 電子發燒友App
電子發燒友App


屹立不倒的 Transformer 迎來了一個強勁競爭者。
在別的領域,如果你想形容一個東西非常重要,你可能將其形容為「撐起了某領域的半壁江山」。但在 AI 大模型領域,Transformer 架構不能這么形容,因為它幾乎撐起了「整個江山」。
自 2017 年被提出以來,Transformer 已經成為 AI 大模型的主流架構,但隨著模型規模的擴展和需要處理的序列不斷變長,Transformer 的局限性也逐漸凸顯。一個很明顯的缺陷是:Transformer 模型中自注意力機制的計算量會隨著上下文長度的增加呈平方級增長,比如上下文增加 32 倍時,計算量可能會增長 1000 倍,計算效率非常低。
為了克服這些缺陷,研究者們開發出了很多注意力機制的高效變體,但這往往以犧牲其有效性特為代價。到目前為止,這些變體都還沒有被證明能在不同領域發揮有效作用。
最近,一項名為「Mamba」的研究似乎打破了這一局面。

在這篇論文中,研究者提出了一種新的架構 ——「選擇性狀態空間模型( selective state space model)」。它在多個方面改進了先前的工作。
作者表示,「Mamba」在語言建模方面可以媲美甚至擊敗 Transformer。而且,它可以隨上下文長度的增加實現線性擴展,其性能在實際數據中可提高到百萬 token 長度序列,并實現 5 倍的推理吞吐量提升。
消息一出,人們紛紛點贊,有人表示已經迫不及待想要把它用在大模型上了。
作為通用序列模型的骨干,Mamba 在語言、音頻和基因組學等多種模態中都達到了 SOTA 性能。在語言建模方面,無論是預訓練還是下游評估,他們的 Mamba-3B 模型都優于同等規模的 Transformer 模型,并能與兩倍于其規模的 Transformer 模型相媲美。

這篇論文的作者只有兩位,一位是卡內基梅隆大學機器學習系助理教授 Albert Gu,另一位是 Together.AI 首席科學家、普林斯頓大學計算機科學助理教授(即將上任)Tri Dao。
