 電子發燒友App
電子發燒友App


說到近些年的火熱名詞,“人工智能”必須榜上有名。隨著去年ChatGPT爆火出圈,“AI(Artificial Intelligence,人工智能)”屢次霸屏熱搜榜,并被英國詞典出版商柯林斯評為2023年的年度詞。
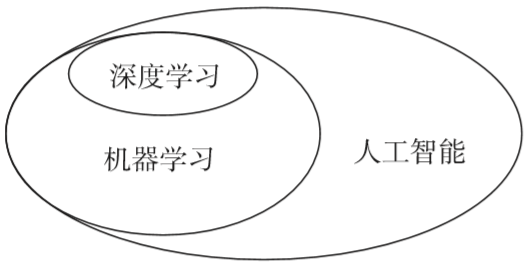
除了“人工智能”,我們還經常聽到“機器學習”、“深度學習”…… 這些術語都是啥意思?它們之間有什么關系呢?跟著文檔君來了解一下吧~~
人工智能——Artificial Intelligence
說到人工智能,大家的第一反應可能是科幻電影里那些擁有人類智慧的機器人,但實際上,人工智能可不僅僅是機器人哦。
人工智能是由約翰·麥卡錫(John McCarthy)于1956年提出來的,當時的定義是“制造智能機器的科學與工程”。 現在的人工智能是指“研究、開發用于模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學”。 聽起來有點繞是不是,文檔君來總結一下,人工智能就是讓機器能夠模擬人類的思維能力,讓機器能像人一樣去感知、思考甚至決策。 時至今日,人工智能已經不再是一門單純的學科,而是涉及了計算機、心理學、語言學、邏輯學、哲學等多個學科的交叉領域。
人工智能看起來是高深的科技,實際上是一個覆蓋范圍很廣的概念。我們的身邊,早就有了各種人工智能,例如:自動駕駛、人臉識別、智能機器人、機器翻譯等等。
面對多種多樣的人工智能,我們按照人工智能的實力,可將其分成三類:
弱人工智能(Artificial Narrow Intelligence,ANI)
擅長于某個方面的人工智能,只能執行特定的任務。例如,人臉識別系統就只能識別圖像,你要是問它明天天氣怎么樣,它可不知道怎么回答。
強人工智能(Artificial General Intelligence,AGI)
類似于人類級別的人工智能,能夠在多個領域表現出類似于人的智慧,能理解、學習和執行各種任務。目前,強人工智能尚未實現,仍是人工智能研究的長期目標。
超人工智能(Artificial Superintelligence,ASI)
超越人類智慧的人工智能,在各個領域都比人類聰明,可以執行任何智力任務并且在許多方面超越人類。盡管超人工智能在科幻作品中經常出現,但在實際中只是一個理論概念,目前還沒有實現的可能。
說到這里,文檔君想問大家,打敗圍棋世界冠軍的AlphaGo屬于什么人工智能呢?
AlphaGo雖然在圍棋上戰勝了人類,但是它的能力也僅限于圍棋,如果讓它下五子棋或飛行棋,它還是不行的,所以AlphaGo屬于弱人工智能。
機器學習——Machine Learning
前面提到,人工智能的目的是讓機器能夠像人一樣思考并決策,到底如何實現呢?
