 電子發(fā)燒友App
電子發(fā)燒友App


?本綜述探討了深度度量學(xué)習(xí)的意義、問題、背景、最新改進(jìn)和與深度學(xué)習(xí)的關(guān)系,詳述了其問題、樣本選擇和度量損失函數(shù),以及現(xiàn)狀和未來。??
1 介紹
如今,機(jī)器學(xué)習(xí)的應(yīng)用廣泛,包括人臉識別、醫(yī)療診斷等,為復(fù)雜問題和大量數(shù)據(jù)提供解決方案。機(jī)器學(xué)習(xí)算法能基于數(shù)據(jù)產(chǎn)生成功的分類模型,但每個(gè)數(shù)據(jù)都有其問題,需定義區(qū)別特征進(jìn)行正確分類。常用的機(jī)器學(xué)習(xí)算法包括k最近鄰、支持向量機(jī)和樸素貝葉斯分類器,但需注意特征加權(quán)和數(shù)據(jù)轉(zhuǎn)換。
度量學(xué)習(xí)(Metric Learning)是機(jī)器學(xué)習(xí)領(lǐng)域中的一個(gè)重要分支,它專注于學(xué)習(xí)數(shù)據(jù)集中樣本之間的相似性或距離度量。這種學(xué)習(xí)方法在許多機(jī)器學(xué)習(xí)應(yīng)用中發(fā)揮著關(guān)鍵作用,特別是在那些需要比較和區(qū)分不同樣本的任務(wù)中。
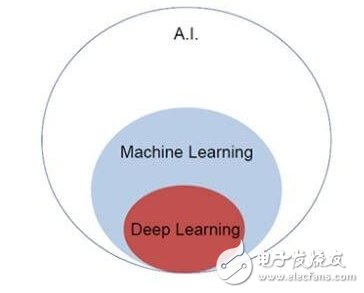
深度學(xué)習(xí)提供了新的數(shù)據(jù)表示,自動(dòng)提取特征,包括非線性結(jié)構(gòu)。深度學(xué)習(xí)和度量學(xué)習(xí)結(jié)合成深度度量學(xué)習(xí)(如圖1),基于樣本相似性原理。網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)和樣本選擇是深度度量學(xué)習(xí)成功的關(guān)鍵因素。
本綜述旨在探討深度度量學(xué)習(xí)的意義以及該領(lǐng)域所面臨的問題,介紹了其背景、最新改進(jìn)、與深度學(xué)習(xí)的關(guān)系,并詳細(xì)解釋了深度度量學(xué)習(xí)問題、樣本選擇和度量損失函數(shù),同時(shí)提出了深度度量學(xué)習(xí)的現(xiàn)狀和未來。
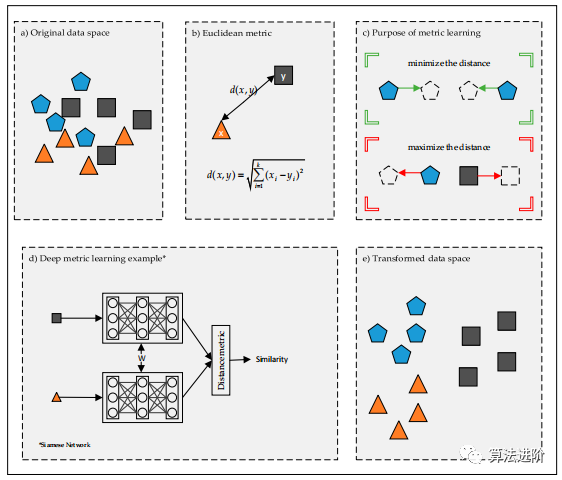
圖1 深度度量的學(xué)習(xí)
2 ?度量學(xué)習(xí)
每個(gè)數(shù)據(jù)集在分類和聚類方面都有特定的問題,需要一個(gè)良好的距離度量才能獲得成功的結(jié)果。度量學(xué)習(xí)方法通過分析數(shù)據(jù)提供了新的距離度量,提高了樣本數(shù)據(jù)的區(qū)分能力。其主要目的是學(xué)習(xí)一個(gè)新的度量,以減少同一類樣本之間的距離并增加不同類樣本之間的距離。這樣可以在不同對象之間創(chuàng)造更大的間隙,從而優(yōu)化分類和聚類的效果,如圖1c。