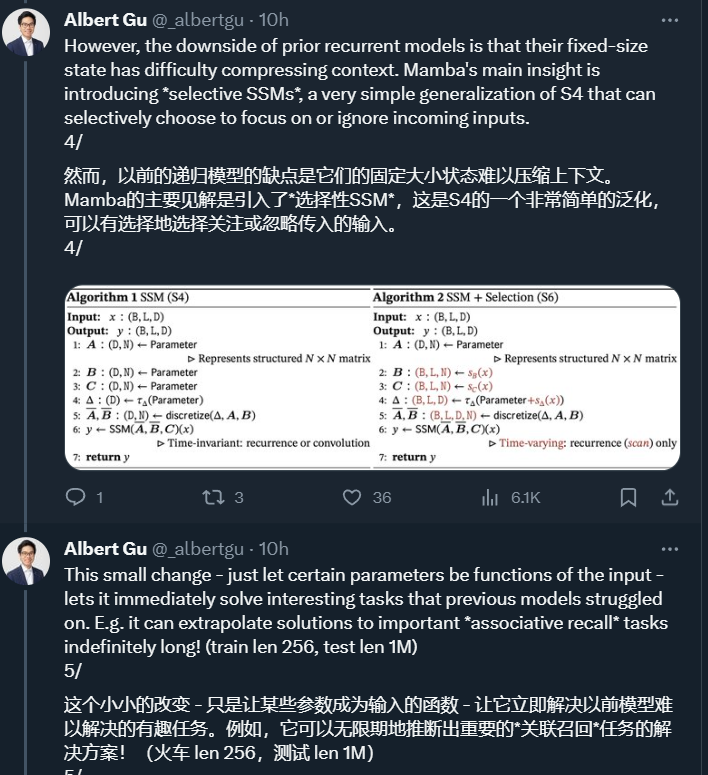
Albert Gu 表示,這項研究的一個重要創新是引入了一個名為「選擇性 SSM」的架構,該架構是 Albert Gu 此前主導研發的 S4 架構(Structured State Spaces for Sequence Modeling ,用于序列建模的結構化狀態空間)的一個簡單泛化,可以有選擇地決定關注還是忽略傳入的輸入。一個「小小的改變」—— 讓某些參數成為輸入的函數,結果卻非常有效。
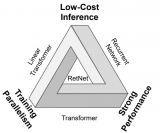
值得一提的是,S4 是一個非常成功的架構。此前,它成功地對? Long Range Arena (LRA) 中的長程依賴進行了建模,并成為首個在 Path-X 上獲得高于平均性能的模型。更具體地說,S4 是一類用于深度學習的序列模型,與 RNN、CNN 和經典的狀態空間模型(State Space Model,SSM)廣泛相關。SSM 是獨立的序列轉換,可被整合到端到端神經網絡架構中( SSM 架構有時也稱 SSNN,它與 SSM 層的關系就像 CNN 與線性卷積層的關系一樣)。Mamba 論文也討論了一些著名的 SSM 架構,比如 Linear attention、H3、Hyena、RetNet、RWKV,其中許多也將作為論文研究的基線。Mamba 的成功讓 Albert Gu 對 SSM 的未來充滿了信心。
Tri Dao 則是 FlashAttention、Flash Attention v2、Flash-Decoding的作者。FlashAttention 是一種對注意力計算進行重新排序并利用經典技術(平鋪、重新計算)加快速度并將內存使用從序列長度的二次減少到線性的算法。Flash Attention v2、Flash-Decoding 都是建立在 Flash Attention 基礎上的后續工作,把大模型的長文本推理效率不斷推向極限。在 Mamba 之前,Tri Dao 和 Albert Gu 也有過合作。

