 電子發燒友App
電子發燒友App


機器學習是為各種復雜的回歸和分類任務構建預測模型的最流行的技術之一。梯度提升機(Gradient Boosting Machine,GBM)被認為是最強大的提升算法之一。
盡管機器學習中使用的算法非常多,但Boosting算法已成為全球機器學習社區的主流。Boosting 技術遵循集成學習的概念,因此它結合了多個簡單模型(弱學習器或基礎估計器)來生成最終輸出。GBM 還用作機器學習中的集成方法,將弱學習器轉換為強學習器。在本主題“機器學習中的 GBM”中,我們將討論梯度機器學習算法、機器學習中的各種 boosting 算法、GBM 的歷史、它的工作原理、GBM 中使用的各種術語等。但在開始之前,首先,了解機器學習中的 boosting 概念和各種 boosting 算法。
什么是機器學習中的Boosting?
Boosting 是流行的學習集成建模技術之一,用于從各種弱分類器構建強分類器。它首先根據可用的訓練數據集構建主要模型,然后識別基本模型中存在的錯誤。識別錯誤后,建立第二個模型,并進一步在此過程中引入第三個模型。這樣,引入更多模型的過程就會持續下去,直到我們得到一個完整的訓練數據集,模型可以通過該數據集進行正確的預測。
AdaBoost(自適應增強)是機器學習歷史上第一個將各種弱分類器組合成單個強分類器的增強算法。它主要致力于解決二元分類等分類任務。
Boosting算法的步驟:
增強算法有以下幾個重要步驟:
考慮具有不同數據點的數據集并對其進行初始化。
現在,為每個數據點賦予相同的權重。
假設該權重作為模型的輸入。
識別錯誤分類的數據點。
增加步驟 4 中數據點的權重。
如果獲得適當的輸出,則終止此過程,否則再次執行步驟 2 和 3。
例子:
假設我們有三個不同的模型及其預測,并且它們以完全不同的方式工作。例如,線性回歸模型顯示數據中的線性關系,而決策樹模型嘗試捕獲數據中的非線性關系,如下圖所示。
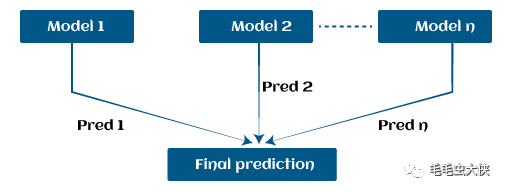
此外,如果我們以系列或組合的形式使用這些模型,而不是單獨使用這些模型來預測結果,那么我們會得到一個比所有基本模型具有正確信息的結果模型。換句話說,如果我們使用這些模型的平均預測,而不是使用每個模型的單獨預測,那么我們將能夠從數據中捕獲更多信息。它被稱為集成學習,Boosting 也是基于機器學習中的集成方法。
增強機器學習中的算法
機器學習中主要有 4 種 boosting 算法。具體如下:
梯度提升機(GBM)
極限梯度提升機(XGBM)
輕型GBM
貓助推器
機器學習中的 GBM 是什么?
梯度提升機(GBM)是機器學習中最流行的前向學習集成方法之一。它是構建回歸和分類任務預測模型的強大技術。
GBM 幫助我們獲得弱預測模型(例如決策樹)集合形式的預測模型。每當決策樹作為弱學習器執行時,生成的算法就稱為梯度增強樹。
它使我們能夠結合來自各種學習器模型的預測,并構建具有正確預測的最終預測模型。
但這里可能會出現一個問題,如果我們應用相同的算法,那么多個決策樹如何能夠比單個決策樹提供更好的預測?此外,每個決策樹如何從相同的數據中捕獲不同的信息?
