 電子發(fā)燒友App
電子發(fā)燒友App


機(jī)器學(xué)習(xí)按照模型類型分為監(jiān)督學(xué)習(xí)模型、無(wú)監(jiān)督學(xué)習(xí)模型兩大類。
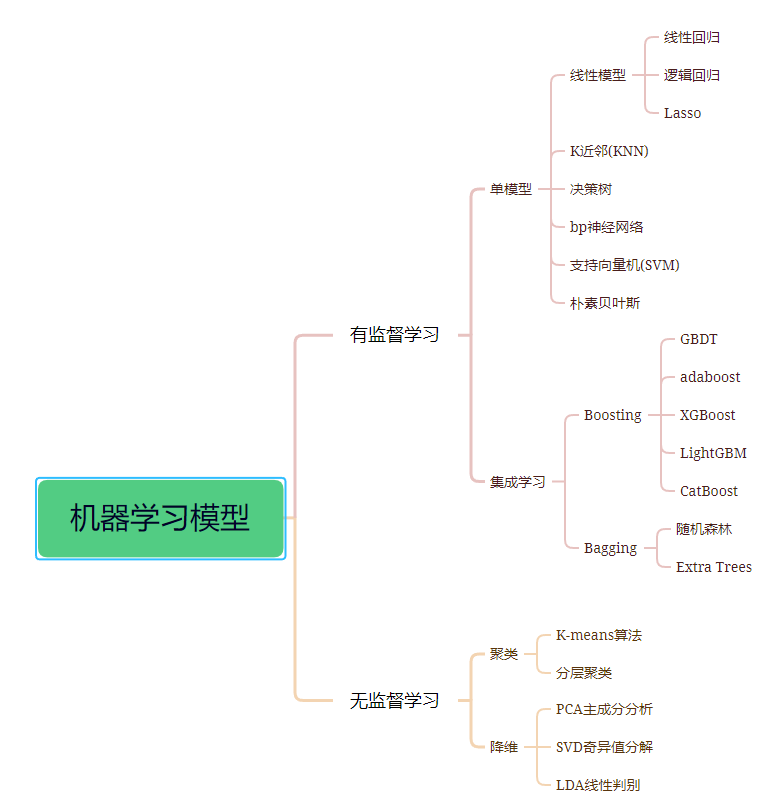
1. 有監(jiān)督學(xué)習(xí)
有監(jiān)督學(xué)習(xí)通常是利用帶有專家標(biāo)注的標(biāo)簽的訓(xùn)練數(shù)據(jù),學(xué)習(xí)一個(gè)從輸入變量X到輸入變量Y的函數(shù)映射。Y = f (X),訓(xùn)練數(shù)據(jù)通常是(n×x,y)的形式,其中n代表訓(xùn)練樣本的大小,x和y分別是變量X和Y的樣本值。 有監(jiān)督學(xué)習(xí)可以被分為兩類:
分類問(wèn)題:預(yù)測(cè)某一樣本所屬的類別(離散的)。比如判斷性別,是否健康等。
回歸問(wèn)題:預(yù)測(cè)某一樣本的所對(duì)應(yīng)的實(shí)數(shù)輸出(連續(xù)的)。比如預(yù)測(cè)某一地區(qū)人的平均身高。
除此之外,集成學(xué)習(xí)也是一種有監(jiān)督學(xué)習(xí)。它是將多個(gè)不同的相對(duì)較弱的機(jī)器學(xué)習(xí)模型的預(yù)測(cè)組合起來(lái),用來(lái)預(yù)測(cè)新的樣本。 ?
