的支持。蓬勃發展的大模型應用所帶來的特殊性需求,正推動芯片設計行業邁向新紀元。眾多頂級的半導體廠商紛紛為大模型應用而專門構建 AI 芯片,其高算力、高帶寬、動輒千億的晶體管數量成為大芯片的標配。 芯片設計復雜度,邁向新高峰 在人工
2023-08-15 11:02:11 836
836 
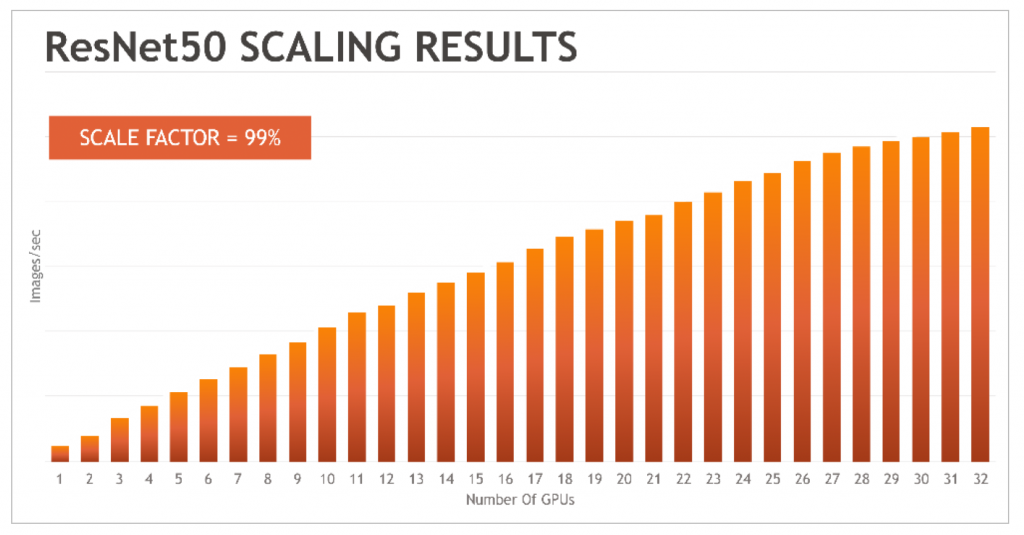
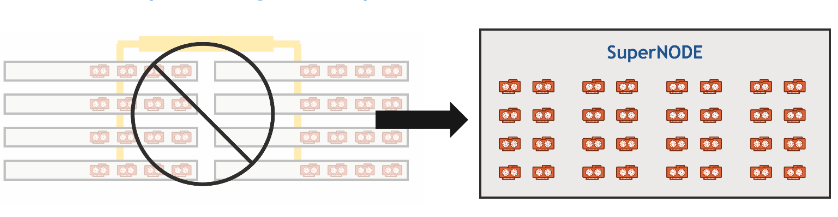
? 流行的GPU/TPU集群網絡組網,包括:NVLink、InfiniBand、ROCE以太網Fabric、DDC網絡方案等,深入了解它們之間的連接方式以及如何在LLM訓練中發揮作用。為了獲得良好的訓練性能,GPU網絡需要滿足以下條件。
2023-12-25 10:11:431377 
NVIDIA與Arm、Ampere、Cray、富士通、HPE、Marvell攜手構建GPU加速服務器,以滿足從超大規模云到邊緣、從模擬到AI、從高性能存儲到百萬兆級超級計算等多樣化需求。
2019-11-20 09:38:421384 NVIDIA NeMo Megatron 框架; 可定制的大規模語言模型 Megatron 530B;多GPU、多節點 Triton推理服務器助力基于語言的AI開發和部署,推動行業和科學發展。
2021-11-10 14:22:52752 而言,核心三要素是算法、數據和算力,其中算力是底座。 ?對于算力而言,目前行業基本的共識是基于通用GPU來構建AI大模型的算力集群,上海天數智芯半導體有限公司(以下簡稱:天數智芯)是目前國內第一家實現通用GPU量產并落地的公司。在WAIC上,天數
2023-07-11 01:07:002462 
1 個 AI 模型 = 5 輛汽車終身碳排量,AI 為何如此耗能?
