 電子發(fā)燒友App
電子發(fā)燒友App


作者:lovelypanda
1. 筆者總結(jié)
本文方法是一種自監(jiān)督的單目深度估計(jì)框架,名為GasMono,專門設(shè)計(jì)用于室內(nèi)場(chǎng)景。本方法通過應(yīng)用多視圖幾何的方式解決了室內(nèi)場(chǎng)景中幀間大旋轉(zhuǎn)和低紋理導(dǎo)致自監(jiān)督深度估計(jì)困難的挑戰(zhàn)。GasMono首先利用多視圖幾何方法獲取粗糙的相機(jī)姿態(tài),然后通過旋轉(zhuǎn)和平移/尺度優(yōu)化來進(jìn)一步優(yōu)化這些姿態(tài)。為了減輕低紋理的影響,該框架將視覺Transformer與迭代式自蒸餾機(jī)制相結(jié)合。通過在多個(gè)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),展示了GasMono框架在室內(nèi)自監(jiān)督單目深度估計(jì)方面的最先進(jìn)性能。
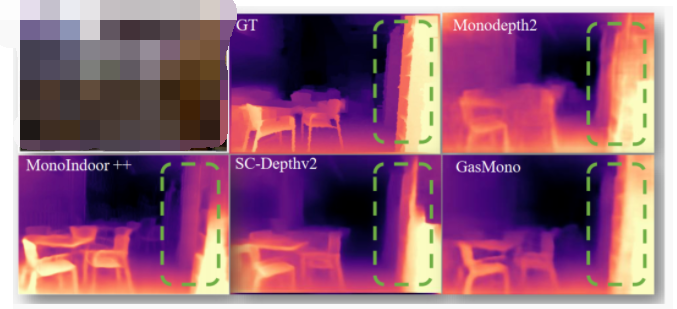
圖1. 現(xiàn)有方法和GasMono的比較。我們的框架在薄物體和全局結(jié)構(gòu)上展現(xiàn)出了卓越的精度。
2. 原文摘要
本文針對(duì)室內(nèi)場(chǎng)景中存在的大旋轉(zhuǎn)和低紋理等挑戰(zhàn),提出了一種單目自監(jiān)督深度估計(jì)的框架。我們通過利用多視幾何方法從單目序列中估計(jì)粗略的相機(jī)姿態(tài)來緩解大旋轉(zhuǎn)的問題。然而,我們發(fā)現(xiàn)由于訓(xùn)練集中不同場(chǎng)景間的尺度不確定性,直接使用幾何粗略姿態(tài)并不能提升深度估計(jì)的性能,這與直覺相悖。為了解決這個(gè)問題,我們提出在訓(xùn)練過程中對(duì)這些姿態(tài)進(jìn)行旋轉(zhuǎn)和平移/尺度優(yōu)化。為了應(yīng)對(duì)低紋理的問題,我們將視覺Transformer的全局推理能力與迭代式自蒸餾機(jī)制相結(jié)合,提供來自網(wǎng)絡(luò)自身的更準(zhǔn)確的深度指導(dǎo)。在NYUv2、ScanNet、7scenes和KITTI數(shù)據(jù)集上的實(shí)驗(yàn)驗(yàn)證了我們框架中每個(gè)組件的有效性,我們的方法在室內(nèi)自監(jiān)督單目深度估計(jì)方面達(dá)到了最先進(jìn)的水平,并展現(xiàn)了優(yōu)異的泛化能力。
3. GasMono框架
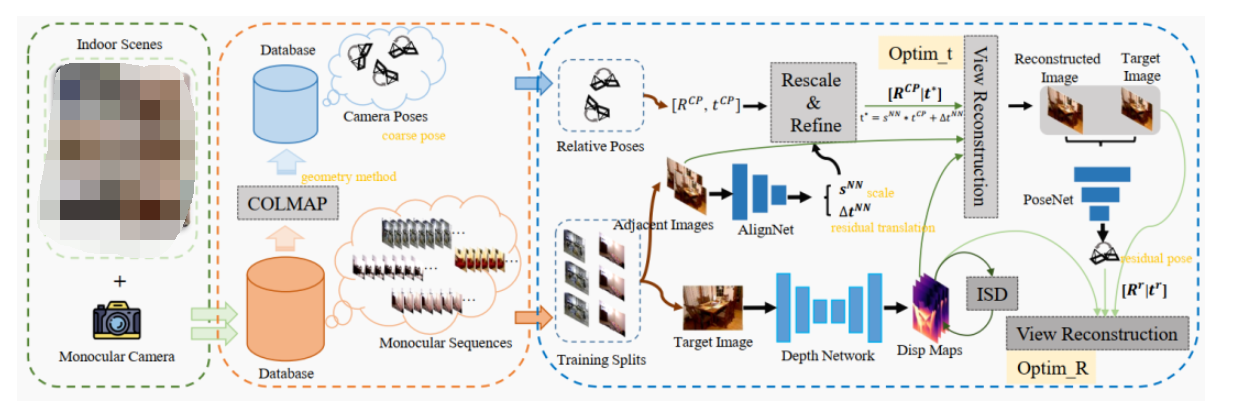
