 電子發(fā)燒友App
電子發(fā)燒友App


算力調(diào)度層可類比為“算網(wǎng)大腦”,是算力網(wǎng)絡(luò)中最核心的部分。除技術(shù)自身的難 度外,算力調(diào)度還需綜合考慮成本、需求等因素,是困難的多約束求解問題。1)技 術(shù):算力調(diào)度的技術(shù)創(chuàng)新主要包括計算能力跨區(qū)域調(diào)度、多級調(diào)度、算力資源統(tǒng)一 安排、網(wǎng)絡(luò)協(xié)議、可視化監(jiān)控和智能運(yùn)維。2)需求:不同的應(yīng)用場景對應(yīng)不同的算 力或時延需求,如科學(xué)計算類和國計民生類工程項(xiàng)目需要超高算力,而普通商用、 民用交互場景則往往側(cè)重于對時延的要求。3)成本:算力調(diào)度的一般原則為,根據(jù) 算力、時延要求,選擇最經(jīng)濟(jì)的算力網(wǎng)絡(luò)架構(gòu)布局,來降低算力成本、網(wǎng)絡(luò)成本、 運(yùn)營成本。
算力調(diào)度平臺建設(shè)如火如荼。“東數(shù)西算”工程啟動以來,各地區(qū)相關(guān)單位就算力 度量、算力互聯(lián)互通、算力調(diào)度、算力交易等重點(diǎn)問題展開前瞻性研究。據(jù)不完全 統(tǒng)計,目前全國已發(fā)布或建設(shè) 10 余個算力平臺,涉及 3 個省份和 7 個城市,其中既 有“東數(shù)西算”樞紐節(jié)點(diǎn),也有非樞紐節(jié)點(diǎn)參與算力平臺建設(shè)。1)寧夏上線國內(nèi)首 個一體化算力交易調(diào)度平臺——東數(shù)西算一體化算力服務(wù)平臺,該平臺可為智算、 超算、通用算力等各類算力產(chǎn)品提供算力發(fā)現(xiàn)、供需撮合、交易購買、調(diào)度使用等 綜合服務(wù)。2)北京發(fā)布算力互聯(lián)互通驗(yàn)證平臺,并已初步實(shí)驗(yàn)跨服務(wù)商、跨地區(qū)、 跨架構(gòu)的算力互聯(lián)互通能力,未來將實(shí)現(xiàn)對京津冀地區(qū),寧夏、內(nèi)蒙等國家算力樞 紐、四部戰(zhàn)略合作地區(qū)的算力互聯(lián)互通。
算力平臺多以政府/國企/研究機(jī)構(gòu)/數(shù)據(jù)單位/超算中心為建設(shè)主體,聯(lián)合數(shù)據(jù)運(yùn)營公 司、數(shù)據(jù)服務(wù)企業(yè)、數(shù)字化轉(zhuǎn)型解決方案提供商等企業(yè),及算力服務(wù)提供商、設(shè)備 商、大模型廠商等共同建設(shè)。以寧夏東數(shù)西算一體化算力服務(wù)平臺為例,該平臺通 過資源整合,已將中科曙光、華為、中興、阿里云、天翼云等國內(nèi)大算力領(lǐng)先企 業(yè),國家信息中心、北京大數(shù)據(jù)研究院等國內(nèi)主要大數(shù)據(jù)機(jī)構(gòu),以及商湯、百度等 大模型頭部企業(yè),中國電信、中興通訊、萬達(dá)信息、安恒信息、鵬博士、思特奇等 多家上市公司共計 27 家納入平臺。 ? ?
算力調(diào)度,算力網(wǎng)絡(luò)的大腦中樞
“東數(shù)西算”拉開全國一體化算力網(wǎng)絡(luò)序幕,布局 8 大樞紐節(jié)點(diǎn)、10 大集群。2022 年 2 月 17 日,國家發(fā)改委、中央網(wǎng)信辦、工信部、國家能源局聯(lián)合印發(fā)通知,同意在京津冀、長三角、粵 港澳大灣區(qū)、成渝、內(nèi)蒙古、貴州、甘肅、寧夏等 8 地啟動建設(shè)國家算力樞紐節(jié)點(diǎn),并規(guī)劃了 10 個國家數(shù)據(jù)中心集群。至此,全國一體化大數(shù)據(jù)中心體系完成總體布局設(shè)計,“東數(shù)西算”工程 正式全面啟動。根據(jù)布局,8 個國家算力樞紐節(jié)點(diǎn)將作為我國算力網(wǎng)絡(luò)的骨干連接點(diǎn),開展數(shù)據(jù)中心與網(wǎng)絡(luò)、云 計算、大數(shù)據(jù)之間的協(xié)同建設(shè),并作為國家“東數(shù)西算”工程的戰(zhàn)略支點(diǎn)。每個樞紐節(jié)點(diǎn)將發(fā)展 1-2 個數(shù)據(jù)中心集群,算力樞紐和集群的關(guān)系,類似于交通樞紐和客運(yùn)車站,數(shù)據(jù)中心集群將匯 聚大型、超大型數(shù)據(jù)中心,具體承接數(shù)據(jù)流量。
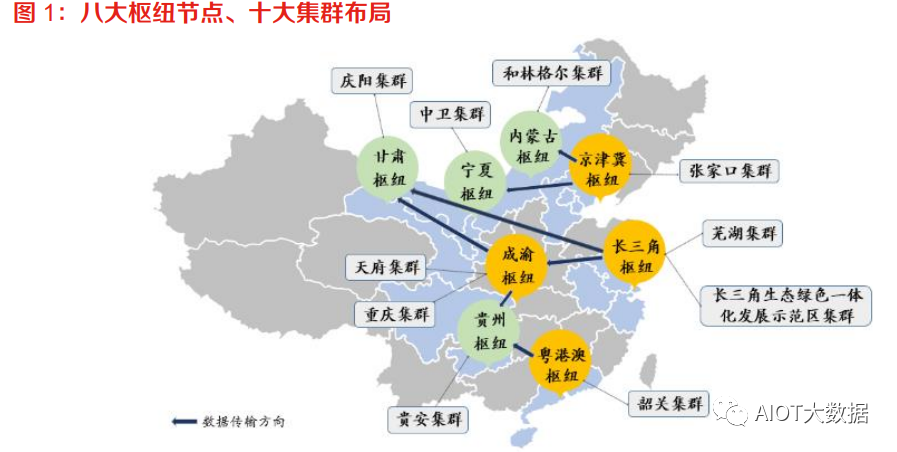
?