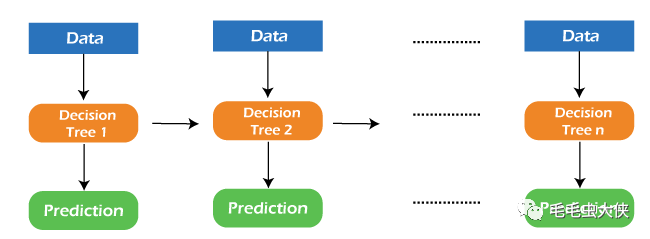
因此,這些問題的答案是每個決策樹的節點采用不同的特征子集來選擇最佳分割。這意味著每棵樹的行為不同,因此從相同的數據中捕獲不同的信號。
GBM 是如何運作的?
一般來說,大多數監督學習算法都基于單一預測模型,例如線性回歸、懲罰回歸模型、決策樹等。但是機器學習中也有一些監督算法依賴于通過集成將各種模型組合在一起。換句話說,當多個基本模型貢獻其預測時,所有預測的平均值將通過增強算法進行調整。
梯度增強機由以下 3 個要素組成:
損失函數
學習能力較弱
加法模型
讓我們詳細了解這三個要素。
1.損失函數:
盡管如此,機器學習中有很多損失函數,可以根據要解決的任務類型來使用。損失函數的使用是根據條件分布的魯棒性等具體特征的需求來估計的。在我們的任務中使用損失函數時,我們必須指定損失函數和計算相應負梯度的函數。一旦我們得到了這兩個函數,它們就可以很容易地實現到梯度提升機中。然而,已經為 GBM 算法提出了幾種損失函數。
損失函數的分類:
根據響應變量y的類型,損失函數可以分為以下不同類型:
連續響應,y ∈ R:
高斯 L2 損失函數
拉普拉斯 L1 損失函數
Huber 損失函數,指定 δ
分位數損失函數,指定 α
分類響應,y ∈ {0, 1}:
二項式損失函數
Adaboost 損失函數
其他響應變量系列:
生存模型的損失函數
損失函數計數數據
自定義損失函數
2. 弱學習者:
弱學習器是基礎學習器模型,可以從過去的錯誤中學習,并幫助構建強大的預測模型設計,以增強機器學習中的算法。一般來說,決策樹在增強算法中充當弱學習器。
Boosting 被定義為持續改進基礎模型輸出的框架。許多梯度增強應用程序允許您“插入”各種類別的弱學習器供您使用。因此,決策樹最常用于弱(基礎)學習器。
如何訓練弱學習者:
機器學習使用訓練數據集來訓練基礎學習器,并根據先前學習器的預測,通過關注先前樹具有最大錯誤或殘差的訓練數據行來提高性能。例如,淺樹被認為是決策樹的弱學習者,因為它包含一些分裂。一般來說,在 boosting 算法中,具有最多 6 個分割的樹是最常見的。
下面是訓練弱學習器以提高其性能的序列,其中每棵樹都與前一棵樹的殘差位于序列中。此外,我們引入每棵新樹,以便它可以從前一棵樹的錯誤中學習。具體如下:
考慮一個數據集并在其中擬合決策樹。
F1(x)=y
用前一棵樹的最大誤差來擬合下一棵決策樹。
h1(x)=y?F1(x)
通過在步驟 1 和 2 中添加這棵新樹,將其添加到算法中。
F2(x)=F1(x)+h1(x)
再次將下一個決策樹與前一個決策樹的殘差進行擬合。
h2(x)=y?F2(x)
重復我們在步驟 3 中所做的相同操作。
F3(x)=F2(x)+h2(x)
繼續這個過程,直到某種機制(即交叉驗證)告訴我們停止。這里的最終模型是 b 個個體樹的階段性加性模型:
f(x)=BΣb=1fb(x)
因此,樹是貪婪地構建的,根據基尼等純度分數選擇最佳分割點或最小化損失。
3. 加法模型:
加性模型被定義為向模型添加樹。盡管我們不應該一次添加多棵樹,但必須只添加一棵樹,這樣模型中的現有樹就不會改變。此外,我們還可以通過添加樹來選擇梯度下降法來減少損失。
