 電子發燒友App
電子發燒友App


人群的監控與監測已經成為當前的一個重要領域。政府和安全部門都已經開始尋求在公共場所智能監測人群的更先進的方式,從而避免在來不及采取行動之前檢測到任何異常活動。但是在有效達成這一目的之前還需要克服一些障礙。例如,如果需要一天 24 小時同時監測整個城市里所有可能的人群活動,僅靠全人工監測是不可能的,尤其在安裝有數千部 CCTV 攝像頭的情況下更是如此。
這個問題的解決方案在于開發全新的智能攝像頭或視覺系統,借助先進的視頻分析技術自動監測人群的活動,從而能夠立即向中央控制站報告任何異常事件。
設計這種智能攝像頭/視覺系統不僅需要標準的成像傳感器和光學設備,還需要高性能視頻處理器來執行視頻分析工作。使用這種功能強大的板載視頻處理器的原因在于先進視頻分析技術具有較高的處理要求,大多數此類技術通常會使用計算密集型視頻處理算法。
FPGA 非常適合于此類高性能要求的應用。借助賽靈思 Vivado? Design Suite 中高層次綜合 (HLS) 功能實現的 UltraFast? 設計方法,現在可以為 FPGA 輕松創建理想的高性能設計。此外,賽靈思 MicroBlaze? 等嵌入式處理器與 FPGA 可重配置邏輯的完美融合,讓用戶現在能夠將具有復雜控制流的應用方便地移植到 FPGA 上。
鑒于這種情況,我們使用 Vivado HLS、賽靈思嵌入式開發套件 (EDK) 和 ISE? Design Suite 中基于軟件的EDA工具,設計出一種用于人群運動分類和監測系統的原型。這種設計方法基于我們所認為的軟件控制和硬件加速架構。我們的設計采用低成本的賽靈思 Spartan?-6 LX45 FPGA。我們在較短時間內即完成了總體系統設計,其在設計的實時性能、低成本和高靈活性方面均展現出頗有前景的結果。
利用加權絕對差之和 (SWAD),我們計算出圖像上分布的 900 多個運動向量。
系統設計
總體系統設計分兩個階段完成。第一階段是開發人群運動分類算法。在這個算法的驗證完成后,接下來是把它實現到 FPGA 中。在開發的第二階段,我們主要關注基于 FPGA 的實時視頻處理應用的架構設計方面。具體工作包括開發實時視頻流水線、開發硬件加速器,最后將二者集成并實現到算法控制和數據流中,從而完成系統設計。
下面介紹每個開發階段,首先從簡要介紹算法設計開始,然后詳細介紹如何將算法實現到 FPGA 平臺上。
算法設計
就人群監視和監控而言,文獻中提出了多種算法。大多數此類算法從在人群場景中檢測(或布置)特征點開始,然后隨時間推移跟蹤這些特征點,采集運動統計數據。隨后把這些運動統計數據投射到一些之前預先計算好的運動模型上,用來預測任何異常活動 [1]。進一步改進包括聚集特征點,跟蹤這些集群而非單獨的特征點[2]。
本文的人群運動分類算法基于相同的概念,除了我們優先使用模板匹配方法進行運動估計,而不是采用 Kanade-Lucas- Tomasi (KLT) 特征跟蹤器等傳統方法。該模板匹配方法經驗證表明,增加一些計算量能顯著改善低對比度或對比度不斷變化情況下的運動估計。