1.1 單模型
1.11 線性回歸
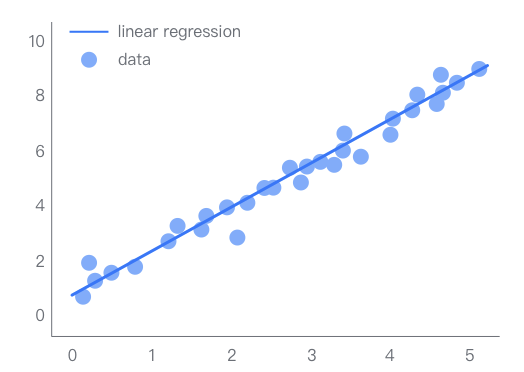
線性回歸是指完全由線性變量組成的回歸模型。在線性回歸分析中,只包括一個(gè)自變量和一個(gè)因變量,且二者的關(guān)系可用一條直線近似表示,這種回歸分析稱為一元線性回歸分析。
如果回歸分析中包括兩個(gè)或兩個(gè)以上的自變量,且因變量和自變量之間是線性關(guān)系,則稱為多元線性回歸分析。
1.12 邏輯回歸
用于研究Y為定類數(shù)據(jù)時(shí)X和Y之間的影響關(guān)系情況,如果Y為兩類比如0和1(比如1為愿意和0為不愿意,1為購(gòu)買(mǎi)和0為不購(gòu)買(mǎi)),此時(shí)就叫二元邏輯回歸;如果Y為三類以上,此時(shí)就稱為多分類邏輯回歸。
自變量并不一定非要定類變量,它們也可以是定量變量。如果X是定類數(shù)據(jù),此時(shí)需要對(duì)X進(jìn)行啞變量設(shè)置。
1.13 Lasso
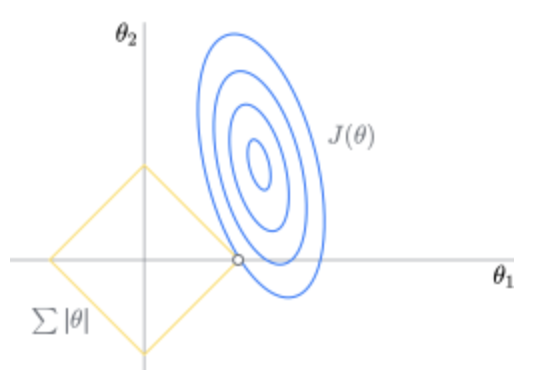
Lasso方法是一種替代最小二乘法的壓縮估計(jì)方法。Lasso的基本思想是建立一個(gè)L1正則化模型,在模型建立過(guò)程中會(huì)壓縮一些系數(shù)和設(shè)定一些系數(shù)為零,當(dāng)模型訓(xùn)練完成后,這些權(quán)值等于0的參數(shù)就可以舍去,從而使模型更為簡(jiǎn)單,并且有效防止模型過(guò)擬合。被廣泛用于存在多重共線性數(shù)據(jù)的擬合和變量選擇。 1.14 K近鄰(KNN)
KNN做回歸和分類的主要區(qū)別在于最后做預(yù)測(cè)時(shí)候的決策方式不同。KNN做分類預(yù)測(cè)時(shí),一般是選擇多數(shù)表決法,即訓(xùn)練集里和預(yù)測(cè)的樣本特征最近的K個(gè)樣本,預(yù)測(cè)為里面有最多類別數(shù)的類別。
KNN做回歸時(shí),一般是選擇平均法,即最近的K個(gè)樣本的樣本輸出的平均值作為回歸預(yù)測(cè)值。但它們的理論是一樣的。
1.15 決策樹(shù)
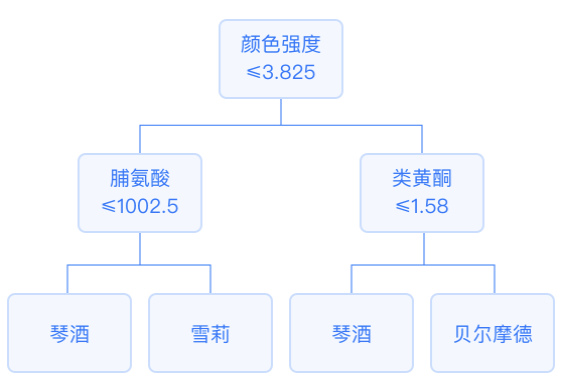
決策樹(shù)中每個(gè)內(nèi)部節(jié)點(diǎn)都是一個(gè)分裂問(wèn)題:指定了對(duì)實(shí)例的某個(gè)屬性的測(cè)試,它將到達(dá)該節(jié)點(diǎn)的樣本按照某個(gè)特定的屬性進(jìn)行分割,并且該節(jié)點(diǎn)的每一個(gè)后繼分支對(duì)應(yīng)于該屬性的一個(gè)可能值。