圖2. GasMono: 一種基于幾何的自監(jiān)督單目深度估計(jì)框架,用于室內(nèi)場(chǎng)景。注意,在訓(xùn)練過程中沒有使用真實(shí)標(biāo)簽。通過從多個(gè)室內(nèi)場(chǎng)景中選擇的單目圖像序列,使用結(jié)構(gòu)從運(yùn)動(dòng)(structure-from-motion)軟件包COLMAP來估計(jì)每個(gè)序列上相機(jī)的粗略姿態(tài)。然后,使用圖像序列和粗略姿態(tài)來訓(xùn)練深度模型。為了改善粗略的平移,設(shè)計(jì)了一個(gè)AlignNet來估計(jì)尺度sNN和殘差平移?t。此外,還設(shè)計(jì)了一個(gè)PoseNet來進(jìn)一步改善姿態(tài),特別是基于重建和目標(biāo)圖像的粗略旋轉(zhuǎn)。AlignNet和PoseNet只在訓(xùn)練過程中使用。
3.1. 幾何輔助姿態(tài)估計(jì)
自監(jiān)督單目深度估計(jì)框架對(duì)于訓(xùn)練視頻序列的標(biāo)準(zhǔn)監(jiān)督協(xié)議包括根據(jù)估計(jì)的深度Dt和相對(duì)相機(jī)姿態(tài)Et→s = Rt→s|tt→s將像素從源圖像Is重投影到目標(biāo)It。這意味著對(duì)于目標(biāo)視圖中的像素pt,它在源視圖中的坐標(biāo)ps可以得到
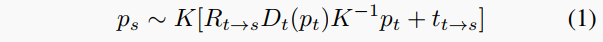
鑒于在圖像之間學(xué)習(xí)準(zhǔn)確的相對(duì)姿態(tài)存在大旋轉(zhuǎn)的挑戰(zhàn),我們提出擺脫通常使用的PoseNet,并用傳統(tǒng)姿態(tài)估計(jì)算法替換它。為此,我們利用COLMAP為訓(xùn)練集中每個(gè)單獨(dú)的室內(nèi)序列的圖像Ii獲得相機(jī)姿態(tài)ECPi = RCPi |tCPi。然后,對(duì)于給定的圖像對(duì)It,Is,分別是目標(biāo)和源幀,我們可以獲得兩者之間的相對(duì)姿態(tài) Et→s = RCPt→s|tCPt→s = ECPsECPt?1。與兩幀姿態(tài)估計(jì)不同,COLMAP等結(jié)構(gòu)從運(yùn)動(dòng)管道可以在整個(gè)序列上進(jìn)行全局推理。我們認(rèn)為,由于姿態(tài)估計(jì)是學(xué)習(xí)單目深度的一個(gè)邊緣任務(wù),利用整個(gè)序列是值得的。
盡管如此,COLMAP估計(jì)的姿態(tài),我們將稱之為粗略姿態(tài),有一些問題,特別是1)在訓(xùn)練集的不同序列之間存在尺度不一致性和由于單目歧義導(dǎo)致的尺度漂移,2)由于缺乏紋理導(dǎo)致的旋轉(zhuǎn)和平移中的噪聲。這使得COLMAP本身無法無縫地替代PoseNet來訓(xùn)練單目深度網(wǎng)絡(luò)。
