 電子發(fā)燒友App
電子發(fā)燒友App


近年來(lái),深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)各個(gè)領(lǐng)域中的應(yīng)用成效顯著,新的深度學(xué)習(xí)方法和深度神經(jīng)網(wǎng)絡(luò)模型不斷涌現(xiàn),算法性能被不斷刷新。 ? 本文著眼于當(dāng)下一些典型網(wǎng)絡(luò)和模型,對(duì)基于深度學(xué)習(xí)的計(jì)算機(jī)視覺(jué)研究新進(jìn)展進(jìn)行綜述。首先總結(jié)了針對(duì)圖像分類的主流深度神經(jīng)網(wǎng)絡(luò)模型,包括標(biāo)準(zhǔn)模型及輕量化模型等;然后總結(jié)了針對(duì)不同計(jì)算機(jī)視覺(jué)領(lǐng)域的主流方法和模型,包括目標(biāo)檢測(cè)、圖像分割和圖像超分辨率等;最后總結(jié)了深度神經(jīng)網(wǎng)絡(luò)搜索方法。 ? 1? 通用深度神經(jīng)網(wǎng)絡(luò)模型
? ? 圖像分類任務(wù)的通用網(wǎng)絡(luò)模型是基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的。1989年,LeCun首次訓(xùn)練了CNN,開啟了這個(gè)領(lǐng)域的研究。1998年提出了LeNet-5,由兩個(gè)卷積層和三個(gè)全連接層組成,如圖1所示。
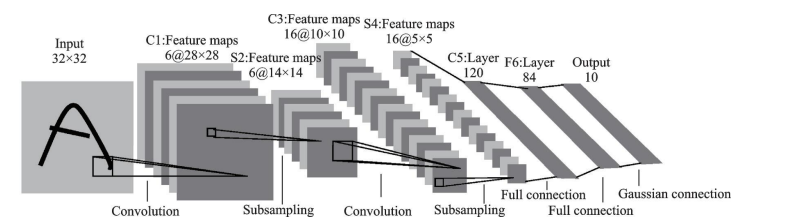
圖1 LeNet-5 結(jié)構(gòu)示意圖 然而,當(dāng)時(shí)的CNN復(fù)雜度較低,性能不如現(xiàn)代深度網(wǎng)絡(luò)。
? ? 直到2012年,AlexNet將深度學(xué)習(xí)技術(shù)應(yīng)用到大規(guī)模圖像分類領(lǐng)域,取得了重大突破。AlexNet的結(jié)構(gòu)與LeNet相似,但使用了ReLU激活函數(shù)、dropout方法,并增加了深度,如圖 2 所示。
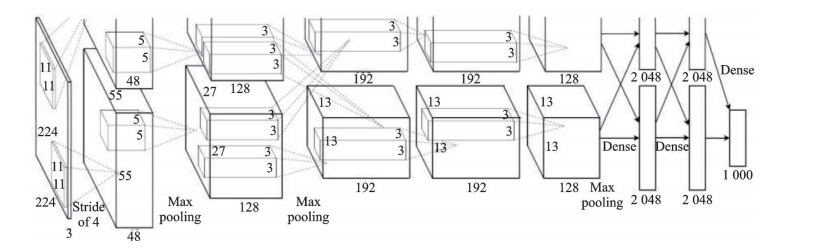
圖2 AlexNet結(jié)構(gòu)示意圖
之后的幾年中,出現(xiàn)了ZFNet、GoogLeNet和VGGNet等結(jié)構(gòu)。GoogLeNet引入了Inception模塊,通過(guò)不同尺寸的卷積層和最大池化層并行提取信息,降低了模型復(fù)雜度,如圖3所示。VGGNet重復(fù)使用了3×3的卷積核和2×2的池化層,將深度網(wǎng)絡(luò)加深到16~19層,如圖4所示。
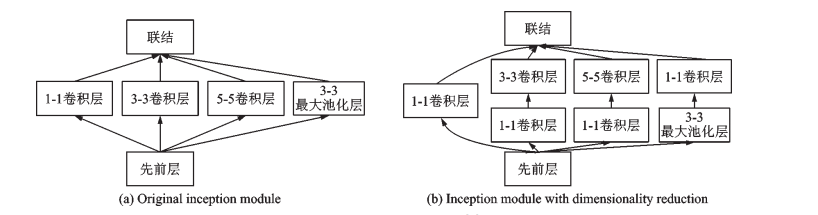
圖3 Inception 模塊示意圖
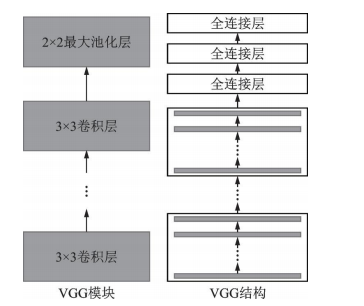
圖?4 VGG?模塊和VGG?結(jié)構(gòu)示意圖
2016年,微軟亞洲研究院提出了ResNet模型,該模型最深可達(dá)到152層,并贏得了目標(biāo)檢測(cè)、分類和定位三個(gè)賽道的冠軍。該研究提出了殘差模塊的跳接結(jié)構(gòu),網(wǎng)絡(luò)學(xué)習(xí)殘差映射f(x)-x,每個(gè)殘差模塊里有兩個(gè)相同輸出通道的3x3卷積層,每個(gè)卷積層后接一個(gè)BN層和ReLU激活函數(shù)。跳接結(jié)構(gòu)使數(shù)據(jù)更快向前傳播,保證網(wǎng)絡(luò)沿著正確方向深化,準(zhǔn)確率不斷提高。ResNet的思想產(chǎn)生了深遠(yuǎn)影響,奠定了訓(xùn)練更深的深度網(wǎng)絡(luò)的基礎(chǔ),結(jié)構(gòu)如圖5所示。 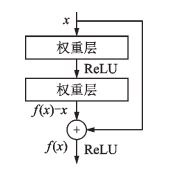 圖 5 殘差模塊 2017年提出的DenseNet和ResNeXt都受到ResNet的啟發(fā),除了學(xué)習(xí)殘差映射外,DenseNet還學(xué)習(xí)更高階的項(xiàng),采用跳接結(jié)構(gòu)進(jìn)行連接,如圖6所示。ResNeXt結(jié)合了ResNet和Inceptionv4,采用GoogLeNet分組卷積的思想,加入殘差連接,如圖7所示。
圖 5 殘差模塊 2017年提出的DenseNet和ResNeXt都受到ResNet的啟發(fā),除了學(xué)習(xí)殘差映射外,DenseNet還學(xué)習(xí)更高階的項(xiàng),采用跳接結(jié)構(gòu)進(jìn)行連接,如圖6所示。ResNeXt結(jié)合了ResNet和Inceptionv4,采用GoogLeNet分組卷積的思想,加入殘差連接,如圖7所示。
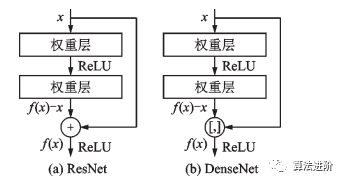
圖6 ResNet和DenseNet結(jié)構(gòu)比較
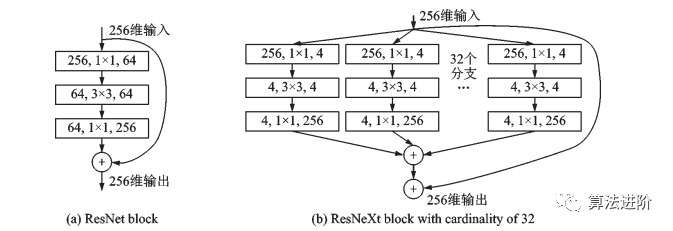
圖7 ResNet殘差模塊和基數(shù)為 32 的 ResNeXt模塊