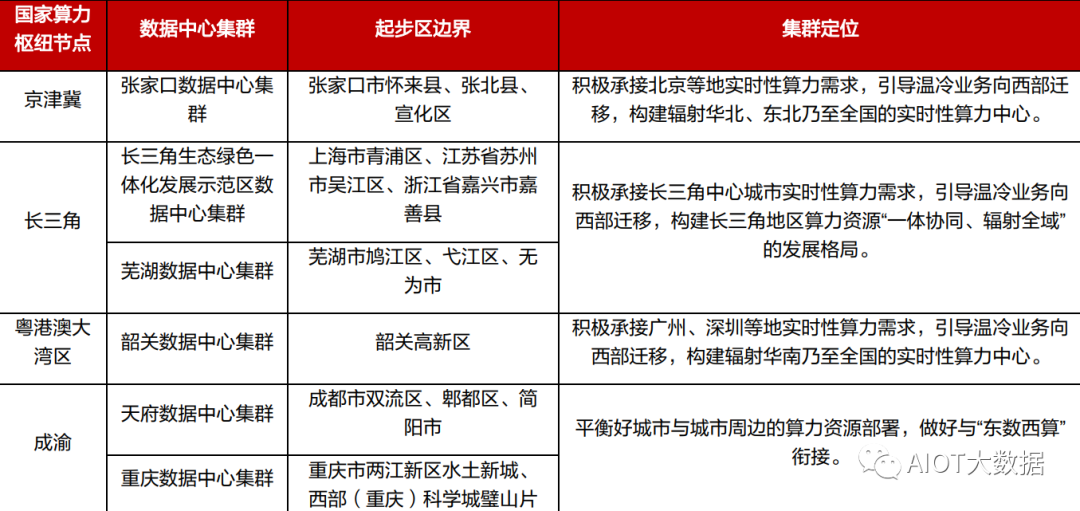
?
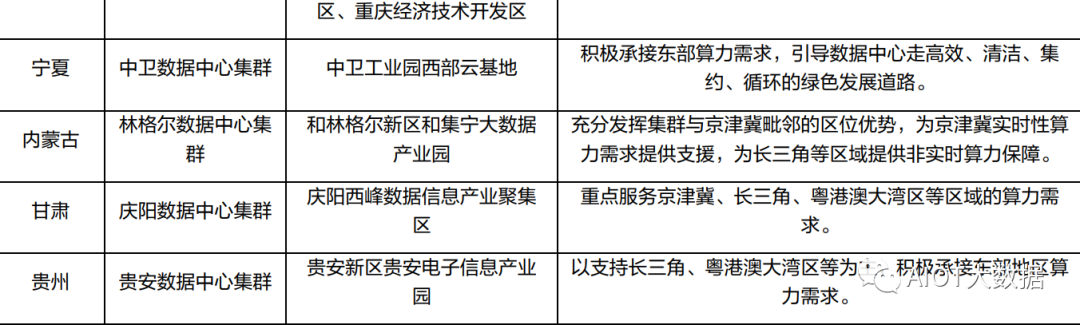
? ?
算力網(wǎng)絡(luò)的目標(biāo),實(shí)現(xiàn)算力隨取隨用。
1961 年,美國科學(xué)家約翰·麥卡錫曾提出,算力應(yīng)該像水 電資源一樣隨用隨取。以電力資源為例,電力基礎(chǔ)設(shè)施從發(fā)電、輸電、儲電、用電等各個環(huán)節(jié)全 面實(shí)現(xiàn)全局統(tǒng)一和環(huán)節(jié)解耦。發(fā)電環(huán)節(jié),不論火力發(fā)電、水力發(fā)電還是光伏發(fā)電,都通過統(tǒng)一規(guī) 格和標(biāo)準(zhǔn)接入電網(wǎng);輸電環(huán)節(jié),電網(wǎng)建設(shè)已經(jīng)實(shí)現(xiàn)大范圍覆蓋,可以實(shí)現(xiàn)分級分片的電力資源的 多級管理和統(tǒng)一調(diào)度,做到電力資源即插即用。然而類比來看,算力設(shè)施基礎(chǔ)化依然有一段路要 走。中國工程院院士、中國科學(xué)院計算技術(shù)研究所學(xué)術(shù)委員會主任孫凝暉認(rèn)為,算力設(shè)施基礎(chǔ)化 存在兩個核心問題,一是標(biāo)準(zhǔn)化、統(tǒng)一供給,二是算力使用的抽象化。算力抽象的目的是使算力 的獲取、使用更便捷更易上手,并基于抽象的生成工具、傳輸工具、消費(fèi)工具,做出豐富多樣的 各行各業(yè)應(yīng)用。算網(wǎng)之于算力基礎(chǔ)設(shè)施,就類似于電網(wǎng)之于電力基礎(chǔ)設(shè)施,是串聯(lián)起各環(huán)節(jié)的橋 梁。 ? ?
算力網(wǎng)絡(luò)分為資源層、控制層、服務(wù)層和編排管理層。
算力國際標(biāo)準(zhǔn) ITU-T Y.2501 中提出將算力 網(wǎng)絡(luò)功能架構(gòu)分成 4 大模塊:算力網(wǎng)絡(luò)資源層、算力網(wǎng)絡(luò)控制層、算力網(wǎng)絡(luò)服務(wù)層和算力網(wǎng)絡(luò)編 排管理層。其中,算網(wǎng)資源層主要提供算力資源、存儲資源和網(wǎng)絡(luò)轉(zhuǎn)發(fā)資源,并結(jié)合網(wǎng)絡(luò)中計算 處理能力和網(wǎng)絡(luò)轉(zhuǎn)發(fā)能力的實(shí)際情況,實(shí)現(xiàn)各類計算、存儲資源的傳遞和流動;算網(wǎng)控制層主要 通過網(wǎng)絡(luò)控制平面實(shí)現(xiàn)計算和網(wǎng)絡(luò)多維度資源融合的路由;算網(wǎng)服務(wù)提供層主要實(shí)現(xiàn)面向用戶的 服務(wù)、原子功能能力開放;算網(wǎng)編排管理層主要解決異構(gòu)算力資源、服務(wù)/功能資源的注冊、建模、 納管、編排、安全等問題。
編排管理(即調(diào)度)層可類比于算力網(wǎng)絡(luò)的大腦。
“算網(wǎng)大腦”即算力網(wǎng)絡(luò)中最核心的部分,主 要進(jìn)行全網(wǎng)算力資源的智能編排、彈性調(diào)度,具體而言有四個作用:
1) 獲取全域?qū)崟r的算、網(wǎng)、數(shù)資源,以及云、邊、端分布情況,構(gòu)建全域態(tài)勢感知地圖。
2) 跨域協(xié)同調(diào)度,將多域協(xié)同的調(diào)度任務(wù)智能、自動地分解給各個使能平臺,實(shí)現(xiàn)算、網(wǎng)、數(shù) 的資源調(diào)度。
3) 多域融合編排,針對多域融合業(yè)務(wù)需求,基于算、網(wǎng)、數(shù)的原子能力按需靈活組合編排。
4) 智能輔助決策,基于不同業(yè)務(wù)的 SLA 要求、網(wǎng)絡(luò)整體負(fù)載、可用算力資源池分布等因素,智 能、動態(tài)地計算出算、網(wǎng)、數(shù)的最優(yōu)協(xié)同策略。
算力調(diào)度需綜合考慮需求、成本等因素。
目前,我國東中西部數(shù)字新型基礎(chǔ)設(shè)施布局不平衡的問 題依然存在,東西部數(shù)據(jù)中心在用機(jī)架數(shù)大概比例在7:3,北上廣深等一線城市存在明顯的供不應(yīng) 求,平均缺口率達(dá) 25%,而中西部地區(qū)能源條件豐富,算力資源有一定的產(chǎn)能過剩。因此需通過 編排管理調(diào)度實(shí)現(xiàn)資源的合理分配與使用。由于平臺異構(gòu)、部署差異、網(wǎng)絡(luò)帶寬資源性價比差異等原因,算力調(diào)度存在諸多挑戰(zhàn)。除了技術(shù) 本身的挑戰(zhàn)外,還存在是否調(diào)度的問題,即資源在跨中心的流通還需考慮成本問題、代價問題以 及一些商業(yè)情況的問題。一般而言,算力調(diào)度主要針對計算、存儲、時延等要求高的場景。 ? ?