文獻(xiàn)中的度量學(xué)習(xí)研究與馬哈拉諾比斯距離度量直接相關(guān)。訓(xùn)練樣本X由N個(gè)d維向量組成,xi和xj之間的距離計(jì)算公式為馬哈拉諾比斯距離:
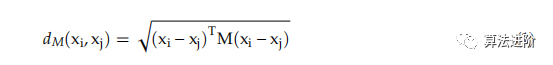
dM(xi, xj) 是一種距離度量,需滿足非負(fù)性、不可辨別性恒等性、對稱性和三角不等式。M必須是對稱且半正定的,其特征值或行列式需為正或零,分解如下:
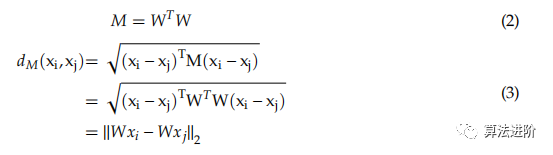
從式(3)可知,W具有線性變換性質(zhì)。因此,兩個(gè)樣本在變換空間中的歐幾里得距離等于原始空間中的馬哈拉諾比斯距離。這種線性變換體現(xiàn)了度量學(xué)習(xí)基礎(chǔ)設(shè)施的現(xiàn)實(shí)。
更好的數(shù)據(jù)表示能力有助于更準(zhǔn)確的分類和聚類預(yù)測。度量學(xué)習(xí)通過學(xué)習(xí)良好的距離度量,提供更有意義的數(shù)據(jù)表示。線性度量學(xué)習(xí)方法在轉(zhuǎn)換后的數(shù)據(jù)空間中提供更靈活的約束并提高學(xué)習(xí)性能,但捕獲非線性特征性能較差。核方法將問題轉(zhuǎn)移到非線性空間以實(shí)現(xiàn)更高性能,但可能產(chǎn)生過度擬合。深度度量學(xué)習(xí)提出了更緊湊的解決方案,克服了線性和非線性方法的問題。
3 ?深度度量學(xué)習(xí)
傳統(tǒng)機(jī)器學(xué)習(xí)受限于數(shù)據(jù)處理能力,需特征工程,如預(yù)處理和特征提取,需專業(yè)知識。而深度學(xué)習(xí)直接在分類結(jié)構(gòu)中學(xué)習(xí)更高層次數(shù)據(jù)。深度學(xué)習(xí)需要大量數(shù)據(jù),在小數(shù)據(jù)量下效果不佳,且訓(xùn)練時(shí)間長。NVIDIA推出cuDNNGPU加速庫,用于深度神經(jīng)網(wǎng)絡(luò)的高性能計(jì)算,許多深度學(xué)習(xí)框架都是在使用GPU的同時(shí)開發(fā)的。
數(shù)據(jù)分類的基本相似性度量包括EuclideanMahalanobis、Matusita、Bhattacharyya和Kullback-Leibler距離,但這些預(yù)定義度量在數(shù)據(jù)分類方面的能力有限。為解決這個(gè)問題,提出了基于馬哈拉諾比斯度量的方法,將數(shù)據(jù)分類為傳統(tǒng)的度量學(xué)習(xí),將數(shù)據(jù)變換到具有更高判別力的新特征空間。然而,這些方法不足以揭示數(shù)據(jù)的非線性知識。深度學(xué)習(xí)使用具有非線性結(jié)構(gòu)的激活函數(shù)來解決這個(gè)問題。
