neural Network,TgNN)的替代模型(圖13)具有理論指導的深度學習模型框架,將物理規律、工程控制、專家經驗等先驗信息融合到深度學習模型的訓練中,實現更高的預測準確性、更好的可解釋性、更強的魯棒性。在理論指導下,TgNN替代模型可以在較少的訓練數據的情況下進行構建,減小對數據量的依賴,例如,用基于TgNN/物理信息神經網絡(Physics-informed Nerual Network,PINN)替代模型進行不同滲透率場實現的解的預測(圖14),訓練過程中僅使用30個現實提供的訓練數據就達到了足夠的精度。
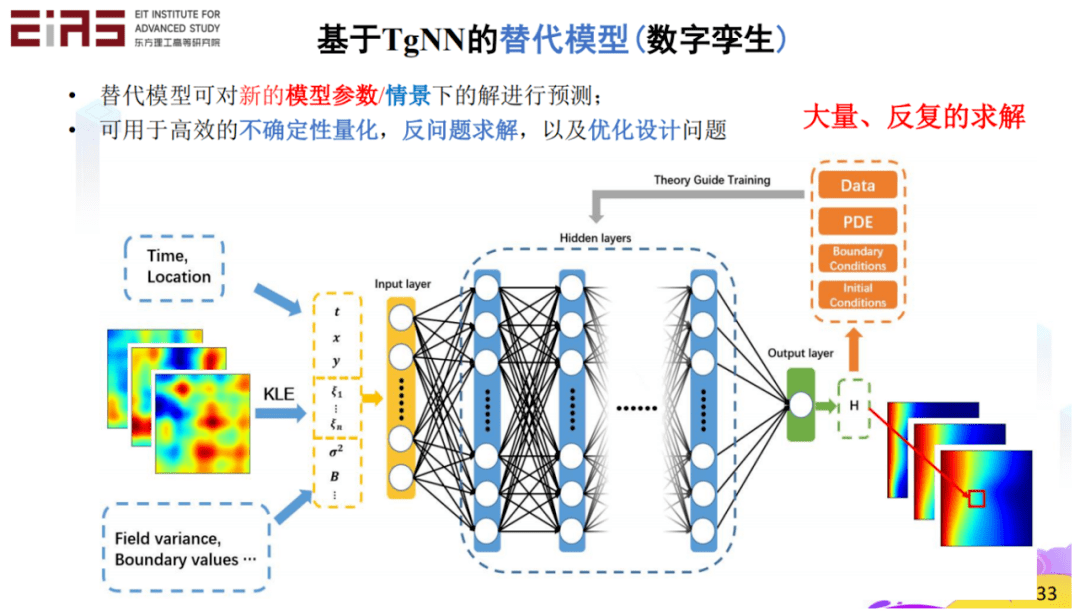
? 圖13 基于TgNN的替代模型 ?
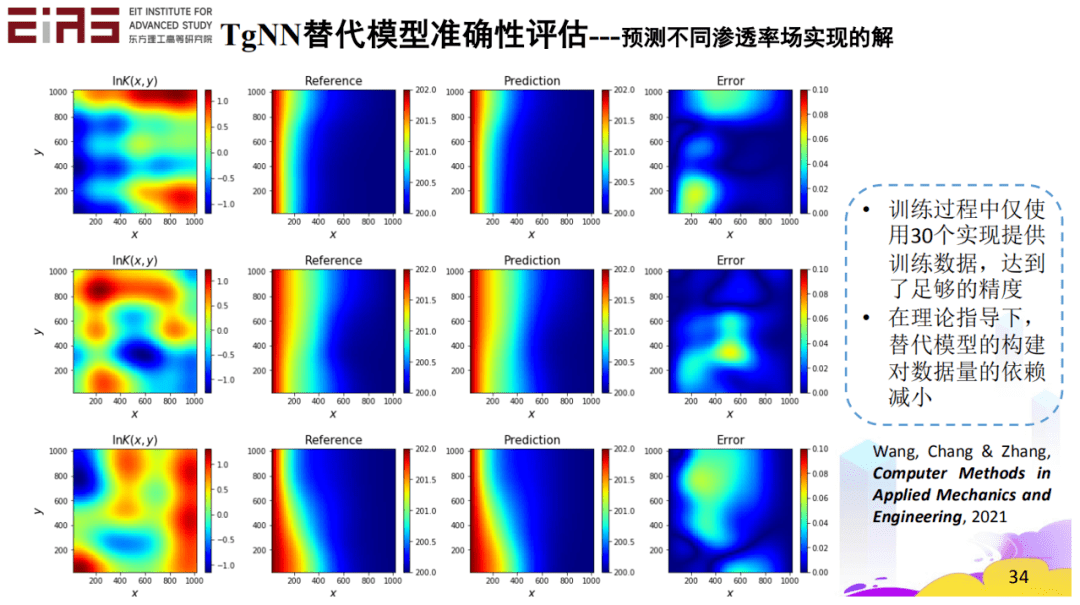
? 圖14 TgNN/PINN替代模型準確性評估——預測不同滲透率場實現的解 ? 此外,將TgNN替代模型應用于工程問題中的不確定性量化(圖15),能夠大大提升不確定性量化任務的效率。以蒙特卡羅方法(MC)作為參考值,使用KL展開生成10000個實現,使用MODFLOW求解,所需時間約為1.74h;使用TgNN替代模型預測求解,因為神經網絡的預測速度很快,因此只需要大約9min,TgNN替代模型顯著提高了不確定性量化的效率。 ?
