 電子發燒友App
電子發燒友App


光計算研究始于20世紀60年代,但受到當時應用范圍有限以及電子計算技術快速發展的影響,光計算處理器未能成功邁向商用。時過境遷,人工智能(AI)飛速發展,以ChatGPT為代表的大語言模型所展現的強大能力引發全球關注,紫東太初、悟道、混元、文心、通義、盤古、言犀等一大批千億級乃至萬億級參數的國產大模型不斷涌現,大有引發新一輪科技與產業變革之勢。
高性能大模型擁有龐大參數規模、要求海量數據高效處理和高速傳輸,即使是當前最先進的電子計算平臺也開始出現計算、存儲和傳輸的瓶頸。大模型的創新發展和迭代,離不開海量數據及高質量數據集的構建,更要依靠大算力集群來支撐訓練和推理。近期,大模型訓練計算量平均每2個月就要翻倍,激增的算力需求已遠超摩爾定律。因此,光子計算近年來又重新受到廣泛關注。
硅光計算芯片是AI芯片國產化和彎道超車的有效途徑
當前,大模型訓練和推理的硬件以通用圖形處理單元(GPU)為主,2022年全球GPU市場規模達到448.3億美元,美國AI芯片巨頭英偉達公司占有80%的市場份額并仍在持續攀升。目前,中國仍以英偉達的產品作為主流算力平臺,只有較小規模的算力來自國產神經網絡加速平臺。然而,自2021年起,美國對中國集成電路領域實行了最為嚴苛的技術封鎖,限制向我國出口最先進的AI芯片和軟件。英偉達向我國提供的AI芯片是傳輸帶寬受限的特別版本,使用該版本GPU組成的超算集群的訓練和推理效率均落后于國外同期產品。
因此,算力基建亟需向自主可控的國產化邁進。 寒武紀、燧原科技、壁仞科技和昆侖芯等國產AI芯片廠商,均提供了深度學習訓練和推理的專用芯片,其主要使用專用集成電路(ASIC)硬件架構,用于特定算法或應用場景的優化,計算能力在特定情況下優于英偉達產品,但通用性、靈活性有待提升。基于電子計算的AI芯片的國產化之路受技術封鎖影響仍需突破重重阻礙,尤其是受限于先進工藝制程,國產同類芯片在能耗、算力、帶寬等方面難以在短期內趕超。
此外,電子計算技術還存在固有的計算延時高和內存墻等問題。 光子器件具有高速、大帶寬和低功耗的特點,在信息傳輸和處理方面具有重要優勢,而且光信號可以在光子器件中并行傳輸和處理。這使得光子計算可以更好地實現海量數據的高效處理,也可以避免電子信號傳輸帶來的噪聲和時延等問題,更好地實現高帶寬的傳輸互連,從而為大模型提供關鍵支撐。
此外,與最先進的電子神經網絡架構及數字電子系統相比,光子計算架構在速度和能效上優勢突出。因此,光子計算能夠有效突破傳統電子器件的性能瓶頸,滿足高速、低功耗通信和計算的需求。需要指出的是,光子計算的發展目標不是要取代傳統計算機,而是要輔助已有計算技術在基礎物理研究、非線性規劃、機器學習加速和智能信號處理等應用場景更高效地實現低延遲、大帶寬和低能耗。
硅光計算芯片通過在單個芯片上集成多種光子器件實現了更高的集成度,還能兼容現有半導體制造工藝,降低成本。光子計算芯片包括激光器、光波導、光調制器、光探測器等主要元件,運行過程大致如圖1所示:激光器產生的光,經過光波導傳輸到光調制器實現對光信號的控制和處理,最后傳輸到光探測器將光信號轉換為電信號,再進行后續的處理和輸出。 ?
