 電子發(fā)燒友App
電子發(fā)燒友App


前言
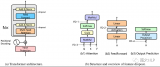
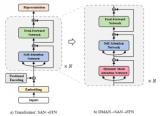
標(biāo)準(zhǔn)的Transformer Block并不簡介,每個(gè)block由attention, MLP, skip connection, normalization各子模塊構(gòu)成。一些看似微小的修改可能導(dǎo)致模型訓(xùn)練速度下降,甚至導(dǎo)致模型無法收斂。
在本篇工作中,我們探索了Transformer Block精簡的方式。結(jié)合了信號傳播理論以及一些經(jīng)驗(yàn)性的觀察,我們在不損失訓(xùn)練速度的前提下,移除了skip connection, out project, value project, normalization操作 以及串行組織block的形式。在Decoder-only和Encoder-only兩類模型上,我們減少了15%可訓(xùn)練參數(shù),并提高了15%的訓(xùn)練速度。
官方倉庫:
bobby-he/simplified_transformers
論文:Simplifying Transformer Blocks.
一些標(biāo)記注解:

?
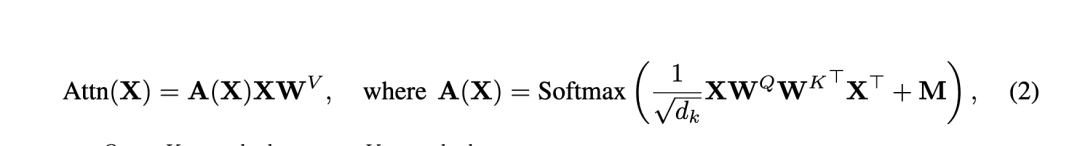
每個(gè)transformer block如上述公式組成,每個(gè)子模塊都配備了一個(gè)系數(shù),這個(gè)后續(xù)會(huì)使用到
Removing Skip Connection
作者先前的一項(xiàng)工作Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation 刪除了殘差連接,提出的操作Value-SkipInit,將自注意力相關(guān)操作修改為:
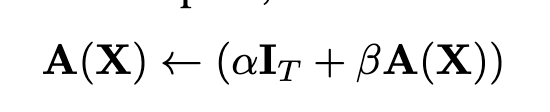
其中I代表的是一個(gè)Identity操作,A(X)表示原始注意力操作。這兩個(gè)操作各自有一個(gè)可訓(xùn)練標(biāo)量 和 ,初始化為 , 。
這個(gè)設(shè)計(jì)的insight是每個(gè)token在訓(xùn)練前期更多的是關(guān)注自身相關(guān)性,類似的如Pre-LN操作,在Batch Normalization Biases Residual Blocks Towards the Identity Function in Deep Networks這項(xiàng)工作發(fā)現(xiàn),Pre-LN相當(dāng)于把 skip-branch 權(quán)重提高,降低residual-branch權(quán)重,以在較深的神經(jīng)網(wǎng)絡(luò)里仍然有良好的信號傳播。
而The Shaped Transformer: Attention Models in the Infinite Depth-and-Width Limit 該工作里提出了Shape Attention,也是收到信號傳播理論的啟發(fā),將注意力公式更改為:
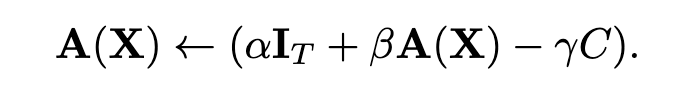
相比之下多了一個(gè)C矩陣,這是個(gè)常量矩陣(論文稱其為centering matrix),不參與訓(xùn)練。他的值被設(shè)置為當(dāng) querykey dot 為0時(shí)候,A(x)的值,那么我們回去看A(x)公式,就剩一個(gè)mask值,因此代碼里是這么寫的:
?
?
#?Centered?attention,?from?https://arxiv.org/abs/2306.17759 ????????uniform_causal_attn_mat?=?torch.ones( ????????????(max_positions,?max_positions),?dtype=torch.float32 ????????)?/?torch.arange(1,?max_positions?+?1).view(-1,?1) ????????self.register_buffer( ????????????"uniform_causal_attn_mat", ????????????torch.tril( ????????????????uniform_causal_attn_mat, ????????????).view(1,?1,?max_positions,?max_positions), ????????????persistent=False, ????????)
?
?