同年提出的Xception是一種基于Inception分組卷積思想的模型,其分組卷積思想將通道拆分成不同大小感受野的子通道,可以提取多尺寸特征并減少參數(shù)量,如圖8所示。許多科技巨頭開放大規(guī)模數(shù)據(jù)集,如OpenImage、JFT-300M和Kinetics,這些數(shù)據(jù)集增強(qiáng)了深度學(xué)習(xí)模型的泛化能力。
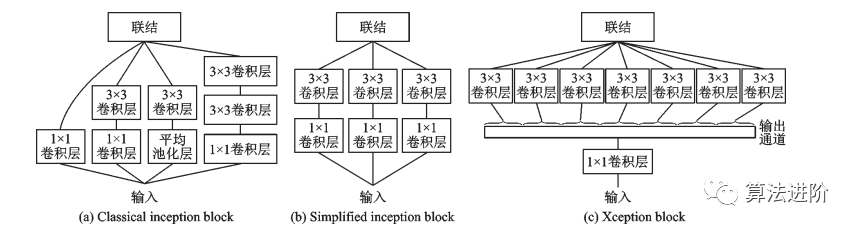
圖8 經(jīng)典及簡(jiǎn)化的 Inception 模塊和 Xception?模塊
生成模型能學(xué)習(xí)數(shù)據(jù)中隱含特征并對(duì)分布進(jìn)行建模,應(yīng)用于圖像、文本、語(yǔ)音等,采樣生成新數(shù)據(jù)。在深度學(xué)習(xí)前就有許多生成模型,因建模困難有挑戰(zhàn)。
變分自編碼器(Variationalautoencoder,VAE)是當(dāng)前主流的基于深度學(xué)習(xí)技術(shù)的生成模型,是標(biāo)準(zhǔn)自編碼器的一種變形,關(guān)注重構(gòu)損失和隱向量的約束。通過(guò)強(qiáng)迫隱變量服從單位高斯分布,優(yōu)化了以下?lián)p失函數(shù):
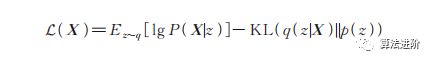
其中,E表示期望,z為隱變量,q(z|X)表示隱變量的建議分布(編碼器輸出的隱變量的分布),p(z)表示標(biāo)準(zhǔn)高斯分布,P(X|z)表示解碼器分布,KL表示KL散度。為了優(yōu)化KL散度,變分自編碼器生成了1個(gè)均值向量和1個(gè)標(biāo)準(zhǔn)差向量用于參數(shù)重構(gòu)。在隱向量分布中采樣就可以生成新的圖片。自編碼器和變分自編碼器示意圖如圖9、10所示。
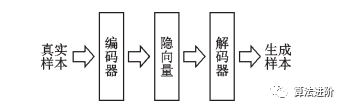
圖9 自編碼器示意圖
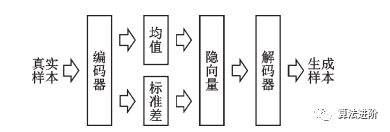
圖10 變分自編碼器示意圖
生成對(duì)抗網(wǎng)絡(luò)(Generative adversarial net,GAN)是另一種常見(jiàn)的基于深度學(xué)習(xí)技術(shù)的生成模型,包括生成器和判別器2個(gè)組件,如圖11。二者相互對(duì)抗,互相促進(jìn)。
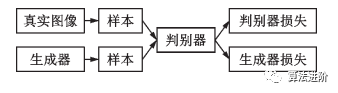
圖11 生成對(duì)抗網(wǎng)絡(luò)示意圖
變分自編碼器和GAN在計(jì)算機(jī)視覺(jué)領(lǐng)域中已經(jīng)廣泛應(yīng)用于圖像翻譯、超分辨率、目標(biāo)檢測(cè)、視頻生成和圖像分割等領(lǐng)域,具有廣闊的研究?jī)r(jià)值和應(yīng)用前景。 ?
2??輕量化網(wǎng)絡(luò)
輕量化網(wǎng)絡(luò)是在保證模型精度前提下,降低計(jì)算和空間復(fù)雜度的深度神經(jīng)網(wǎng)絡(luò),以便在計(jì)算和存儲(chǔ)有限的嵌入式設(shè)備上部署,實(shí)現(xiàn)學(xué)術(shù)到工業(yè)的躍遷。目前,學(xué)術(shù)和工業(yè)界主要采用四種方法設(shè)計(jì)輕量化深度網(wǎng)絡(luò)模型:人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)、基于神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(Neural architecture search,NAS)的自動(dòng)設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)技術(shù)、卷積神經(jīng)網(wǎng)絡(luò)壓縮和基于AutoML的自動(dòng)模型壓縮。這些方法旨在減少計(jì)算和存儲(chǔ)需求,使深度學(xué)習(xí)模型能夠在資源受限設(shè)備上運(yùn)行。本節(jié)主要介紹人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)。
人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)是指通過(guò)手動(dòng)設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)和參數(shù)來(lái)減少模型的計(jì)算和存儲(chǔ)需求的方法。這種方法通常需要深入理解深度神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)和參數(shù),以及對(duì)不同任務(wù)的特征進(jìn)行分析和提取。常見(jiàn)的人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)包括MobileNet、ShuffleNet、SqueezeNet等。
SqueezeNet是2016年伯克利和斯坦福的研究者提出的深度模型輕量化工作之一,結(jié)構(gòu)如圖12,其結(jié)構(gòu)借鑒了VGG堆疊的形式,使用了Fire模塊(如圖13)來(lái)減少參數(shù)量。