3.1.1 平移縮放和精煉
為了解決前一個(gè)問題,我們部署一個(gè)淺層網(wǎng)絡(luò)AlignNet來在訓(xùn)練過程中精煉平移并重新縮放它,以克服跨訓(xùn)練集中的不同序列的尺度不一致性。
因此,AlignNet處理目標(biāo)和源圖像,并預(yù)測(cè)應(yīng)用于COLMAP估計(jì)的平移分量tCPt→s的尺度因子sNN和殘差移位ΔtNN。然后,從目標(biāo)視圖到源視圖的估計(jì)平移tt→s得到為
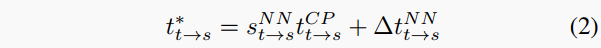
這向量用于方程1,導(dǎo)致僅在學(xué)習(xí)估計(jì)單目深度圖時(shí)調(diào)整訓(xùn)練圖像的尺度,使用RCPt→s|t?t→s。
我們可以將AlignNet視為一個(gè)訓(xùn)練優(yōu)化工具,在訓(xùn)練過程中精煉粗略姿態(tài)以使其整體尺度一致。因此,一旦完成訓(xùn)練,它就失去了效用。

圖3. 不同編碼器對(duì)低紋理深度估計(jì)的影響。
3.1.2 旋轉(zhuǎn)優(yōu)化
前面部分僅關(guān)注平移優(yōu)化,盡管粗略姿態(tài)估計(jì)的旋轉(zhuǎn)也可能不準(zhǔn)確和嘈雜,所以也提出了旋轉(zhuǎn)優(yōu)化。為了進(jìn)一步展示訓(xùn)練中旋轉(zhuǎn)優(yōu)化的效果,在圖3中,我們分別報(bào)告了不準(zhǔn)確粗略旋轉(zhuǎn)(頂部樣本)和準(zhǔn)確粗略旋轉(zhuǎn)(底部樣本)的樣本。對(duì)于兩者,我們基于“Optim t”和“Optim R”計(jì)算重構(gòu)損失,并在第3列中給出。對(duì)于第一個(gè)樣本,由于不準(zhǔn)確的粗略旋轉(zhuǎn),僅優(yōu)化平移(“Optim t”,第1行)無法補(bǔ)償錯(cuò)誤旋轉(zhuǎn),從而產(chǎn)生高的重投影誤差。在精煉旋轉(zhuǎn)之后,基于“Optim R”的重構(gòu)(第2行)產(chǎn)生了更低的光度誤差。相反,在第二個(gè)樣本中顯示準(zhǔn)確的粗略姿態(tài),基于“Optim t”的重構(gòu)已經(jīng)可以達(dá)到合理的重構(gòu)圖像。
3.2 低紋理區(qū)域
