 電子發燒友App
電子發燒友App


亞馬遜網絡服務可能不是第一家創建自己的定制計算引擎的超大規模提供商和云構建商,但它緊隨谷歌之后發布了自研的AI芯片——谷歌于 2015 年開始使用其自主研發的 TPU 加速器來處理人工智能工作負載。
AWS 于 2017 年開始使用“Nitro”DPU,并很快決定如果要在未來繼續在服務器基礎設施方面進行創新,就需要在所有方面對計算引擎進行創新。現在我們已經看到了多代 Nitro DPU、四代 Graviton Arm 服務器 CPU、兩代 Inferentia AI 推理加速器,以及現在的第二代 Trainium AI 訓練加速器。Trainium2 芯片與 Graviton4 服務器 CPU 一起在 AWS 最近于拉斯維加斯舉辦的 re:Invent 2023 大會上亮相,我們花了一些時間嘗試了解這個新的 AI 訓練引擎以及它與 Inferentia 系列的關系。
AWS 尚未公布有關這些 AI 計算引擎的大量詳細信息,但我們(指代nextplatform)設法與 Gadi Hutt 進行了一些交流,他是 AWS Annapurna Labs 部門的業務開發高級總監,負責設計其計算引擎并通過代工廠和指導它們。深入了解 AWS 系統,更深入地了解 Inferentia 和 Trainium 之間的關系以及對 Trainium2 的期望;我們還對技術文檔中的規格進行了一些挖掘,并嘗試填補空白,就像我們發現信息缺乏時所做的那樣。
不過,為了做好準備,我們先做一點數學計算,然后再了解 AWS AI 計算引擎的數據源和速度。
在 AWS 首席執行官 Adam Selipsky 的 re:Invent 主題演講中,Nvidia 聯合創始人兼首席執行官黃仁勛是一位驚喜嘉賓,他在講話中表示,在“Ampere”A100 和“Hopper”H100 期間,AWS 購買了兩百萬個這樣的設備。
有傳言稱,AWS 將在 2023 年完成大約 50,000 個 H100 訂單,我們假設去年可能有 20,000 個訂單。以每臺 30,000 美元的價格——考慮到需求,Nvidia 幾乎沒有動力打折,而且最近幾個季度的凈利潤率遠高于其數據中心收入的 50% ——即 21 億美元。這還剩下 193 萬美元的 A100,按照 2020 年至今的平均價格約為 12,500 美元計算,總計 241.3 億美元。
在如此巨大的投資流中,性價比曲線顯然還有彎曲的空間,而且 AWS 創建了自己的 Titan 模型,以供母公司 Amazon 和數以萬計的企業客戶使用,并提供其他模型,重要的是來自 Anthropic 的Claude 2,在其本土開發的 Inferentia 和 Trainium 上運行。