分類樹(shù)葉節(jié)點(diǎn)所含樣本中,其輸出變量的眾數(shù)就是分類結(jié)果。回歸樹(shù)的葉節(jié)點(diǎn)所含樣本中,其輸出變量的平均值就是預(yù)測(cè)結(jié)果。
1.16 bp神經(jīng)網(wǎng)絡(luò)
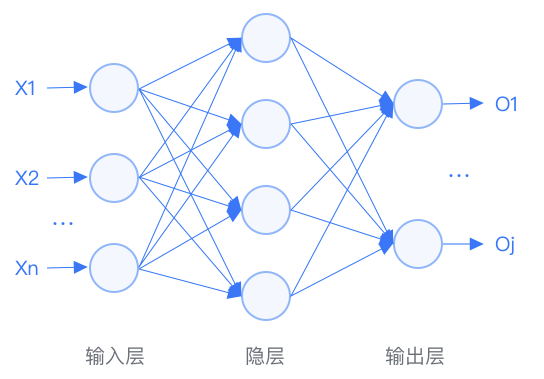
bp神經(jīng)網(wǎng)絡(luò)是一種按誤差逆?zhèn)鞑?a target="_blank">算法訓(xùn)練的多層前饋網(wǎng)絡(luò),是目前應(yīng)用最廣泛的神經(jīng)網(wǎng)絡(luò)模型之一。bp神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)規(guī)則是使用最速下降法,通過(guò)反向傳播來(lái)不斷調(diào)整網(wǎng)絡(luò)的權(quán)值和閾值,使網(wǎng)絡(luò)的分類錯(cuò)誤率最小(誤差平方和最小)。
BP 神經(jīng)網(wǎng)絡(luò)是一種多層的前饋神經(jīng)網(wǎng)絡(luò),其主要的特點(diǎn)是:信號(hào)是前向傳播的,而誤差是反向傳播的。具體來(lái)說(shuō),對(duì)于如下的只含一個(gè)隱層的神經(jīng)網(wǎng)絡(luò)模型,BP 神經(jīng)網(wǎng)絡(luò)的過(guò)程主要分為兩個(gè)階段:
第一階段是信號(hào)的前向傳播,從輸入層經(jīng)過(guò)隱含層,最后到達(dá)輸出層;
第二階段是誤差的反向傳播,從輸出層到隱含層,最后到輸入層,依次調(diào)節(jié)隱含層到輸出層的權(quán)重和偏置,輸入層到隱含層的權(quán)重和偏置。
1.17 支持向量機(jī)(SVM)

支持向量機(jī)回歸(SVR)用非線性映射將數(shù)據(jù)映射到高維數(shù)據(jù)特征空間中,使得在高維數(shù)據(jù)特征空間中自變量與因變量具有很好的線性回歸特征,在該特征空間進(jìn)行擬合后再返回到原始空間。
支持向量機(jī)分類(SVM)是一類按監(jiān)督學(xué)習(xí)方式對(duì)數(shù)據(jù)進(jìn)行二元分類的廣義線性分類器,其決策邊界是對(duì)學(xué)習(xí)樣本求解的最大邊距超平面。
1.18 樸素貝葉斯
在給定一個(gè)事件發(fā)生的前提下,計(jì)算另外一個(gè)事件發(fā)生的概率——我們將會(huì)使用貝葉斯定理。假設(shè)先驗(yàn)知識(shí)為d,為了計(jì)算我們的假設(shè)h為真的概率,我們將要使用如下貝葉斯定理:
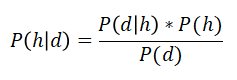
該算法假定所有的變量都是相互獨(dú)立的。
