 電子發燒友App
電子發燒友App


?
推薦系統是機器學習的一類,它可使用數據來幫助預測、縮小范圍,并找到人們在呈指數級增長的選項中尋找的內容。
1?
什么是推薦系統?
推薦系統是一種人工智能或人工智能算法,通常與機器學習相關,使用大數據向消費者建議或推薦其他產品。這些推薦可以基于各種標準,包括過去的購買、搜索歷史記錄、人口統計信息和其他因素。推薦系統非常有用,因為它們可以幫助用戶了解自己無法自行找到的產品和服務。
推薦系統經過訓練,可使用收集的交互數據了解用戶和產品偏好、之前的決策和特征。其中包括展示、點擊、喜歡和購買。推薦系統由于能夠高度個性化地預測消費者興趣和需求,因此受到內容和產品提供商的喜愛。從書籍、視頻、健康課程到服裝,它們都可以促使消費者選擇其感興趣的任何產品或服務。
推薦系統類型
雖然有許多推薦算法和技術,但大多數都屬于以下廣泛類別:協作過濾、內容過濾和上下文過濾。
協作過濾算法根據許多用戶的偏好信息(這是協作部分)推薦物品(這是過濾部分)。此方法使用用戶偏好行為的相似性,并鑒于用戶與物品之間的之前交互,推薦算法便可以學會預測未來交互。這些推薦系統基于用戶過去的行為構建模型,例如之前購買的物品或給予這些物品的評分以及其他用戶的類似決策。相關理念在于,如果有些人過去也做出過類似的決策和購買,比如電影選擇,那么他們很有可能會同意未來的其他選擇。例如,如果協作過濾推薦系統了解您和另一個用戶在電影中有著相似的品味,它可能會向您推薦一部其了解的其他用戶已經喜歡的電影。
相比之下,內容過濾則使用物品的屬性或特征(這是內容部分)來推薦類似于用戶偏好的其他物品。此方法基于物品和用戶特征的相似性,并鑒于用戶及其與之交互過的物品的信息(例如,用戶的年齡、餐廳的菜系、電影的平均評價),來模擬新互動的可能性。例如,如果內容過濾推薦系統了解到您喜歡電影《電子情書》和《西雅圖夜未眠》,它可能會向您推薦另一部相同類別和/或演員陣容的電影,例如《跳火山的人》。
混合推薦系統結合了上述類型系統的優勢,以便創建更全面的推薦系統。
上下文過濾包括推薦過程中用戶的背景信息。Netflix 在 NVIDIA GTC 大會上提出,將推薦內容框定為上下文序列預測,以便作出更好的推薦。此方法使用一系列上下文用戶操作和當前上下文來預測下一個操作的概率。在 Netflix 示例中,鑒于每位用戶的序列(用戶在觀看電影時的國家/地區、設備、日期和時間),他們訓練出一個模型,來預測用戶接下來要觀看的內容。

2?
用例和應用
電子商務與零售:個性化營銷
假設用戶已經購買了一條圍巾。何不提供匹配的帽子,來完善外觀?此功能通常通過基于 AI 的算法實現,如電子商務平臺(例如 Amazon、沃爾瑪、Target 等)的“搭配造型”或“您可能還喜歡”部分。智能推薦系統能夠將網頁產品的轉換率平均提升 22.66%。
媒體與娛樂:個性化內容
基于 AI 的推薦引擎可以分析個人的購買行為并檢測模式,這有助于為他們提供更有可能符合其興趣的內容建議。這是 Google 和 Facebook 在推薦廣告時主動應用的內容,或 Netflix 在推薦電影和電視節目時在幕后所應用的內容。
個性化銀行
作為一款由數百萬人數字化消費的大眾市場產品,銀行是推薦產品的主要選擇。了解客戶的詳細金融情況及其過去偏好,加上數千名類似用戶的數據,這一點非常強大。
3?