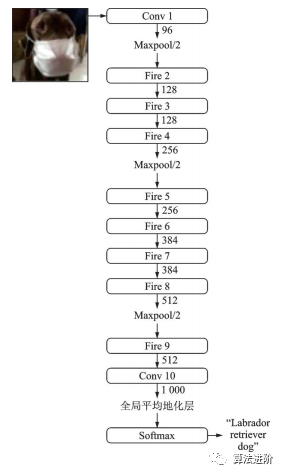
圖12 SqueezeNet網(wǎng)絡(luò)結(jié)構(gòu)示意圖
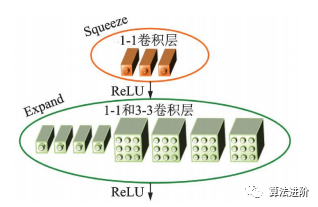
圖13 SqueezeNet的 Fire 模塊
MobileNet是谷歌于2017年提出的輕量化網(wǎng)絡(luò),核心是使用深度可分離卷積代替標(biāo)準(zhǔn)卷積,可以將計(jì)算量降低至原來(lái)的1/8~1/9。標(biāo)準(zhǔn)卷積和深度可分離卷積+BN+ReLU 結(jié)構(gòu)如圖 14 所示。
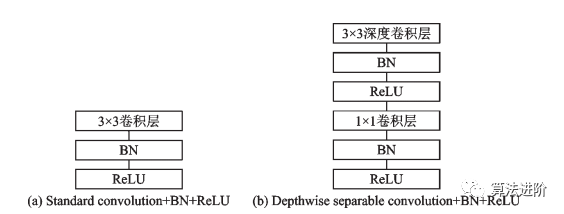
圖14 標(biāo)準(zhǔn)卷積+BN+ReLU 網(wǎng)絡(luò)和深度可分離卷積+BN+ReLU 網(wǎng)絡(luò)
ShuffleNet晚于MobileNet兩個(gè)月由Face++團(tuán)隊(duì)提出,ShuffleNet采用了ResNet的跳接結(jié)構(gòu),使用了Channel Shuffle(圖15)和分組卷積的思想。ShuffleNet模塊的設(shè)計(jì)借鑒了 ResNet bottleneck 的結(jié)構(gòu),如圖 16 所示。
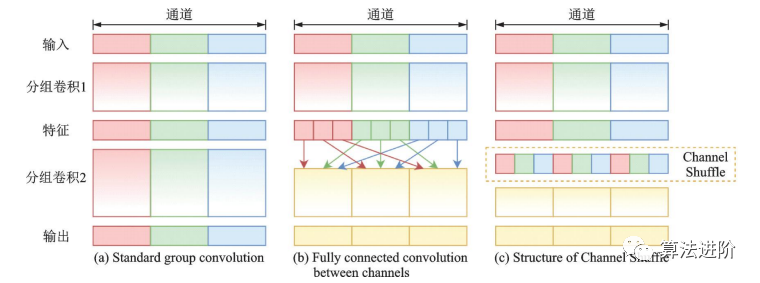
圖15 Channel Shuffle 示意圖
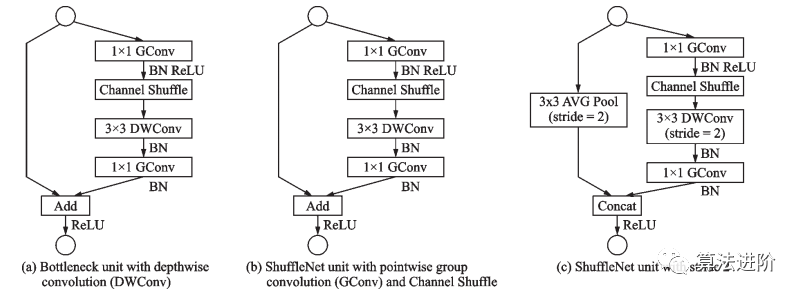
圖16 ShuffleNet模塊
2018年,MobileNet和ShuffleNet又相繼提出了改進(jìn)版本,MobileNetv2采用了效率更高的殘差結(jié)構(gòu)(圖17),ShuffleNetv2采用了一種ChannelSplit操作。ShuffleNet v1 和 ShuffleNet v2 結(jié)構(gòu)如圖 18 所示。
圖17 MobileNet v2 模塊
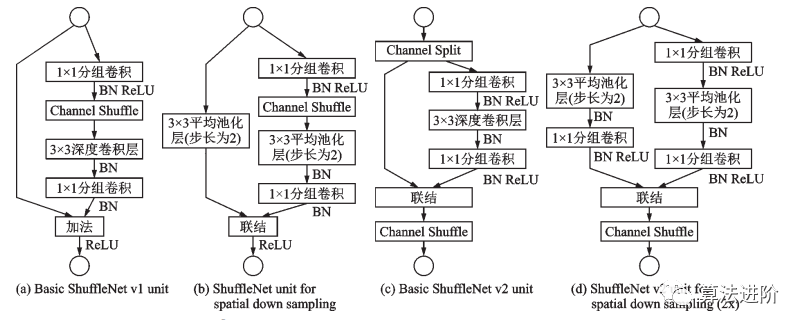
圖18 ShuffleNet v1 和 ShuffleNet v2 結(jié)構(gòu)
2020年,華為諾亞方舟實(shí)驗(yàn)室的團(tuán)隊(duì)提出了GhostNet,如圖19所示。該網(wǎng)絡(luò)用更少的參數(shù)量提取更多的特征圖。Ghost模塊通過(guò)一系列簡(jiǎn)單的線性操作生成特征圖,模擬傳統(tǒng)卷積層的效果,降低了參數(shù)量和計(jì)算量。
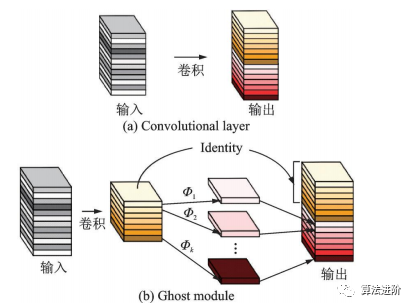
圖19 卷積層和 Ghost模塊
這些網(wǎng)絡(luò)通過(guò)使用深度可分離卷積、通道重排、瓶頸結(jié)構(gòu)等技術(shù)來(lái)減少模型的計(jì)算和存儲(chǔ)需求,同時(shí)保持較高的精度。人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)通常具有較好的可解釋性和可控性,但是需要大量的人力和經(jīng)驗(yàn)來(lái)設(shè)計(jì)和優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)和參數(shù)。
3??面向特定任務(wù)的深度網(wǎng)絡(luò)模型
本節(jié)主要介紹特定計(jì)算機(jī)視覺(jué)任務(wù)的深度神經(jīng)網(wǎng)絡(luò)模型,包括目標(biāo)檢測(cè)、圖像分割、圖像超分辨率和神經(jīng)架構(gòu)搜索等。
3.1??目標(biāo)檢測(cè)
目標(biāo)檢測(cè)任務(wù)包括物體的分類、定位和檢測(cè)。自2014年R-CNN模型提出后,目標(biāo)檢測(cè)成為計(jì)算機(jī)視覺(jué)熱點(diǎn)。Girshick團(tuán)隊(duì)隨后推出Fast R-CNN、Faster R-CNN等兩階段模型,將問(wèn)題分為提出可能包含目標(biāo)的候選區(qū)域和對(duì)這些區(qū)域分類。
R-CNN系列模型由共享特征提取子網(wǎng)和RoI預(yù)測(cè)回歸子網(wǎng)組成。全卷積網(wǎng)絡(luò)結(jié)構(gòu)在性能更強(qiáng)的分類網(wǎng)絡(luò)出現(xiàn)后應(yīng)用于目標(biāo)檢測(cè)任務(wù),但檢測(cè)精度低于分類精度。R-FCN提出位置敏感分?jǐn)?shù)圖,增強(qiáng)網(wǎng)絡(luò)對(duì)位置信息的表達(dá)能力,提高檢測(cè)精度,結(jié)構(gòu)如圖20所示。
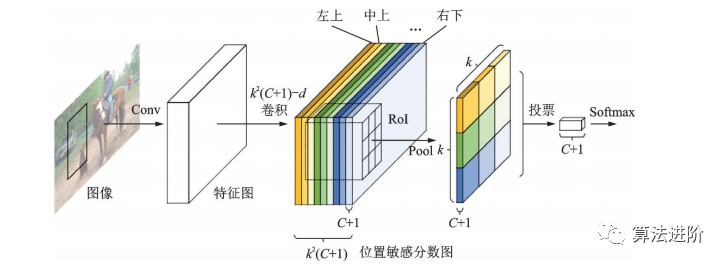
圖20 R-FCN?結(jié)構(gòu)示意圖
如何準(zhǔn)確識(shí)別不同尺寸的物體是目標(biāo)檢測(cè)任務(wù)的難點(diǎn)之一。不同方法包括提取不同尺度特征(圖21(a))、單一特征圖(圖21(b))和多尺度融合(圖21(c))。

圖21?多尺度檢測(cè)的常見(jiàn)結(jié)構(gòu)