為將這一方法用于運動估計,我們將視頻幀劃分為更小矩形貼片組成的網格,然后使用基于加權絕對差之和 (SWAD) 的方法對每個貼片的當前圖像和之前圖像進行運動計算。每個貼片相應地提供一個運動向量,用于說明該特定位置兩幀之間的運動范圍和方向。結果就是需要在整個圖像上計算超過 900 個運動向量。計算這些運動向量涉及的具體步驟如圖1所示。
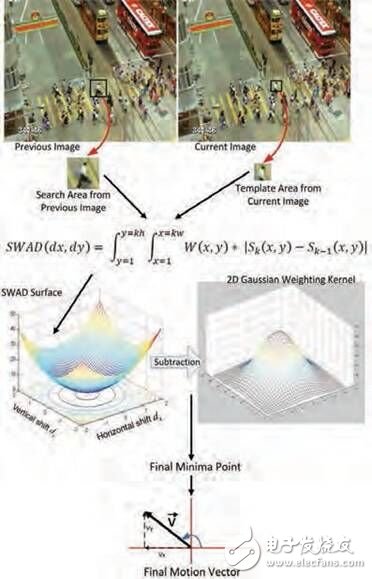
圖 1:計算運動向量的步驟,從圖像采集開始(上)
此外,我們使用加權高斯內核實現圖像中遮擋區和零對比度區的可靠性。而且,用于計算一個運動向量的一個貼片處理工作獨立于其它貼片的處理工作,因此該方法非常適合使用 FPGA 上的并行實現方案。
在計算完整個圖像上的運動向量后,該算法隨即計算它們的統計屬性。這些屬性包括平均運動向量長度、運動向量數量、運動的主導方向和類似指標。
另外我們還計算了運動向量方向的 360 度柱狀圖,進一步分析其標準偏差、平均偏差和偏差系數等屬性。這些統計屬性隨后被投射到預先計算好的運動模型上,從而將當前運動分類到幾大類別之一。隨后我們運用多個幀來解釋這些統計屬性,從而確認分類結果。
預先計算好的運動模型采用加權決策樹分類器的形式構建,其充分考慮了這些統計屬性來對所觀察到的運動進行分類。例如,如果觀察到運動速度快而且場景中有動量突變,同時運動方向隨機或超出圖像平面,就可以分類為可能的恐慌情況。該算法的開發工作使用微軟 Visual C++ 配合 OpenCV 庫完成。算法的完整演示請參閱本文文末提供的 Web 鏈接。
FPGA 實現方案
系統設計的第二階段是該算法的 FPGA 實現過程。 這一步實現工作有它自己的設計難題,例如 FPGA 設計現在要包括視頻輸入/輸出和幀緩存。此外,有限的資源和可用性能可能需要必要的設計優化。
鑒于這些設計特點和其它架構考慮,整個 FPGA 實現方案被分為三個部分。第一部分是在 FPGA 上開發通用的實時視頻流水線,用于處理必要的視頻輸入/輸出和幀緩存。第二部分是開發算法專用硬件加速器。最后在設計的第三階段,我們把它們集成到一起,實現算法控制和數據流。這就完成了整個基于 FPGA 的系統設計。
下面對這個過程的每一階段進行更詳細的介紹。
實時視頻流水線
在為 FPGA 平臺開發任何視頻處理應用時,實時視頻流水線都是最重要的構建模塊。這個流水線對用戶隱藏了視頻輸入/輸出和幀緩存相關的復雜存儲器管理工作,而是提供了簡單的訪問界面以供用戶處理視頻幀數據。
雖然在這方面目前有幾種先進的、商業許可的視頻流水線[3],我們選擇構建針對這個用途的定制視頻流水線。我們基于賽靈思 EDK 構建該流水線,使用定制視頻采集/顯示端口處理視頻輸入/輸出數據。這個流水線也可以方便地進行配置,從而用于其它賽靈思 FPGA 系列。
視頻采集端口負責解碼來自視頻 ADC 的輸入視頻流數據并在本地緩存。隨后該數據被轉發至主存儲器,用于創建視頻幀。與此類似,視頻顯示端口負責對本地緩存中存儲的視頻幀數據進行編碼,然后將其轉發到視頻 DAC 中供顯示使用。視頻輸入輸出端口連接到 MicroBlaze 主機處理器的主外設總線,該處理器負責處理與主存儲器之間的視頻數據流量。