1.2 集成學(xué)習(xí)
集成學(xué)習(xí)是一種將不同學(xué)習(xí)模型(比如分類器)的結(jié)果組合起來(lái),通過(guò)投票或平均來(lái)進(jìn)一步提高準(zhǔn)確率。一般,對(duì)于分類問(wèn)題用投票;對(duì)于回歸問(wèn)題用平均。這樣的做法源于“眾人拾材火焰高”的想法。 集成算法主要有三類:Bagging,Boosting 和Stacking。本文將不談及stacking。

Boosting
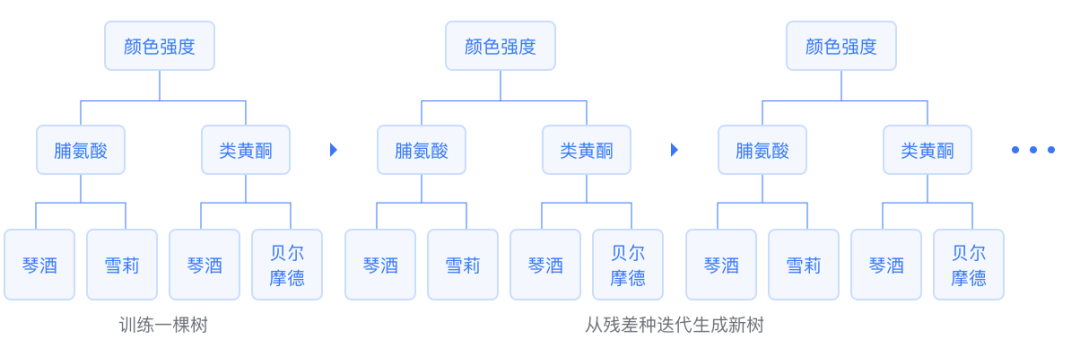
1.21 GBDT
GBDT 是以 CART 回歸樹(shù)為基學(xué)習(xí)器的 Boosting 算法,是一個(gè)加法模型,它串行地訓(xùn)練一組 CART 回歸樹(shù),最終對(duì)所有回歸樹(shù)的預(yù)測(cè)結(jié)果加和,由此得到一個(gè)強(qiáng)學(xué)習(xí)器,每一顆新樹(shù)都擬合當(dāng)前損失函數(shù)的負(fù)梯度方向。最后輸出這一組回歸樹(shù)的加和,直接得到回歸結(jié)果或者套用 sigmod 或者 softmax 函數(shù)獲得二分類或者多分類結(jié)果。
1.22 adaboost
adaboost給予誤差率低的學(xué)習(xí)器一個(gè)高的權(quán)重,給予誤差率高的學(xué)習(xí)器一個(gè)低的權(quán)重,結(jié)合弱學(xué)習(xí)器和對(duì)應(yīng)的權(quán)重,生成強(qiáng)學(xué)習(xí)器。回歸問(wèn)題與分類問(wèn)題算法的不同點(diǎn)在于誤差率計(jì)算的方式不同,分類問(wèn)題一般都采用0/1損失函數(shù),而回歸問(wèn)題一般都是平方損失函數(shù)或者是線性損失函數(shù)。
1.23 XGBoost
XGBoost 是"極端梯度上升"(Extreme Gradient Boosting)的簡(jiǎn)稱,XGBoost 算法是一類由基函數(shù)與權(quán)重進(jìn)行組合形成對(duì)數(shù)據(jù)擬合效果佳的合成算法。由于 XGBoost 模型具有較強(qiáng)的泛化能力、較高的拓展性、較快的運(yùn)算速度等優(yōu)勢(shì), 從2015年提出后便受到了統(tǒng)計(jì)學(xué)、數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)領(lǐng)域的歡迎。
xgboost是GBDT的一種高效實(shí)現(xiàn),和GBDT不同,xgboost給損失函數(shù)增加了正則化項(xiàng);且由于有些損失函數(shù)是難以計(jì)算導(dǎo)數(shù)的,xgboost使用損失函數(shù)的二階泰勒展開(kāi)作為損失函數(shù)的擬合。