需求 1:算力。算力要求高的場景,如科學(xué)計算類和國計民生類工程項(xiàng)目,需依托超級算力 平臺來實(shí)現(xiàn)。截至 2022 年 12 月,科技部批準(zhǔn)建立了 10 家國家超級計算中心,分別位于天 津、廣州、深圳、長沙、濟(jì)南、無錫、鄭州、昆山、成都、西安。另外鵬城實(shí)驗(yàn)室、華為公 司等聯(lián)合建設(shè)了包括 20 個節(jié)點(diǎn)的中國算力網(wǎng),主打 AI 算力。從布局看,均為集中式的算力 能力庫需求。
需求 2:時延。針對普通商用、民用交互場景,時延則是關(guān)鍵因素。時延敏感型業(yè)務(wù)可分為 通信類、功能類、三維交互類。
(1)通信類:主要解決人的通信需求。一般而言,實(shí)時競 技類游戲的時延要求是 50ms;實(shí)時交互類游戲的時延要求是 100ms;實(shí)時交互語音類的時 延要求是 100ms;實(shí)時交互視頻類的時延要求是 150ms;非實(shí)時大部分互聯(lián)網(wǎng)應(yīng)用時延要 求是 300ms。
(2)功能類:主要指機(jī)器之間的通信需求,例如工業(yè)自動化控制的時延要求 是小于 10ms;遠(yuǎn)程 / 遙控駕駛的時延要求是小于 10ms。
(3)三維交互類:基于三維顯示 和交互的元宇宙應(yīng)用,為了避免頭暈,需要 10ms 以內(nèi)的交互時延。
成本:不同業(yè)務(wù)的需求決定了選擇算力、網(wǎng)絡(luò)的下限,往往對應(yīng)多種算力調(diào)度方式。最終的 算力調(diào)度方式還取決于成本,一般原則為,根據(jù)算力、時延要求,選擇最經(jīng)濟(jì)的算力網(wǎng)絡(luò)架 構(gòu)布局,來降低算力成本、網(wǎng)絡(luò)成本、運(yùn)營成本。 ? ?
據(jù)不完全統(tǒng)計,目前全國已發(fā)布或建設(shè) 10 余個算力平臺,涉及 3 個省份和 7 個城市,其中既有“東數(shù)西算”樞紐節(jié)點(diǎn),也有非樞紐節(jié)點(diǎn)參 與算力平臺建設(shè)。已經(jīng)發(fā)布算力平臺的地區(qū)有北京市、上海市、南京市、寧夏回族自治區(qū)、貴州 省、甘肅省,待發(fā)布算力平臺的地區(qū)有深圳市,正在建設(shè)算力平臺的地區(qū)有合肥市、鄭州市、慶 陽市。數(shù)據(jù)顯示,算力產(chǎn)業(yè)中每投入 1 元,平均將帶動 3-4 元的經(jīng)濟(jì)產(chǎn)出,算力指數(shù)每提高 1 個 百分點(diǎn)可帶來數(shù)字經(jīng)濟(jì) 3.3‰的增長和 GDP1.8‰的增長。
基于 GPT 4.0 模型的通信基礎(chǔ)設(shè)施需求測算
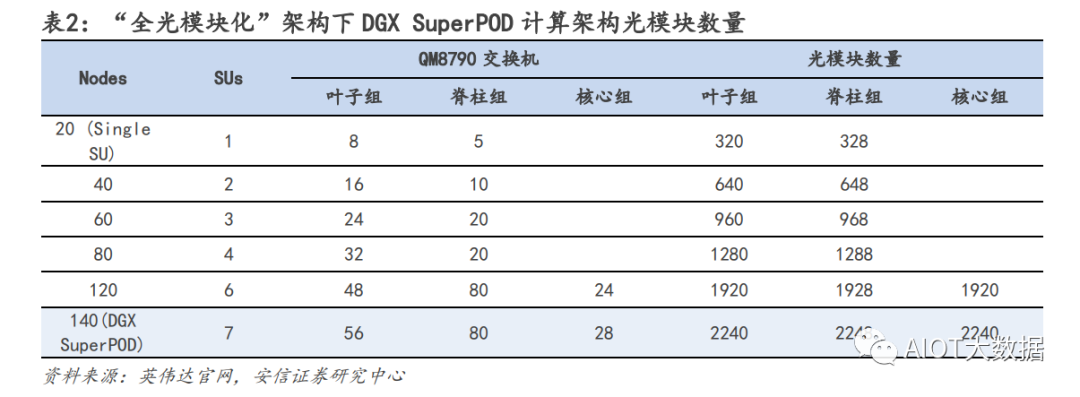
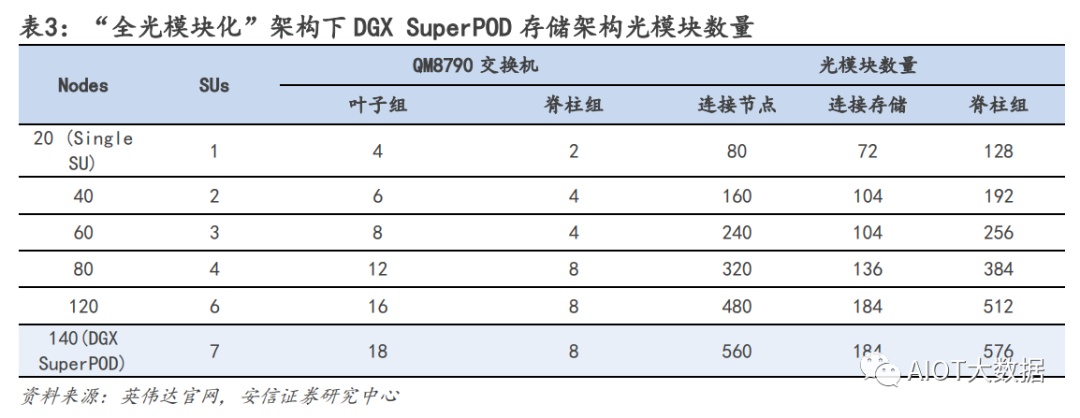
基于英偉達(dá) AI 網(wǎng)絡(luò)架構(gòu)硬件需求比例:服務(wù)器:交換機(jī):光模塊=1:1.2:11.4 由于當(dāng)前大部分 AIGC 模型都是基于英偉達(dá)方案來部署,我們從英偉達(dá)的 AI 集群模型架構(gòu)進(jìn)行拆解。對于較大的 AI 數(shù)據(jù)中心集群,一般可多達(dá)幾千臺 AI 服務(wù)器的需求,在部署方面會拆分成一個個基本單元 進(jìn)行組件,英偉達(dá)對應(yīng)的一個基本單元為 SuperPOD。根據(jù) SuperPOD 公開信息:一個標(biāo)準(zhǔn)的 SuperPOD 由 140 臺 DGX A100 GPU 服務(wù)器、HDR InfiniBand 200G 網(wǎng)卡和 170 臺 NVIDIA Quantum QM8790 交換機(jī)構(gòu)建而成,其中交換機(jī)速率為 200G,每個端口數(shù)為 40 個。
網(wǎng)絡(luò)結(jié)構(gòu)上,英偉達(dá)采用 Infinband 技術(shù)(“無限帶寬”技術(shù),簡稱 IB)和 fat tree(胖樹)網(wǎng)絡(luò)拓?fù)?結(jié)構(gòu),和傳統(tǒng)的數(shù)據(jù)中心的區(qū)別在于,在 IB fat tree 結(jié)構(gòu)下,使用的交換機(jī)數(shù)量更多,且因?yàn)槊總€節(jié)點(diǎn) 上行下行的端口數(shù)完全一致,使得該網(wǎng)絡(luò)是是無收斂帶寬的,每個端口可采用同樣速率的光模塊.