2021-01-22 06:35:03
摘要: 3月28日,在2018云棲大會·深圳峰會上,阿里云宣布與英偉達GPU 云 合作 (NGC),開發者可以在云市場下載NVIDIA GPU 云鏡像和運行NGC 容器,來使用阿里云上的NVIDIA
2018-04-04 14:39:24
AI算法中比較常用的模型都有什么
2022-08-27 09:19:06
雖然GPU解決方案對訓練,AI部署需要更多。
預計到2020年代中期,人工智能行業將增長到200億美元,其中大部分增長是人工智能推理。英特爾Xeon可擴展處理器約占運行AI推理的處理器單元的70
2023-08-04 07:25:00
在 CPU 和 GPU 上推斷出具有 OpenVINO? 基準的相同模型:
benchmark_app.exe -m model.xml -d CPU
benchmark_app.exe -m
2023-08-15 06:43:46
GPU來完成。但GPU于手機及PC端滲透率基本見頂,根據中國社科院數據,2011-2018年全球主要國家PC每百人滲透率呈下降趨勢,智能手機對PC具有一定替代性。而云計算與智能駕駛及AI的興起對高算力
2021-12-07 10:04:11
GPU編程--OpenCL四大模型
2019-04-29 07:40:44
ai芯片和gpu的區別▌車載芯片的發展趨勢(CPU-GPU-FPGA-ASIC)過去汽車電子芯片以與傳感器一一對應的電子控制單元(ECU)為主,主要分布與發動機等核心部件上。...
2021-07-27 07:29:46
集群通信網絡是什么?數字集群移動通信網絡是如何運行的?
2021-05-26 06:27:08
上漲,因為事實表明,它們的 GPU 在訓練和運行 深度學習模型 方面效果明顯。實際上,英偉達也已經對自己的業務進行了轉型,之前它是一家純粹做 GPU 和游戲的公司,現在除了作為一家云 GPU 服務
2024-03-21 15:19:45
服務器,而隨著人們對服務器工作負載模式的新需求,越來越多的智能場景需要小型服務器來部署。方案簡介集群服務器解決方案,以多塊核心板的組合方式,提供標準的軟硬件接口,支持分布式AI運算,可用于機器學習
2019-08-16 15:09:56
Imagination全新BXS GPU助力德州儀器汽車處理器系列產品實現先進圖形處理功能
2020-12-16 07:04:43
Mali GPU 支持tensorflow或者caffe等深度學習模型嗎? 好像caffe2go和tensorflow lit可以部署到ARM,但不知道是否支持在GPU運行?我希望把訓練
2022-09-16 14:13:01
的任務中,比如運行用于語言翻譯的GNMT模型等。功能豐富、應用廣泛的NVIDIA T4Tensor Core GPU 在多個場景取得了優秀的成績。這個功耗僅為70瓦的GPU能夠輕松安裝到任何帶有PCIe槽
2019-11-08 19:44:51
的模型在微控制器上平穩運行。這使我們能夠保持競爭力,并為客戶提供最佳解決方案。“多虧了 STM32Cube.AI 開發人員云,我們可以在很短的時間內確認我們創建具有嵌入式AI的產品的方法的有效性。通過
2023-02-02 09:52:43
層多活解決方案。DRDS按照之前說的業務數據拆分的維度,阿里云DRDS有兩種集群分別支持買家維度與賣家維度:unit 模式的DRDS集群:多地用戶分別在本地域讀寫本地域的數據,且本地域的數據會和中心數據做雙向同步。copy 模式的DRDS集群:此集群數據在中心數據庫寫,完成后全.
