 電子發燒友App
電子發燒友App


作者:王利民
本文介紹我們在 3D 目標檢測領域的新工作:SparseBEV。我們所處的 3D 世界是稀疏的,因此稀疏 3D 目標檢測是一個重要的發展方向。然而,現有的稀疏3D目標檢測模型(如 DETR3D[1],PETR[2] 等)和稠密3D檢測模型(如 BEVFormer[3],BEVDet[8])在性能上尚有差距。針對這一現象,我們認為應該增強檢測器在 BEV 空間和 2D 空間的適應性(adaptability)。基于此,我們提出了高性能、全稀疏的 SparseBEV 模型。在 nuScenes 驗證集上,SparseBEV 在取得 55.8 NDS 性能的情況下仍能維持 23.5 FPS 的實時推理速度。在 nuScenes 測試集上,SparseBEV 在僅使用 V2-99 這種輕量級 backbone 的情況下就取得了 67.5 NDS 的超強性能。如果用上 HoP[5] 和 StreamPETR-large[6] 等方法中的 ViT-large 作為 backbone,沖上 70+ 不在話下。
我們的工作已被 ICCV 2023 接收,論文、代碼和權重(包括我們在榜單上 67.5 NDS 的模型)均已公開:

在CVer微信公眾號后臺回復:SparseBEV,可下載本論文pdf和代碼
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
論文:https://arxiv.org/abs/2308.09244
代碼:https://github.com/MCG-NJU/SparseBEV
1. 引言
現有的 3D 目標檢測方法可以被分類為兩種:基于稠密 BEV 特征的方法和基于稀疏 query 的方法。前者需要構建稠密的 BEV 空間特征,雖然性能優越,但是計算復雜度較大;基于稀疏 query 的方法避免了這一過程,結構更簡單,速度也更快,但是性能還落后于基于 BEV 的方法。因而我們自然而然地提出疑問:基于稀疏 query 的方法是否可以實現和基于稠密 BEV 的方法接近甚至更好的性能?