特征金字塔網(wǎng)絡(luò)(FeaturePyramidnetwork,F(xiàn)PN)借鑒ResNet跳接思想,結(jié)合了層間特征融合與多分辨率預(yù)測(cè),結(jié)構(gòu)如圖22。用于Faster R-CNN的RPN,實(shí)現(xiàn)多尺度特征提取,提高檢測(cè)性能。實(shí)驗(yàn)證明FPN特征提取效果優(yōu)于單尺度特征提取。
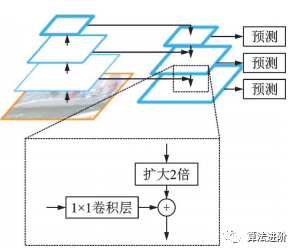
圖22 FPN?結(jié)構(gòu)示意圖
YOLO是單階段模型的代表,它將候選區(qū)域和分類統(tǒng)一為邊界框回歸問(wèn)題,實(shí)現(xiàn)了端到端的學(xué)習(xí),示意圖如圖23。它采用等分網(wǎng)格對(duì)圖片進(jìn)行劃分,并運(yùn)行單獨(dú)的卷積網(wǎng)絡(luò)進(jìn)行預(yù)測(cè),最后使用非極大值抑制得到最終的預(yù)測(cè)框。其損失函數(shù)包括坐標(biāo)誤差、物體誤差和類別誤差,并添加權(quán)重平衡類別不均衡和大小物體影響。YOLO網(wǎng)絡(luò)結(jié)構(gòu)圖如圖24。
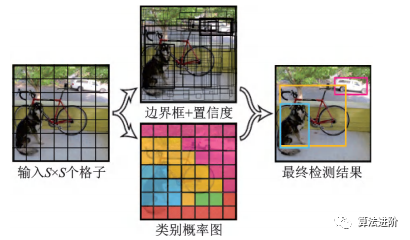
圖23 YOLO 示意圖
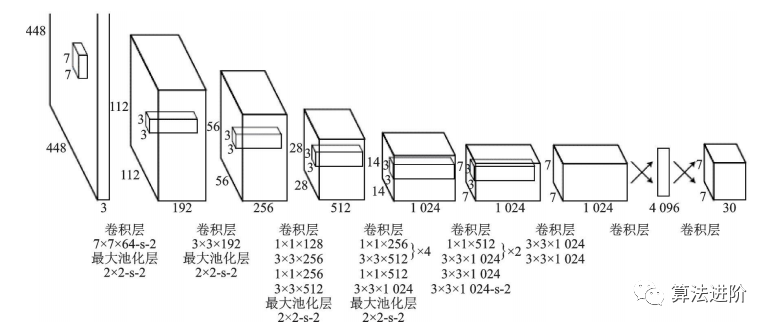
圖24 YOLO網(wǎng)絡(luò)結(jié)構(gòu)圖
YOLOv1的訓(xùn)練流程簡(jiǎn)單,背景誤檢率低,但由于每個(gè)格子只能預(yù)測(cè)出一個(gè)物體,限制了其檢測(cè)能力。YOLOv2在YOLOv1的基礎(chǔ)上采用了以VGG16為基礎(chǔ)的Darknet19,借鑒了FasterR-CNN錨框的設(shè)計(jì),并采用多尺度訓(xùn)練,提高了模型的健壯性。YOLOv3則采用了Darknet53作為骨干網(wǎng)絡(luò),引入了FPN結(jié)構(gòu),解決了小目標(biāo)檢測(cè)精度較差的問(wèn)題,使得YOLO系列模型在單階段檢測(cè)方面更加強(qiáng)大和健壯。
SSD是最早達(dá)到兩階段模型精度的單階段模型之一,結(jié)構(gòu)如圖25所示。為提高小目標(biāo)檢測(cè)精度,SSD采用多尺度特征圖和更多預(yù)測(cè)框。

圖25 SSD 網(wǎng)絡(luò)結(jié)構(gòu)圖
單階段模型相比兩階段模型擁有更快的速度和更小的內(nèi)存占用,最新的單階段模型如FCOS、VFNet等工作已接近兩階段模型精度,更適合在移動(dòng)端部署。目標(biāo)檢測(cè)技術(shù)從傳統(tǒng)的手工特征算法發(fā)展到深度學(xué)習(xí)算法,精度和速度不斷提升。工業(yè)界已經(jīng)實(shí)現(xiàn)了多種基于目標(biāo)檢測(cè)技術(shù)的應(yīng)用,如人臉檢測(cè)識(shí)別、行人檢測(cè)、交通信號(hào)檢測(cè)、文本檢測(cè)和遙感目標(biāo)檢測(cè)等。小目標(biāo)檢測(cè)和視頻目標(biāo)檢測(cè)是未來(lái)的研究熱點(diǎn)問(wèn)題,目標(biāo)檢測(cè)的輕量化和多模態(tài)信息融合也是未來(lái)的研究方向。
3.2? 圖像分割
圖像語(yǔ)義分割任務(wù),要求將圖像像素分類為多個(gè)預(yù)定義類別。由于是像素級(jí)稠密分類,比圖像分類和目標(biāo)檢測(cè)更困難。深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域取得成功,因此大量研究基于深度學(xué)習(xí)的圖像分割方法。
2015年提出的U-Net和全卷積網(wǎng)絡(luò)(Fully convolutional network,F(xiàn)CN)啟發(fā)了圖像分割和目標(biāo)檢測(cè)工作。U-Net是醫(yī)學(xué)圖像分割的卷積神經(jīng)網(wǎng)絡(luò),贏得兩項(xiàng)挑戰(zhàn)賽冠軍。U-Net為編碼器-解碼器結(jié)構(gòu),通過(guò)最大池化和上采樣調(diào)整分辨率,結(jié)構(gòu)如圖26。卷積采用Valid模式,輸出分辨率低于輸入。U-Net采用跳接結(jié)構(gòu),連接上采樣結(jié)果和編碼器輸出,作為解碼器輸入,融合高低分辨率信息,適用于醫(yī)學(xué)圖像分割。
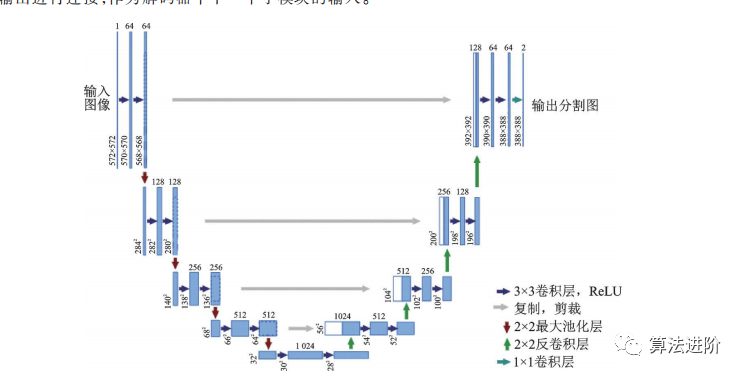
圖26 U-Net結(jié)構(gòu)示意圖
MaskR-CNN在FasterR-CNN基礎(chǔ)上改進(jìn),實(shí)現(xiàn)像素級(jí)分類,拓展至圖像分割。通過(guò)RoIAlign提高定位精度,添加二進(jìn)制Mask表征目標(biāo)范圍。網(wǎng)絡(luò)結(jié)構(gòu)圖和分支結(jié)構(gòu)圖如圖27、28所示。
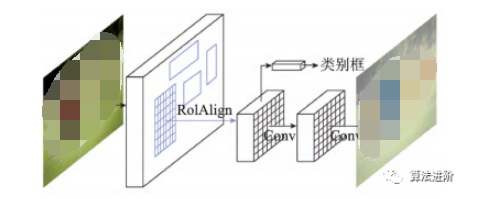
圖27?Mask R-CNN網(wǎng)絡(luò)示意圖
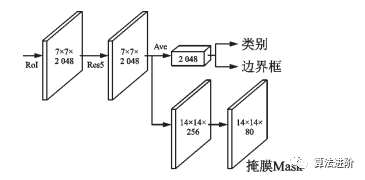