推薦系統的優勢
推薦系統是推動個性化用戶體驗、與客戶更深入互動以及零售、娛樂、醫療健康、金融等行業中功能強大的決策支持工具的關鍵組件。在某些大型商業平臺上,推薦系統所產生的收入占比高達 30%。推薦質量每提高 1% 可以轉化為數十億美元的收入。
公司出于各種以下原因實施推薦系統:
提高保留率。通過持續迎合用戶和客戶偏好,企業更有可能將其保留為忠誠的訂閱者或購物者。如果客戶感覺到品牌真正理解他們且不僅是隨機地為其提供信息,他們更有可能保持忠誠度,并繼續在您的網站購物。
增加銷量。各種研究表明,“您可能還喜歡”準確的產品推薦導致銷售收入增加 10% 到 50%。只需在購買確認函中添加匹配的產品推薦內容、收集廢棄電子購物車的信息、分享有關“客戶現在購買的產品的信息”以及分享其他買家的購買和評論,推薦系統策略就可以提高銷量。
幫助形成客戶習慣和趨勢。持續提供準確且相關的內容可以觸發線索,從而建立客戶的良好的習慣并影響其使用模式。
加快工作進度。當為進一步研究所需資源和其他材料提供定制建議時,分析師和研究人員可以節省高達 80% 的時間。
提升購物車價值。擁有成千上萬商品出售的公司將面臨的挑戰是,需針對這種庫存提供硬編碼產品建議。通過使用各種過濾方法,這些電子商務巨頭可以找到合適時間,以建議客戶通過網站、電子郵件或其他方式想購買的新產品。
4?
推薦系統的工作原理
推薦模型如何進行推薦將取決于您擁有的數據類型。如果您只擁有過去發生的交互數據,您可能有興趣使用協作過濾。如果您有描述用戶及其與之交互過的物品的數據(例如,用戶的年齡、餐廳的菜系、電影的平均評價),您可以通過添加內容和上下文過濾,對當前給定這些屬性下新交互的可能性進行建模。
推薦矩陣分解
矩陣分解?(MF) 技術是許多熱門算法(包括詞嵌入和主題建模)的核心,已成為基于協作過濾的推薦中的主要方法。MF 可用于計算用戶的評分或交互中的相似度,以提供推薦。
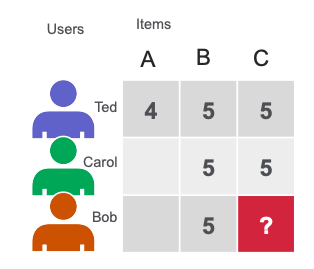
在下方簡單的用戶物品矩陣中,Ted 和 Carol 喜歡電影 B 和 C。Bob 喜歡電影 B。為了向 Bob 推薦電影,矩陣分解計算喜歡 B 的用戶也喜歡 C,因此 C 是 Bob 的一個可能建議。
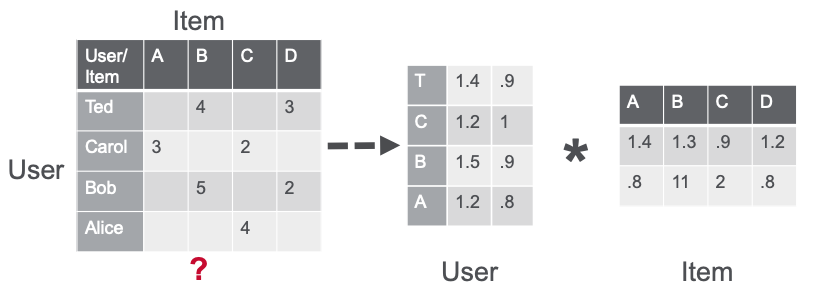
使用交替最小二乘法 (ALS) 算法的矩陣分解將稀疏用戶物品評價矩陣 u-by-i 近似為用戶和物品因素矩陣的兩個密集矩陣的乘積,其大小分別為 u × f 和 f × i(其中 u 表示用戶數,i 表示物品數,f 表示潛在特征數)。因素矩陣表示算法嘗試發現的潛在特征或隱藏特征。一個矩陣試圖描述每個用戶的潛在特征或隱藏特征,另一個矩陣則試圖描述每部電影的潛在特性。對于每個用戶和每個物品,ALS 算法會迭代學習 (f) 數字,“factors”表示用戶或物品。在每一次迭代中,算法可以交替地修復一個因子矩陣并針對另一個矩陣進行優化,并且此過程會一直持續到其收斂。
CuMF?是基于 NVIDIA CUDA?的矩陣因子庫,可優化替代最小二乘法 (ALS) 方法,以求解大規模的 MF。CuMF 使用一系列技術,以便在單個和多個 GPU 上更大限度地提高性能。這些技術包括利用 GPU 顯存層次結構對稀疏數據進行智能訪問、將數據并行與模型并行結合使用,以大幅度減少 GPU 之間的通信用度以及全新的拓撲感知型并行減少方案。
5?