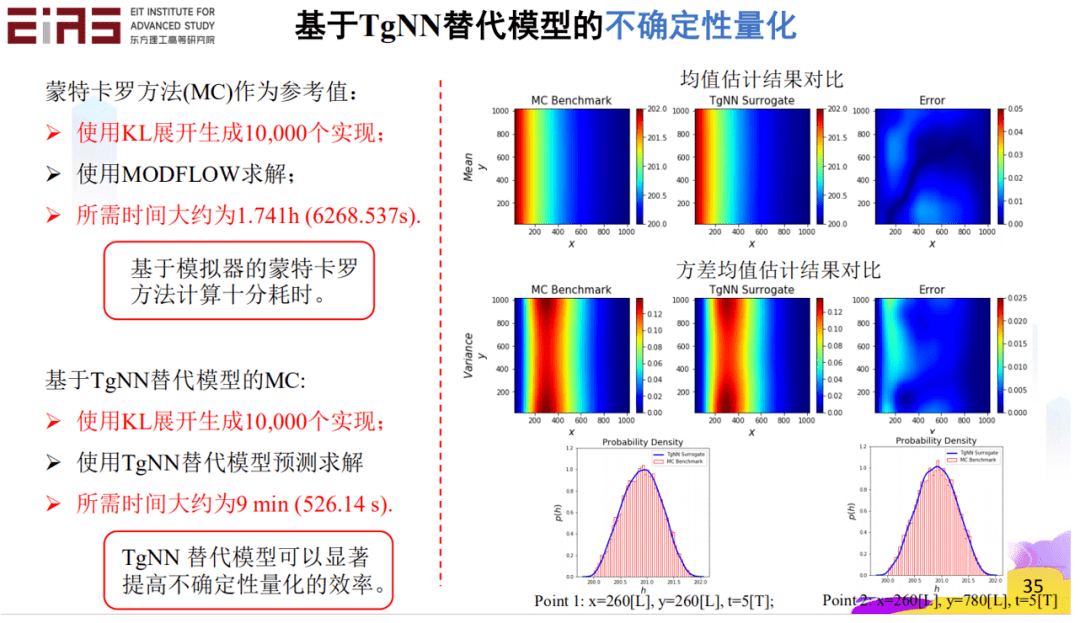
? 圖15 基于TgNN/PINN替代模型的不確定性量化 ? 面對復雜問題,例如兩相流(油—水、油—氣)問題——同時預測壓力和飽和度(圖16、17),在兩個方程組的情況下,利用控制方程也能進行高效預測。 ?
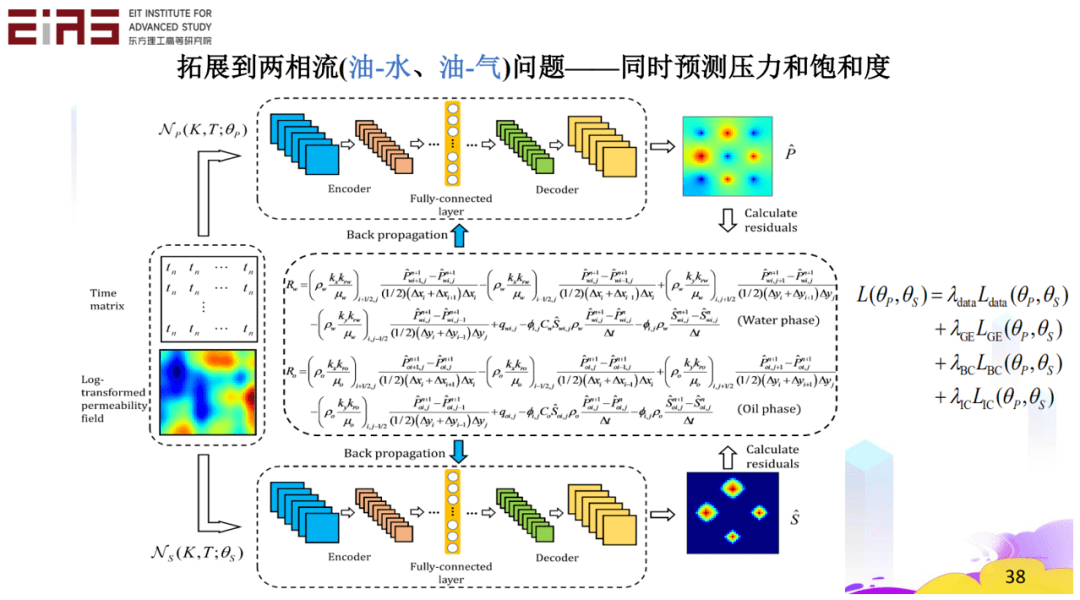
? 圖16 兩相流(油—水、油—氣)問題 ?
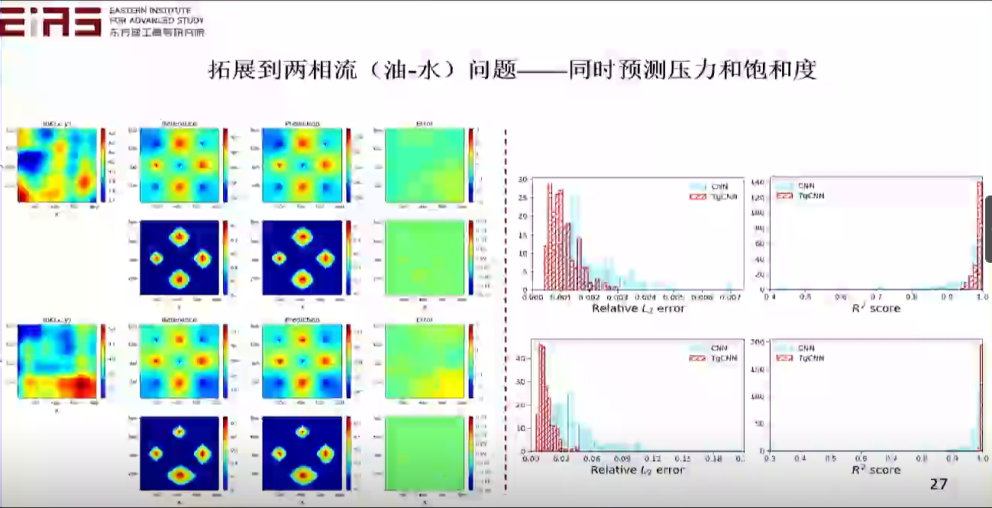
? 圖17 兩相流(油—水、油—氣)問題預測結果 ? 2.3 在模型結構設計和效果評估階段嵌入領域知識 ? 利用軟約束嵌入控制方程雖然易于實現但只能產生平均意義上符合物理約束的預測結果,相比之下,硬約束能通過映射的方式(圖18),利用投影矩陣,將模型輸出值映射到嚴格符合物理機理的值域,保證局部嚴格滿足物理約束,具有更高的收斂速度和更低的數據需求。 ?