光模塊用量測算:我們從線纜角度測算光模塊需求,一個 SuperPOD 170 個交換機(jī),每個交換機(jī)有 40 個端 口,最簡單方式上下個 70 臺服務(wù)器,依次端口互聯(lián)(上下 1:1 連接)對應(yīng)的線纜需求為 40×170/2=3400 根,但是由于實(shí)際網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)交換價不是該情況,連接情況更加復(fù)雜且會分為三層結(jié)構(gòu),因此線纜數(shù)需 求有所提升,我們假設(shè)上升至 4000 根線纜需求。線纜的需求分為三種,第一種用在機(jī)柜內(nèi)部,互聯(lián)距離 5m 以內(nèi),常用需求為銅纜,不需要光模塊;第二 類互聯(lián)距離為 10m 以內(nèi),可以采用 AOC(有源光纖)連接,也不需要光模塊;第三類,帶光模塊的光纖, 單根需求為 2 個光模塊。考慮到 10m 以內(nèi)的連接占據(jù)多數(shù),我們假設(shè)銅纜:AOC:光模塊光纖比例=4:4:2. 光模塊需求=4000*0.2*2=1600 個。 ? ?
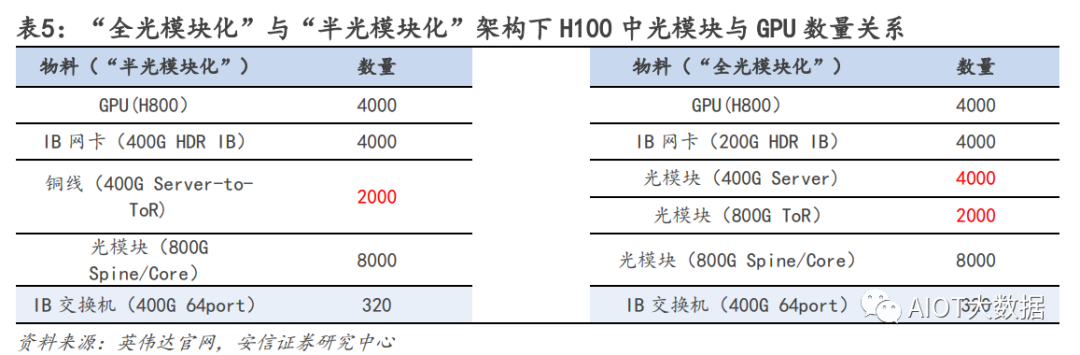
對于一個 SuperPod,服務(wù)器:交換機(jī):光模塊的用量比例=140:170:1600=1:1.2:11.4. u 應(yīng)用層面:單 GPT4.0 模型對于服務(wù)器需求用量測算 從用戶使用角度來測算,我們對于服務(wù)器算力的測算受大模型參數(shù),日活人數(shù),每日每人提問等多因素影 響。在 ChatGPT 中,一個 token 通常指的是響應(yīng)請求所需的最小文本單位,一般一個 30 詞的提問大約對應(yīng) 40 個 token,推理是 token 的算力調(diào)用是 2N。對應(yīng)模型算力的需求我們分?jǐn)傇谝惶?24h 的每一秒。

基于以下假設(shè),我們可得到對應(yīng)一個在 1 億日活的應(yīng)用需要的 AI 服務(wù)器的需求約為 1.5 萬臺。

彈性測算一:現(xiàn)有采購部署層面彈性測算(基礎(chǔ)投入維度)
角度 1 我們選擇從現(xiàn)有完成一個類似 GPT4.0 入門級別要求的需求假設(shè)去測算硬件基礎(chǔ)設(shè)施層面需求。假設(shè) 1:結(jié)合現(xiàn)有各類公開數(shù)據(jù),完成 ChatGPT4.0(訓(xùn)練+推理)需要至少 3 萬張英偉達(dá) A100 卡的算力投 入,對應(yīng) 3750 臺 A100 的 DGX 服務(wù)器。假設(shè) 2:全球假設(shè)國內(nèi)和海外有潛在 20 家公司可能按照此規(guī)模進(jìn)行測投入。假設(shè) 3:網(wǎng)絡(luò)結(jié)構(gòu)比例按照單個 SuperPOD 方式部署,即服務(wù)器:交換機(jī):光模塊的用量比例=1:1.2:11.4。假設(shè) 4:服務(wù)器價格參考英偉達(dá)價格,為 20 萬美元;交換價結(jié)合 Mellanox 售價,假設(shè)單價為 2w 美金,光 模塊根據(jù)交換機(jī)速率,現(xiàn)在主流為 200G,假設(shè)售價為 250 美金。結(jié)論:服務(wù)器、交換機(jī)、光模塊的市場彈性分別為 15%、5%、3%。 ? ?