根據我們的實驗分析,我們認為實現這一目標的關鍵在于提升檢測器在 BEV 空間和 2D 空間的適應性。這種適應性是針對 query 而言的,即對于不同的 query,檢測器要能以不同的方式來編碼和解碼特征。這種能力正是之前的全稀疏 3D 檢測器 DETR3D 所欠缺的。因此,我們提出了 SparseBEV,主要做了三個改進。首先,設計了尺度自適應的自注意力模塊(scale-adaptive self attention, SASA)以實現在 BEV 空間的自適應感受野。其次,我們設計了自適應性的時空采樣模塊以實現稀疏采樣的自適應性,并充分利用長時序的優勢。最后,我們使用動態 Mixing 來自適應地 decode 采到的特征。
早在今年的2月9日,ICCV 投稿前夕,我們的 SparseBEV(V2-99 backbone)就已經在 nuScenes 測試集上取得了65.6 NDS 的成績,超過了 BEVFormer V2[7] 等方法。如下圖所示,該方案命名為 SparseBEV-Beta,具體可見 eval.ai 榜單。
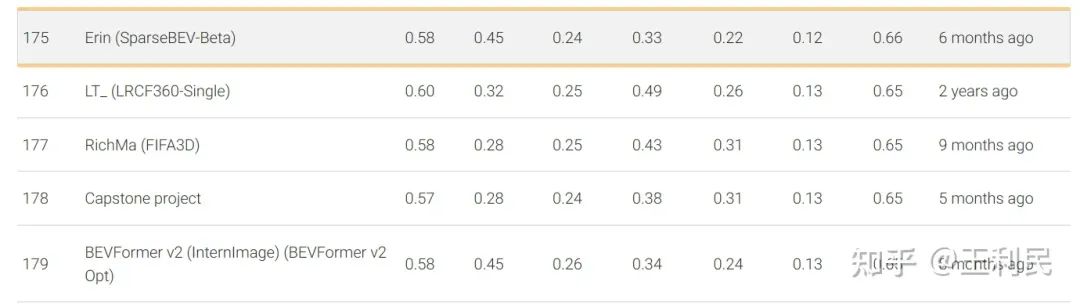
最近,我們采用了一些來自 StreamPETR 的最新 setting,包括將 bbox loss 的 X 和 Y 的權重調為 2.0,并使用 query denoising 來穩定訓練等等。現在,僅采用輕量級 V2-99 作為 backbone 的 SparseBEV 在測試集上就能夠實現 67.5 NDS 的超強性能,在純視覺 3D 檢測排行榜中排名第四(前三名均使用重量級的 ViT-large 作為 backbone):
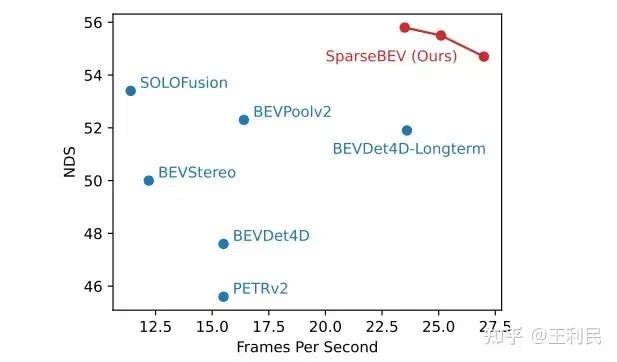
在驗證集的小規模的 Setting(ResNet50,704x256)下,SparseBEV 能取得 55.8 NDS 的性能,同時保持 23.5 FPS 的實時推理速度,充分發揮了 Sparse 設計帶來的優勢。