圖28?Mask R-CNN?分支示意圖
深度卷積神經(jīng)網(wǎng)絡(luò)中池化層和上采樣層設(shè)計(jì)存在缺陷,導(dǎo)致圖像分割精度受限。2016年DeepLab提出空洞卷積,避免信息損失,并使用全連接的條件隨機(jī)場(chǎng)(Condi-tionalrandomfield,CRF)優(yōu)化分割精度,結(jié)構(gòu)如圖29。空洞卷積增大感受野,不增加參數(shù)。DeepLabv1作為后處理,用條件隨機(jī)場(chǎng)描述像素點(diǎn)關(guān)系,在分割邊界取得良好效果。DeepLabv1速度快,平均交并比達(dá)71.6%,對(duì)后續(xù)工作產(chǎn)生深遠(yuǎn)影響。
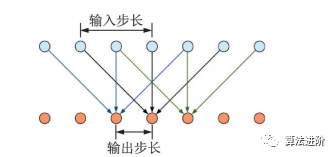
圖 29 空洞卷積示意圖(卷積核尺寸為 3,輸入步長(zhǎng)為2,輸出步長(zhǎng)為1)
2017年劍橋大學(xué)提出的SegNet,針對(duì)道路和室內(nèi)場(chǎng)景理解,設(shè)計(jì)像素級(jí)圖像分割網(wǎng)絡(luò),高效且內(nèi)存、計(jì)算時(shí)間要求低。采用全卷積“編碼器-解碼器”結(jié)構(gòu),復(fù)用池化索引減少參數(shù)量,改善邊界劃分。在CamVid11RoadClassSegmentation和SUNRGB-DIndoorScenes數(shù)據(jù)集上表現(xiàn)優(yōu)異。結(jié)構(gòu)如圖30所示。
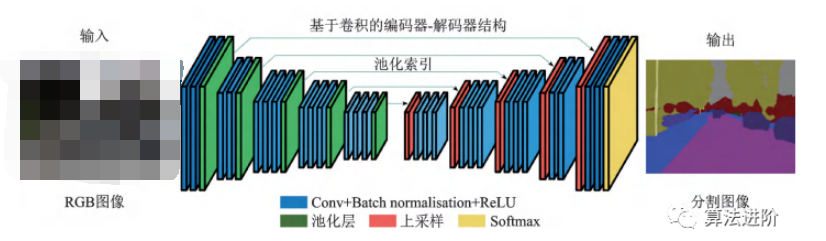
圖30 SegNet結(jié)構(gòu)示意圖
2017年香港中文大學(xué)提出PSPNet,采用金字塔池化模塊,用不同尺度的金字塔提取信息,通過(guò)雙線性插值恢復(fù)長(zhǎng)寬,融合多尺度信息。PSPNet在PASCALVOC2012和MSCOCO數(shù)據(jù)集上分別達(dá)到82.6%和85.4%的mIoU。結(jié)構(gòu)如圖31。
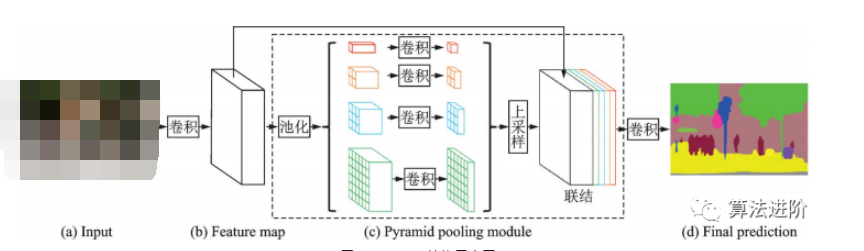
圖31?PSPNet結(jié)構(gòu)示意圖
DeepLabv2在DeepLabv1和PSPNet的基礎(chǔ)上,使用ResNet101和ASPP模塊提取特征圖信息,增加了感受野,其結(jié)構(gòu)如圖32所示,mIoU達(dá)79.7%。DeepLabv3重新審視了空洞卷積的作用,將其應(yīng)用在ResNet最后一個(gè)模塊之后,并改進(jìn)了ASPP模塊(圖33),去掉了后處理的DenseCRF模塊,mIoU達(dá)86.9%。圖34展示了不使用空洞卷積和使用空洞卷積的級(jí)聯(lián)模塊示意圖。DeepLabv3+,結(jié)構(gòu)如圖35,相對(duì)于DeepLabv3采用了“編碼器-解碼器”的結(jié)構(gòu)(圖36),并將骨干網(wǎng)絡(luò)替換為Xception,結(jié)合空洞深度可分離卷積,mIoU達(dá)89.0%。深度卷積、逐點(diǎn)卷積和空洞深度可分離卷積示意圖如圖 37所示。
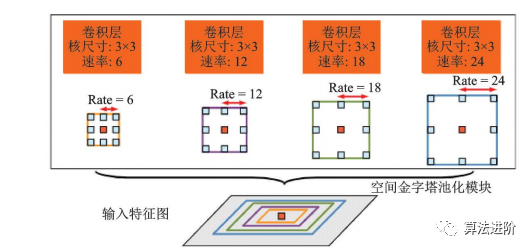
圖32 空洞空間金字塔池化示意圖
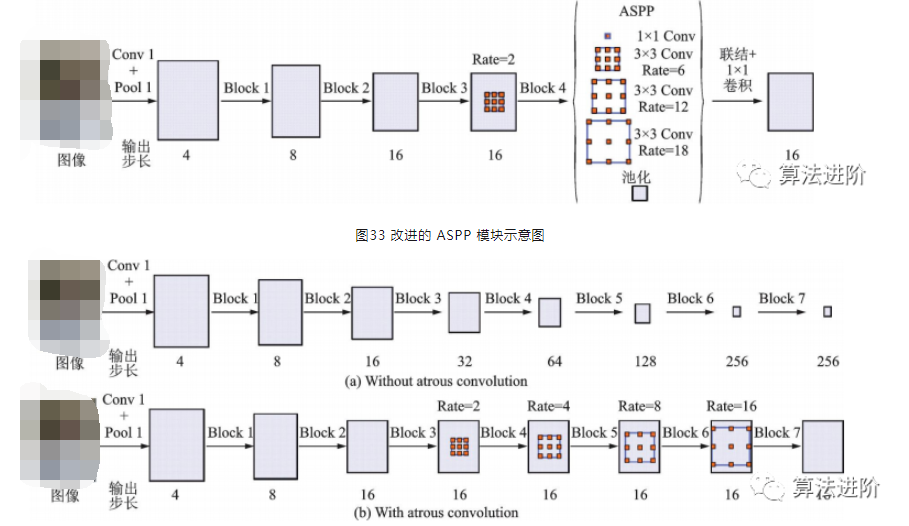
圖34 不使用和使用空洞卷積的級(jí)聯(lián)模塊示意圖
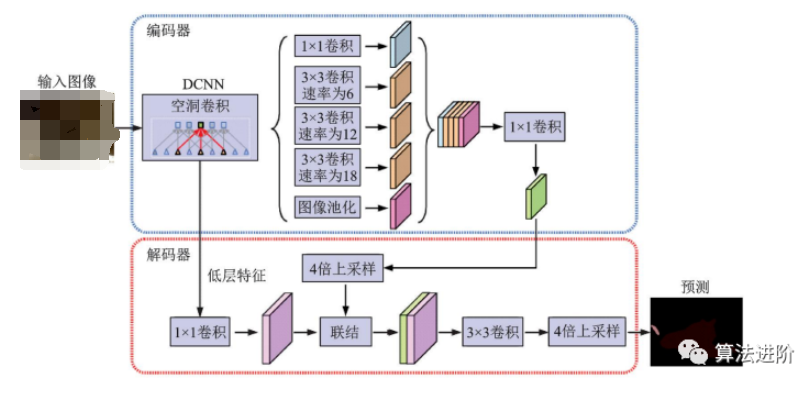
圖35?DeepLabv3+示意圖
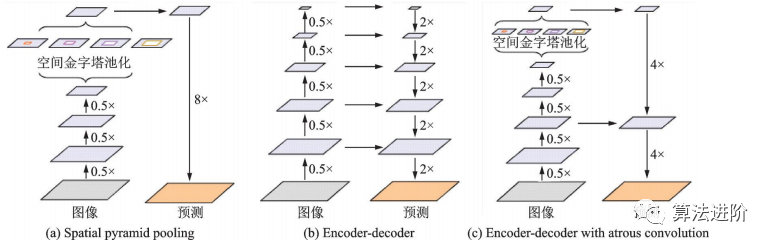
圖36?DeepLabv3+使用了空間金字塔池化模塊,“編碼器-解碼器”結(jié)構(gòu)和空洞卷積
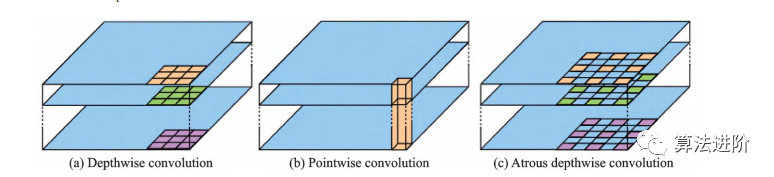
圖37 空洞深度可分離卷積示意圖
2019年,曠視科技提出DFANet高效CNN架構(gòu),通過(guò)子網(wǎng)和子級(jí)聯(lián)聚合多尺度特征,減少參數(shù)量,結(jié)構(gòu)如圖38所示。采用“編碼器-解碼器”結(jié)構(gòu),解碼器為3個(gè)改良輕量級(jí)Xception融合結(jié)構(gòu),編碼器為高效上采樣模塊。
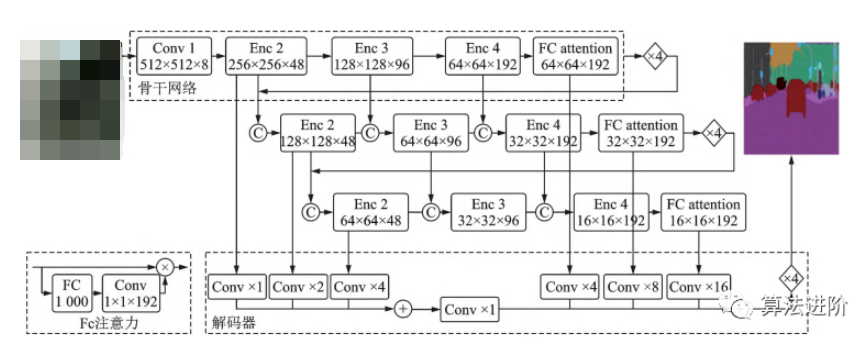
圖38 DFANet結(jié)構(gòu)示意圖 2020年提出的輕量級(jí)網(wǎng)絡(luò)LRNNet,包含分解卷積塊FCB(圖39(a))和高效的簡(jiǎn)化Non-Local模塊LRN(圖39(b))。FCB通過(guò)1×3和3×1的空間分解卷積處理短距離特征,并使用空洞深度分離卷積處理遠(yuǎn)距離特征。LRN利用區(qū)域主奇異向量作為Non-Local模塊的Key和Value,降低了計(jì)算量和內(nèi)存占用,同時(shí)保持處理遠(yuǎn)距離關(guān)聯(lián)的效果。
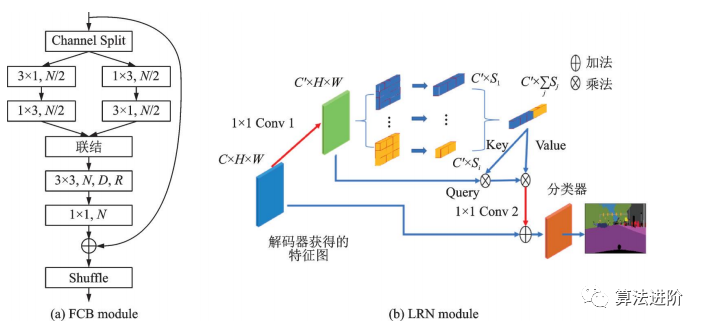
圖39 LRNNet中的?FCB?和?LRN?模塊