對于CausalLM來說,MASK是個(gè)下三角矩陣,形狀為(S, S)的矩陣,第i行,只有前i個(gè)位置有值,經(jīng)過softmax后,1.0概率被平分到有值的位置,這就是為什么它要做一個(gè) ones / arange 的操作,一段示例代碼為:
?
?
import?torch max_positions?=?32 mask?=?torch.tril(torch.ones(max_positions,?max_positions))?+?torch.triu(torch.ones(max_positions,?max_positions),?1)?*?-65536 print(torch.softmax(mask,?-1)) tensor([[1.0000,?0.0000,?0.0000,??...,?0.0000,?0.0000,?0.0000], ????????[0.5000,?0.5000,?0.0000,??...,?0.0000,?0.0000,?0.0000], ????????[0.3333,?0.3333,?0.3333,??...,?0.0000,?0.0000,?0.0000], ????????..., ????????[0.0333,?0.0333,?0.0333,??...,?0.0333,?0.0000,?0.0000], ????????[0.0323,?0.0323,?0.0323,??...,?0.0323,?0.0323,?0.0000], ????????[0.0312,?0.0312,?0.0312,??...,?0.0312,?0.0312,?0.0312]])
?
?
而新的可訓(xùn)練標(biāo)量 = ,以保證初始化時(shí),
其中這些可訓(xùn)練標(biāo)量如果改成headwise,即每個(gè)注意力頭獨(dú)立,則性能有部分提升。當(dāng)然作者還是強(qiáng)調(diào)其中的一個(gè)重要的點(diǎn)是,顯式的將MLP Block的系數(shù)降低:

論文里針對18層Transformer,設(shè)置為0.1
Recovering Training Speed
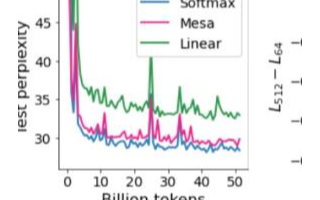
在引入shape attention并移除殘差連接后,訓(xùn)是沒問題了,但是會(huì)導(dǎo)致收斂變慢:
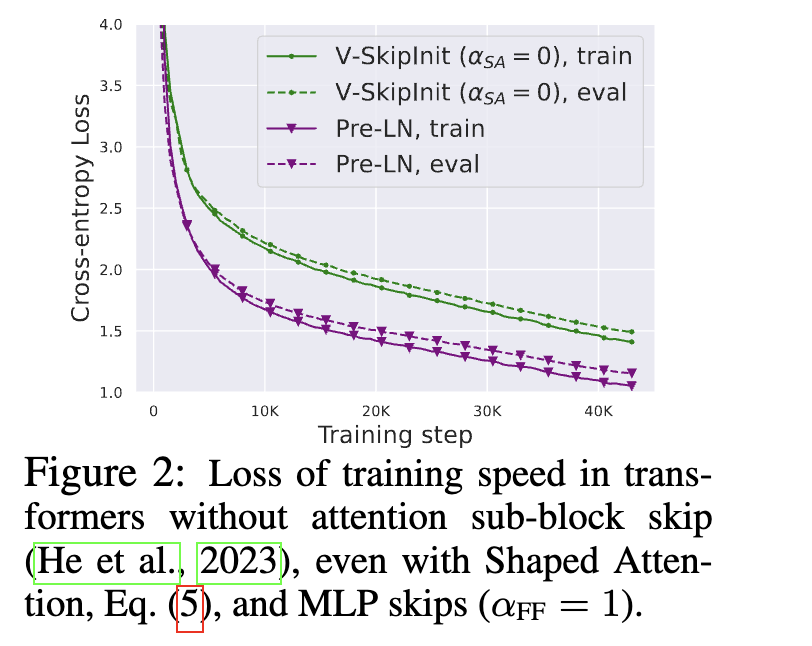
經(jīng)過前面的修改,那么對于Attention模塊里,在訓(xùn)練初期其實(shí)就簡化成X和Vproject矩陣和OutProject矩陣做矩陣乘操作。
眾所周知,這種沒有殘差連接的網(wǎng)絡(luò)訓(xùn)練是要比帶殘差結(jié)構(gòu)的網(wǎng)絡(luò)要慢的。我們從別的工作也可以得知,Pre-LN操作,是會(huì)降低殘差分支的占比系數(shù),相當(dāng)于降低了學(xué)習(xí)率,也縮減了線性層里參數(shù)更新的scale