回想一下,我們剛出生時基本上什么都不會,經過了幾十年的學習,我們學會了各種知識、技能。 機器也是一樣的,要讓它會思考,就要讓它先學習,從經驗中總結規律,進而擁有一定的決策和辨別能力,這就是人工智能的核心——機器學習。
機器學習專門研究計算機怎樣模擬或實現人類的學習行為,通過學習獲取新的知識、技能,從而重新組織已有的知識結構,不斷改善自身性能。
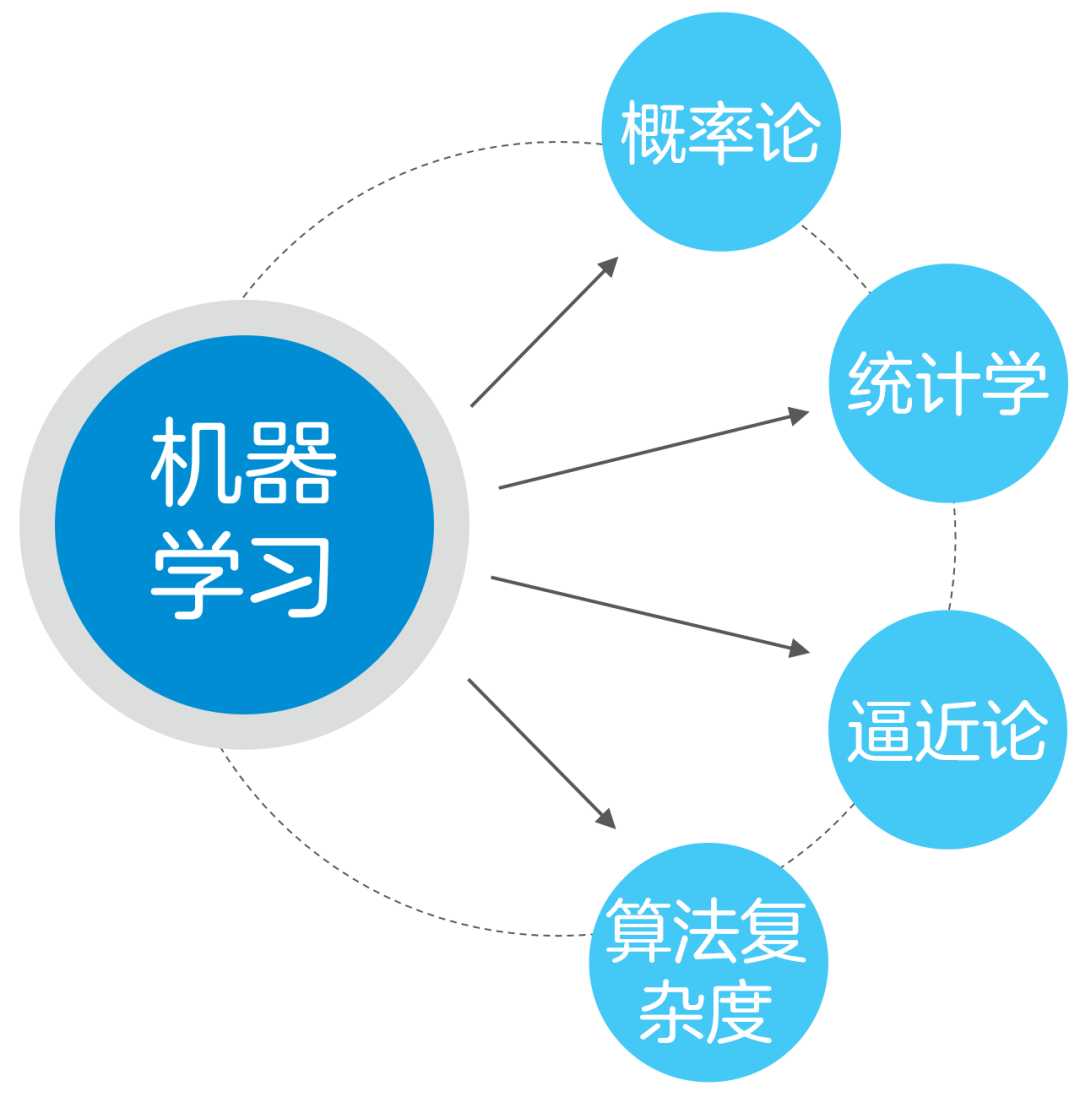
機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、算法復雜度理論等多門學科。
機器是怎樣學習的呢?我們先來看一下人的學習過程:
上課:學習理論知識,進行知識輸入
總結復習:通過復習,強化理解
梳理知識框架:整理知識,形成體系
課后作業:通過練習,進一步加深理解
每周測驗:檢查掌握情況
查漏補缺:改善學習方法
期末考試:檢查最終學習成果
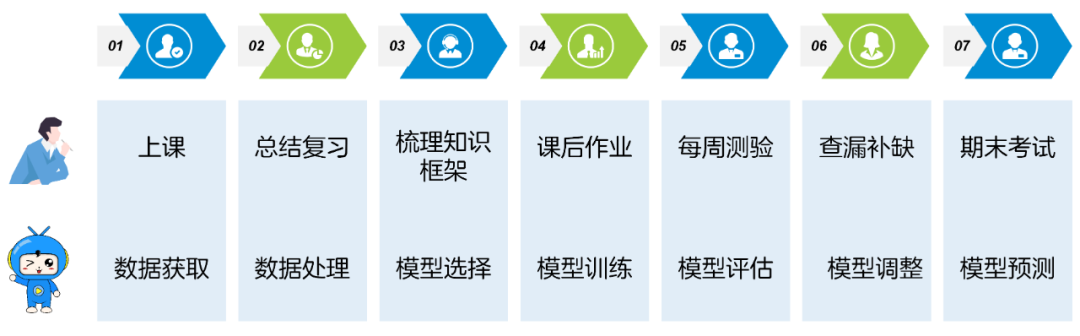
機器的學習過程也是類似的,包括以下7個步驟:
數據獲取:收集相關的數據
數據處理:對數據進行轉換,統一數據格式
模型選擇:選擇適合的算法
模型訓練:使用數據訓練模型,優化算法
模型評估:根據預測結果評估模型性能
模型調整:調整模型參數,優化模型性能
模型預測:對未知結果數據進行預測
簡而言之,機器學習就是從數據中通過算法自動歸納邏輯或規則,并根據歸納的結果與新數據來進行預測。