1.24 LightGBM
LightGBM 是 XGBoost 一種高效實(shí)現(xiàn),其思想是將連續(xù)的浮點(diǎn)特征離散成 k 個(gè)離散值,并構(gòu)造寬度為 k 的直方圖。然后遍歷訓(xùn)練數(shù)據(jù),計(jì)算每個(gè)離散值在直方圖中的累計(jì)統(tǒng)計(jì)量。在進(jìn)行特征選擇時(shí),只需要根據(jù)直方圖的離散值,遍歷尋找最優(yōu)的分割點(diǎn);且使用帶有深度限制的按葉子生長(zhǎng)(leaf-wise)策略,節(jié)省了不少時(shí)間和空間上的開(kāi)銷。
1.25 CatBoost
catboost 是一種基于對(duì)稱決策樹(shù)算法的 GBDT 框架,主要解決的痛點(diǎn)是高效合理地處理類別型特征和處理梯度偏差、預(yù)測(cè)偏移問(wèn)題,提高算法的準(zhǔn)確性和泛化能力。
Bagging
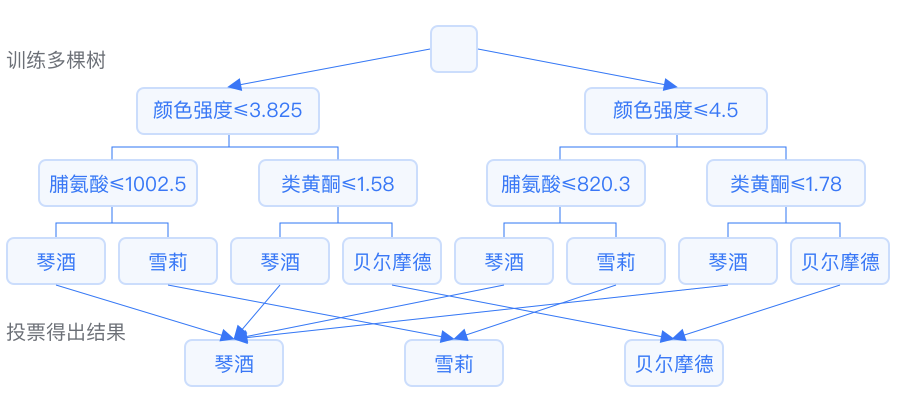
1.26 隨機(jī)森林 隨機(jī)森林分類在生成眾多決策樹(shù)的過(guò)程中,是通過(guò)對(duì)建模數(shù)據(jù)集的樣本觀測(cè)和特征變量分別進(jìn)行隨機(jī)抽樣,每次抽樣結(jié)果均為一棵樹(shù),且每棵樹(shù)都會(huì)生成符合自身屬性的規(guī)則和分類結(jié)果(判斷值),而森林最終集成所有決策樹(shù)的規(guī)則和分類結(jié)果(判斷值),實(shí)現(xiàn)隨機(jī)森林算法的分類(回歸)。 1.27 Extra Trees
extra-trees (極其隨機(jī)的森林)和隨機(jī)森林非常類似,這里的“及其隨機(jī)”表現(xiàn)在決策樹(shù)的結(jié)點(diǎn)劃分上,它干脆直接使用隨機(jī)的特征和隨機(jī)的閾值劃分,這樣我們每一棵決策樹(shù)形狀、差異就會(huì)更大、更隨機(jī)。
2 無(wú)監(jiān)督學(xué)習(xí)
無(wú)監(jiān)督學(xué)習(xí)問(wèn)題處理的是,只有輸入變量X沒(méi)有相應(yīng)輸出變量的訓(xùn)練數(shù)據(jù)。它利用沒(méi)有專家標(biāo)注訓(xùn)練數(shù)據(jù),對(duì)數(shù)據(jù)的結(jié)構(gòu)建模。
2.1 聚類
將相似的樣本劃分為一個(gè)簇(cluster)。與分類問(wèn)題不同,聚類問(wèn)題預(yù)先并不知道類別,自然訓(xùn)練數(shù)據(jù)也沒(méi)有類別的標(biāo)簽。 2.11 K-means算法