圖像分割需要像素級(jí)稠密分類,真值標(biāo)注耗時(shí)且昂貴。研究人員采用弱監(jiān)督和半監(jiān)督學(xué)習(xí)方法,使用圖像類別標(biāo)簽、邊界框、顯著圖和類激活圖等弱標(biāo)注訓(xùn)練網(wǎng)絡(luò)。
2015年谷歌和UCLA團(tuán)隊(duì)最早研究基于弱監(jiān)督學(xué)習(xí)技術(shù)的圖像分割算法,基于DeepLab模型,研究了弱標(biāo)注與少量強(qiáng)標(biāo)注和大量弱標(biāo)注混合對(duì)DCNN圖像分割模型的影響,提出了一種期望最大化方法,證實(shí)了僅使用圖像級(jí)標(biāo)簽的弱標(biāo)注存在性能差距,在半監(jiān)督設(shè)定下使用少量強(qiáng)標(biāo)注和大量弱標(biāo)注混合可以獲得優(yōu)越的性能。另一篇文獻(xiàn)提出一個(gè)僅使用類別標(biāo)簽和顯著圖信息的圖像分割模型,結(jié)構(gòu)如圖40所示。通過(guò)種子信息確定目標(biāo)的類別和位置,測(cè)試精度mIoU達(dá)到56.7%。AffinityNet結(jié)合類別標(biāo)簽和CAM信息,通過(guò)構(gòu)建圖像的語(yǔ)義相似度矩陣,結(jié)合隨機(jī)游走進(jìn)行擴(kuò)散,最終恢復(fù)出目標(biāo)的形狀。AffinityNet流程如圖 41 所示。
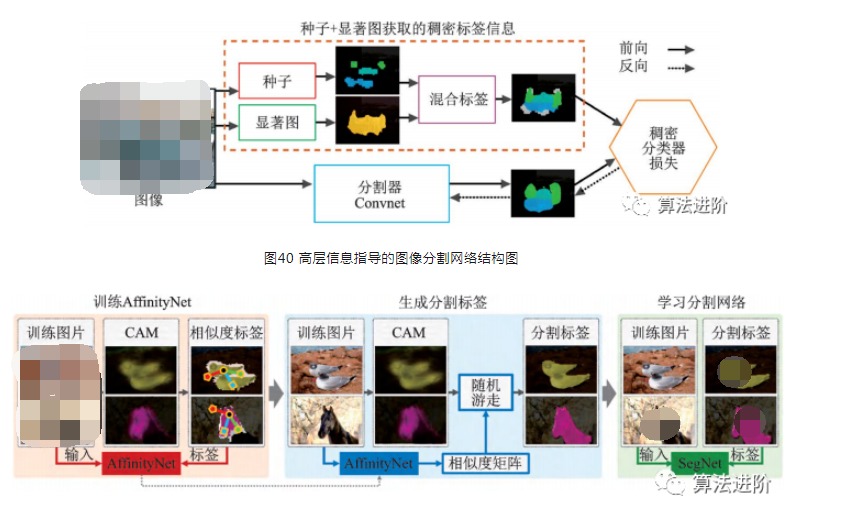
圖41 AffinityNet流程示意圖
深度學(xué)習(xí)在圖像分割領(lǐng)域取得了顯著成就,但仍面臨挑戰(zhàn)。當(dāng)前的大規(guī)模數(shù)據(jù)集無(wú)法滿足工業(yè)界需求,而具有多目標(biāo)和重疊目標(biāo)的數(shù)據(jù)集更具應(yīng)用價(jià)值。基于小樣本學(xué)習(xí)技術(shù)的圖像分割算法前景廣闊,醫(yī)學(xué)圖像分析等領(lǐng)域獲取學(xué)習(xí)樣本成本高、難度大。圖像分割技術(shù)的實(shí)時(shí)性是一個(gè)難題,大多數(shù)模型無(wú)法達(dá)到實(shí)時(shí)性要求,但在很多應(yīng)用場(chǎng)景下速度比精度更重要。 ? 深度學(xué)習(xí)在圖像分割領(lǐng)域取得顯著成果,但仍面臨挑戰(zhàn)。現(xiàn)有大規(guī)模數(shù)據(jù)集不能滿足工業(yè)需求,多目標(biāo)和重疊目標(biāo)數(shù)據(jù)集更具應(yīng)用價(jià)值。小樣本學(xué)習(xí)技術(shù)有前景,適用于醫(yī)學(xué)圖像分析等高成本領(lǐng)域。實(shí)時(shí)性是難題,速度在某些場(chǎng)景下比精度更重要。 ? 3. 3 超分辨率
超分辨率技術(shù)是計(jì)算機(jī)視覺(jué)領(lǐng)域提高圖像和視頻分辨率的關(guān)鍵處理技術(shù),廣泛應(yīng)用于高清電視、監(jiān)控視頻、醫(yī)學(xué)成像等領(lǐng)域。本文從圖像分類、目標(biāo)檢測(cè)、圖像分割到超分辨率,輸出逐級(jí)復(fù)雜,最后生成比輸入圖像大的高分辨率圖像,需要生成輸入中不存在的信息。
超分辨率概念始于光學(xué)領(lǐng)域,1952年Francia提出,1964年Harris和Goodman提出Harris?Goodman頻譜外推方法,但實(shí)際效果不佳。1984年Tsai首次利用單幅低分辨率圖像的頻域信息重建高分辨率圖像,超分辨率重建技術(shù)得到廣泛認(rèn)可和應(yīng)用,成為圖像增強(qiáng)和計(jì)算機(jī)視覺(jué)領(lǐng)域的重要研究方向。
傳統(tǒng)的超分辨率方法包括基于預(yù)測(cè)、基于邊緣、基于統(tǒng)計(jì)、基于塊和基于稀疏表示等方法。根據(jù)輸入輸出的不同,超分辨率問(wèn)題可以分為基于重建的超分辨率問(wèn)題、視頻超分辨率問(wèn)題和單幅圖像超分辨率問(wèn)題。根據(jù)是否依賴訓(xùn)練樣本,超分辨率問(wèn)題則又可以分為增強(qiáng)邊緣的超分辨率問(wèn)題(無(wú)訓(xùn)練樣本)和基于學(xué)習(xí)的超分辨率問(wèn)題(有訓(xùn)練樣本)。
插值法是最簡(jiǎn)單的單幅圖像超分辨率方法,包括Lanczos、Bicubic、Bilinear和Nearest等,操作簡(jiǎn)單、實(shí)施性好,但難以恢復(fù)清晰邊緣和細(xì)節(jié)。因此,許多傳統(tǒng)算法被提出,以增強(qiáng)細(xì)節(jié)。其中,基于塊的方法,利用局部線性嵌入重構(gòu)高分辨率圖像。基于稀疏表示的方法,將圖像表示為字典D與原子α,用低分辨率圖像得到α,重構(gòu)高清圖像。基于學(xué)習(xí)的超分辨率技術(shù)如圖42所示,上、下采樣方法示意圖如圖43所示。
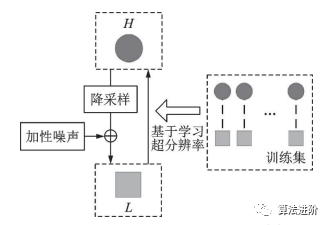
圖42 基于學(xué)習(xí)的超分辨率技術(shù)
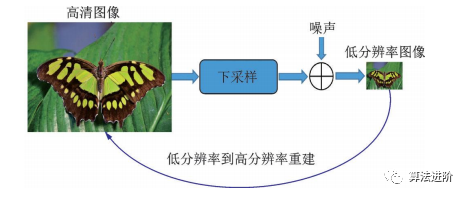
圖43?超分辨率問(wèn)題中的上采樣和下采樣方法 ?