用于推薦的深度神經網絡模型
人工神經網絡 (ANN) 存在不同變體,如下所示:
只將信息從一層向前饋送至下一層的人工神經網絡稱為前饋神經網絡。多層感知器 (MLP) 是一種前饋 ANN,由至少三層節點組成:輸入層、隱藏層和輸出層。MLP 是可應用于各種場景的靈活網絡。
卷積神經網絡是識別物體的圖像處理器。
時間遞歸神經網絡是解析語言模式和序列數據的數學工具。
深度學習 (DL) 推薦模型基于現有技術(例如分解)而構建,以便對變量和嵌入之間的交互進行建模,從而處理類別變量。嵌入是表示實體特征的已學習的數字向量,因此相似的實體(用戶或物品)在向量空間中具有相似的距離。例如,協作過濾深度學習方法基于用戶和物品與神經網絡的交互來學習用戶和物品嵌入(潛在特征向量)。
DL 技術還利用龐大且快速發展的新穎網絡架構和優化算法,對大量數據進行訓練,利用深度學習的強大功能進行特征提取,并構建更具表現力的模型。
當前基于 DL 的推薦系統模型:DLRM、Wide and Deep (W&D)、神經協作過濾 (NCF)、b 變分自動編碼器 (VAE)?和 BERT(適用于 NLP)構成了 NVIDIA GPU 加速 DL 模型產品組合的一部分,并涵蓋推薦系統以外的許多不同領域的各種網絡架構和應用程序,包括圖像、文本和語音分析。這些模型專為使用 TensorFlow 和 PyTorch 進行訓練而設計和優化。
神經協作過濾
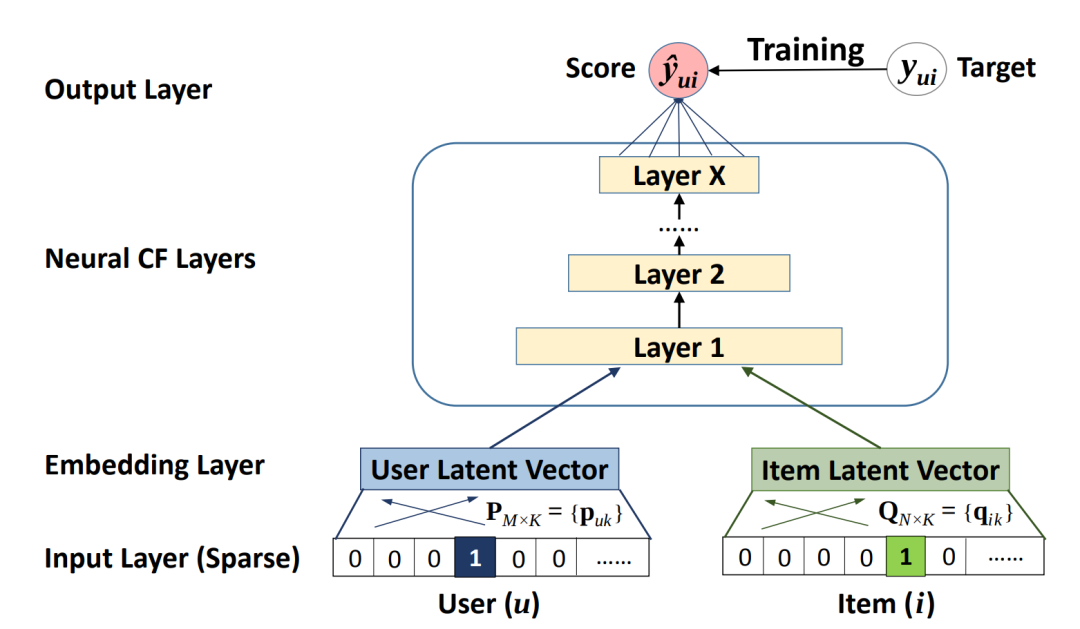