我們認為這條曲線看起來與 AWS 使用 Graviton 服務器 CPU 所做的沒有太大不同。AWS 非常樂意銷售 Intel 和 AMD 的 CPU,但它的價格/性能比“傳統”高出 30% 到 40%。由于它通過 Graviton 省去了中間商,因此可以以更低的價格提供 Arm CPU 實例,這對越來越多的客戶有吸引力。我們預計 Nvidia 和 AMD GPU 以及 AWS 制造的 Inferentia 和 Trainium 設備之間也會存在同樣的傳統定價差距。
拋開這些數學問題,我們來談談 Inferentia1,并概覽一下 Inferentia2 和 Trainium1,這樣我們就可以了解 Trainium2,它將與當前在 Hopper H100 GPU 加速器上運行的工作負載進行正面競爭。如您所知,H100 的價格幾乎與黃金一樣昂貴(目前 SXM5 版本每盎司的價格約為黃金的一半),并且像稀土礦物一樣難以獲得,并且是支撐人工智能經濟的不可或缺的一部分。
推斷 TRAINIUM 的架構
所有計算引擎都是計算元素、存儲元素和將它們連接在一起的網絡的層次結構,并且圍繞這些元素的抽象級別可能會發生變化,特別是當架構是新的并且工作負載快速變化時。
Inferentia1 芯片由 Annapurna Labs 的人員創建,于 2018 年 11 月首次發布,一年后全面上市,是 AWS AI 引擎工作的基礎,以下是該設備的架構:
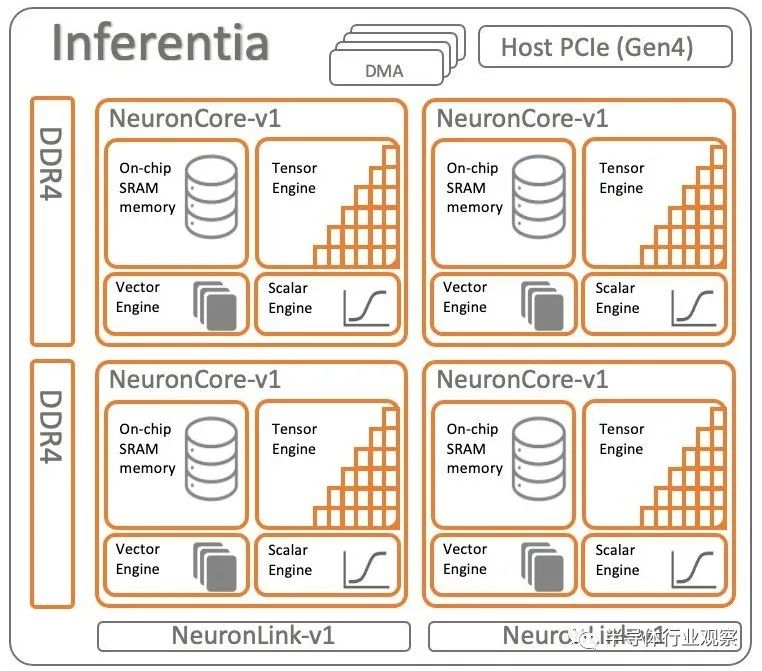
該器件有四個內核,具有四個不同的計算元件,以及用于片上存儲的片上 SRAM 存儲器和用于片外存儲的 DDR4 主存儲器,這與當今許多 AI 芯片制造商一樣。AWS 沒有提供 Inferentia1 設備的 SRAM 內存和緩存大小或時鐘速度的詳細規格,甚至沒有提供設備中使用的每個 NeuronCore 內的元件數量。不過在 Inferentia 和 Trainium 芯片的 Neuron SDK 中,AWS 確實討論了 Inferentia2 和 Trainium1 中使用的 NeuroCore-V2 核心的架構,我們可以以此為基礎來弄清楚 Inferentia1 是什么,并推斷出 Trainium2 可能是什么是。
無論是哪代,NeuronCore 都有一個處理標量計算的 ScalarEngine 和一個處理各種精度的整數和浮點數據向量計算的 VectorEngine。這些大致相當于 Nvidia GPU 中的 CUDA 核心。根據 Neuron SDK,NeuronCore-v1 ScalarEngine 每個周期處理 512 個浮點運算,VectorEngine 每個周期處理 256 個浮點運算。(我們認為AWS的意思是ScalarEngine上每個周期有512位處理,VectorEngine上每個周期有256位處理,然后您通過這些以選擇的格式泵送數據以進行特定類型的計算。