X matmul W,那么計(jì)算X的梯度公式有一項(xiàng)就是W嘛
這促使我們開始引入重參數(shù)化操作思考V矩陣和OutProject矩陣

作者針對Vproject和Outproject兩個(gè)矩陣乘操作,給殘差分支和跳躍分支各引入一個(gè)可訓(xùn)練參數(shù) , ,通過實(shí)驗(yàn)發(fā)現(xiàn),大部分層最終系數(shù)比值 收斂到了0
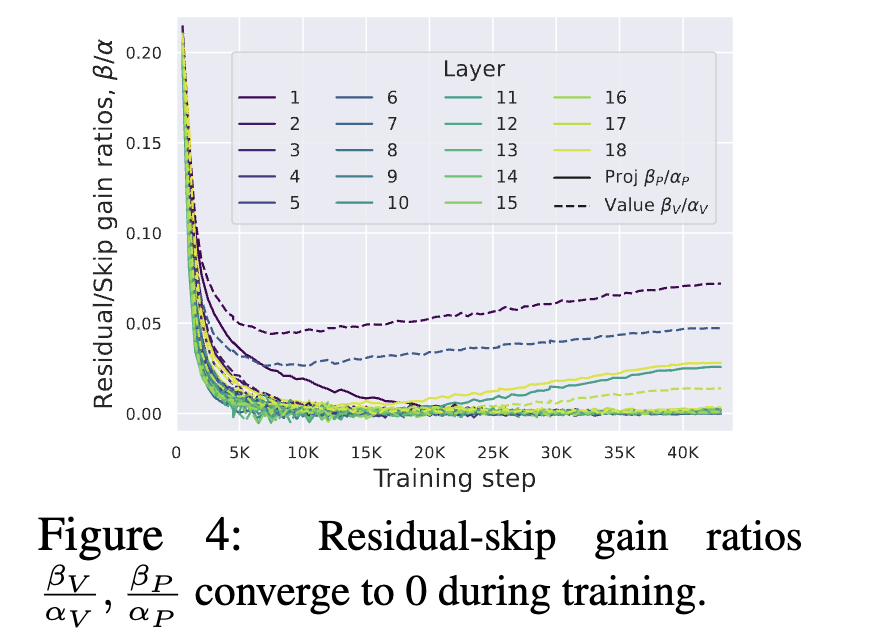
這意味著 和 兩個(gè)矩陣是一個(gè)Identity矩陣,因此作者將這兩個(gè)參數(shù)移除掉,并稱為Simplified Attention Sub-block (SAS),使用SAS比原始Pre-LN block收斂更快了:
REMOVING THE MLP SUB-BLOCK SKIP CONNECTION
在這部分實(shí)驗(yàn)里,作者把目光投向了GPT-J里提出的Parallel Block,其移除了MLP的殘差分支,保留了另外一個(gè)殘差分支:
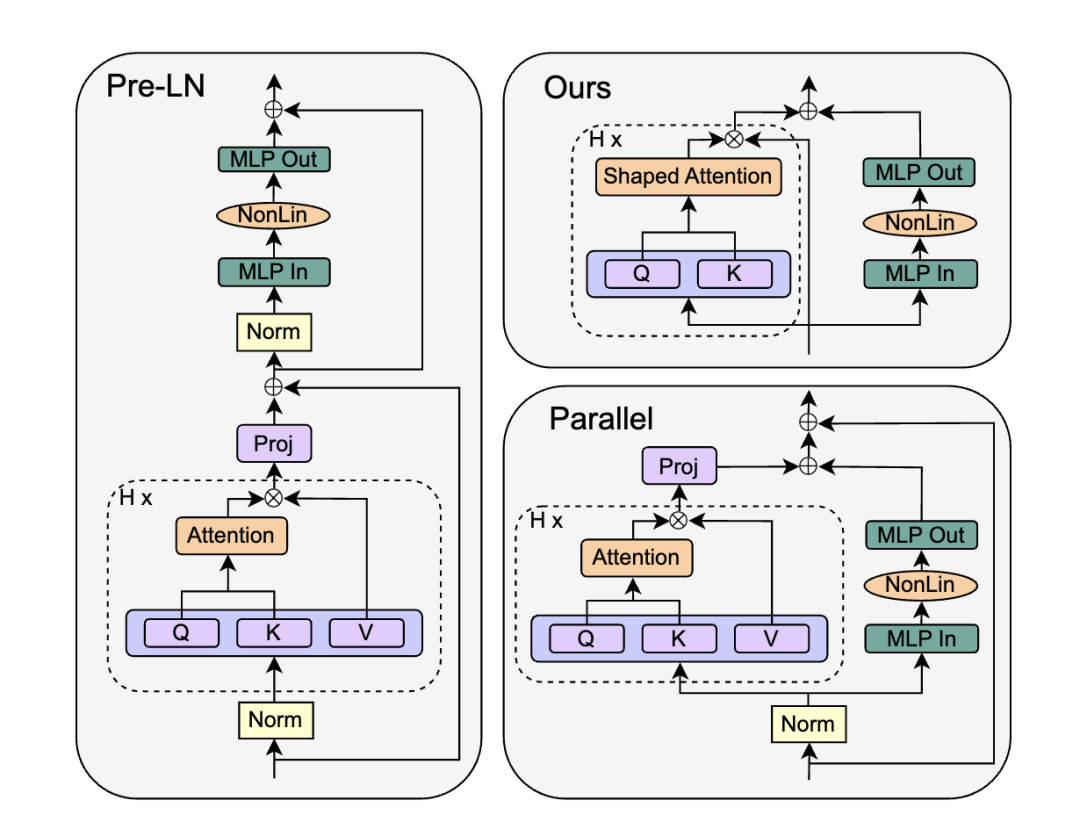
對應(yīng)公式為:
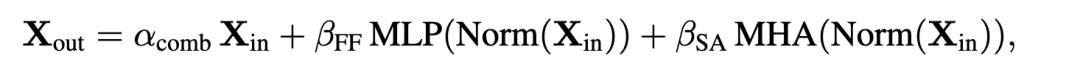
作者直接將SAS Block進(jìn)行替換,得到Parallel形式的 SAS-P Block。我們比較下和原始串行的實(shí)現(xiàn):
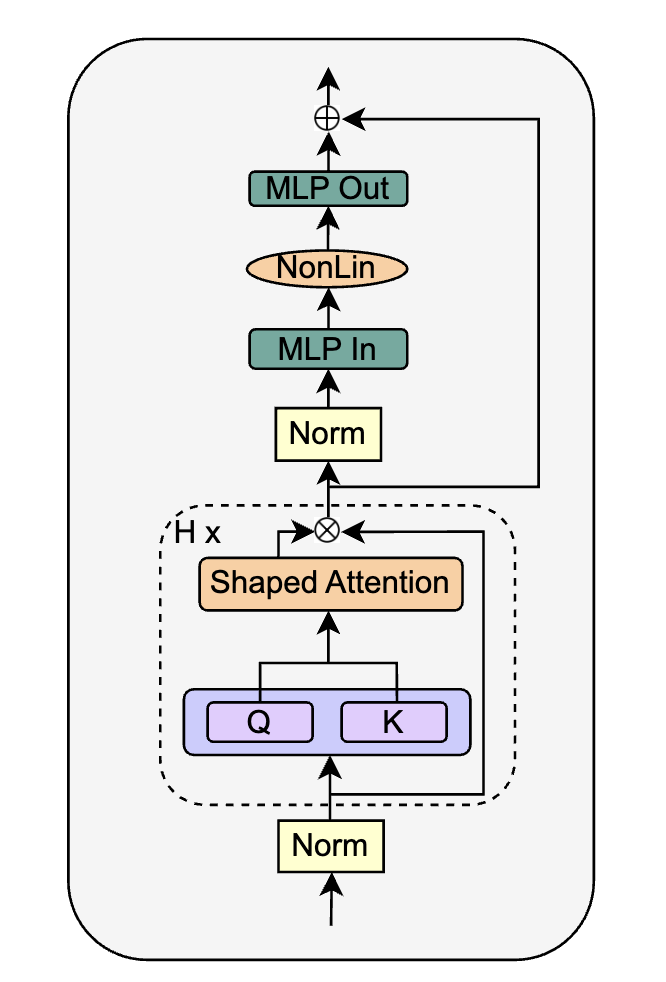
?