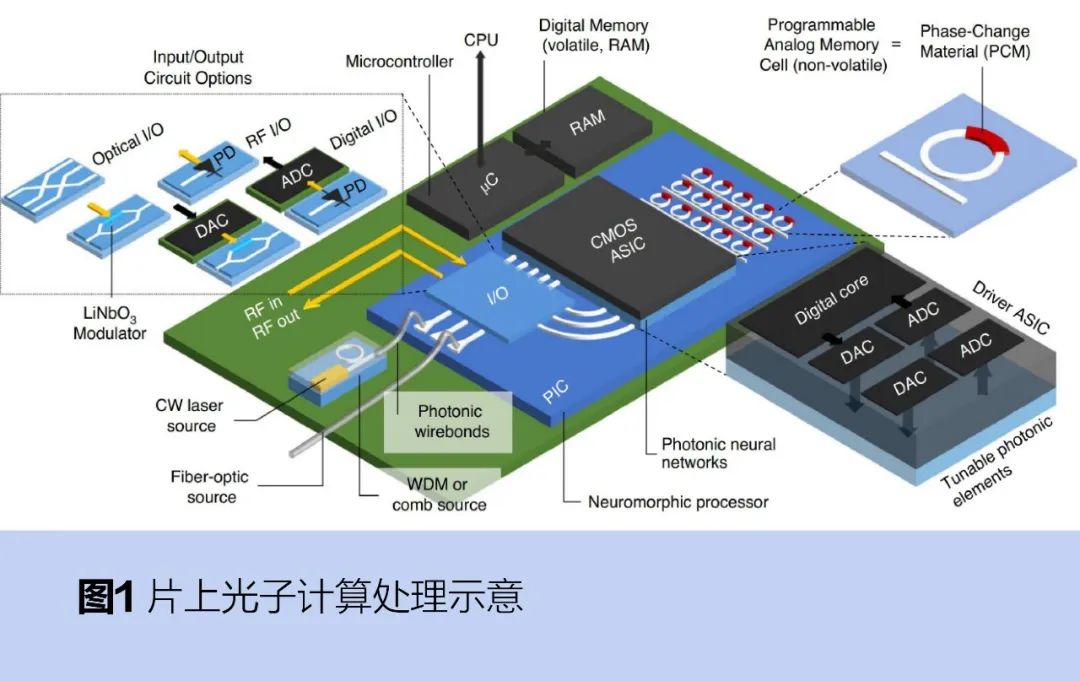
光子計算芯片利用成熟的硅基工藝平臺(產業界通常為45~180nm制程),有望在短期內實現低功耗、高性能的計算系統,解決后摩爾時代AI硬件的性能需求,突破馮·諾依曼架構的速度和功耗瓶頸。因此,硅光計算芯片是實現AI芯片國產化和彎道超車的有效途徑。
基于硅光平臺的神經網絡
人工神經網絡(ANN)是現有AI大模型的重要基礎,由人工神經元相互連接組成,連接強弱由權重大小決定,權重即模型參數。利用光計算在信息傳輸、處理和并行計算等方面以及光通信在片內、片間和板級系統間數據傳輸等方面的優勢,硅光計算芯片可對神經網絡訓練和推理過程中的大規模矩陣運算、神經元非線性運算進行加速;還可通過對不同神經網絡的拓撲結構進行硬件結構映射,來提高芯片的通用性和靈活性。
在人工神經網絡計算加速方面,基于硅光平臺的神經網絡已取得多項進展。例如,2017年沈亦晨等人提出一種基于硅光平臺的全光前饋神經網絡架構,采用馬赫-曾德干涉儀(MZI)進行神經元線性部分的計算,非線性激活函數則通過電域仿真的方法實現;2022年阿什蒂亞尼等人采用可調光衰減器實現權重調節。隨著技術的發展,基于硅光平臺的神經網絡也逐步走向商業化。例如,美國AI芯片公司Lightmatter推出通用光子AI加速器方案“Envise”;曦智科技于2021年發布光子計算處理器“PACE”。
人工神經網絡是大腦神經元的極簡數學模型,目前仍無法實現推理歸納、聯想想象、學習記憶等大腦的高級功能,而且現有AI大模型的功耗水平遠高于人類大腦。受腦科學和神經科學研究的啟發,學界提出了下一代AI基礎——脈沖神經網絡(SNN)。其利用與大腦神經元表現極為近似的脈沖神經元搭建整個網絡結構,具備模擬生物大腦的網絡結構和信息處理的潛能,通過部署到模擬計算硬件上,可以發揮低延時、低功耗等特性,為類腦大模型的訓練和推理提供了可能性。
目前,圍繞基于硅光平臺的脈沖神經網絡,已有科研團隊利用硅波導和相變材料集成等方式實現了光學突觸、光子脈沖神經元乃至全光脈沖神經網絡的構建。例如,2019年費爾德曼等人構建基于集成可塑突觸的全光脈沖神經網絡,將可塑突觸上的相變材料晶化程度作為權重,將微環諧振器上的相變材料胞體相變閾值能量作為神經元閾值調控激活函數,實現有監督和無監督學習。