NeuronCore 架構還包括一個 TensorEngine,用于加速矩陣數學,超出了通過 VectorEngine 推動代數矩陣數學的能力,而矩陣數學對于 HPC 和 AI 工作負載至關重要,它們通常會完成大量工作并提供最大的吞吐量。TensorEngine 大致類似于 Nvidia GPU 中的 TensorCore,在 NeuronCore-v1 內核中,它們可以在 FP16/BF16 粒度下提供 16 teraflops。
Trainium1 芯片于 2020 年 12 月發布,并以兩個不同的實例(Trn1 和 Trn1n)發貨。我們當時對 Trainium1 和2021 年 12 月的這些實例進行了盡可能多的分析,坦率地說,AWS 沒有提供大量有關這些本土 AI 計算引擎的數據。Trainium1 使用了新的 NeuroCore-v2 核心,它具有相同的元素,但核心數量更少,如下所示:
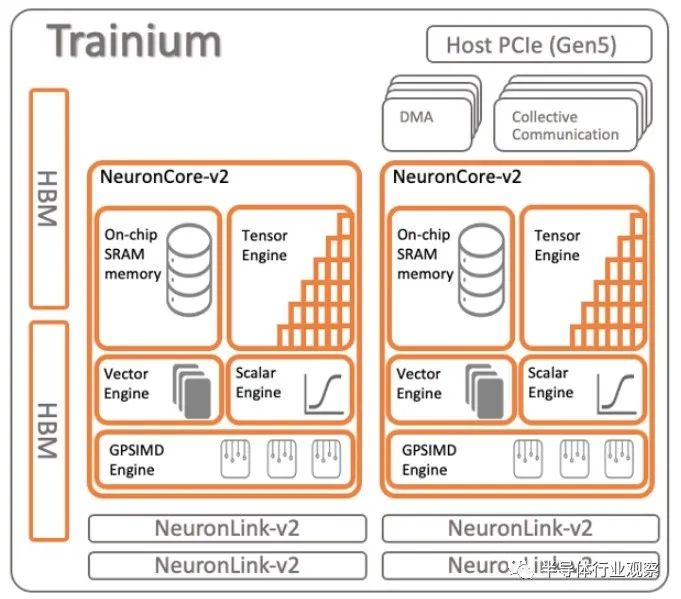
通過 Trainium1 芯片,AWS 添加了 32 GB HBM 堆疊 DRAM 內存以提高設備的帶寬,轉向 PCI-Express 5.0 外形尺寸和 I/O 插槽,并增加了 NeuronLink 芯片間互連鏈路的數量其帶寬提高了 2 到 4 倍,同時帶寬也提高了 2 倍。
我們沒有證據證明這一點,但我們認為,通過 Trainium1,AWS 將每個芯片的 NeuronCore 數量比 Inferentia1 減少了一半(兩個而不是四個),然后每個核心內的標量、矢量和張量引擎的數量增加了一倍。當時的變化實際上是緩存和內存層次結構抽象級別的變化,基本上使 NeuronCore 在每個計算元素類型中實現多線程。
有趣的是,Trainium 芯片中首次使用的 NeuronCore-v2 還包括稱為 GPSIMD 引擎的東西,它是一組 8 個 512 位寬的通用處理器。(確實非常有趣。)這些設備可以直接使用 C 和 C++ 進行尋址,并且可以訪問片上 SRAM 和內核上的其他三種類型的引擎,并用于實現需要加速且不需要加速的自定義操作。直接受其他引擎中的數據和計算格式支持。(我們必須查閱Flynn 的分類法,試圖弄清楚這個 GPSIMD 引擎是如何適應的,并且從文檔中并不清楚我們看到的是這是一個陣列處理器、管道處理器還是關聯處理器.)