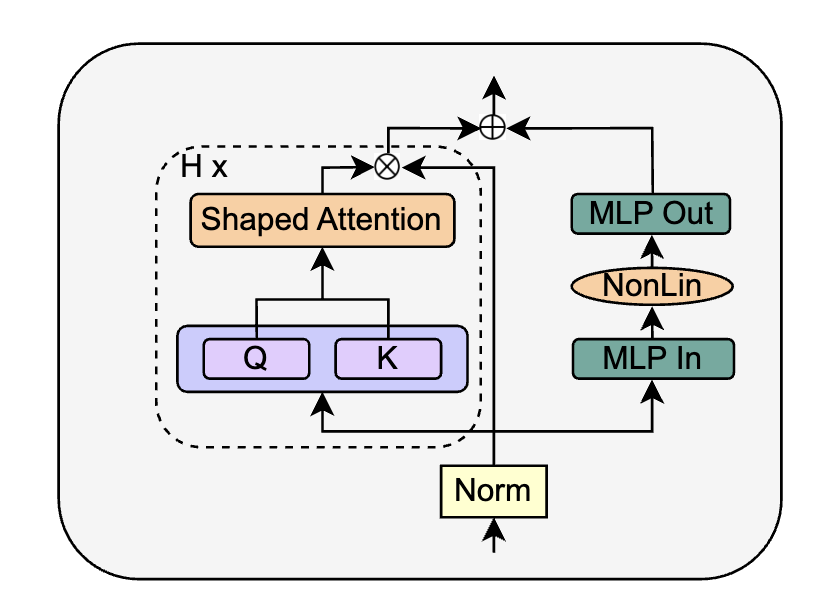
在訓(xùn)練初期,Attention部分是Identity輸出,因此兩種形式的SAS Block在訓(xùn)練初期是等價(jià)的。
REMOVING NORMALISATION LAYERS
最后作者嘗試將Norm層給移除,得到
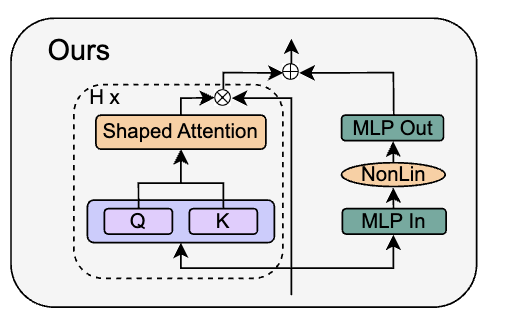
作者的idea來自于,先前PreLN的作用(如把 skip-branch 權(quán)重提高,降低residual-branch權(quán)重)已經(jīng)通過前面的一系列修改實(shí)現(xiàn)了,因此可以直接刪除Norm層