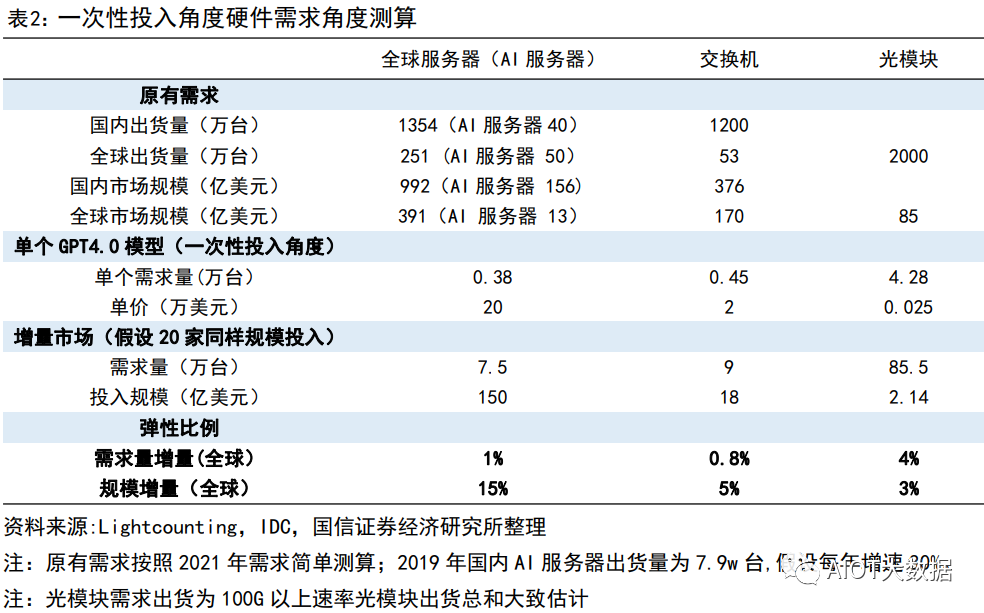
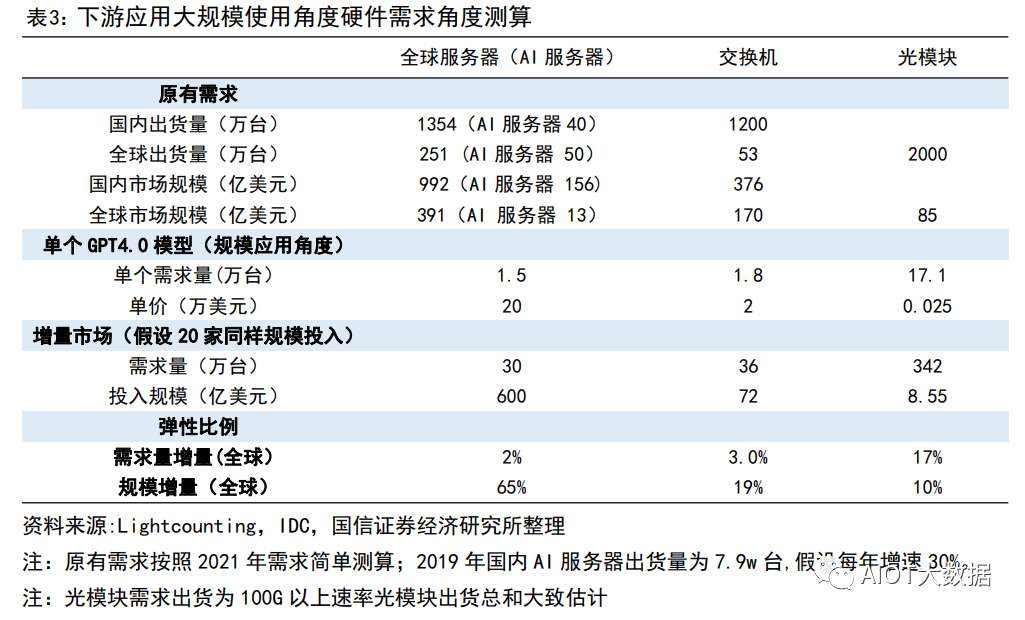
彈性測算二:下游需求億級別大規(guī)模響應(yīng)(遠(yuǎn)期應(yīng)用規(guī)模起量角度) 角度 2:基于下游應(yīng)用呈現(xiàn)規(guī)模角度,即按照單 GPT4.0 模型對于服務(wù)器需求用量測算。假設(shè) 1:單個應(yīng)用的需求角度開看,服務(wù)器潛在用量為 1.5 萬臺。假設(shè) 2:全球假設(shè)國內(nèi)和海外有潛在 20 家公司可能形成同樣類型規(guī)模應(yīng)用。假設(shè) 3:網(wǎng)絡(luò)結(jié)構(gòu)比例按照單個 SuperPOD 方式部署,即服務(wù)器:交換機(jī):光模塊的用量比例=1:1.2:11.4。假設(shè) 4:服務(wù)器價格參考英偉達(dá)價格,為 20 萬美元;交換價結(jié)合 Mellanox 售價,假設(shè)為 2.5-3w 美金,光 模塊根據(jù)交換機(jī)速率,現(xiàn)在主流為 200G,假設(shè)售價為 250 美金。結(jié)論:服務(wù)器、交換機(jī)、光模塊的市場彈性分別為 65%、19%、10%。 ? ?
?
? ?

?
服務(wù)器整體市場情況
服務(wù)器構(gòu)成:主要硬件包括處理器、內(nèi)存、芯片組、I/O (RAID卡、網(wǎng)卡、HBA卡) 、硬盤、機(jī)箱 (電源、風(fēng) 扇)。以一臺普通的服務(wù)器生產(chǎn)成本為例,CPU及芯片組大致占比50% 左右,內(nèi)存大致占比 15% 左右,外部 存儲大致占比10%左右,其他硬件占比25%左右。
服務(wù)器的邏輯架構(gòu)和普通計算機(jī)類似。但是由于需要提供高性能計算,因此在處理能力、穩(wěn)定性、可靠性、 安全性、可擴(kuò)展性、可管理性等方面要求較高。
邏輯架構(gòu)中,最重要的部分是CPU和內(nèi)存。CPU對數(shù)據(jù)進(jìn)行邏輯運(yùn)算,內(nèi)存進(jìn)行數(shù)據(jù)存儲管理。
服務(wù)器的固件主要包括BIOS或UEFI、BMC、CMOS,OS包括32位和64位。
2022年12月,Open AI的大型語言生成模型ChatGPT火熱,它能勝任刷高情商對話、生成代碼、構(gòu)思劇本 和小說等多個場景,將人機(jī)對話推向新的高度。全球各大科技企業(yè)都在積極擁抱AIGC,不斷推出相關(guān)技術(shù)、 平臺和應(yīng)用。
生成算法、預(yù)訓(xùn)練模式、多模態(tài)等AI技術(shù)累計融合,催生了AIGC的大爆發(fā)。
目前,AIGC產(chǎn)業(yè)生態(tài)體系的雛形已現(xiàn),呈現(xiàn)為上中下三層架構(gòu):①第一層為上游基礎(chǔ)層,也就是由預(yù)訓(xùn)練 模型為基礎(chǔ)搭建的AIGC技術(shù)基礎(chǔ)設(shè)施層。②第二層為中間層,即垂直化、場景化、個性化的模型和應(yīng)用工 具。③第三層為應(yīng)用層,即面向C端用戶的文字、圖片、音視頻等內(nèi)容生成服務(wù)。 ? ?