2021-11-16 09:23:44
模型收斂的情況下,最大集群規模只支持10塊GPU。這意味著在進行數據運算時,即時使用更多的GPU,計算效果也只相當于10塊GPU的能力,這樣訓練的時間將更加的漫長。 而華為云的深度學習
2018-08-02 20:44:09
Vitis AI 的所有工具和庫,而不需要在本地安裝任何依賴。CPU版本的Vitis AI docker 可以在沒有 GPU 的機器上運行,但是模型優化的速度會比 GPU 版本慢一些。
實際上,我會選擇通過
2023-10-14 15:34:26
,本周將會推出針對異構計算GPU實例GN5年付5折的優惠活動,希望能夠打造良好的AI生態環境,幫助更多的人工智能企業以及項目順利上云。隨著深度學習對人工智能的巨大推動,深度學習所構建的多層神經網絡模型
2017-12-26 11:22:09
華為云華為云IoT,致力于提供極簡接入、智能化、安全可信等全棧全場景服務和開發、集成、托管、運營等一站式工具服務,助力合作伙伴/客戶輕松、快速地構建5G、AI萬物互聯的場景化物聯網解決方案,包括實現設備的統一接入和管理;處理和分析物聯網數據,實現數據快速變現等
2022-12-12 10:35:23
介紹在STM32cubeIDE上部署AI模型的系列教程,開發板型號STM32H747I-disco,值得一看。MCUAI原文鏈接:【嵌入式AI開發】篇四|部署篇:STM32cubeIDE上部署神經網絡之模型部署
2021-12-14 09:05:03
使用cube-AI分析模型時報錯,該模型是pytorch的cnn轉化成onnx
```
Neural Network Tools for STM32AI v1.7.0 (STM.ai v8.0.0-19389)
INTERNAL ERROR: list index out of range
```
2024-03-14 07:09:26
是否可以使用NVidia虛擬化在云計算中使用GPU虛擬化創建VM群集?怎么能實現呢?以上來自于谷歌翻譯以下為原文Is it possible to use NVidia virtualization
2018-09-30 10:47:56
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,沒有問題,過一會再訓練出現非常卡頓,使用nvidia-smi查看發現,顯示GPU的風扇和電源報錯:解決方案自動風扇控制在nvidia
2022-01-03 08:24:09
你好, 我試圖在 X-CUBE-AI.7.1.0 中導入由在線 AI 平臺生成的 .h5 模型,收到錯誤:E010(InvalidModelError): Model saved with Keras 2.7.0 but
2022-12-27 06:10:35
的定義和訓練的收斂趨勢。總結我們可以利用阿里云Kubernetes容器服務,輕松的搭建在云端搭建TensorFlow的環境,運行深度學習的實驗室,并且利用TensorBoard追蹤訓練效果。歡迎大家使用阿里云上的GPU容器服務,在使用GPU高效計算的能力同時,比較簡單和快速的開始模型開發工作。原文鏈接
2018-05-10 10:24:11
當我為 TFLite 模型運行基準測試時,有一個選項 --nnapi=true我如何知道 GPU 和 NPU 何時進行推理?謝謝
2023-03-20 06:10:30
在即將開展的“中國移動全球合作伙伴大會”上,華為將發布一款面向運營商電信領域的一站式AI開發平臺——SoftCOM AI平臺,幫助電信領域開發者解決AI開發在數據準備、模型訓練、模型發布以及部署驗證
2021-02-25 06:53:41
的時間線(右)默認情況下,所有 ML-Agents 模型都使用 Barracuda 執行。Barracuda包是 Unity的跨平臺 NN 推理庫。它可以在 GPU 和 CPU 上運行 NN 模型。但
2022-08-15 15:43:38
+ OSS on ACK,允許Spark分布式計算節點對阿里云OSS對象存儲的直接訪問。容器開啟數據服務之旅系列(二):Kubernetes如何助力Spark大數據分析(二):Kubernetes
2018-04-17 15:10:33
和模型編譯成與浪潮深度學習加速解決方案的配置腳本,即可進行線上應用,省去至少3個月到半年的開發周期和相關成本。并且在算法運行效率上,浪潮FPGA加速方案相比CPU、GPU都有著很大優勢。 目前,浪潮
2021-09-17 17:08:32
AI設計主要參與方都是功能強大的CPU,GPU和FPGA等。微型微控制器與強大的人工智能(AI)世界有什么關系?但隨著AI從云到邊緣的發展,使得這一觀點正在迅速改變,AI計算引擎使MCU能夠突破
2021-11-01 08:55:02
躺在實驗機器上在現有條件下,一般涉及到模型的部署就要涉及到模型的轉換,而轉換的過程也是隨著對應平臺的不同而不同,一般工程師接觸到的平臺分為GPU云平臺、手機和其
2021-07-16 06:08:20
在計算棒上,計算棒是一個專用AI應用模塊;Toybrick 1808計算棒提供全套模型保護方案加解密過程均運行中TrustZone安全環境中,無法跟蹤讓您的模型在計算棒上不用擔心被盜走,每顆計算棒上
2020-07-24 10:58:40
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-10 06:33:37
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-09 07:57:45
雖然人工智能和機器學習計算通常在數據中心中大規模地執行,但是最新的處理設備使得能夠將AI / ML能力嵌入到網絡邊緣的IoT設備中。邊緣的AI可以快速響應,無需等待云的響應。如果可以在本地完成推理
2019-05-29 10:38:09
將AI推向邊緣的影響通過在邊緣運行ML模型可以使哪些具體的AI項目更容易運行?