光計算核心器件:
非易失性高消光比硅光開關研究
在片上和片間光互連、高速光通信、集成傳感和智能計算等應用場景,光開關都是硅光集成所需的核心器件。當前,硅光集成開關器件主要采用馬赫-曾德干涉儀或微環諧振器的結構設計,這些器件存在占用空間大、對外界溫度敏感以及因需要持續外部電源維持開關狀態導致的高靜態功耗等問題,為高密度的硅光集成帶來了額外的困難。
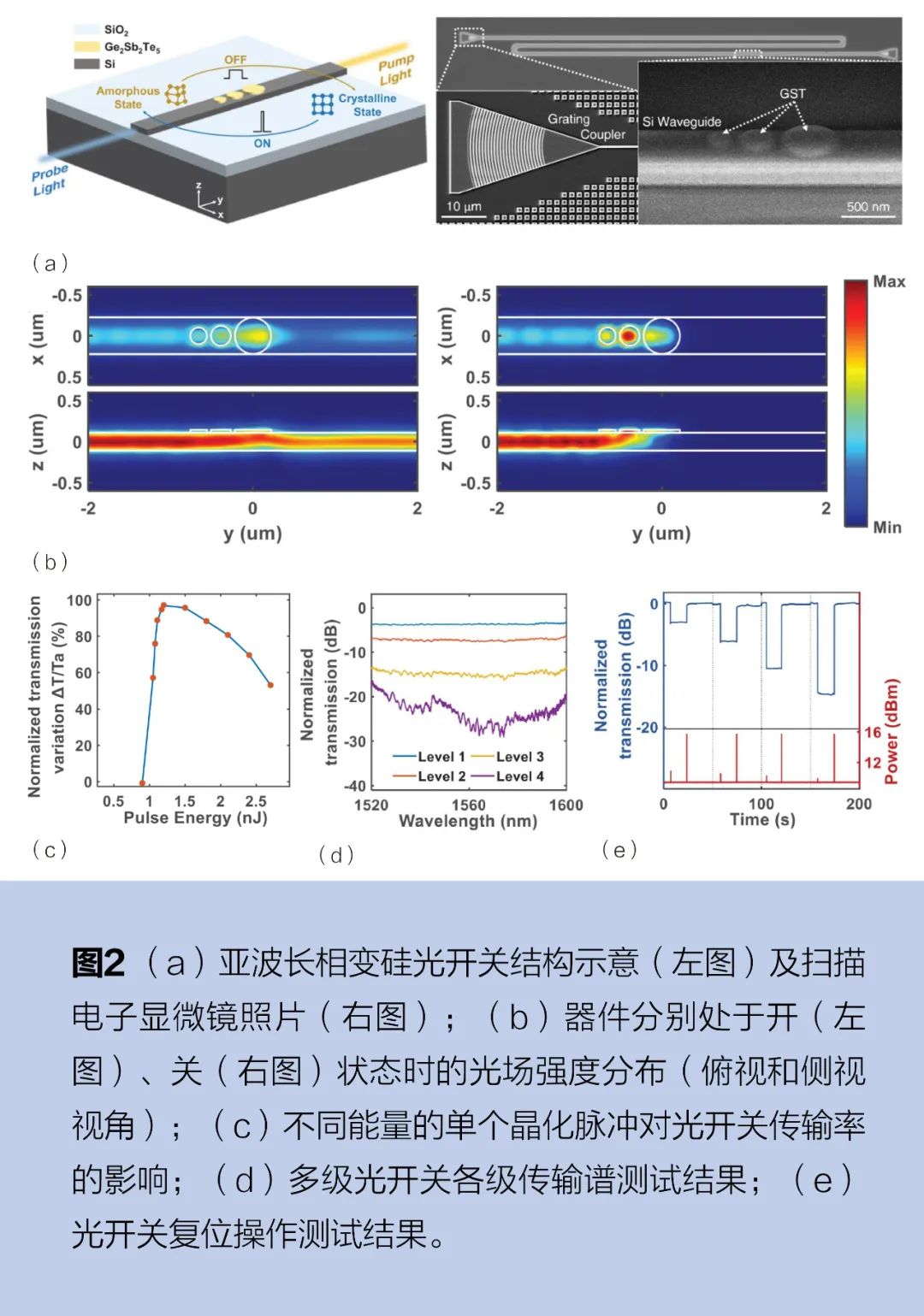
2022年,中國科學院上海微系統與信息系統研究所(以下簡稱上海微系統所)武愛民研究員團隊研制出基于亞波長相變結構的超小尺寸、高消光比、低能耗和良好結構穩定性的片上光子開關。這一新的光開關器件結構,由單模硅光波導和3個級聯的鍺銻碲化合物Ge2Sb2Te5(以下簡稱GST)納米盤組成,見圖2a,總體積僅為0.229μm2×35nm。在通信波段,GST是一種具有高光學對比度的相變材料(PCM),非晶態下的折射率與硅相近,具有較低的消光系數,而晶態下的折射率則會增大兩倍。通過改變GST納米盤的相態可以調制沿波導傳輸的光強。GST處于非晶態時,波導中的光可以正常通過;而處于晶態時,沿波導輸入的入射光被級聯的GST納米盤吸收或散射,實現對入射光的截止,見圖2b。
受益于GST的非易失性,光開關的開關狀態是可持續的,在施加控制脈沖后不會產生額外的能量消耗。在實驗中,通過對光開關施加不同能量的泵浦脈沖光,精確地加熱GST納米盤以切換其相位,從而實現對相變材料的調控,圖2c展示了波導中傳輸率的變化和脈沖能量的關系。實驗測得,該器件在C波段實現了高達27dB的超高消光比,并能在70nm的寬帶范圍內保持20dB以上的高消光性能,見圖2d;通過施加特定能量的光脈沖,可對非同級狀態的光開關實現復位操作,見圖2e。由于GST材料已具備在互補金屬氧化物半導體(CMOS)平臺上的加工能力,與單模波導制備的光開關結合能夠直接應用于規模化集成的光子芯片中,該工作有望在大規模集成的光互連和光計算新型架構等方面發揮重要作用。相關成果以《基于結構化相變材料的超緊湊高消光比非易失性片上開關》