神經協作過濾?(NCF) 模型是一個神經網絡,可基于用戶和物品交互提供協作過濾。該模型從非線性角度處理矩陣分解。NCF TensorFlow 以一系列(用戶 ID、物品 ID)對作為輸入,然后分別將其輸入到矩陣分解步驟(其中嵌入成倍增加)并輸入到多層感知器 (MLP) 網絡中。
然后,將矩陣分解和 MLP 網絡的輸出將組合到一個密集層中,以預測輸入用戶是否可能與輸入物品交互。
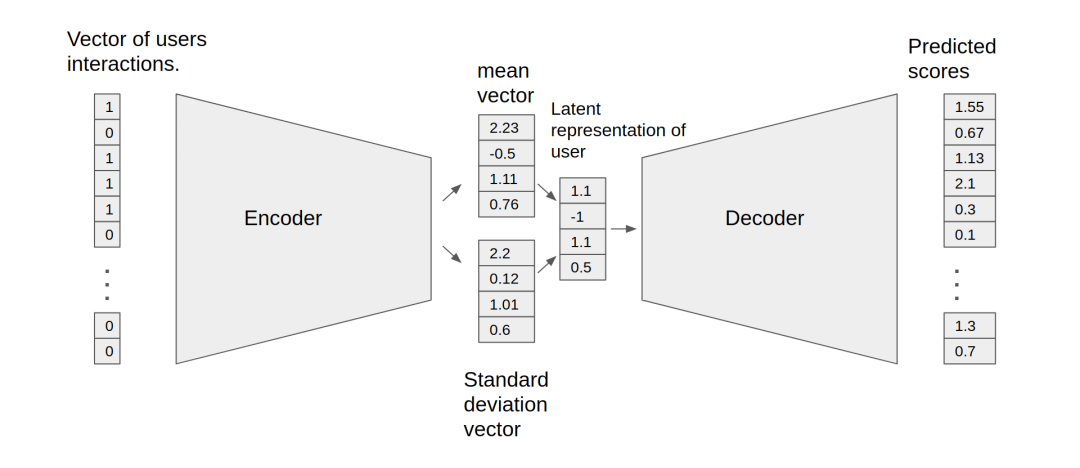
用于協作過濾的變分自動編碼器
自動編碼器神經網絡使用隱藏層中獲取的表征,來重建輸出層的輸入層。用于協作過濾的自動編碼器可以學習用戶物品矩陣的非線性表征,并可通過確定缺失值重建該矩陣。
用于協作過濾 (VAE-CF) 的 NVIDIA GPU 加速變分自動編碼器是一種優化的架構實現,首先在用于協作過濾的變分自動編碼器中介紹。VAE-CF 是一個神經網絡,可基于用戶和物品交互提供協作過濾。此模型的訓練數據由用戶和物品之間的每次交互的用戶項 ID 對組成。
模型包含兩部分:編碼器和解碼器。編碼器是一個前饋全連接神經網絡,可將輸入向量(包含特定用戶的交互)轉換為 n 維變分分布。這種變分分布用于獲取用戶(或嵌入)的潛在特征表征。然后,將這種潛在表征輸入到解碼器中,解碼器也是一個與編碼器結構相似的前饋網絡。結果為特定用戶的物品交互概率向量。
上下文序列學習
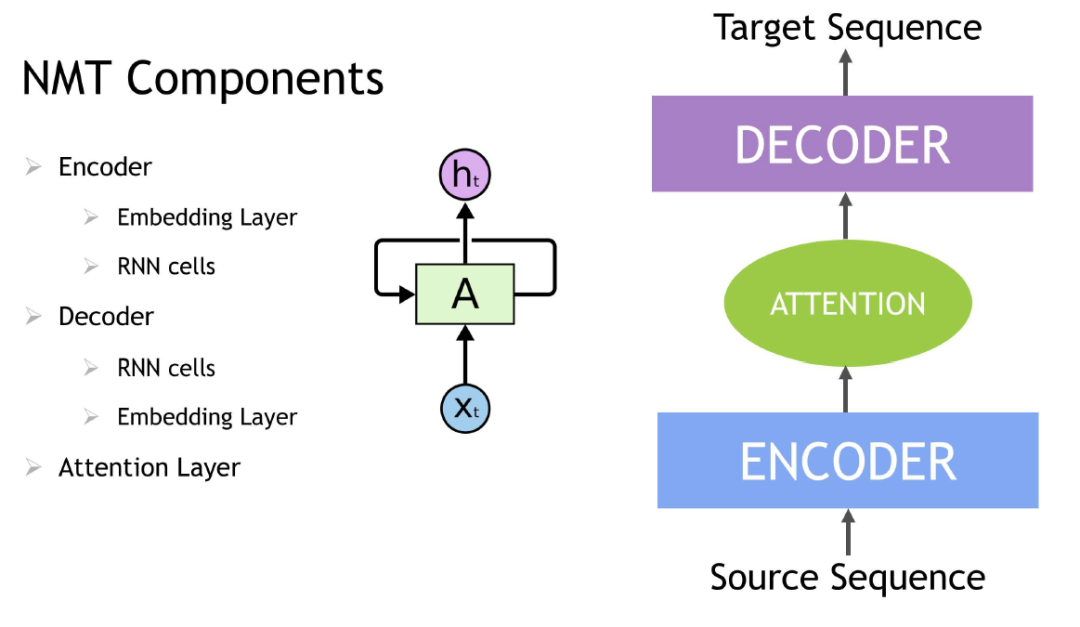