視頻端口能夠生成中斷,以通知 MicroBlaze 處理器在視頻輸入端口有可用的新數據或視頻輸入端口需要新數據。兩種視頻端口采用“往復式”緩存管理方案,這樣即使是 MicroBlaze 處理器都無法立即響應視頻端口,也不會發生緩存溢出或欠載。圖2所示是視頻端口與 MicroBlaze 處理器之間的互聯。
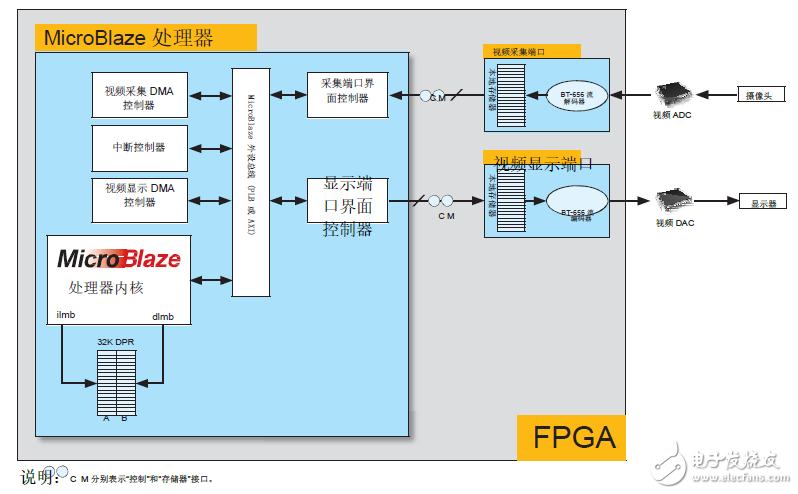
圖 2:視頻端口及其互聯
視頻端口設計用于檢測和生成視頻行數量、場 ID(如果是隔行視頻)和視頻輸入/輸出流中的其它控制信息。當有足夠數量的視頻數據被視頻輸入端口緩存,或當視頻顯示端口請求的數據達到足夠數量時,該信息就會通過視頻端口的中斷服務例程 (ISR) 傳遞給 MicroBlaze 處理器。這些服務例程相應地通過 DMA 完成視頻端口本地存儲器和主存儲器之間的視頻數據傳輸。
除了視頻端口 ISR,還有我們稱之為“視頻幀隊列 API”的一套高級視頻幀隊列管理功能在這些 ISR 和用戶層應用之間工作。該 API 負責維持多個采集幀和顯示幀的隊列,以支持雙幀或三幀緩存方案。在MicroBlaze上運行的用戶應用能輕松獲得視頻采集幀,或利用“視頻幀隊列 API”功能提供視頻顯示幀。圖 3 顯示了在層級結構中各級別的相關功能。
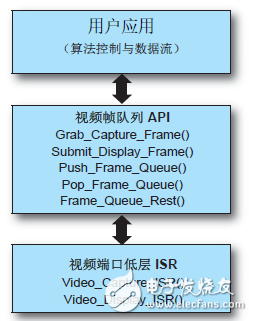
圖 3:視頻端口 ISR 和視頻幀隊列 API 功能
將 MicroBlaze 用作主機處理器以連接系統中的各個構建模塊能產生眾多優勢。例如我們可以使用 MicroBlaze 方便地連接各種外部存儲器(SRAM、SDRAM 等),加載或存儲來自視頻端口的視頻幀數據。類似地,我們可以使用 EDK 中的 DMA 控制器,在視頻端口和主存儲器之間傳輸視頻數據。此外,我們還可用 MicroBlaze 處理器以同樣方式連接定制硬件加速器。
這些“視頻幀隊列 API”功能加上視頻端口 ISR 和視頻輸入輸出端口讓設計中的視頻處理流水線的構造更加完善。圖 4 所示的是使用 FPGA 上的本視頻流水線采集、處理和顯示實際的視頻幀。它還顯示了通過計算出的運動向量縮小視圖實現的畫中畫功能。
圖 4:右下被運動向量網格覆蓋的、經過 FPGA 處理后的實際幀
基于 Vivado HLS 的硬件加速器
在前文介紹的人群運動分類算法中,最為耗時、計算最密集的工作是計算運動向量。另一項系統工作——進行分類——因不涉及像素級的處理,非常簡單而且易于實現。注意到設計的這個方面,我們為計算運動向量構建了一個硬件加速器。我們借助賽靈思 Vivado HLS,用 C/C++ 語言在 RTL 中對該加速器進行了設計、測試和綜合。
Vivado 生成的 RTL 代碼的關鍵特征之一是其在很大程度上已經過了精心優化。Vivado HSL 把陣列存取(例如存儲在陣列中的像素數據)綜合到存儲器接口中,通過分析代碼自動生成所需的地址。Vivado HSL 還可分析預先計算好的偏移和常量,從而非常快速地執行所謂的“跨步式”存儲器訪問。跨步式存儲器訪問從圖像的多行數據訪問開始(就如同在 2D 卷積中)。