Ultracompact High-Extinction-Ratio Nonvolatile On-Chip Switches Based on Structured Phase Change Materials為題發表在國際光學權威期刊《激光與光子學評論》(Laser & Photonics Reviews)。
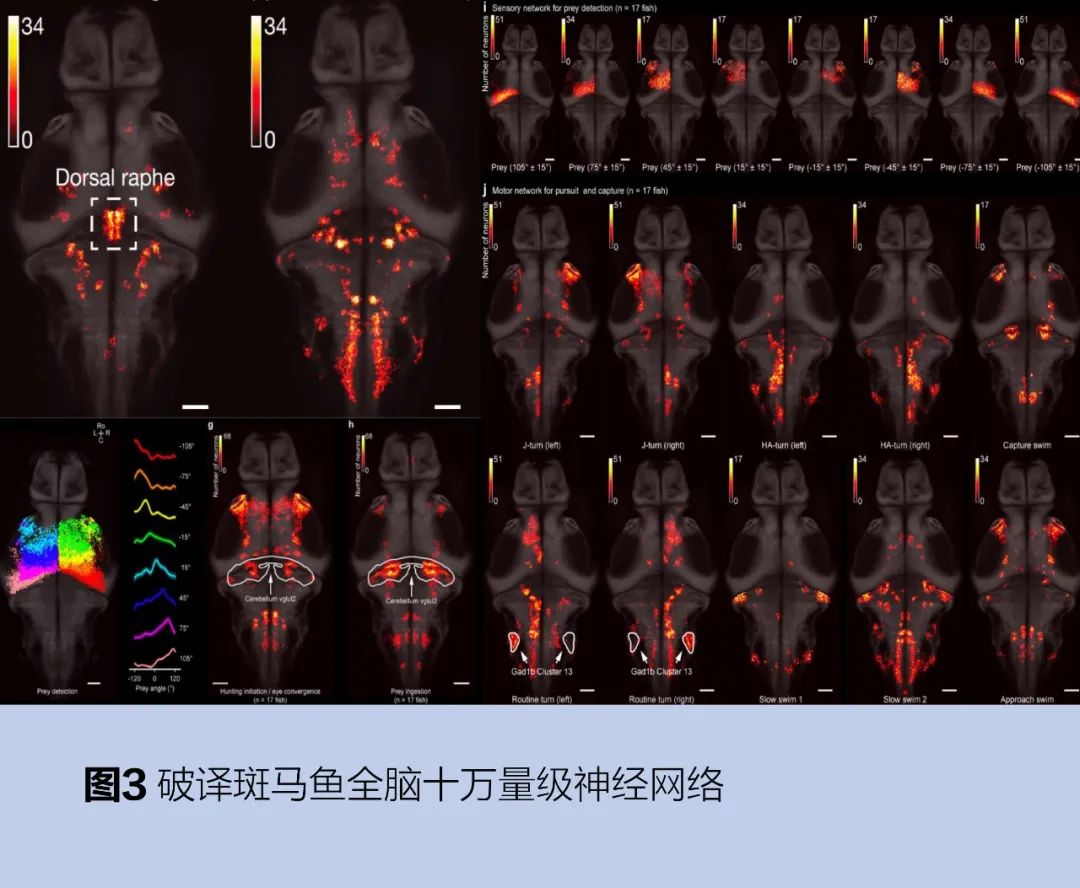
上海微系統所李孟研究員團隊長期從事腦科學與AI的交叉領域研究,研究方向主要包括兩個方面:一是應用AI技術解決腦科學領域的重要問題,如使用深度神經網絡對腦科學研究中動物的復雜行為進行分析和建模,并建立生物大腦神經網絡活動信號與動物行為模式的對應關系,以理解生物復雜行為、內在狀態是如何被大腦神經網絡表達、計算和調控的;二是根據腦科學前沿發現,將腦科學領域的最新成果和原理應用于類腦算法研究,致力于研發更符合生物神經系統特性的類腦算法和相應硬件,建立面向應用的類腦系統框架。在大腦破譯方向,尤其是大尺度群體神經信號編解碼領域取得系列創新成果。2019年,解碼了十萬神經元量級的全腦神經信號,如圖3所示,揭示了大腦內在狀態動態轉化的控制機理,建立了復雜高階行為與大腦神經網絡內在狀態間的關系,相關成果以《內部狀態動態塑造了全腦活動和覓食行為》
Internal state dynamics shape brainwide activity and foraging behaviour為題發表在國際頂級期刊《自然》上。
當前,兩個團隊正在合作研究基于硅光平臺的受腦科學和神經科學啟發的下一代AI計算芯片。目標是使其具有網絡低功耗、低延時等性能優勢,可執行因果推理、在線學習、終身學習、長時記憶、聯想想象、行為決策等類腦復雜功能及高級智能行為,并能廣泛應用于智能人形機器人、自動駕駛、仿生傳感器、智能安防與檢測、腦機接口等前沿領域。