GPT模型對比BERT模型、T5模型的參數(shù)量有明顯提升。GPT-3是目前最大的知名語言模型之一,包含了 1750億(175B)個參數(shù)。在GPT-3發(fā)布之前,最大的語言模型是微軟的Turing NLG模型,大小為170 億(17B)個參數(shù)。GPT-3 的 paper 也很長,ELMO 有 15 頁,BERT 有 16 頁,GPT-2 有 24 頁,T5 有 53 頁,而 GPT-3 有 72 頁。
訓(xùn)練數(shù)據(jù)量不斷加大,對于算力資源需求提升。
回顧GPT的發(fā)展,GPT家族與BERT模型都是知名的NLP模型,都基于Transformer技術(shù)。GPT,是一種 生成式的預(yù)訓(xùn)練模型,由OpenAI團(tuán)隊(duì)最早發(fā)布于2018年,GPT-1只有12個Transformer層,而到了 GPT-3,則增加到96層。其中,GPT-1使用無監(jiān)督預(yù)訓(xùn)練與有監(jiān)督微調(diào)相結(jié)合的方式,GPT-2與GPT-3 則都是純無監(jiān)督預(yù)訓(xùn)練的方式,GPT-3相比GPT-2的進(jìn)化主要是數(shù)據(jù)量、參數(shù)量的數(shù)量級提升。
未來異構(gòu)計算或成為主流
異構(gòu)計算(Heterogeneous Computing)是指使用不同類型指令集和體系架構(gòu)的計算單元組成系統(tǒng)的計算方式,目前主 要包括GPU云服務(wù)器、FPGA云服務(wù)器和彈性加速計算實(shí)例EAIS等。讓最適合的專用硬件去服務(wù)最適合的業(yè)務(wù)場景。
在CPU+GPU的異構(gòu)計算架構(gòu)中,GPU與CPU通過PCle總線連接協(xié)同工作,CPU所在位置稱為主機(jī)端 (host),而GPU所在 位置稱為設(shè)備端(device)。基于CPU+GPU的異構(gòu)計算平臺可以優(yōu)勢互補(bǔ),CPU負(fù)責(zé)處理邏輯復(fù)雜的串行程序,而GPU重 點(diǎn)處理數(shù)據(jù)密集型的并行計算程序,從而發(fā)揮最大功效。
越來越多的AI計算都采用異構(gòu)計算來實(shí)現(xiàn)性能加速。 ? ?
阿里第一代計算型GPU實(shí)例,2017年對外發(fā)布GN4,搭載Nvidia M40加速器.,在萬兆網(wǎng)絡(luò)下面向人工智能深度學(xué)習(xí)場 景,相比同時代的CPU服務(wù)器性能有近7倍的提升。
CPU 適用于一系列廣泛的工作負(fù)載,特別是那些對于延遲和單位內(nèi)核性能要求較高的工作負(fù)載。作為強(qiáng)大的執(zhí)行引擎, CPU 將它數(shù)量相對較少的內(nèi)核集中用于處理單個任務(wù),并快速將其完成。這使它尤其適合用于處理從串行計算到數(shù)據(jù) 庫運(yùn)行等類型的工作。
GPU 最初是作為專門用于加速特定 3D 渲染任務(wù)的 ASIC 開發(fā)而成的。隨著時間的推移,這些功能固定的引擎變得更加 可編程化、更加靈活。盡管圖形處理和當(dāng)下視覺效果越來越真實(shí)的頂級游戲仍是 GPU 的主要功能,但同時,它也已經(jīng) 演化為用途更普遍的并行處理器,能夠處理越來越多的應(yīng)用程序。
訓(xùn)練和推理過程所處理的數(shù)據(jù)量不同。
在AI實(shí)現(xiàn)的過程中,訓(xùn)練(Training)和推理(Inference)是必不可少的,其中的區(qū)別在于:
訓(xùn)練過程:又稱學(xué)習(xí)過程,是指通過大數(shù)據(jù)訓(xùn)練出一個復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,通過大量數(shù)據(jù)的訓(xùn)練確定網(wǎng)絡(luò)中權(quán)重和 偏置的值,使其能夠適應(yīng)特定的功能。
推理過程:又稱判斷過程,是指利用訓(xùn)練好的模型,使用新數(shù)據(jù)推理出各種結(jié)論。
簡單理解,我們學(xué)習(xí)知識的過程類似于訓(xùn)練,為了掌握大量的知識,必須讀大量的書、專心聽老師講解,課后還要做 大量的習(xí)題鞏固自己對知識的理解,并通過考試來驗(yàn)證學(xué)習(xí)的結(jié)果。分?jǐn)?shù)不同就是學(xué)習(xí)效果的差別,如果考試沒通過 則需要繼續(xù)重新學(xué)習(xí),不斷提升對知識的掌握程度。而推理,則是應(yīng)用所學(xué)的知識進(jìn)行判斷,比如診斷病人時候應(yīng)用 所學(xué)習(xí)的醫(yī)學(xué)知識進(jìn)行判斷,做“推理”從而判斷出病因。 ? ?