2. 方法
模型架構
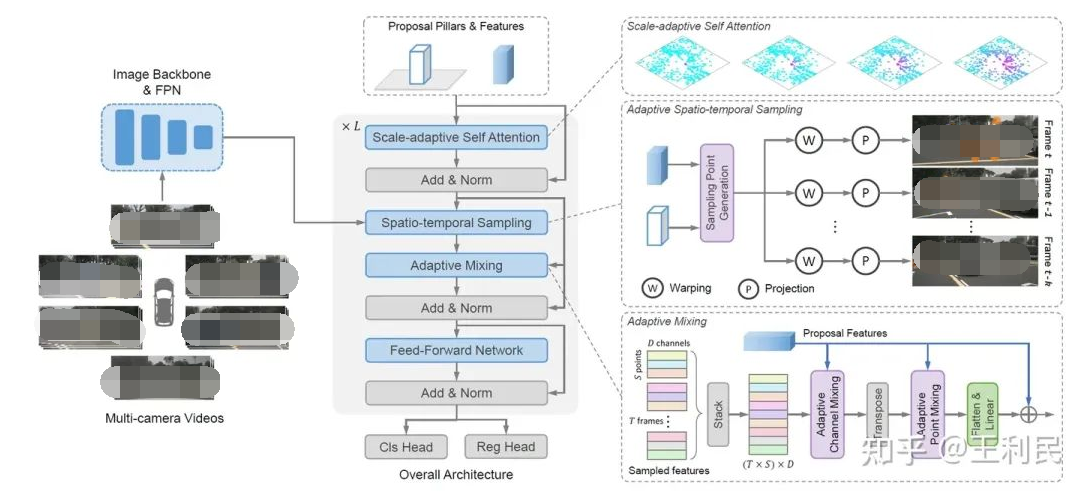
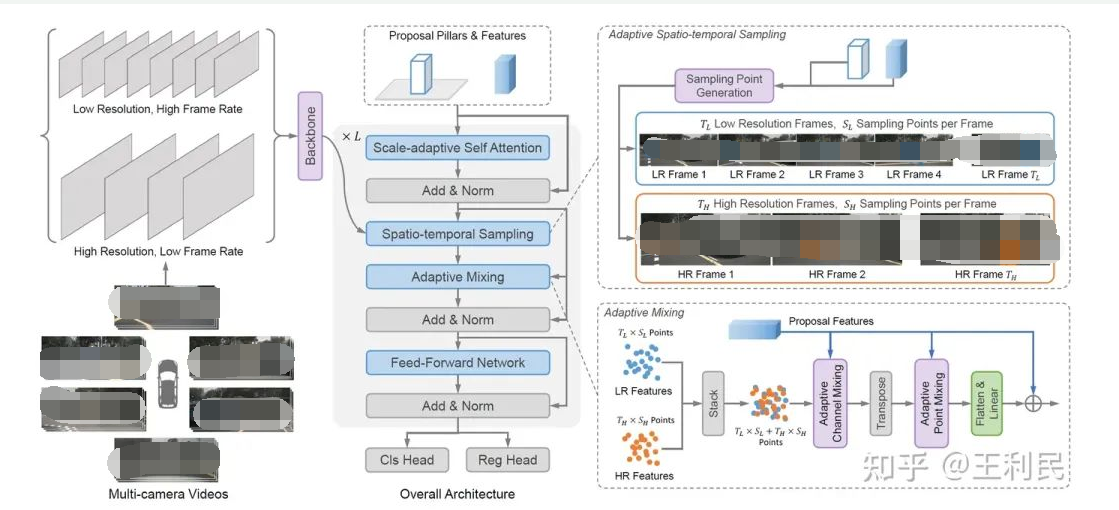
SparseBEV 的模型架構如上所示,其核心模塊包括尺度自適應自注意力、自適應時空采樣、自適應融合。

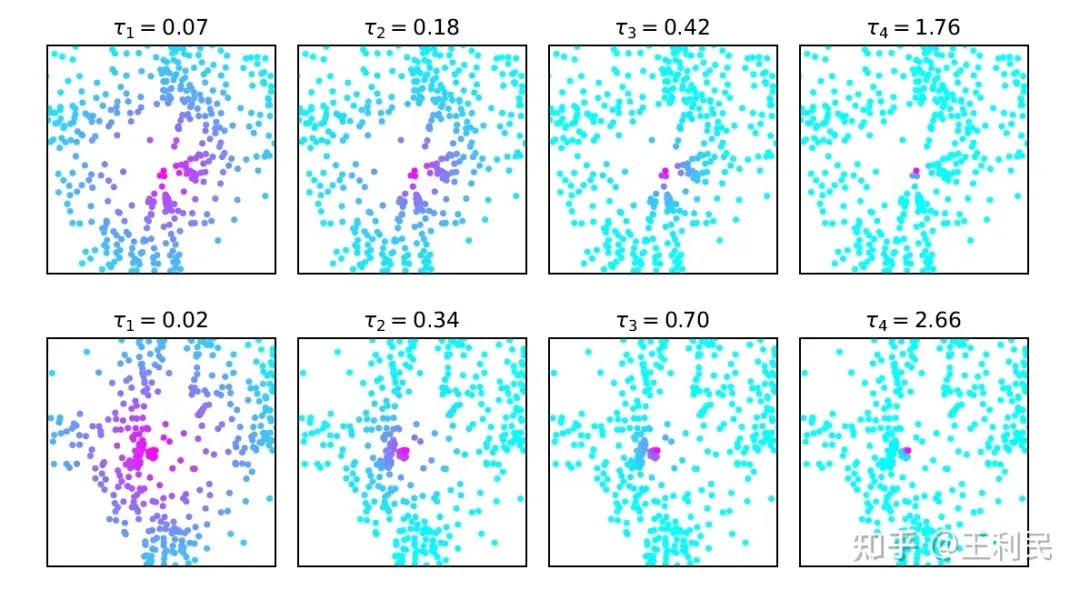
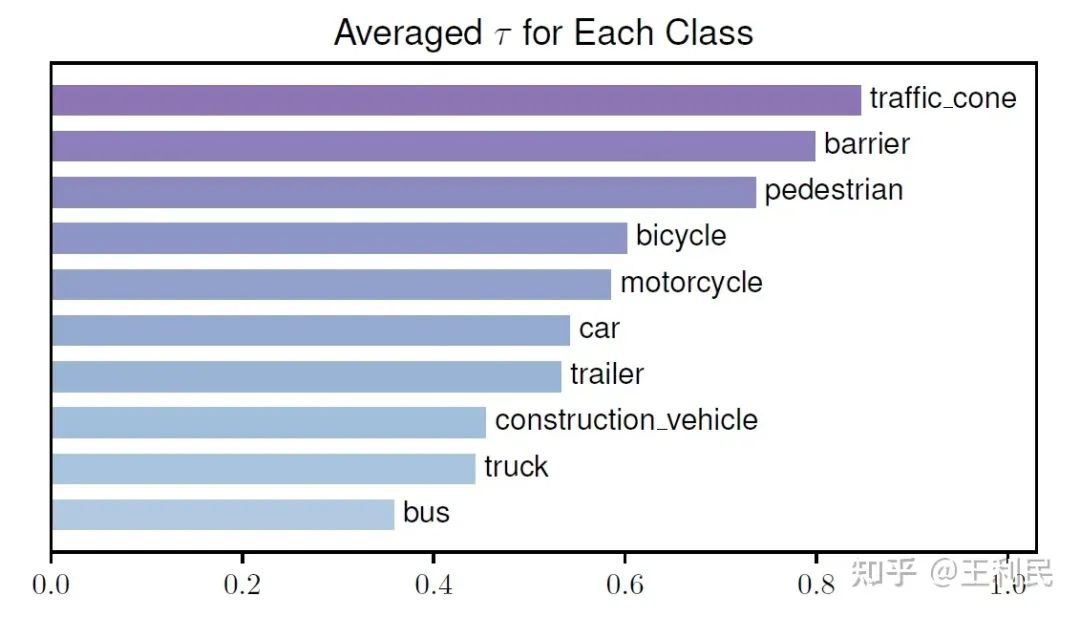
二:不同類別的物體所對應的 query 生成的?τ?值有著明顯差異。我們發現,大物體(例如公交車)對應 query 的感受野明顯大于小物體對應 query(例如行人)的感受野。(如下圖所示。注意:τ?越大,感受野越小)
相比于標準的 MHSA,SASA 幾乎沒有引入額外開銷,簡單又有效。在消融實驗中,使用 SASA 替換 MHSA 能直接暴漲 4.0 mAP 和 2.2 NDS:

Adaptive Spatio-temporal Sampling

這樣,我們生成的采樣點可以適應于給定的 query,從而能夠更好地處理不同尺寸、遠近的物體。同時,這些采樣點并不局限于給定的 query bbox 內部,它們甚至可以撒到框外面去,這由模型自己決定。
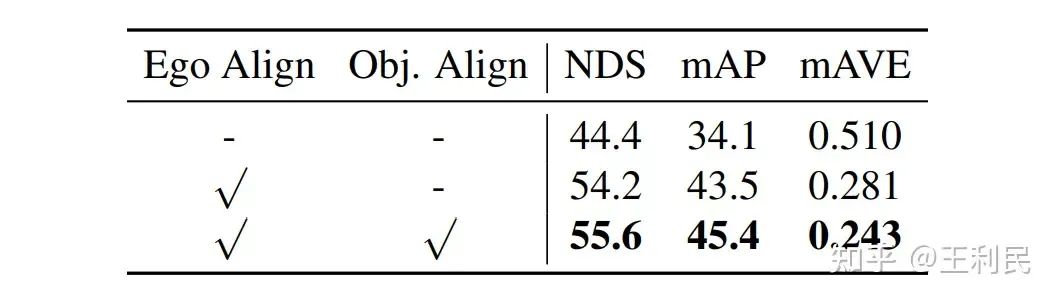
接著,為了進一步捕捉長時序的信息,我們將采樣點 warp 到不同時刻的坐標系中,以此實現幀間對齊。在自動駕駛場景中,有兩種類型的運動:一是車自身的運動(ego motion),二是其他物體的運動(object motion)。對于 ego motion,我們使用數據集提供的 ego pose 來實現對齊;對于 object motion,我們利用 query 中定義的瞬時速度向量,并配合一個簡單的勻速運動模型來對運動物體進行自適應的對齊。這兩種對齊操作都能漲點:
隨后我們將 3D 采樣點投影到 2D 圖像并通過雙線性插值獲取對應位置的 2D 特征。這里有一個工程上的小細節:由于是六張圖的環視輸入,DETR3D 是將每個采樣點分別投影到六個視圖中,并對正確的投影點抽到的特征取平均。我們發現,大多數情況下就只有一個投影點是正確的,偶爾會有兩個(即采樣點位于相鄰視圖的重疊區域)。于是,我們干脆只取其中一個投影點(即使有時會有兩個),把它對應的視圖 ID 作為一個新的坐標軸,從而可以通過 Pytorch 內置的 grid sample 算子的 3D 版一步到位。這樣可以顯著提速,并且不咋掉點(印象里只掉了 0.1~0.2 NDS)。具體可以看代碼:
github.com/MCG-NJU/SparseBEV/blob/main/models/sparsebev_sampling.py.py
對于稀疏采樣這塊,我們后來也基于 Deformable DETR 寫了一個 CUDA 優化。不過,純 PyTorch 實現其實也挺快的,CUDA 優化進一步提速了 15% 左右。
我們還提供了采樣點的可視化(第一行是當前幀,二三兩行是歷史前兩幀),可以看到,SparseBEV 的采樣點精準捕捉到了場景中不同尺度的物體(即在空間上具備適應性),且對于不同運動速度的物體也能很好的對齊(即在時間上具備適應性)。

Dual-branch SparseBEV
在實驗中,我們發現將輸入的多幀圖像分為 Fast、Slow 兩個分支處理可以進一步提升性能。具體地,我們將輸入分為高分辨率、低幀率的 Slow 分支和低分辨率、高幀率的 Fast 分支。于是,Slow 分支專注于提取高分辨率的靜態細節,而 Fast 分支則專注于捕獲運動信息。加入 Dual-branch 的 SparseBEV 結構圖如下所示:
Dual-branch 設計不光減小了訓練開支,還顯著提升了性能,具體可見補充材料。它的漲點說明了自駕長時序中的靜態細節和運動信息應該解耦處理。但是,它把整個模型搞得太復雜,因此我們默認情況下并沒有使用它(本文中只有測試集 NDS=63.6 的那行結果用了它)。