2021-02-23 06:21:10
萌新求助,求云模型及發生器matlab代碼
2021-11-19 07:11:38
摘要: 阿里云ECS彈性裸金屬服務器(神龍)已經與其容器服務全面兼容,用戶可以選擇在彈性裸金屬服務器上直接運行容器、管控Kubernetes/Docker容器集群,如此將會獲得非常出色的性能、數倍
2018-06-13 15:52:15
訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
Mali T604 GPU的結構是由哪些部分組成的?Mali T604 GPU的編程特性有哪些?Mali GPU的并行化計算模型是怎樣構建的?基于Mali-T604 GPU的快速浮點矩陣乘法并行化該如何去實現?
2021-04-19 08:06:26
使用 STM32Cube.AI 的模型轉換工具,獲得一個集成了 AI 的 BSP對,就是這么硬核,一步肝到位!內部的流程請看源碼或者 plugin_stm32 倉庫下的 readme 文檔運行命令進入
2022-09-02 15:06:14
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-08 06:28:56
模型并為其提供了輸入數據。最后,我運行了模型的推理,并輸出了預測結果。此外,還需要考慮其他因素,如模型的優化器、損失函數和評估指標等。
為了防止AI大模型被黑客病毒入侵控制,通常可以采取以下措施
2024-03-19 11:18:16
。 對于世界杯這種超大觀看量級、超強影響力的重要體育賽事,阿里云一直致力研究的AI技術一定不會缺席。本屆世界杯互聯網直播的順利進行,離不開各大云計算廠商的支持。在這其中,阿里云是當之無愧的“C位“,除了
2018-07-12 15:12:13
拷貝多份占用存儲空間,也給網絡管理和數據管理帶來了復雜性;并且由于數據無法共享,無法支持整個GPU集群同時運行任務,降低了整個IT系統的使用效率。為了便于數據管理和共享,傳統文件存儲在AI系統中得到一定
2018-08-23 17:39:35
群擴容和縮容。同云桌面/GPU服務器的結合 一般在仿真工作流里面,完成大量的仿真計算后會進入到渲染階段,所以一般會經過GPU服務器集群的Pipeline,最后通過云桌面展示給客戶的客戶。于是E-HPC
2018-05-18 22:19:53
作業在上汽仿真計算云平臺上完成,模擬了整車、發動機數百種工況。由于阿里云超級計算集群帶來的性能提升,相對本地集群節約了計算求解時間,用戶作業排隊時間也明顯縮短,工程師可以在工作時間段做更多的模型調整
2018-05-31 15:30:30
摘要: kubernetes集群讓您能夠方便的部署管理運維容器化的應用。但是實際情況中經常遇到的一些問題,就是單個集群通常無法跨單個云廠商的多個Region,更不用說支持跨跨域不同的云廠商。這樣會給
2018-03-12 17:10:52
,Hovorod等多種深度學習框架,CPU、GPU、FPGA等異構計算集群可以統一管理調度和高效運行,如此實現模型持續訓練和迭代上線,從而降低開發AI應用服務的門檻,大大提升AI落地的效率。未來阿里云將在
2018-07-02 15:27:20
智行,裝車量已突破60萬輛。未來雙方也將繼續深入合作,從端到云全面拓展合作。上汽仿真計算云 基于ECS神龍SCC超級計算集群+E-HPC彈性高性能計算產品,讓客戶在阿里云端打造了一個媲美物理機集群性能,同時兼具與HPC業務部署靈活性和彈性的高性能云端計算服務平臺,助力智能制造行業客戶上云。原文鏈接
2018-06-19 16:04:24
摘要: 近日,阿里云重磅推出視頻點播新功能——視頻AI ,基于深度學習、計算機視覺技術和海量數據,為廣大用戶提供多場景的視頻AI服務。近日,阿里云重磅推出視頻點播新功能——視頻AI,基于深度學習