舉個例子,如果我們想讓計算機看到狗時能判斷出是狗,就需要給計算機展示大量狗的圖片,同時告訴它這就是狗。 經過大量的訓練,計算機會總結出一定的規律,當下次看到狗時,捕捉到對應的特征,得出“這是狗”的結論。 如果算法不夠完善,可能會把貓誤認為狗,這就需要計算機通過經驗數據自動改進算法,從而增強預測能力。
按照學習方式,機器學習可分為以下四類:
監督學習
從有標記的數據中學習,即數據中包含自變量和因變量,通過學習已知的輸入和輸出數據來進行預測,如分類任務和回歸任務。
分類任務:預測數據所屬的類別,如垃圾郵件檢測 、識別動植物類別等。
回歸任務:根據先前觀察到的數據預測數據,如房價預測,身高體重預測等。
無監督學習
分析沒有標簽的數據,即數據中只有自變量沒有因變量,發現數據的規律,如聚類、降維等。
聚類:把相似的東西聚在一起,并不關注這類東西是什么,如客戶分組。
降維:通過提取特征,將高維數據壓縮用低維表示,如將汽車的里程數和使用年限合并為磨損值。
半監督學習
訓練數據只有部分有標記,先使用無監督學習對數據進行處理,再用監督學習對模型進行訓練和預測。 例如手機可以識別同一個人的照片(無監督學習),當把同一個人的照片打上標簽后,之后新增的這個人的照片也會自動加上對應的標簽(監督學習)。
強化學習
通過與環境進行交互,根據獎勵或懲罰來優化算法,直到獲得最大獎勵,產生最優策略。例如掃地機器人撞到障礙物后,會優化清掃路徑。
深度學習——Deep Learning
通過上面的了解,相信大家對機器學習已經不陌生了。那么深度學習又是個啥?跟機器學習有什么關系?