另外,這項研究的模型代碼和預訓練的檢查點是開源的,參見以下鏈接:https://github.com/state-spaces/mamba.

論文鏈接:https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
https://github.com/state-spaces/mamba
方法創新
論文第 3.1 節介紹了如何利用合成任務的直覺來啟發選擇機制,第 3.2 節解釋了如何將這一機制納入狀態空間模型。由此產生的時變 SSM 不能使用卷積,導致了高效計算的技術難題。研究者采用了一種硬件感知算法,利用當前硬件的內存層次結構來克服這一難題(第 3.3 節)。第 3.4 節描述了一個簡單的 SSM 架構,不需要注意力,甚至不需要 MLP 塊。第 3.5 節討論了選擇機制的一些其他特性。
選擇機制
研究者發現了此前模型的一個關鍵局限:以依賴輸入的方式高效選擇數據的能力(即關注或忽略特定輸入)。
序列建模的一個基本方法是將上下文壓縮到更小的狀態,我們可以從這個角度來看待當下流行的序列模型。例如,注意力既高效又低效,因為它根本沒有明確壓縮上下文。這一點可以從自回歸推理需要明確存儲整個上下文(即 KV 緩存)這一事實中看出,這直接導致了 Transformer 緩慢的線性時間推理和二次時間訓練。
遞歸模型的效率很高,因為它們的狀態是有限的,這意味著恒定時間推理和線性時間訓練。然而,它們的高效性受限于這種狀態對上下文的壓縮程度。
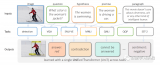
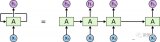
為了理解這一原理,下圖展示了兩個合成任務的運行示例:
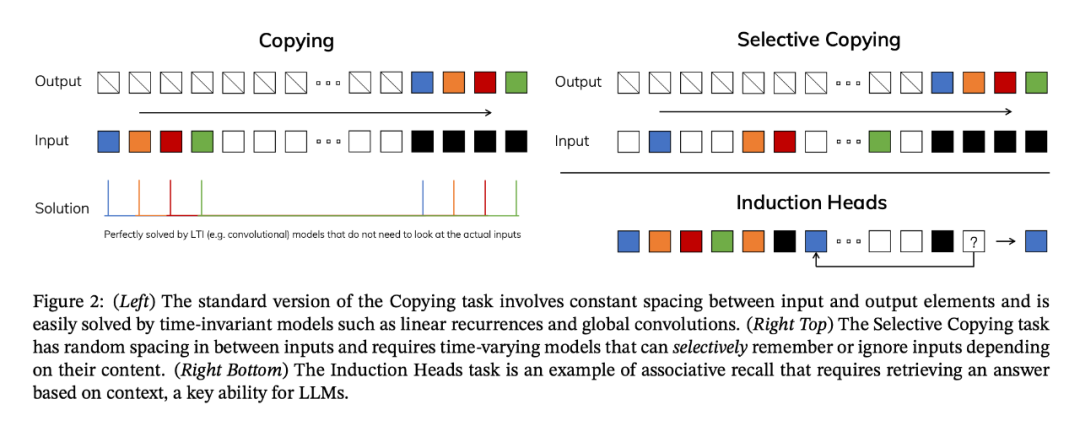
研究者設計了一種簡單的選擇機制,根據輸入對 SSM 參數進行參數化。這樣,模型就能過濾掉無關信息,并無限期地記住相關信息。