AI創新時代,算力即為生產力。《2022—2023全球計算力指數評估報告》顯示,信息技術的支出每投入1美元,可以拉動29美元的國內生產總值(GDP)產出。隨著AI和計算科學的發展,大模型訓練和海量數據處理對于計算的需求將呈爆發式增長。
以光子計算技術為核心的硅光計算芯片,有望成為后摩爾時代AI算力基座。其主要優勢在于:一是高速計算能力,即光計算具有快速傳輸和處理能力,可實現神經網絡中所需的高速計算;二是低功耗特性,即相比于傳統的電子計算,光計算利用光信號進行信息傳輸和處理,可降低能耗;三是并行計算能力,即光信號可在光子器件中并行傳輸,在光學神經網絡中可實現更高效的并行計算。
硅光計算芯片在AI和計算科學領域走向廣泛應用也面臨一定挑戰。例如,當前單個光子矩陣運算規模較小,無法滿足大模型所需的計算需求;硅光計算芯片的設計尚未充分考慮集群化的應用情形,限制了芯片的可擴展能力;由于光信號是模擬信號,光子矩陣計算尚不支持浮點數運算,無法直接表示和處理浮點數據的精確值,而AI模型訓練則需要浮點數運算作為支持。
對標全球AI芯片行業翹楚,將硅光計算芯片打造成為未來AI和計算科學領域的主流計算平臺,需要構建完整、可持續的軟硬件生態環境。例如,硅光計算芯片的底層設計需要引入可微分思想,使其具有可擴展性;通過軟硬件協同,針對不同規模的硅光計算芯片和應用場景,開發硅光計算芯片的底層編譯器、高級編程語言接口、硬件驅動,以及基于開源指令集(如RSIC-V等)的硅光芯片專用計算指令集;開發面向AI和計算科學的學習框架和計算加速庫,更廣泛地吸引各領域相關人員利用硅光計算芯片開展研發工作,建設硅光計算社群,助推硅光計算蓬勃發展。通過構建硅光計算芯片的完整軟硬件生態,硅光計算的核心競爭力將大幅提升,為未來AI芯片領域的國產化超越貢獻力量。 本文刊登于IEEE Spectrum中文版《科技縱覽》2023年11月刊。 專家簡介
何王吉:工程師。
魯若天:碩士研究生。 王碩:助理研究員。 李孟:研究員。 武愛民:研究員。 注:作者單位均為中國科學院上海微系統與信息技術研究所。
審核編輯:黃飛
?















 工商網監
工商網監
評論