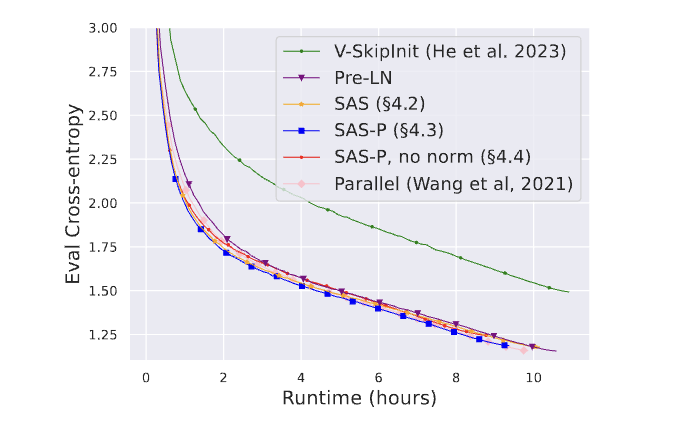
當(dāng)然還是得看實(shí)驗(yàn)效果,回到這張圖,可以看到移除了Norm對收斂還是有一定影響的。作者猜測在信號傳播理論范圍之外,Norm層能加速訓(xùn)練收斂,如Scaling Vision Transformers to 22 Billion Parameters
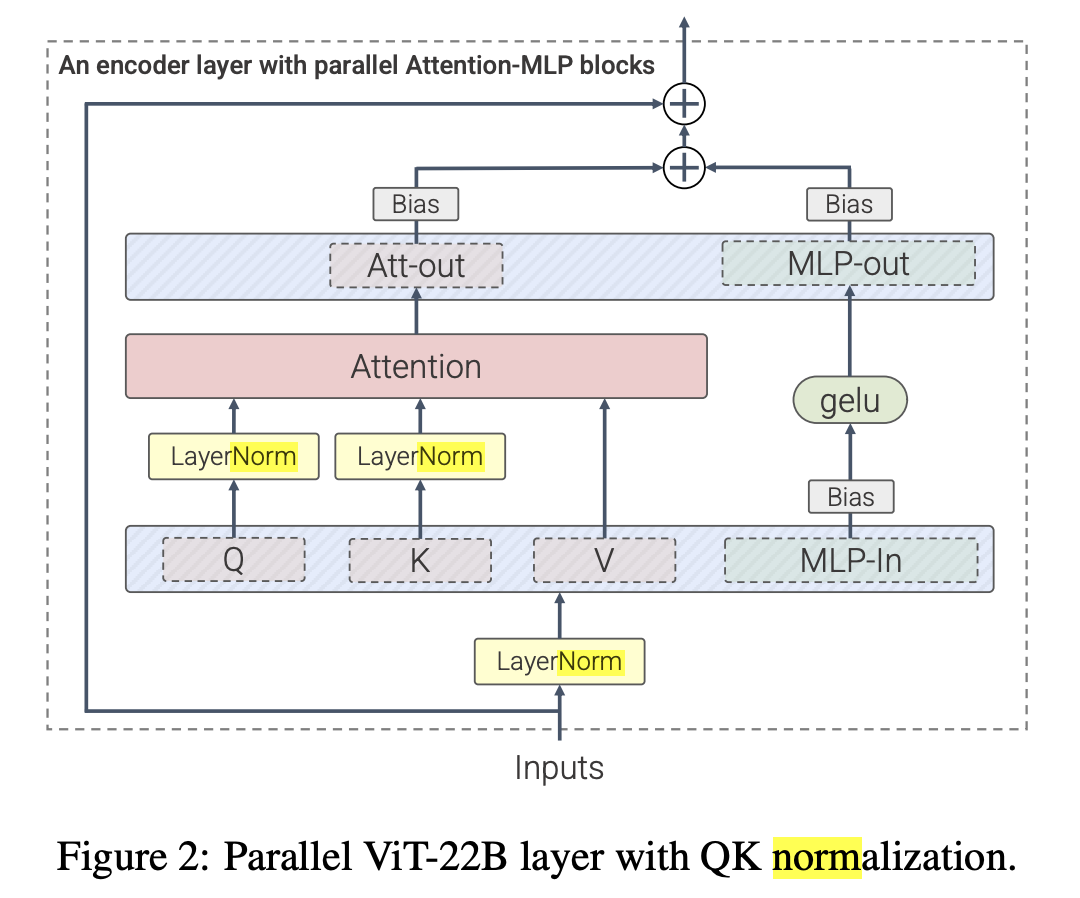
引入了更多LayerNorm層,將ViT縮放至22B參數(shù)量上
因此作者還是主張保留PreLN結(jié)構(gòu):