深度學(xué)習(xí)方法通常基于深層架構(gòu),而非新的數(shù)據(jù)表示空間中的距離度量。然而,基于距離的方法在深度學(xué)習(xí)中越來越受關(guān)注。深度度量學(xué)習(xí)的目的是增加相似樣本之間的距離,減少不同樣本之間的距離,這與樣本之間的距離直接相關(guān)。通過執(zhí)行這個(gè)過程,度量損失函數(shù)在深度學(xué)習(xí)中得到了好處。為了使來自相同類別的樣本彼此更接近,我們將來自不同類別的樣本彼此分開(圖2)。在對比損失的情況下,MNIST圖像數(shù)據(jù)集上的實(shí)驗(yàn)證明了該方法的有效性。
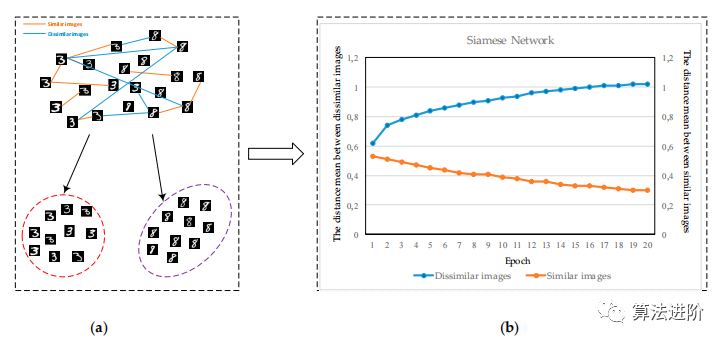
圖2 連體網(wǎng)絡(luò)的距離關(guān)系。(a) 期望的三位數(shù)和八位數(shù)手寫數(shù)據(jù)辨別,(b) Siamese網(wǎng)絡(luò)應(yīng)用于三位數(shù)和八位數(shù)的MNIST數(shù)據(jù)后
3.1 ?深度度量學(xué)習(xí)問題
深度度量學(xué)習(xí)通過深層架構(gòu)學(xué)習(xí)非線性子空間特征相似性,開發(fā)出基于問題的解決方案。其應(yīng)用廣泛,包括視頻理解、人員重新識別、醫(yī)療問題、3D建模、人臉驗(yàn)證和識別、簽名驗(yàn)證等。
視頻理解。理解視頻存在多種問題,如視頻注釋推薦、搜索等,可通過非度量空間提出解決方案。李等人首先提取音頻和視覺特征,然后提出基于三元組學(xué)習(xí)的深度神經(jīng)網(wǎng)絡(luò)嵌入模型,用于學(xué)習(xí)基于深度度量學(xué)習(xí)的度量,以促進(jìn)視頻監(jiān)控中的人類定位。該方法優(yōu)于其他方法,因?yàn)轭A(yù)定義的距離度量可能不足以滿足視覺任務(wù)。Hu等人使用基于距離度量的方法進(jìn)行視覺跟蹤,表明在度量空間中工作的優(yōu)勢。
人員重識別。人員重識別是機(jī)器學(xué)習(xí)的重要問題,旨在識別同一人在不同情況下拍攝的不同圖像。深度學(xué)習(xí)方法受到質(zhì)疑,因此需學(xué)習(xí)合適的距離度量來解決問題。深度度量學(xué)習(xí)使輸入圖像和變換后的特征空間之間能夠使用端到端學(xué)習(xí)。模型從兩層捆綁卷積和最大池化開始,計(jì)算交叉輸入鄰域差異,利用補(bǔ)丁求和屬性、交叉補(bǔ)丁屬性和softmax函數(shù)來識別同一個(gè)人或不同的人。另一項(xiàng)研究中,丁等人改進(jìn)了三元組生成方案并優(yōu)化了梯度下降算法,以實(shí)現(xiàn)三元組損失。
醫(yī)療問題。深度學(xué)習(xí)在醫(yī)學(xué)圖像診斷中應(yīng)用廣泛,解決分類、檢測、分割和配準(zhǔn)等問題。深度度量學(xué)習(xí)算法通過相似性方法提高數(shù)據(jù)表示級別,區(qū)分正常和異常圖像。與Triplet Network不同,ML2損失考慮嵌入空間全局結(jié)構(gòu)和重疊標(biāo)簽,為醫(yī)學(xué)圖像分析提供更高級別的數(shù)據(jù)。
