 電子發燒友App
電子發燒友App


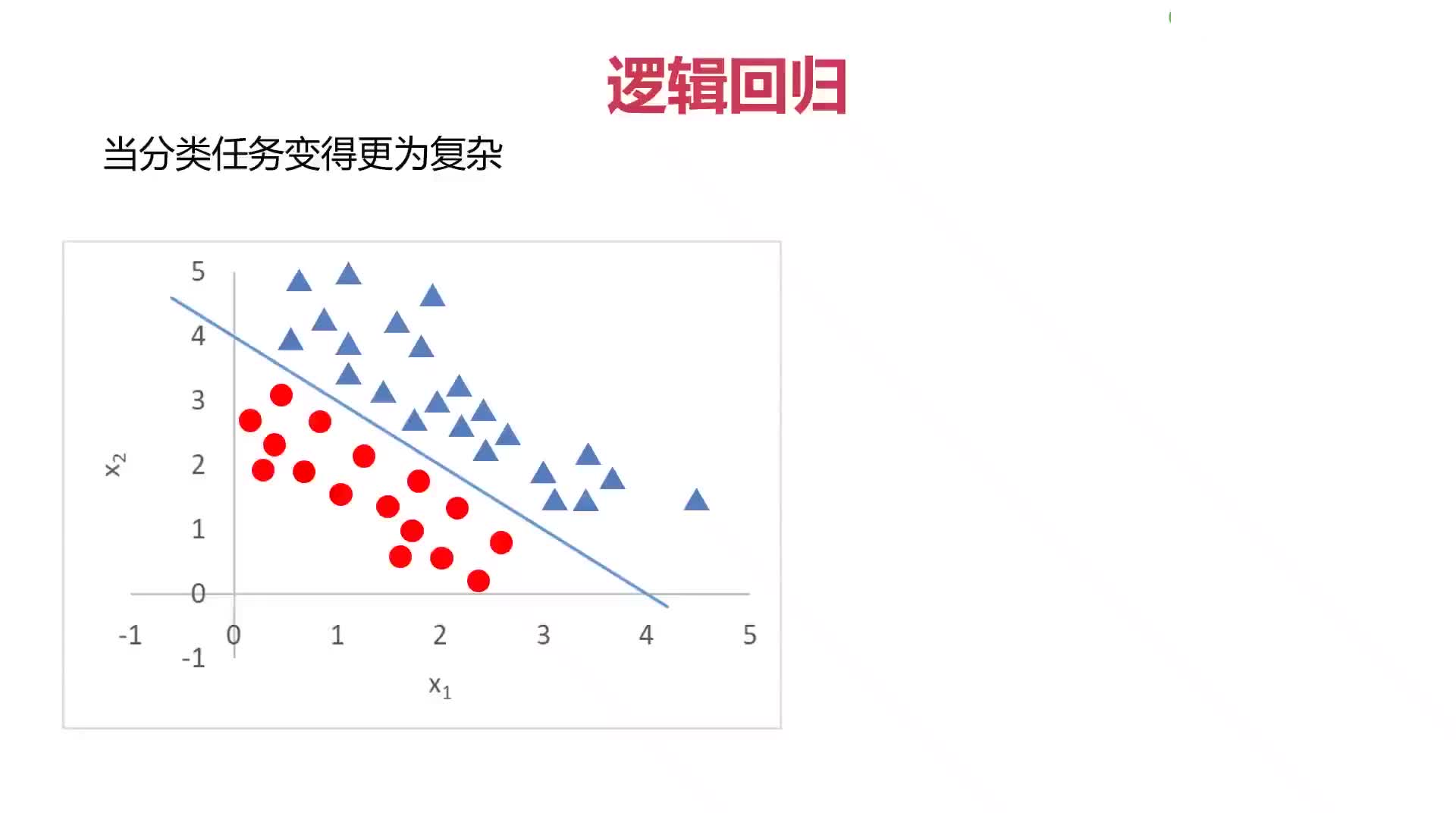
對人工智能領域來說,2016年是值得紀念的一年。不僅計算機「學」得更多更快了,我們也 懂得了如何改進計算機系統。一切都在步入正軌,因此,我們正目睹著前所未有的重大進步:我們有了能用圖片來講故事的程序,有了無人駕駛汽車,甚至有了能夠 創作藝術的程序。如果你想要了解2016年的更多進展,請一定要讀一讀這篇文章。AI技術已逐步成為許多技術的核心,所以,理解一些常用術語和工作原理成為了一件很重要的事。
人工智能是什么?