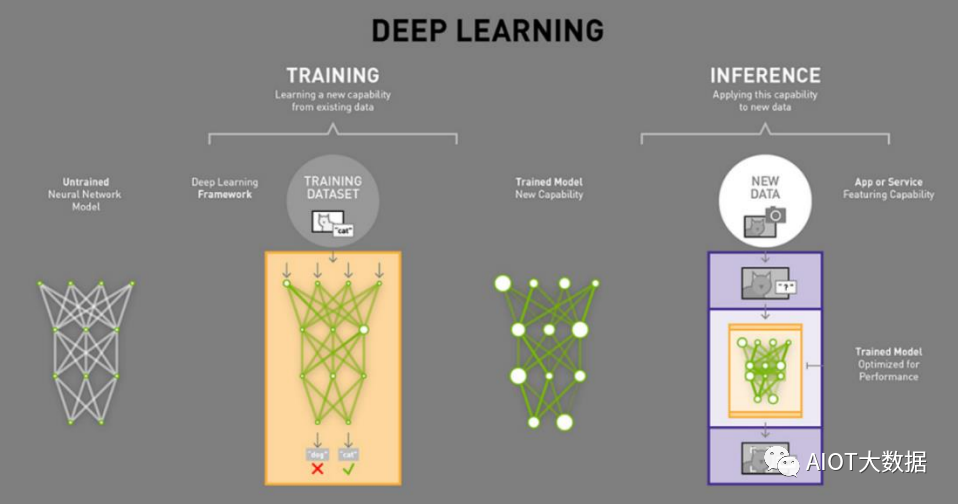
訓(xùn)練需要密集的計算,通過神經(jīng)網(wǎng)絡(luò)算出結(jié)果后,如果發(fā)現(xiàn)錯誤或未達(dá)到預(yù)期,這時這個錯誤會通過網(wǎng)絡(luò) 層反向傳播回來,該網(wǎng)絡(luò)需要嘗試做出新的推測,在每一次嘗試中,它都要調(diào)整大量的參數(shù),還必須兼顧 其它屬性。再次做出推測后再次校驗(yàn),通過一次又一次循環(huán)往返,直到其得到“最優(yōu)”的權(quán)重配置,達(dá)成 預(yù)期的正確答案。如今,神經(jīng)網(wǎng)絡(luò)復(fù)雜度越來越高,一個網(wǎng)絡(luò)的參數(shù)可以達(dá)到百萬級以上,因此每一次調(diào) 整都需要進(jìn)行大量的計算。吳恩達(dá)(曾在谷歌和百度任職)舉例“訓(xùn)練一個百度的漢語語音識別模型不僅 需要4TB的訓(xùn)練數(shù)據(jù),而且在整個訓(xùn)練周期中還需要20 exaflops(百億億次浮點(diǎn)運(yùn)算)的算力”,訓(xùn)練是 一個消耗巨量算力的怪獸。
推理是利用訓(xùn)練好的模型,使用新數(shù)據(jù)推理出各種結(jié)論,它是借助神經(jīng)網(wǎng)絡(luò)模型進(jìn)行運(yùn)算,利用輸入的新 數(shù)據(jù)“一次性”獲得正確結(jié)論的過程,他不需要和訓(xùn)練一樣需要循環(huán)往復(fù)的調(diào)整參數(shù),因此對算力的需求 也會低很多。
此外,訓(xùn)練和推理過程中,芯片的部署位置、準(zhǔn)確度/精度要求、存 儲要求等都有所不同。
訓(xùn)練和推理所應(yīng)用的GPU/服務(wù)器也有不同。
推理常用:NVIDIA T4 GPU 為不同的云端工作負(fù)載提供加速,其 中包括高性能計算、深度學(xué)習(xí)訓(xùn)練和推理、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析和 圖形學(xué)。引入革命性的 Turing Tensor Core 技術(shù),使用多精度計算 應(yīng)對不同的工作負(fù)載。從 FP32 到 FP16,再到 INT8 和 INT4 的精 度,T4 的性能比 CPU 高出 40 倍,實(shí)現(xiàn)了性能的重大突破。 ? ?
訓(xùn)練:A100和H100。對于具有龐大數(shù)據(jù)表的超大型模型,A100 80GB 可為每個節(jié)點(diǎn)提供高達(dá) 1.3TB 的統(tǒng)一顯存,而且吞吐量比 A100 40GB 多高達(dá) 3 倍。在 BERT 等先進(jìn)的對話式 AI 模型上, A100 可將推理吞吐量提升到高達(dá) CPU 的 249 倍。
根據(jù)OpenAI在2020年發(fā)表的論文,訓(xùn)練階段算力需求與模型參數(shù)數(shù)量、訓(xùn)練數(shù)據(jù)集規(guī)模等有關(guān),且為兩者乘積的 6倍:訓(xùn)練階段算力需求=6×模型參數(shù)數(shù)量×訓(xùn)練集規(guī)模。
GPT-3模型參數(shù)約1750億個,預(yù)訓(xùn)練數(shù)據(jù)量為45 TB,折合成訓(xùn)練集約為3000億tokens。即訓(xùn)練階段算力需求 =6×1.75×1011×3×1011=3.15×1023 FLOPS=3.15×108 PFLOPS
依據(jù)谷歌論文,OpenAI公司訓(xùn)練GPT-3采用英偉達(dá)V100 GPU,有效算力比率為21.3%。GPT-3的實(shí)際算力需求應(yīng) 為1.48×109 PFLOPS(17117 PFLOPS-day)。
假設(shè)應(yīng)用A100 640GB服務(wù)器進(jìn)行訓(xùn)練,該服務(wù)器AI算力性能為5 PFLOPS,最大功率為6.5 kw,則我們測算訓(xùn)練 階段需要服務(wù)器數(shù)量=訓(xùn)練階段算力需求÷服務(wù)器AI算力性能=2.96×108臺(同時工作1秒),即3423臺服務(wù)器工 作1日。

H100性能更強(qiáng),與上一代產(chǎn)品相比,H100 的綜合技術(shù)創(chuàng)新可以將大型語言模型的速度提高 30 倍。根據(jù)Nvidia測 試結(jié)果,H100針對大型模型提供高達(dá) 9 倍的 AI 訓(xùn)練速度,超大模型的 AI 推理性能提升高達(dá) 30 倍。 ? ?
在數(shù)據(jù)中心級部署 H100 GPU 可提供出色的性能,并使所有研究人員均能輕松使用新一代百億億次級 (Exascale) 高性能計算 (HPC) 和萬億參數(shù)的 AI。
H100 還采用 DPX 指令,其性能比 NVIDIA A100 Tensor Core GPU 高 7 倍,在動態(tài)編程算法(例如,用于 DNA 序列比對 Smith-Waterman)上比僅使用傳統(tǒng)雙路 CPU 的服務(wù)器快 40 倍。
假設(shè)應(yīng)用H100服務(wù)器進(jìn)行訓(xùn)練,該服務(wù)器AI算力性能為32 PFLOPS,最大功率為10.2 kw,則我們測算訓(xùn)練階段需 要服務(wù)器數(shù)量=訓(xùn)練階段算力需求÷服務(wù)器AI算力性能=4.625×107臺(同時工作1秒),即535臺服務(wù)器工作1日。
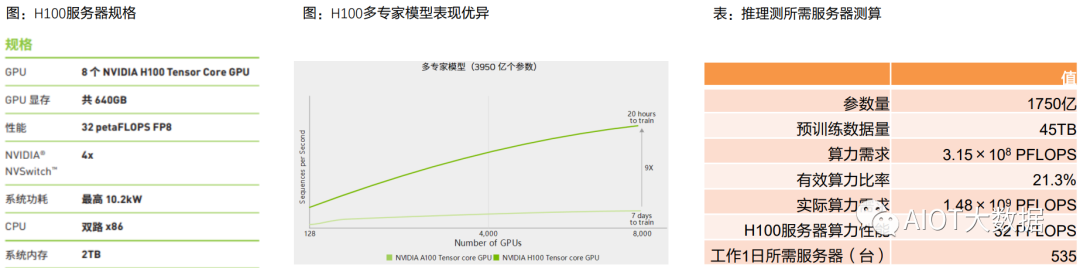
根據(jù)天翼智庫,GPT-3模型參數(shù)約1750億個,預(yù)訓(xùn)練數(shù)據(jù)量為45 TB,折合成訓(xùn)練集約為3000億tokens。按照有 效算力比率21.3%來計算,訓(xùn)練階段實(shí)際算力需求為1.48×109 PFLOPS。
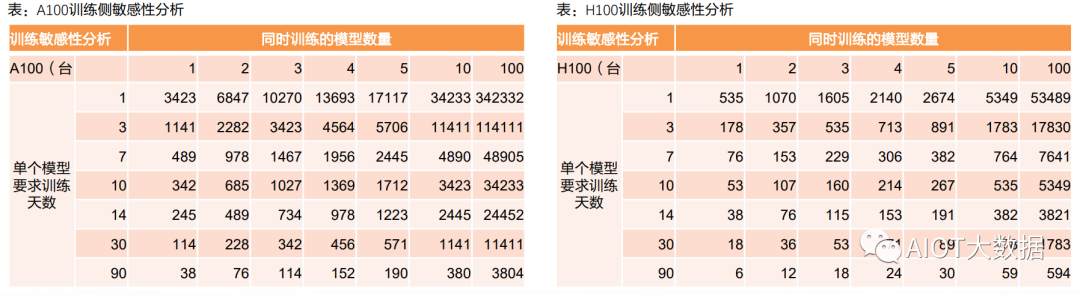
對AI服務(wù)器訓(xùn)練階段需求進(jìn)行敏感性分析,兩個變化參數(shù):①同時并行訓(xùn)練的大模型數(shù)量、②單個模型要求訓(xùn)練完 成的時間。
按照A100服務(wù)器5 PFLOPs,H100服務(wù)器32 PFLOPs來進(jìn)行計算。
若不同廠商需要訓(xùn)練10個大模型,1天內(nèi)完成,則需要A100服務(wù)器34233臺,需要H100服務(wù)器5349臺。
此外,若后續(xù)GPT模型參數(shù)迭代向上提升(GPT-4參數(shù)量可能對比GPT-3倍數(shù)級增長),則我們測算所需AI服務(wù) 器數(shù)量進(jìn)一步增長。 ? ?