在自監(jiān)督訓(xùn)練中,反向傳播行為回復(fù)到RGB圖像的光度漸變變化。那些具有有效光度變化的區(qū)域?yàn)?a href="http://www.1cnz.cn/v/tag/448/" target="_blank">深度學(xué)習(xí)提供強(qiáng)大的漸變,而低紋理區(qū)域,如墻壁和地板,無法提供有效的監(jiān)督信號(hào),因?yàn)閷?duì)深度的多個(gè)假設(shè)導(dǎo)致光度誤差接近零,從而使網(wǎng)絡(luò)陷入局部最小值。因此,對(duì)于低紋理區(qū)域,深度估計(jì)過程主要依賴于網(wǎng)絡(luò)自身的推理能力。使用某些額外約束可能有助于緩解這個(gè)問題,這些約束來自諸如光流或平面法線之類的提示。盡管如此,這需要額外的監(jiān)督,并且由于低紋理而在光流的情況下也可能遭受同樣的問題。因此,我們選擇在架構(gòu)方面解決它,特別是通過Transformer超越CNN的有限感受野。此外,以前的工作證明了標(biāo)簽蒸餾的有效性,以提高深度網(wǎng)絡(luò)的準(zhǔn)確性。
3.2.1 網(wǎng)絡(luò)架構(gòu)
我們的框架由三個(gè)網(wǎng)絡(luò)組成,一個(gè)用于單目深度估計(jì)的Depth Network,一個(gè)用于尺度校正和殘差平移預(yù)測(cè)的Alignment Network(AlignNet),以及一個(gè)用于殘差姿態(tài)估計(jì)的PoseNet。整體訓(xùn)練架構(gòu)如圖2所示。
考慮到Transformer在特征之間建模長(zhǎng)程關(guān)系的出色性能,為了增強(qiáng)低紋理區(qū)域的全局特征提取,我們引入了一個(gè)Transformer編碼器MPViT作為深度編碼器。編碼器中的自注意力機(jī)制以一種高效的因素化方式實(shí)現(xiàn):
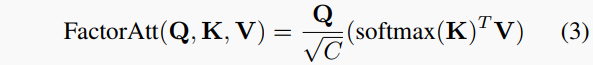
其中C指的是嵌入維度。查詢(Q)、鍵(K)和值(V∈R^{N×C})向量是從視覺標(biāo)記投影的。此外,對(duì)于深度解碼器,我們用Convex upsampling 替換了Monodepth2等使用的標(biāo)準(zhǔn)上采樣,將4個(gè)縮放度圖像映射帶到全分辨率,在此它們用于下面描述的迭代自我蒸餾操作。

3.2.2 迭代自我蒸餾
我們提出一個(gè)過擬合驅(qū)動(dòng)的迭代自我蒸餾(ISD)過程,以獲得最小像素重投影誤差的深度圖,為任何特定訓(xùn)練樣本提供更準(zhǔn)確的標(biāo)簽。ISD的關(guān)鍵步驟在算法1中列出。對(duì)于每張訓(xùn)練圖像,我們多次迭代此過程(行4)。在第一次迭代中,我們?cè)谒谐叨壬线x擇每個(gè)像素的最小重建誤差及其對(duì)應(yīng)的預(yù)測(cè)深度(第6-14行)。然后,我們通過最小化當(dāng)前最佳深度圖與每個(gè)尺度上的預(yù)測(cè)之間的深度損失來更新網(wǎng)絡(luò)(第15-16行)。重復(fù)此過程多次迭代。