深度學(xué)習(xí)技術(shù)在超分辨率領(lǐng)域的應(yīng)用研究。
香港中文大學(xué)Dong等于 2015年首次將卷積神經(jīng)網(wǎng)絡(luò)用于單幅圖像超分辨率重建,提出了SRCNN。SRCNN激活函數(shù)采用 ReLU,損失函數(shù)采用均方誤差,流程圖如圖44所示。
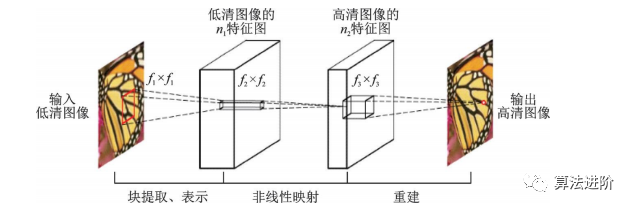
圖44 SRCNN?流程圖
2016年Dong團(tuán)隊(duì)提出了FSRCNN,這是一種更快、更實(shí)時(shí)的超分辨率卷積神經(jīng)網(wǎng)絡(luò)。FSRCNN在原始SRCNN的基礎(chǔ)上,加入反卷積層放大尺寸,摒棄 Bicubic插值法,使用更多映射層和更小卷積核,改變特征維度并共享映射層,F(xiàn)SRCNN改進(jìn)示意圖如圖45所示。
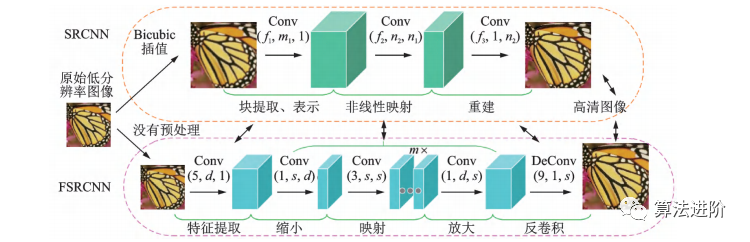
圖45 FSRCNN 對(duì) SRCNN 的改進(jìn)
同年提出的ESPCN是一種基于SRCNN的超分辨率網(wǎng)絡(luò),結(jié)構(gòu)如圖46所示。主要特點(diǎn)是提高了速度,其引入了一種亞像素卷積層,直接在低分辨率圖像上提取特征,降低計(jì)算復(fù)雜度。
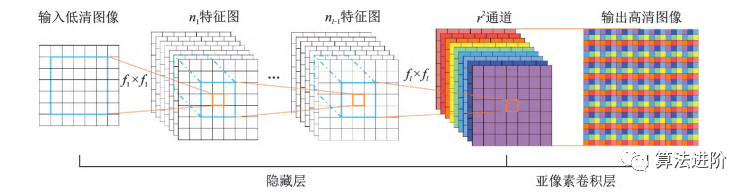
圖46?ESPCN示意圖
由于 SRCNN的計(jì)算復(fù)雜度高,F(xiàn)SRCNN和 ESPCN選擇在網(wǎng)絡(luò)末端上采樣以降低復(fù)雜度。但上采樣后沒(méi)有足夠深的網(wǎng)絡(luò)提取特征,圖像信息就會(huì)損失。為了解決這個(gè)問(wèn)題,很多工作引入了殘差網(wǎng)絡(luò)。Kim等人在 2016年提出的 VDSR是第一個(gè)引入全局殘差的模型,結(jié)構(gòu)如圖47。高低分辨率圖像攜帶的低頻信息很相近,因此網(wǎng)絡(luò)只需要學(xué)習(xí)高頻信息之間的殘差即可。
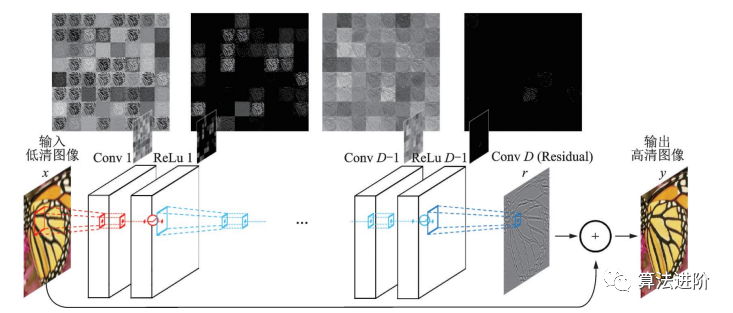
圖47 VSDR 網(wǎng)絡(luò)結(jié)構(gòu)圖
CARN是NTIRE2018超分辨率挑戰(zhàn)賽冠軍方案,采用全局和局部級(jí)聯(lián),用級(jí)聯(lián)模塊和1×1卷積模塊替換ResNet殘差塊,并提出殘差?E模塊提升效率。如圖48和圖49所示。
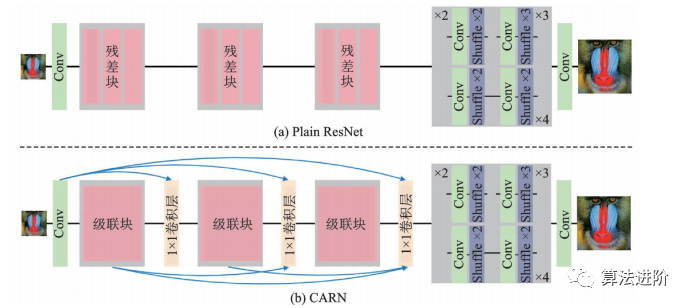
圖48 CARN 對(duì)于 ResNet的改進(jìn)
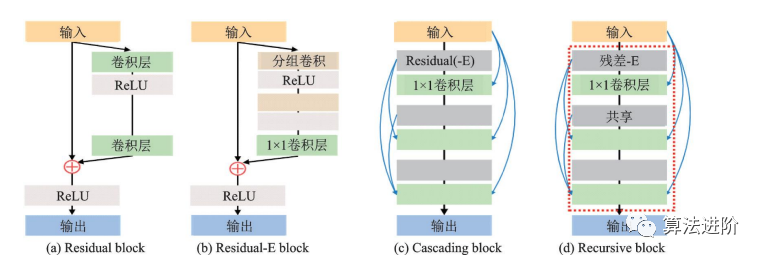
圖49 殘差-E 模塊與其他常見(jiàn)模塊的對(duì)比
EDVR是商湯科技2019年提出的一種視頻修復(fù)通用框架,在NITRE2019的4個(gè)賽道中均獲得冠軍。它通過(guò)增強(qiáng)的可變形卷積網(wǎng)絡(luò)實(shí)現(xiàn)視頻修復(fù)和增強(qiáng),適用于各種視頻修復(fù)任務(wù)。EDVR框架示意圖如圖50所示。EDVR提出了PCD對(duì)齊模塊和TSA兩個(gè)模塊,結(jié)構(gòu)如圖51所示。PCD模塊用可變形卷積將每個(gè)相鄰幀與參考幀對(duì)齊,TSA模塊用于在多個(gè)對(duì)齊的特征層之間融合信息。?
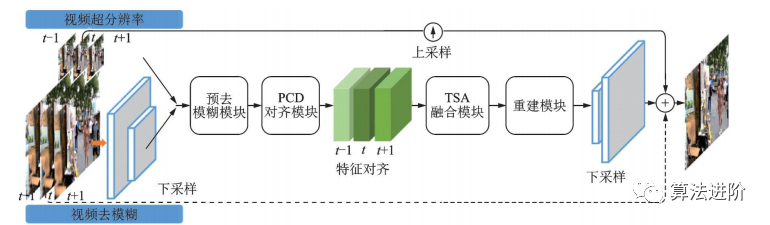
圖50 EVDR 框架示意圖
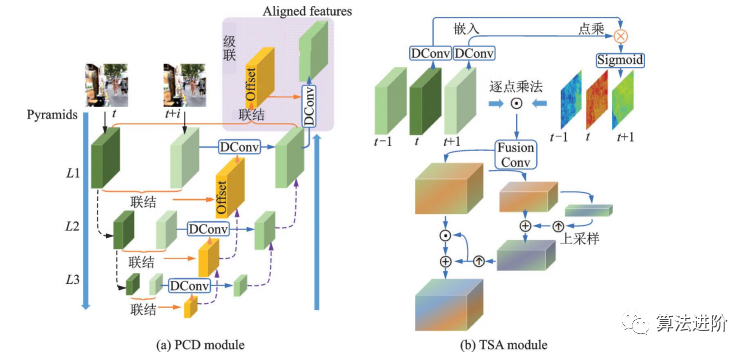
圖51?EVDR中的 PCD 模塊和 TSA 模塊 ?