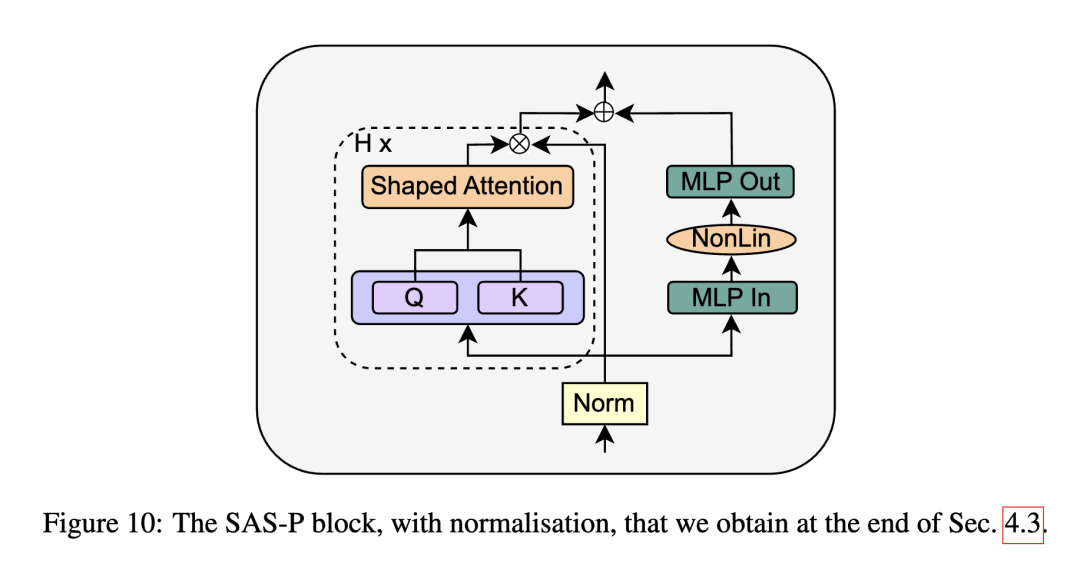
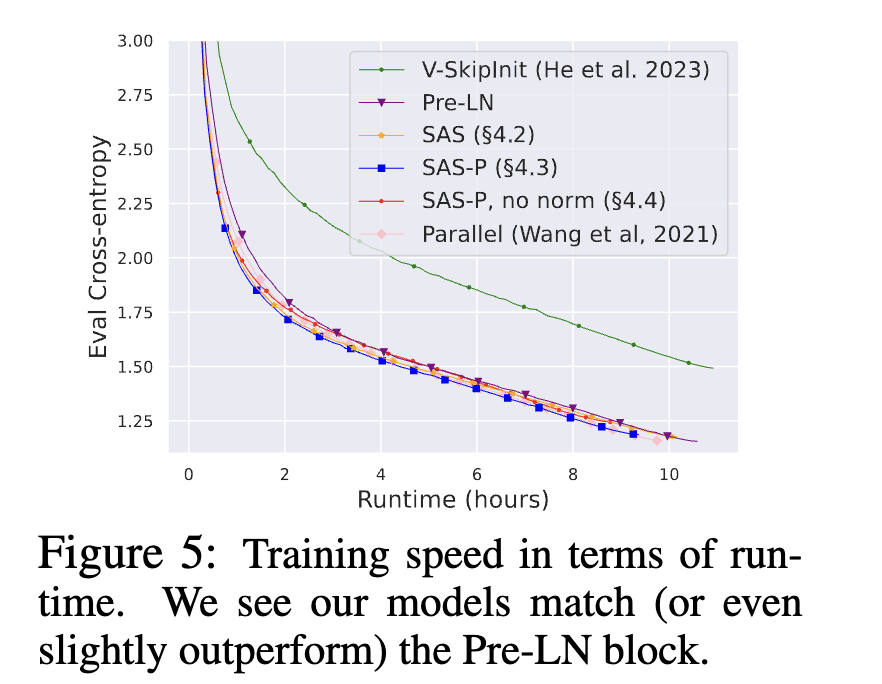
最后實(shí)驗(yàn)
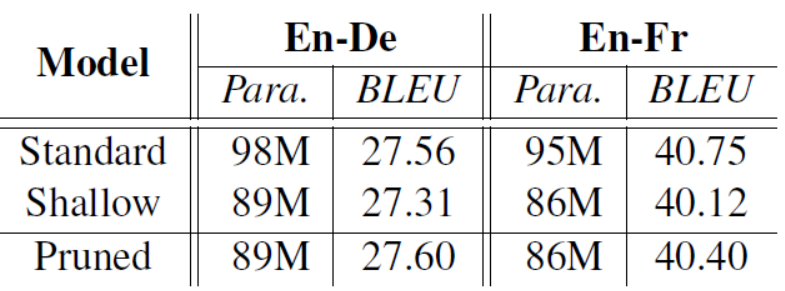
作者也補(bǔ)充了一些訓(xùn)練速度benchmark,模型準(zhǔn)確率,以及收斂趨勢的實(shí)驗(yàn):
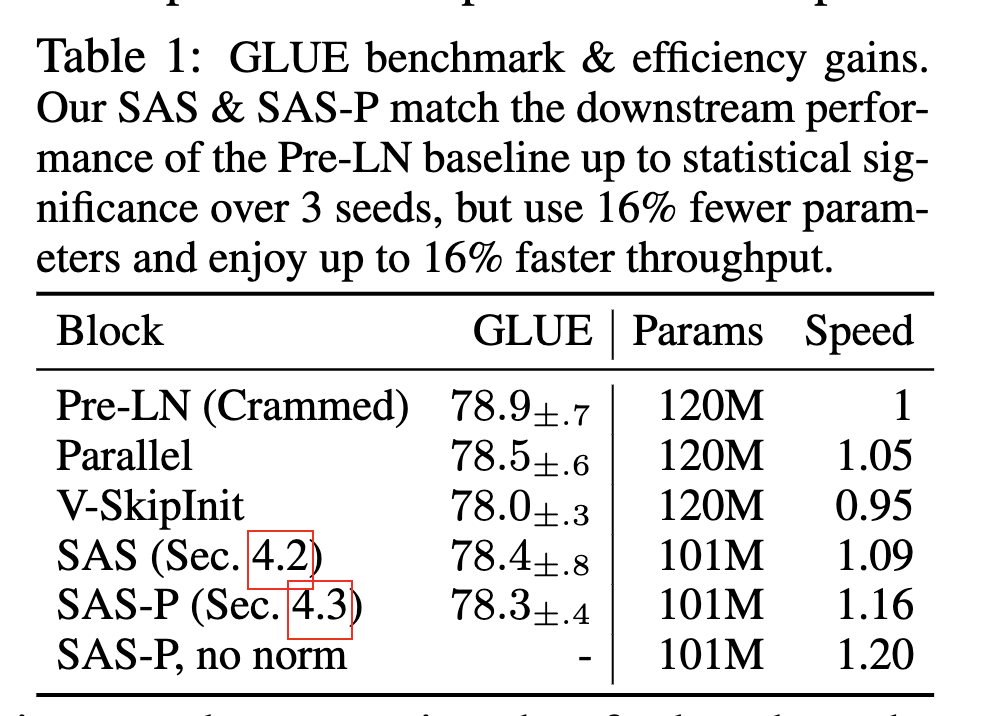
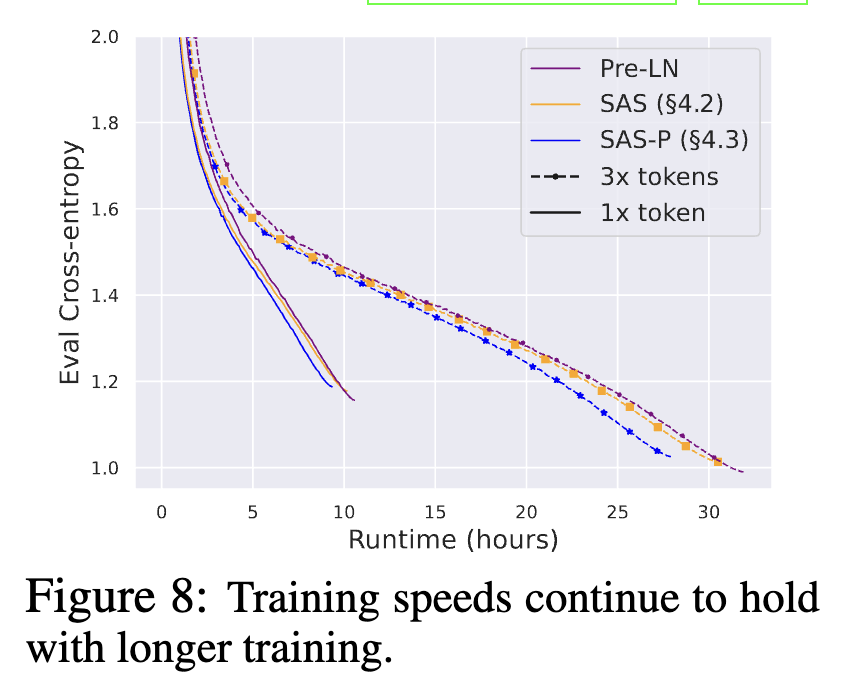
總結(jié)
作者對Transformer Block移除了各種參數(shù),減少了15%參數(shù)量,提高了15%的訓(xùn)練速度,各個(gè)環(huán)節(jié)都有做充分的實(shí)驗(yàn),但一些經(jīng)驗(yàn)性得到的結(jié)論也并沒有直接回答一些問題(如LN為什么影響收斂速度)。
實(shí)驗(yàn)規(guī)模并不大,而標(biāo)準(zhǔn)的TransformerBlock還是在各個(gè)Scale里得到廣泛驗(yàn)證的,期待有人進(jìn)一步試驗(yàn)
你說的對,但我還是套LLAMA結(jié)構(gòu)
審核編輯:黃飛
?

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論