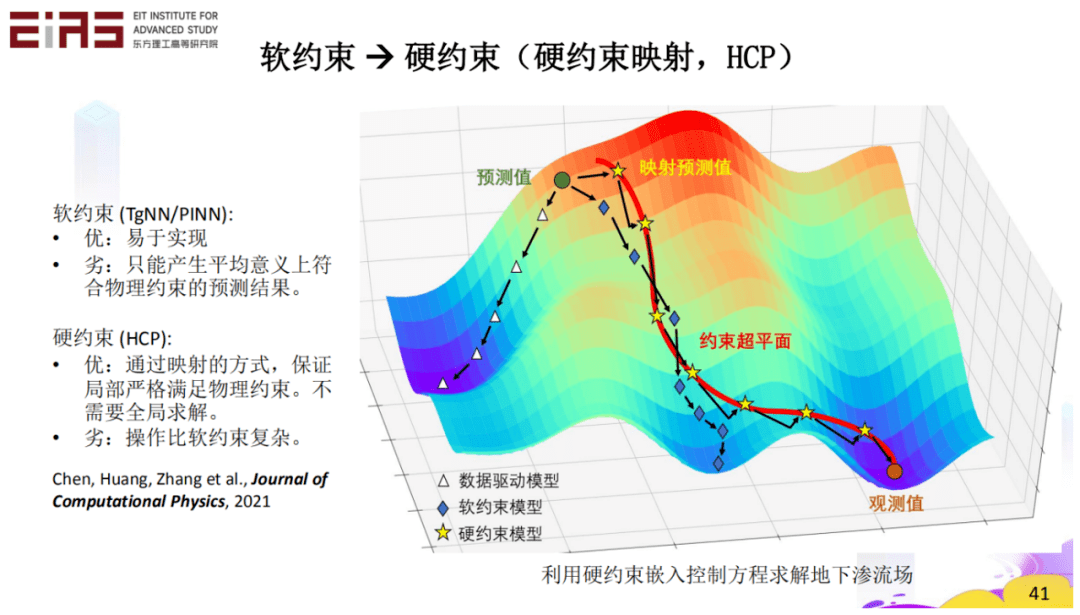
? 圖18 利用硬約束嵌入控制方程求解地下滲流場的硬約束映射 ? ?
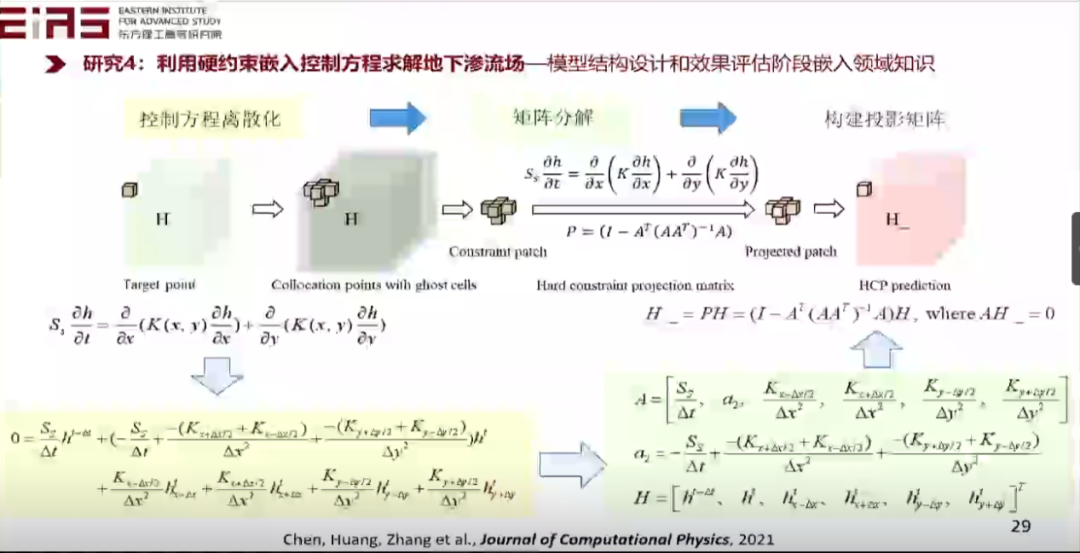
? 圖19 利用硬約束嵌入控制方程求解地下滲流場投影矩陣構建 ? ?
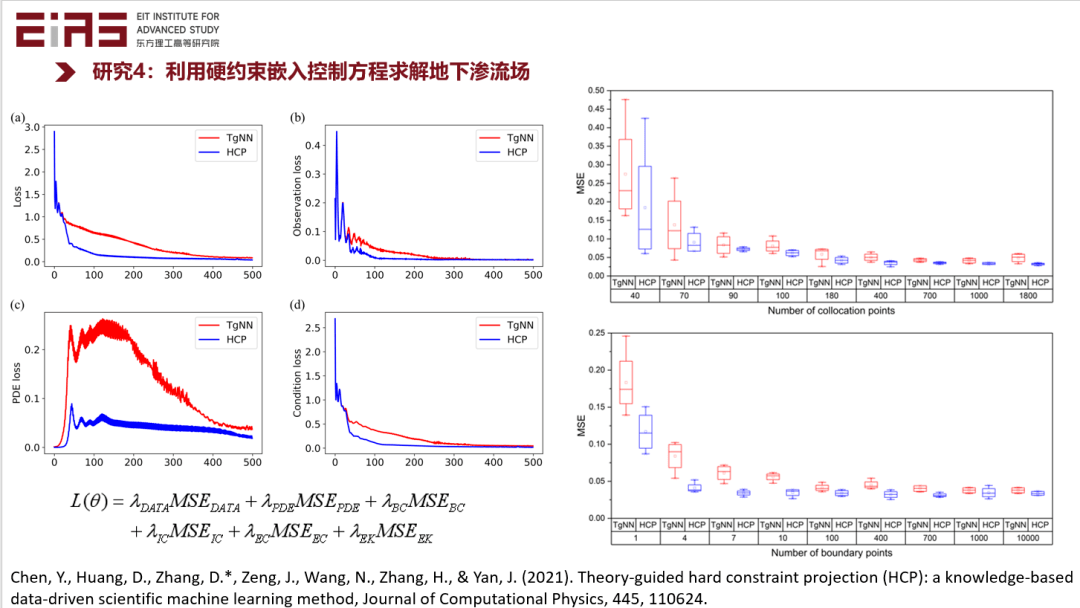
? 圖20 利用硬約束嵌入控制方程求解地下滲流場的效果評估 ? ? 在實際嵌入知識的過程中存在大量難點,尤其是嵌入復雜方程,如具有分式結構或者復合函數的方程,難以直接利用神經網絡的自動微分機制求梯度,因此也難以直接嵌入到人工智能模型中,因此,筆者在研究的過程中開發了自動化知識嵌入框架及工具包(圖21、22)。 ?