3D建模。深度度量學(xué)習(xí)在3D形狀檢索中表現(xiàn)出色,通過共享權(quán)重和度量損失函數(shù),圖像草圖和3D形狀都能提高3D形狀檢索效果。基于CNN+Siamese網(wǎng)絡(luò)的模型在大型數(shù)據(jù)集上實(shí)現(xiàn)高效的3D圖像檢索,使用結(jié)合相關(guān)性和辨別損失的度量損失。訓(xùn)練過程中隱藏層也使用度量損失。一種新穎的損失函數(shù)結(jié)合三重態(tài)損失和中心損失,用于3D圖像檢索任務(wù)。三元組網(wǎng)絡(luò)模型用于檢測3D圖像的風(fēng)格,將三重態(tài)損失值與相似和不相似圖像的距離進(jìn)行比較。
人臉驗(yàn)證和識別。深度度量學(xué)習(xí)在人臉識別和驗(yàn)證方面取得突破,如胡等人提出的分層非線性變換模型,揭示人與人之間的親屬關(guān)系。FaceNet系統(tǒng)使用在線三元組學(xué)習(xí)模型,關(guān)注歐幾里德空間下的人臉相似性,處理驗(yàn)證、人臉識別和人臉聚類等任務(wù)。此外,還有面部表情識別和面部年齡估計(jì)等研究。
深度學(xué)習(xí)在文本理解和信息檢索領(lǐng)域有廣泛研究,如Mueller和Thyagarajan的Siamese網(wǎng)絡(luò)識別語義相似性,貝納吉巴等人利用回歸函數(shù)訓(xùn)練網(wǎng)絡(luò)模型,以及基于依賴關(guān)系的Siamese LSTM網(wǎng)絡(luò)模型。此外,還有研究旨在學(xué)習(xí)句子之間的主題相似性,通過生成弱監(jiān)督的三元組句子,使用Triplet網(wǎng)絡(luò)對高質(zhì)量句子嵌入的維基百科句子進(jìn)行聚類。
深度度量學(xué)習(xí)在音頻信號處理領(lǐng)域取得成果,如Triplet和Quadruple網(wǎng)絡(luò)用于說話人二值化。不同的采樣策略和裕度參數(shù)對二值化性能有影響。半硬負(fù)挖掘在計(jì)算機(jī)視覺應(yīng)用中成功,但在說話人二值化中僅在固定參數(shù)和三元組損失情況下有效。王等人使用原型網(wǎng)絡(luò)損失和三元組損失進(jìn)行說話人驗(yàn)證和識別任務(wù),在兩個(gè)數(shù)據(jù)集中獲得成功結(jié)果,其中原型網(wǎng)絡(luò)損失效果更好,訓(xùn)練時(shí)間更快。
深度度量學(xué)習(xí)在音樂相似性、擁擠回歸、相似區(qū)域搜索、體積圖像識別、實(shí)例分割、邊緣檢測、全色銳化等領(lǐng)域有廣泛應(yīng)用,其高性能為文獻(xiàn)做出了貢獻(xiàn)。從學(xué)術(shù)出版物數(shù)量來看,如圖3,深度度量學(xué)習(xí)越來越受到關(guān)注。
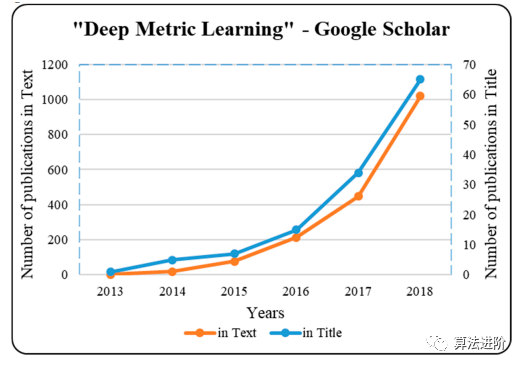
圖3 深度度量學(xué)習(xí)的學(xué)術(shù)出版物數(shù)量
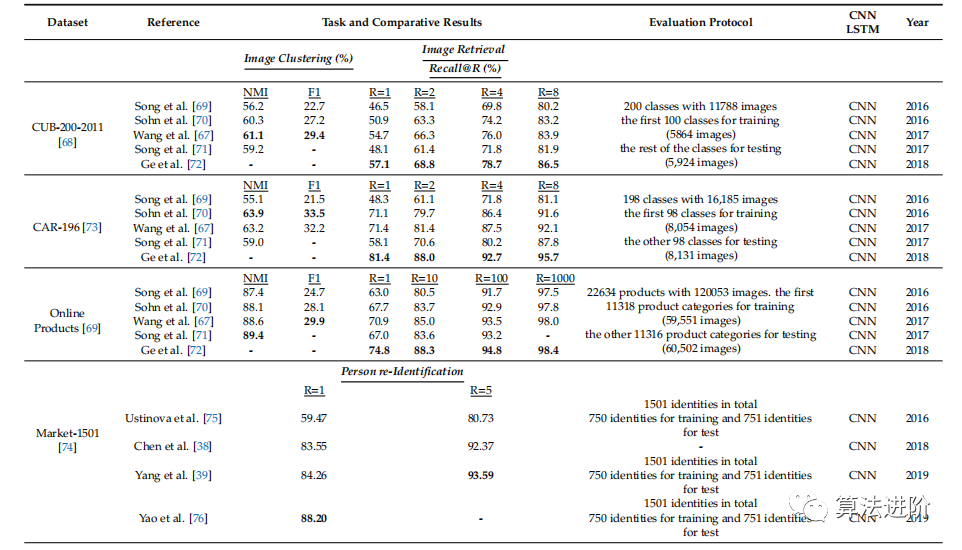
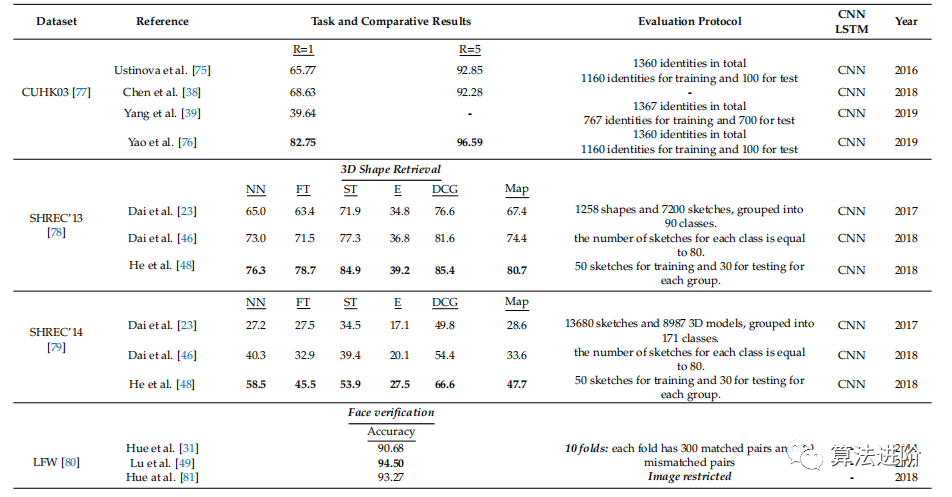