3.3 訓(xùn)練損失
訓(xùn)練損失的關(guān)鍵項(xiàng)由最小視圖重建損失組成。
視圖重建損失。對(duì)于重構(gòu)圖像I~的誤差相對(duì)于目標(biāo)圖像I,我們采用結(jié)構(gòu)相似性指數(shù)度量(SSIM)和L1差異的組合進(jìn)行衡量:
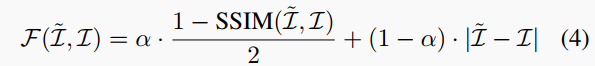
其中α通常設(shè)置為0.85 。此外,為了減輕兩視圖之間的遮擋效應(yīng),相對(duì)于前向和后向相鄰幀進(jìn)行變形的損失的最小值被計(jì)算:
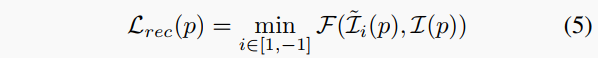
其中‘1’和‘-1’分別指前向和后向相鄰幀。
光滑損失。邊緣感知平滑損失用于進(jìn)一步改進(jìn)反深度映射d:
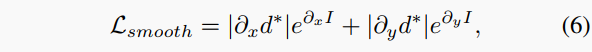
其中表示平均歸一化的反深度。并計(jì)算一個(gè)自動(dòng)掩碼μ來過濾靜止幀和一些重復(fù)的紋理區(qū)域。
迭代自我蒸餾損失。如前所述,GasMono自我蒸餾偽標(biāo)簽以提供額外的監(jiān)督。給定根據(jù)算法1獲得的偽標(biāo)簽,我們最小化預(yù)測(cè)深度d相對(duì)于它的對(duì)數(shù)誤差:
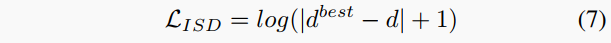
總損失。最后,在任何給定尺度上計(jì)算視圖重建損失、光滑損失 和蒸餾項(xiàng)(均帶到全分辨率),以獲得總損失項(xiàng)。更具體地說,計(jì)算兩個(gè)重建損失,即 和 :
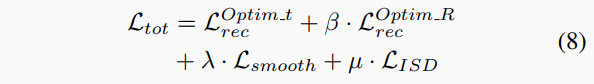
其中和分別基于平移和旋轉(zhuǎn)優(yōu)化后得到的姿態(tài)進(jìn)行圖像重建計(jì)算,β、λ和μ分別設(shè)置為0.2、0.001和0.1。最后,在所有尺度上平均總損失。
4. 實(shí)驗(yàn)結(jié)果
本文的實(shí)驗(yàn)結(jié)果主要通過在多個(gè)數(shù)據(jù)集上分析和比較GasMono框架的性能來進(jìn)行評(píng)估。在實(shí)驗(yàn)部分,作者使用了三個(gè)室內(nèi)數(shù)據(jù)集(NYUv2、7scenes和ScanNet)和一個(gè)室外數(shù)據(jù)集(KITTI)。作者對(duì)GasMono的行為進(jìn)行了詳細(xì)的研究,分析了使用COLMAP位置和姿態(tài)優(yōu)化策略訓(xùn)練的GasMono的效果。此外,作者還對(duì)模型的各個(gè)組件進(jìn)行了消融實(shí)驗(yàn),評(píng)估了它們對(duì)解決室內(nèi)單目深度估計(jì)挑戰(zhàn)的貢獻(xiàn)。最后,作者還與現(xiàn)有的先進(jìn)方法進(jìn)行了比較,證明了GasMono在室內(nèi)自監(jiān)督單目深度估計(jì)中的優(yōu)勢(shì)。