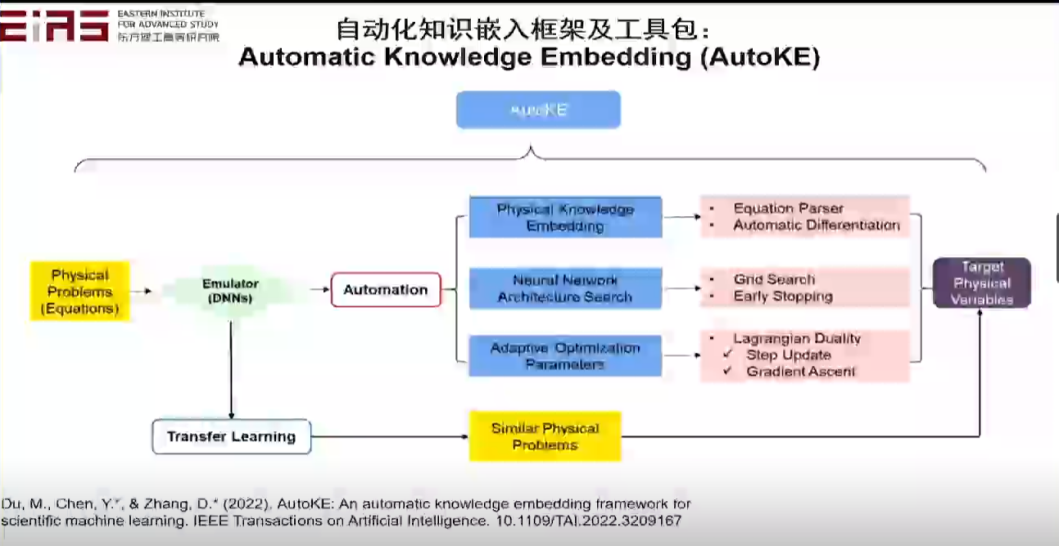
? 圖21 自動化知識嵌入框架及工具包(1) ? ?
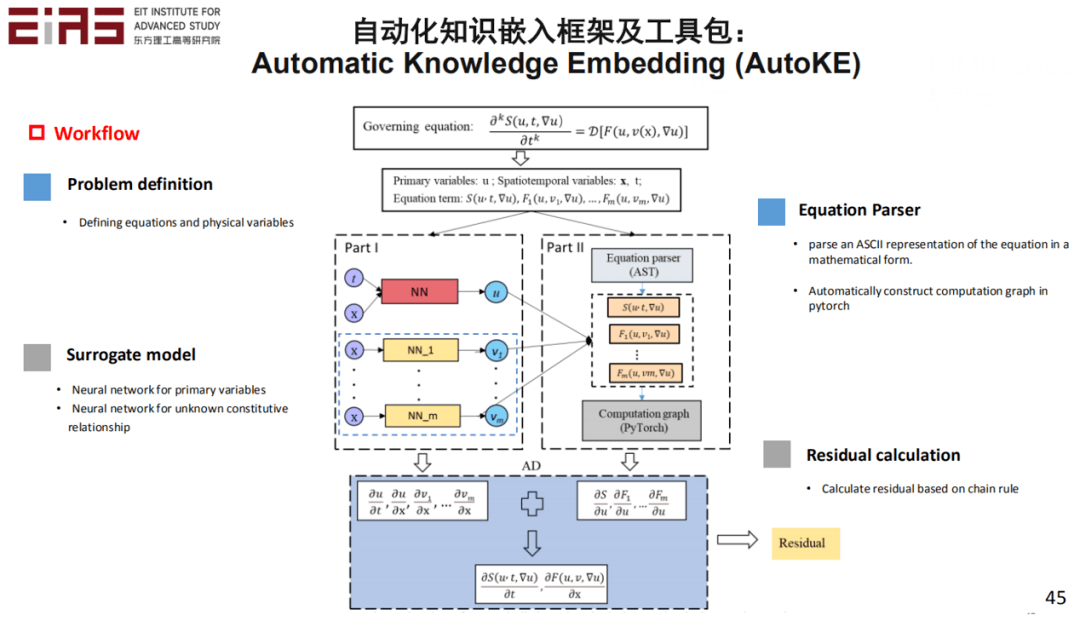
? 圖22 自動化知識嵌入框架及工具包(2) ? ▍3、數據驅動的模型挖掘(知識發現) ? 知識發現是指從觀測數據中提煉物理知識,借助人工智能自動探索物理原理,推進人類認知前沿,同時迭代利用發現的知識,即結合知識嵌入,形成知識和數據的閉環系統。其核心問題在于五個方面:一是控制方程的靈活表示方法以及優化算法;二是復雜結構控制方程的挖掘方法;三是復雜系數控制方程的挖掘方法;四是針對稀缺且嘈雜的數據的挖掘方法;五是從實驗數據中挖掘全新的控制方程。 ? 3.1 從行星運動三大定律的提出看控制方程的挖掘 ? 第谷耗時38年觀測火星軌跡數據,但是他沒有找到規律;第谷的學生開普勒耗時17年研究數據,最后總結出行星運動三大定律;在此基礎上,牛頓發現了萬有引力定律。而AI技術的發展將大大加快這一進程,根據數據找出內在規律,這一過程需要發揮機器學習算法描述高維非線性映射的優勢,從實驗數據中直接挖掘新的知識,加深對物理本質的理解。 ? 3.2 從人工智能的發展看控制方程的挖掘 ? 神經網絡作為傳統的機器學習的研究方向,實際上是一種黑盒模式(圖23),其可解釋性差,但隨著人工智能的發展,通過模型挖掘顯式表達出神經網絡的內部邏輯(控制方程),能夠提高可解釋性。 ? ?

? 圖23 神經網絡 ? ? 3.3 數據驅動的偏微分方程挖掘
利用機器學習方法從數據中直接發現潛在的物理過程及其控制方程。
3.3.1 封閉候選集方法:稀疏回歸 ? 在具備數據的情況下就可以得到它的梯度和各階導數。理論上系統中可能存在許多項,但是實際的方程是稀疏的,它只有其中的幾項,其他的項的系數都是0,所以那些項是不存在的。這樣問題就轉化成,在一個系統中如何找到稀疏的向量,而且它的系數也能同時找出來。利用稀疏回歸進行偏微分方程的挖掘(圖24),能夠從數據中識別出時間導數、潛在偏微分方程的項以及稀疏的系數向量。 ?