時間遞歸神經網絡?(RNN) 是具有記憶或反饋回路的一類神經網絡,允許其更好地識別數據中的模式。RNN 可以解決處理上下文和序列(例如自然語言處理)的艱巨任務,還可用于上下文序列推薦。序列學習與其他任務的區別是,序列學習需要使用具有主動數據存儲的模型(例如 LSMS(長短期記憶模型)或 GRU 門控循環單元)來學習輸入數據的時間依賴關系。這種對過往輸入的記憶對于順利進行序列學習至關重要。
Transformer 深度學習模型,如 BERT(Transformer 雙向編碼器表征模型),是 RNN 的一個替代方案,它應用了一種注意力技術 – 通過將注意力集中在前后最相關的詞上來解析一個句子。基于 Transformer 的深度學習模型不需要按順序處理連續數據,與 RNN 相比,可以在 GPU 上實現更多的并行化,并減少訓練時間。
在 NLP 應用中,會使用詞嵌入等技術將輸入文本轉換為詞向量。借助詞嵌入,可將句子中的每個詞翻譯成一組數字,然后再輸入到 RNN 變體、Transformer 或 BERT 中,以理解上下文。神經網絡在訓練自身時,這些數字會隨時發生變化,編碼每個單詞的語義和上下文信息等獨特屬性,這意味著,相似詞在此數字空間中彼此接近,不同詞則相距遙遠。這些 DL 模型為特定語言任務(例如下一詞語預測和文本摘要)提供適當的輸出,這些任務用于生成輸出序列。
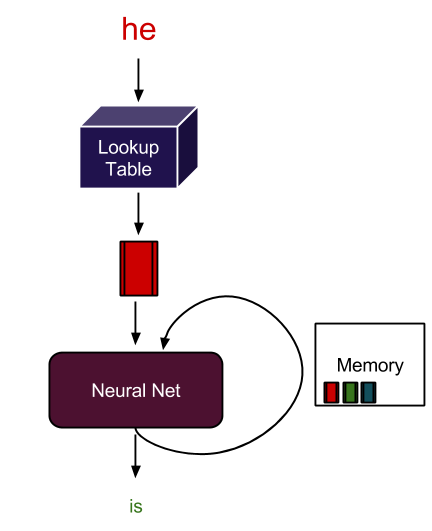
基于會話上下文的推薦將深度學習和 NLP 序列建模方面的進步應用于推薦內容。基于用戶會話中的事件序列訓練的 RNN 模型(例如,查看的產品、數據和交互時間)會學習預測會話中的下一個物品。會話中的用戶物品交互類似于句子中的詞嵌入。例如,在將觀看的電影輸入 RNN 變體(例如 LSTM、GRU 或 Transformer)之前,需要將其轉換為一組數字,以理解上下文。