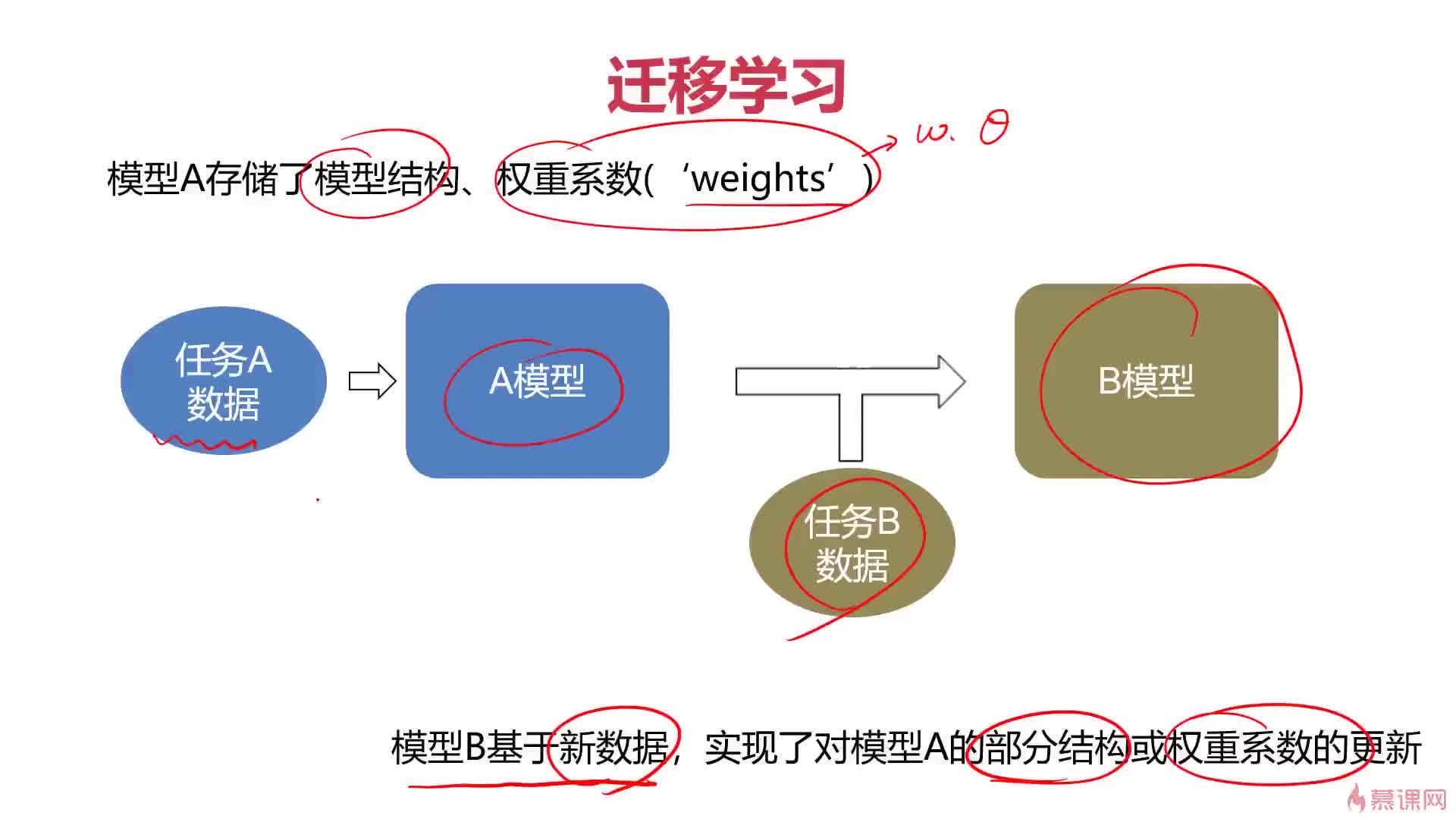
人工智能的很多進步都是新的統計模型,其中絕大多數來自于一項稱作「人工神經網絡」(artificial neural networks)的技術,簡稱ANN。這種技術十分粗略地模擬了人腦的結構。值得注意的是,人工神經網絡和神經網絡是不同的。很多人為了方便起見而把 「人工神經網絡」中的人工二字省略掉,這是不準確的,因為使用「人工」這個詞正是為了與計算神經生物學中的神經網絡相區別。以下便是真實的神經元和神經突 觸。
我 們的ANN中有稱作「神經元」的計算單元。這些人工神經元通過「突觸」連接,這里的「突觸」指的是權重值。這意味著,給定一個數字,一個神經元將執行某種 計算(例如一個sigmoid函數),然后計算結果會被乘上一個權重。如果你的神經網絡只有一層,那么加權后的結果就是該神經網絡的輸出值。或者,你也可 以配置多層神經元,這就是深度學習的基礎概念。
它們起源何處?