? 圖24 稀疏回歸挖掘偏微分方程 ? 3.3.2 半開放候選集方法:遺傳算法 ? 稀疏回歸的前提是項(候選集)的存在,在項不完全存在的情況下,則需要通過遺傳算法(Genetic Algorithm,GA)挖掘控制方程。遺傳算法是一種最基本的進化算法,它是模擬達爾文生物進化理論的一種優化模型,最早由J.Holland教授于1975年提出。遺傳算法中種群中的每個個體都是解空間上的一個可行解,通過模擬生物的進化過程,進行遺傳、變異、交叉、復制從而在解空間內搜索最優解。 ? 在KdV方程的挖掘(圖25)中,遺傳算法比稀疏回歸更為有效,這是因為對于更大的備選集,DL-PDE中使用稀疏回歸時將需要更大的稀疏性,這會增加挖掘難度。DLGA-PDE可以在非完全備選集的情況下挖掘PDE,并且待挖掘的PDE項可以通過基因組的變異和交叉產生,可以避免出現DL-PDE中遇到的備選集大小問題。 ?
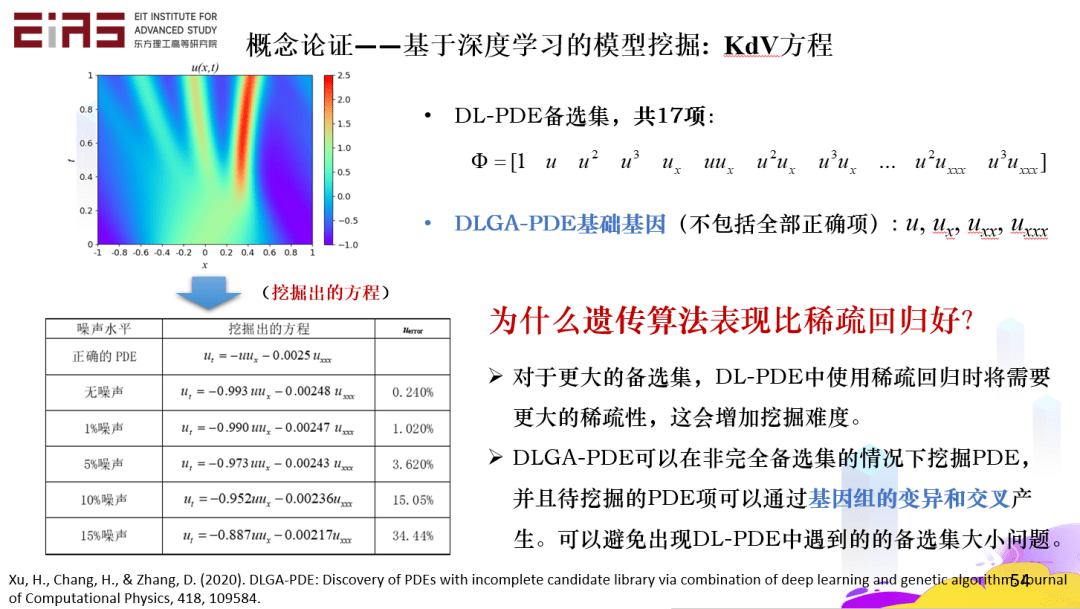
? 圖25 基于深度學習的模型挖掘——KdV方程 ? 3.3.3 開放候選集方法:符號數學 ? 在一個自變量、一個因變量的情況下,定義一些運算符、運算法則,那么方程的每一項都是一個樹的結構,再通過一次次變異去改變樹的結構,就可以挖掘出控制方程(圖26),即使是比較復雜的方程也能被挖掘,這只需要自變量和因變量。
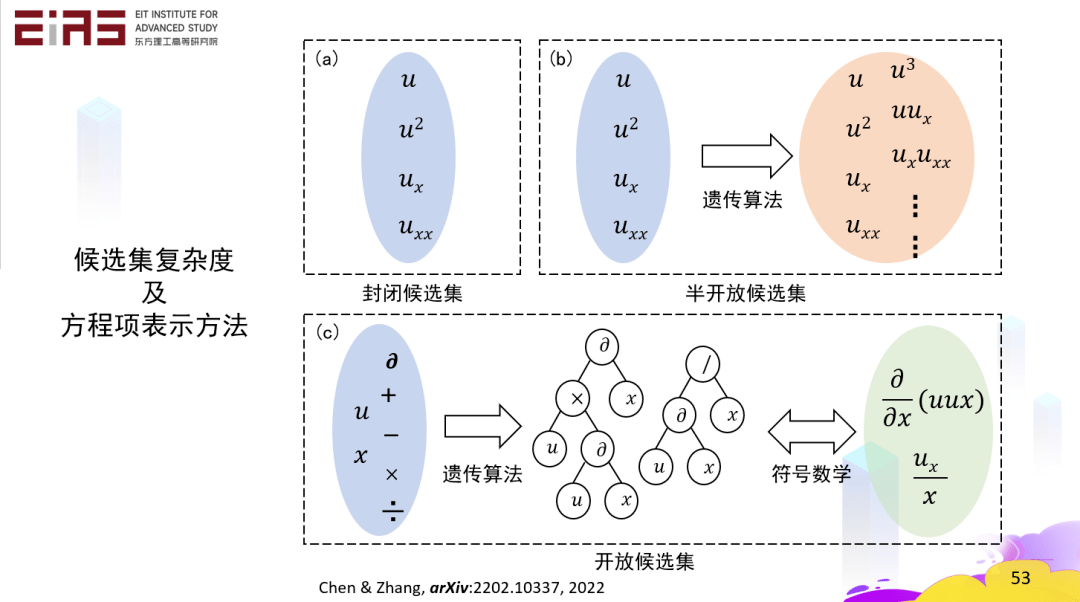
? 圖26 候選集復雜度及方程項表示方法 ? 3.4 基于知識發現和符號數學實現控制方程自挖掘(生產知識) ? 找到最適合數據的偏微分方程的關鍵在于解決兩個問題,一是如何通過符號數學表示任何給定的復雜開放式偏微分方程,二是如何使用機器學習算法從偏微分方程的無限可行域中挖掘正確的方程。 ? 引入符號回歸中樹結構的概念,在開放空間中挖掘方程形式,每一項都可以變成一個樹的結構,這個樹由節點構成,父節點為運算符(包括偏微分算符),子節點為系數、變量或函數,對樹結構的深度和廣度都可以調整,表明樹或者說方程的項的復雜程度(圖27)。如此一來,任何方程都是一片森林,森林里的樹代表不同的方程項,通過遺傳算法、符號數學等方式能夠挖掘出自由形式的方程,即使方程的形式非常的復雜。(圖28) ?