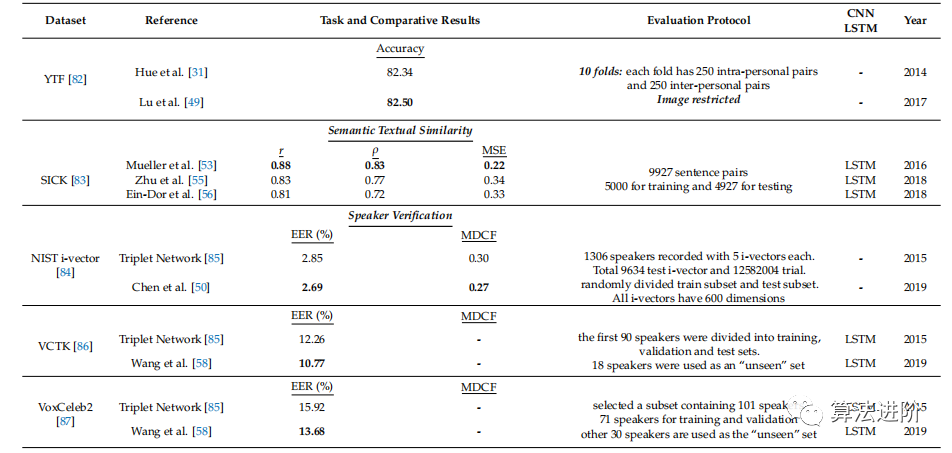
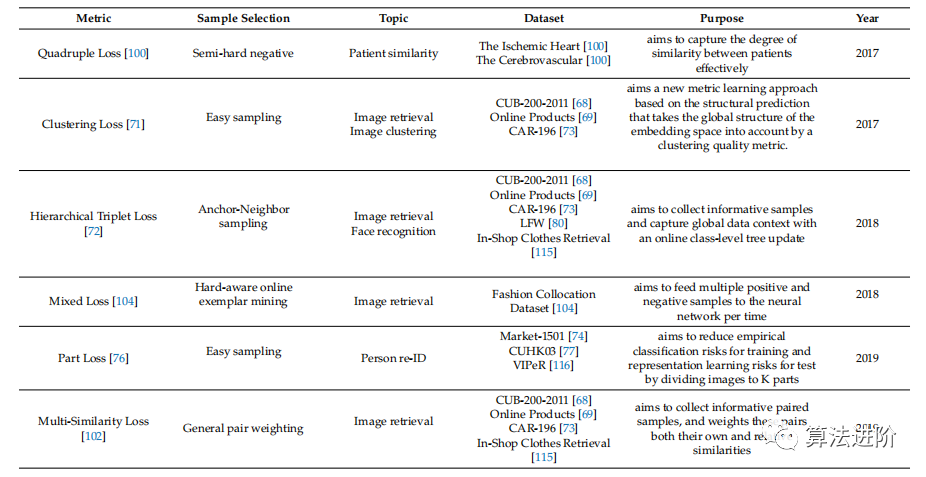
深度度量學(xué)習(xí)在各種主題上取得了顯著成果(表1),如圖像聚類、圖像檢索、3D形狀檢索和語義文本相似性任務(wù)。評估指標(biāo)包括F1、歸一化互信息(NMI)、召回@R(排名精度)、準(zhǔn)確性、第一層(FT)、最近鄰(NN)、Emeasure(E)、第二層(ST)、折扣累積增益(DCG)和平均精度(mAP)、皮爾遜相關(guān)性(r)、斯皮爾曼相關(guān)性(ρ)和均方誤差(MSE)、等錯(cuò)誤率(EER)和最小決策成本函數(shù)(MDCF)。
表1 深度度量學(xué)習(xí)問題的基準(zhǔn)數(shù)據(jù)集比較
3.2 ?樣本選擇
深度度量學(xué)習(xí)由信息輸入樣本、網(wǎng)絡(luò)模型結(jié)構(gòu)和度量損失函數(shù)組成。信息樣本選擇對分類和聚類至關(guān)重要,影響網(wǎng)絡(luò)成功率和訓(xùn)練速度。隨機(jī)選擇正負(fù)對象對是最簡單的訓(xùn)練樣本對比損失方法,但在網(wǎng)絡(luò)性能達(dá)到一定水平后,學(xué)習(xí)過程可能會(huì)減慢。硬負(fù)挖掘和三元組網(wǎng)絡(luò)等方法可以提高網(wǎng)絡(luò)性能,但簡單的三元組可能效果不佳。因此,使用信息豐富的樣本三元組可以提供更好的訓(xùn)練模型。
硬負(fù)樣本是假陽性樣本,半硬負(fù)挖掘?qū)ふ疫吔鐑?nèi)負(fù)樣本,與硬負(fù)樣本相比,負(fù)樣本距離錨樣本更遠(yuǎn)。三元組挖掘根據(jù)錨點(diǎn)、正樣本和負(fù)樣本之間的距離進(jìn)行負(fù)挖掘,如圖 4 所示。負(fù)樣本距離錨點(diǎn)太近會(huì)導(dǎo)致梯度高方差和低信噪比,建議使用距離加權(quán)采樣避免噪聲樣本。負(fù)類挖掘使用每個(gè)類樣本之一作為三重網(wǎng)絡(luò)的負(fù)樣本,使用貪婪搜索策略選擇多個(gè)負(fù)樣本。
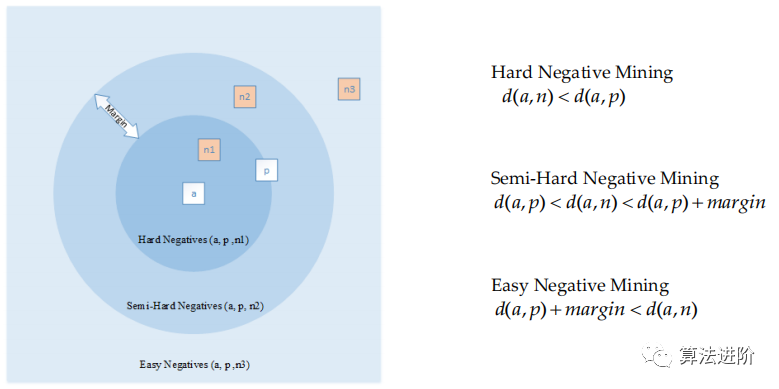
圖4 負(fù)挖掘
總之,即使有良好的數(shù)學(xué)模型和架構(gòu),網(wǎng)絡(luò)的學(xué)習(xí)能力也會(huì)受到樣本辨別能力的限制。因此,應(yīng)向網(wǎng)絡(luò)呈現(xiàn)有區(qū)別的訓(xùn)練樣例,以實(shí)現(xiàn)更好的學(xué)習(xí)和表示。樣本選擇作為預(yù)處理步驟可以提高網(wǎng)絡(luò)模型的成功率。深度度量學(xué)習(xí)中的負(fù)挖掘研究具有高影響價(jià)值。選擇信息豐富的樣本可以避免過度擬合,提高學(xué)習(xí)速度,并減少資源浪費(fèi)。因此,在選擇信息豐富的樣本后,可以實(shí)現(xiàn)性能的顯著提高。
3.3 ?深度度量學(xué)習(xí)的損失函數(shù)
