 電子發燒友App
電子發燒友App


今天,一則重磅消息席卷了 AI 圈:OpenAI 發布了視頻模型 Sora,能根據文本生成長達一分鐘的高質量 1920x1080 視頻,生成能力遠超此前只能生成 25 幀 576x1024 圖像的頂尖視頻生成模型 Stable Video Diffusion。
同時,OpenAI 也公布了一篇非常簡短的技術報告。報告僅大致介紹了 Sora 的架構及應用場景,并未對模型的原理詳加介紹。讓我們來快速瀏覽一下這份報告,看看科研人員從這份報告中能學到什么。
LDM 與 DiT 的結合
簡單來說,Sora 就是 Latent Diffusion Model (LDM) [1] 加上 Diffusion Transformer (DiT) [2]。我們先簡要回顧一下這兩種模型架構。
LDM 就是 Stable Diffusion 使用的模型架構。擴散模型的一大問題是計算需求大,難以擬合高分辨率圖像。為了解決這一問題,實現 LDM時,會先訓練一個幾乎能無損壓縮圖像的自編碼器,能把 512x512 的真實圖像壓縮成 64x64 的壓縮圖像并還原。接著,再訓練一個擴散模型去擬合分辨率更低的壓縮圖像。這樣,僅需少量計算資源就能訓練出高分辨率的圖像生成模型。
LDM 的擴散模型使用的模型是 U-Net。而根據其他深度學習任務中的經驗,相比 U-Net,Transformer 架構的參數可拓展性強,即隨著參數量的增加,Transformer 架構的性能提升會更加明顯。這也是為什么大模型普遍都采用了 Transformer 架構。從這一動機出發,DiT 應運而生。DiT 在 LDM 的基礎上,把 U-Net 換成了 Transformer。
順帶一提,Transformer 本來是用于文本任務的,它只能處理一維的序列數據。為了讓 Transformer 處理二維圖像,通常會把輸入圖像先切成邊長為 的圖塊,再把每個圖塊處理成一項數據。也就是說,原來邊長為 的正方形圖片,經圖塊化后,變成了長度為 的一維序列數據。
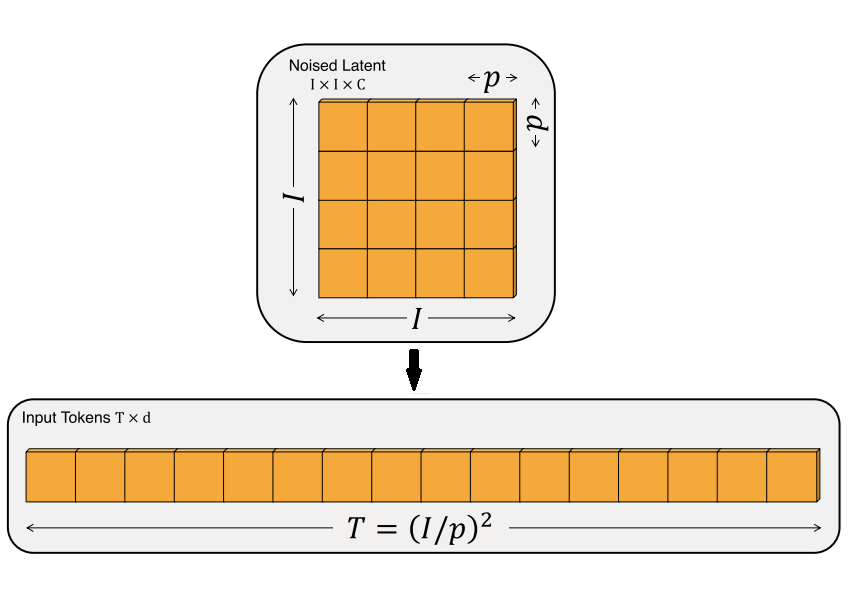
Transformer 是一種和順序無關的計算。比如對于輸入"abc"和"bca",Transformer 會輸出一模一樣的值。為了描述數據的先后順序,使用 Transformer 時,一般會給數據加一個位置編碼。
Sora 是一個視頻版的 DiT 模型。讓我們看一下 Sora 在 DiT 上做了哪些改進。
時空自編碼器
在此之前,許多工作都嘗試把預訓練 Stable Diffusion 拓展成視頻生成模型。在拓展時,視頻的每一幀都會單獨輸入進 Stable Diffusion 的自編碼器,再重新構成一個壓縮過的圖像序列。而 VideoLDM[3] 工作發現,直接對視頻使用之前的圖像自編碼器,會令輸出視頻出現閃爍的現象。為此,該工作對自編碼器的解碼器進行了微調,加入了一些能夠處理時間維度的模塊,使之能一次性處理整段壓縮視頻,并輸出連貫的真實視頻。
Sora 則是從頭訓練了一套能直接壓縮視頻的自編碼器。相比之前的工作,Sora 的自編碼器不僅能在空間上壓縮圖像,還能在時間上壓縮視頻長度。這估計是為什么 Sora 能生成長達一分鐘的視頻。
報告中提到,Sora 也能處理圖像,即長度為1的視頻。那么,自編碼器怎么在時間上壓縮長度為1的視頻呢?報告中并沒有給出細節。我猜測該自編碼器在時間維度做了填充(比如時間被壓縮成原來的 1/2,那么就對輸入視頻填充空數據直至視頻長度為偶數),也可能是輸入了視頻長度這一額外約束信息。
時空壓縮圖塊
輸入視頻經過自編碼器后,會被轉換成一段空間和時間維度上都變小的壓縮視頻。這段壓縮視頻就是 Sora 的 DiT 的擬合對象。在處理視頻數據時,DiT 較 U-Net 又有一些優勢。