2018-01-23 15:19:23
提出一種適用于SMP 集群的混合MPI+OpenMP 并行編程模型。該模型貼近于SMP 集群的體系結構且綜合了消息傳遞和共享內存2 種編程模型的優勢,能獲得較好的性能。討論該混合模型的實
2009-03-30 09:28:40 32
32 GPU將開創計算新紀元
魏鳴,是NVIDIA公司中國區市場總監。
美國著名計算機科學家、田納西州大學計算機創新實驗室主任Jack Dongarra博士曾經說過,將來的計算
2009-12-30 10:17:391221 研究如何使用Jini 來實現集群網格計算環境,給出系統模型JCGE(a Jini-based cluster grid environment),設計一個在此模型上進行并行計算的通用算法,并在集群主機上對此模型及算法進行測試,
2011-05-14 11:05:4517 作為NVIDIA在中國重要的合作伙伴,阿里巴巴正在將GPU大規模的應用于諸多業務的AI推理應用中,借助GPU帶來的強大算力為AI應用賦能,助力多個業務實現突破。
2018-10-04 08:41:003066 亞馬遜宣布推出Inferentia,這是由AWS設計的芯片,專門用于部署帶有GPU的大型AI模型,該芯片將于明年推出。
2018-12-03 09:46:081753 然而,如果攻擊者在使用AI模型時也“以管理員身份運行”,給AI模型埋藏一個“后門”,平時程序運行正常,然而一旦被激活,模型輸出就會變成攻擊者預先設置的目標。
2020-08-23 09:47:391412 研究的熱點之一。 本篇文章希望能提供一個對GPU共享工作的分享,希望能和相關領域的研究者們共同討論。 GPU共享,是指在同一張GPU卡上同時運行多個任務。優勢在于: (1)集群中可以運行更多任務,減少搶占。 (2)資源利用率(GPU/顯存/e.t.c.)提高;GPU共享后,總利用率接近運行任務利
2020-11-27 10:06:213271 NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力
2021-10-20 09:25:432078 基于京東部署的DGX SuperPOD集群 “天琴α”,京東探索研究院聯合悉尼大學共同研發了織女模型,一并攻克了 GLUE 兩項挑戰性任務。
2022-01-04 14:22:553380 Meta的AI超級計算機是迄今為止最大的NVIDIA DGX A100客戶系統。該系統將為Meta的AI研究人員提供5百億億次級AI計算性能,采用了最先進的NVIDIA系統、InfiniBand網絡和軟件,實現了數千個GPU集群的系統優化。
2022-02-07 10:40:561621 Microsoft 的目標是,通過結合使用 Azure 與 NVIDIA GPU 和 Triton 推理軟件,率先將一系列強大的 AI Transformer 模型投入生產用途。
2022-03-28 09:43:381029 近期,該團隊在 GPU 助力的服務器上測試了適用于 Apache Spark 的 NVIDIA RAPIDS 加速器,該軟件可將工作分配到集群中的各節點。
2022-04-01 14:15:03890 “強悍的織女模型在京東探索研究院建設的全國首個基于 DGX SuperPOD 架構的超大規模計算集群 “天琴α” 上完成訓練,該集群具有全球領先的大規模分布式并行訓練技術,其近似線性加速比的數據、模型、流水線并行技術持續助力織女模型的高效訓練。”
2022-04-13 15:13:11783 經過百度內部 NLP 研究團隊的驗證,在這個網絡環境下的超大規模集群上提交千億模型訓練作業時,同等機器規模下整體訓練效率是普通 GPU 集群的 3.87 倍。