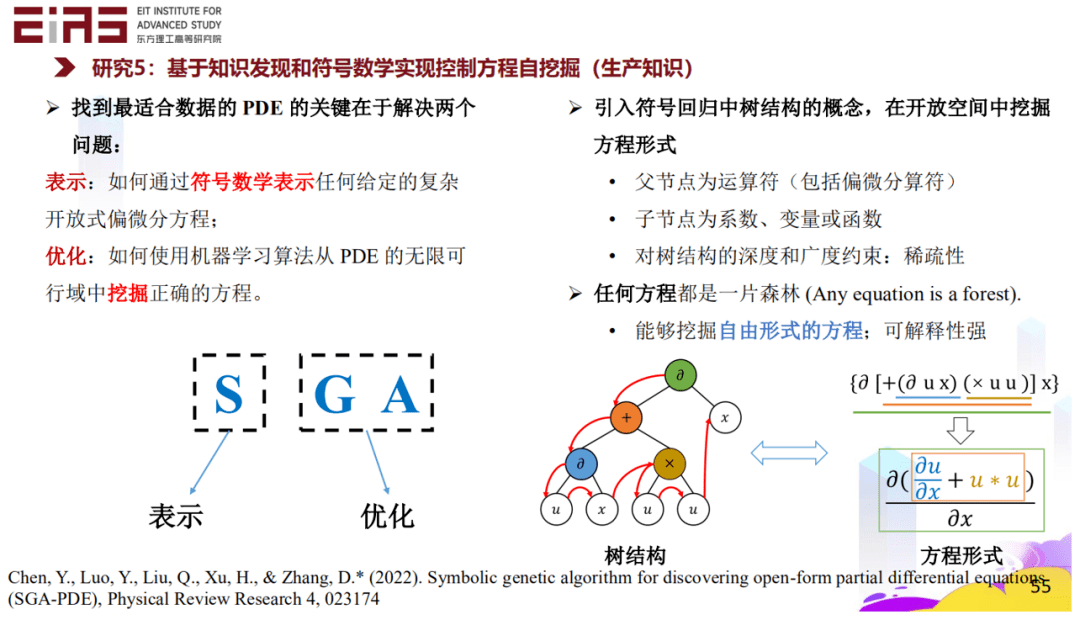
? 圖27 基于樹結構挖掘自由形式的方程 ?
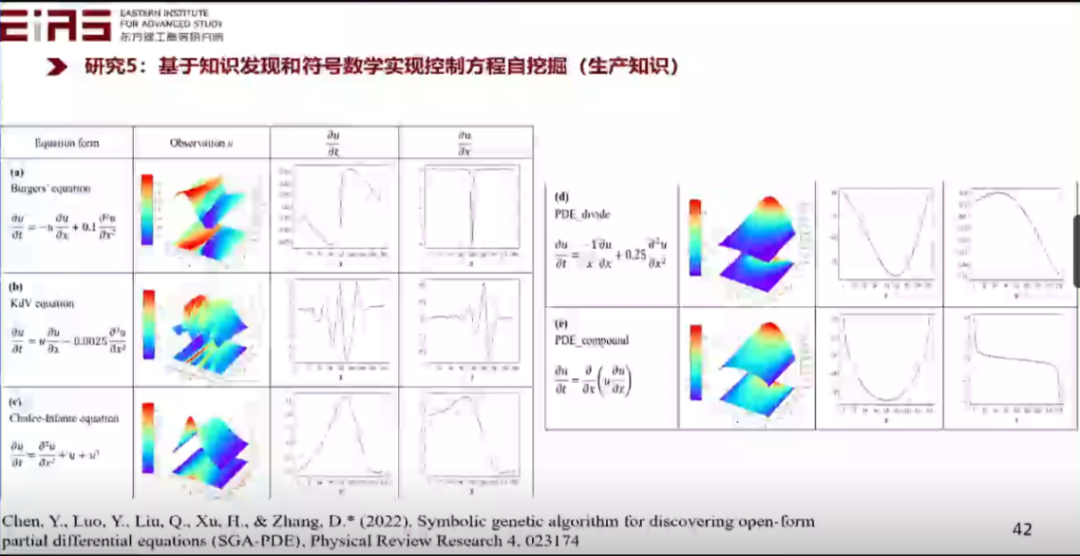
? 圖28 基于知識發現和符號數學實現控制方程自挖掘 ? 3.4.1 挖掘“分式結構方程” ? ? 在分式結構方程的挖掘過程中,初始有一個自變量、因變量,在第一代迭代后可能找出了這些簡單的項,但這些項是不正確的,再經過幾十代的迭代,不斷地交叉、變異、進化,最后挖掘出正確的方程(圖29、30),即使這是一個極其復雜的方程。 ?
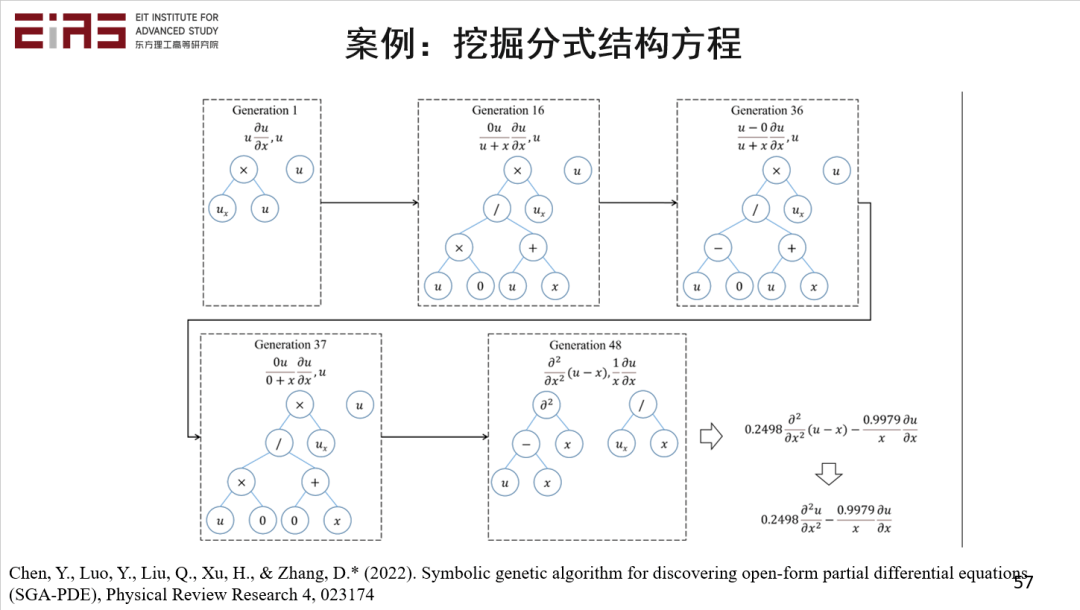
? 圖29 挖掘“分式結構方程”(1) ? ?