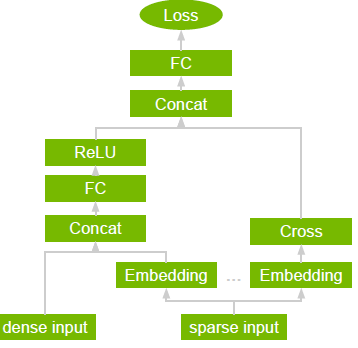
Wide & Deep
Wide & Deep 是指使用并行處理兩個部分(Wide 模型和 Deep 模型)的輸出,并對其輸出進行求和以創建交互概率的網絡類別。Wide 模型是特征及其轉換的一個廣義線性模型。Deep 模型是一個密集神經網絡 (DNN),由 5 個隱藏 MLP 層(包含 1024 個神經元)組成,每個層都從密集特征嵌入開始。分類變量會嵌入到連續向量空間中,然后通過學習的嵌入或用戶確定的嵌入輸入到 DNN 中。
為何模型能夠成功執行推薦任務,原因之一是提供數據中的兩種學習模式:“deep”和“shallow”。復雜的非線性 DNN 能夠學習數據中豐富的關系表征,并可通過嵌入來推廣到相似的物品,但需要查看相關關系的多種示例才能做得更好。另一方面,線性部分能夠“記住”可能僅在訓練集內發生幾次的簡單關系。
綜合來說,這兩種表征信道通常比單種表征信道提供更多的建模能力。NVIDIA 與許多使用離線和在線指標報告改進的行業合作伙伴合作,他們使用 Wide & Deep 替代傳統機器學習模型。
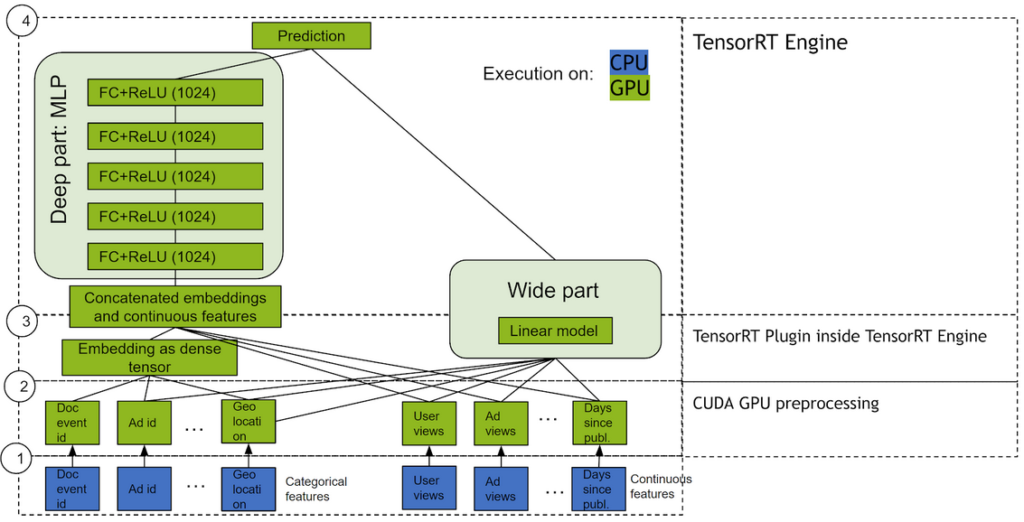
DLRM
DLRM 是一種基于 DL 的模型,適用于推薦,由 Facebook 研究院提出。它旨在同時使用推薦系統訓練數據中通常呈現的分類輸入和數值輸入。要處理分類數據,嵌入層將每個類別映射到密集表征,然后再將其輸入到多層感知器 (MLP)。數值特征可直接輸入到 MLP。