本節(jié)將介紹用于應(yīng)用深度度量學(xué)習(xí)的損失函數(shù),包括其使用方式和差異。這些函數(shù)幫助我們通過調(diào)整對象相似性來優(yōu)化特征表示。
Siamese網(wǎng)絡(luò)最初用于簽名驗(yàn)證,基于從基于能量的模型的判別學(xué)習(xí)框架中學(xué)習(xí)。該方法將兩張相同圖像放入連體網(wǎng)絡(luò),通過學(xué)習(xí)獲得二進(jìn)制值,判斷圖像是否屬于同一類。Siamese網(wǎng)絡(luò)作為度量學(xué)習(xí)方法,接收成對圖像訓(xùn)練網(wǎng)絡(luò)模型。圖像對之間的距離通過損失函數(shù)計(jì)算(等式(5))。對比損失使Siamese網(wǎng)絡(luò)受益,啟發(fā)了深度度量學(xué)習(xí)領(lǐng)域的研究人員。Siamese網(wǎng)絡(luò)可以最大化或最小化對象之間的距離以提高分類性能。共享權(quán)重用于在深度度量學(xué)習(xí)中獲得圖像中有意義的模式,如圖 5 所示,對神經(jīng)網(wǎng)絡(luò)性能產(chǎn)生積極影響。Siamese網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)可以結(jié)合,同時(shí)從直接圖像像素、顏色和紋理信息進(jìn)行相似性學(xué)習(xí)。深度度量學(xué)習(xí)模型結(jié)合兩個(gè)Siamese卷積神經(jīng)網(wǎng)絡(luò)和馬哈拉諾比斯度量進(jìn)行行人重新識別。
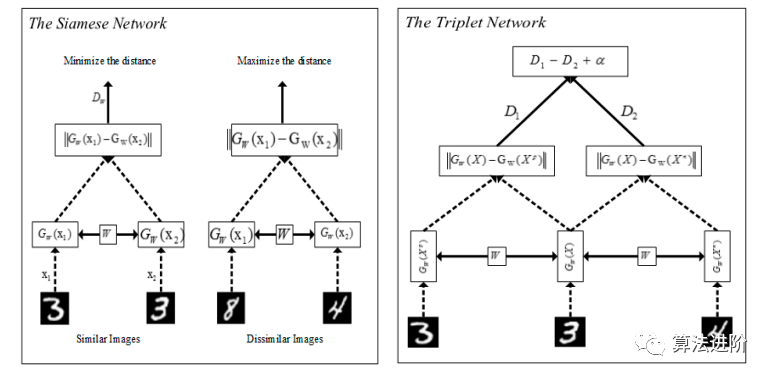
圖5 Siamese 網(wǎng)絡(luò)和 Triplet 網(wǎng)絡(luò)
Triplet網(wǎng)絡(luò)受Siamese網(wǎng)絡(luò)啟發(fā),包含三個(gè)對象,形成正、負(fù)和錨樣本。這種網(wǎng)絡(luò)利用歐幾里得空間來比較模式識別過程中的對象,與度量學(xué)習(xí)緊密相關(guān)。從等式(6)中可以看出,三元組損失關(guān)注相同類和不同類的成對樣本相似性,通過比較成對樣本的相似性進(jìn)行分類(圖 6)。三元組網(wǎng)絡(luò)不僅利用類內(nèi)和類間關(guān)系,還提供了更高的區(qū)分能力。分層三元組損失通過在線自適應(yīng)樹更新提高了網(wǎng)絡(luò)的性能。另外,角度損失是一種新穎的方法,側(cè)重于三重三角形負(fù)點(diǎn)處的角度約束,將負(fù)點(diǎn)推離正簇的中心,使正點(diǎn)彼此靠近,同時(shí)使用作為旋轉(zhuǎn)和尺度不變度量的角度(等式(8))。四倍損失在每個(gè)訓(xùn)練批次中使用四倍樣本,以獲得更好的接近度。直方圖損失使用四元組訓(xùn)練樣本,利用直方圖來計(jì)算正負(fù)對的相似度分布,無需調(diào)整參數(shù),在人員重新識別數(shù)據(jù)集的實(shí)驗(yàn)研究中獲得了優(yōu)異的結(jié)果。部分損失旨在使用不同的身體部位進(jìn)行評估,將圖像分為五個(gè)部分,計(jì)算每個(gè)部分的部分損失值。