過去幾年,梯度下降法被用來最小化神經網絡中回歸方程的系數和權重等參數集。計算出誤差或損失后,使用權重參數來最小化誤差。但最近,大多數機器學習專家更喜歡弱學習子模型或決策樹作為這些參數的替代品。其中,我們必須在模型中添加一棵樹來減少誤差并提高模型的性能。這樣,新添加的樹的預測與現有樹系列的預測相結合,得到最終的預測。此過程持續進行,直到損失達到可接受的水平或不再需要改進。
該方法也稱為函數梯度下降或函數梯度下降。
極限梯度提升機 (XGBM)
XGBM 是梯度增強機的最新版本,其工作原理也與 GBM 非常相似。在 XGBM 中,樹是按順序添加的(一次一棵),從先前樹的錯誤中學習并改進它們。雖然 XGBM 和 GBM 算法在外觀和感覺上很相似,但它們之間仍然存在一些差異,如下所示:
XGBM 使用各種正則化技術來減少模型的欠擬合或過擬合,這也比梯度增強機更能提高模型性能。
XGBM 遵循每個節點的并行處理,而 GBM 則不然,這使得它比梯度增強機更快。
XGBM 幫助我們擺脫缺失值的插補,因為默認情況下模型會處理它。它自行了解這些值是否應該位于右側節點或左側節點中。
光梯度增強機(Light GBM)
Light GBM 是梯度增強機的升級版,因其效率高且速度快。與GBM和XGBM不同,它可以處理大量數據而沒有任何復雜性。另一方面,它不適合那些數量較少的數據點。
Light GBM 更喜歡樹節點的葉向生長,而不是水平生長。此外,在light GBM中,主節點被分裂為兩個輔助節點,然后選擇一個輔助節點進行分裂。輔助節點的這種分裂取決于兩個節點之間哪個具有更高的損耗。
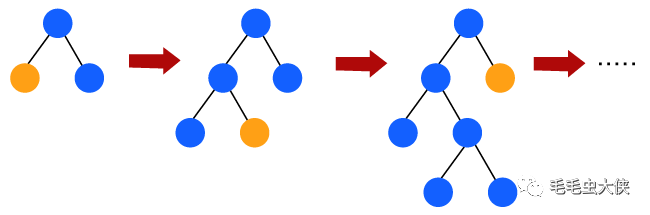
因此,由于葉向分割,在給定大量數據的情況下,光梯度提升機(LGBM)算法始終優于其他算法。
CATBOOST
catboost 算法主要用于處理數據集中的分類特征。盡管 GBM、XGBM 和 Light GBM 算法適用于數值數據集,但 Catboost 旨在將分類變量處理為數值數據。因此,catboost 算法包含一個重要的預處理步驟,用于將分類特征轉換為任何其他算法中不存在的數值變量。
Boosting算法的優點:
增強算法遵循集成學習,這使得模型能夠給出更準確的預測,這是不可超越的。
Boosting 算法比其他算法靈活得多,因為它可以優化不同的損失函數并提供多種超參數調整選項。
它不需要數據預處理,因為它適用于數值變量和分類變量。
它不需要對數據集中的缺失值進行插補,它會自動處理缺失的數據。
Boosting算法的缺點:
以下是 boosting 算法的一些缺點:
提升算法可能會導致過度擬合以及過分強調異常值。
梯度提升算法不斷關注最小化錯誤,并且需要多個樹,因此計算成本很高。
這是一種耗時且內存耗盡的算法。
盡管可以使用各種工具輕松解決這個問題,但本質上解釋性較差。
結論:
通過這種方式,我們學習了機器學習中預測建模的增強算法。此外,我們還討論了 ML 中使用的各種重要的 boosting 算法,例如 GBM、XGBM、light GBM 和 Catboost。此外,我們還了解了各種組件(損失函數、弱學習器和加性模型)以及 GBM 如何與它們配合使用。Boosting 算法如何有利于在現實場景中的部署等。
審核編輯:黃飛
?














 工商網監
工商網監
評論