在下一級別中,通過在所有嵌入向量對和已處理的密集特征之間取點積,顯式計算不同特征的二次交互。并將這些成對交互輸入到頂層 MLP 中,以計算用戶和物品對之間的交互概率。
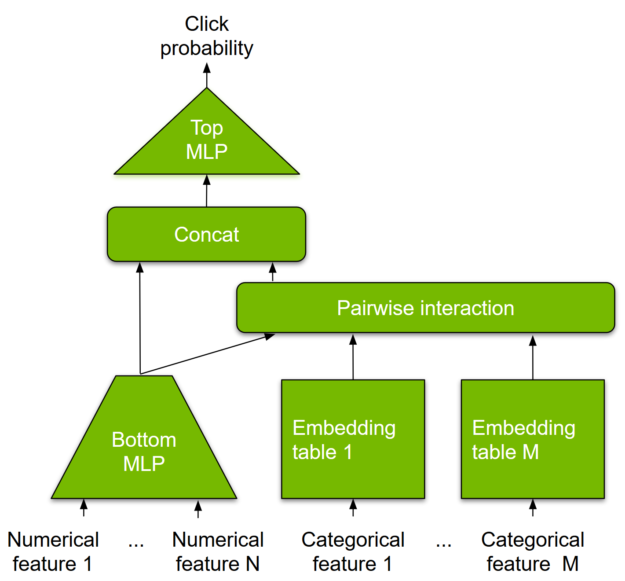
與其他基于 DL 的推薦方法相比,DLRM 有兩種差異。首先,它可以對特征交互進行顯式計算,同時將交互順序限制為成對交互。其次,DLRM 將每個嵌入式特征向量(對應分類特征)視為一個單元,而其他方法(如 Deep 和 Cross)則將特征向量中的每個元素視為應生成不同交叉項目的新單元。這些設計選項,有助于降低計算/內存成本,同時保持競爭的準確性。
DLRM 是 NVIDIA Merlin 的一部分,后者是一個基于 DL 所構建的高性能推薦系統框架,我們下面將介紹這一框架。
6?
為何推薦系統在 GPU 上表現更出色?
推薦系統能夠提高消費者在熱門平臺上的參與度。隨著數據規模變得越來越大(數千萬到數十億的示例),DL 技術正展現出傳統方法所不具備的優勢。因此,更復雜的模型與數據的快速增長相結合,提高了計算資源的標準。
許多機器學習算法的基礎數學運算通常是矩陣乘法。這些類型的運算具有高度并行性,并且可以使用 GPU 大幅加速。
一個由數百個核心組成的 GPU,可以并行處理數千個線程。由于神經網絡由大量相同的神經元構建而成,因此本質上具有高度并行性。這種并行性自然地映射到 GPU,GPU 的性能比僅依賴 CPU 的平臺高 10 倍。因此,GPU 已成為訓練基于神經網絡的大型復雜系統的首選平臺,推理運算的并行性質也有助于在 GPU 上執行。

7?