深度學習是機器學習領域的一個新的研究方向,是一種通過多層神經網絡來學習和理解復雜數據的算法。 機器通過學習樣本數據的深層表示來學習復雜任務,最終能夠像人一樣具有分析學習能力,能夠識別文字、圖像和聲音等。
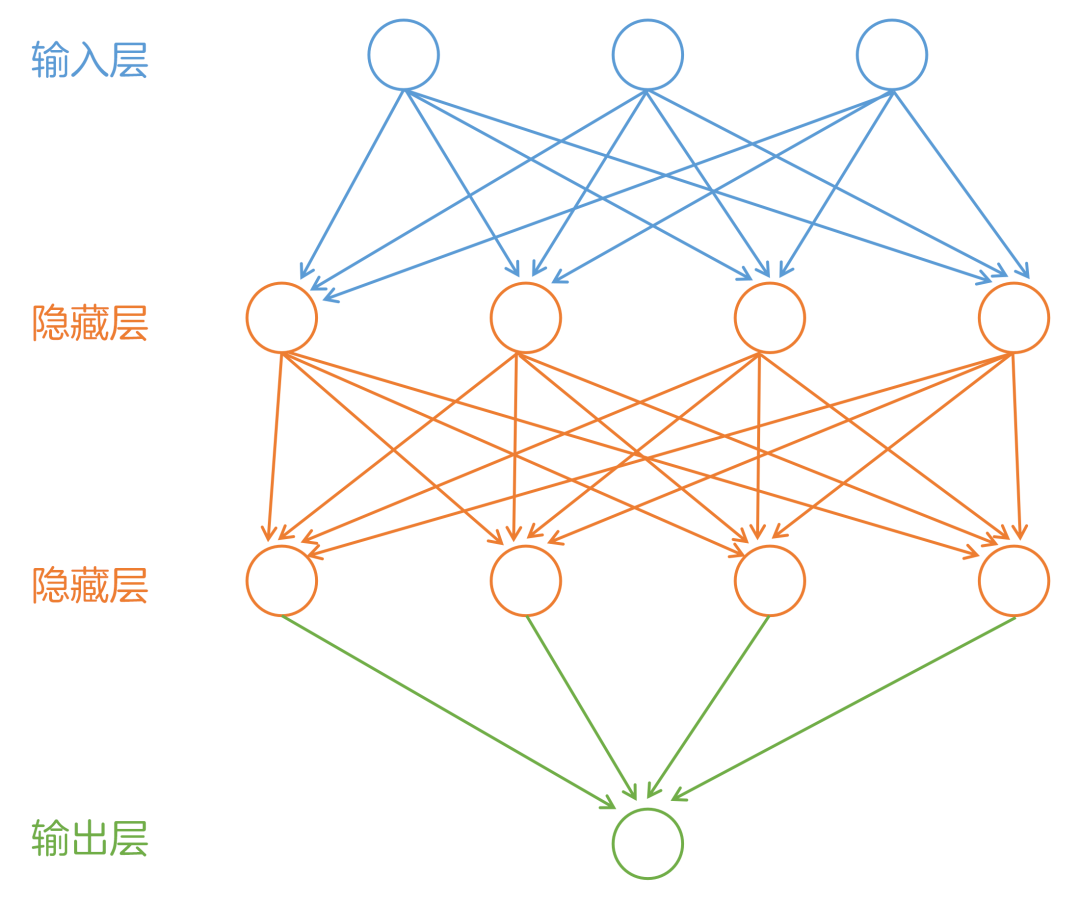
與傳統機器學習不同的是,深度學習使用了神經網絡結構,神經網絡的長度稱為模型的“深度”,因此基于神經網絡的學習被稱為“深度學習”。 神經網絡模擬了人類大腦的神經元網絡,神經元節點可以對數據進行處理和轉換。通過多層神經網絡,數據的特征可以被不斷地提取和抽象,從而使機器能更好地解決各種問題。
典型的深度學習算法有以下四種類型:
卷積神經網絡(Convolutional Neural Network,CNN):常用于圖像識別和分類任務。
遞歸神經網絡(Recurrent Neural Network,RNN):適用于處理序列數據,如自然語言處理。 ?
長短期記憶網絡(Long Short-Term Memory,LSTM):一種特殊的RNN結構,能夠更好地處理長序列數據。
生成對抗網絡(Generative Adversarial Network,GAN):用于生成新的數據,如圖像、音頻或文本。
在深度學習的加持下,人工智能得以快速發展,相信在不久的將來,我們將擁有一個全新的AI時代。
結束語
有用的知識又增加了,文檔君來淺淺總結一下吧:
“人工智能”是一個廣泛的概念,目的是讓機器像人一樣思考和執行任務。
“機器學習”是實現人工智能的一種方法,目的是從數據中學習規律,傳統的機器學習需要人工確定數據特征。
“深度學習”是機器學習的一個特定分支,基于神經網絡,能夠自動學習數據特征。
審核編輯:黃飛













 工商網監
工商網監
評論