設計基于 Vivado 的加速器的主要考慮因素是并行處理運動向量的計算,最大限度地提高從主存儲器中的數據讀取。為此目的,我們使用八個 Block RAM 并行加載和存儲視頻幀數據。硬件加速器的內核能夠并行計算四個運動向量,而且在計算中它會用到所有八個 Block RAM。從主存儲器傳輸到這些 Block RAM 的數據由 MicroBlaze 通過 DMA 加以控制。
Vivado HLS 生成的硬件加速器具有部分自動生成的握手信號,這些信號對于啟停硬件加速器必不可少。 這些握手信號包含“啟動”、“繁忙”、“閑置”、“完成”等標志。這些標志通過 GPIO 傳送到 MicroBlaze 處理器以完成握手。圖 5 所示為該硬件加速器、八個 Block RAM 和 MicroBlaze 處理器主外設總線之間的互聯。
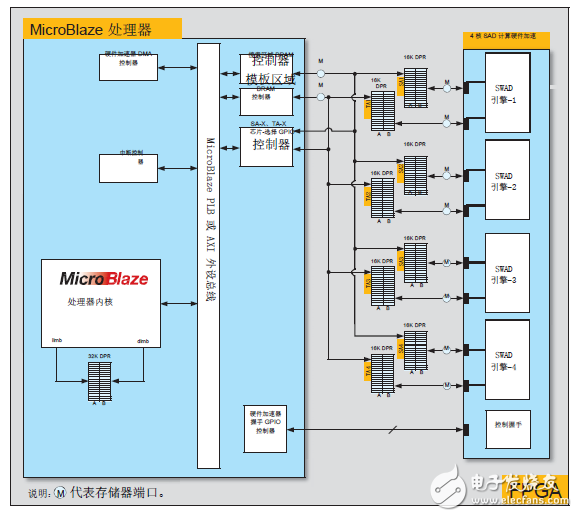
圖 5:基于 Vivado HLS 的硬件加速器及其互聯
圖 5 中分別被命名為 SA1、TA1 到 SA4、TA4 的這些 Block RAM,每個的容量為 16KB。每對 SA1、TA1 到 SA4、TA4 能夠保存計算一個完整行的運動向量所需的數據。因此硬件加速器在完成運行后,會輸出四行運動向量寫回到相同的 Block RAM 存儲器中。這些計算完的運動向量隨即由 MicroBlaze 處理器讀回,然后把結果以運動向量網格的形式復制到自己的主存儲器中。(圖 4 所示的是被硬件加速器計算出的運動向量網格覆蓋的實際幀)
該硬件加速器在 200MHz 頻率下工作,計算整個圖像的運動向量所需的全部處理任務能夠在不足 10 毫秒內完成,包括與存儲器之間的所有數據往來傳輸。
算法控制和數據流
在視頻流水線和硬件加速器開發就緒后,完成該系統的最后一步是把這兩個單元與 MicroBlaze 主機處理器集成,并使用賽靈思軟件開發套件 (SDK_,用 C/C++ 實現用戶層應用的算法控制和數據流。 在賽靈思 SDK 中實現算法控制和數據流能為設計帶來極大的靈活性。這是因為用戶可以用相同的方式設計和集成新的硬件加速器,同時還可以修改必要的控制和數據流以集成新的硬件加速器。最終得到的就是一種軟件控制、硬件加速的設計,其靈活度可媲美純軟件實現方案,同時其性能可媲美純硬件實現方案。
本文介紹的人群運動分類算法的控制和數據流從通過視頻幀隊列 API 功能采集視頻幀開始。當視頻幀獲取完畢,用戶應用把當前的和之前的視頻幀數據傳輸到硬件加速器,完成運動向量的計算。
此時系統在軟件中計算運動向量的統計屬性和分類結果。這樣做的原因是這些步驟不涉及任何像素級處理,只會增加很少的處理開銷。當分類結果計算完成時,用屏幕顯示(OSD)功能把結果和運動向量顯示在處理后的幀上。這些屏幕顯示功能也是在賽靈思 SDK 中用 C/C++ 語言實現的。
這些構建模塊(實時視頻流水線、硬件加速器和算法控制/數據流)全部就緒后,總體系統設計即告完成。隨后我們對基于 FPGA 的實現方案進行了測試,并與之前的桌面 PC 型實現方案比較結果的準確性。兩個結果是完全一致的。我們使用來自明尼蘇達大學數據庫( http://mha.cs.umn.edu/proj_recognition.sht- ml )和來自www.gettyimages.com 的各種測試視頻對本系統進行了測試。