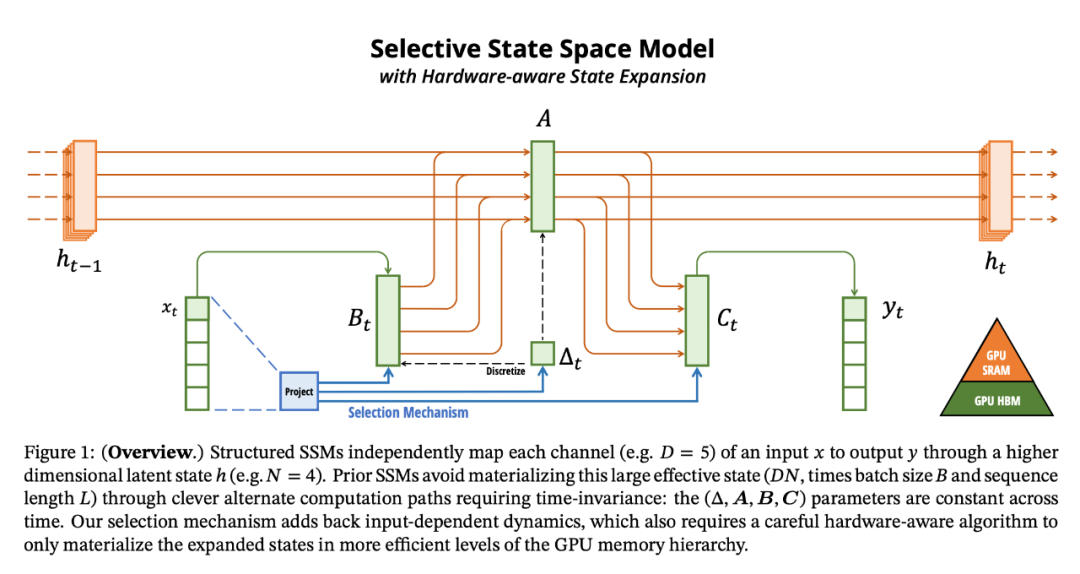
將選擇機制納入模型的一種方法是讓影響序列交互的參數(如 RNN 的遞歸動力學或 CNN 的卷積核)與輸入相關。算法 1 和 2 展示了本文使用的主要選擇機制。其主要區別在于,該方法只需將幾個參數 ?,B,C 設置為輸入函數,并在整個過程中改變張量形狀。這些參數現在都有一個長度維度 L ,意味著模型已經從時間不變變為時間可變。

硬件感知算法
上述變化對模型的計算提出了技術挑戰。所有先前的 SSM 模型都必須是時間和輸入不變的,這樣才能提高計算效率。為此,研究者采用了一種硬件感知算法,通過掃描而不是卷積來計算模型,但不會將擴展狀態具體化,以避免在 GPU 存儲器層次結構的不同級別之間進行 IO 訪問。由此產生的實現方法在理論上(與所有基于卷積的 SSM 的偽線性相比,在序列長度上呈線性縮放)和現有硬件上都比以前的方法更快(在 A100 GPU 上可快達 3 倍)。
架構
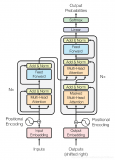
研究者將先前的 SSM 架構設計與 Transformer 的 MLP 塊合并為一個塊,從而簡化了深度序列模型架構,形成了一種包含選擇性狀態空間的簡單、同質的架構設計(Mamba)。
與結構化 SSM 一樣,選擇性 SSM 也是一種獨立的序列變換,可以靈活地融入神經網絡。H3 架構是著名的同質化架構設計的基礎,通常由線性注意力啟發的塊和 MLP(多層感知器)塊交錯組成。
研究者簡化了這一架構,將這兩個部分合二為一,均勻堆疊,如圖 3。他們受到門控注意力單元(GAU)的啟發,該單元也對注意力做了類似的處理。
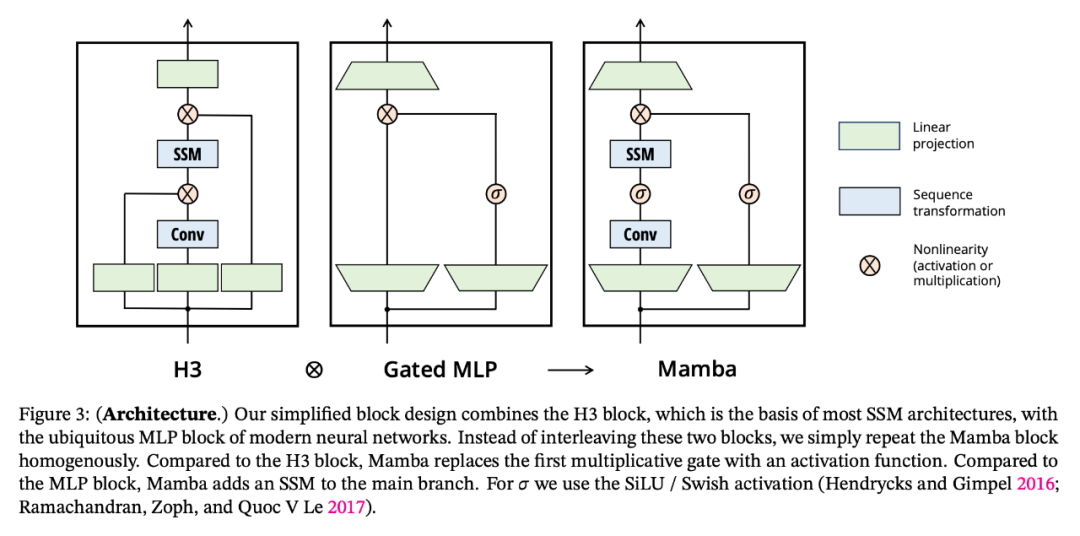
選擇性 SSM 以及 Mamba 架構的擴展是完全遞歸模型,幾個關鍵特性使其適合作為在序列上運行的通用基礎模型的骨干:
高質量:選擇性為語言和基因組學等密集模型帶來了強大的性能。