損失函數(shù)是深度度量學(xué)習(xí)模型的關(guān)鍵,嵌入空間中配對樣本的新表示需要考慮一些損失函數(shù)。例如,一對輸入樣本DW(X1, X2)的距離為:
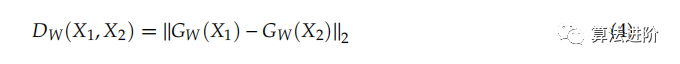
其中,GW(X1) 和 GW(X2) 是新表示的輸入樣本,DW用于計(jì)算損失函數(shù)中兩個(gè)輸入之間的距離。用于計(jì)算 Siamese 網(wǎng)絡(luò)模型中損失函數(shù)的 LContrastive 是:
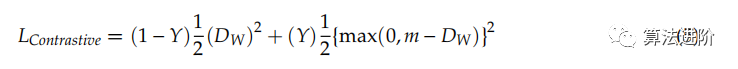
其中Y是標(biāo)簽值,如果輸入來自同一類則Y=1,否則Y=0。m是LContrastive中的margin值。三元組網(wǎng)絡(luò)有三個(gè)輸入:錨輸入X、與X相似的X_p、與X不同的X_n。LTriplet損失是:
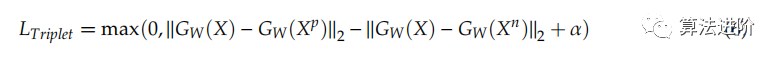
其中 α 是裕度值。四元網(wǎng)絡(luò)模型還具有與三元網(wǎng)絡(luò)模型不同的另一個(gè)輸入X。X s 類似于 X 輸入,如 X p 輸入。四倍損失 LQuadruple 是:
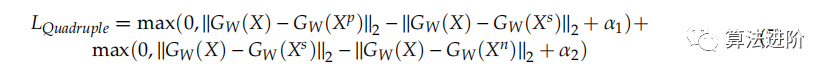
角度損失考慮了樣本之間的角度關(guān)系。角度損失 LAngular 是:
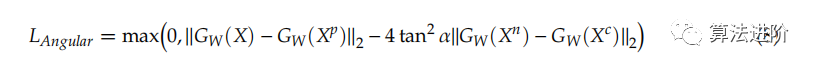
其中 X c 位于 X 和 X p 的中間。Xc 是:

傳統(tǒng)深度結(jié)構(gòu)度量學(xué)習(xí)模型,如Siamese和Triplet Networks,忽略了訓(xùn)練樣本的結(jié)構(gòu)信息。深度結(jié)構(gòu)度量學(xué)習(xí)方法通過深度網(wǎng)絡(luò)中的特殊結(jié)構(gòu)化損失將成對距離向量提升為成對距離矩陣,充分利用上下文信息。Sohn提出了多類N對損失解決Siamese和Triplet網(wǎng)絡(luò)收斂速度慢和局部最優(yōu)性差的問題。Npair loss受益于N-1個(gè)負(fù)類樣本來比較錨樣本(圖 6e)。多重相似性損失同時(shí)考慮了自相似性和相對相似性,使模型更有效地收集和加權(quán)信息豐富的樣本對。
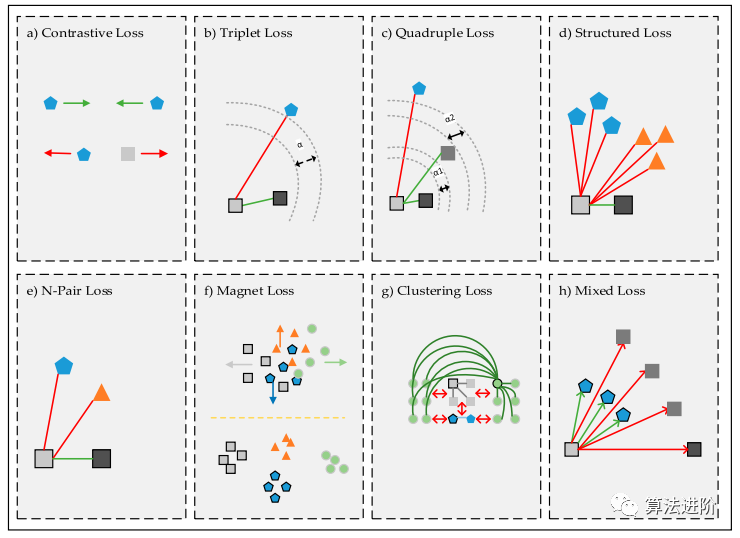
圖6?度量損失函數(shù)
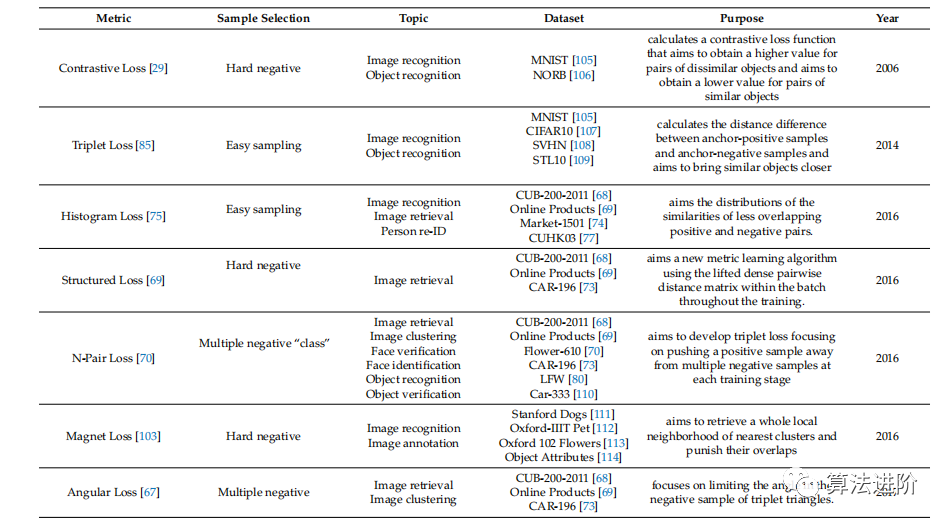