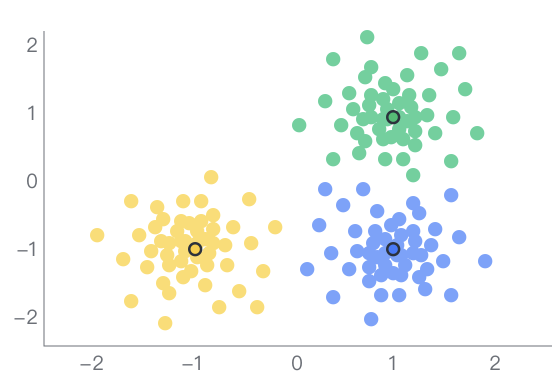
聚類分析是一種基于中心的聚類算法(K 均值聚類),通過(guò)迭代,將樣本分到 K 個(gè)類中,使得每個(gè)樣本與其所屬類的中心或均值的距離之和最小。與分層聚類等按照字段進(jìn)行聚類的算法不同的是,快速聚類分析是按照樣本進(jìn)行聚類。 2.12 分層聚類
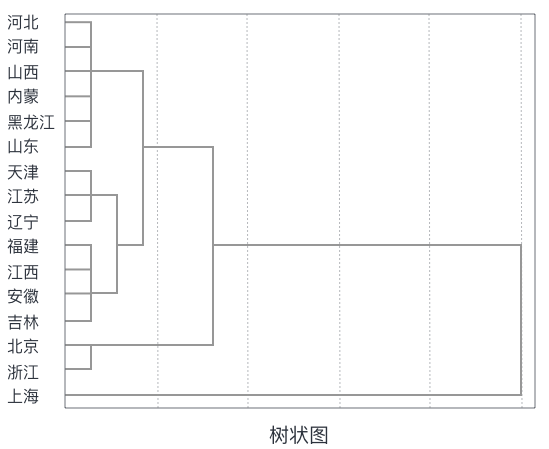
分層聚類法作為聚類的一種,是對(duì)給定數(shù)據(jù)對(duì)象的集合進(jìn)行層次分解,根據(jù)分層分解采用的分解策略。層次聚類算法按數(shù)據(jù)分層建立簇,形成一棵以簇為節(jié)點(diǎn)的樹(shù)。如果按自底向上進(jìn)行層次分解,則稱為凝聚的層次聚類,比如 AGNES。而按自頂向下的進(jìn)行層次分解,則稱為分裂法層次聚類,比如 DIANA。一般用的比較多的是凝聚層次聚類。
2.2 降維
降維指減少數(shù)據(jù)的維度同時(shí)保證不丟失有意義的信息。利用特征提取方法和特征選擇方法,可以達(dá)到降維的效果。特征選擇是指選擇原始變量的子集。特征提取是將數(shù)據(jù)從高緯度轉(zhuǎn)換到低緯度。廣為熟知的主成分分析算法就是特征提取的方法。 2.21 PCA主成分分析
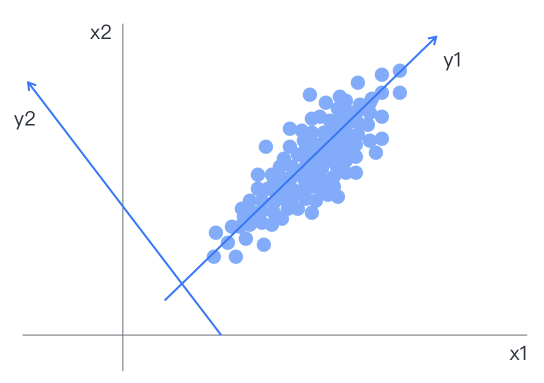
主成分分析將多個(gè)有一定相關(guān)性的指標(biāo)進(jìn)行線性組合,以最少的維度解釋原數(shù)據(jù)中盡可能多的信息為目標(biāo)進(jìn)行降維,降維后的各變量間彼此線性無(wú)關(guān),最終確定的新變量是原始變量的線性組合,且越往后主成分在方差中的比重也小,綜合原信息的能力越弱。
2.22 SVD奇異值分解 奇異值分解(SVD)是在機(jī)器學(xué)習(xí)領(lǐng)域廣泛運(yùn)用的算法,他不光可以用在降維算法中的特征值分解,還可以用于推薦系統(tǒng),以及自然語(yǔ)言處理等領(lǐng)域,是很多算法的基石。 2.23 LDA線性判別
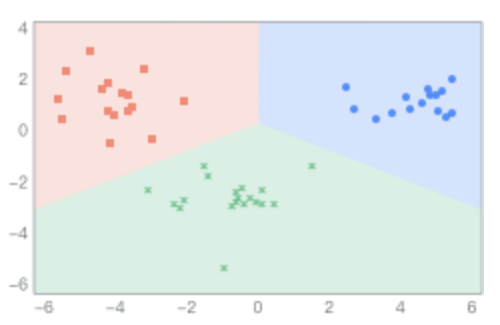
線性判別的原理是將樣本投影到一條直線上,使得同類樣本的投影點(diǎn)盡可能接近,不同樣本的投影點(diǎn)盡可能遠(yuǎn)離;在對(duì)新樣本進(jìn)行分類時(shí),將其投影到同樣的直線上,再根據(jù)投影點(diǎn)的位置來(lái)確定新樣本的類別。
審核編輯:黃飛
?










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論