2022-05-20 15:00:27953 通過 NVIDIA GPU 加速平臺,Colossal-AI 實現了通過高效多維并行、異構內存管理、大規模優化庫、自適應任務調度等方式,更高效快速部署 AI 大模型訓練與推理。
2022-10-19 09:39:391149 近日,天數智芯通用GPU產品“天垓100”與計圖即時編譯深度學習框架完成兼容性適配認證,同時支持加速深度學習模型的訓練和推理,支持運行多種前沿AI應用,進一步助力國產AI生態發展。
2022-12-23 09:35:33684 第七屆集微半導體峰會于6月初在廈門成功舉辦,上海天數智芯半導體有限公司(以下簡稱“天數智芯”)產品線總裁鄒翾受邀參加“集微通用芯片行業應用峰會”,發表了題為“國產GPU助力大模型的實踐”的主題演講
2023-06-08 22:55:02952 
專為生成式AI設計的GPU:HBM密度是英偉達H100的2.4倍,帶寬是英偉達H100的1.6倍。
2023-06-20 10:47:47605 據悉,SDXL 0.9是在所有開源圖像模型中參數數量位居前茅,并且可以在消費級GPU上運行,還具備一個35億參數的基礎模型和一個66億參數的附加模型。
2023-06-26 09:41:49720 6 月 27 日上午1000,電子工程專輯【EE直播間】最新一期即將開播! 本期直播將圍繞“GPU助力數據中心高性能計算和AI大模型的開發”為主題,由 AspenCore 產業分析師為大家介紹
2023-06-26 11:20:02337 
據了解,星脈網絡具備業界最高的 3.2T 通信帶寬,可提升 40% 的 GPU 利用率、節省 30%~60% 的模型訓練成本,進而能為 AI 大模型帶來 10 倍通信性能提升。基于騰訊云新一代算力集群,可支持 10 萬卡的超大計算規模。
2023-07-14 14:46:331215 
適配。測試結果顯示,曦云C500在智譜AI的升級版大模型上充分兼容、高效穩定運行。 沐曦旗艦產品曦云C500基于自主研發的高性能GPU IP,特別適合千億參數AI大模型的訓練和推理;基于全自研 GPU 指令集打造的MXMACA軟件棧,全面兼容主流GPU生態,實現用戶零成本遷移;
2023-08-23 10:38:473030 ,具有自學能力,能夠自動從大量數據中提取并學習規律,從而實現人工智能的基礎。 盤古AI大模型采用了GPU(圖形處理器)加速技術,GPU優化的算法使其在短時間內能夠完成非常龐大的數據集的學習和處理。GPU的基本原理是通過并行處理來加
2023-08-31 09:01:402008 目前,GPT-4、PaLM-2的算力當量,已經達到了GPT-3的數十倍,相當于上萬顆業界性能領先的NVIDIA Hopper架構的GPU芯片組成的AI集群,訓練超過1個月的時間。
2023-09-01 15:54:24568 
盤古ai大模型怎么使用 盤古AI大模型是一個基于自然語言處理的人工智能模型,是華為公司發布的 超大規模預訓練模型, 可以進行文本分析、問題回答、智能客服、智能寫作等多種應用。盤古ai大模型
2023-09-04 10:42:449386 在大模型趨勢下,墨芯通過領先的稀疏計算優勢,助力企業加速AI應用,商業化進程接連取得重要突破。
2023-09-07 11:37:15620 
聯發科天璣9300最高可運行330億參數AI大模型 聯發科這個是要把AI大模型帶到手機端的節奏嗎?聯發科正式發布了天璣9300旗艦5G生成式AI移動芯片,天璣9300號稱最高可運行330億參數AI
2023-11-07 19:00:06912 AI大模型逐步走入冷靜期,思考大模型如何助力解決實際問題、實現商業化落地成為新趨勢。
2024-01-12 09:18:04207
 電子發燒友App
電子發燒友App















 工商網監
工商網監
評論