3. 實驗結果
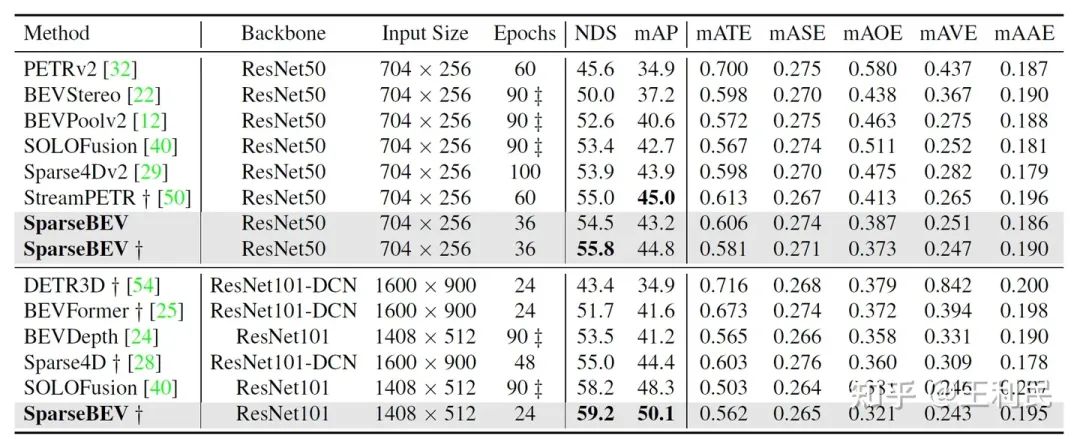
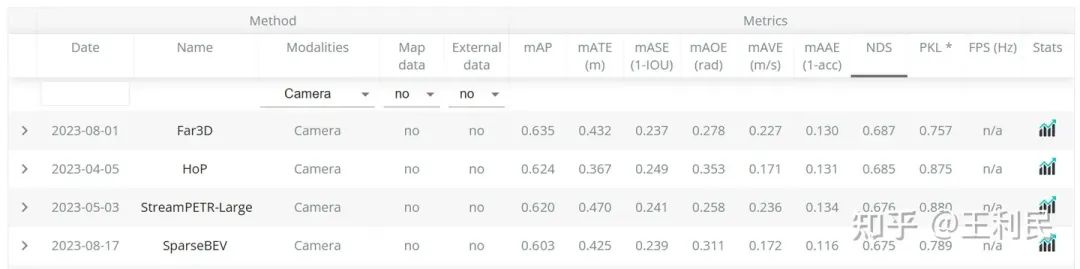
上表為 SparseBEV 與現有方法在 nuScenes 的驗證集上的結果對比,其中???表示方法使用了透視預訓練。在使用 ResNet-50 作為 backbone 和 900 個 query,且輸入圖像分辨率為 704x256 的情況下,SparseBEV 超越現有最優方法 SOLOFusion[4] 0.5 mAP 和 1.1 NDS。在使用 nuImages 預訓練并將 query 數量降低到 400 后,SparseBEV 在達到 55.8 的 NDS 的情況下仍能維持 23.5 FPS 的推理速度。而將 backbone 升級為 ResNet-101 并將輸入圖像尺寸升為 1408x512 后,SparseBEV 超越 SOLOFusion 達 1.8 mAP 和 1.0 NDS。
nuScenes test split
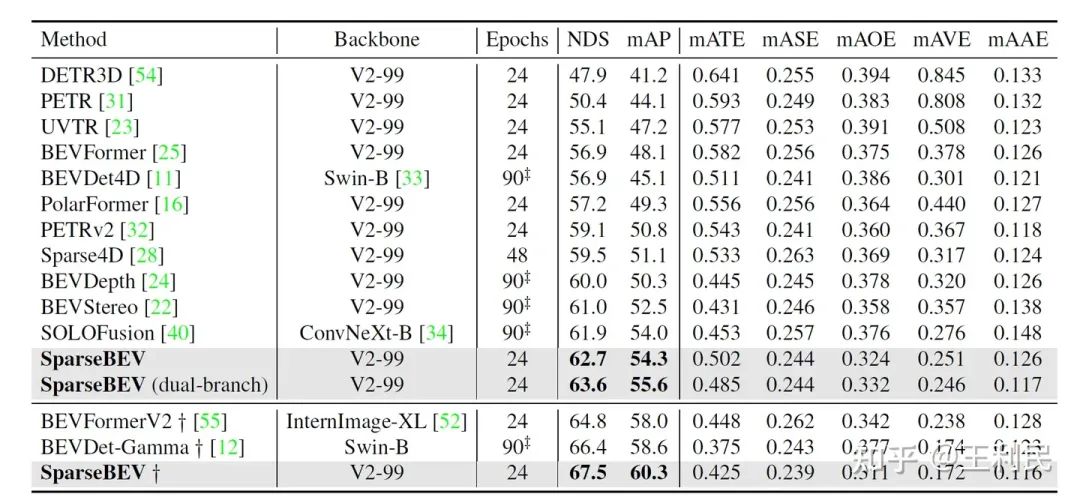
上表為 SparseBEV 與現有方法在測試集上的結果對比,其中???表示方法使用了未來幀。在不使用未來幀的情況下,SparseBEV 取得了 62.7 NDS 和 54.3 mAP;其 Dual-branch 版本進一步提升到了 63.6 NDS 和 55.6 mAP。在加入未來幀后,SparseBEV 超越 BEVFormer V2 高達 2.8 mAP 和 2.2 NDS,而我們使用的 V2-99 僅約 70M 參數,參數量遠低于 BEVFormer V2 使用的 InternImage-XL(超過 300M 參數)。
4. 局限性
SparseBEV 的弱點還不少:
SparseBEV 非常依賴 ego pose 來實現幀間對齊。在論文的 Table 5 中,如果不使用 ego-based warping,NDS 能掉 10 個點左右,幾乎和沒加時序一樣。