用于推理的 Inferentia2 芯片基本上是一個 Trainium1 芯片,其數量只有一半的 NeuronLink-v2 互連端口。芯片的某些元件也可能未激活。時鐘速度和性能似乎大致相同,HBM 內存容量和帶寬也是如此。
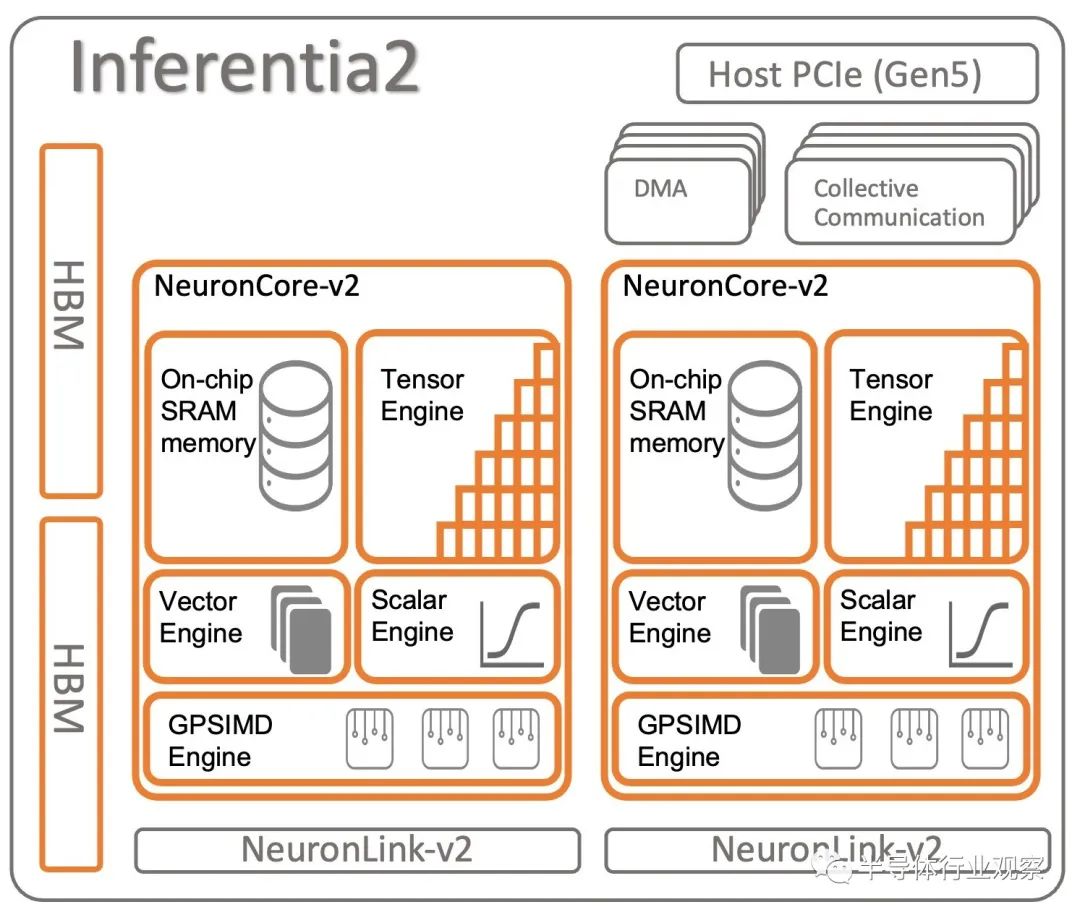
“Inferentia2 和 Trainium1 之間的芯片架構幾乎相同,”Hutt 告訴The Next Platform。“我們為 Inferentia2 保留了 HBM 帶寬,因為這對于推理非常重要,而不僅僅是訓練。LLM 推理實際上受內存限制,而不是計算限制。因此,我們實際上可以采用類似的硅架構并盡可能降低成本 - 例如,我們不需要那么多的 NeuronLink。通過推理,當我們從一個加速器移動到另一個加速器時,我們只需要環形的鏈接來生成token。當然,通過訓練,您需要完整的網狀連接,最大限度地減少服務器內部每個加速器之間的跳數。當然,當你訪問訓練服務器時,你需要大量的網絡帶寬。”
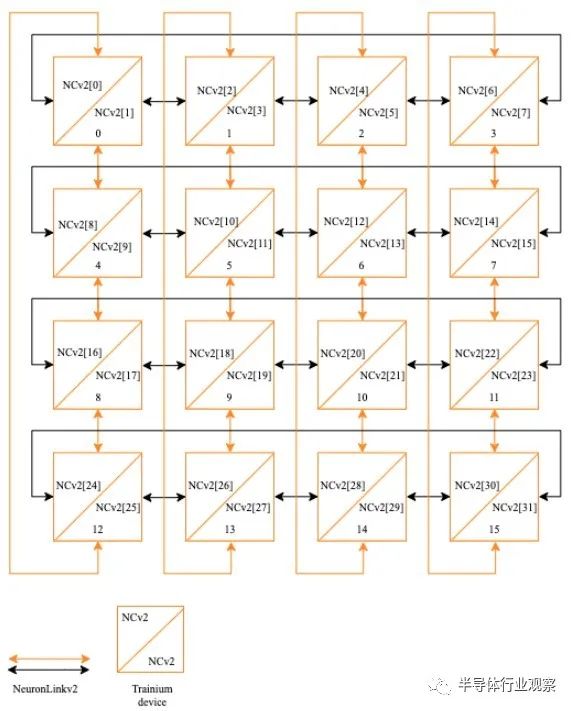
使用 16 個 Trainium1 芯片的服務器上的互連是一個 2D 環面或 3D 超立方體,根據 Hutt 的說法,它們是同一件事,具體取決于你想如何談論它,它看起來像這樣:
下面的表格匯集了我們所知道的 Inferentia1、Inferentia2 和 Trainium1 的饋送和速度,以及我們對 Trainium2 的預測(以粗體紅色斜體顯示)。Neuron SDK 尚未使用有關 Trainium2 的任何信息進行更新。
根據如下所示的 Trainium2 芯片封裝圖片,我們認為它本質上是兩個 Trainium1 芯片互連在一起,要么作為單片芯片,要么作為兩個小芯片插槽,通過某種高速互連將它們連接在一起:
Hutt 沒有透露 Trainium 芯片的任何數據和速度,但他確實確認 Trainium2 擁有更多的內核和更多的內存帶寬,并進一步補充說,芯片的有效性能將擴展到 4 倍——他稱這是一個保守的數字,也許超出了現實世界人工智能訓練工作負載的 Trainium1 的數字,因為這些工作負載更多地受到內存容量和內存帶寬的限制,而不是受計算的限制。
我們認為Trainium2芯片將有32個核心,并將從Trainium 1使用的7納米工藝縮小到4納米工藝,這樣核心的加倍就可以在與Trainium1相同或稍高的功率范圍內完成。我們還認為,Trainium2 中的時鐘速度將從 Trainium1 中使用的 3 GHz(AWS 已透露的數字)適度提高到 3.4 GHz。