? 圖30 挖掘分式結構方程(2) ? 3.4.2 從細觀模擬數據中挖掘粘性重力流的宏觀控制方程 ? 知識發現也可以用來解決實際的問題,比如粘性重力流問題,通過控制方程的自挖掘,最終也能成功驗證其數學上的合理性、物理上的預測性。粘性重力流的短期行為尚不存在控制方程,在這種情況下,通過精細的微觀數據模擬得到數據,并利用這些數據進行學習,挖掘宏觀控制方程(圖31、32、33、34)。 ? 為了從數據空間中的原始仿真數據挖掘出語義空間中的可解釋的物理定律(PDE),需要以下三個步驟:數據重構,基于深度神經網絡(DNN)的替代模型訓練;構造語義片段,計算空間導數和積分通量;語義整合,基于遺傳算法挖掘出的簡約偏微分方程。 ?
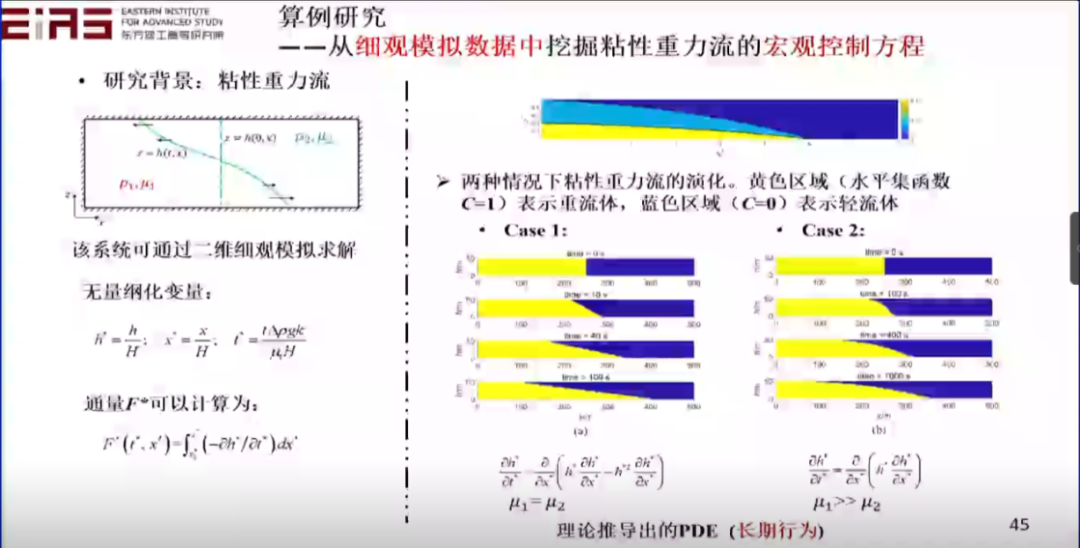
? 圖31 從細觀模擬數據中挖掘粘性重力流的宏觀控制方程 ?
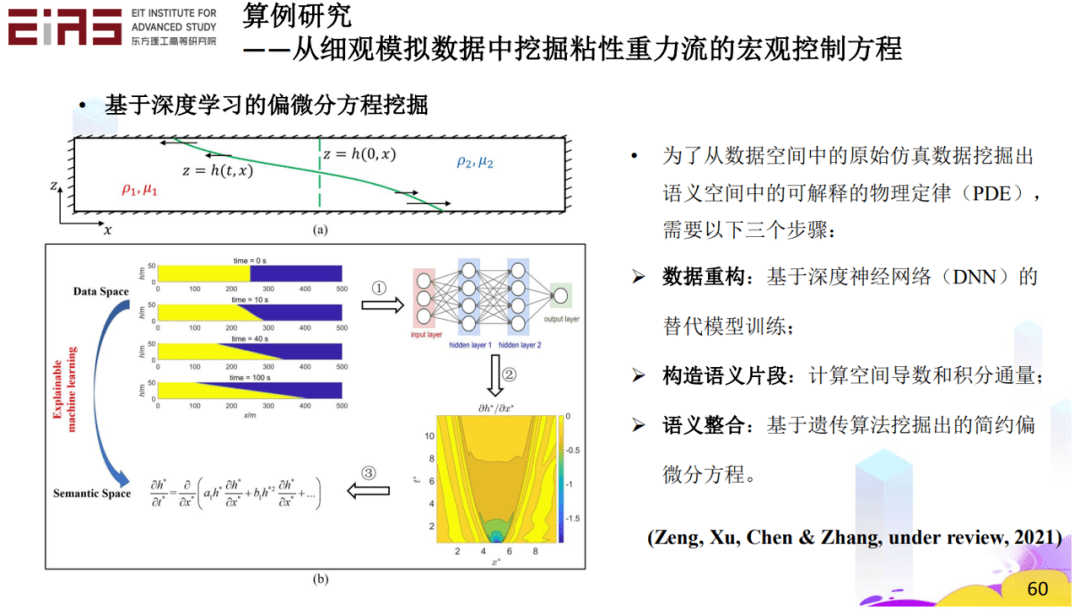
? 圖32 基于深度學習的偏微分方程挖掘 ?