之前基于 U-Net 的去噪模型在處理視頻數據時(如 [3]),都需要額外加入一些和時間維度有關的操作,比如時間維度上的卷積、自注意力。而 Sora 的 DiT 是一種完全基于圖塊的 Transformer 架構。要用 DiT 處理視頻數據,不需要這種設計,只要把視頻看成一個 3D 物體,再把 3D 物體分割成「圖塊」,并重組成一維數據輸入進 DiT 即可。和原本圖像 DiT 一樣,假設視頻邊長為 ,時長也為 ,要切成邊長為 的圖塊,最后會得到 個數據。
處理任意分辨率、時長的視頻
報告中反復提及,Sora 在訓練和生成時使用的視頻可以是任何分辨率(在 1920x1080 以內)、任何長寬比、任何時長的。這意味著視頻訓練數據不需要做縮放、裁剪等預處理。這些特性是絕大多數其他視頻生成模型做不到的,讓我們來著重分析一下這一特性的原理。
Sora 的這種性質還是得益于 Transformer 架構。前文提到,Transformer 的計算與輸入順序無關,必須用位置編碼來指明每個數據的位置。盡管報告沒有提及,我覺得 Sora 的 DiT 使用了類似于 的位置編碼來表示一個圖塊的時空位置。這樣,不管輸入的視頻的大小如何,長度如何,只要給每個圖塊都分配一個位置編碼,DiT 就能分清圖塊間的相對關系了。
相比以前的工作,Sora 的這種設計是十分新穎的。之前基于 U-Net 的 Stable Diffusion 為了保證所有訓練數據可以統一被處理,輸入圖像都會被縮放與裁剪至同一大小。由于訓練數據中有被裁剪的圖像,模型偶爾也會生成被裁剪的圖像。生成訓練分辨率以外的圖像時,模型的表現有時也會不太好。SDXL [4] 的解決方式是把裁剪的長寬做為額外信息輸入進 U-Net。為了生成沒有裁剪的圖像,只要令輸入的裁剪長寬為 0 即可。類似地,SDXL 也把圖像分辨率做為額外輸入,使得 U-Net 學習不同分辨率、長寬比的圖像。相比 SDXL,Sora 的做法就簡潔多了。
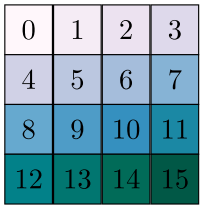
之前基于 DiT 的模型 (比如華為的 PixArt [5])似乎都沒有利用到 Transformer 可以隨意設置位置編碼這一性質。DiT 在處理輸入圖塊時,會先把圖塊變形成一維數據,再從左到右編號,即從從左到右,從上到下地給二維圖塊組編號。這種位置編碼并沒有保留圖像的二維空間信息,因此,在這種編碼下,模型的輸入分辨率必須固定。比如對于下面這個的圖塊組,如果是從左到右、從上到下編碼,模型等于是強行學習到了「1號在0號右邊、4號在0號下面」這樣的位置信息。如果輸入的圖塊形狀為 ,那么圖塊間的相對關系就完全對不上了。而如果像 Sora 這樣以視頻圖塊的 來生成位置編碼的話,就沒有這種問題了,輸入視頻可以是任何分辨率、任何長度。
Transformer 在視頻生成的可拓展性
前文提過,Transformer 的特點就是可拓展性強,即模型越大,訓練越久,效果越好。報告中展示了1倍、4倍、16倍某單位訓練時間下的生成結果,可以看出模型確實一直有進步。
語言理解能力
之前大部分文生圖擴散模型都是在人工標注的圖片-文字數據集上訓練的。后來大家發現,人工標注的圖片描述質量較低,紛紛提出了各種提升標注質量的方法。Sora 復用了自家 DALL·E 3 的重標注技術,用一個訓練的能生成詳細描述的標注器來重新為訓練視頻生成標注。這種做法不僅解決了視頻缺乏標注的問題,且相比人工標注質量更高。Sora 的部分結果展示了其強大了抽象理解能力(如理解人和貓之間的交互),這多半是因為視頻標注模型足夠強大,視頻生成模型學到了視頻標注模型的知識。但同樣,視頻標注模型的相關細節完全沒有公開。
其他生成功能
基于已有圖像和視頻進行生成:除了約束文本外,Sora 還支持在一個視頻前后補充內容(如果是在一張圖片后面補充內容,就是圖生視頻)。報告沒有給出實現細節,我猜測是直接做了反演(inversion)再把反演得到的隱變量替換到隨機初始隱變量中。