表1. 消融研究。
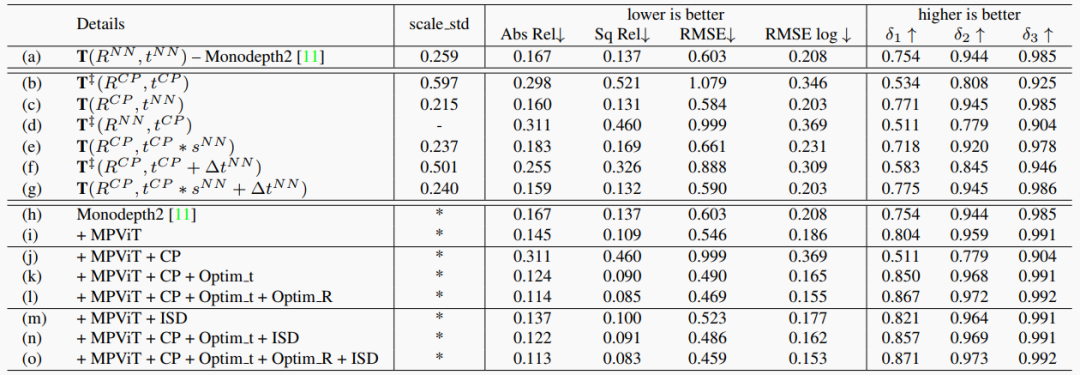
表2. 在室外KITTI數(shù)據(jù)集上測(cè)試了我們的ISD和不同基線方法。
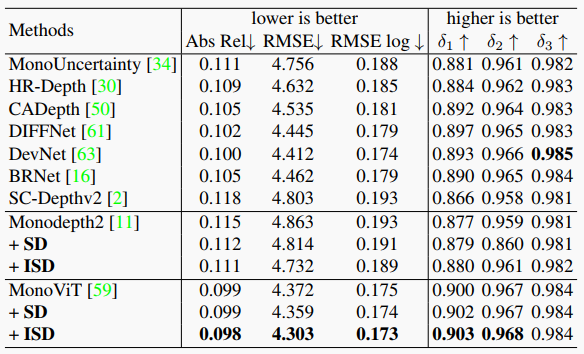
表3. 在NYUv2上的評(píng)估結(jié)果。
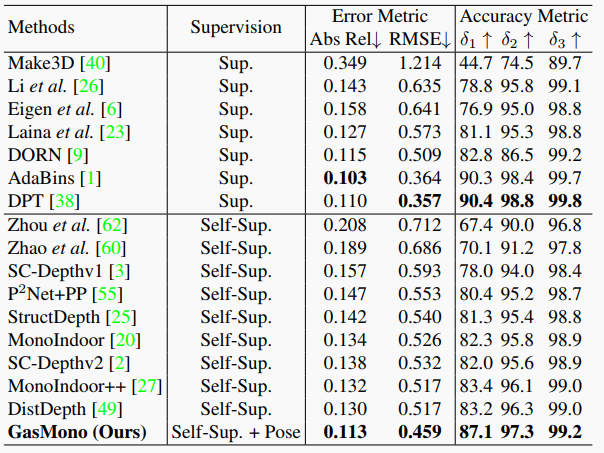
表4. 在ScanNet上的零測(cè)量泛化結(jié)果。
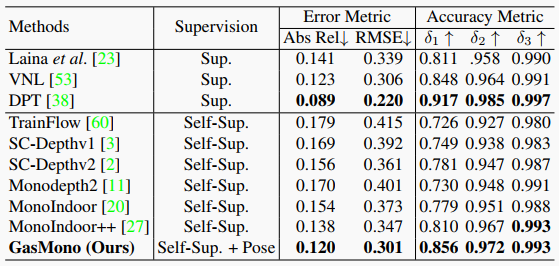
表5. 在RGB-D 7場(chǎng)景上的零測(cè)量泛化結(jié)果。注意,Monoindoor++從每個(gè)視頻序列中提取每30幀的第一張圖像作為測(cè)試集,而我們遵循SC-Depthv2,從每10幀中提取第一張圖像。
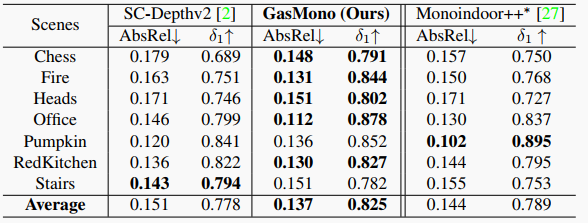
表6. 在RGB-D 7場(chǎng)景上微調(diào)后的結(jié)果。
可視化結(jié)果如下:

圖4. 深度評(píng)估中的低紋理區(qū)域。

圖5. 在NYUv2上的定性比較。我們的GasMono相比于基線方法Monodepth2和最近的工作SC-Depthv2,獲得了更細(xì)致和更準(zhǔn)確的深度估計(jì)。

圖6. 在ScanNet和7scenes上的泛化比較。與TrainFlow、Monodepth2和SC-Depthv2相比,GasMono在新場(chǎng)景上顯示出更準(zhǔn)確和更細(xì)致的深度估計(jì)。

5. 結(jié)論
本文提出了GasMono,一種利用幾何信息的自監(jiān)督單目深度估計(jì)框架,適用于復(fù)雜的室內(nèi)場(chǎng)景。我們的方法通過縮放和精煉兩個(gè)步驟,解決了自監(jiān)督訓(xùn)練中由于姿態(tài)估計(jì)不準(zhǔn)確而導(dǎo)致的尺度不一致和深度不精確的問題,并有效地利用了幾何方法提供的粗略姿態(tài)。實(shí)驗(yàn)結(jié)果表明,我們的方法在NYUv2和KITTI數(shù)據(jù)集上顯著并穩(wěn)定地超越了所有現(xiàn)有方法。此外,我們的方法在ScanNet和7Scenes數(shù)據(jù)集上也表現(xiàn)出了優(yōu)異的泛化能力。
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論