我們還認為(僅基于預感),Trainium2 上的總 NeuronLink 帶寬將增加 33%,達到每個端口 256 GB/秒,從 Trainium2 產生 2 TB/秒,并且仍然允許 2D環面互連。每個芯片上的 NeuronLink 端口數量可能會增加,以增加環面的維數,并減少設備共享數據時設備之間的一些跳數。2D 環面意味著集群中任意兩個 NeuronCore 芯片之間有固定的兩跳。網絡似乎不太可能增加到全面配置,但這是可能的。(SGI 曾經用其超級計算機芯片組來做到這一點。)
我們還認為,鑒于 AWS 希望使用 Trainium2 將 UltraCluster 擴展到 100,000 個設備,它將減少 Trainium2 上的實際核心數量,使其比我們在上表中顯示的 64 個核心少很多。
很難說它會在哪里,假設大約 10% 的核心將是無用的,因此芯片的產量將會高得多。您可以打賭,AWS 將保留任何可以在一組單獨的機器中運行所有核心的 Trainium2 設備,很可能供每個核心都很重要的內部使用。這將使 Trainium2 擁有 56 個核心或 58 個核心,甚至可能高達 56 個核心,并且所有帶寬都可供它們使用。AWS 承諾的 96 GB 可能僅用于我們認為在設備上看到的四個內存堆棧中的三個,該設備可能具有 128 GB 的實際 HBM 內存。我們強烈懷疑這將是 HBM3 內存,但 Hutt 沒有證實任何事情。
但他多次說過,性能是由內存驅動的,而不是指望原始峰值理論計算的增長速度快于內存帶寬,如果我們是對的,內存帶寬將增長 5 倍位于 Trainium1 和 Trainium2 之間。
以下是使用 Inferentia 和 Trainium 芯片可用的實例:
任何人都在猜測 Trn2 實例在價格或性能方面的比較,但根據暗示和預感,我們堅信 Trainium2 將提供 Nvidia H100 大約 2 倍的性能,這意味著它將與之旗鼓相當- Nvidia 剛剛發布的 H200 配備了更大、更快的 HBM3e 內存,適用于許多型號。當我們建議 AWS 可能會對基于 Trainium2 的 EC2 實例相對于使用 Nvidia 的 H100 和 H200 GPU 的實例進行定價時,其比率與其自己的 Graviton CPU 與 AMD 和 Intle X86 處理器之間的比率相同 - 介于 30% 到 40% 之間物有所值——Hutt并沒有勸阻我們放棄這種想法。但Hutt也沒有做出任何承諾,只是說性價比肯定會更好。
這并非毫無意義,而是將 100,000 個設備以 FP16 精度以 65 exaflops 連接在一起,并且沒有任何稀疏技巧,而是真正的 FP16 分辨率,有機會成為世界上最大的人工智能集群。
審核編輯:黃飛
?











 工商網監
工商網監
評論