FSTRN(2019)將三維卷積用于視頻超分辨率,通過(guò)分解三維濾波器降低復(fù)雜度,實(shí)現(xiàn)更深網(wǎng)絡(luò)和更好性能。此外,提出跨空間殘差學(xué)習(xí)方法,連接低分辨率空間和高分辨率空間,減輕計(jì)算負(fù)擔(dān)。FSTRN結(jié)構(gòu)如圖52所示。
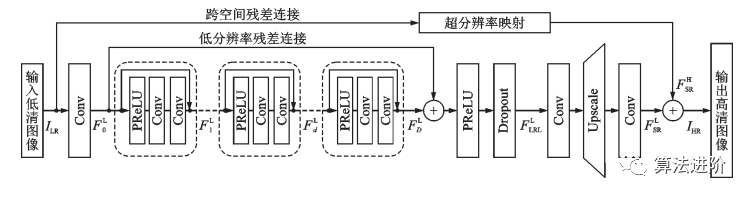
圖52 FSTRN 結(jié)構(gòu)示意圖
深度學(xué)習(xí)技術(shù)的發(fā)展推動(dòng)了超分辨率領(lǐng)域的快速進(jìn)步,出現(xiàn)了許多性能優(yōu)異的模型,但距離實(shí)際應(yīng)用仍有差距。圖像配準(zhǔn)技術(shù)對(duì)多幀圖像超分辨率重建效果至關(guān)重要,但目前還沒(méi)有成熟的解決方案。另一難點(diǎn)是密集計(jì)算限制了視頻超分辨率重建的計(jì)算效率,難以達(dá)到實(shí)時(shí)性要求。魯棒性和可遷移性是未來(lái)的研究熱點(diǎn),現(xiàn)有的評(píng)價(jià)標(biāo)準(zhǔn)還不夠客觀,有時(shí)與人眼視覺(jué)相違背。
4? 神經(jīng)架構(gòu)搜索
深度學(xué)習(xí)在圖像分類、語(yǔ)音識(shí)別等領(lǐng)域取得顯著成功。神經(jīng)架構(gòu)搜索技術(shù)(Neuralarchitecturesearch,NAS)可自動(dòng)設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu),如圖像分割的Auto-DeepLab和目標(biāo)檢測(cè)的NAS-FPN。NAS是機(jī)器學(xué)習(xí)自動(dòng)化的子領(lǐng)域,代表未來(lái)發(fā)展方向。流程包括搜索空間、搜索策略和性能評(píng)估,如圖53所示。搜索空間包括網(wǎng)絡(luò)架構(gòu)參數(shù)和超參數(shù),如卷積層、池化層等,典型的網(wǎng)絡(luò)架構(gòu)如圖54所示。搜索策略有隨機(jī)搜索、貝葉斯優(yōu)化、遺傳算法、強(qiáng)化學(xué)習(xí)等。性能評(píng)估需降低成本,可能導(dǎo)致偏差。更高級(jí)策略包括權(quán)重共享、通過(guò)迭代表現(xiàn)推斷最終性能等。
DARTS是第一個(gè)基于連續(xù)松弛的搜索空間的神經(jīng)網(wǎng)絡(luò)架構(gòu)技術(shù),通過(guò)梯度下降優(yōu)化網(wǎng)絡(luò)在驗(yàn)證集上的性能,實(shí)現(xiàn)了端到端的網(wǎng)絡(luò)搜索,大大減少了迭代次數(shù),降低了搜索時(shí)間。DARTS流程包括:初始未知操作、候選操作的組合、雙層規(guī)劃問(wèn)題聯(lián)合優(yōu)化混合概率與網(wǎng)絡(luò)權(quán)重、用學(xué)到的混合概率求得最終的網(wǎng)絡(luò)架構(gòu),如圖55。DARTS適用于CNN和RNN,在CIFAR-10和PTB數(shù)據(jù)集上取得了優(yōu)異性能,優(yōu)于很多手工設(shè)計(jì)的輕量化模型。
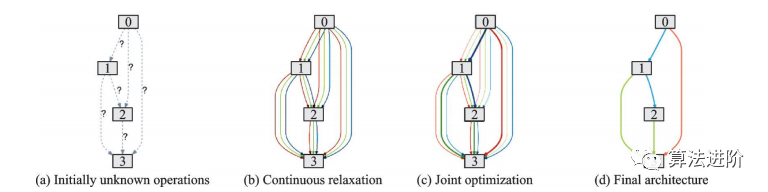
圖55?DARTS流程示意圖
基于DARTS,一系列改進(jìn)算法相繼提出,包括P-DARTS、ProxylessNAS、DARTS+和SNAS。P-DARTS采用漸進(jìn)式搜索,逐步增加網(wǎng)絡(luò)深度和減少候選操作數(shù)量,如圖56所示。ProxylessNAS提出無(wú)代理神經(jīng)架構(gòu)搜索技術(shù),降低顯存需求,并首次提出針對(duì)特定時(shí)延的神經(jīng)網(wǎng)絡(luò)架構(gòu)方法,如圖57所示。DARTS+通過(guò)引入早停機(jī)制,縮短搜索時(shí)間并提高性能,如圖58所示。SNAS將NAS重新表述為聯(lián)合分布參數(shù)優(yōu)化問(wèn)題,直接優(yōu)化損失函數(shù),偏差更小。PC-DARTS在P-DARTS基礎(chǔ)上設(shè)計(jì)了部分通道連接機(jī)制,節(jié)省訓(xùn)練資源,降低不確定性,取得更快更好的搜索效果,如圖59所示。
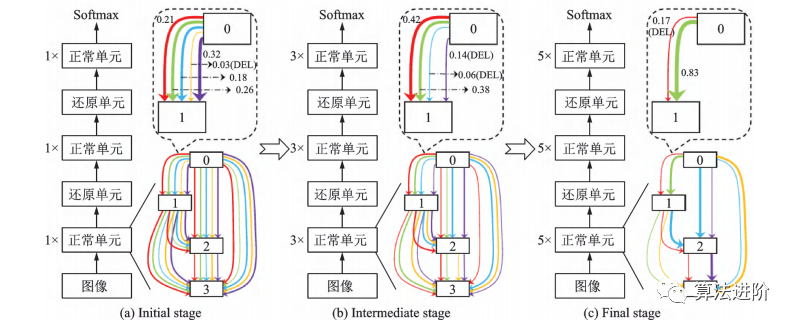
圖56 P-DARTS?流程示意圖
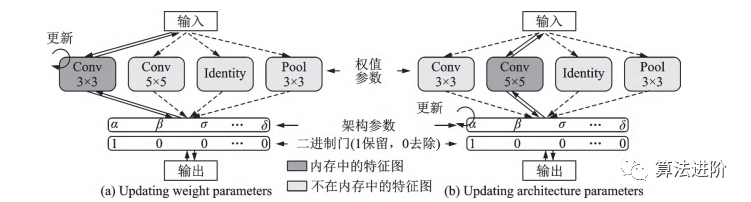
圖57 ProxylessNAS?示意圖
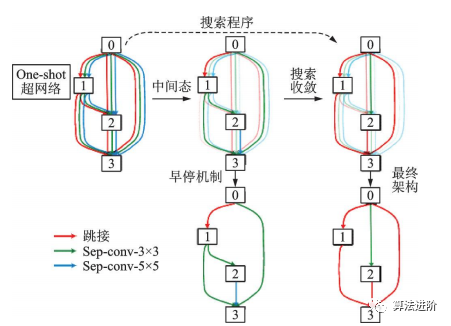
圖58 DARTS+中的早停機(jī)制示意圖
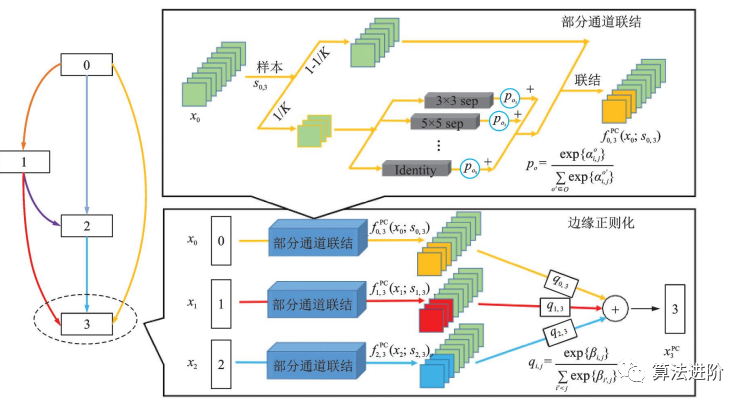
圖59?PC?-DARTS?結(jié)構(gòu)示意圖
神經(jīng)架構(gòu)搜索技術(shù)主要應(yīng)用于圖像分類任務(wù),但搜索空間的定義限制了其設(shè)計(jì)出與人工網(wǎng)絡(luò)有本質(zhì)區(qū)別的網(wǎng)絡(luò)。此外,NAS技術(shù)設(shè)計(jì)的網(wǎng)絡(luò)可解釋性差,不同研究者的方法不同,使得NAS設(shè)計(jì)出的架構(gòu)難以復(fù)現(xiàn)和比較性能。因此,神經(jīng)架構(gòu)搜索領(lǐng)域仍面臨挑戰(zhàn),如何解決這些問(wèn)題將是未來(lái)的研究方向之一。
5? 總結(jié)
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)中的目標(biāo)檢測(cè)、圖像分割、超分辨率和模型壓縮等任務(wù)上取得卓越成績(jī),但仍存在難題,如對(duì)數(shù)據(jù)依賴強(qiáng)、模型遷移困難、可解釋性不強(qiáng)。科技巨頭投入巨型模型建設(shè),如GPT的訓(xùn)練需要大量時(shí)間和計(jì)算資源。且深度學(xué)習(xí)依賴大規(guī)模帶標(biāo)簽數(shù)據(jù)集,無(wú)監(jiān)督學(xué)習(xí)和自監(jiān)督技術(shù)是重要研究方向。同時(shí),深度學(xué)習(xí)技術(shù)帶來(lái)的安全隱患也引起重視,優(yōu)化分布式訓(xùn)練是具有潛力的研究方向。
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論