快速訓練和推理:在訓練過程中,計算量和內存與序列長度成線性關系,而在推理過程中,由于不需要緩存以前的元素,自回歸展開模型每一步只需要恒定的時間。
長上下文:質量和效率共同提高了實際數據的性能,序列長度可達 100 萬。
實驗評估
實證驗證了 Mamba 作為通用序列基礎模型骨干的潛力,無論是在預訓練質量還是特定領域的任務性能方面,Mamba 都能在多種類型的模態和環境中發揮作用:
合成任務。在復制和感應頭等重要的語言模型合成任務上,Mamba 不僅能輕松解決,而且能推斷出無限長的解決方案(>100 萬 token)。
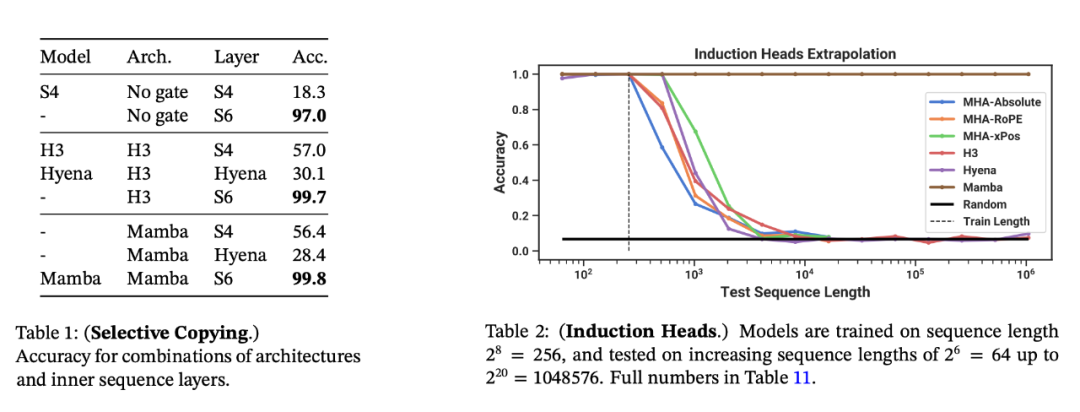
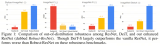
音頻和基因組學。在音頻波形和 DNA 序列建模方面,Mamba 在預訓練質量和下游指標方面都優于 SaShiMi、Hyena、Transformer 等先前的 SOTA 模型(例如,在具有挑戰性的語音生成數據集上將 FID 降低了一半以上)。在這兩種情況下,它的性能隨著上下文長度的增加而提高,最高可達百萬長度的序列。
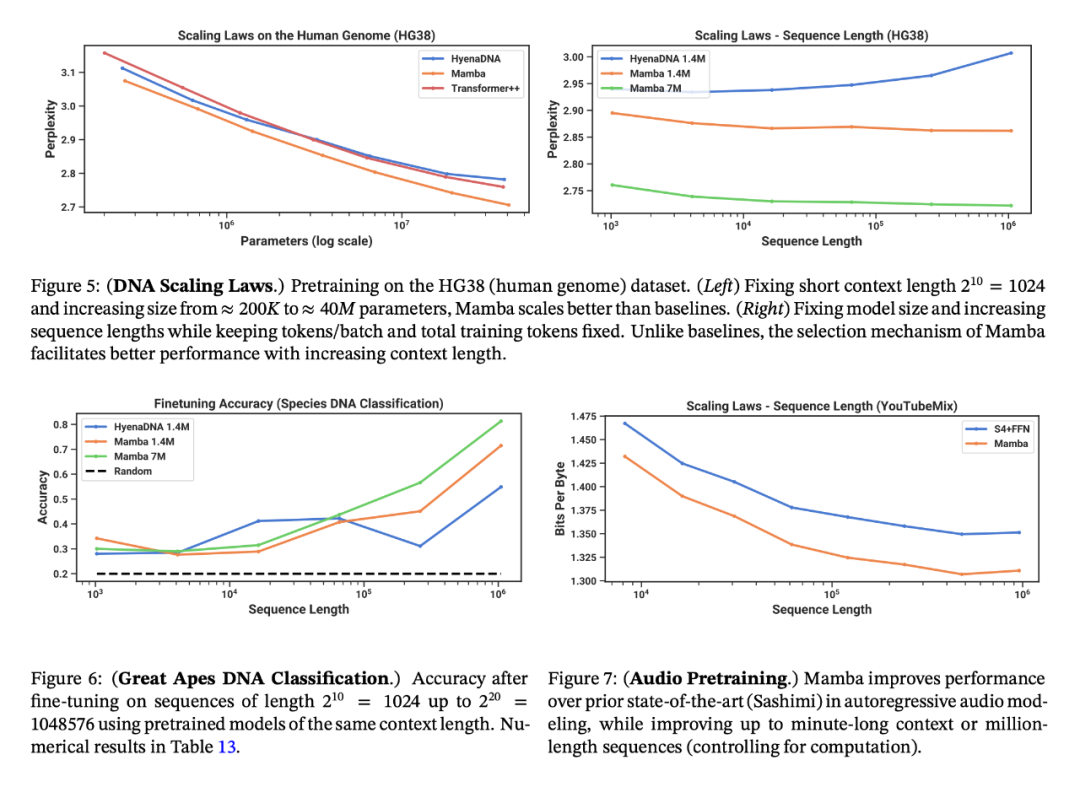
語言建模。Mamba 是首個線性時間序列模型,在預訓練復雜度和下游評估方面都真正達到了 Transformer 質量的性能。通過多達 1B 參數的縮放規律,研究者發現 Mamba 的性能超過了大量基線模型,包括 LLaMa 這種非常強大的現代 Transformer 訓練配方。
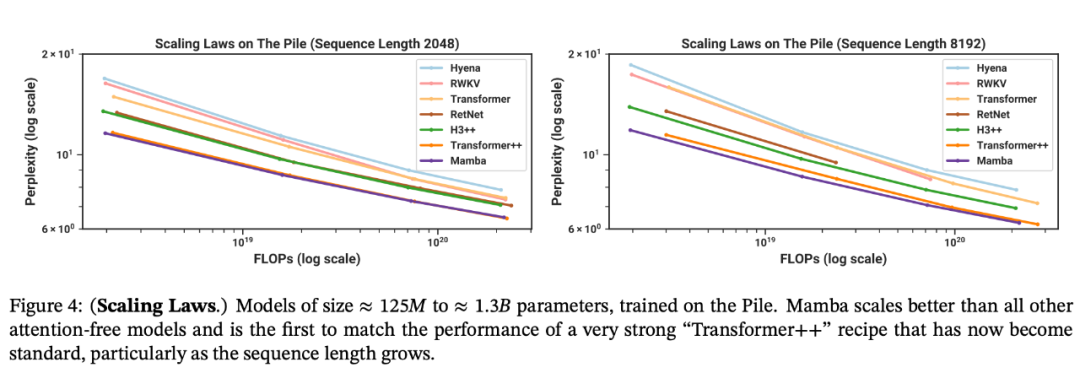
與類似規模的 Transformer 相比,Mamba 具有 5 倍的生成吞吐量,而且 Mamba-3B 的質量與兩倍于其規模的 Transformer 相當(例如,與 Pythia-3B 相比,常識推理的平均值高出 4 分,甚至超過 Pythia-7B)。
審核編輯:黃飛


















 工商網監
工商網監
評論