在訓(xùn)練階段之前,必須為Siamese、Triplet和n-double網(wǎng)絡(luò)準(zhǔn)備訓(xùn)練數(shù)據(jù),此過程需要更多磁盤空間并且非常耗時(shí)。宋等人提出了一種新的深度度量學(xué)習(xí)方法,使用聚類損失將樣本聚集在一個(gè)聚類中(圖 6g),防止不同的簇相互接近。里佩爾等人強(qiáng)調(diào)三元組損失一次評估一個(gè)三元組樣本來訓(xùn)練數(shù)據(jù)集,減少網(wǎng)絡(luò)的學(xué)習(xí)時(shí)間。然而,這種方法會(huì)導(dǎo)致性能不佳和培訓(xùn)不足。因此,他們建議磁體損失,這會(huì)懲罰簇重疊并評估簇中最近的鄰居以分離多個(gè)簇。所提出的方法具有局部區(qū)分度,并且與優(yōu)化過程全局一致。混合損失受到三元組損失的啟發(fā),除了anchor和負(fù)樣本之外,還使用三個(gè)正樣本和三個(gè)負(fù)樣本來建立樣本之間的相似關(guān)系。圖6h說明了在使用局部鄰域時(shí)相似樣本如何接近最近的集群。表2詳細(xì)總結(jié)了文獻(xiàn)中最先進(jìn)的損失指標(biāo)。
表2 損失指標(biāo)
4 ?討論
深度度量學(xué)習(xí)(DML)用于人臉驗(yàn)證、識別、人員重識別和3D形狀檢索,表1顯示,DML對類別多、樣本少的任務(wù)效果顯著。DML由度量損失函數(shù)、采樣策略和網(wǎng)絡(luò)結(jié)構(gòu)組成,如Siamese、Triplet和Quadruple網(wǎng)絡(luò)。度量損失函數(shù)如對比損失、三重?fù)p失、四重?fù)p失和n對損失,增加數(shù)據(jù)樣本大小,但可能導(dǎo)致訓(xùn)練時(shí)間過長和內(nèi)存消耗大。硬負(fù)挖掘和半硬負(fù)挖掘提供信息豐富的樣本,而正確的采樣策略對快速收斂至關(guān)重要。聚類損失作為度量函數(shù),無需數(shù)據(jù)準(zhǔn)備步驟。DML通常在GPU上執(zhí)行,但某些策略也可用于CPU集群以使用大批量數(shù)據(jù)。DML高度依賴數(shù)據(jù),度量損失函數(shù)可能無法提供快速收斂。預(yù)訓(xùn)練網(wǎng)絡(luò)模型的權(quán)重有助于嵌入空間快速收斂和更具辨別力的學(xué)習(xí)。
5 ?結(jié)論
深度度量學(xué)習(xí)是近年來的研究熱點(diǎn),旨在學(xué)習(xí)相似性度量,用于計(jì)算對象間的相似性或不相似性。目前,Siamese和Triplet網(wǎng)絡(luò)在圖像、視頻、文本和音頻任務(wù)中表現(xiàn)出高效性。深度度量學(xué)習(xí)研究包括信息輸入樣本、網(wǎng)絡(luò)模型結(jié)構(gòu)和度量損失函數(shù)。未來研究方向包括優(yōu)化采樣策略、共享權(quán)重和度量損失函數(shù)的組合。雖然研究已取得進(jìn)展,但仍有許多方面有待探索,如現(xiàn)有方法的缺點(diǎn)和局部特征與全局特征的結(jié)合。
審核編輯:黃飛
?













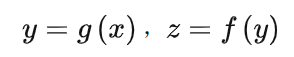











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論