SparseBEV 中使用的時序建模屬于堆疊時序,它的耗時和輸入幀數成正比。當輸入幀數太多的時候(比如 16 幀),會拖慢推理速度。
目前 SparseBEV 采用的訓練方式還是傳統方案。對于一次訓練迭代,DataLoader 會將所有幀全部 load 進來。這對于機器的 CPU 能力有較高的要求,因此我們使用了諸如 TurboJPEG 和 Pillow-SIMD 庫來加速 loading 過程。接著,所有的幀全部會經過 backbone,對 GPU 顯存也有一定要求。對于 ResNet50 和 8 幀 704x256 的輸入來說,2080Ti-11G 還可以塞下;但如果把分辨率、未來幀等等都拉滿,就只有 A100-80G 可以跑了。我們開源的代碼中使用的 Training 配置均為能跑的最低配置。目前有兩種解決方案:
A.將部分視頻幀的梯度截斷。我們開源的 config 中有個 stop_prev_grad 選項,它會將所有之前幀都以 no_grad 模式推理,只有當前幀會有梯度回傳。
B. 另一種解決方案是采用 SOLOFusion、StreamPETR 等方法中使用的 sequence 訓練方案,省顯存省時間,我們未來可能會嘗試。
5. 結論
本文中,我們提出了一種全稀疏的單階段 3D 目標檢測器 SparseBEV。SparseBEV 通過尺度自適應自注意力、自適應時空采樣、自適應融合三個核心模塊提升了基于稀疏 query 模型的自適應性,取得了和基于稠密 BEV 的方法接近甚至更優的性能。此外我們還提出了一種 Dual-branch 的結構進行更加高效的長時序處理。SparseBEV 在 nuScenes 同時實現了高精度和高速度。我們希望該工作可以對稀疏 3D 檢測范式有所啟發。
編輯:黃飛





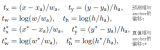







 工商網監
工商網監
評論