視頻編輯:報告明確寫出,只用簡單的 SDEdit (即目前 Stable Diffusion 中的圖生圖)即可實現視頻編輯。
視頻內容融合:可能是對兩個視頻的初始隱變量做了插值。
圖像生成:當然,Sora 也可以生成圖像。報告表明,Sora 可以生成最大 2048x2048 的圖像。
涌現出的能力
通過學習大量數據,Sora 還涌現出一些意想不到的能力。
3D 一致性:視頻中包含自然的相機視角變換。之前的 Stable Video Diffusion 也有類似發現。
長距離連貫性:AI 生成出來的視頻往往有物體在中途突然消失的情況。而 Sora 有時候能克服這一問題。
與世界的交互:比如在描述畫畫的視頻中,畫紙上的內容隨畫筆生成。
模擬數字世界:報告展示了在輸入文本有"Minecraft"時,模型能生成非常真實的 Minecraft 游戲視頻。這大概只能說明模型的擬合能力太強了,以至于學會了生成 Minecraft 這一種特定風格的視頻。
局限性
報告結尾還是給出了一些失敗的生成示例,比如玻璃杯在桌子上沒有摔碎。這表明模型還不能完全學會某些物理性質。然而,我覺得現階段 Sora 已經展示了足夠強大的學習能力。想模擬現有視頻中已經包含的物理現象,只需要增加數據就行了。
總結
Sora 是一個驚艷的視頻生成模型,它以卓越的生成能力(高分辨率、長時間)與生成質量令一眾同期的視頻生成模型黯然失色。Sora 的技術報告非常簡短,不過我們從中還是可以學到一些東西。從技術貢獻上來看,Sora 的創新主要有兩點:
讓 LDM 的自編碼器也在視頻時間維度上壓縮。
使用了一種不限制輸入形狀的 DiT
其中,第二點貢獻是非常有啟發性的。DiT 能支持不同形狀的輸入,大概率是因為它以視頻的3D位置生成位置編碼,打破了一維編碼的分辨率限制。后續大家或許會逐漸從 U-Net 轉向 DiT 來建模擴散模型的去噪模型。
我認為 Sora 的成功有三個原因。前兩個原因對應兩項創新。第一,由于在時間維度上也進行了壓縮,Sora 最終能生成長達一分鐘的視頻;第二,使用 DiT 不僅去除了視頻空間、時間長度上的限制,還充分利用了 Transformer 本身的可拓展性,使訓練一個視頻生成大模型變得可能。第三個原因來自于視頻標注模型。之前 Stable Diffusion 能夠成功,很大程度上是因為有一個能夠關聯圖像與文本的 CLIP 模型,且有足夠多的帶標注圖片。相比圖像,視頻訓練本來就少,帶標注的視頻就更難獲得了。一個能夠理解視頻內容,生成詳細視頻標注的標注器,一定是讓視頻生成模型理解復雜文本描述的關鍵。除了這幾點原因外,剩下的就是砸錢、擴大模型、加數據了。
Sora 顯然會對 AIGC 社區產生一定影響。對于 AIGC 愛好者而言,他們或許會多了一些生成創意視頻的方法,比如給部分幀讓 Sora 來根據文本補全剩余幀。當然,目前 Sora 依然不能取代視頻創作者,長視頻的質量依然有待觀察。對于正在開發相似應用的公司,我覺得他們應該要連夜撤銷之前的方案,轉換為這套沒有分辨率限制的 DiT 的方案。他們的壓力應該會很大。對于相關科研人員而言,除了學習這種較為新穎的 DiT 用法外,也沒有太多收獲了。這份技術報告透露出一股「我絕對不會開源」的意思。沒有開源模型,普通的研究者也就什么都做不了。新技術的誕生絕對不可能靠一家公司,一個模型就搞定。像之前的 Stable Diffusion,也是先開源了一個基礎模型,科研者和愛好者再補充了各種豐富的應用。我呼吁各大公司盡快訓練并開源一個這種不限分辨率的 DiT,這樣科研界或許會拋開 U-Net,基于 DiT 開發出新的擴散模型應用。
審核編輯:黃飛
?












 工商網監
工商網監
評論