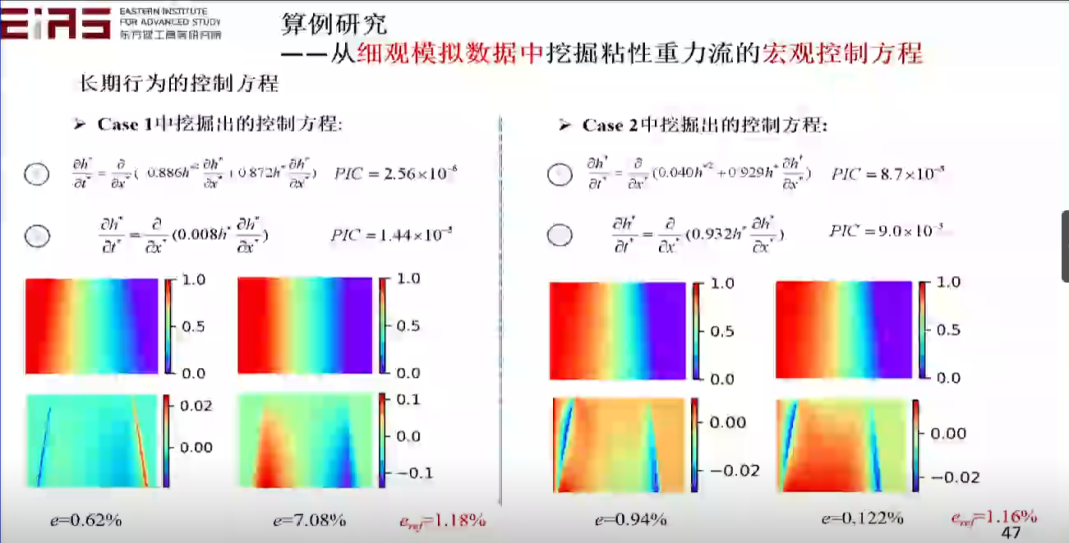
? 圖33 長期行為的控制方程 ?
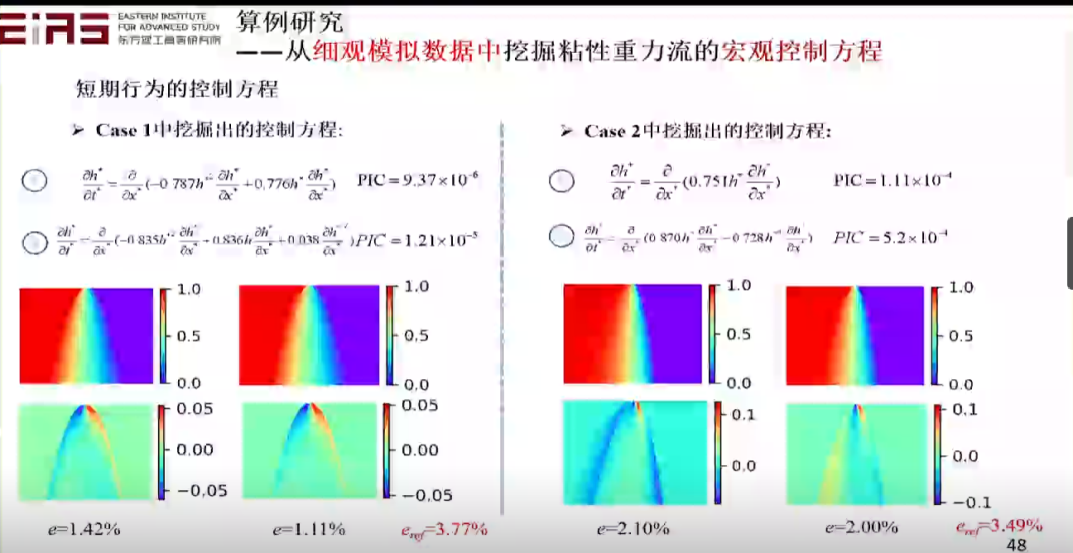
? 圖34 短期行為的控制方程
? ▍4、結束語
綜上所述,筆者認為,機器學習算法可以有效地解決具有復雜非線性映射關系的問題。但數據是其基礎,在社會不斷向著信息化、數字化、智能化方向發展的過程中,從數據大要走向大數據,光有數據已然不夠,大數據技術將更具價值。其次,通過引入行業知識,可以有效提升機器學習模型的效果,可以在數據預處理、機器學習模型結構以及模型效果評估環節嵌入領域知識,提升精度和魯棒性,同時還能在一定程度上降低數據需求。在“行業+AI”的未來,數據驅動(機器學習)與模型驅動(傳統模型)要得到有機結合(圖35),而核心就在于知識的嵌入和知識的發現,只有當二者形成一個閉環,才能大大提高人工智能解決實際問題的能力。
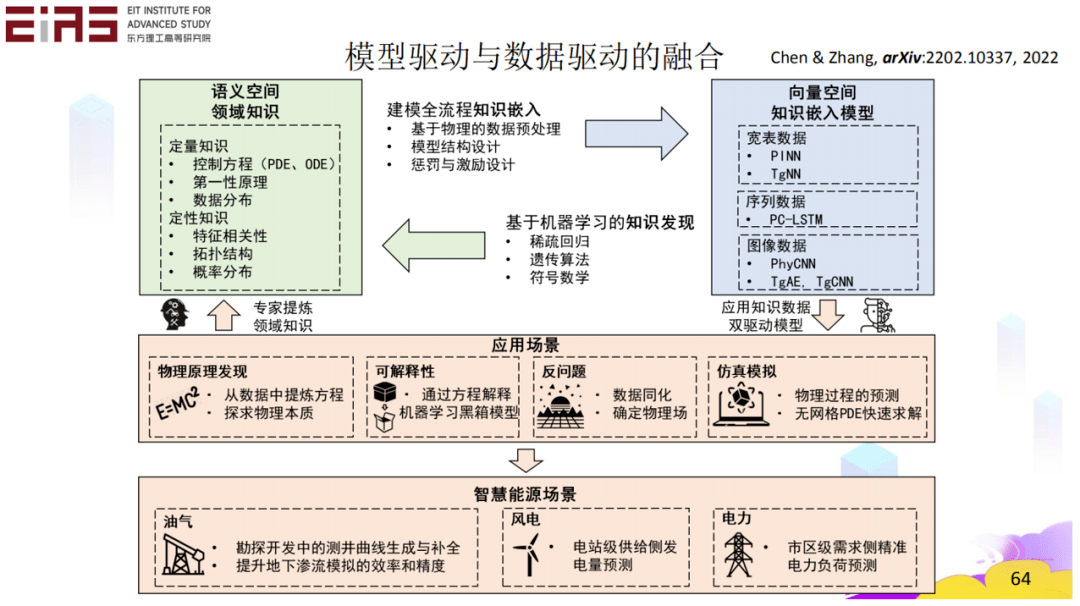
? 圖35 數據驅動與模型驅動的融合
? 編輯:黃飛
?








 工商網監
工商網監
評論