人工神經網絡不是一個新概念。事實上,它們過去的名字不叫神經網絡,它們最早的狀態和我們今天所看到的也完全不一樣。20世紀60年代,我們把它稱之為感知 機(perceptron),是由McCulloch-Pitts神經元組成。我們甚至還有了偏差感知機。最后,人們開始創造多層感知機,也就是我們今天 通常聽到的人工神經網絡。
如果神經網絡開始于20世紀60年代,那為什么它們直到今天才流行起來?這是個很長的故事,簡單來說,有一些原因阻礙了ANN的發展。比如,我們過去的計算 能力不夠,沒有足夠多的數據去訓練這些模型。使用神經網絡會很不舒服,因為它們的表現似乎很隨意。但上面所說的每一個因素都在變化。如今,我們的計算機變 得更快更強大,并且由于互聯網的發展,我們可使用的數據多種多樣。
它們是如何工作的?
上面我提到了運行計算的神經元和神經突觸。你可能會問:「它們如何學習要執行何種計算?」從本質上說,答案就是我們需要問它們大量的問題,并提供給它們答 案。這叫做有監督學習。借助于足夠多的「問題-答案」案例,儲存在每個神經元和神經突觸中的計算和權值就能慢慢進行調整。通常,這是通過一個叫做反向傳播 (backpropagation)的過程實現的。
想象一下,你在沿著人行道行走時看到了一個燈柱,但你以前從未見過它,因此你可能會不慎撞到它并「哎呦」慘叫一聲。下一次,你會在這個燈柱旁邊幾英寸的距離 匆匆而過,你的肩膀可能會碰到它,你再次「哎呦」一聲。直到第三次看到這個燈柱,你會遠遠地躲開它,以確保完全不會碰到它。但此時意外發生了,你在躲開燈 柱的同時卻撞到了一個郵箱,但你以前從未見過這個郵箱,你徑直撞向它——「燈柱悲劇」的全過程又重現了。這個例子有些過度簡化,但這實際上就是反向傳播的 工作原理。一個人工神經網絡被賦予多個類似案例,然后它試著得出與案例答案相同的答案。當它的輸出結果錯誤時,這個錯誤會被重新計算,每個神經元和神經突 觸的值會通過人工神經網絡反向傳播,以備下次計算。此過程需要大量案例。為了實際應用,所需案例的數目可能達到數百萬。
既然我們理解了人工神經網絡以及它們的部分工作原理,我們可能會想到另外一個問題:我們怎么知道我們需要多少神經元?為什么前文要用粗體標出「多層」一詞? 其實,每層人工神經網絡就是一個神經元的集合。在為ANN輸入數據時我們有輸入層,同時還有許多隱藏層,這正是魔法誕生之地。最后,我們還有輸出 層,ANN最終的計算結果放置于此供我們使用。
一 個層級本身是神經元的集合。在多層感知機的年代,我們起初認為一個輸入層、一個隱藏層和一個輸出層就夠用了。那時是行得通的。輸入幾個數字,你僅需要一組 計算,就能得到結果。如果ANN的計算結果不正確,你再往隱藏層上加上更多的神經元就可以了。最后我們終于明白,這么做其實只是在為每個輸入和輸出創造一 個線性映射。換句話說,我們了解了,一個特定的輸入一定對應著一個特定的輸出。我們只能處理那些此前見過的輸入值,沒有任何靈活性。這絕對不是我們想要 的。
如今,深度學習為我們帶來了更多的隱藏層,這是我們如今獲得了更好的ANN的原因之一,因為我們需要數百個節點和至少幾十個層級,這帶來了亟需實時追蹤的大 量變量。并行程序的進步也使我們能夠運行更大的ANN批量計算。我們的人工神經網絡正變得如此之大,使我們不能再在整個網絡中同時運行一次迭代。我們需要 對整個網絡中的子集合進行批量計算,只有完成了一次迭代,才可以應用反向傳播。





















































































 工商網監
工商網監
評論