NVIDIA Merlin 推薦系統應用程序框架
大型推薦系統解決方案的性能存在多種挑戰,包括大型數據集、復雜的數據預處理和特征工程流程,以及大量重復實驗。為滿足大規模 DL 推薦系統訓練和推理的計算需求,推薦您使用 GPU 解決方案,可為您提供快速的特征工程和高訓練吞吐量(以實現快速實驗和生產再訓練)。它們還可為您提供低延遲、高吞吐量的推理。
NVIDIA Merlin 是一個開源應用程序框架和生態系統,旨在促進從實驗到生產的推薦系統開發的所有階段,并由 NVIDIA GPU 加速。
該框架可為推薦數據集中常見的運算符提供快速的特征工程和預處理,以及為其提供多個基于深度學習的典型推薦模型的高訓練吞吐量。其中包括 Wide & Deep、Deep Cross Networks、DeepFM 和 DLRM,這些模型可實現快速實驗和生產再訓練。對于生產部署,Merlin 還提供低延遲、高吞吐量和生產推理。這些組件相結合,為在 GPU 上的訓練和部署深度學習推薦系統模型提供端到端框架,該框架既易于使用,又具有高性能。
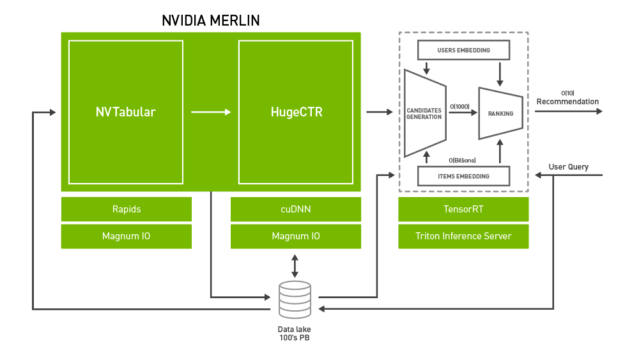
Merlin 還包括用于構建基于深度學習的推薦系統的工具,并可提供比傳統方法更準確的預測。管線的每個階段都經過優化,可支持數百 TB 的數據,您可通過易于使用的 API 訪問所有這些數據。
NVTabular 通過 GPU 加速特征轉換和預處理來縮短數據準備時間。
HugeCTR 是一種 GPU 加速深度神經網絡訓練框架,旨在跨多個 GPU 和節點分發訓練。它支持模型并行嵌入表和數據并行神經網絡及其變體,例如 Wide and Deep Learning (WDL)、Deep Cross Network (DCN)、DeepFM 和深度學習模型 (DLRM)。
NVIDIA Triton?推理服務器和 NVIDIA TensorRT?加速 GPU 上的生產推理,以便實現特征轉換和神經網絡執行。
8?
NVIDIA GPU 加速的端到端數據科學和 DL
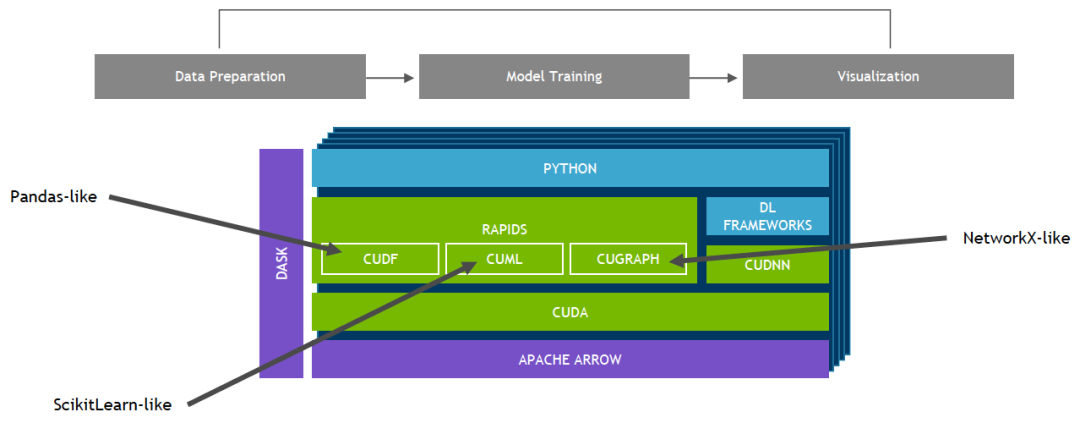
NVIDIA Merlin 基于 NVIDIA RAPIDS 構建。通過基于 CUDA 構建的 RAPIDS?開源軟件庫套件,您能夠完全在 GPU 上執行端到端數據科學和分析流程,同時仍然使用 Pandas 和 Scikit-Learn API 等熟悉的界面。
9?
NVIDIA GPU 加速的深度學習框架
GPU 加速深度學習框架能夠為設計和訓練自定義深度神經網絡帶來靈活性,并為 Python 和 C/C++ 等常用編程語言提供編程接口。MXNet、PyTorch、TensorFlow 等廣泛使用的深度學習框架依賴于 NVIDIA GPU 加速庫,能夠提供高性能的多 GPU 加速訓練。
編輯:黃飛
?















 工商網監
工商網監
評論