實現方案結果
整個設計只使用了 Spartan-6-LX45 FPGA 上 30% 的Slice LUT、60% 的 BRAM 和12% 的 DSP48E 乘法器資源。圖 6 所示是硬件設置(上)和實際系統輸出。硬件設置由 Digilent Atlys Spartan 6 FPGA 板和定制視頻接口卡組成,利用視頻 ADC 和 DAC 可為 FPGA 提供視頻輸入/輸出功能。如欲觀看該系統的詳細演示視頻,敬請訪問下列 Web 鏈接:
http://www.dailymotion.com/video/x2av1wo_fpga-based-real-time-hu-man-cro.。.
http://www.dailymotion.com/vid-eo/x23icxj_real-time-motion-vec-tors-comp.。.
http://www.dailymotion.com/video/x28sq1c_crowd-motion-classifica-tion-us.。.
圖 6:硬件設置(上)和把場景分類為驚恐的實際 FPGA 處理后的幀
巨大的未來潛力
FPGA 是面向實時視頻處理等需要高性能的應用的理想平臺。開發這種應用要求進行一定的架構考量,以充分發揮所選 FPGA 的性能優勢。此外使用 EDK 和 Vivado HLS 等先進工具,能夠以比過去高得多的效率和更短的開發時間實現總體系統設計。
因此正如我們在本文中所展示的,利用上述工具在 FPGA 上實現性能關鍵型應用有著巨大的潛力。有這樣成功運行的平臺作為先例,我們期望把這一成果推廣用于解決更多的技術問題,例如自動化交通監測、醫院中的自動病患觀察等更多的應用。
1. Ramin Mehran、Mubarak Shah,《使用社會力模型檢測異常人群行為》,IEEE 計算機視覺與模式識別 (CVPR) 國際會議,邁阿密,2009年
2. Duan-Yu Chen、Po-Chung Huang,《基于運動的人群異常事件檢測》,《視覺計算和圖像顯示期刊(Journal of Visual Computation and Image Representation)》,2011 年第 2 期第 22 卷,第 178-186 頁
3. OmniTek OSVP:http://omnitek.tv/sites/ default/files/OSVP.pdf
鳴謝
作者在此鳴謝合著者 Shoab A. Khan 教授貢獻的偉大創意以及 Darshika G. Parera 博士和 Umair Ahsun 博士給予的杰出靈感。
作者:Muhammad Bilal 在讀理科碩士 先進工程研究中心,巴基斯坦伊斯蘭堡 bilal.case.edu@gmail.com
Shoab.A. Khan 教授 先進工程研究中心( www.case.edu.pk ) 巴基斯坦伊斯蘭堡 shoab@case.edu.pk
?








 工商網監
工商網監
評論