AI服務(wù)器產(chǎn)業(yè)鏈
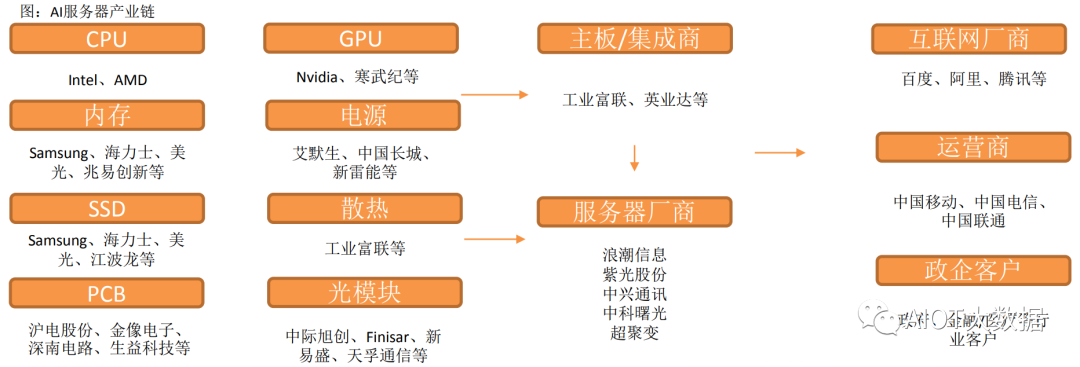
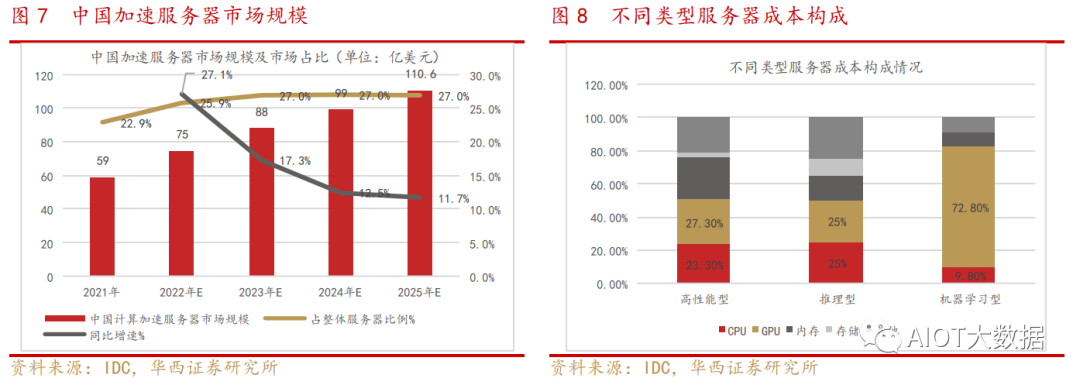
AI服務(wù)器核心組件包括GPU(圖形處理器)、DRAM(動態(tài)隨機(jī)存取存儲器)、SSD(固態(tài)硬盤)和 RAID卡、CPU(中央處理器)、網(wǎng)卡、PCB、高速互聯(lián)芯片(板內(nèi))和散熱模組等。
CPU主要供貨廠商為Intel、GPU目前領(lǐng)先廠商為國際巨頭英偉達(dá),以及國內(nèi)廠商如寒武紀(jì)、海光信息等。
內(nèi)存主要為三星、美光、海力士等廠商,國內(nèi)包括兆易創(chuàng)新等。
SSD廠商包括三星、美光、海力士等,以及國內(nèi)江波龍等廠商。
PCB廠商海外主要包括金像電子,國內(nèi)包括滬電股份、鵬鼎控股等。
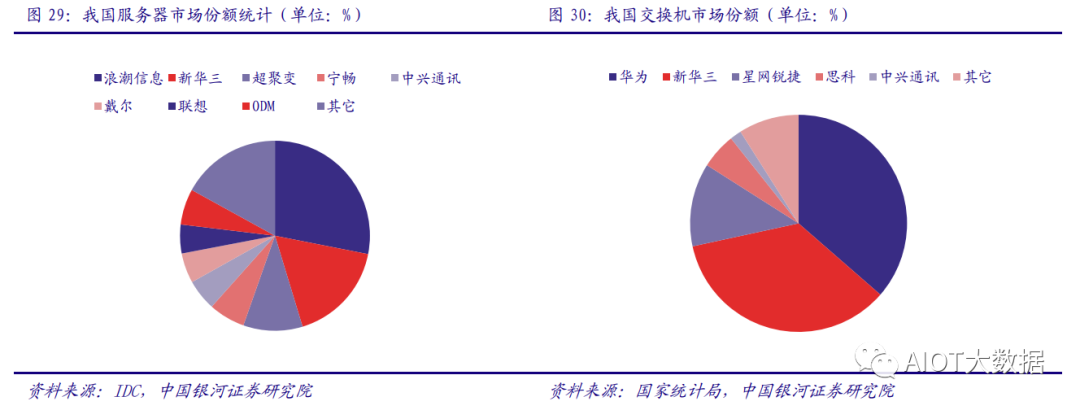
主板廠商包括工業(yè)富聯(lián),服務(wù)器品牌廠商包括浪潮信息、紫光股份、中科曙光、中興通訊等。
? ?
?
? ?
審核編輯:黃飛
?





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論